一种智能话术推荐方法、系统、设备及存储介质与流程
1.本发明实施例涉及语音处理技术领域,具体涉及一种智能话术推荐方法、系统、设备及存储介质。
背景技术:
2.随着云计算和大数据技术发展,电信产业的客户服务呼叫中心需要对来电咨询人的对话语音进行识别并转录为文本,根据转录文本为客服工作人员推荐相关的答复话术,从而提高客户服务工作人员的工作效率。
3.现有技术方案是基于普通话的主流语音识别,对于不同地域的方言语音识别错误率高,并且由于地域方言韵律差异性而导致信号频率分布不均匀,使得方言语音的语义分析歧义较大,导致基于语义的话术推荐的推荐错误率高。
技术实现要素:
4.为此,本发明实施例提供一种智能话术推荐方法、系统、设备及存储介质,以解决现有技术针对带有方言的语音的语音识别错误率高和话术推荐错误率高的问题。
5.为了实现上述目的,本发明实施例提供如下技术方案:
6.根据本发明实施例的第一方面,提供了一种智能话术推荐方法,所述方法包括:
7.对客户服务电话中的语音进行声音采集,得到对话语音信号,对所述对话语音信号进行信号预处理,得到预处理后的对话语音文件;
8.利用所述预处理后的对话语音文件进行第一向量化处理,得到对应的频谱特征矩阵;
9.将所述频谱特征矩阵输入至预先训练好的韵律模型,得到模型计算结果,利用所述模型计算结果,得到所述频谱特征矩阵的韵律识别结果,并根据所述韵律识别结果,对所述频谱特征矩阵进行文本映射处理,得到第一词序文本;
10.基于所述第一词序文本中的词特征,对所述第一词序文本进行第二向量化处理,得到对应的第一向量特征矩阵;
11.对所述第一向量特征矩阵进行意图实体识别,得到意图识别结果,根据所述意图识别结果,从所述第一词序文本中提取出意图实体,并利用所述意图实体,得到第二词序文本;
12.利用所述第二词序文本,在语料库中进行语义相似度匹配,得到推荐话术。
13.进一步地,对客户服务电话中的语音进行声音采集,得到对话语音信号,对所述对话语音信号进行信号预处理,得到预处理后的对话语音文件,包括:
14.利用麦克风采集所述客户服务电话中的对话语音,得到所述对话语音信号;
15.对所述对话语音信号进行第一波束形成处理,得到第一预处理信号;
16.对所述第一预处理信号进行第二波束形成处理,得到第二预处理信号;
17.利用所述第二预处理信号进行频谱信号控制处理,得到所述对话语音文件。
18.进一步地,利用所述预处理后的对话语音文件进行第一向量化处理,得到对应的频谱特征矩阵,包括:
19.基于时序对所述对话语音文件进行切分,得到切分后的对话语音文件;
20.针对每段所述切分后的对话语音文件进行特征提取,得到所述切分后的对话语音文件对应的语音频谱特征,所述语音频谱特征包括频谱权重参数tn、信号延时参数yn和方言音强参数τn,其中,n为大于或等于0且小于切分总段数的正整数;
21.利用所述频谱权重参数tn、所述信号延时参数yn和所述方言音强参数τn,计算得到频谱特征矩阵a,所述频谱特征矩阵a的计算公式为:
22.a={a(n)}
23.a(n)=∑yn×
s(tn+τn)
24.其中,a(n)表示所述频谱特征矩阵a中的第n个元素;s为多元非线性拟合参数。
25.进一步地,将所述频谱特征矩阵输入至预先训练好的韵律模型,得到模型计算结果,利用所述模型计算结果,得到所述频谱特征矩阵的韵律识别结果,包括:
26.将所述频谱特征矩阵a输入至韵律识别模型,计算得到韵律模型计算结果x,所述韵律模型计算结果x的计算公式为:
[0027][0028]
其中,m由所述频谱特征矩阵a的长度决定;j为预设的加权参数;x为预设参数;ω、θ和v分别为音高参数、音强参数和音长参数,分别通过提取历史语音数据的音高、音强和音长并计算平均值得到;
[0029]
分别利用预设的普通话模板语音文件和预设的方言话模板语音文件,得到普通话模板阈值x'和方言话模板阈值x”;
[0030]
利用所述韵律模型计算结果x和所述普通话模板阈值x',计算得到第一差值绝对值c1,所述第一差值绝对值c1的计算公式为:
[0031]
c1=||x|-|x
′
||
[0032]
利用所述韵律模型计算结果x和所述方言话模板阈值x”,计算得到第二差值绝对值c2,所述第二差值绝对值c2的计算公式为:
[0033]
c2=||x|-|x
″
||
[0034]
判断所述第一差值绝对值c1是否大于所述第二差值绝对值c2;
[0035]
若所述第一差值绝对值c1大于所述第二差值绝对值c2,则所述频谱特征矩阵a的韵律识别结果为方言话;
[0036]
若所述第一差值绝对值c1小于或等于所述第二差值绝对值c2,则所述频谱特征矩阵a的韵律识别结果为普通话。
[0037]
进一步地,基于所述第一词序文本中的词特征,对所述第一词序文本进行第二向量化处理,得到对应的第一向量特征矩阵,包括:
[0038]
对所述第一词序文本进行向量化编码,得到词序文本向量;
[0039]
利用所述词序文本向量和对应的预设特征加权参数,计算得到第一向量特征矩阵q,所述第一向量特征矩阵q的计算公式为:
[0040]
q={q
t
}
[0041]qt
=f(x
t
+k
t
)
[0042]
其中,q
t
为特征词向量,表示所述第一向量特征矩阵q的第t个的元素;x
t
表示所述词序文本向量中的第t个词向量;k
t
为所述第t个词向量对应的预设特征加权参数,所述预设特征加权参数包括词性特征参数、词根特征参数和词缀特征参数。
[0043]
进一步地,对所述第一向量特征矩阵进行意图实体识别,得到意图识别结果,根据所述意图识别结果,从所述第一词序文本中提取出意图实体,并利用所述意图实体,得到第二词序文本,包括:
[0044]
针对所述第一向量特征矩阵q中的各个所述特征词向量q
t
,计算得到对应的意图实体概率p,所述意图实体概率p的计算公式为:
[0045][0046]
其中,z和a分别表示预设词法权重参数和预设语法权重参数;q
t-1
表示所述第一向量特征矩阵q的第t-1个的元素;m由所述特征词向量q
t
对应的词序文本的字符长度决定;h表示词法语法识别参数;β为预设字符权重参数;bf表示意图实体比例参数;wf表示预设实体名词权重参数;
[0047]
判断所述意图实体概率p是否大于第一预设阈值;
[0048]
若所述意图实体概率p大于第一预设阈值,则将该所述意图实体概率p对应的所述第一词序文本中的词汇作为意图实体;
[0049]
若所述意图实体概率p小于或等于第一预设阈值,则不将所述意图实体概率p对应的所述第一词序文本中的词汇作为所述意图实体;
[0050]
利用所述意图实体,得到所述第二词序文本。
[0051]
进一步地,利用所述第二词序文本,在语料库中进行语义相似度匹配,得到推荐话术,包括:
[0052]
对所述第二词序文本进行第二向量化处理,得到第二向量特征矩阵qk,其中,k为大于或等于零的正整数;
[0053]
对所述语料库中的话术对应的话术文本和所述话术文本对应的话术语音均进行第二向量化处理,分别得到第三向量特征矩阵q
k-1
和第四向量特征矩阵q
k+1
;
[0054]
利用所述第二向量特征矩阵qk、所述第三向量特征矩阵q
k-1
和所述第四向量特征矩阵q
k+1
,计算得到话术相似度sim,所述话术相似度sim的计算公式为:
[0055][0056]
判断所述话术相似度sim是否大于第二预设阈值;
[0057]
若所述话术相似度sim大于所述第二预设阈值,则将所述语料库中的话术作为所述推荐话术;
[0058]
若所述话术相似度sim小于或等于所述第二预设阈值,则不将所述语料库中的话术作为所述推荐话术。
[0059]
根据本发明实施例的第二方面,提供了一种智能话术推荐系统,所述系统包括:
[0060]
语音信号预处理模块,用于对客户服务电话中的语音进行声音采集,得到对话语音信号,对所述对话语音信号进行信号预处理,得到预处理后的对话语音文件;
[0061]
第一向量化模块,用于利用所述预处理后的对话语音文件进行第一向量化处理,得到对应的频谱特征矩阵;
[0062]
韵律识别模块,用于将所述频谱特征矩阵输入至预先训练好的韵律模型,得到模型计算结果,利用所述模型计算结果,得到所述频谱特征矩阵的韵律识别结果,并根据所述韵律识别结果,对所述频谱特征矩阵进行文本映射处理,得到第一词序文本;
[0063]
第二向量化模块,用于基于所述第一词序文本中的词特征,对所述第一词序文本进行第二向量化处理,得到对应的第一向量特征矩阵;
[0064]
意图识别模块,用于对所述第一向量特征矩阵进行意图实体识别,得到意图识别结果,根据所述意图识别结果,从所述第一词序文本中提取出意图实体,并利用所述意图实体,得到第二词序文本;
[0065]
话术推荐模块,用于利用所述第二词序文本,在语料库中进行语义相似度匹配,得到推荐话术。
[0066]
进一步地,对客户服务电话中的语音进行声音采集,得到对话语音信号,对所述对话语音信号进行信号预处理,得到预处理后的对话语音文件,包括:
[0067]
利用麦克风采集所述客户服务电话中的对话语音,得到所述对话语音信号;
[0068]
对所述对话语音信号进行第一波束形成处理,得到第一预处理信号;
[0069]
对所述第一预处理信号进行第二波束形成处理,得到第二预处理信号;
[0070]
利用所述第二预处理信号进行频谱信号控制处理,得到所述对话语音文件。
[0071]
进一步地,利用所述预处理后的对话语音文件进行第一向量化处理,得到对应的频谱特征矩阵;
[0072]
基于时序对所述对话语音文件进行切分,得到切分后的对话语音文件;
[0073]
针对每段所述切分后的对话语音文件进行特征提取,得到所述切分后的对话语音文件对应的语音频谱特征,所述语音频谱特征包括频谱权重参数tn、信号延时参数yn和方言音强参数τn,其中,n为大于或等于0且小于切分总段数的正整数;
[0074]
利用所述频谱权重参数tn、所述信号延时参数yn和所述方言音强参数τn,计算得到频谱特征矩阵a,所述频谱特征矩阵a的计算公式为:
[0075]
a={a(n)}
[0076]
a(n)=∑yn×
s(tn+τn)
[0077]
其中,a(n)表示所述频谱特征矩阵a中的第n个元素;s为多元非线性拟合参数。
[0078]
进一步地,将所述频谱特征矩阵输入至预先训练好的韵律模型,得到模型计算结果,利用所述模型计算结果,得到所述频谱特征矩阵的韵律识别结果,包括:
[0079]
将所述频谱特征矩阵a输入至韵律识别模型,计算得到韵律模型计算结果x,所述韵律模型计算结果x的计算公式为:
[0080][0081]
其中,m由所述频谱特征矩阵a的长度决定;j为预设的加权参数;x为预设参数;ω、
θ和v分别为音高参数、音强参数和音长参数,分别通过提取历史语音数据的音高、音强和音长并计算平均值得到;
[0082]
分别利用预设的普通话模板语音文件和预设的方言话模板语音文件,得到普通话模板阈值x'和方言话模板阈值x”;
[0083]
利用所述韵律模型计算结果x和所述普通话模板阈值x',计算得到第一差值绝对值c1,所述第一差值绝对值c1的计算公式为:
[0084]
c1=||x|-|x
′
||
[0085]
利用所述韵律模型计算结果x和所述方言话模板阈值x”,计算得到第二差值绝对值c2,所述第二差值绝对值c2的计算公式为:
[0086]
c2=||x|-|x
″
||
[0087]
判断所述第一差值绝对值c1是否大于所述第二差值绝对值c2;
[0088]
若所述第一差值绝对值c1大于所述第二差值绝对值c2,则所述频谱特征矩阵a的韵律识别结果为方言话;
[0089]
若所述第一差值绝对值c1小于或等于所述第二差值绝对值c2,则所述频谱特征矩阵a的韵律识别结果为普通话。
[0090]
进一步地,基于所述第一词序文本中的词特征,对所述第一词序文本进行第二向量化处理,得到对应的第一向量特征矩阵,包括:
[0091]
对所述第一词序文本进行向量化编码,得到词序文本向量;
[0092]
利用所述词序文本向量和对应的预设特征加权参数,计算得到第一向量特征矩阵q,所述第一向量特征矩阵q的计算公式为:
[0093]
q={q
t
}
[0094]qt
=f(x
t
+k
t
)
[0095]
其中,q
t
为特征词向量,表示所述第一向量特征矩阵q的第t个的元素;x
t
表示所述词序文本向量中的第t个词向量;k
t
为所述第t个词向量对应的预设特征加权参数,所述预设特征加权参数包括词性特征参数、词根特征参数和词缀特征参数。
[0096]
进一步地,对所述第一向量特征矩阵进行意图实体识别,得到意图识别结果,根据所述意图识别结果,从所述第一词序文本中提取出意图实体,并利用所述意图实体,得到第二词序文本,包括:
[0097]
针对所述第一向量特征矩阵q中的各个所述特征词向量q
t
,计算得到对应的意图实体概率p,所述意图实体概率p的计算公式为:
[0098][0099]
其中,z和a分别表示预设词法权重参数和预设语法权重参数;q
t-1
表示所述第一向量特征矩阵q的第t-1个的元素;m由所述特征词向量q
t
对应的词序文本的字符长度决定;h表示词法语法识别参数;β为预设字符权重参数;bf表示意图实体比例参数;wf表示预设实体名词权重参数;
[0100]
判断所述意图实体概率p是否大于第一预设阈值;
[0101]
若所述意图实体概率p大于第一预设阈值,则将该所述意图实体概率p对应的所述
第一词序文本中的词汇作为意图实体;
[0102]
若所述意图实体概率p小于或等于第一预设阈值,则不将所述意图实体概率p对应的所述第一词序文本中的词汇作为所述意图实体;
[0103]
利用所述意图实体,得到所述第二词序文本。
[0104]
进一步地,利用所述第二词序文本,在语料库中进行语义相似度匹配,得到推荐话术,包括:
[0105]
对所述第二词序文本进行第二向量化处理,得到第二向量特征矩阵qk,其中,k为大于或等于零的正整数;
[0106]
对所述语料库中的话术对应的话术文本和所述话术文本对应的话术语音均进行第二向量化处理,分别得到第三向量特征矩阵q
k-1
和第四向量特征矩阵q
k+1
;
[0107]
利用所述第二向量特征矩阵qk、所述第三向量特征矩阵q
k-1
和所述第四向量特征矩阵q
k+1
,计算得到话术相似度sim,所述话术相似度sim的计算公式为:
[0108][0109]
判断所述话术相似度sim是否大于第二预设阈值;
[0110]
若所述话术相似度sim大于所述第二预设阈值,则将所述语料库中的话术作为所述推荐话术;
[0111]
若所述话术相似度sim小于或等于所述第二预设阈值,则不将所述语料库中的话术作为所述推荐话术。
[0112]
根据本发明实施例的第三方面,提供了一种智能话术推荐设备,所述设备包括:处理器和存储器;
[0113]
所述存储器用于存储一个或多个程序指令;
[0114]
所述处理器,用于运行一个或多个程序指令,用以执行如上任一项所述的一种智能话术推荐方法的步骤。
[0115]
根据本发明实施例的第四方面,提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如上任一项所述一种智能话术推荐方法的步骤。
[0116]
本发明实施例具有如下优点:
[0117]
本发明实施例公开了一种智能话术推荐方法、系统、设备及存储介质,首先采集客户服务电话中的对话语音并进行信号预处理,得到预处理后的对话语音文件;然后利用预处理后的对话语音文件进行语音韵律识别,根据韵律识别结果,映射得到第一词序文本;对第一词序文本进行第二向量化处理,得到对应的第一向量特征矩阵;对第一向量特征矩阵进行意图实体识别,得到意图识别结果,根据意图识别结果,从第一词序文本中提取出意图实体,并利用意图实体,得到第二词序文本;利用第二词序文本,在语料库中进行语义相似度匹配,得到推荐话术。本发明实施例实现了针对带有方言的语音的语音准确识别,有效提高了话术推荐的推荐准确率。
附图说明
[0118]
为了更清楚地说明本发明的实施方式或现有技术中的技术方案,下面将对实施方
式或现有技术描述中所需要使用的附图作简单地介绍。显而易见地,下面描述中的附图仅仅是示例性的,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图引伸获得其它的实施附图。
[0119]
本说明书所绘示的结构、比例、大小等,均仅用以配合说明书所揭示的内容,以供熟悉此技术的人士了解与阅读,并非用以限定本发明可实施的限定条件,故不具技术上的实质意义,任何结构的修饰、比例关系的改变或大小的调整,在不影响本发明所能产生的功效及所能达成的目的下,均应仍落在本发明所揭示的技术内容得能涵盖的范围内。
[0120]
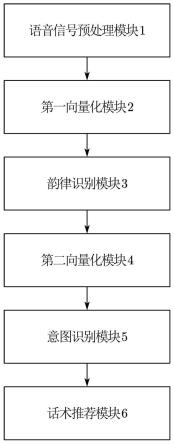
图1为本发明实施例提供的一种智能话术推荐系统的逻辑结构示意图;
[0121]
图2为本发明实施例提供的一种智能话术推荐方法的流程示意图;
[0122]
图3为本发明实施例提供的语音采集及信号预处理的流程示意图;
[0123]
图4为本发明实施例提供的频谱特征矩阵映射的流程示意图;
[0124]
图5为本发明实施例提供的韵律识别的流程示意图;
[0125]
图6为本发明实施例提供的意图识别的流程示意图;
[0126]
图7为本发明实施例提供的话术推荐的流程示意图。
具体实施方式
[0127]
以下由特定的具体实施例说明本发明的实施方式,熟悉此技术的人士可由本说明书所揭露的内容轻易地了解本发明的其他优点及功效,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0128]
参考图1,本发明实施例提供了一种智能话术推荐系统,其具体包括:语音信号预处理模块1、第一向量化模块2、韵律识别模块3、第二向量化模块4、意图识别模块5和话术推荐模块6。
[0129]
进一步地,语音信号预处理模块1用于对客户服务电话中的语音进行声音采集,得到对话语音信号,对对话语音信号进行信号预处理,得到预处理后的对话语音文件;第一向量化模块2用于利用预处理后的对话语音文件进行第一向量化处理,得到对应的频谱特征矩阵;韵律识别模块3用于将频谱特征矩阵输入至预先训练好的韵律模型,得到模型计算结果,利用模型计算结果,得到频谱特征矩阵的韵律识别结果,并根据韵律识别结果,对频谱特征矩阵进行文本映射处理,得到第一词序文本;第二向量化模块4用于基于第一词序文本中的词特征,对第一词序文本进行第二向量化处理,得到对应的第一向量特征矩阵;意图识别模块5用于对第一向量特征矩阵进行意图实体识别,得到意图识别结果,根据意图识别结果,从第一词序文本中提取出意图实体,并利用意图实体,得到第二词序文本;话术推荐模块6用于利用第二词序文本,在语料库中进行语义相似度匹配,得到推荐话术。
[0130]
本发明实施例公开了一种智能话术推荐系统,首先采集客户服务电话中的对话语音并进行信号预处理,得到预处理后的对话语音文件;然后利用预处理后的对话语音文件进行语音韵律识别,根据韵律识别结果,映射得到第一词序文本;对第一词序文本进行第二向量化处理,得到对应的第一向量特征矩阵;对第一向量特征矩阵进行意图实体识别,得到意图识别结果,根据意图识别结果,从第一词序文本中提取出意图实体,并利用意图实体,得到第二词序文本;利用第二词序文本,在语料库中进行语义相似度匹配,得到推荐话术。
本发明实施例实现了针对带有方言的语音的语音准确识别,有效提高了话术推荐的推荐准确率。
[0131]
与上述公开的一种智能话术推荐系统相对应,本发明实施例还公开了一种智能话术推荐方法。以下结合上述描述的一种智能话术推荐系统详细介绍本发明实施例中公开的一种智能话术推荐方法。
[0132]
参考图2,以下对本发明实施例提供的一种智能话术推荐方法的具体步骤进行描述。
[0133]
由语音信号预处理模块1对客户服务电话中的语音进行声音采集,得到对话语音信号,对对话语音信号进行信号预处理,得到预处理后的对话语音文件。
[0134]
参考图3,上述步骤具体包括:首先利用麦克风对客户服务电话中的对话语音进行采集,得到对话语音信号;然后通过麦克风信号放大器对对话语音信号进行麦克风阵列波束形成处理,得到第一预处理信号;再通过麦克风信号处理器对第一预处理信号分别进行固定波束形成处理和自适应波束形成处理,得到第二预处理信号;最后利用麦克风信号控制器对第二预处理信号进行频谱信号控制处理,得到对话语音文件。
[0135]
本发明实施例通过上述步骤对客户服务电话中的语音进行声音采集,并对采集到的对话语音信号进行信号预处理,实现了将声音信号转换为电波时序信号,再将电波时序信号转换为电磁波频率信号。
[0136]
由第一向量化模块2利用预处理后的对话语音文件进行第一向量化处理,得到对应的频谱特征矩阵。
[0137]
参考图4,上述步骤具体包括:首先基于上述对话语音文件的时序特征对其进行切分处理,将对话语音文本切位为若干段,得到切分后的对话语音文件;然后针对每段切分后的对话语音文件进行特征提取,得到切分后的对话语音文件对应的语音频谱特征,上述语音频谱特征包括频谱权重参数tn、信号延时参数yn和方言音强参数τn,其中,n为大于或等于0且小于切分总段数的正整数;利用频谱权重参数tn、信号延时参数yn和方言音强参数τn,计算得到频谱特征矩阵a,上述频谱特征矩阵a的计算公式为:
[0138]
a(n)=∑yn×
s(tn+τn)
[0139]
其中,a(n)表示频谱特征矩阵a中的第n个元素;s为多元非线性拟合参数。
[0140]
本发明实施例通过对预处理后的对话语音文件进行第一向量化处理,实现了根据对话语音文件的信号特征,将对话语音文件映射为频谱特征矩阵,以便于后续的计算。
[0141]
由韵律识别模块3将频谱特征矩阵输入至预先训练好的韵律模型,得到模型计算结果,利用模型计算结果,得到频谱特征矩阵的韵律识别结果,并根据韵律识别结果,对频谱特征矩阵进行文本映射处理,得到第一词序文本。
[0142]
参考图5,上述步骤具体包括:将频谱特征矩阵a输入至韵律识别模型,计算得到韵律模型计算结果x,上述韵律模型计算结果x的计算公式为:
[0143][0144]
其中,m表示连续说话的频谱特征矩阵时长权值,由频谱特征矩阵a的长度决定;j为预设的迪利克雷加权参数;x为预设参数;ω、θ和v分别为音高参数、音强参数和音长参
数,三者分别通过提取历史语音数据的音高、音强和音长并计算平均值得到。
[0145]
对预设的普通话模板语音文件进行切分,得到切分后的普通话模板语音文件;利用切分后的普通话模板语音文件,计算得到对应的普通话频谱特征矩阵b;利用普通话频谱特征矩阵b,计算得到普通话模板阈值x',普通话模板阈值x'的计算公式为:
[0146][0147]
其中,m'表示连续说话的普通话频谱特征矩阵时长权值,由普通话频谱特征矩阵b的长度决定,b(n')表示普通话频谱特征矩阵b中的第n'个元素;n'为大于或等于0且小于切分后的普通话模板语音文件的分段总数的正整数;
[0148]
对预设的方言话模板语音文件进行切分,得到切分后的方言话模板语音文件;利用切分后的方言话模板语音文件,计算得到对应的方言话频谱特征矩阵c;利用方言话频谱特征矩阵c,计算得到方言话模板阈值x”,方言话模板阈值x”的计算公式为:
[0149][0150]
其中,m”表示连续说话的方言话频谱特征矩阵时长权值,由方言话频谱特征矩阵c的长度决定;c(”)表示方言话频谱特征矩阵c中的第n”个元素;n”为大于或等于0且小于切分后的方言话模板语音文件的分段总数的正整数。
[0151]
利用韵律模型计算结果x和普通话模板阈值x',计算得到第一差值绝对值c1,第一差值绝对值c1的计算公式为:
[0152]
c1=||x|-|x
′
||
[0153]
利用韵律模型计算结果x和方言话模板阈值x”,计算得到第二差值绝对值c2,第二差值绝对值c2的计算公式为:
[0154]
c2=||x|-|x
″
||
[0155]
判断上述第一差值绝对值c1是否大于上述第二差值绝对值c2;若第一差值绝对值c1大于第二差值绝对值c2,则频谱特征矩阵a的韵律识别结果为方言话;若第一差值绝对值c1小于或等于第二差值绝对值c2,则频谱特征矩阵a的韵律识别结果为普通话;再判断频谱特征矩阵a的韵律识别结果;若频谱特征矩阵a的韵律识别结果为普通话,则对频谱特征矩阵a进行第一编码映射处理,得到第一映射文本d;若频谱特征矩阵a的韵律识别结果为方言话,则对频谱特征矩阵a进行第二编码映射处理,得到第二映射文本d',将上述第一映射文本d或第二映射文本d'作为第一词序文本。
[0156]
本发明实施例对上述频谱特征矩阵采用数列和函数转换的方法提取音高、音长、音强三个维度的特征参数,然后按照阈值比较分类识别出普通话和方言话,再采用两种不同的特征编码方式将频谱特征矩阵统一映射到词序文本上,实现了方言话和普通话的语音分类识别,并将普通话和方言多种多模态数据统一编解码映射输出为统一的词序文本。
[0157]
由第二向量化模块4基于第一词序文本中的词特征,对第一词序文本进行第二向量化处理,得到对应的第一向量特征矩阵。
[0158]
上述步骤具体包括:首先对第一词序文本进行向量化编码,将第一词序文本转码为词序文本向量;利用词序文本向量和对应的预设特征加权参数,计算得到第一向量特征矩阵q,第一向量特征矩阵q的计算公式为:
[0159]
q={q
t
}
[0160]qt
=f(x
t
+k
t
)
[0161]
其中,q
t
为特征词向量,表示第一向量特征矩阵q的第t个的元素;x
t
表示词序文本向量中的第t个词向量;k
t
为第t个词向量对应的预设特征加权参数,预设特征加权参数包括词性特征参数、词根特征参数和词缀特征参数。
[0162]
由意图识别模块5对第一向量特征矩阵进行意图实体识别,得到意图识别结果,根据意图识别结果,从第一词序文本中提取出意图实体,并利用意图实体,得到第二词序文本。
[0163]
参考图6,上述步骤具体包括:对于第一向量特征矩阵q中的每个特征词向量q
t
,均计算对应的意图实体概率p,意图实体概率p的计算公式为:
[0164][0165]
其中,z和a分别表示预设词法权重参数和预设语法权重参数;q
t-1
表示第一向量特征矩阵q的第t-1个的元素;m由特征词向量q
t
对应的词序文本的字符长度决定;h表示词法语法识别参数;β为预设字符权重参数,表示输入实体中含有名词性实体的字符的权重参数;bf为意图实体比例参数,表示当前词序文本中包含实体个数的比例参数;wf为预设实体名词权重参数,表示输入内容中包含实体名词的权重参数;e为自然常数。
[0166]
然后判断意图实体概率p是否大于第一预设阈值;若意图实体概率p大于第一预设阈值,则将该意图实体概率p对应的第一词序文本中的词汇作为意图实体;若意图实体概率p小于或等于第一预设阈值,则不将意图实体概率p对应的第一词序文本中的词汇作为意图实体;利用所有意图实体,组合得到第二词序文本。
[0167]
本发明实施例利用基于上下文的注意力机制,对上述第一向量特征矩阵q进行意图类型分类识别,从而实现意图实体的识别、语义信息歧义消除和缺失语义信息补全,同时根据条件概率计算方式实现上下文实体注意力内容感知为后续的话术推荐提供更高质量的词序文本内容。
[0168]
由话术推荐模块6利用第二词序文本,在语料库中进行语义相似度匹配,得到推荐话术。
[0169]
参考图7,上述步骤具体包括:对第二词序文本进行上述的第二向量化处理,得到第二向量特征矩阵qk,其中,k为大于或等于零的正整数;对语料库中的话术对应的话术文本和话术文本对应的话术语音均进行过程相同的第二向量化处理,分别得到第三向量特征矩阵q
k-1
和第四向量特征矩阵q
k+1
;利用第二向量特征矩阵qk、第三向量特征矩阵q
k-1
和第四向量特征矩阵q
k+1
,计算得到上述第二词序文本与该话术文本的话术相似度sim,话术相似度sim的计算公式为:
[0170]
[0171]
判断该话术相似度sim是否大于第二预设阈值;若话术相似度sim大于第二预设阈值,则将语料库中的话术作为推荐话术;若话术相似度sim小于或等于第二预设阈值,则不将语料库中的话术作为推荐话术。
[0172]
本发明实施例通过上述步骤实现了将客服对话中咨询人的对话语音对应的带有意图实体的第二词序文本与语料库中的推荐话术进行相似度计算,输出最佳推荐话术。
[0173]
本发明实施例公开了一种智能话术推荐方法,首先采集客户服务电话中的对话语音并进行信号预处理,得到预处理后的对话语音文件;然后利用预处理后的对话语音文件进行语音韵律识别,根据韵律识别结果,映射得到第一词序文本;对第一词序文本进行第二向量化处理,得到对应的第一向量特征矩阵;对第一向量特征矩阵进行意图实体识别,得到意图识别结果,根据意图识别结果,从第一词序文本中提取出意图实体,并利用意图实体,得到第二词序文本;利用第二词序文本,在语料库中进行语义相似度匹配,得到推荐话术。本发明实施例实现了针对带有方言的语音的语音准确识别,有效提高了话术推荐的推荐准确率。
[0174]
另外,本发明实施例还提供了一种智能话术推荐设备,所述设备包括:处理器和存储器;所述存储器用于存储一个或多个程序指令;所述处理器,用于运行一个或多个程序指令,用以执行如上任一项所述的一种智能话术推荐方法的步骤。
[0175]
另外,本发明实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如上任一项所述一种智能话术推荐方法的步骤。
[0176]
在本发明实施例中,处理器可以是一种集成电路芯片,具有信号的处理能力。处理器可以是通用处理器、数字信号处理器(digital signal processor,简称dsp)、专用集成电路(application specific integrated circuit,简称asic)、现场可编程门阵列(field programmable gatearray,简称fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。
[0177]
可以实现或者执行本发明实施例中的公开的各方法、步骤及逻辑框图。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。结合本发明实施例所公开的方法的步骤可以直接体现为硬件译码处理器执行完成,或者用译码处理器中的硬件及软件模块组合执行完成。软件模块可以位于随机存储器,闪存、只读存储器,可编程只读存储器或者电可擦写可编程存储器、寄存器等本领域成熟的存储介质中。处理器读取存储介质中的信息,结合其硬件完成上述方法的步骤。
[0178]
存储介质可以是存储器,例如可以是易失性存储器或非易失性存储器,或可包括易失性和非易失性存储器两者。
[0179]
其中,非易失性存储器可以是只读存储器(read-only memory,简称rom)、可编程只读存储器(programmable rom,简称prom)、可擦除可编程只读存储器(erasable prom,简称eprom)、电可擦除可编程只读存储器(electrically eprom,简称eeprom)或闪存。
[0180]
易失性存储器可以是随机存取存储器(random access memory,简称ram),其用作外部高速缓存。通过示例性但不是限制性说明,许多形式的ram可用,例如静态随机存取存储器(static ram,简称sram)、动态随机存取存储器(dynamic ram,简称dram)、同步动态随机存取存储器(synchronous dram,简称sdram)、双倍数据速率同步动态随机存取存储器
(double data rate sdram,简称ddrsdram)、增强型同步动态随机存取存储器(enhanced sdram,简称esdram)、同步连接动态随机存取存储器(synchlink dram,简称sldram)和直接内存总线随机存取存储器(direct rambus ram,简称drram)。
[0181]
本发明实施例描述的存储介质旨在包括但不限于这些和任意其它适合类型的存储器。
[0182]
本领域技术人员应该可以意识到,在上述一个或多个示例中,本发明所描述的功能可以用硬件与软件组合来实现。当应用软件时,可以将相应功能存储在计算机可读介质中或者作为计算机可读介质上的一个或多个指令或代码进行传输。计算机可读介质包括计算机存储介质和通信介质,其中通信介质包括便于从一个地方向另一个地方传送计算机程序的任何介质。存储介质可以是通用或专用计算机能够存取的任何可用介质。
[0183]
虽然,上文中已经用一般性说明及具体实施例对本发明作了详尽的描述,但在本发明基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1