语音信息的识别方法、装置、电子设备及存储介质与流程
本申请涉及语音交互,尤其涉及一种语音信息的识别方法、装置、电子设备及存储介质。
背景技术:
1、智能座舱语音交互主要分为唤醒、聆听、理解、播报四个部分。在唤醒车载语音助手之时,同时也需要对声源进行定位。目前市面上的音区识别技术主要是通过安装在每个座位旁的独立的拾音麦克风,通过每个拾音麦克风接收到的声音的声强大小进行比较,从而确定发声对象的位置。但是这种通过声音的大小判断发声对象位置的方式在一些场景下是无法适用的。例如,当后排左位置上的乘客转向右方发出唤醒词唤醒语音助手时,车机可能会判断为后排右乘客对语音助手进行唤醒,从而选择不接受后排左乘客下达的后续指令,导致后排音区识别错误。此外,当车内外环境的噪音较大时,同时乘客之间的讨论和回声会影响语音交互的拾音质量,影响后排音区识别的准确性。
2、因此,现有技术中存在音区识别不准确导致语音交互不顺畅的问题。
技术实现思路
1、有鉴于此,本申请实施例提供了一种语音信息的识别方法、装置、电子设备及存储介质,以解决现有技术中存在的音区识别不准确导致语音交互不顺畅的问题。
2、本申请实施例的第一方面,提供了一种语音信息的识别方法,包括:
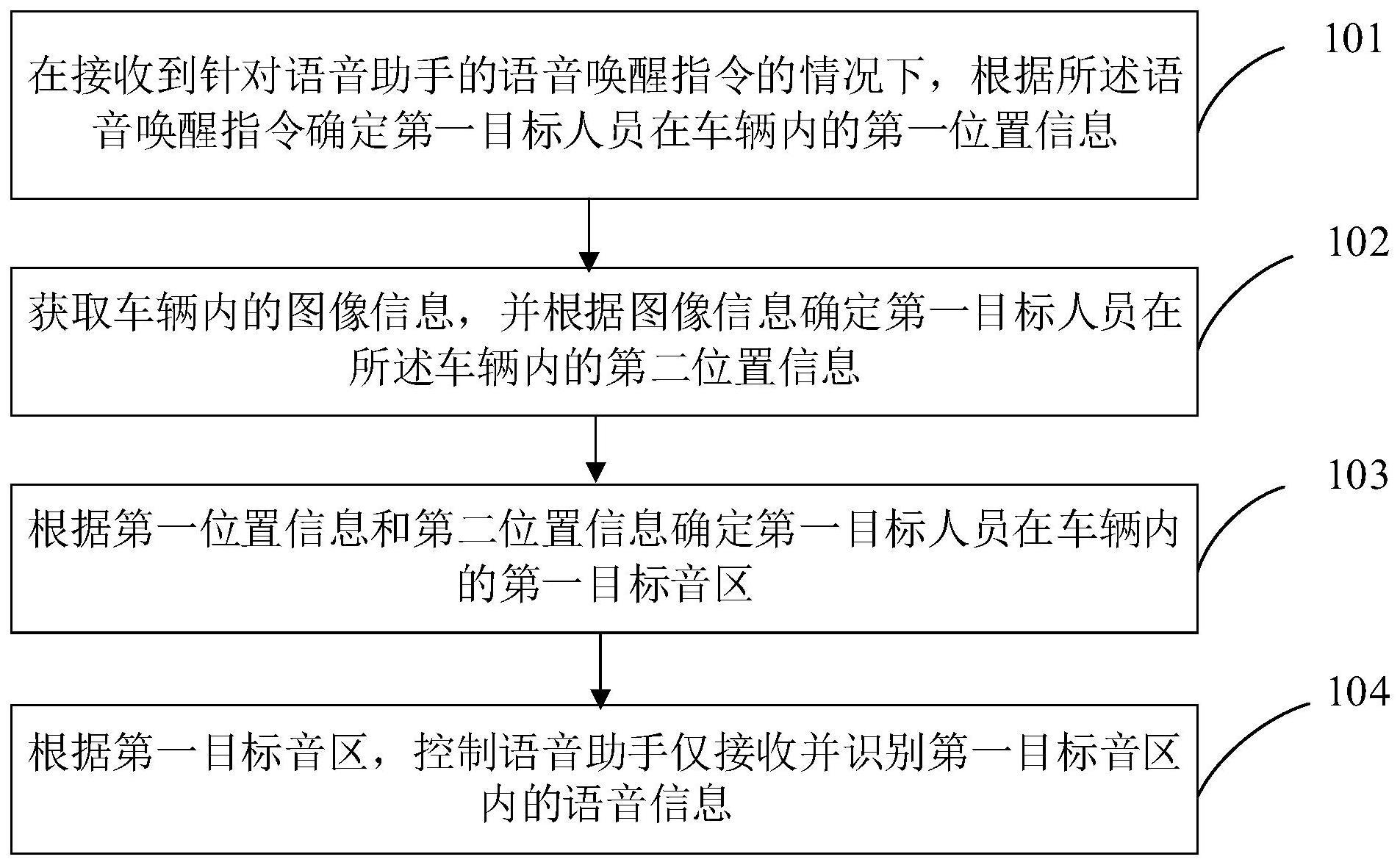
3、在接收到针对语音助手的语音唤醒指令的情况下,根据所述语音唤醒指令确定第一目标人员在车辆内的第一位置信息,所述第一目标人员为发出所述语音唤醒指令的人员;
4、获取所述车辆内的图像信息,并根据所述图像信息确定所述第一目标人员在所述车辆内的第二位置信息;
5、根据所述第一位置信息和所述第二位置信息确定所述第一目标人员在所述车辆内的第一目标音区;
6、根据所述第一目标音区,控制所述语音助手仅接收并识别所述第一目标音区内的语音信息。
7、本申请实施例的第二方面,提供了一种语音信息的识别装置,包括:
8、第一确定模块,用于在接收到针对语音助手的语音唤醒指令的情况下,根据所述语音唤醒指令确定第一目标人员在车辆内的第一位置信息,所述第一目标人员为发出所述语音唤醒指令的人员;
9、第二确定模块,用于获取所述车辆内的图像信息,并根据所述图像信息确定所述第一目标人员在所述车辆内的第二位置信息;
10、第三确定模块,用于根据所述第一位置信息和所述第二位置信息确定所述第一目标人员在所述车辆内的第一目标音区;
11、语音识别模块,用于根据所述第一目标音区,控制所述语音助手仅接收并识别所述第一目标音区内的语音信息。
12、本申请实施例的第三方面,提供了一种电子设备,包括存储器、处理器以及存储在存储器中并且可在处理器上运行的计算机程序,该处理器执行计算机程序时实现上述方法的步骤。
13、本申请实施例的第四方面,提供了一种可读存储介质,该可读存储介质存储有计算机程序,该计算机程序被处理器执行时实现上述方法的步骤。
14、本申请实施例与现有技术相比存在的有益效果是:
15、本实施例在接收到针对语音助手的语音唤醒指令的情况下,根据语音唤醒指令确定发出语音唤醒指令的第一目标人员在车辆内的第一位置信息,并根据图像信息确定第一目标人员在车辆内的第二位置信息,根据第一位置信息和第二位置信息确定第一目标人员在车辆内的第一目标音区,然后控制语音助手仅接收并识别第一目标音区内的语音信息;实现了结合声音维度和视觉维度共同确定第一目标人员在车辆内的第一目标音区,提高了所确定的第一目标音区的准确性,减少了目标音区识别错误情景的出现,此外控制语音助手仅接收并识别第一目标音区内的语音信息,避免了其他音区出现的声音对第一目标音区内语音识别的干扰,保证了发出语音唤醒指令的第一目标人员后续发出的一系列指令能够被语音助手准确接收识别,提高了车辆内人员进行语音交互时的顺畅性,解决了现有技术中存在的音区识别不准确导致语音交互不顺畅的问题。
技术特征:
1.一种语音信息的识别方法,其特征在于,包括:
2.根据权利要求1所述的语音信息的识别方法,其特征在于,所述图像信息包括所述车辆内各人员的人脸图像和所述各人员的乘坐座位信息;
3.根据权利要求2所述的语音信息的识别方法,其特征在于,所述根据所述各人员的面部特征和预先存储的人员在输出所述语音唤醒指令时的预设面部特征,确定所述第一目标人员,包括:
4.根据权利要求1所述的语音信息的识别方法,其特征在于,所述根据所述第一位置信息和所述第二位置信息确定所述第一目标人员在所述车辆内的第一目标音区,包括:
5.根据权利要求1所述的语音信息的识别方法,其特征在于,所述根据所述第一目标音区,控制所述语音助手仅接收并识别所述第一目标音区内的语音信息之后,还包括:
6.根据权利要求1所述的语音信息的识别方法,其特征在于,所述根据所述第一目标音区,控制所述语音助手仅接收并识别所述第一目标音区内的语音信息之后,还包括:
7.根据权利要求1所述的语音信息的识别方法,其特征在于,所述根据所述第一目标音区,控制所述语音助手仅接收并识别所述第一目标音区内的语音信息之后,还包括:
8.一种语音信息的识别装置,其特征在于,包括:
9.一种电子设备,包括存储器、处理器以及存储在所述存储器中并且可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如权利要求1至7中任一项所述方法的步骤。
10.一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至7中任一项所述方法的步骤。
技术总结
本申请涉及语音交互技术领域,提供了一种语音信息的识别方法、装置、电子设备及存储介质。该方法包括:在接收到针对语音助手的语音唤醒指令的情况下,根据语音唤醒指令确定第一目标人员在车辆内的第一位置信息,第一目标人员为发出语音唤醒指令的人员;获取车辆内的图像信息,并根据图像信息确定第一目标人员在车辆内的第二位置信息;根据第一位置信息和第二位置信息确定第一目标人员在车辆内的第一目标音区;根据第一目标音区,控制语音助手仅接收并识别第一目标音区内的语音信息。本申请实施例解决了现有技术中存在的音区识别不准确导致语音交互不顺畅的问题。
技术研发人员:包涵,包楠,徐焱均,于红超
受保护的技术使用者:重庆赛力斯新能源汽车设计院有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!