语音识别纠错方法和装置与流程
本发明涉及人工智能,尤其涉及一种语音识别纠错方法和装置。
背景技术:
1、语音识别是人机对话中的关键技术,广泛应用于生活中的常见服务,如手机端的语音转文字、视频网站的字幕自动生成等。然而,目前的语音识别模型并不完美,总是会出现一些识别错误,因此,需要使用纠错模型来纠正语音识别文本中的错误。目前,大部分纠错模型通过比对语音识别文本和人工标注的正确文本来学习纠错信息。然而,许多识别错误单从文本层面并不能确定正确的识别结果,这导致现有纠错模型的纠错准确率不高。
技术实现思路
1、有鉴于此,本发明实施例提供一种语音识别纠错方法和装置,通过在纠错模型中引入融合语音和文本的双模态特征来提高纠错准确率。
2、为实现上述目的,根据本发明的一个方面,提供了一种语音识别纠错方法。
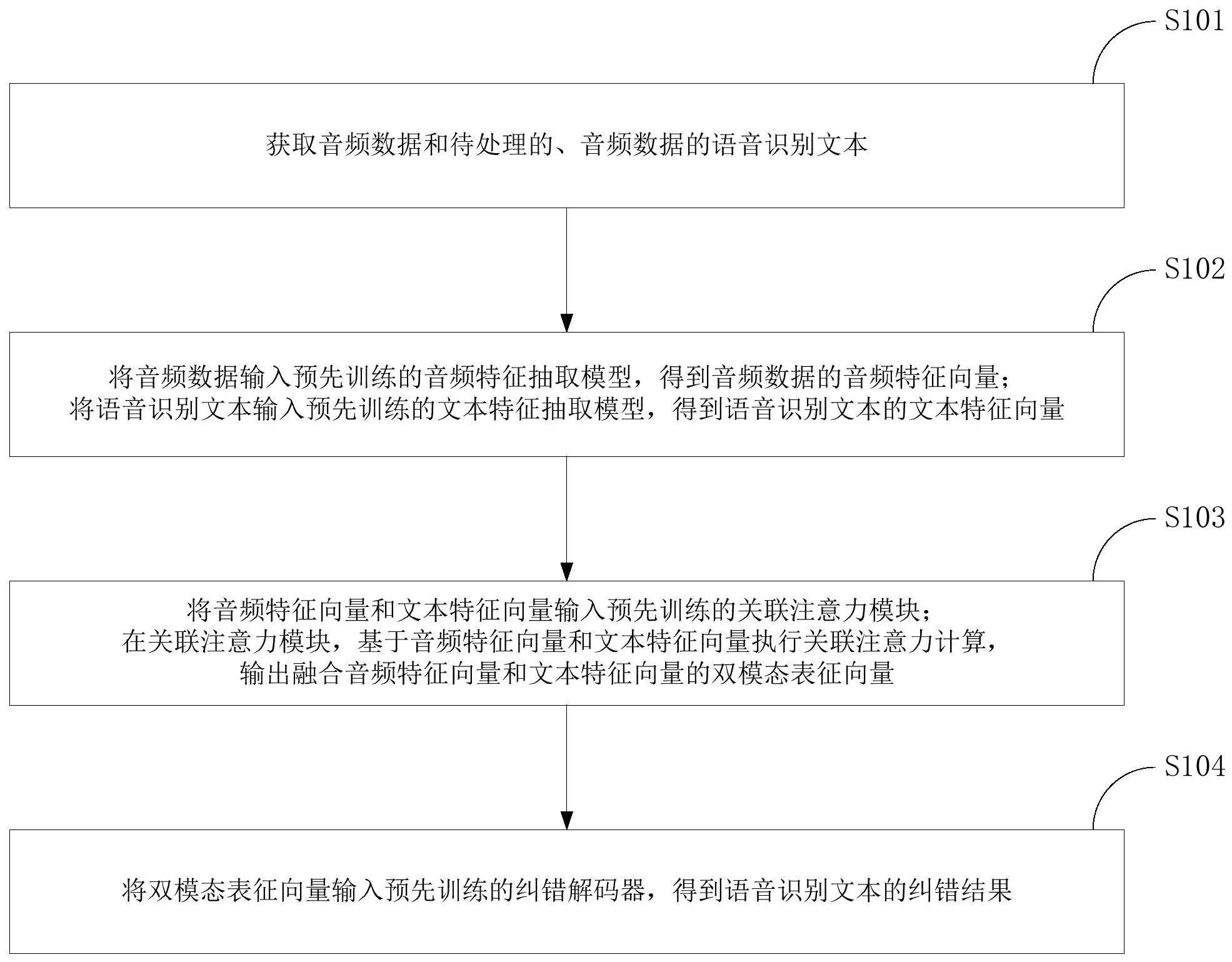
3、本发明实施例的语音识别纠错方法包括:获取音频数据和待处理的、所述音频数据的语音识别文本;将所述音频数据输入预先训练的音频特征抽取模型,得到所述音频数据的音频特征向量;将所述语音识别文本输入预先训练的文本特征抽取模型,得到所述语音识别文本的文本特征向量;将所述音频特征向量和所述文本特征向量输入预先训练的关联注意力模块;在所述关联注意力模块,基于所述音频特征向量和所述文本特征向量执行关联注意力计算,输出融合所述音频特征向量和所述文本特征向量的双模态表征向量;将所述双模态表征向量输入预先训练的纠错解码器,得到所述语音识别文本的纠错结果。
4、可选地,所述基于所述音频特征向量和所述文本特征向量执行关联注意力计算,输出融合所述音频特征向量和所述文本特征向量的双模态表征向量,包括:基于所述文本特征向量形成多个注意力头的查询向量,基于所述音频特征向量形成所述多个注意力头的键向量和值向量;根据所述查询向量、键向量和值向量计算每一注意力头的单头注意力输出向量,将每一注意力头的单头注意力输出向量拼接后形成多头注意力输出向量;将所述多头注意力输出向量与所述文本特征向量拼接为所述双模态表征向量。
5、可选地,所述纠错解码器包括依次连接并且结构相同的多个解码层,每一解码层包括依次连接的自注意力子层、关联注意力子层和前馈网络子层;以及,所述将所述双模态表征向量输入预先训练的纠错解码器,包括:将所述双模态表征向量输入每一解码层的关联注意力子层。
6、可选地,所述方法进一步包括:在所述纠错解码器的任一解码层,基于该解码层的自注意力子层计算该解码层的输入向量的自注意力向量,将所述自注意力向量执行归一化之后与所述输入向量结合,获得第一中间向量向该解码层的关联注意力子层传递;在该关联注意力子层,基于第一中间向量形成多个注意力头的查询向量,基于所述双模态表征向量形成该多个注意力头的键向量和值向量,根据该查询向量、键向量和值向量计算融合第一中间向量和所述双模态表征向量的多头注意力向量;将所述多头注意力向量执行归一化之后与第一中间向量结合,获得第二中间向量后向该解码层的前馈网络子层传递;基于该前馈网络子层计算第二中间向量的映射向量,将所述映射向量执行归一化之后与第二中间向量结合,获得该解码层的输出向量。
7、可选地,所述纠错解码器进一步包括连接在最后端解码层的线性层、归一化层和输出层;以及,所述纠错解码器的最前端解码层在任一时间步的输入向量是当前已生成语素的嵌入向量,所述输出层在任一时间步的输出结果是当前已生成语素的下一语素,所述输出层在各时间步的输出结果组成所述纠错结果。
8、可选地,所述关联注意力模块和所述纠错解码器通过以下步骤进行联合训练:获取包括训练音频数据以及相应的训练语音识别文本和作为标签的训练纠错文本;将所述训练音频数据输入所述音频特征抽取模型,得到所述训练音频数据的训练音频特征向量;将所述训练语音识别文本输入所述文本特征抽取模型,得到所述训练语音识别文本的训练文本特征向量;将所述训练音频特征向量和所述训练文本特征向量输入所述关联注意力模块;在所述关联注意力模块,基于所述训练音频特征向量和所述训练文本特征向量执行关联注意力计算,输出融合所述训练音频特征向量和所述训练文本特征向量的训练表征向量;将所述训练表征向量输入所述纠错解码器中各解码层的关联注意力子层,将当前时间步的已生成语素的嵌入向量输入所述纠错解码器的最前端解码层,获得所述纠错解码器的训练输出结果;比对所述训练输出结果与所述训练纠错文本形成用于训练所述关联注意力模块和所述纠错解码器的损失函数。
9、为实现上述目的,根据本发明的另一方面,提供了一种语音识别纠错装置。
10、本发明实施例的语音识别纠错装置可以包括:数据准备单元,用于获取音频数据和待处理的、所述音频数据的语音识别文本;特征提取单元,用于将所述音频数据输入预先训练的音频特征抽取模型,得到所述音频数据的音频特征向量;将所述语音识别文本输入预先训练的文本特征抽取模型,得到所述语音识别文本的文本特征向量;特征融合单元,用于将所述音频特征向量和所述文本特征向量输入预先训练的关联注意力模块;在所述关联注意力模块,基于所述音频特征向量和所述文本特征向量执行关联注意力计算,输出融合所述音频特征向量和所述文本特征向量的双模态表征向量;解码单元,用于将所述双模态表征向量输入预先训练的纠错解码器,得到所述语音识别文本的纠错结果。
11、可选地,所述特征融合单元可进一步用于:基于所述文本特征向量形成多个注意力头的查询向量,基于所述音频特征向量形成所述多个注意力头的键向量和值向量;根据所述查询向量、键向量和值向量计算每一注意力头的单头注意力输出向量,将每一注意力头的单头注意力输出向量拼接后形成多头注意力输出向量;将所述多头注意力输出向量与所述文本特征向量拼接为所述双模态表征向量。
12、为实现上述目的,根据本发明的又一方面,提供了一种电子设备。
13、本发明的一种电子设备包括:一个或多个处理器;存储装置,用于存储一个或多个程序,当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现本发明所提供的语音识别纠错方法。
14、为实现上述目的,根据本发明的再一方面,提供了一种计算机可读存储介质。
15、本发明的一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现本发明所提供的语音识别纠错方法。
16、根据本发明的技术方案,上述发明中的实施例具有如下优点或有益效果:
17、在对某音频数据的语音识别文本纠错时,首先利用预训练的特征抽取模型分别对该音频数据及其语音识别文本进行特征抽取,之后利用关联注意力机制将抽取出的音频特征向量和文本特征向量融合为指示音频模态和文本模态的双模态表征向量,最后将双模态表征向量输入纠错解码器从而得到语音识别文本的纠错结果。如此,通过在编码过程中使用多头注意力机制融合音频和文本的双模态特征(即双模态表征向量)、以及在解码过程中使用多头注意力机制对双模态特征和解码器输入特征进行联合计算,实现了纠错准确率的提高。
18、上述的非惯用的可选方式所具有的进一步效果将在下文中结合具体实施方式加以说明。
- 还没有人留言评论。精彩留言会获得点赞!