一种基于深度学习的声反馈抵消方法
1.本发明涉及声反馈装置和处理方法领域,具体涉及一种深度学习的声反馈抵消方法。
背景技术:
2.扩声系统广泛应用于多媒体电教室、本地会议系统和助听器以及人工耳蜗等电声设备,该电声系统至少包括一个传声器、一个放大器和一个扬声器。当传声器与扬声器处于同一个声学环境,扬声器信号经过声学反馈路径之后将被传声器重新采集,被放大器再次放大,并再次被扬声器播放,该过程不断循环形成声反馈。当某些频点满足奈奎斯特不稳定性条件时则会使得信号幅度不断增加并引发啸叫,信号的幅值过大会对音频设备造成严重的破坏。因此,抵消或抑制声反馈既能提高系统的扩声性能,又能保证扩声系统的稳定性和安全性。
技术实现要素:
3.本发明的目的在于建立一种基于深度学习的声反馈抵消模型,并将训练好的声反馈抵消模型应用在闭环系统(闭环系统是指系统的输入影响输出同时又受输出的直接或者间接影响的系统,例如如助听器系统和现场扩声系统等)实现声反馈消除。
4.为达到上述目的,本发明通过下述技术方案实现。
5.本发明提出了一种基于深度学习的声反馈抵消方法,该方法包括:
6.将预先建立并在开环条件下训练好的基于深度学习的声反馈抵消模型应用在闭环系统中;
7.通过基于深度学习的声反馈抵消模型对闭环系统中带声反馈的目标音频信号进行处理,获得目标音频信号的时频谱;
8.根据目标音频信号的时频谱重建时域目标音频信号,实现声反馈的抵消。
9.作为上述技术方案的改进之一,所述方法还包括:对基于深度学习的声反馈抵消模型进行训练,具体包括以下步骤:
10.在开环条件下生成带反馈的音频信号和目标音频信号,建立训练数据集;
11.设计深度学习神经网络结构及超参数,建立基于深度学习的声反馈抵消模型;
12.使用训练数据通过基于深度学习的声反馈抵消模型对带反馈的音频信号进行分帧和特征提取,根据目标音频信号与带反馈的音频信号逐帧逐频点提取学习目标,并进行深度学习神经网络的目标映射;
13.选取损失函数进行训练,得到训练好的基于深度学习的声反馈抵消模型。
14.作为上述技术方案的改进之一,所述在开环条件下生成带反馈的音频信号和目标音频信号,建立训练数据集,具体包括:
15.对声反馈的闭环系统进行建模,并根据闭环系统生成声反馈路径;
16.生成闭环系统的目标音频信号s(t);
17.对目标音频信号s(t)作延时处理,得到参考信号x(t);
18.将参考信号x(t)与根据闭环系统生成的声反馈路径进行卷积,并和目标音频信号s(t)线性叠加,得到带反馈的开环信号z(t);
19.将参考信号x(t)的复频谱和带反馈的开环信号z(t)的复频谱进行张量堆叠,得到训练数据集,作为深度学习模型的输入。
20.作为上述技术方案的改进之一,所述对目标音频信号s(t)作延时处理,得到参考信号x(t),表达式为:
21.x(t)=s(t-τ)
22.其中,τ的取值由整个扩声系统前向通路处理时延确定;
23.所述将参考信号x(t)与根据闭环系统生成的声反馈路径进行卷积,并和目标音频信号s(t)线性叠加,得到带反馈的开环信号z(t),表达式为:
24.z(t)=αx(t)*f(t)+s(t)
25.其中,*表示卷积,α为可变参数,用于调节反馈音频信号与目标音频信号占比。
26.作为上述技术方案的改进之一,所述使用训练数据通过基于深度学习的声反馈抵消模型对带反馈的音频信号进行分帧和特征提取,根据目标音频信号与带反馈的音频信号逐帧逐频点提取学习目标,并进行深度学习神经网络的目标映射,具体包括:
27.对z(t)、x(t)和s(t)分别作k点短时傅里叶变换,分别得到z(t)、x(t)和s(t)在时间帧l和频带k处的复数谱z(k,l)、x(k,l)和s(k,l);
28.根据z(t)、x(t)和s(t)的表达式关系,得到z(k,l)和x(k,l)的计算关系式;
29.通过基于深度学习的声反馈抵消模型对z(k,l)和x(k,l)的相关参数f(k,l)进行估计;
30.利用相关参数f(k,l)的估计值获得s(k,l)的估计信号完成深度学习神经网络的目标映射。
31.作为上述技术方案的改进之一,所述z(k,l)、x(k,l)和s(k,l)的表达式分别为:
[0032][0033][0034][0035]
其中,w(μ)为窗函数,r为帧移,μ为求和变量,j为虚数符号;
[0036]
所述z(k,l)和x(k,l)的计算关系式为:
[0037]
z(k,l)=x(k,l)f(k,l)+s(k,l);
[0038]
所述的表达式为:
[0039][0040]
其中,表示f(k,l)的估计值,为神经网络映射函数,φ为网络参数;
[0041]
所述的表达式为:
[0042][0043]
作为上述技术方案的改进之一,所述根据目标音频信号的时频谱重建时域目标音频信号,包括:对作反傅里叶变换并进行重叠相加,得到目标音频估计信号的时域形式完成重建。
[0044]
作为上述技术方案的改进之一,在提取的特征和训练目标都是幅度谱的情况下,所述损失函数的表达式为:
[0045][0046]
其中,表示目标音频估计信号的复数谱,下标f表示求矩阵的frobenius范数。
[0047]
作为上述技术方案的改进之一,在提取的特征和训练目标都是复数谱的情况下,所述损失函数的表达式为:
[0048][0049]
其中,和分别表示目标音频估计信号的实数谱和虚数谱,sr(k,l)和si(k,l)分别表示目标音频信号的实数谱和虚数谱。
[0050]
作为上述技术方案的改进之一,在提取的特征和训练目标都是复数谱的情况下,设计损失函数时在幅度上做限制,所述损失函数的表达式为:
[0051][0052]
其中,λ为取值在0至1之间的权重系数。
[0053]
本发明与现有技术相比优点在于:
[0054]
本发明方法通过构造开环数据集来训练深度学习声反馈抵消模型,采用开环模式对模型进行训练,并将训练好的模型应用在闭环系统实现声反馈消除,提高语音质量和可懂度,并显著提升扩声系统增益。
附图说明
[0055]
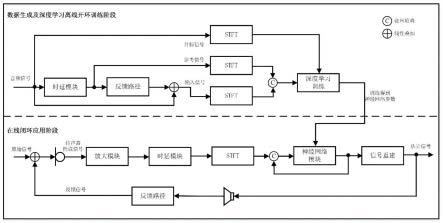
图1是本发明的算法流程图;
[0056]
图2是闭环系统的示意图;
[0057]
图3是深度网络模型结构图,以gcrn为例;
[0058]
图4是深度网络模块消除声反馈的示意图;
[0059]
图5是一段语音未经过算法和经过算法的处理结果语谱图,其中,图5(a)为原始信号谱图,图5(b)为带反馈的闭环信号谱图,图5(c)为估计信号谱图。
具体实施方式
[0060]
本发明涉及声反馈装置和处理方法,针对语音扩声系统、音乐扩声系统或者语音和音乐扩声兼用系统以及助听器、辅听器和对讲机等,通过设计深度学习网络结构并通过
生成专用训练数据集以实现声反馈抵消。该方法通过模拟生成大量的单位脉冲响应模拟声学反馈路径,并和大量的语音和音频数据耦合,生成相应训练数据集并完成模型训练。该模型采用开环模式进行训练,并应用于闭环系统从而有效抵消反馈信号,提高语音质量和可懂度,并显著提升扩声系统增益。该方法的创新之处是通过构造开环数据集来训练深度声反馈抵消网络,并将其应用在闭环系统实现声反馈消除。
[0061]
本发明针对扩声系统的声反馈现象,提出基于深度学习的声反馈抵消方法。首先是构造训练集,先生成大量的单位脉冲响应模拟声学反馈路径,以语音和音频信号作为外部音频输入,在开环条件下生成带反馈的音频信号和目标音频信号;接着,对带反馈的音频信号进行分帧和特征提取,根据目标音频信号与带反馈的音频信号逐帧逐频点提取学习目标,搭建深度神经网络模型,并采用开环方式训练网络,直至误差收敛到一定的范围,完成模型训练;最后,在实际系统测试及应用阶段,对闭环系统中的带反馈音频信号进行分帧和特征提取,采用已训练的深度神经网络模型对其进行处理,得到目标音频信号时频谱,并重建时域目标音频信号。
[0062]
本发明提供一种基于深度学习的声反馈抵消方法,该方法针对助听器或者现场扩声等声反馈系统可能存在的啸叫问题,以开环训练方式训练深度神经网络模型,再将模型置于闭环的实际系统中对信号进行反馈消除,具体步骤包括:
[0063]
步骤一:对声反馈的闭环系统进行建模;
[0064]
步骤二:根据应用场景模拟生成声学反馈路径单位脉冲响应;
[0065]
步骤三:数据的特征提取和网络的目标映射;
[0066]
步骤四:设计深度学习网络结构及超参数;
[0067]
步骤五:选取损失函数,并训练网络;
[0068]
步骤六:将训练好的模型加入闭环系统中进行声反馈抵消或处理,并重建时域信号。
[0069]
以下结合实施例进一步说明本发明所提供的技术方案。
[0070]
实施例
[0071]
本发明的流程图如图1所示,具体实施方式如下:
[0072]
步骤一:如图2所示,v(t)为外部输入信号,假定为外部音频信号,u(t)为馈给扬声器信号,y(t)为传声器拾取信号,f(t)为声学反馈路径的单位脉冲响应,g(t)为正向通路放大模块的单位脉冲响应,由此得到:
[0073][0074]
其中t为采样时刻,*为卷积运算,对时域信号作傅里叶变换,有:
[0075][0076]
其中,ω为角频率。不失一般性,我们假设正向通路增益为全带增益,即g(ω)=g为常数;如果g(ω)=g与频率相关,可将频率相关的部分并入声学反馈路径的频率响应。由此可得到扬声器到传声器的闭环传递函数:
[0077][0078]
根据nyquist系统不稳定判决条件,当环路增益满足以下条件时:
[0079][0080]
其中表示取相位,|
·
|表示取模值,系统处于不稳定状态。在角频率ω位置,当系统环路增益函数模值大于等于1时,且环路增益函数相位角为2π整数倍时,扩声系统就会在该频率产生震荡,形成啸叫。
[0081]
步骤二:声学反馈路径可以通过实际测量获得,但是在深度学习的模型训练中,需要大量的数据,故我们在本步骤中采用仿真的手段生成声学反馈路径。以房间中的扩声系统为例,可以通过以下的公式模拟生成:
[0082][0083]
其中,b(t)为零均值高斯噪声,fs为采样频率,单位为赫兹(hz),t
60
为混响时间,单位为秒(s)。在针对助听器的应用中,f(t)的阶长为50到100;针对会议扩声系统,f(t)的阶长可根据混响时间和传声器与扬声器的距离确定,混响时间越长、扬声器与传声器距离越远,阶长越高。会议扩声系统应用也可用现有大量实际录制的房间脉冲响应作为f(t)。
[0084]
步骤三:将目标音频信号s(t)作τs的延时,得到参考信号:
[0085]
x(t)=s(t-τ)(6)
[0086]
其中,τ的取值由整个扩声系统前向通道处理时延确定,对于助听器应用一般小于0.01s,对于现场扩声系统,这个时延应更小。将x(t)与步骤二中的反馈路径f(t)卷积,并和目标音频信号s(t)在开环的条件下直接叠加,得到带反馈的开环信号:
[0087]
z(t)=αx(t)*f(t)+s(t)(7)
[0088]
其中,α为可变参数,用于调节反馈音频信号与目标音频信号占比。分别对时域信号z(t),x(t)和s(t)作k点短时傅里叶变换,得到二者在时间帧l和频带k处的复数谱表示:
[0089][0090]
其中,w(t)为窗函数,r为帧移。
[0091]
由式(7)得,在时频域上有如下的近似:
[0092]
z(k,l)=x(k,l)f(k,l)+s(k,l)(9)
[0093]
其中,f(k,l)是和z(k,l),x(k,l)相关的参数,在本方法中,我们利用深度神经网络对该参数进行估计:
[0094][0095]
其中,为神经网络映射函数,φ为网络参数,将该式代入式(9),有
[0096][0097]
步骤四:深度神经网络框架的设计。本步骤可以采用卷积循环网络(rnn)及其变体(lstm,gru等)以及卷积循环网络(crn)等网络框架。以gcrn网络为例,该网络由三部分构成,分别为卷积编码器(encoderblock)、分组长短时记忆模块(glstm)和两个卷积解码器(decoder block),如图3所示。编码器一共包括5个卷积模块,每一个卷积模块包括二维卷积层(conv)、批归一化层(bn)和指数线性激活(elu)单元。在解码器端,本发明采用与编码部分相似的卷积模块。解码部分为两个解码器,每个解码器包括5个反卷积块,每个卷积块包括反卷积层(conv-trans)、批归一化层和指数线性激活单元。为了补充编码部分由于特征维压缩引起的信息损失,本发明引入跳跃连接(skip connection),将解码块的特征与对应编码端的特征在通道维度上堆叠并送入下一个反卷积块。在反馈系统中,上下帧的信号之间均存在因果关系,为了保证系统的正常运行,本发明采用了因果卷积,确保当前帧的计算只与过去时刻帧的计算有关,而不涉及到未来帧的信息。在fs=16000hz,k=320情况下,具体的网络参数设置与维度变化如表1所示。
[0098]
表1是具体的网络参数设置和维度变化。
[0099][0100]
其中,卷积层的参数以卷积核,通道数、跳跃值形式表示,输入和输出尺寸以通道数、时间维、特征维的形式表示。此外,设置网络的训练批次为16,迭代次数为30次,使用学习率为1.0
×
10-3
和衰减率为1.0
×
10-7
的adam优化器对网络训练进行优化,并开始训练。这里的深度神经网络可采用其他网络形式,如基于幅度映射的深度神经网络,基于实数或者复数掩膜映射的深度神经网络;采用浅层神经网络也可实现该目标,依然是本发明的简单延申。采用本发明提出的平行数据构造方法,以及开环训练,在线应用模式,即便采用时域深度神经网络模型,也是本发明的简单延申。
[0101]
步骤五:损失函数可以直接选择估计结果与训练目标之间的均方误差(mean squared error,mse),对于提取的特征和训练目标是幅度谱的情况下,其损失函数表达式如下:
[0102]
[0103]
其中,表示估计信号的复数谱,下标f表示求矩阵的frobenius范数。而对于提取的特征和训练目标都是复数谱的情况下,其损失函数如下式所示:
[0104][0105]
其中,和分别表示估计信号的实数谱和虚数谱,sr和si分别表示目标信号的实数谱和虚数谱。此外,对于网络的映射目标是复数谱的情况,在幅度上做限制可以有效地提升语音或音频的质量,故该情况下的损失函数可以进一步表示为:
[0106][0107]
其中λ为取值在0至1之间的权重系数,典型取值为0.5,在强混响场景,λ应趋近于0,低混响场景,λ应趋近于1.0。
[0108]
步骤六:将训练好的神经网络加入闭环系统中抵消声反馈,如图4所示。由式(1)得,参考信号为u(t),带反馈信号为y(t),作短时傅里叶变换,有:
[0109][0110]
根据式(11),利用训练好的神经网络模块对该信号处理,有:
[0111][0112]
得到估计信号的复数谱再对其作反傅里叶变换和重叠相加便可得到估计信号的时域形式原始信号、带反馈的闭环信号、估计信号如图5所示,其中,图5(a)为原始信号谱图,图5(b)为带反馈的闭环信号谱图,图5(c)为估计信号谱图。
[0113]
从上述对本发明的具体描述可以看出,该模型采用开环模式进行训练,并应用于闭环系统从而有效抵消反馈信号,提高语音质量和可懂度,并显著提升扩声系统增益。
[0114]
最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制。尽管参照实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,对本发明的技术方案进行修改或者等同替换,都不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1