一种校园语音识别的方法、装置及存储介质与流程
本发明涉及语音识别,尤其涉及一种校园语音识别的方法、装置及存储介质。
背景技术:
1、语音识别是把输入语音中的词汇内容转换成对应的文本信息。现有的语音识别模型首先对语音进行处理之后,使用声学模型进行解码,之后将音节与词表进行匹配得到词序列,最后再使用语言模型得到语句。
2、人们在进行自然口语对话时,不仅传递声音,更重要的是传递说话人的情感状态、态度、意图等。目前智慧校园设备的语音识别功能中,缺乏专门针对暴力词汇的语音识别的关键词检索以及情感语音识别,而且不能够对获取的语音进行声源定位,语音识别性能差,不能通过对学生的语音识别全面保护校园学生的安全。
技术实现思路
1、本发明提供了一种校园语音识别的方法、装置及存储介质,以实现校园中的暴力语音的识别和定位。
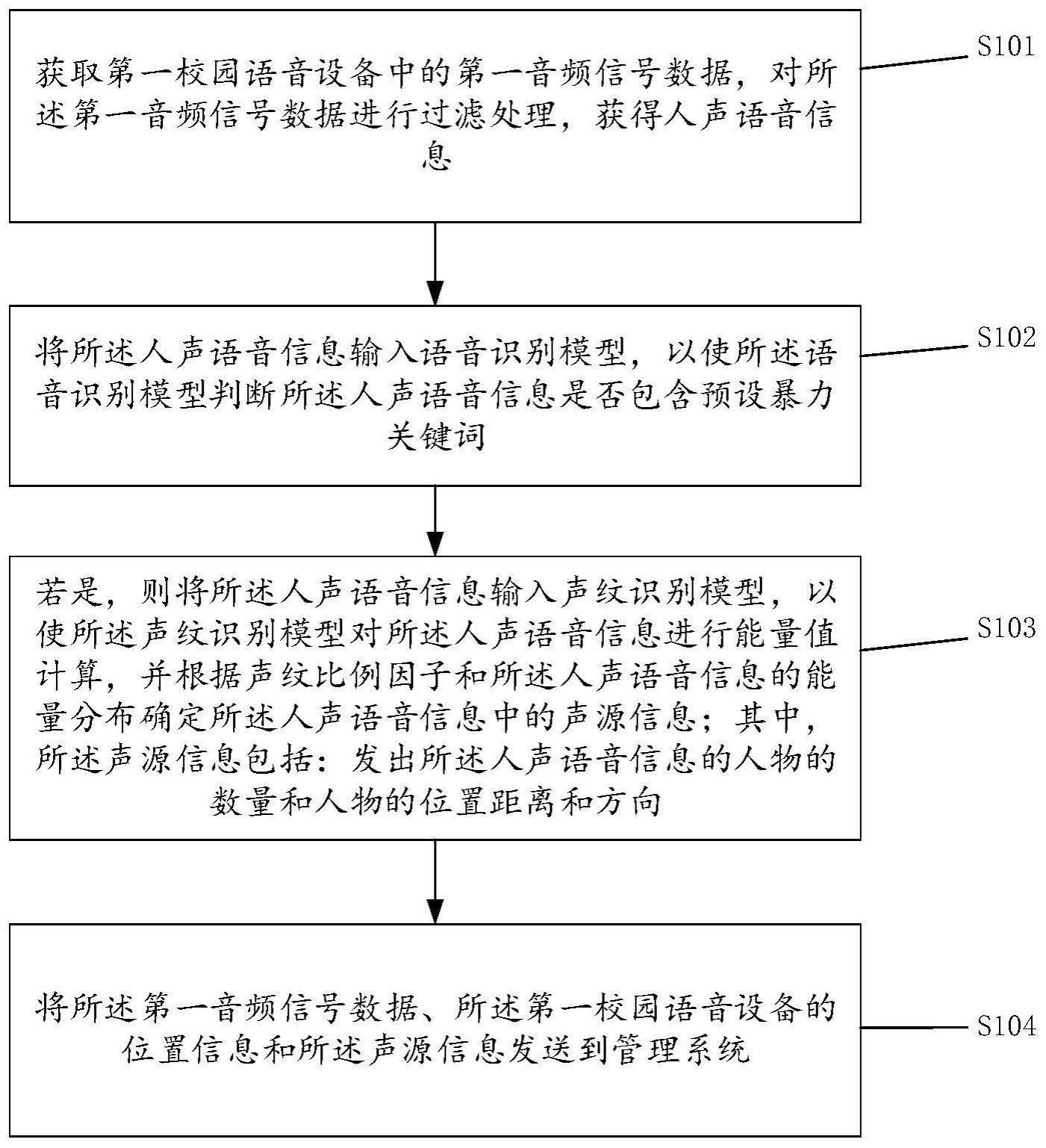
2、为了校园中的暴力语音的识别和定位,本发明实施例提供了一种校园语音识别的方法、装置及存储介质,包括:获取第一校园语音设备中的第一音频信号数据,对所述第一音频信号数据进行过滤处理,获得人声语音信息;
3、将所述人声语音信息输入语音识别模型,以使所述语音识别模型判断所述人声语音信息是否包含预设暴力关键词;
4、若是,则将所述人声语音信息输入声纹识别模型,以使所述声纹识别模型对所述人声语音信息进行能量值计算,并根据声纹比例因子和所述人声语音信息的能量分布确定所述人声语音信息中的声源信息;其中,所述声源信息包括:发出所述人声语音信息的人物的数量和人物的位置距离和方向;
5、将所述第一音频信号数据、所述第一校园语音设备的位置信息和所述声源信息发送到管理系统。
6、作为优选方案,本发明对校园的任意一个语音设备的第一音频信号数据,并对第一音频信号数据进行特征提取,输入语音识别模型中进行语音分析,判断该第一音频信号数据中是否存在暴力语音;若判断获取到第一音频信号数据是暴力语音后,再获取到的暴力语音进行声纹分析,获取该段暴力语音的声源信息,发出所述人声语音信息的人物的数量和人物的位置距离和方向,实现在校园内实时收录学生的语音信息并检测语音信息是否为暴力语音,并判断发出暴力语音的人物数量和位置距离和方向,从而进行声源定位。
7、作为优选方案,获取第一语音设备中的第一音频信号数据,对所述第一音频信号数据进行过滤处理,获得人声语音信息,具体为:
8、将第一音频信号数据分割成语音区和静音区,去除所述语音区的噪声,将去除噪声后的语音区作为所述人声语音信息。
9、作为优选方案,本发明在检测语音之前先对语音信息进行人声语音区的分割提取,并提取人声语音区的特征信息,减少了对环境语音的计算,提升对人声语音分析的精度,提取出人声语音的关键词和声纹,以实现在校园内实时收录学生的语音信息并检测语音信息是否为暴力语音,根据声纹特征判断发出暴力语音的人物数量和位置距离和方向,从而进行声源定位。
10、作为优选方案,检测所述判断所述人声语音信息是否包含预设暴力关键词,具体为:
11、调用统一的api接口获取人声语音信息的第一关键词的信道信息;
12、将所述第一关键词的信道信息与训练语音信息中的第二关键词的信道信息进行匹配计算;其中,所述第二关键词为预设暴力关键词;
13、若所述第一关键词的信道信息与第二关键词的信道信息匹配相同,则语音识别模型判断所述人声语音信息包含预设暴力关键词。
14、作为优选方案,本发明通过对人声语音信息的关键词特征信息与训练语音信息的关键词特征信息进行匹配,判断该人声语音信息的关键词是否为暴力词汇或者负面情绪的词汇,实现在校园内实时收录学生的语音信息并检测语音信息是否为暴力语音。
15、作为优选方案,对所述人声语音信息进行能量值计算,并根据声纹比例因子和所述人声语音信息的能量分布确定所述人声语音信息中的声源信息,具体为:
16、将若干个人声语音信息分别输入若干个对应的矩阵单元中,分别计算出每个音频采集终端采集到的人声语音信息的能量值和频域能量分布;其中,第一校园语音设备配有若干个所述音频采集终端;若干个所述人声语音信息分别由不同的音频采集终端采集到的第一音频信号数据过滤处理而来;
17、根据每个矩阵单元的能量值和频域能量分布,提取声纹比例因子,对所述人声语音信息做均衡处理,输出矩阵能量分布;
18、根据矩阵能量分布和若干个音频采集终端的位置确定人物的数量和声音的方向。
19、作为优选方案,第一校园语音设备配有若干个所述音频采集终端,根据若干个音频采集终端采集到的第一音频信号数据过滤处理后的人声语音信息,分别计算出每个人声语音信息的能量值和频域能量分布,提取声纹比例因子,对所述人声语音信息做均衡处理,输出矩阵能量分布;根据矩阵能量分布和若干个音频采集终端的位置确定人物的数量和声音的方向,从而进行声源定位。
20、作为优选方案,将所述人声语音信息输入语音识别模型之前,还包括:
21、获取若干训练音频数据,提取所述训练音频数据的特征信息;其中,所述训练音频数据包括含有暴力词汇或情感关键词的人声语音和不含有暴力词汇或情感关键词的人声语音;
22、根据所述特征信息将所述训练音频数据分割成语音区和静音区;根据所述语音区和所述静音区的特征类型,对所述特征信息进行融合计算,获得所述训练音频数据的特征参数;
23、根据所述特征参数,分别对所述训练音频数据的语音区和静音区的信道进行建模,获得语音识别模型。
24、作为优选方案,本发明在将人声语音信息输入语音识别模型之前,先对语音识别模型进行训练,将含有暴力词汇或情感关键词的人声语音和不含有暴力词汇或情感关键词的人声语音作为训练音频数据,以便模型能训练区分含有暴力词汇或情感关键词和不含有暴力词汇或情感关键词的多种特征值,并根据各自特点加以融合,根据融合后的特征参数建立的模型能够检测语音信息是否为暴力语音以及该语音信息所表达的情绪值。
25、作为优选方案,将所述声纹参数输入声纹识别模型之前,还包括:
26、获取若干训练音频数据,提取所述训练音频数据的第一能量特征信息;对所述第一能量特征信息进行融合计算,获得所述训练音频数据的声纹特征参数;根据所述声纹特征参数,对所述训练音频数据进行建模,获得声纹识别模型。
27、作为优选方案,本发明在将声纹参数输入声纹识别模型之前,对声纹识别模型进行训练,提取所述训练音频数据的第一能量特征信息,获取该段训练音频数据的声纹特征参数,根据所述声纹特征参数,对声纹识别模型进行训练,以使声纹识别模型实现判断发出暴力语音的人物数量和位置距离和方向,从而进行声源定位。
28、作为优选方案,将所述第一音频信号数据、所述第一校园语音设备的位置信息和所述声源信息发送到管理系统之前,还包括:
29、通过播音设备播放警报信息;若播放警报信息后的预设时间内,再次检测到暴力语音,则将第一音频信号数据、所述第一校园语音设备的位置信息和所述声源信息发送到管理系统。
30、作为优选方案,本发明在预设时间内二次检测到暴力语音时,将所述人声语音信息、获取所述人声语音信息的语音设备的位置和所述人声语音信息的人物信息发送到管理系统以通知管理员暴力语音内容,人数和人物位置,实现在校园内实时收录学生的语音信息并检测语音信息是否为暴力语音,进行暴力语音的声源定位,及时通知管理员并发送相关内容,全面保护校园的学生安全。
31、相应地,本发明还提供一种校园语音识别的装置,包括:获取模块、暴力检测模块、声纹定位模块和信息发送模块;
32、其中,所述获取模块用于获取校园语音设备中的音频信号数据,对所述音频信号数据进行特征提取,获得人声语音信息;
33、所述暴力检测模块用于将所述人声语音信息输入语音识别模型,以使所述语音识别模型判断所述人声语音信息是否包含预设暴力关键词;
34、所述声纹定位模块用于若所述人声语音信息包含预设暴力关键词,则将所述人声语音信息输入声纹识别模型,以使所述声纹识别模型对所述人声语音信息进行能量值计算,并根据声纹比例因子和所述人声语音信息的能量分布确定所述人声语音信息中的声源信息;其中,所述声源信息包括:发出所述人声语音信息的人物的数量和人物的位置距离和方向;
35、所述信息发送模块用于将所述第一音频信号数据、所述第一校园语音设备的位置信息和所述声源信息发送到管理系统。
36、作为优选方案,本发明校园语音识别的装置的获取模块获取校园的任意一个语音设备的第一音频信号数据,并对第一音频信号数据进行特征提取获得人声语音信息,暴力检测模块将人声语音信息输入语音识别模型中进行语音分析,判断该第一音频信号数据中是否存在暴力语音;若判断获取到第一音频信号数据是暴力语音后,声纹定位模块将获取到的暴力语音进行声纹分析,获取该段暴力语音的声源信息,发出所述人声语音信息的人物的数量和人物的位置距离和方向,实现在校园内实时收录学生的语音信息并检测语音信息是否为暴力语音,并判断发出暴力语音的人物数量和位置距离和方向,从而进行声源定位。信息发送模块及时将暴力语言的声源信息反馈给管理人员。
37、作为优选方案,获取模块包括分割单元和特征提取单元;
38、所述分割单元用于将第一音频信号数据分割成语音区和静音区,获取所述语音区;
39、所述特征提取单元用于提取所述语音区的人声语音信息;其中,所述人声语音信息包括关键词特征信息和声纹特征信息。
40、作为优选方案,本发明分割单元在检测语音之前先对语音信息进行人声语音区的分割提取,特征提取单元提取人声语音区的特征信息,减少了对环境语音的计算,提升对人声语音分析的精度,提取出人声语音的关键词和声纹,以实现在校园内实时收录学生的语音信息并检测语音信息是否为暴力语音,根据声纹特征判断发出暴力语音的人物数量和位置距离和方向,从而进行声源定位。
41、作为优选方案,暴力检测模块包括训练单元和检测单元;
42、所述训练单元用于获取若干训练音频数据,提取所述训练音频数据的特征信息;其中,所述训练音频数据包括含有暴力词汇或情感关键词的人声语音和不含有暴力词汇或情感关键词的人声语音;
43、根据所述特征信息将所述训练音频数据分割成语音区和静音区;根据所述语音区和所述静音区的特征类型,对所述特征信息进行融合计算,获得所述训练音频数据的特征参数;
44、根据所述特征参数,分别对所述训练音频数据的语音区和静音区的信道进行建模,获得语音识别模型;
45、所述检测单元用于提取人声语音信息的第一关键词的特征信息;调用统一的api接口获取所述第一关键词的特征信息;将所述第一关键词的特征信息与训练语音信息中的第二关键词的特征信息进行匹配计算,判断所述第一关键词是否为暴力词汇;若所述第二关键词为暴力词汇且所述第一关键词的特征信息与第二关键词的特征信息匹配相同,则判断所述第一关键词为暴力词汇。
46、作为优选方案,本发明在将人声语音信息输入语音识别模型之前,训练单元先对语音识别模型进行训练,将含有暴力词汇或情感关键词的人声语音和不含有暴力词汇或情感关键词的人声语音作为训练音频数据,以便模型能训练区分含有暴力词汇或情感关键词和不含有暴力词汇或情感关键词的多种特征值,并根据各自特点加以融合,根据融合后的特征参数建立的模型能够检测语音信息是否为暴力语音以及该语音信息所表达的情绪值;检测单元通过对人声语音信息的关键词特征信息与训练语音信息的关键词特征信息进行匹配,判断该人声语音信息的关键词是否为暴力词汇或者负面情绪的词汇,实现在校园内实时收录学生的语音信息并检测语音信息是否为暴力语音。
47、相应地,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质包括存储的计算机程序;其中,所述计算机程序在运行时控制所述计算机可读存储介质所在的设备执行如本
技术实现要素:
所述的一种校园语音识别的方法。
- 还没有人留言评论。精彩留言会获得点赞!