扩展真核生物遗传密码的制作方法与工艺
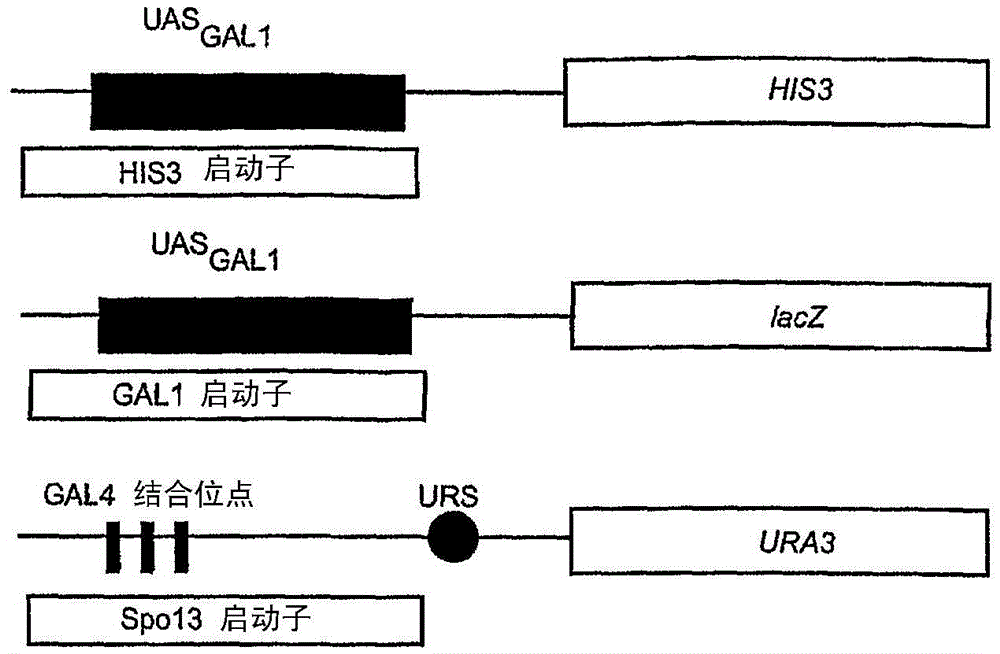
扩展真核生物遗传密码本申请是2004.04.16提交的CN200480015171.6,题为“扩展真核生物遗传密码”的分案申请。相关申请的交叉参考本申请是基于Chin等于2003年4月17日提交的题为“扩展真核生物遗传密码”的申请USSN60/463,869、Chin等于2003年6月18日提交的题为“扩展真核生物遗传密码”的申请USSN60/479,931、Chin等于2003年8月5日提交的题为“扩展真核生物遗传密码”的申请USSN60/493,014和Chin等于2003年8月19日提交的题为“扩展真核生物遗传密码”的申请USSN60/496,548的常规用途专利申请。本文据此要求这些在先申请的优先权和利益。关于在联邦资助的研究和发展中所作发明权利的声明本发明在国立卫生研究院基金编号GM62159的政府资助和能源部基金DE-FG0300ER45812的资助下完成。政府拥有本发明的一定权利。发明领域本发明属于真核细胞中的翻译生物化学领域。本发明涉及在真核细胞中生产和组合正交tRNA、正交合成酶和它们配对的方法。本发明也涉及非天然氨基酸的组合物、蛋白质和在真核细胞中生产包括非天然氨基酸的蛋白质的方法。发明背景从细菌到人类,每个已知生物的遗传密码都编码了相同的二十个普通氨基酸。这20个相同的天然氨基酸的不同组合构成蛋白质,进行实际上所有的复杂生命过程,从光合作用到信号转导和免疫反应。为了研究和修饰蛋白的结构和功能,科学家们试图操纵遗传密码和蛋白质的氨基酸序列。但是,难以去除由遗传密码强加的限制,即将蛋白质限于二十个遗传编码的标准构建(除了罕用的硒代半胱氨酸(参见,例如,A.Bock等,(1991),MolecularMicrobiology5:515-20)和吡咯赖氨酸(参见,例如,G.Srinivasan,等,(2002),Science296:1459-62)。在消除这些限制方面已经取得了一些进展,虽然该进展已被限制而且合理控制蛋白结构和功能的能力仍就处于萌芽状态。例如,化学家已经开发了合成和操纵小分子结构的方法和策略(参见,例如,E.J.Corey和X.-M.Cheng,化学合成的逻辑(TheLogicofChemicalSynthesis)(Wiley-Interscience,NewYork,1995))。全合成(参见,例如,B.Merrifield,(1986),Science232:341-7(1986))和半合成方法(参见,例如,D.Y.Jackson等,(1994)Science266:243-7和P.E.Dawson和S.B.Kent,(2000),AnnualReviewofBiochemistry69:923-60)使合成肽和小蛋白成为可能,但是这些方法的使用在超过10千道尔顿(kDa)的蛋白质中受到限制。诱变法虽然是强大的,但也限于有限数量的结构改变。在很多情况下,可能在整个蛋白质中竞争性掺入与普通氨基酸接近的结构类似物。参见,例如,R.Furter,(1998),ProteinScience7:419-26;K.Kirshenbaum,等,(2002),ChemBioChem3:235-7和V.Doring等,(2001),Science292:501-4。在尝试扩展操纵蛋白结构和功能的能力中,开发了用化学酰化正交tRNA的体外方法,该方法允许在体外响应于无义密码子将非天然氨基酸选择性掺入(参见,例如,J.A.Ellman,等,(1992),Science255:197-200)。将具有新结构和物理性质的氨基酸选择性掺入蛋白中,以研究蛋白折叠和稳定性,以及生物分子识别和催化作用。参见,例如,D.Mendel,等,(1995),AnnualReviewofBiophysicsandBiomolecularStructure24:435-462和V.W.Cornish,等(1995年3月31日),AngewChem.Int.Ed.Engl.,34:621-633。然而,该方法的化学计量性质严重限制了可以产生的蛋白量。将非天然氨基酸显微注射入细胞。例如,通过显微注射化学错酰化嗜热四膜虫tRNA(例如,M.E.Saks,等(1996),用于通过无义抑制将非天然氨基酸体内掺入蛋白质中的工程四膜虫tRNAGln,J.Biol.Chem.271:23169-23175)和相应的mRNA将非天然氨基酸引入爪蟾卵母细胞的烟酰乙酰胆碱受体中(例如,M.W.Nowak,等(1998),将非天然氨基酸体内掺入爪蟾卵母细胞表达系统的离子通道中,酶学方法.293:504-529)。这允许通过引入含有物理或化学性质独特的侧链氨基酸,对卵母细胞内的受体进行详细的生物物理研究。参见,例如,D.A.Dougherty(2000),作为蛋白结构和功能探针的非天然氨基酸,Curr.Opin.Chem.Biol.4:645-652。不幸的是,该方法限于可显微注射的细胞中的蛋白质,因为相关的tRNA是体外化学酰化的,不能再酰化,所以蛋白产率很低。为克服这些限制,将新组分加入原核生物大肠杆菌的蛋白生物合成机器中(例如,L.Wang,等,(2001),Science292:498-500),这允许在体内遗传编码非天然氨基酸。为响应琥珀密码子TAG,用该方法将具有新化学、物理或生物学性质的一些新氨基酸,包括光亲和标记和可光致异构的氨基酸、酮基氨基酸和糖基化氨基酸以高保真度有效掺入大肠杆菌的蛋白中。参见,例如,J.W.Chin等,(2002),JournaloftheAmericanChemicalSociety124:9026-9027;J.W.Chin和P.G.Schultz,(2002),ChemBioChem11:1135-1137;J.W.Chin,等,(2002),PNASUnitedStatesofAmerica99:11020-11024:和L.Wang和P.G.Schultz,(2002),Chem.Comm.,1-10。然而,原核细胞和真核细胞的翻译机器并不是高度保守的;因此,加入大肠杆菌的生物合成机器的组分不能经常用来将非天然氨基酸位点特异性地掺入真核细胞的蛋白中。例如,大肠杆菌中使用的詹氏甲烷球菌酪氨酰-tRNA合成酶/tRNA对在真核细胞中是不正交的。此外,tRNA在真核细胞中,而非在原核细胞中的转录是通过RNA聚合酶III进行的,这限制了可在真核细胞中转录的tRNA结构基因的一级序列。而且,与原核细胞相反,真核细胞中的tRNA需要从转录它们的细胞核中输出至胞质,以在翻译中起作用。最后,真核80S核糖体与70S原核核糖体不同。因此,需要开发改进的生物合成机器组件,以扩展真核生物遗传密码。本发明满足了这些和其它需要,这在下面公开的综述中显而易见。发明概要本发明提供了具有翻译组件的真核细胞,例如,正交氨酰基-tRNA合成酶(O-RS)对和正交tRNA(O-tRNA),及它们的个别组件,它们用于真核蛋白生物合成机器,在真核细胞中将非天然氨基酸掺入生长的多肽链中。本发明组合物包括含有正交氨酰基-tRNA合成酶(O-RS)(例如,来源于非真核生物,如大肠杆菌、嗜热脂肪芽孢杆菌等)的真核细胞(例如,酵母细胞(如酿酒酵母细胞),哺乳动物细胞、植物细胞、藻类细胞、真菌细胞、昆虫细胞等),其中O-RS在真核细胞中优选地氨酰化具有至少一个非天然氨基酸的正交tRNA(O-tRNA)。任选地,在给定真核细胞中可以氨酰化两种或多种OtRNA。在一个方面,O-RS氨酰化例如,至少40%、至少45%、至少50%、至少60%、至少75%、至少80%、或甚至90%或更多的具有非天然氨基酸的O-tRNA,与具有氨基酸序列,如SEQIDNO.:86或45中所列序列的O-RS一样有效。在一个实施方式中,本发明的O-RS氨酰化具有非天然氨基酸的O-tRNA,比O-RS氨酰化具有天然氨基酸的O-tRNA的效率高例如,至少10倍、至少20倍、至少30倍等。在一个实施方式中,SEQIDNO.:3-35(例如,3-19、20-35或序列3-35的任何其它亚组)中所列任一个多核苷酸序列,或与其互补的多核苷酸序列编码了O-RS或它的一部分。在另一实施方式中,O-RS包含了SEQIDNO.:36-63(例如,36-47、48-63或36-63的任何其它亚组)和/或86,或其保守变异的氨基酸序列。在另一实施方式中,O-RS包含氨基酸序列,即与天然产生的酪氨酰氨酰基-tRNA合成酶(TyrRS)例如、至少90%、至少95%、至少98%、至少99%或至少99.5%或更多相同,并包含来自A-E族的两种或多种氨基酸。A族包括与大肠杆菌TyrRS的Tyr37相对应位置上的缬氨酸、异亮氨酸、亮氨酸、甘氨酸、丝氨酸、丙氨酸或苏氨酸。B族包括与大肠杆菌TyrRS的Asn126相对应位置上的天冬氨酸。C族包括与大肠杆菌TyrRS的Asp182相对应位置上的苏氨酸、丝氨酸、精氨酸、天冬酰胺或甘氨酸。D族包括与大肠杆菌TyrRS的Phel83相对应位置上的甲硫氨酸、丙氨酸、缬氨酸或酪氨酸;E族包括与大肠杆菌TyrRS的Leul86相对应位置上的丝氨酸、甲硫氨酸、缬氨酸、半胱氨酸、苏氨酸或丙氨酸。任何这些族组合的亚组是本发明的特征。例如,在一个实施方式中,O-RS具有两种或多种选自与大肠杆菌TyrRS的Tyr37相对应位置上出现的缬氨酸、异亮氨酸、亮氨酸、或苏氨酸;与大肠杆菌TyrRS的Asp182相对应位置上的苏氨酸、丝氨酸、精氨酸、或甘氨酸;与大肠杆菌TyrRS的Phel83相对应位置上的甲硫氨酸、或酪氨酸;和与大肠杆菌TyrRS的Leul86相对应位置上的丝氨酸、或丙氨酸的氨基酸。在另一实施方式中,O-RS包括两种或多种选自与大肠杆菌TyrRS的Tyr37相对应位置上的甘氨酸、丝氨酸、或丙氨酸,与大肠杆菌TyrRS的Asnl26相对应位置上的天冬氨酸,与大肠杆菌TyrRS的Aspl82相对应位置上的天冬酰胺,与大肠杆菌TyrRS的Phel83相对应位置上的丙氨酸或缬氨酸和/或和与大肠杆菌TyrRS的Leul86相对应位置上的甲硫氨酸、缬氨酸、半胱氨酸、或苏氨酸。在另一实施方式中,与天然氨基酸相比,O-RS对于非天然氨基酸具有一种或多种改进或增强的酶性质。例如,与天然氨基酸相比对非天然氨基酸的改进或增强的性质包括,例如,较高km、较低km、较高kcat、较低kcat、较低kcat/km、较高kcat/km等的任意一种。真核细胞也任选地包括非天然氨基酸。真核细胞任选地包括正交tRNA(O-tRNA)(例如,来自非真核生物,如大肠杆菌,嗜热脂肪芽孢杆菌和/或类似物),其中O-tRNA识别选择密码子,并优选地由O-RS氨酰化具有非天然氨基酸的O-tRNA。在一个方面,O-tRNA介导非天然氨基酸掺入蛋白质中,其效率相当于包含SEQIDNO.:65中所列多核苷酸序列或在该序列的细胞中加工的tRNA效率的例如,至少45%、至少50%、至少60%、至少75%、至少80%、至少90%、至少95%或99%。在另一方面,O-tRNA包含SEQIDNO.:65的序列,O-RS包含选自SEQIDNO.:36-63(例如,36-47、48-63或36-63的任何其它亚组)和/或86和/或它们的保守变异中任意一个所列氨基酸序列的多肽序列。在另一实施方式中,真核细胞包含含有编码感兴趣多肽的多核苷酸的核酸,其中多核苷酸包含O-tRNA识别的选择密码子。在一个方面,包含非天然氨基酸的感兴趣多肽的产率是从多核苷酸缺少选择密码子的细胞中获得的天然产生的感兴趣多肽的例如,至少2.5%、至少5%、至少10%、至少25%、至少30%、至少40%、50%或更多。在另一方面,细胞在没有非天然氨基酸的情况下生产感兴趣多肽的产率是在有非天然氨基酸的情况下多肽产率的例如,小于35%、小于30%、小于20%、小于15%、小于10%、小于5%、小于2.5%等。本发明也提供包含正交氨酰基-tRNA合成酶(O-RS)、正交tRNA(O-tRNA)、非天然氨基酸和含有编码感兴趣多肽的多核苷酸的核酸的真核细胞。多核苷酸包含O-tRNA识别的选择密码子。此外,在真核细胞中O-RS优选地氨酰化具有非天然氨基酸的正交tRNA(O-tRNA),细胞在没有非天然氨基酸的情况下生产感兴趣多肽的产率是在有非天然氨基酸的情况下多肽产率的例如,小于30%、小于20%、小于15%、小于10%、小于5%、小于2.5%等。包括含有正交tRNA(O-tRNA)的真核细胞的组合物也是本发明的特征。一般地,O-tRNA在体内介导非天然氨基酸掺入蛋白质中,该蛋白质通过含有O-tRNA识别的选择密码子的多核苷酸编码。在一个实施方式中,O-tRNA介导非天然氨基酸掺入蛋白质中,其效率相当于包含SEQIDNO.:65中所列多核苷酸序列或在该序列的细胞中加工的tRNA效率的例如,至少45%、至少50%、至少60%、至少75%、至少80%、至少90%、至少95%或甚至99%或更高。在另一实施方式中,O-tRNA包含SEQIDNO.:65中所列的多核苷酸序列或它的保守变异,或从该序列加工而来。在另一实施方式中,O-tRNA包含可循环的O-tRNA。在本发明的一个方面,O-tRNA是转录后修饰的。本发明也提供在真核细胞中编码O-tRNA的核酸或它的互补多核苷酸。在一个实施方式中,核酸包含A框和B框。本发明也表征了生产翻译组件的方法,例如,O-RSs或O-tRNA/O-RS对(和这些方法生产的翻译组件)。例如,本发明提供了生产正交氨酰基-tRNA合成酶(O-RS)的方法,该酶在真核细胞中优选地氨酰化具有非天然氨基酸的正交tRNA。该方法包括,例如,将第一种类的生物真核细胞的群体在非天然氨基酸存在下进行正选择,其中各真核细胞包含:i)氨酰基-tRNA合成酶(RS)文库的一员、ii)正交tRNA(O-tRNA)、iii)编码正选择标记的多核苷酸和iv)编码负选择标记的多核苷酸;其中在正选择下存活的细胞包含在非天然氨基酸存在下氨酰化正交tRNA(O-tRNA)的活性RS。在没有非天然氨基酸的情况下将在正选择下存活的细胞进行负选择,以去除氨酰化具有天然氨基酸的O-tRNA的活性RS。这提供了优选地氨酰化具有非天然氨基酸的O-tRNA的O-RS。在某些实施方式中,将编码正选择标记的多核苷酸可操作地连接到效应元件上,细胞还包括a)编码从效应元件调节转录的转录调节蛋白(例如,真核转录调节蛋白等)和b)包含至少一种选择密码子的的多核苷酸。通过氨酰化具有非天然氨基酸的O-tRNA将非天然氨基酸掺入转录调节蛋白中导致正选择标记的转录。在一个实施方式中,转录调节蛋白是转录激活蛋白(例如,GAL4等),选择密码子是琥珀终止密码子,例如,其中琥珀终止密码子位于或基本上接近编码转录激活蛋白的DNA结合域的部分多核苷酸。正选择标记可以是各种分子中任意一种。在一个实施方式中,正选择标记包含生长营养补充剂,在缺少营养补充剂的培养基中进行选择。在另一实施方式中,编码正选择标记的多核苷酸是例如,ura3、leu2、lys2、lacZ基因、his3(例如,其中his3基因编码咪唑甘油磷酸脱氢酶,由提供的3-氨基三唑(3-AT)和/或类似物检测。在另一实施方式中,编码正选择标记的多核苷酸包含选择密码子。如同正选择标记一样,负选择标记也可以是各种分子中任意一种。在某些实施方式中,编码负选择标记的多核苷酸可操作地连接到效应元件上,转录调节蛋白从效应元件介导转录。通过氨酰化具有天然氨基酸的O-tRNA将天然氨基酸掺入转录调节蛋白中导致负选择标记的转录。在一个实施方式中,编码负选择标记的多核苷酸是例如,ura3基因,负选择在含有5-氟乳清酸(5-FOA)的培养基中完成。在另一实施方式中,用于负选择的培养基包含可以被负选择标记转化为可检测物质的选择剂或筛选剂。在本发明的一个方面,可检测物质是有毒物质。在一个实施方式中,编码负选择标记的多核苷酸包括选择密码子。在某些实施方式中,正选择标记和/或负选择标记包含在合适反应物的存在下使发光反应发荧光或催化发光反应的多肽。在本发明的一个方面,通过荧光激活细胞分选(FACS)或通过发光检测正选择标记和/或负选择标记。在某些实施方式中,正选择标记和/或负选择标记包含基于亲和力的筛选标记或转录调节蛋白。在一个实施方式中,同一多核苷酸编码正选择标记和负选择标记。在一个实施方式中,编码本发明正选择标记和/或负选择标记的多核苷酸可以包含至少两个选择密码子,各自或两者可以包含至少两个不同的选择密码子或至少两个相同的选择密码子。选择/筛选严格性的附加水平也可用于本发明方法。在一个实施方式中,方法可包括,例如,在步骤(a)、(b)或(a)和(b)提供数量不等的失活合成酶,其中数量不等的失活合成酶提供附加水平的选择或筛选严格性。在一个实施方式中,本方法用于生产O-RS的步骤(a),(b)或步骤(a)和(b)包括不同的选择或筛选严格性,例如,正和/或负选择标记的严格性。该方法任选地包括将优选地氨酰化具有非天然氨基酸的O-tRNA的O-RS进行附加选择轮,例如,附加正选择轮、附加负选择轮或附加正和负选择轮的组合。在一个实施方式中,选择/筛选包括一种或多种正或负选择/筛选,它们选自,例如,氨基酸通透性的改变,翻译效率的改变,翻译保真度的改变等。一种或多种改变是基于编码正交tRNA-tRNA合成酶对的组件的一种或多种多核苷酸中的突变被用来生产蛋白。一般地,RS文库(例如,突变体RS文库)包含来自至少一种例如,来自非真核生物的氨酰基-tRNA合成酶(RS)的RS。在一个实施方式中,RS文库来自失活的RS,例如,其中失活RS通过突变活性RS而产生。在另一实施方式中,失活RS包含氨基酸结合口袋和一个或多个含有用一种或多种不同氨基酸取代结合口袋的氨基酸,例如,取代的氨基酸用丙氨酸取代。在某些实施方式中,生产O-RS的方法还包括在编码RS的核酸上进行随机突变、位点特异性突变、重组、嵌合构建或它们的任意组合,因此产生突变体RS文库。在某些实施方式中,该方法还包括,例如,(c)分离编码O-RS的核酸;(d)从核酸中产生一组编码突变O-RS的多核苷酸(例如,通过随机诱变、位点特异性诱变、嵌合构建、重组或它们的任意组合);和(e)重复步骤(a)和/或(b),直到获得优选地氨酰化具有非天然氨基酸的O-tRNA的突变O-RS。在本发明的一个方面,步骤(c)-(e)至少进行两次。生产O-tRNA/O-RS对的方法也是本发明的特征。在一个实施方式中,如上所述地获得O-RS,通过将第一种类的真核细胞的群体进行负选择获得O-tRNA,其中真核细胞包括tRNA文库的一员,以去除包含被对真核细胞内源性氨酰基-tRNA合成酶(RS)氨酰化的tRNA文库的一员的细胞。这提供了与第一种类的真核细胞正交的tRNA库。在本发明的一个方面,tRNA文库包含来自至少一种例如,来自非真核生物的tRNA的tRNA。在本发明的另一方面,氨酰基-tRNA合成酶(RS)文库包括来自至少一种例如,来自非真核生物的氨酰基-tRNA合成酶(RS)的RS。在本发明的另一方面,tRNA文库包括来自至少一种来自第一种非真核生物的tRNA的tRNAs。氨酰基-tRNA合成酶(RS)文库任选地包含来自至少一种来自第二种非真核生物的氨酰基-tRNA合成酶(RS)的RS。在一个实施方式中,第一种和第二种非真核生物是相同的。另外,第一种和第二种非真核生物可以是不同的。通过本发明方法生产的特异性O-tRNA/O-RS对也是本发明的特征。本发明的另一特征是在一种类中生产翻译组件和将选择/筛选的翻译组件引入第二种类的方法。例如,在第一种类(例如,真核生物,如酵母等)中生产O-tRNA/O-RS对的方法还包括将编码O-tRNA的核酸和编码O-RS的核酸引入第二种类的真核细胞(例如,哺乳动物、昆虫、真菌、藻类、植物等)。第二种类可以在体内用引入的翻译组件将非天然氨基酸掺入生长的多肽链中,例如,在翻译过程中。在另一实施例中,生产在真核细胞中优选地氨酰化具有非天然氨基酸的正交tRNA的正交氨酰基-tRNA合成酶(O-RS)的方法包括:(a)在非天然氨基酸存在下对第一种类的真核细胞群体(例如,真核生物,如酵母或类似物)进行正选择。各第一种类的真核细胞包括:i)氨酰基-tRNA合成酶(RS)文库的一员,ii)正交tRNA(O-tRNA),iii)编码正选择标记的多核苷酸,和iv)编码负选择标记的多核苷酸。能够在正选择下存活的细胞包含在非天然氨基酸存在下氨酰化正交tRNA(O-tRNA)的活性RS。将在正选择下存活的细胞在没有非天然氨基酸的情况下进行负选择,以去除氨酰化具有天然氨基酸的O-tRNA的活性RS,因此提供优选地氨酰化具有非天然氨基酸的O-tRNA的O-RS。将编码O-tRNA的核酸和编码O-RS的核酸引入第二种类的真核细胞(例如,哺乳动物、昆虫、真菌、藻类、植物和/或类似物)。当这些组件在第二种类中翻译时,这些组件可以用来将非天然氨基酸掺入第二种类中感兴趣的蛋白或多肽。在一个实施方式中,将O-tRNA和/或O-RS引入第二种类的生物真核细胞中。在某些实施方式中,通过将第一种类真核细胞的群体进行负选择获得O-tRNA,其中真核细胞包含tRNA文库的一员,以去除被对真核细胞内源性氨酰基-tRNA合成酶(RS)氨酰化的tRNA文库的一员的细胞。这提供了与第一种类和第二种类的真核细胞正交的tRNA库。在一个方面,本发明包括含有一种蛋白的组合物,其中该蛋白包含至少一种非天然氨基酸和至少一个翻译后修饰,其中至少一个翻译后修饰是将含有第二活性基团的分子通过[3+2]环加成附着到含有第一活性基团的至少一种非天然氨基酸上。因此,具有至少一种非天然氨基酸的蛋白(或感兴趣多肽)也是本发明的特征。在本发明的某些实施方式中,具有至少一种非天然氨基酸的蛋白包括至少一个翻译后修饰。在一个实施方式中,至少一个翻译后修饰是将含有第二活性基团的分子(例如,染料、聚合物如聚乙二醇的衍生物、光交联剂、细胞毒化合物、亲和标记、生物素的衍生物、树脂、第二种蛋白或多肽、金属螯合剂、辅因子、脂肪酸、碳水化合物、多核苷酸(例如、DNA、RNA等)等)通过[3+2]环加成附着到含有第一活性基团的至少一种非天然氨基酸上。例如,第一活性基团是炔基部分(例如,非天然氨基酸中对-炔丙基氧基苯丙氨酸)(该基团有时也称为乙炔部分),第二活性基团是叠氮基部分。在另一个实施例中,第一活性基团是叠氮基部分(例如,非天然氨基酸中对-叠氮基-L-苯丙氨酸),第二活性基团是炔基部分。在某些实施方式中,本发明的蛋白包括至少一种含有至少一个翻译后修饰的非天然氨基酸(例如,酮式非天然氨基酸),其中至少一个翻译后修饰是糖部分。在某些实施方式中,在真核细胞中体内进行翻译后修饰。在某些实施方式中,蛋白包括至少一个通过真核细胞体内进行的翻译后修饰,其中翻译后修饰并不是通过原核细胞进行的。翻译后修饰的例子包括但不限于乙酰化、酰化、脂质-修饰、棕榈酰化、棕榈酸酯加成、磷酸化、糖脂-连接修饰等。在一个实施方式中,翻译后修饰包括将寡糖通过GlcNAc-天冬酰胺连接附着到天冬酰胺上(例如,其中寡糖包括(GlcNAc-Man)2-Man-GlcNAc-GlcNAc等)。在另一实施方式中,翻译后修饰是将寡糖(例如,Gal-GalNAc,Gal-GlcNAc等)通过GalNAc-丝氨酸、GalNAc-苏氨酸、GlcNAc-丝氨酸或GlcNAc-苏氨酸连接附着到丝氨酸或苏氨酸上。在某些实施方式中,本发明的蛋白或多肽可包含分泌或定位序列、表位标记、FLAG标记、聚组氨酸标记、GST融合蛋白和/或类似物。一般地,蛋白与任意可用蛋白(例如,治疗蛋白、诊断蛋白、工业酶或它们的一部分和/或类似物)的例如,至少60%、至少70%、至少75%、至少80%、至少90%、至少95%或甚至至少99%或更多相同,它们包含一种或多种非天然氨基酸。在一个实施方式中,本发明组合物包括感兴趣的蛋白或多肽和赋形剂(例如,缓冲液、药学上可接受的赋形剂等)。感兴趣的蛋白或多肽可含有至少一个、至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个、或十个或更多非天然氨基酸。非天然氨基酸可以是相同或不同的,例如,在包含1、2、3、4、5、6、7、8、9、10或更多不同的非天然氨基酸的蛋白中可以有1、2、3、4、5、6、7、8、9、10或更多不同位点。在某些实施方式中,蛋白质天然产生形式中存在的至少一种,但少于全部的具体氨基酸被非天然氨基酸取代。一种蛋白(或感兴趣多肽)的例子包括但不限于,例如,细胞因子、生长因子、生长因子受体、干扰素、白介素、炎症分子、癌基因产物、肽激素、信号转导分子、甾类激素受体、促红细胞生成素(EPO)、胰岛素、人生长激素、α-1抗胰蛋白酶、血管生成抑制素、抗溶血因子、抗体、载脂蛋白、脱辅蛋白质、心钠素、心房钠尿多肽、心房肽、C-X-C趋化因子、T39765、NAP-2、ENA-78、Gro-a、Gro-b、Gro-c、IP-10、GCP-2、NAP-4、SDF-1、PF4、MIG、降钙素、c-kit配体、细胞因子、CC趋化因子、单核细胞趋化蛋白-1、单核细胞趋化蛋白-2、单核细胞趋化蛋白-3、单核细胞炎症蛋白-1α、单核细胞炎症蛋白-1β、RANTES、I309、R83915、R91733、HCC1、T58847、D31065、T64262、CD40、CD40配体、C-kit配体、胶原、集落刺激因子(CSF)、补体因子5a、补体抑制剂、补体受体1、细胞因子、DHFR、上皮嗜中性粒细胞激活肽-78、GROα/MGSA、GROβ、GROγ、MIP-lα、MIP-1δ、MCP-1、表皮生长因子(EGF)、上皮嗜中性粒细胞激活肽、促红细胞生成素(EPO)、剥脱性毒素、因子IX、因子VII、因子VIII、因子X、成纤维细胞生长因子(FGF)、纤维蛋白原、纤连蛋白、G-CSF、GM-CSF、葡糖脑苷脂酶、促性腺素、生长因子、生长因子受体、Hedgehog蛋白、血红蛋白、肝细胞生长因子(HGF)、水蛭素、人血清白蛋白、ICAM-1、ICAM-1受体、LFA-1、LFA-1受体、胰岛素、胰岛素-样生长因子(IGF)、IGF-I、IGF-II、干扰素、IFN-α、IFN-β、IFN-γ、白介素、IL-1、IL-2、IL-3、IL-4、IL-5、IL-6、IL-7、IL-8、IL-9、IL-10、IL-11、IL-12、角质形成细胞生长因子(KGF)、乳铁蛋白、白血病抑制因子、荧光素酶、Neurturin、嗜中性粒细胞抑制因子(NIF)、制瘤素M、成骨蛋白、癌基因产物、甲状旁腺激素、PD-ECSF、PDGF、肽激素、人生长激素、多效营养因子、蛋白A、蛋白G、热源性外毒素A、B或C、松弛素、肾素、SCF、可溶性补体受体I、可溶性I-CAM1、可溶性白介素受体、可溶性TNF受体、生长调节素、促生长素抑制素、促生长素、链激酶、超抗原、葡萄球菌肠毒素、SEA、SEB、SEC1、SEC2、SEC3、SED、SEE、甾类激素受体、超氧化物歧化酶(SOD)、中毒性休克综合征毒素、胸腺素α1、组织纤溶酶原激活物、肿瘤生长因子(TGF)、TGF-α、TGF-β、肿瘤坏死因子、肿瘤坏死因子α、肿瘤坏死因子β、肿瘤坏死因子受体(TNFR)、VLA-4蛋白、VCAM-1蛋白、血管内皮生长因子(VEGEF)、尿激酶、Mos、Ras、Raf、Met;p53、Tat、Fos、Myc、Jun、Myb、Rel、雌激素受体、孕酮受体、睾酮受体、醛固酮受体、LDL受体、SCF/c-Kit、CD40L/CD40、VLA-4/VCAM-1、ICAM-l/LFA-1、透明质酸苷(hyalurin)/CD44、皮质酮、Genebank或其它可用数据库中存在的蛋白等,和/或它们的一部分。在一个实施方式中,感兴趣多肽包括转录调节蛋白(例如,转录激活蛋白(如GAL4),或转录抑制蛋白等)或它们的一部分。真核细胞中的GAL4蛋白或其部分的组合物也是本发明的特征。一般地,GAL4蛋白或其一部分包含至少一种非天然氨基酸。本发明的真核细胞提供了合成含大有用量非天然氨基酸的蛋白的能力。例如,生产含有非天然氨基酸的蛋白在细胞抽提物、缓冲液、药学上可接受的赋形剂和/或类似物中的蛋白浓度是,例如,至少10微克/升、至少50微克/升、至少75微克/升、至少100微克/升、至少200微克/升、至少250微克/升、或至少500微克/升或更高。在某些实施方式中,本发明组合物包括,例如,至少10微克、至少50微克、至少75微克、至少100微克、至少200微克、至少250微克、或至少500微克或更多含有非天然氨基酸的蛋白。在某些实施方式中,核酸编码感兴趣的蛋白或多肽(或它们的一部分)。一般地,该核酸包含至少一个选择密码子、至少两个选择密码子、至少三个选择密码子、至少四个选择密码子、至少五个选择密码子、至少六个选择密码子、至少七个选择密码子、至少八个选择密码子、至少九个选择密码子、或甚至十个或更多选择密码子。本发明也提供在真核细胞中生产至少一种含有至少一个非天然氨基酸的蛋白质(以及用这种方法生产的蛋白)的方法。方法包括,例如,在合适的培养基中培养含有一种核酸的真核细胞,该核酸包含至少一个选择密码子并编码该蛋白。真核细胞也含有细胞中有功能且能识别选择密码子的正交tRNA(O-tRNA),以及优选地氨酰化具有非天然氨基酸的O-tRNA的正交氨酰基tRNA合成酶(O-RS),培养基含有非天然氨基酸。在一个实施方式中,O-RS氨酰化具有非天然氨基酸的O-tRNA相当于具有如SEQIDNO.:86或45中所列氨基酸序列的O-RS的效率的例如,至少45%、至少50%、至少60%、至少75%、至少80%、至少90%、至少95%、或甚至99%或更高。在另一实施方式中,O-tRNA包括SEQIDNO.:64或65或其互补多核苷酸序列,或从该序列加工而来,或由该序列编码。在另一实施方式中,O-RS包含SEQIDNO.:36-63(例如,36-47、48-63或36-63的任意其它亚组)和/或86中任一个所列氨基酸序列。在一个实施方式中,该方法还包括将非天然氨基酸掺入该蛋白中,其中非天然氨基酸包含第一活性基团;并将该蛋白与含有第二活性基团的分子(例如,染料、聚合物、例如、聚乙二醇的衍生物、光交联剂、细胞毒化合物、亲和标记、生物素的衍生物、树脂、第二种蛋白或多肽、金属螯合剂、辅因子、脂肪酸、碳水化合物、多核苷酸(例如、DNA、RNA等)等)接触。第一活性基团与第二活性基团反应,将该分子通过[3+2]环加成附着到非天然氨基酸上。在一个实施方式中,第一活性基团是炔基或叠氮基部分,第二活性基团是叠氮基或炔基部分。例如,第一活性基团是炔基部分(例如,非天然氨基酸中对-炔丙基氧基苯丙氨酸),第二活性基团是叠氮基部分。在另一实施例中,第一活性基团是叠氮基部分(例如,非天然氨基酸中对-叠氮基-L-苯丙氨酸),第二活性基团是炔基部分.在某些实施方式中,编码蛋白包含治疗蛋白、诊断蛋白、工业酶或它们的一部分。在一个实施方式中,通过非天然氨基酸进一步修饰该方法生产的蛋白。例如,通过如亲核-亲电子反应,经由[3+2]环加成等修饰非天然氨基酸。在另一实施方式中,通过至少一个翻译后修饰(例如,N-糖基化,O-糖基化,乙酰化,酰化,脂质-修饰,棕榈酰化,棕榈酸酯加成,磷酸化,糖脂-连接修饰等)体内修饰该方法生产的蛋白质。也提供了生产筛选或选择转录调节蛋白的方法(以及用这种方法生产的筛选或选择转录调节蛋白)。方法包括,例如,选择第一个多核苷酸序列,其中多核苷酸序列编码核酸结合域;将第一个多核苷酸序列突变,以包括至少一种选择密码子。这提供了筛选或选择多核苷酸序列。方法也包括,例如,选择第二个多核苷酸序列,其中第二个多核苷酸序列编码转录激活域;提供构建物,它包含可操作地连接于第二个多核苷酸序列的筛选或选择多核苷酸序列;和,将构建物非天然氨基酸、正交tRNA合成酶(O-RS)和正交tRNA(O-tRNA)引入细胞。用这些组件,响应于筛选或选择多核苷酸序列中的选择密码子,O-RS优选地氨酰化具有非天然氨基酸的O-tRNA,O-tRNA识别选择密码子并将非天然氨基酸掺入核酸结合域中。这提供了筛选或选择转录调节蛋白。在某些实施方式中,本发明的组合物和方法包括真核细胞。本发明的真核细胞包括,例如,哺乳动物细胞、酵母细胞、真菌细胞、植物细胞、昆虫细胞等的任意一种。本发明的翻译组件可以来自各种生物,例如,非真核生物,如原核生物(例如,大肠杆菌,嗜热脂肪芽孢杆菌等),或古细菌,或例如,真核生物。本发明的选择密码子扩展了真核蛋白生物合成机器的遗传密码子构架。本发明中可以使用各种选择密码子的任意一种,包括终止密码子(例如,琥珀密码子、赭石密码子或乳白终止密码子)、无义密码子、罕用密码子、四(或更多)碱基密码子和/或类似物。可用于本文描述的组合物和方法的非天然氨基酸的例子包括(但不限于):对-乙酰基-L-苯丙氨酸、对-碘代-L-苯丙氨酸、O-甲基-L-酪氨酸、对-炔丙基氧基苯丙氨酸、对-炔丙基-苯丙氨酸、L-3-(2-萘基)丙氨酸、3-甲基-苯丙氨酸、0-4-烯丙基-L-酪氨酸、4-丙基-L-酪氨酸、三-氧-乙酰基-GlcNAcβ-丝氨酸、L-多巴、氟化苯丙氨酸、异丙基-L-苯丙氨酸、对-叠氮基-L-苯丙氨酸、对-酰基-L-苯丙氨酸、对-苯甲酰基-L-苯丙氨酸、L-磷酸丝氨酸、膦酰基丝氨酸、膦酰基酪氨酸、对-溴苯丙氨酸、对-氨基-L-苯丙氨酸、异丙基-L-苯丙氨酸、酪氨酸氨基酸的非天然类似物;谷氨酰胺氨基酸的非天然类似物;苯丙氨酸氨基酸的非天然类似物;丝氨酸氨基酸的非天然类似物;苏氨酸氨基酸的非天然类似物;烷基、芳基、酰基、叠氮基、氰基、卤素、肼、酰肼、羟基、链烯基、炔基、醚、硫醇、磺酰基、硒、酯、硫代酸、硼酸、硼酸盐、磷酰基、膦酰基、膦、杂环、烯酮、亚胺、醛、羟胺、酮基或氨基取代的氨基酸或它们的任意组合;具有可光敏化的交联剂的氨基酸;自旋标记的氨基酸;荧光氨基酸;金属结合氨基酸;含金属的氨基酸;放射性氨基酸;光笼蔽(photocaged)和/或可光致异构的氨基酸;含有生物素或生物素-类似物的氨基酸;含酮氨基酸;含有聚乙二醇或聚醚的氨基酸;重原子取代的氨基酸;可化学切割或可光切割的氨基酸;具有延长侧链的氨基酸;含有毒基团的氨基酸;糖取代的氨基酸;含有碳-连接糖的氨基酸;具有氧化还原活性的氨基酸;含α-羟基的酸;氨基硫代酸;α,α双取代的氨基酸;β-氨基酸;除脯氨酸或组氨酸外的环氨基酸,除苯丙氨酸,酪氨酸或色氨酸外的芳族氨基酸,和/或类似物。本发明也提供多肽(O-RS)和多核苷酸,例如,0-tRNA,编码O-RS或其一部分(例如,合成酶的活性位点)的多核苷酸,用于构建氨酰基-tRNA合成酶突变体的寡核苷酸,编码含有一种或多种选择密码子的感兴趣的蛋白或多肽的多核苷酸等。例如,本发明的多肽包括包含SEQIDNO.:36-63(例如,36-47、48-63或36-63的任意其它亚组)和/或86中任一个所列氨基酸序列的多肽,包含由SEQIDNO.:3-35(例如,3-19、20-35或序列3-35的任何其它亚组)中任一个所列多核苷酸序列编码的氨基酸序列的多肽,和具有抗体特异免疫活性的多肽,该抗体对包含SEQIDNO.:36-63(例如,36-47、48-63或36-63的任意其它亚组)和/或86中任一个所列氨基酸序列的多肽或包含SEQIDNO.:3-35(例如,3-19、20-35或序列3-35的任何其它亚组)中任一所列多核苷酸序列编码的氨基酸序列的多肽特异。本发明的多肽也包括与天然产生的酪氨酰氨酰基-tRNA合成酶(TyrRS)(例如,SEQIDNO.:2)具有至少90%相同氨基酸序列的多肽,和包含A-E族(上述)中两种或多种氨基酸的多肽。类似地,本发明多肽也任选地包括含有SEQIDNO.:36-63(例如,36-47、48-63或36-63的任意其它亚组)和/或86中任意一个的至少20个连续氨基酸的多肽,和如A-E族中所述的两个或多个氨基酸取代。含有任一上述多肽的保守变异的氨基酸序列也作为本发明的多肽包括在内。在一个实施方式中,组合物包括本发明的多肽和赋形剂(例如,缓冲液、水、药学上可接受的赋形剂等)。本发明也提供与本发明多肽具有特异免疫活性的抗体或抗血清。本发明中也提供了多核苷酸。本发明的多核苷酸包括那些用一种或多种选择密码子编码本发明感兴趣的蛋白或多肽的多核苷酸。此外,本发明的多核苷酸包括,例如,含有SEQIDNO.:3-35(例如,3-19、20-35或序列3-35的任意其它亚组)、64-85中任意一个所列核苷酸序列的多核苷酸;与该多核苷酸序列互补或编码该多核苷酸序列的多核苷酸;和/或编码含有SEQIDNO.:36-63(例如,36-47、48-63或36-63的任意其它亚组)和/或86中任意一个所列氨基酸序列或其保守变异的多肽的多核苷酸。本发明的多核苷酸也包括编码本发明多肽的多核苷酸。类似地,在高度严谨条件下与上述多核苷酸基本上全长杂交的核酸是本发明的多核苷酸。本发明的多核苷酸也包括编码多肽的多核苷酸,该多肽包含与天然产生的酪氨酰氨酰基-tRNA合成酶(TyrRS)(例如,SEQIDNO.:2)至少90%相同的氨基酸序列,和包含A-E族(上述)中两个或多个突变。与上述多核苷酸和/或含有任一上述多核苷酸的保守变异的多核苷酸至少70%(或至少75%、至少80%、至少85%、至少90%、至少95%、至少98%、或至少99%或更多)相同的多核苷酸也包括在本发明的多核苷酸中。在某些实施方式中,载体(例如,质粒、粘粒、噬菌体、病毒等)包含本发明的多核苷酸。在一个实施方式中,载体是表达载体。在另一实施方式中,表达载体包括可操作地连接于一种或多种本发明的多核苷酸的启动子。在另一实施方式中,细胞含有包括本发明的多核苷酸的载体。在另一方面,本发明提供了化合物的组合物和生产所述化合物的方法。例如,化合物包括,例如,非天然氨基酸(如对-(炔丙基氧基)-苯丙氨酸(例如,图11中的1),叠氮基染料(如化学结构4和化学结构6中所示),炔基聚乙二醇(例如化学结构7中所示),其中n是例如,50和10,000、75和5,000、100和2,000、100和1,000等之间的整数等。在本发明的实施方式中,炔基聚乙二醇的分子量为,例如约5,000至约100,000Da、约20,000至约50,000Da、约20,000至约10,000Da(例如,20,000Da)。也提供了含有这些化合物的各种组合物,例如,具有蛋白质和细胞。在一个方面,组合物包括对-(炔丙基氧基)-苯丙氨酸非天然氨基酸,还包括正交tRNA。可将非天然氨基酸结合到(例如,以共价方式)正交tRNA,例如,通过氨基-酰基键共价结合到正交tRNA,共价结合到正交tRNA的末端核糖的3'OH或2'OH等。在本发明的一个方面,含有叠氮基染料的蛋白质(例如,化学结构4或化学结构6)还包括至少一种非天然氨基酸(例如,炔氨基酸),其中叠氮基染料通过[3+2]环加成附着到非天然氨基酸上。在一个实施方式中,一种蛋白含有化学结构7的炔基聚乙二醇。在另一实施方式中,该组合物还包括至少一种非天然氨基酸(例如,叠氮基氨基酸),其中炔基聚乙二醇通过[3+2]环加成附着到非天然氨基酸上。本发明中包括了合成各种化合物的方法。例如,提供了合成对-(炔丙基氧基)苯丙氨酸化合物的方法。例如,该方法包括(a)将N-叔-丁氧基羰基-酪氨酸和K2C03悬浮在无水DMF中;(b)将炔丙基溴加入(a)的反应混合物中,烷化羟基和羧基基团,产生具有下述结构的保护中间化合物:和(c)将保护中间化合物与无水HC1在MeOH中混合,使胺部分去保护,从而合成对-(炔丙基氧基)苯丙氨酸化合物。在一个实施方式中,该方法还包括(d)将对-(炔丙基氧基)苯丙氨酸HCl溶解于NaOH和MeOH溶液中,室温搅拌;(e)将pH调整到7;和(f)沉淀对-(炔丙基氧基)苯丙氨酸化合物。也提供了合成叠氮基染料的方法。例如,方法包括:(a)提供含有磺酰基卤化物部分的染料化合物;(b)在3-叠氮基丙胺和三乙胺的存在下将染料化合物加热到室温,将3-叠氮基丙胺的胺部分偶联到染料化合物的卤素位置,从而合成叠氮基染料。在一个实施方式中,该染料化合物含有丹磺酰氯,叠氮基染料含有化学结构4的组合物。在一个方面,该方法还包括从反应混合物中纯化叠氮基染料。在另一实施例中,合成叠氮基染料的方法包括(a)提供含胺染料化合物;(b)将含胺染料化合物与碳二亚胺和4-(3-叠氮基丙基氨基甲酰基)-丁酸在合适的溶剂中混合,将酸的羰基与染料化合物的胺部分偶联,从而合成叠氮基染料。在一个实施方式中,碳二亚胺包括1-乙基-3-(3-二甲基氨丙基)碳二亚胺盐酸盐(EDCI)。在一个方面,含胺染料包括荧光胺(fluoresceinamine),合适的溶剂包括吡啶。例如,含胺染料包括荧光胺,叠氮基染料包括化学结构6的组合物。在一个实施方式中,该方法还包括(c)沉淀叠氮基染料;(d)用HC1洗涤沉淀;(e)将洗涤过的沉淀溶解在EtOAc中;和(f)在己烷中沉淀叠氮基染料。也提供了合成炔丙基酰胺聚乙二醇的方法。例如,该方法包括在室温下将炔丙基胺与聚乙二醇(PEG)-羟基琥珀酰亚胺酯在有机溶剂(例如,CH2Cl2)中反应,产生化学结构7的炔丙基酰胺聚乙二醇。在一个实施方式中,该方法还包括用乙酸乙酯沉淀炔丙基酰胺聚乙二醇。在一个方面,该方法还包括在甲醇中再结晶炔丙基酰胺聚乙二醇;真空下干燥产物。试剂盒也是本发明的特征。例如,提供了在细胞中生产包含至少一种非天然氨基酸的蛋白质的试剂盒,其中该试剂盒包括一个含有编码O-tRNA或O-tRNA的多核苷酸序列和编码O-RS或O-RS的多核苷酸序列的容器。在一个实施方式中,该试剂盒还包括至少一种非天然氨基酸。在另一实施方式中,该试剂盒还包括生产该蛋白质的指导材料。定义在详细描述本发明之前,应理解本发明不限于具体装置或生物系统,当然它们可以改变。也应理解本文使用的术语是仅为描述具体实施方式所用,并不打算限制。如本说明书和所附权利要求书中所用的单数形式“一个”、“一种”和“该”包括复数,除非该内容有明确规定。因此,例如,“一个细胞”的提法包括两种或多种细胞的组合;“细菌”的提法包括细菌的混合物等。除非本文或下面的说明书剩余部分中有其它限定,本文中使用的所有技术和科学术语的含义与本发明所属领域普通技术人员通常理解的含义相同。同源:当蛋白质和/或蛋白序列天然地或人工地来自共同的祖先蛋白质或蛋白序列时,则它们“同源”。类似地,当核酸和/或核酸序列天然地或人工地来自共同的祖先核酸和/或核酸序列时,则它们“同源”。例如,可以通过任何可行的诱变方法修饰任何天然产生的核酸,使其包括一种或多种选择密码子。当该诱变的核酸表达时,它编码含有一个或多个非天然氨基酸的多肽。当然,该突变过程还可以改变一个或多个标准密码子,从而也在所得的突变蛋白中改变一个或多个标准氨基酸。同源性通常由两种或多种核酸或蛋白(或其序列)之间的序列相似性推定。用于确定同源性的序列间相似性精确百分数随核酸和蛋白而变还有争论,但通常将少至25%的序列相似性用来确定同源性。较高水平的序列相似性,例如,30%、40%、50%、60%、70%、80%、90%、95%或99%或更高,也可以用来确定同源性。本文描述了通常可用的确定序列相似性百分数的方法(例如,使用默认参数的BLASTP和BLASTN)。正交:本文使用的术语“正交”指与细胞内源性组件一起作用,而其效率比相应的细胞或翻译系统的内源性分子、或不能与细胞内源性组件一起作用的分子低的分子(例如,正交tRNA(O-tRNA)和/或正交氨酰基tRNA合成酶(O-RS))。在指tRNA和氨酰基-tRNA合成酶的情况下,正交指不能或效率降低,例如,正交tRNA与内源性tRNA合成酶一起作用的效率比内源性tRNA与内源性tRNA合成酶的效率低,或正交氨酰基-tRNA合成酶与内源性tRNA一起作用的效率比内源性tRNA合成酶与内源性tRNA一起作用的效率小于20%、小于10%、小于5%、或小于1%。细胞中的正交分子缺少功能内源性互补分子。例如,由细胞的任意内源性RS氨酰化细胞中正交tRNA的效率比由内源性RS氨酰化内源性tRNA的效率低,或甚至是零。在另一实施例中,在感兴趣的细胞中,正交RS氨酰化任意内源性tRNA的效率比由内源性RS氨酰化内源性tRNA的效率低,或甚至是零。可以将第二个正交分子引入细胞,与第一个正交分子一起作用。例如,正交tRNA/RS对包括引入的互补组件,它们在细胞中一起发挥作用,其效率相当于相应tRNA/RS内源对的效率的(例如,50%、60%、70%、75%、80%、90%、95%、或99%或更高)。互补:术语“互补”指可以一起发挥作用的正交对、O-tRNA和O-RS组件,例如,其中O-RS使O-tRNA氨酰化。优选地氨酰化:术语“优选地氨酰化”指与O-RS氨酰化天然产生的tRNA或用于产生O-tRNA的起始材料相比,以例如,70%、75%、85%、90%、95%或99%或更高的效率氨酰化具有非天然氨基酸的O-tRNA。将非天然氨基酸以高保真度掺入生长的多肽链中,例如,对于给定的选择密码子效率大于75%、对于给定的选择密码子效率高于约80%、对于给定的选择密码子效率大于约90%、对于给定的选择密码子效率大于约95%或对于给定的选择密码子效率大于约99%或对于给定的选择密码子效率更高。选择密码子:术语“选择密码子”指在翻译过程中被O-tRNA识别而不被内源性tRNA识别的密码子。O-tRNA抗密码子环识别mRNA上的选择密码子并在多肽的这个位点上掺入其氨基酸,例如,非天然氨基酸。选择密码子可包括,例如,无义密码子,如终止密码子,如,琥珀、赭石和乳白密码子;四个或更多碱基密码子;罕用密码子;来自天然或非天然碱基对和/或类似物的密码子。抑制型tRNA:抑制型tRNA是在给定翻译系统中,例如,通过响应于选择密码子将氨基酸掺入多肽链的机制改变信使RNA(mRNA)的阅读的tRNA。例如,抑制型tRNA可以通过,例如终止密码子、四碱基密码子、罕用密码子和/或类似物阅读。可循环tRNA:术语“可循环tRNA”指氨酰化的tRNA,可用氨基酸(例如,非天然氨基酸),通过在翻译期间将该氨基酸掺入一种或多种多肽链,将其重复地再氨酰化。翻译系统:术语“翻译系统”指将天然产生的氨基酸掺入生长的多肽链(蛋白)中的组分的综合组。翻译系统的组分可包括,例如,核糖体、tRNA、合成酶、mRNA、氨基酸等。可将本发明的组件(例如,ORS、OtRNAs、非天然氨基酸等)加入到体外或体内翻译系统例如,真核细胞,例如,酵母细胞、哺乳动物细胞、植物细胞、藻类细胞、真菌细胞、昆虫细胞、和/或类似物中。非天然氨基酸:本文使用的术语“非天然氨基酸”指不是20种普通的天然产生的氨基酸、硒半胱氨酸或吡咯赖氨酸之一的任意氨基酸、修饰氨基酸和/或氨基酸类似物。来源于:本文使用的术语“来源于”指从具体的分子或生物分离或用来自具体分子或生物的信息制成的组件。失活RS:本文使用的术语“失活RS”指经过突变使其不再可用氨基酸氨酰化它的天然关联tRNA的合成酶。正选择或筛选标记:本文使用的术语“正选择或筛选标记”指存在时,例如表达、激活等,可以从没有正选择标记的细胞中鉴定出具有正选择标记的细胞的标记。负选择或筛选标记:本文使用的术语“负选择或筛选标记”指指存在时,例如表达、激活等,可以鉴定不具有所需性质的细胞的标记(例如,与具有所需性质的细胞相比)。报道者:本文使用的术语“报道者”指可以用来选择感兴趣的系统的靶组件的组件。例如,报道者可包括荧光筛选标记(例如,绿色荧光蛋白)、发光标记(例如,萤火虫荧光素酶蛋白)、基于亲和力的筛选标记或可选择的标记基因,如his3、ura3、leu2、lys2、lacZ、β-gal/lacZ(β-半乳糖苷酶)、Adh(醇脱氢酶)等。真核生物:本文使用的术语“真核生物”指属于系统发育域真核生物,例如,动物(例如,哺乳动物、昆虫、爬虫、鸟等)、纤毛虫、植物(例如,单子叶植物、双子叶植物、藻类等)、真菌、酵母、鞭毛虫、微孢子虫、原生生物等的生物。非-真核生物:本文使用的术语“非-真核生物”指非真核生物。例如,属于真细菌(例如,大肠杆菌、嗜热栖热菌、嗜热脂肪芽孢杆菌等)系统发育域,或古细菌(例如,詹氏甲烷球菌、热自养甲烷杆菌、盐杆菌属如沃氏富盐菌和盐杆菌种NRC-1、闪烁古生球菌、激烈火球菌、堀越氏火球菌、敏捷气热菌等)系统发育域的非真核生物。抗体:本文使用的术语“抗体"包括但不限于基本上通过一个或多个免疫球蛋白基因编码的多肽,或其片段,它特异性结合并识别分析物(抗原)。例子包括多克隆、单克隆、嵌合和单链抗体等。本发明使用的术语“抗体”也包括免疫球蛋白的片段,包括Fab片段和表达文库包括噬菌体展示产生的片段。抗体结构和术语参见,例如,Paul,《基本免疫学》(FundamentalImmunology),第4版,1999,RavenPress,纽约。保守变体:术语“保守变体”指翻译组件,例如,保守变体O-tRNA或保守变体O-RS,其功能类似保守变体基于的组件,例如,O-tRNA或O-RS,但序列上有变化。例如,O-RS将氨酰化具有非天然氨基酸的互补O-tRNA或保守变体O-tRNA,虽然O-tRNA和保守变体O-tRNA并不具有相同序列。保守变体在序列中可具有例如,一种变化、两种变化、三种变化、四种变化或五种或更多的变化,只要保守变体与相应的O-tRNA或O-RS互补。选择或筛选剂:本文使用的术语“选择或筛选剂”指存在时,可以从群体中选择/筛选某种组分的试剂。例如,选择或筛选剂包括但不限于,例如,营养物、抗生素、光波长,抗体,表达的多核苷酸(例如,转录调节蛋白)等。选择剂可随,例如,浓度、强度等而不同。可检测物质:本文使用的术语“可检测物质”指当激活、改变、表达等时,可以从群体中选择/筛选某种组分的试剂。例如,可检测物质可以是化学试剂,例如,5-氟乳清酸(5-FOA),它在某些条件下,例如,URA3报道基因表达下,成为可检测的,例如,能够杀死表达URA3报道基因的细胞的有毒产物。附图简要描述图1,A、B和C组以图解说明通常用于扩展真核细胞例如,酿酒酵母遗传密码的正和负选择方案,A组图解说明报道基因的激活转录,它是通过GAL4中TAG密码子的琥珀抑制驱动的。条纹框指出DNA结合域,阴影框指出主要和隐蔽的激活域。B组说明报道基因的例子,例如,MaV203中的HIS3、LacZ、URA3。C组图解说明可以用于选择方案的质粒,例如,pEcTyrRS/tRNACUA和pGADGAL4xxTAG。图2说明在选择性培养基上第一代GAL4报道基因的EcTyrRS和tRNACUA依赖性表型。DB-AD是GAL4DNA结合域和激活域间的融合。DB-TAG-AD在合成接头DB和AD之间有代替酪氨酸密码子的TAG密码子。A5是EcTyrRS的失活型,其中活性位点中的5个残基突变为丙氨酸。图3,A和B组说明在选择性培养基上第二代GAL4报道基因的EcTyrRS和tRNACUA依赖性表型。条纹框指出DNA结合域,阴影框指出主要和隐蔽的激活域。A组说明GAL4中具有单个氨基酸突变的构建物。B组说明GAL4中具有两个氨基酸突变的构建物。图4A、B和C组说明有或不没有EcTyrRS的pGADGAL4(T44TAG、R110TAG),以及MaV203中的各种报道基因。A组显示在X-gal、-Ura或-Leu、-Trp存在下的结果。B组显示在不同浓度的3-AT存在下的结果。C组显示在不同百分数的5-FOA存在下的结果。图5A和B组说明ONPG水解各种GAL4突变体,例如,其中残基T44(A)和R110(B)是允许位点。A组说明用T44位点上各种类型的突变测定的ONPG水解。B组说明用Rl10位点上各种类型的突变测定的ONPG水解。‘GAL4’是转染了pCL1的MaV203,超出标度~600ONPG水解单位。‘没有’是分别用编码GAL4DB和GAL4AD的质粒转化MaV203。图6显示了活性EcTyrRS克隆的选择。将含有1:10的pEcTyrRS-tRNACUA:pA5-tRNACUA混合物的MaV203以103稀释度铺板于(-Leu,-Trp)平板(左)或(-Leu,-Trp,-His+50mM3-AT)平板(右),用XGAL覆盖处理。图7,A和B组。A组说明结合了酪氨酸的嗜热脂肪芽孢杆菌酪氨酰-tRNA合成酶的活性位点的立体视图。显示了突变的残基,并与来自大肠杆菌酪氨酰-tRNA合成酶Tyr37(嗜热脂肪芽孢杆菌TyrRS残基Tyr34)、Asn126(Asn123)、Asp182(Asp176)、Phe183(Phel77)和Leu186(Leu180)的残基相对应。B组说明非天然氨基酸例子(从左至右)对-乙酰基-L-苯丙氨酸(1)、对-苯甲酰基-L-苯丙氨酸(2)、对-叠氮基-L-苯丙氨酸(3)、0-甲基-L-酪氨酸(4)和对-碘代-L-酪氨酸(5)的结构式。图8,A、B、C和D组。A组说明可以用于选择/筛选正交tRNA的载体和报道构建物、真核细胞中的正交氨酰基合成酶或正交tRNA/RS对。B组说明含有GAL4反应型HIS3、URA3以及lacZ反应型报道者的酵母的表型,在选择培养基上,响应于活性(TyrRS)或失活(A5RS)氨酰基-tRNA合成酶。C组说明一个选择方案的例子,用于在真核细胞例如,UAA是非天然氨基酸的酿酒酵母中选择编码附加氨基酸的突变体合成酶。D组说明从具有对-乙酰基-L-苯丙氨酸的选择中分离酵母的表型。图9说明人超氧化物歧化酶(hSOD)(33TAG)HIS在酿酒酵母中的蛋白表达,它遗传编码非天然氨基酸,如图7B组中所示。图10,A-H组说明如图7B组中所示的含有非天然氨基酸(标为Y*)的胰蛋白酶肽VY*GSIK(SEQIDNO:87)的串联质谱分析。A组说明具有非天然氨基酸p-乙酰基-L-苯丙氨酸的胰蛋白酶肽(1)的串联质谱分析。B组说明具有非天然氨基酸对-苯甲酰基-L-苯丙氨酸的胰蛋白酶肽(2)的串联质谱分析。C组说明具有非天然氨基酸对-叠氮基-L-苯丙氨酸的胰蛋白酶肽(3)的串联质谱分析。D组说明具有非天然氨基酸邻-甲基-L-酪氨酸的胰蛋白酶肽(4)的串联质谱分析。E组说明具有非天然氨基酸对-碘代-L-酪氨酸的胰蛋白酶肽(5)的串联质谱分析。F组说明在Y*位置有色氨酸(W)的胰蛋白酶肽的串联质谱分析。G组说明在Y*位置有酪氨酸(Y)的胰蛋白酶肽的串联质谱分析。H组说明在Y*位置有亮氨酸(L)的胰蛋白酶肽的串联质谱分析。图11说明两种非天然氨基酸的例子,(1)对-炔丙基氧基苯丙氨酸和(2)对-叠氮基苯丙氨酸。图12,A、B和C组说明在图11中所示的非天然氨基酸1和2存在或不存在的情况下SOD的表达。A组说明Gelcode蓝染色实验。B组说明用抗-SOD抗体的Western印迹实验。C组说明用抗-6xHis抗体的Western印迹实验。图13,A、B和C组说明通过[3+2]环加成标记的蛋白质。A组说明合成的染料标记3-6。B组说明SOD和染料间的反应。C组说明凝胶内荧光扫描和Gelcode蓝染色。图14说明真核细胞,如在缺少尿嘧啶的SD培养基上,在图11中所示1或2的存在或不存在下用合成酶突变体转化酿酒酵母细胞的生长。图15,A和B组说明在Y*位置含有叠氮(Az)(A组)或炔(Al)(B组)非天然氨基酸的胰蛋白酶肽VY*GSIK(SEQIDNO:87)的串联质谱分析,显示它们的预计片段离子质量。箭头表明观察到各肽的b(蓝)和y(红)离子系列。图16图解说明将非天然氨基酸,如对-炔丙基氧基苯丙氨酸体内掺入生长多肽链中,以及通过该非天然氨基酸的[3+2]环加成反应,与有机小分子生物共轭。图17,A、B和C组说明用[3+2]环加成PEG化含有非天然氨基酸的蛋白质。A组说明炔丙基酰胺PEG在Cu(I)和磷酸盐缓冲液(PB)存在下与含有叠氮基氨基酸的蛋白质(例如,N3-SOD)的反应。B组说明通过凝胶分析蛋白质的PEG化。C组说明炔丙基酰胺PEG的合成。发明详述在真核细胞中超越遗传密码强加的化学限制直接遗传修饰蛋白结构的能力,将提供强大的分子工具,以探测或操纵细胞过程。本发明提供了在真核细胞中能扩展遗传编码的氨基酸数目的翻译组件。这些包括tRNAs(例如,正交tRNAs(O-tRNAs))、氨酰基-tRNA合成酶(例如,正交合成酶(O-RS))、O-tRNA/O-RS对和非天然氨基酸。一般地,能够有效表达并加工本发明的0-tRNA,它在真核细胞的翻译中发挥功能,但不被宿主的氨酰基-tRNA合成酶显著地氨酰化。响应于选择密码子,本发明的O-tRNA将非天然氨基酸在mRNA翻译期间输送到生长的多肽链上,该非天然氨基酸并不编码普通的二十种氨基酸的任意一种。本发明的O-RS在真核细胞中优选地氨酰化本发明具有非天然氨基酸的O-tRNA,但并不氨酰化任何胞质宿主的tRNA。而且,本发明氨酰基-tRNA合成酶的特异性使其接受非天然氨基酸而拒绝任何内源性氨基酸。包括例子O-RS或其部分氨基酸序列的多肽也是本发明的特征。此外,编码翻译组件。0-tRNA。O-RS及其部分的多核苷酸是本发明的特征。本发明也提供生产将非天然氨基酸用于真核细胞的所需翻译组件,如O-RS和或正交对(正交tRNA和正交氨酰基-tRNA合成酶)的方法,(以及由所述方法生产的翻译组件)。例如,来自大肠杆菌的酪氨酰-tRNA合成酶/tRNACUA对是本发明的O-tRNA/O-RS对。此外,本发明也表征在一个真核细胞中选择/筛选翻译组件的方法,一旦选择/筛选,就可以在不同真核细胞(没有用于选择/筛选的真核细胞)中使用那些组件。例如,生产用于真核细胞的翻译组件的选择/筛选方法可以在酵母,例如,酿酒酵母中进行,然后可以将那些选择组件用于另外的真核细胞,例如,另外的酵母细胞、哺乳动物细胞、昆虫细胞、植物细胞、真菌细胞等。本发明还提供了在真核细胞中生产蛋白质的方法,其中该蛋白含有非天然氨基酸。用本发明的翻译组件生产该蛋白。本发明也提供包括非天然氨基酸的蛋白质(和由本发明方法生产的蛋白)。感兴趣的蛋白或多肽也可包括翻译后修饰,例如,通过[3+2]环加成或亲核-亲电子反应加入修饰,这不能通过原核细胞进行,等。在某些实施方式中,本发明也包括用非天然氨基酸生产转录调节蛋白的方法(和由所述方法生产的蛋白)。包括含有非天然氨基酸的蛋白的组合物也是本发明的特征。用非天然氨基酸生产蛋白或多肽的试剂盒也是本发明的特征。正交氨酰基-tRNA合成酶(O-RS)为了将非天然氨基酸特异性参入到感兴趣的蛋白或多肽中,在真核细胞中,改变合成酶的底物特异性以致只有所需的非天然氨基酸,而非任意普通的20种氨基酸加入tRNA。如果正交合成酶是混杂的,它将导致在靶位上混合有天然和非天然氨基酸的突变蛋白质。本发明提供了对于具体的非天然氨基酸具有修饰的底物特异性的生产正交氨酰基-tRNA合成酶的组合物和方法。包括正交氨酰基-tRNA合成酶(O-RS)的真核细胞是本发明的特征。O-RS在真核细胞中优选地氨酰化具有非天然氨基酸的正交tRNA(O-tRNA)。在某些实施方式中,O-RS利用多于一个非天然氨基酸,例如,两个或更多,三个或更多等。因此,本发明的O-RS可具有用不同的非天然氨基酸优选地氨酰化O-tRNA的能力。通过选择哪一个非天然氨基酸或非天然氨基酸的组合放入细胞和/或通过选择放入细胞以掺入的不同量的非天然氨基酸提供了附加的对照水平。与天然氨基酸相比,本发明的O-RS对非天然氨基酸任选地具有一种或多种改进或增强的酶性质。这些性质包括,例如,与天然产生的氨基酸如,20种已知普通氨基酸之一相比,对非天然氨基酸较高km、较低km、较高kcat、较低kcat、较低kcat/km、较高kcat/km等。任选地,O-RS可通过包括O-RS的多肽和/或通过编码O-RS或其部分的多核苷酸提供给真核细胞。例如,如SEQIDNO.:3-35(例如,3-19、20-35或序列3-35的任何其它亚组)或其互补多核苷酸序列中任意一个所列多核苷酸序列编码O-RS或其部分。在另一实施例中,O-RS包含如SEQIDNO.:36-63(例如,36-47、48-63或36-63的任意其它亚组)和/或86,或它们的保守变异的氨基酸序列。参见例如,本文表5、6和8以及实施例6用于示例O-RS分子的序列。O-RS也可包含与天然产生的酪氨酰氨酰基-tRNA合成酶(TyrRS)(例如,SEQIDNO.:2中所列)的氨基酸序列例如,至少90%、至少95%、至少98%、至少99%、或甚至至少99.5%相同的氨基酸序列,包含A-E族的两种或多种氨基酸。A族包括与大肠杆菌TyrRS的Tyr37相对应位置上的缬氨酸、异亮氨酸、亮氨酸、甘氨酸、丝氨酸、丙氨酸、或苏氨酸;B族包括与大肠杆菌TyrRS的Asn126相对应位置上的天冬氨酸;C族包括与大肠杆菌TyrRS的Asp182相对应位置上的苏氨酸、丝氨酸、精氨酸、天冬酰胺或甘氨酸;D族包括与大肠杆菌TyrRS的Phe183相对应位置上的甲硫氨酸、丙氨酸、缬氨酸、或酪氨酸;E族包括与大肠杆菌TyrRS的Leu186相对应位置上的丝氨酸、甲硫氨酸、缬氨酸、半胱氨酸、苏氨酸、或丙氨酸。这些族的任何亚组组合是本发明的特征。例如,在一个实施方式中,O-RS具有两种或多种选自出现与大肠杆菌TyrRS的Tyr37相对应位置上的缬氨酸、异亮氨酸、亮氨酸、或苏氨酸;与大肠杆菌TyrRS的Asp182相对应位置上的苏氨酸、丝氨酸、精氨酸或甘氨酸;与大肠杆菌TyrRS的Phe183相对应位置上的甲硫氨酸、或酪氨酸;和与大肠杆菌TyrRS的Leu186相对应位置上的丝氨酸或丙氨酸的氨基酸。在另一实施方式中,O-RS包括两种或多种选自与大肠杆菌TyrRS的Tyr37相对应位置上的甘氨酸、丝氨酸或丙氨酸,与大肠杆菌TyrRS的Asn126相对应位置上的天冬氨酸,与大肠杆菌TyrRS的Asp182相对应位置上的天冬酰胺,与大肠杆菌TyrRS的Phe183相对应位置上的丙氨酸或缬氨酸,和/或与大肠杆菌TyrRS的Leu186相对应位置上的甲硫氨酸、缬氨酸、半胱氨酸或苏氨酸的氨基酸。也参见,例如,本文的表4、表6和表8。除了O-RS,本发明的真核细胞还可包括附加组分,例如,非天然氨基酸。真核细胞也包括正交tRNA(O-tRNA)(例如,来自非真核生物,如大肠杆菌、嗜热脂肪芽孢杆菌和/或类似物),其中O-tRNA识别选择密码子,并由O-RS优选地氨酰化具有非天然氨基酸的O-tRNA。细胞中也可存在包含编码感兴趣多肽的多核苷酸的核酸,其中多核苷酸包含O-tRNA识别的选择密码子,或它们中一种或多种的组合。在一个方面,O-tRNA介导非天然氨基酸掺入蛋白质中,其效率相当于包含SEQIDNO.:65所列多核苷酸序列或由其加工而来的tRNA效率的例如、至少45%、至少50%、至少60%、至少75%、至少80%、至少90%、至少95%或99%。在另一方面,O-tRNA包含SEQIDNO.:65和O-RS包含SEQIDNO.:36-63(例如,36-47、48-63或36-63的任何其它亚组)和/或86和/或它们的保守变异中任意一个所列多肽序列。也参见,例如,本文表5和实施例6中用于示例O-RS和O-tRNA分子的序列。在一个实施例中,真核细胞包含正交氨酰基-tRNA合成酶(O-RS)、正交tRNA(O-tRNA)、非天然氨基酸和含有编码感兴趣多肽的多核苷酸的核酸,其中多核苷酸包含O-tRNA识别的选择密码子。O-RS在真核细胞中优选地氨酰化具有非天然氨基酸的正交tRNA(O-tRNA),细胞在不存在非天然氨基酸的情况下生产感兴趣多肽,其产率相当于在非天然氨基酸存在下多肽产率的例如,小于30%、小于20%、小于15%、小于10%、小于5%、小于2.5%等。是本发明特征的生产O-RS的方法任选地包括从野生型合成酶的构架产生突变合成酶库,然后基于它们相对于普通的二十种氨基酸对非天然氨基酸的特异性选择突变RS。为了分离所述合成酶,选择方法是:(i)敏感的,因为来自首轮的所需合成酶的活性可以低,数目小;(ii)“可调的”,因为需要在不同的选择轮中改变选择严格性;和(iii)通用的,以使这些方法可用于不同非天然氨基酸。生产在真核细胞中优选地氨酰化具有非天然氨基酸的正交tRNA的正交氨酰基-tRNA合成酶(O-RS)的方法一般包括应用正选择的组合,然后负选择。在正选择中,在阳性标记的非必需位点引入选择密码子的抑制使真核细胞在正选择压力下存活。在非天然氨基酸存在下,存活细胞从而编码将非天然氨基酸加入正交抑制型tRNA的活性合成酶。在负选择中,在阴性标记的非必需位点引入选择密码子的抑制除去具有天然氨基酸特异性的合成酶。正和负选择中存活的细胞编码仅(或至少优选地)氨酰化(加入)具有非天然氨基酸的正交抑制型tRNA的合成酶。例如,该方法包括:(a)进行正选择,在非天然氨基酸存在下,第一种类生物真核细胞的群体,其中真核细胞各包含:i)氨酰基-tRNA合成酶(RS)文库的一员,ii)正交tRNA(O-tRNA),iii)编码正选择标记的多核苷酸,和iv)编码负选择标记的多核苷酸;其中在正选择中存活的细胞包含在非天然氨基酸存在下氨酰化正交tRNA(O-tRNA)的活性RS;和(b)将在正选择中存活的细胞在不存在非天然氨基酸的情况下进行负选择,以去除氨酰化具有天然氨基酸的O-tRNA的活性RS,从而提供优选地氨酰化具有非天然氨基酸的O-tRNA的O-RS。正选择标记可以是各种分子中的任意一种。在一个实施方式中,正选择标记是为生长提供营养添加剂的产品,并在缺少营养添加剂的培养基上进行选择。编码正选择标记的多核苷酸的例子包括但不限于,例如,基于补充细胞的氨基酸营养缺陷的报道基因、his3基因(例如,其中his3基因编码咪唑甘油磷酸脱氢酶,通过3-氨基三唑(3-AT))、ura3基因、leu2基因、lys2基因、lacZ基因、adh基因等检测。参见,例如,G.M.Kishore和D.M.Shah,(1988),作为除草剂的氨基酸生物合成抑制剂(Aminoacidbiosynthesisinhibitorsasherbicides),AnnualReviewofBiochemistry57:627-663。在一个实施方式中,通过邻-硝基苯基-β-D-半乳糖吡喃糖苷(ONPG)的水解检测lacZ产生。参见,例如,I.G.Serebriiskii和E.A.Golemis,(2000),lacZ在研究基因功能中的用途:用于酵母双杂交系统的β-半乳糖苷测定的评价(UsesoflacZtostudygenefunction:evaluationofbeta-galactosidaseassaysemployedintheyeasttwo-hybridsystem),AnalyticalBiochemistry285:1-15。附加的正选择标记包括,例如、荧光素酶、绿色荧光蛋白(GFP)、YFP、EGFP、RFP、抗生素抗性基因产物(例如,氯霉素乙酰基转移酶(CAT))、转录调节蛋白(例如,GAL4)等。编码正选择标记的多核苷酸任选地包含选择密码子。可以将编码正选择标记的多核苷酸可操作地连接到效应元件上。也可存在编码从效应元件调节转录的转录调节蛋白,并包含至少一个选择密码子的附加多核苷酸。通过非天然氨基酸氨酰化的O-tRNA将非天然氨基酸掺入转录调节蛋白中导致编码正选择标记的多核苷酸(例如,报道基因)的转录。例如,见图1A。选择密码子任选地位于编码转录调节蛋白的DNA结合域的多核苷酸内或基本上在其部分的附近。也可将编码负选择标记的多核苷酸可操作地连接到效应元件上,由转录调节蛋白介导转录。参见,例如,A.J.DeMaggio等,(2000),酵母分裂-杂交系统(Theyeastsplit-hybridsystem),MethodEnzymol.328:128-137;H.M.Shih等,(1996),阳性遗传选择破坏蛋白-蛋白相互作用:鉴定阻止与辅激活物CBP结合的CREB突变(Apositivegeneticselectionfordisruptingprotein-proteininteractions:identificationofCREBmutationsthatpreventassociationwiththecoactivatorCBP),Proc.Natl.Acad.Sci.U.S.A.93:13896-13901;M.Vidal,等,(1996),用酵母反向双杂交系统遗传表征哺乳动物蛋白-蛋白相互作用域(Geneticcharacterizationofamammalianprotein-proteininteractiondomainbyusingayeastreversetwo-hybridsystem),[评论],Proc.Natl.Acad.Sci.U.S.A.93:10321-10326;和M.Vidal,等,(1996),用反向双杂交和单杂交系统检测蛋白-蛋白解离和DNA-蛋白相互作用(Reversetwo-hybridandone-hybridsystemstodetectdissociationofprotein-proteinandDNA-proteininteractions),[评论],Proc.Natl.Acad.Sci.U.S.A.93:10315-10320。通过天然氨基酸氨酰化的O-tRNA将天然氨基酸掺入转录调节蛋白中导致负选择标记的转录。负选择标记任选地包含选择密码子。在一个实施方式中,本发明的正选择标记和/或负选择标记可包含至少两个选择密码子,它们每个或两个可含有至少两种不同的选择密码子或至少两种相同的选择密码子。转录调节蛋白是与核酸序列(例如,效应元件)结合(直接或间接)并调节可操作地连接于效应元件的序列的转录的分子。转录调节蛋白可以是转录激活蛋白(例如,GAL4、核激素受体、AP1、CREB、LEF/tcf家族成员、SMADs、VP16、SP1等),转录抑制蛋白(例如,核激素受体、Groucho/tle家族、Engrailed家族等)或可根据环境具有两种活性的蛋白(例如,LEF/tcf、同源框蛋白等)。效应元件一般是转录调节蛋白可识别的核酸序列或与转录调节蛋白一致作用的附加剂。转录调节蛋白另一例子是转录激活蛋白,GAL4(参见例如,图1A)。参见,例如,A.Laughon,等,(1984),鉴定两种通过酿酒酵母GAL4基因编码的蛋白(IdentificationoftwoproteinsencodedbytheSaccharomycescerevisiaeGAL4gene),Molecular&CellularBiology4:268-275;A.Laughon和R.F.Gesteland,(1984),酿酒酵母GAL4基因的一级结构(PrimarystructureoftheSaccharomycescerevisiaeGAL4gene),Molecular&CellularBiology4:260-267;L.Keegan,等,(1986),从真核调节蛋白的转录-激活功能分离DNA结合(SeparationofDNAbindingfromthetranscription-activatingfunctionofaeukaryoticregulatoryprotein),Science231:699-704;和M.Ptashne,(1988),真核转录激活蛋白是如何工作的(Howeukaryotictranscriptionalactivatorswork),Nature335:683-689。这个881个氨基酸的蛋白的N-末端147氨基酸形成特异地结合DNA序列的DNA结合域(DBD)。参见,例如,M.Carey,等,(1989),GAL4的氨基-末端片段与DNA结合为二聚体(Anamino-terminalfragmentofGAL4bindsDNAasadimer),J.Mol.Biol.209:423-432;和E.Giniger,等,(1985),GAL4,一种酵母阳性调节蛋白的特异性DNA结合(SpecificDNAbindingofGAL4,apositiveregulatoryproteinofyeast),Cell40:767-774.该DBD通过间插蛋白序列连接到C-末端的113氨基酸激活域(AD),当该激活域与DNA结合时可以激活转录。参见,例如,J.Ma和M.Ptashne,(1987),GAL4的缺失分析限定了两种转录激活节段(DeletionanalysisofGAL4definestwotranscriptionalactivatingsegments),Cell48:847-853:和J.Ma和M.Ptashne,(1987),GAL80识别GAL4羧基-末端的30个氨基酸(Thecarboxy-terminal30aminoacidsofGAL4arerecognizedbyGAL80),Cell50:137-142。通过将琥珀密码子置于,例如,含有GAL4的N-末端DBD和它的C-末端AD的单个多肽的N-末端DBD,通过O-tRNA/O-RS对的琥珀抑制可以与通过GAL4的转录激活连接(图1,A组)。GAL4激活的报道基因可以用于用基因进行的正和负选择(图1,B组)。用于负选择的培养基可以包含被负选择标记转化为可检测物质的选择剂或筛选剂。在本发明的一个方面,该可检测物质是有毒物质。编码负选择标记的多核苷酸可以是,例如,ura3基因。例如,可以将URA3报道基因置于含有GAL4DNA结合位点的启动子的控制之下。例如,当用选择密码子编码GAL4的多核苷酸翻译产生负选择标记时,GAL4激活URA3的转录。在含有5-氟乳清酸(5-FOA)的培养基上完成负选择,ura3基因的基因产物可将5-氟乳清酸转化成可检测物质(例如,杀死细胞的有毒物质)。参见,例如,J.D.Boeke,等,(1984),在酵母中正选择缺少乳清苷-5'-磷酸脱羧酶活性的突变体:5-氟乳清酸抗性(Apositiveselectionformutantslackingorotidine-5’-phosphatedecarboxylaseactivityinyeast:5-fluorooroticacidresistance),Molecular&GeneralGenetics197:345-346);M.Vidal,等,(1996),用酵母反向双杂交系统遗传表征哺乳动物蛋白-蛋白相互作用域(Geneticcharacterizationofamammalianprotein-proteininteractiondomainbyusingayeastreversetwo-hybridsystem),[评论],Proc.Natl.Acad.Sci.U.S.A.93:10321-10326;和M.Vidal,等,(1996),用反向双杂交和单杂交系统检测蛋白-蛋白解离和DNA-蛋白相互作用(Reversetwo-hybridandone-hybridsystemstodetectdissociationofprotein-proteinandDNA-proteininteractions),[评论],Proc.Natl.Acad.Sci.U.S.A.93:10315-10320.也参见图8C。如同正选择标记一样,负选择标记也可以是各种分子的任意一种。在一个实施方式中,正选择标记和/或负选择标记是在合适的反应物存在下发荧光或催化发光反应的多肽。例如,负选择标记包括但不限于,例如,荧光素酶、绿色荧光蛋白(GFP)、YFP、EGFP、RFP、抗生素抗性基因产物(例如、氯霉素乙酰基转移酶(CAT))、lacZ基因产物、转录调节蛋白等。在本发明的一个方面,通过荧光激活细胞分选(FACS)或通过发光检测正选择标记和/或负选择标记。在另一实施例中,正选择标记和/或负选择标记包含基于亲和力的筛选标记。同一多核苷酸可编码正选择标记和负选择标记。选择/筛选严格性的附加水平也可用于本发明方法。该选择或筛选严格性可以在生产O-RS方法的一或两步上不同。这可包括,例如,改变编码正和/或负选择标记的多核苷酸中效应元件的量,将数量不等的失活合成酶加入到步骤中的一步或两步,改变使用的选择/筛选剂的量等。也可以进行附加轮的正和/或负选择。选择或筛选也可包括一种或多种正或负选择或筛选,包括,例如,氨基酸通透性的改变、翻译效率的改变、翻译忠实性的改变等。一般地,一种或多种改变是基于包含或编码用于生产蛋白的正交tRNA-tRNA合成酶对的组件的一种或多种多核苷酸中的突变。可以用模型富集研究从过量的失活合成酶中快速选择活性合成酶。可以进行正和/或负模型选择研究。例如,将含有可能的活性氨酰基-tRNA合成酶的真核细胞与过量不同倍数的失活氨酰基-tRNA合成酶混合。比率比较在非选择性培养基中生长的细胞之间进行,例如,X-GAL覆盖测定,和在选择性培养基(例如,不存在组氨酸和/或尿嘧啶的情况下)中生长并能够存活的细胞中进行,例如,X-GAL分析测定。对于负模型选择,将可能的活性氨酰基-tRNA合成酶与过量不同倍数的失活氨酰基-tRNA合成酶混合,用负选择物质,例如,5-FO进行选择。一般地,RS文库(例如,突变体RS文库)含有来自如来自非真核生物的至少一种氨酰基-tRNA合成酶(RS)的RS。在一个实施方式中,RS文库来自失活RS,例如,其中通过,例如在合成酶的活性位点、在合成酶的编辑机制位点、在不同位点通过结合合成酶的不同域等方式突变活性RS产生失活RS。例如,将RS的活性位点残基突变为,例如,丙氨酸残基。将编码丙氨酸突变的RS的多核苷酸用作模板,以将丙氨酸残基诱变为所有20个氨基酸。选择/筛选突变体RS文库以生产O-RS。在另一实施方式中,失活RS包含氨基酸结合口袋,用一种或多种不同氨基酸取代一种或多种含有结合口袋的氨基酸。在一个实施例中,取代的氨基酸用丙氨酸取代。任选地,将编码丙氨酸突变的RS的多核苷酸用作模板,以将丙氨酸残基诱变为所有20个氨基酸,并进行筛选/选择。生产O-RS的方法还可包括用各种本领域已知的诱变技术生产RS文库。例如,可通过位点特异性突变、随机点突变、同源重组、DNA改组或其它递归诱变方法、嵌合构建或它们的任意组合产生突变RS。例如,可以从两种或多种其它,例如较小、变化较少的“亚文库”产生突变体RS文库。一旦合成酶进行正和负选择/筛选策略,就可进一步诱变这些合成酶。例如,可以分离编码O-RS的核酸;可从该核酸产生一组编码突变的O-RS的多核苷酸(例如,通过随机诱变,位点特异性诱变,重组或它们的任意组合);和,可以重复进行这些单独步骤或这些步骤的组合,直到获得优选地氨酰化具有非天然氨基酸的O-tRNA的突变O-RS。在本发明的一个方面,这些步骤至少进行两次。可以在WO2002/086075,题为“用于生产正交tRNA-氨酰基tRNA合成酶对的方法和组合物”中找到生产O-RS的更多细节。也参见,Hamano-Takaku等,(2000)突变大肠杆菌酪氨酰-tRNA合成酶利用非天然氨基酸重氮酪氨酸比酪氨酸更有效(AmutantEscherichiacoliTyrosyl-tRNASynthetaseutilizestheUnnaturalAminoAcidAzatyrosineMoreEfficientlythanTyrosine),JournalofBiologicalChemistry,275(51):40324-40328;Kiga等(2002),在真核翻译中将非天然氨基酸位点特异性掺入蛋白中的工程大肠杆菌酪氨酰-tRNA合成酶及其在麦胚无细胞体系中的应用(AnengineeredEscherichiacolityrosyl-tRNAsynthetaseforsite-specificincorporationofanunnaturalaminoacidintoproteinsineukaryotictranslationanditsapplicationinawheatgermcellfreesystem),PNAS99(15):9715-9723;和Francklyn等,(2002),氨酰基-tRNA合成酶:变化的翻译剧场中多才多艺的演员(Aminoacyl-tRNAsynthetases:Versatileplayersinthechangingtheateroftraslation);RNA,8:1363-1372。正交tRNAs本发明提供了包括正交tRNA(O-tRNA)的真核细胞。该正交tRNA介导非天然氨基酸体内掺入含有O-tRNA识别的选择密码子的多核苷酸编码的蛋白质中。在某些实施方式中,本发明的O-tRNA介导非天然氨基酸掺入蛋白质中,其效率相当于含有SEQIDNO.:65所列多核苷酸序列或在该序列的细胞中加工的tRNA效率的例如,至少40%、至少45%、至少50%、至少60%、至少75%、至少80%或甚至90%或更高。参见本文的表5。本发明O-tRNA的例子是SEQIDNO.:65(参见本文的实施例6和表5)。SEQIDNO.:65是一个剪接/加工前的转录子,它在细胞中被任选地加工,例如,采用细胞的内源性剪切和加工机器,修饰形成活性O-tRNA。一般地,群体所述的剪接前转录子在细胞中形成群体活性tRNA(活性tRNA可以是一种或多种活性形式)。本发明也包括O-tRNA的保守变异和它的细胞加工产物。例如,O-tRNA的保守变异包括功能类似SEQIDNO.:65的O-tRNA并维持tRNAL-型结构如加工形式,但不具有相同序列(不同于野生型tRNA分子)的那些分子。一般地,本发明O-tRNA是可循环的O-tRNA,因为O-tRNA可在体内再氨酰化,响应于选择密码子再介导非天然氨基酸掺入多核苷酸编码的蛋白质中。tRNA在真核生物中而不在原核生物中的转录是通过RNA聚合酶III进行的,该聚合酶对可在真核细胞中转录的tRNA结构基因的一级序列作出限制。此外,在真核细胞中,需要将tRNA从核中输出到转录它们的地方即胞质,以在翻译中发挥作用。编码本发明O-tRNA的核酸或它的互补多核苷酸也是本发明的特征。在本发明的一个方面,编码本发明O-tRNA的核酸包括内部启动子序列,例如,A框(例如,TRGCNNAGY)和B框(例如,GGTTCGANTCC,SEQIDNO:88)。本发明O-tRNA也可以是转录后修饰的。例如,在真核生物中tRNA基因的转录后修饰包括用RNA酶P和3'-核酸内切酶分别去除5'-和3'-侧翼序列。加入3'-CCA序列也是真核生物中tRNA基因的转录后修饰。在一个实施方式中,通过将第一种类的真核细胞的群体进行负选择获得O-tRNA,其中真核细胞含有tRNA文库的一员。负选择清除了含有被对真核细胞内源性氨酰基-tRNA合成酶(RS)氨酰化的tRNA文库的一员的细胞。这提供了与第一种类的真核细胞正交的tRNA库。另外,在上述将非天然氨基酸掺入多肽中的方法或与其它方法结合中,可以使用反式翻译系统。该系统包括存在于大肠杆菌称为tmRNA的分子。该RNA分子结构上涉及丙氨酰tRNA,被丙氨酰合成酶氨酰化。tmRNA和tRNA之间的差异是反密码子环被特殊的大序列代替。该序列允许核糖体用tmRNA内编码的开放阅读框作为模板在被中止的序列上继续翻译。在本发明中,可以产生用正交合成酶优选地氨酰化并载有非天然氨基酸的正交tmRNA。通过借助该系统转录基因,核糖体在特异性位点中止工作;将非天然氨基酸引入该位点,然后用正交tmRNA内编码的序列继续翻译。生产重组正交tRNA的其它方法可以在,例如,国际专利申请WO2002/086075,题为“用于生产正交tRNA-氨酰基tRNA合成酶对的方法和组合物(MethodsandcompositionsfortheproductionoforthogonaltRNA-aminoacyltRNAsynthetasepairs)”中找到。也参见Forster等,(2003)通过翻译从头设计的遗传密码程序化拟肽合成酶(Programmingpeptidomimeticsynthetasesbytranslatinggeneticcodesdesigneddenovo)PNAS100(11):6353-6357;和Feng等,(2003),通过单氨基酸改变扩展tRNA合成酶的tRNA识别(ExpandingtRNArecognitionofatRNAsynthetasebyasingleaminoacidchange),PNAS100(10):5676-5681。正交tRNA和正交氨酰基-tRNA合成酶对正交对由O-tRNA,例如,抑制型tRNA、移码tRNA等和O-RS组成。O-tRNA没有被内源性合成酶酰化,不能介导非天然氨基酸掺入含有O-tRNA体内识别的选择密码子的多核苷酸编码的蛋白质中。在真核细胞中,O-RS识别O-tRNA并优选地氨酰化具有非天然氨基酸的O-tRNA。本发明也包括生产正交对的方法以及由此方法生产的正交对,以及用于真核细胞的正交对组合物。在真核细胞中,多个正交tRNA/合成酶对的产生可以允许用不同密码子同时掺入多个非天然氨基酸。在真核细胞中,可以通过用低效率跨种氨酰化从不同生物输入对,如无义抑制对,来生产正交O-tRNA/O-RS对。在真核细胞中,O-tRNA和O-RS有效地表达和加工,O-tRNA从核中有效地输出至胞质。例如,一个所述对是来自大肠杆菌的酪氨酰-tRNA合成酶/tRNACUA对(参见,例如,H.M.Goodman,等,(1968),Nature217:1019-24;和D.G.Barker,等,(1982),FEBSLetters150:419-23)。当两者都在酿酒酵母的胞质中表达时,大肠杆菌酪氨酰-tRNA合成酶有效地氨酰化其关联大肠杆菌tRNACUA,但不氨酰化酿酒酵母tRNA。参见,例如,H.Edwards和P.Schimmel,(1990),Molecular&CellularBiology10:1633-41;和H.Edwards,等,(1991),PNASUnitedStatesofAmerica88:1153-6。此外,大肠杆菌酪氨酰tRNACUA是酿酒酵母氨酰基-tRNA合成酶的差底物(参见,例如,V.Trezeguet,等,(1991),Molecular&CellularBiology11:2744-51),但是在酿酒酵母的蛋白翻译中有效发挥功能。参见,例如,H.Edwards和P.Schimmel,(1990)Molecular&CellularBiology10:1633-41;H.Edwards,等,(1991),PNASUnitedStatesofAmerica88:1153-6;和V.Trezeguet,等,(1991),Molecular&CellularBiology11:2744-51。而且,大肠杆菌TyrRS不具有校正连接到tRNA的非天然氨基酸的编辑机制。O-tRNA和O-RS可以是各种生物中天然产生的或可以是天然产生的tRNA和/或RS突变获得的,它产生了tRNA文库和/或RS文库。参见本文中题为“来源和宿主”的部分。在各种实施方式中,O-tRNA和O-RS来自至少一种生物。在另一实施方式中,O-tRNA来自第一生物中天然产生或突变的天然产生tRNA,O-RS来自第二生物中天然产生或突变的天然产生RS。在一个实施方式中,第一和第二非真核生物是相同的。另外,第一和第二非真核生物可以是不同的。参见本文中题为“正交氨酰基-tRNA合成酶”和“O-tRNA”的部分中生产O-RS和0-tRNA的方法。也参见国际专利申请WO2002/086075,题为“生产正交tRNA-氨酰基tRNA合成酶对的方法和组合物”(MethodsandcompositionsfortheproductionoforthogonaltRNA-aminoacyltRNAsynthetasepairs)。保真度、效率和产率保真度指将所需分子,例如,非天然氨基酸或氨基酸掺入生长的多肽中所需位置的准确度。本发明翻译组件响应于选择密码子,以高保真度将非天然氨基酸掺入蛋白质中。例如,用本发明的组件,将所需非天然氨基酸掺入生长多肽链中所需位置的效率(例如,响应于选择密码子)相当于将不需要的特异性天然氨基酸掺入生长多肽链中所需位置的效率的例如,大于75%、大于85%、大于95%或甚至大于99%或更高。效率也可指与相应的对照相比,O-RS氨酰化具有非天然氨基酸的O-tRNA的程度。可以通过本发明O-RS的效率对其进行限定。在本发明的某些实施方式中,将一个O-RS与另一O-RS相比。例如,本发明O-RS氨酰化具有非天然氨基酸的O-tRNA的效率相当于具有SEQIDNO.:86或45所列氨基酸序列(或表5中另一特异性RS)的O-RS氨酰化O-tRNA效率的例如,至少40%、至少50%、至少60%、至少75%、至少80%、至少90%、至少95%或甚至99%或更高。在另一实施方式中,本发明的O-RS氨酰化具有非天然氨基酸的O-tRNA的效率比O-RS氨酰化具有天然氨基酸的O-tRNA的效率高至少10倍,至少20倍,至少30倍等。用本发明的翻译组件,含有非天然氨基酸的感兴趣多肽的产率是从多核苷酸缺少选择密码子的细胞中获得天然产生的感兴趣多肽的产率的例如,至少5%、至少10%、至少20%、至少30%、至少40%、50%或更高。在另一方面,细胞在不存在非天然氨基酸的情况下生产感兴趣多肽的产率是在非天然氨基酸存在下生产多肽产率的例如,小于30%、小于20%、小于15%、小于10%、小于5%、小于2.5%等。来源和宿主生物本发明的正交翻译组件一般来自非真核生物,用于真核细胞或翻译系统。例如,正交O-tRNA可以来自非真核生物,例如,真细菌,如大肠杆菌、嗜热栖热菌、嗜热脂肪芽孢杆菌等,或古细菌,如詹氏甲烷球菌、热自养甲烷杆菌、盐杆菌属如沃氏富盐菌和盐杆菌种NRC-1、闪烁古生球菌、激烈火球菌、堀越氏火球菌、敏捷气热菌等,正交O-RS可来自非真核生物,例如,真细菌,如大肠杆菌、嗜热栖热菌、嗜热脂肪芽孢杆菌等,或古细菌,如詹氏甲烷球菌、热自养甲烷杆菌、盐杆菌属如沃氏富盐菌和盐杆菌种NRC-1、闪烁古生球菌、激烈火球菌、堀越氏火球菌、敏捷气热菌等。另外,也可使用真核来源,例如,植物、藻类、原生生物、真菌、酵母、动物(例如,哺乳动物、昆虫、节肢动物等)等,例如,其中组件与感兴趣的的细胞或翻译系统正交,或将它们修饰(例如,突变)为与细胞或翻译系统正交。O-tRNA/O-RS对的单独组件可以来自相同生物或不同生物。在一个实施方式中,O-tRNA/O-RS对来自相同生物。例如,O-tRNA/O-RS对可以来自大肠杆菌的酪氨酰-tRNA合成酶/tRNACUA对。另外,O-tRNA/O-RS对的O-tRNA和O-RS任选地来自不同生物。可以在真核细胞中选择或筛选和/或使用正交O-tRNA、O-RS或O-tRNA/O-RS对,以用非天然氨基酸生产多肽。真核细胞可以来自各种来源的任意一种,例如,植物(例如,高等植物,如单子叶植物或双子叶植物)、藻类、原生生物、真菌、酵母(例如,酿酒酵母)、动物(例如,哺乳动物、昆虫、节肢动物等)等。具有本发明翻译组件的真核细胞组合物也是本发明的特征。本发明也提供在一种类中有效筛选,以任选地用于该种类和/或第二种类(任选地,无附加选择/筛选)。例如,在一种类,如容易操纵的种类(如酵母细胞等)中选择或筛选O-tRNA/O-RS的组件,并引入第二真核生物,例如,植物(例如,高等植物,如单子叶植物或双子叶植物)、藻类、原生生物、真菌、酵母、动物(例如,哺乳动物、昆虫、节肢动物等)等,用于将非天然氨基酸体内掺入第二种类中。例如,可以将酿酒酵母(S.cerevisiae)选作第一种真核生物,因为它是单细胞的,具有快速的世代时间,并且已相当良好地鉴定了它的遗传学特征。参见,例如,D.Burke,等,(2000)《酵母遗传学方法》(MethodsinYeastGenetics),ColdSpringHarborLaboratoryPress,ColdSpringHarbor,NY。而且,因为真核生物的翻译机器是高度保守的(参见,例如,(1996)《翻译控制》(TranslationalControl),ColdSpringHarborLaboratoryPress,ColdSpringHarbor,NY;Y.Kwok和J.T.Wong,(1980),用氨酰基-tRNA合成酶作为系统发育探针确定红皮盐杆菌和真核生物之间的进化关系(EvolutionaryrelationshipbetweenHalobacteriumcutirubrumandeukaryotesdeterminedbyuseofaminoacyl-tRNAsynthetasesasphylogeneticprobes),CanadianJournalofBiochemistry58:213-218;和(2001)核糖体(TheRibosome),ColdSpringHarborLaboratoryPress,ColdSpringHarbor,NY),可以将发现于酿酒酵母用于掺入非天然氨基酸的aaRS基因引入高等真核生物中,与关联tRNA合作使用(参见,例如,K.Sakamoto,等,(2002)将非天然氨基酸位点特异性掺入哺乳动物细胞的蛋白质中(Site-specificincorporationofanunnaturalaminoacidintoproteinsinmammaliancells),NucleicAcidsRes.30:4692-4699;和C.Kohrer,等,(2001),将琥珀和赭石抑制型tRNAs输入哺乳动物细胞:将氨基酸类似物位点特异性地插入蛋白质中的通用方法(ImportofamberandochresuppressortRNAsintomammaliancells:ageneralapproachtosite-specificinsertionofaminoacidanaloguesintoproteins),Proc.Natl.Acad.Sci.U.S.A.98:14310-14315)以掺入非天然氨基酸。在一个实施例中,本文所述的在第一种类中生产O-tRNA/O-RS的方法还包括将编码O-tRNA的核酸和编码O-RS的核酸引入第二种类(例如,哺乳动物、昆虫、真菌、藻类、植物等)真核细胞中。在另一实施例中,通过在真核细胞中优选地氨酰化具有非天然氨基酸的正交tRNA来生产正交氨酰基-tRNA合成酶(O-RS)的方法包括:(a)在非天然氨基酸存在下对第一种类(例如,酵母等)真核细胞的群体进行正选择。各真核细胞包含:i)氨酰基-tRNA合成酶(RS)文库的一员,ii)正交tRNA(O-tRNA),iii)编码正选择标记的多核苷酸,和iv)编码负选择标记的多核苷酸。在正选择下存活的细胞包含在非天然氨基酸存在下氨酰化正交tRNA(O-tRNA)的活性RS。将在正选择下存活的细胞在不存在非天然氨基酸的情况下进行负选择,以去除氨酰化具有天然氨基酸的O-tRNA的活性RS。这提供了优选地氨酰化具有非天然氨基酸的O-tRNA的O-RS。将编码O-tRNA的核酸和编码O-RS的核酸(或O-tRNA和/或O-RS的组件)引入第二种类,例如,哺乳动物、昆虫、真菌、藻类、植物和/或类似物)的真核细胞。一般地,通过将第一种类真核细胞的群体进行负选择而获得O-tRNA,其中真核细胞包含tRNA文库的一员。负选择清除了被对真核细胞内源性氨酰基-tRNA合成酶(RS)氨酰化的tRNA文库的一员的细胞,这提供了与第一种类和第二种类真核细胞正交的tRNA库。选择密码子本发明的选择密码子扩展了蛋白质生物合成机器的遗传密码子构架。例如,选择密码子包括,例如,唯一的三碱基密码子,无义密码子如终止密码子,例如,琥珀密码子(UAG)、乳白密码子(UGA),非天然密码子,至少一个四碱基密码子,罕用密码子等。可以将许多选择密码引入所需基因,例如,一个或多个、两个或多个、多余三个等。一旦基因可以包括给定选择密码子的多个拷贝,就可以包括多个不同的选择密码子,或它们的任意组合。在一个实施方式中,方法包括在真核细胞中用选择密码子中的终止密码子体内掺入非天然氨基酸。例如,生产了识别终止密码子,如UAG的O-tRNA,O-RS用所需非天然氨基酸将O-tRNA氨酰化。天然产生的宿主的氨酰基-tRNA合成酶并不识别该O-tRNA。可用常规的定位诱变在感兴趣多肽的感兴趣的位点引入终止密码子,例如,TAG。参见,例如,Sayers,J.R.,等(1988),在基于硫代磷酸的寡核苷酸-定向诱变中的5',3'核酸外切酶(5',3'Exonucleaseinphosphorothioate-basedoligonucleotide-directedmutagenesis),NucleicAcidsRes.791-802。当O-RS、O-tRNA和编码感兴趣多肽的核酸在体内结合时,响应于UAG密码子掺入非天然氨基酸,产生在指定位置含有非天然氨基酸的多肽。非天然氨基酸的体内掺入可以在不显著扰乱真核宿主细胞的情况下完成。例如,因为UAG密码子的抑制效率取决于O-tRNA,如琥珀抑制型tRNA和真核释放因子(例如,eRF)(它结合到终止密码子上并起始生长肽从核糖体中释放)之间的竞争,所以可以通过,例如增加O-tRNA如抑制型tRNA的表达水平来调节抑制效率。选择密码子也包括扩展密码子,例如,四个或多个碱基的密码子,如四、五、六或更多碱基密码子。四碱基密码子的例子包括,例如,AGGA、CUAG、UAGA、CCCU等。五碱基密码子的例子包括,例如,AGGAC、CCCCU、CCCUC、CUAGA、CUACU、UAGGC等。本发明的特征包括根据移码抑制使用扩展密码子。四个或多个碱基密码子可以插入,例如,相同蛋白的一个或多个非天然氨基酸中。例如,在具有反密码子环,如至少8-10个核苷酸反密码子环的突变0-tRNA,如特殊的移码抑制型tRNA的存在下,可以将四个或多个碱基密码子阅读为单个氨基酸。在其它实施方式中,该反密码子环可以解码,例如,至少四碱基密码子、至少五碱基密码子、或至少六碱基密码子或更多。因为有256种可能的四碱基密码子,所以在同一细胞中可以用四个或多个碱基密码子编码多个非天然氨基酸。参见,Anderson等,(2002)探索密码子和反密码子大小的限度(ExploringtheLimitsofCodonandAnticodonSize),ChemistryandBiology,9:237-244;Magliery,(2001)扩展遗传密码:选择四碱基密码子的有效抑制剂并用大肠杆菌中的文库方法鉴定“不稳定的”四碱基密码子(ExpandingtheGeneticCode:SelectionofEfficientSuppressorsofFour-baseCodonsandIdentificationof"Shifty"Four-baseCodonswithaLibraryApproachinEscherichiacoli),J.Mol.Biol.307:755-769。例如,用体外生物合成方法四碱基密码子已用于将非天然氨基酸掺入蛋白质中。参见,例如,Ma等,(1993)Biochemistry,32:7939;和Hohsaka等,(1999)J.Am.Chem.Soc.,121:34。将CGGG和AGGU用于通过两种化学酰化的移码抑制型tRNA将2-萘基丙氨酸和赖氨酸的NBD衍生物体外同时掺入链霉抗生物素蛋白中,参见,例如,Hohsaka等,(1999)J.Am.Chem.Soc.,121:12194。在体内研究中,Moore等检测了tRNALeu衍生物与NCUA反密码子抑制UAGN密码子(N可以是U、A、G或C)的能力,发现tRNALeu用UCUA反密码子可以解码四联体UAGA,效率为13至26%,在0或-1框中解码少。参见,Moore等,(2000)J.Mol.Biol.,298:195。在一个实施方式中,本发明可使用基于罕用密码子或无义密码子的扩展密码子,它们可以降低在其它不需要位点上的错义连读和移码抑制。对于一个给定系统来说,选择密码子也可包括天然三碱基密码子之一,其中内源性系统并不使用(或很少使用)天然碱基密码子。例如,这包括缺少识别天然三碱基密码子的tRNA的系统和/或三碱基密码子是罕用密码子的系统。选择密码子任选地包括非天然碱基对。这些非天然碱基对还扩展了现有的遗传字母表。一个额外碱基对可以使三联体密码子的数目从64增加到125。第三个碱基对的性质包括稳定和选择性碱基配对、聚合酶以高保真度有效酶促掺入DNA,新生非天然碱基对合成后有效连续的引物延伸。可以适用于方法和组合物的非天然碱基对的描述包括,例如,Hirao,等,(2002)用于将氨基酸类似物掺入蛋白质中的非天然碱基对,NatureBiotechnology,20:177-182。其它相关出版物见以下所列。对于体内使用,非天然核苷是膜可透过的,将其磷酸化形成相应的三磷酸盐。此外,增加的遗传信息是稳定的,且不会被细胞酶所破坏。之前Benner和其他人所做的努力利用了与典范的Watson-Crick对不同的氢键模式,其中最制得注意的例子是异-C:异-G对。参见,例如,Switzer等,(1989)J.Am.Chem.Soc.,111:8322;和Piccirilli等,(1990)Nature,343:33;Kool,(2000)Curr.Opin.Chem.Biol.,4:602。通常,这些碱基与天然碱基有某种程度的错配,不能酶促复制。Kool和同事们证明碱基间的疏水堆积相互作用可以替换氢键,以驱使碱基对形成。参见,Kool,(2000)Curr.Opin.Chem.Biol.,4:602;和Guckian和Kool,(1998)Angew.Chem.Int.Ed.Engl.,36,2825。在开发满足上面所有要求的非天然碱基对的努力中,Schultz、Romesberg和同事们系统地合成并研究了一系列非天然疏水碱基。发现PICS:PICS自身-对比天然碱基对更稳定,大肠杆菌DNA聚合酶I的克列诺片段(KF)可将其有效掺入DNA。参见,例如,McMinn等,(1999)J.Am.Chem.Soc.,121:11586;和Ogawa等,(2000)J.Am.Chem.Soc.,122:3274。KF可以以足够于生物功能的效率和选择性合成3MN:3MN自身-对。参见,例如,Ogawa等,(2000)J.Am.Chem.Soc.,122:8803。然而,两种碱基都作为链终止剂,用于进一步复制。最近发现,突变DNA聚合酶可以用于复制PICS自身对。此外,可以复制7AI自身对。参见,例如,Tae等,(2001)J.Am.Chem.Soc.,123:7439。也开发了新的金属碱基对Dipic:Py,在结合Cu(II)时形成稳定对。参见,Meggers等,(2000)J.Am.Chem.Soc.,122:10714。因为扩展密码子和非天然密码子本质上是与天然密码子正交的,所以本发明方法可以利用该性质为它们产生正交tRNA。翻译旁路系统也可用于在所需多肽中掺入非天然氨基酸。在翻译旁路系统中,将大序列插入基因中,但不翻译成蛋白。该序列包含作为诱导核糖体跳过该序列并继续进行插入的下游翻译的提示的结构。非天然氨基酸本文使用的非天然氨基酸指任何氨基酸、修饰氨基酸,或不是硒半胱氨酸和/或吡咯赖氨酸的氨基酸类似物,下面是20种遗传编码的α-氨基酸:丙氨酸,精氨酸,天冬酰胺,天冬氨酸,半胱氨酸,谷氨酰胺,谷氨酸,甘氨酸,组氨酸,异亮氨酸,亮氨酸,赖氨酸,甲硫氨酸,苯丙氨酸,脯氨酸,丝氨酸,苏氨酸,色氨酸,酪氨酸,缬氨酸。式I说明α-氨基酸的遗传结构:非天然氨基酸一般是任何具有式I的结构,其中R基团是除了20种天然氨基酸中使用的一种以外的任何取代基。参见例如,L.Stryer的《生物化学》,第三版,1988,FreemanandCompany,NewYork中二十种天然氨基酸的结构。需要注意的是,本发明的非天然氨基酸可以是除上述二十种α-氨基酸外的天然产生的化合物。因为本发明的非天然氨基酸一般与侧链中的天然氨基酸不同,非天然氨基酸与其它氨基酸,例如,天然或非天然氨基酸以天然产生的蛋白质中形成的相同方式形成酰胺键。然而,非天然氨基酸具有使其与天然氨基酸不同的侧链基团。例如,式I中的R任选地包括烷基-、芳基-、酰基-、酮基-、叠氮基-、羟基-、肼、氰基-、卤素-、酰肼、链烯基、炔基、醚、硫醇、硒-、磺酰基-、硼酸、硼酸盐、磷酰基、膦酰基、膦、杂环、烯酮、亚胺、醛、酯、硫代酸、羟胺、胺等,或它们的任意组合。其它感兴趣的的非天然氨基酸包括但不限于,含有可光敏化的交联剂的氨基酸、自旋标记的氨基酸、荧光氨基酸、金属结合氨基酸、含金属的氨基酸、放射性氨基酸、具有新官能团的氨基酸、与其他分子共价或非共价相互作用的氨基酸、光笼蔽和/或可光致异构的氨基酸、含有生物素或生物素-类似物氨基酸、含酮氨基酸、含有聚乙二醇或聚醚的氨基酸、重原子取代的氨基酸、可化学切割或可光切割的氨基酸、与天然氨基酸相比具有延长侧链的氨基酸(例如,聚醚或长链烃,如大于约5、大于约10个碳等)、含有碳-连接糖的氨基酸、具有氧化还原活性的氨基酸、含有氨基硫代酸的氨基酸和含有一种或多种有毒部分的氨基酸。在一些实施方式中,非天然氨基酸具有可光敏化的交联剂,它用于,例如,将蛋白质连接到固体支持物上。在一个实施方式中,非天然氨基酸具有附着于氨基酸侧链的糖部分(例如,糖基化氨基酸)和/或其它碳水化合物修饰。除含有新侧链的非天然氨基酸以外,非天然氨基酸也任选地包含修饰的骨架结构,例如,式II和III的结构所示:其中Z一般包括OH、NH2、SH、NH-R'或S-R';X和Y可以相同或不同,它们一般包括S或O,R和R'是任选地相同或不同,它们一般选自上述针对具有式I的非天然氨基酸R基团成分的相同列表以及氢。例如,本发明非天然氨基酸任选地包括在氨基或羧基上的取代,如式II和III所示。该类非天然氨基酸包括但不限于例如,具有与普通的二十种然氨基酸相应的侧链或非天然侧链的α-羟酸、α-硫代酸α-氨基硫代羧酸酯。此外,在α-碳上的取代任选地包括L、D或α-α-双取代氨基酸,如D-谷氨酸、D-丙氨酸、D-甲基-O-酪氨酸、氨基丁酸等。其它结构替代物包括环氨基酸,如脯氨酸类似物,以及3、4、6、7、8和9元环脯氨酸类似物,β和γ氨基酸,如取代的β-丙氨酸和γ-氨基丁酸。例如,很多非天然氨基酸是基于天然氨基酸的,如酪氨酸、谷氨酰胺、苯丙氨酸等。酪氨酸类似物包括对位取代的酪氨酸、邻位取代的酪氨酸和间位取代的酪氨酸,其中取代的酪氨酸包括,例如,酮基(例如乙酰基)、苯甲酰基、氨基、肼、羟胺、硫醇基、羧基、异丙基、甲基、C6-C20直链或支链烃、饱和或不饱和烃、0-甲基、聚醚、硝基、炔基等。此外,也考虑到多取代芳环。本发明的谷氨酰胺类似物包括但不限于,α-羟基衍生物、γ-取代衍生物、环状衍生物和酰胺取代的谷氨酰胺衍生物。苯丙氨酸类似物的例子包括但不限于,对位取代的苯丙氨酸、邻位取代的苯丙氨酸和间位取代的苯丙氨酸,其中取代基包括,例如,羟基、甲氧基、甲基、烯丙基、醛、叠氮基、碘、溴、酮基(例如乙酰基)、苯甲酰基、炔基等。非天然氨基酸的具体例子包括但不限于、对-乙酰基-L-苯丙氨酸、对-炔丙基氧基苯丙氨酸、0-甲基-L-酪氨酸、L-3-(2-萘基)丙氨酸、3-甲基-苯丙氨酸、0-4-烯丙基-L-酪氨酸、4-丙基-L-酪氨酸、三-O-乙酰基-GlcNAcβ-丝氨酸、L-多巴、氟化苯丙氨酸、异丙基-L-苯丙氨酸、对-叠氮基-L-苯丙氨酸、对-酰基-L-苯丙氨酸、对-苯甲酰基-L-苯丙氨酸、L-磷酸丝氨酸、膦酰基丝氨酸、膦酰基酪氨酸、对-碘代-苯丙氨酸、对-溴苯丙氨酸、对-氨基-L-苯丙氨酸和异丙基-L-苯丙氨酸等。非天然氨基酸结构的例子见图7,B组和图11。例如,WO2002/085923题为“体内掺入非天然氨基酸”的图16、17、18、19、26和29中提供了其它结构的各种非天然氨基酸。也可从Kiick等,(2002)通过Staudinger连接将叠氮化物掺入重组蛋白中用于化学选择性修饰,PNAS99:19-24的图1结构2-5中参见其它甲硫氨酸类似物。在一个实施方式中,提供了包括非天然氨基酸(如对-(炔丙基氧基)-苯丙氨酸)的组合物。也提供了各种含有对-(炔丙基氧基)-苯丙氨酸和,如蛋白和/或细胞的组合物。在一个方面,包括对-(炔丙基氧基)-苯丙氨酸非天然氨基酸的组合物还包括正交tRNA。非天然氨基酸可(如共价)结合到正交tRNA上,例如,通过氨基-酰基键共价结合到正交tRNA上,共价结合到正交tRNA的末端核糖的3'OH或2'OH上等。通过可以掺入蛋白的非天然氨基酸的化学部分提供了各种优点和对蛋白的操纵。例如,酮官能团的独特反应性允许用许多含肼或羟胺的试剂在体外和体内进行蛋白选择性修饰。重原子非天然氨基酸,例如,可以用于取向X射线结构数据。用非天然氨基酸位点特异性引入重原子也在选择重原子位置方面提供了选择和灵活性。光敏非天然氨基酸(例如,具有二苯甲酮和芳基叠氮化物(例如,苯基叠氮化物)侧链的氨基酸),例如,允许蛋白在体内和体外进行有效的光交联。光敏非天然氨基酸的例子包括但不限于,例如,对-叠氮基-苯丙氨酸和对-苯甲酰基-苯丙氨酸。然后,可以通过激发光敏基团-提供暂时(和/或空间)对照,任意交联具有光敏非天然氨基酸的蛋白质。在一个实施例中,可以用同位素标记的,例如甲基取代非天然氨基的甲基,在例如使用核磁共振和振动光谱学中用作局部结构和动力学的探针。炔基或叠氮基官能团,例如,允许通过[3+2]环加成反应用分子选择性修饰蛋白质。非天然氨基酸的化学合成许多上面提供的非天然氨基酸都可以从,例如,Sigma(USA)或Aldrich(Milwaukee,WI,USA)购得。如本文所提供的方法或各种出版物中所提供的方法或用本领域技术人员已知的标准方法任选地合成那些不能从市场上购得的非天然氨基酸。有机合成技术参见,例如,Fessendon和Fessendon的《有机化学》,(1982,第二版,WillardGrantPress,BostonMass.);March的《高级有机化学》(第三版,1985,WileyandSons,NewYork);和Carey和Sundberg的《高级有机化学》(第三版,A和B部分,1990,PlenumPress,NewYork)。描述非天然氨基酸合成的其它出版物包括,例如,WO2002/085923题为“体内掺入非天然氨基酸”(InvivoincorporationofUnnaturalAminoAcids);Matsoukas等,(1995)J.Med.Chem.,38,4660-4669;King,F.E.&Kidd,D.A.A.(1949)从邻苯二甲酸的中间体新合成谷氨酰胺和谷氨酸γ-二肽(ANewSynthesisofGlutamineandofγ-DipeptidesofGlutamicAcidfromPhthylatedIntermediates),J.Chem.Soc.,3315-3319;Friedman,O.M.&Chatterrji,R.(1959)合成谷胺酰胺衍生物作为抗肿瘤剂的模式底物(SynthesisofDerivativesofGlutamineasModelSubstratesforAnti-TumorAgents),J.Am.Chem.Soc.81,3750-3752;Craig,J.C.等(1988)7-氯-4[[4-(二乙氨基)-1-甲基丁基]氨基]喹啉(氯喹)的对映体的绝对构型(AbsoluteConfigurationoftheEnantiomersof7-Chloro-4[[4-(diethylamino)-1-methylbutyl]amino]quinoline(Chloroquine)),J.Org.Chem.53,1167-1170;Azoulay,M.,Vilmont,M.&Frappier,F.(1991)作为潜在抗疟药的谷胺酰胺类似物(GlutaminanaloguesasPotentialAntimalarials),Eur.J.Med.Chem.26,201-5;Koskinen,A.M.P.&Rapoport,H.(1989)合成构象受限的氨基酸类似物4-取代脯氨酸(Synthesisof4-SubstitutedProlinesasConformationallyConstrainedAminoAcidAnalogues),J.Org.Chem.54,1859-1866;Christie,B.D.&Rapoport,H.(1985)从L-天冬酰胺合成光学纯的2-哌啶酸(SynthesisofOpticallyPurePipecolatesfromL-Asparagine)。应用于通过氨基酸脱羰和亚胺离子环化全合成(+)-阿扑长春胺(ApplicationtotheTotalSynthesisof(+)-ApovincaminethroughAminoAcidDecarbonylationandIminiumIonCyclization),J.Org.Chem.1989:1859-1866;Barton等,(1987)用自由基化学合成新α-氨基酸和衍生物:合成L-和D-α-氨基-己二酸、L-α-氨基庚二酸和合适的非饱和衍生物(SynthesisofNovelα-Amino-AcidsandDerivativesUsingRadicalChemistry:SynthesisofL-andD-α-Amino-AdipicAcids,L-α-aminopimelicAcidandAppropriateUnsaturatedDerivatives),TetrahedronLett.43:4297-4308;和,Subasinghe等,(1992)使君子氨酸类似物:β-杂环2-氨基丙酸衍生物的合成及其在新使君子氨酸-敏化位点上的活性(Quisqualicacidanalogues:synthesisofbeta-heterocyclic2-aminopropanoicacidderivativesandtheiractivityatanovelquisqualate-sensitizedsite),J.Med.Chem.35:4602-7。也参见2002年12月22日提交的代理人案卷编号P1001USOO的专利申请--题为“蛋白质阵列(ProteinArrays)”。在本发明的一个方面,提供了合成对-(炔丙基氧基)苯丙氨酸化合物的方法。方法包括,例如,(a)将N-叔-丁氧基羰基-酪氨酸和K2CO3悬浮在无水DMF中;(b)将炔丙基溴加入(a)的反应混合物中,烷化羟基和羧基,产生保护的中间体化合物,该化合物具有结构:和(c)将保护的中间体化合物与无水HCl在MeOH中混合,使胺部分去保护,从而合成对-(炔丙基氧基)苯丙氨酸化合物。在一个实施方式中,该方法还包括(d)在NaOH和MeOH的水溶液中溶解对-(炔丙基氧基)苯丙氨酸HCl,室温搅拌;(e)将pH调整到pH7;和(f)沉淀对-(炔丙基氧基)苯丙氨酸化合物。参见例如,本文实施例4中炔丙基氧基苯丙氨酸的合成。非天然氨基酸的细胞摄取当设计和选择非天然氨基酸时,一般会考虑的一个问题是真核细胞对非天然氨基酸的摄取,例如,掺入蛋白。例如,α-氨基酸的高电荷密度提示这些化合物不大可能是细胞可透的。通过收集基于蛋白的运输系统将天然氨基酸摄入真核细胞。可以完成评价细胞摄取哪一种,如果有的话,非天然氨基酸的快速筛选。参见,例如,2002年12月22日提交的代理人案卷编号P1001USOO的申请,题为”蛋白质阵列(ProteinArrays)”中的例如,毒性测定;和Liu,D.R.&Schultz,P.G.(1999)扩展遗传密码有助于生物进化的进行,PNASUnitedStates96:4780-4785。虽然可以用各种测定容易地分析摄取,但是设计适合细胞摄取途径的非天然氨基酸的替代途径是提供体内产生氨基酸的生物合成途径。非天然氨基酸的生物合成细胞中已经存在很多生物合成途径,用于生产氨基酸和其它化合物。然而在自然界中,例如在真核细胞中,可能并不存在针对具体非天然氨基酸的生物合成方法,本发明提供了这种方法。例如,在宿主细胞中通过加入新酶或修饰已有的宿主细胞途径任选地产生非天然氨基酸的生物合成途径。附加新酶是任选地天然产生的酶或人工产生的酶。例如,对-氨基苯丙氨酸的生物合成(如WO2002/085923题为“体内掺入非天然氨基酸”中的实施例所述)取决于加入来自其它生物的已知酶的组合。可以通过用含有基因的质粒转化细胞将这些酶的基因引入真核细胞中。当这些基因在细胞中表达时,它们提供了合成所需化合物的酶途径。下面的实施例中提供了任选加入的酶类型的例子。附加酶的序列在,例如,Genbank中发现。也将人工产生的酶以相同方式任选地加入细胞。在该方式中,操纵细胞机器和细胞的资源以生产非天然氨基酸。对于生产用于生物合成途径或用于发展已有途径的新酶,可以使用各种方法。例如,将Maxygen,Inc开发的如,循环重组(可从万维网的www.maxygen.com得到),任选地用于开发新酶和途径。参见,例如,Stemmer(1994),‘通过DNA改组在体外快速演化蛋白(RapidevolutionofaproteininvitrobyDNAshuffling),Nature370(4):389-391;和,Stemmer,(1994),通过随机片段化和再组装进行DNA改组:用于分子演化的体外重组(DNAshufflingbyrandomfragmentationandreassembly:Invitrorecombinationformolecularevolution),Proc.Natl.Acad.Sci.USA.,91:10747-10751。类似地,将Genencor开发的(可从万维网的genencor.com得到)DesignPathTM任选地用于代谢途径工程,例如,设计在细胞中产生0-甲基-L-酪氨酸的途径,该技术用新基因组合,例如通过功能基因组学鉴定,分子演化和设计重建了在宿主生物中的已有途径。DiversaCorporation(可从万维网diversa.com得到)也提供了快速筛选基因文库和基因途径的技术,例如,建立新途径。一般地,用本发明设计的生物合成途径生产非天然氨基酸是在足够有效的蛋白生物合成的浓度下生产的,例如,天然细胞的量,但不至于达到影响其它氨基酸浓度或耗尽细胞资源的程度。以此方式体内生产的典型浓度是约10mM至约0.05mM。一旦用含有用于生产具体途径所需酶的基因的质粒转化细胞并产生非天然氨基酸,就任选地用体内选择进一步优化非天然氨基酸的生产,用于核糖体蛋白合成和细胞生长。具有非天然氨基酸的多肽具有至少一个非天然氨基酸的感兴趣的蛋白或多肽是本发明的特征。本发明也包括具有至少一个用本发明组合物和方法生产的非天然氨基酸的多肽或蛋白。赋形剂(例如,药学上可接受的赋形剂)也可与该蛋白一起存在。通过用至少一种非天然氨基酸在真核细胞中生产感兴趣的蛋白或多肽,蛋白或多肽一般包括真核生物翻译后修饰。在某些实施方式中,蛋白包括至少一个非天然氨基酸和至少一个由真核细胞体内产生的翻译后修饰,其中该翻译后修饰不是由原核细胞产生的。例如,该翻译后修饰包括,例如,乙酰化、酰化、脂质-修饰、棕榈酰化、棕榈酸加成、磷酸化、糖脂-连接修饰、糖基化等。在一个方面,该翻译后修饰包括将寡糖(例如,(GlcNAc-Man)2-Man-GlcNAc-GlcNAc))通过GlcNAc-天冬酰胺连接附着到天冬酰胺上。也参见,表7,该表列出了与真核生物蛋白(也可存在附加残基,未显示)N-连接的寡糖的一些例子。在另一方面,该翻译后修饰包括将寡糖(例如,Gal-GaINAc,Gal-GlcNAc等)通过GalNAc-丝氨酸或GaINAc-苏氨酸连接,或GlcNAc-丝氨酸或GlcNAc-苏氨酸连接附着到丝氨酸或苏氨酸上。表7:通过GlcNAc-连接的寡糖的例子在又一方面,该翻译后修饰包括蛋白酶水解加工前体(例如,降钙素前体、降钙素基因-相关的肽前体、前甲状旁腺激素原、前胰岛素原、胰岛素原、前阿片黑皮素原、阿片黑皮素原等),组装成多亚基蛋白质或大分子组装,转移到细胞中的另一位点(例如细胞器,如内质网、高尔基体、细胞核、溶酶体、过氧化物酶体、线粒体、叶绿体、液泡等,或通过分泌途径)。在某些实施方式中,该蛋白包含分泌或定位序列、表位标记、FLAG标记、聚组氨酸标记、GST融合等。非天然氨基酸的一个优点是它提供附加化学部分,可以用来加入附加分子。这些修饰可以在真核细胞中体内生成,或体外生成。因此,在某些实施方式中,翻译后修饰是通过非天然氨基酸的。例如,翻译后修饰可以通过亲核-亲电子反应。大部分现在用于选择性修饰蛋白的反应涉及亲核和亲电子反应配偶体之间共价键形成,例如具有组氨酸或半胱氨酸侧链α-卤代酮的反应。这些情况中的选择性由蛋白中亲核残基的数量和可及性决定。在本发明蛋白质中,可以用其它更具选择性的反应,如具有酰肼的非天然酮式-氨基酸或氨氧基化合物在体外和体内的反应。参见,例如,Cornish,等,(1996)Am.Chem.Soc.,118:8150-8151;Mahal,等,(1997)Science,276:1125-1128;Wang,等,(2001)Science292:498-500;Chin,等,(2002)Am.Chem.Soc.124:9026-9027;Chin,等,(2002)Proc.Natl.Acad.Sci.,99:11020-11024;Wang,等,(2003)Proc.Natl.Acad.Sci.,100:56-61;Zhang,等,(2003)Biochemistry,42:6735-6746;和Chin,等,(2003)Science,印刷中。这允许用许多试剂,包括荧光团、交联剂、糖衍生物和细胞毒性分子对基本上任何蛋白进行选择性标记。也参见,2003年10月15日提交的题为“糖蛋白合成”(Glycoproteinsynthesis)的专利申请USSN10/686,944。例如,通过叠氮基氨基酸进行的翻译后修饰也可通过Staudinger连接(例如,用三芳基膦试剂)进行。参见,例如,Kiick等,(2002)将叠氮化合物掺入重组蛋白中用于通过Staudinger连接进行化学选择性修饰(IncorporationofazidesintorecombinantproteinsforchemoselectivemodificationbytheStaudingerligtation),PNAS99:19-24。本发明提供了选择性修饰蛋白的另一高效方法,它包括响应于选择密码子,将非天然氨基酸,例如,含有叠氮化物或炔基部分的非天然氨基酸(参见,例如,图11的2和1)遗传掺入蛋白质中。然后可以通过,例如,Huisgen[3+2]环加成反应(参见,例如,Padwa,A.《综合有机合成》(ComprehensiveOrganicSynthesis),第4卷,(1991)Trost,B.M.编,Pergamon,Oxford,第1069-1109页;和Huisgen,R.《1.3-双极还加成化学》(1,3-DipolarCycloadditionChemistry),(1984)Padwa,A.编,Wiley,NewYork,第1-176页)分别用例如,炔基或叠氮化物衍生物来修饰这些氨基酸侧链。参见,例如,图16。因为该方法包括环加成而不是亲核取代,所以可以以极高的选择性来修饰蛋白质。该反应可以在室温下、含水条件中以极好的区域选择性(1,4>1,5)通过将催化量的Cu(I)盐加入到反应混合物中进行。参见,例如,Tornoe,等,(2002)Org.Chem.67:3057-3064;和Rostovtsev,等,(2002)Angew.Chem.Int.Ed.Eng.41:2596-2599。可以使用的另一方法是具有四半胱氨酸基序的双砷化合物上的配体交换,参见,例如,Griffin,等,(1998)Science281:269-272。可以通过[3+2]环加成加入大批本发明蛋白的分子包括实际上任何具有叠氮基或炔基衍生物的分子。参见,例如,本文实施例3和5。这种分子包括但不限于,染料、荧光团、交联剂、糖衍生物、聚合物(例如,聚乙二醇的衍生物)、光交联剂、细胞毒化合物、亲和标记、生物素的衍生物、树脂、珠、第二个蛋白或多肽(或更多)、多核苷酸(例如,DNA、RNA等)、金属螯合剂、辅因子、脂肪酸、碳水化合物等。参见,例如,本文的图13A和实施例3和5。可以将这些分子分别加入到具有炔基的非天然氨基酸,如对-炔丙基氧基苯丙氨酸,或具有叠氮基的非天然氨基酸,如对-叠氮基-苯丙氨酸中。例如,参见图13B和图17A。在另一方面,本发明提供了包括这种分子的组合物和生产这些分子,例如,叠氮基染料(如化学结构4和化学结构6中所示)、炔基聚乙二醇(例如,化学结构7中所示)的方法,其中n是例如,50和10,000、75和5,000、100和2,000、100和1,000等之间的整数。在本发明的实施方式中,炔基聚乙二醇的分子量为,例如,约5,000至约100,000Da、约20,000至约50,000Da、约20,000至约10,000Da(例如,20,000Da)等。也提供了包含这些化合物,例如,与蛋白和细胞的各种组合物。在本发明的一个方面,含有叠氮基染料(例如,化学结构4或化学结构6)的蛋白还包括至少一种非天然氨基酸(例如,炔基氨基酸),其中通过[3+2]环加成将叠氮基染料附着到非天然氨基酸上。在一个实施方式中,蛋白包括化学结构7的炔基聚乙二醇。在另一实施方式中,该组合物还包括至少一种非天然氨基酸(例如,叠氮基氨基酸),其中通过[3+2]环加成将炔基聚乙二醇附着到非天然氨基酸上。也提供了用于合成叠氮基染料的方法。例如,一种该方法包含:(a)提供含有磺酰卤化物部分的染料化合物;(b)在3-叠氮基丙胺和三乙胺的存在下将染料化合物加热到室,将3-叠氮基丙胺的胺部分与染料化合物的卤化物位置偶联,从而合成叠氮基染料。在一个例子实施方式中,该染料化合物包括丹磺酰氯,该叠氮基染料包括化学结构4的组合物。在一个方面,该方法还包括从反应混合物中纯化叠氮基染料。参见,例如,本文实施例5。在另一实施例中,合成叠氮基染料的方法包括(a)提供含胺的染料化合物;(b)在合适的溶剂中将含胺的染料化合物与碳二亚胺和4-(3-叠氮基丙基氨甲酰基)-丁酸混合,将该酸的羰基与染料化合物的胺部分偶联,从而合成叠氮基染料。在一个实施方式中,碳二亚胺包括1-乙基-3-(3-二甲基氨丙基)碳二亚胺盐酸盐(EDCI)。在一个方面,含胺的染料包括荧光胺,合适溶剂包括吡啶。例如,含胺的染料任选地包括荧光胺,叠氮基染料任选地包括化学结构6的组合物。在一个实施方式中,该方法还包括(c)沉淀叠氮基染料;(d)用HCl洗涤沉淀;(e)在EtOAc中溶解洗涤的沉淀;和(f)在己烷中沉淀叠氮基染料。参见,例如,本文实施例5。也提供了合成炔丙基酰胺聚乙二醇的方法。例如,该方法包括将炔丙基胺与聚乙二醇(PEG)-羟基琥珀酰亚胺酯在有机溶剂(例如,CH2Cl2)中室温下反应,产生化学结构7的炔丙基酰胺聚乙二醇。在一个实施方式中,该方法还包括用乙酸乙酯沉淀炔丙基酰胺聚乙二醇。在一个方面,该方法还包括在甲醇中再结晶炔丙基酰胺聚乙二醇;和真空下干燥产物。参见,例如,本文的实施例5。本发明的真核细胞提供了合成包含大有用量的非天然氨基酸的蛋白的能力。在一个方面,该组合物任选地包括,例如,至少10微克、至少50微克、至少75微克、至少100微克、至少200微克、至少250微克、至少500微克、至少1毫克、至少10毫克或更多含有非天然氨基酸的蛋白,或用体内蛋白生产方法可获得的量(本文详细提供了重组蛋白生产和纯化)。在另一方面,该蛋白任选地以存在于组合物中,即在例如,细胞裂解物、缓冲液、药物缓冲液或其它悬浮液(例如,体积为,例如,从约1纳升至约100升)中的浓度为例如,每升至少10微克蛋白、每升至少50微克蛋白、每升至少75微克蛋白、每升至少100微克蛋白、每升至少200微克蛋白、每升至少250微克蛋白、每升至少500微克蛋白、每升至少1毫克蛋白或每升至少10毫克蛋白或更多。在真核细胞中包括至少一种非天然氨基酸的蛋白的大量生产(例如,比用其它方法,例如,体外翻译一般性可能量更大)是本发明的特征。可以完成非天然氨基酸的掺入以,例如,修改蛋白结构和/或功能中的变化,例如,改变大小、酸度、亲核性、氢键合、疏水性、蛋白酶靶位点的可及性,靶向一个部分(例如,蛋白阵列)等。包括非天然氨基酸的蛋白可具有增加的或甚至新的催化或物理性质。例如,通过蛋白中包括非天然氨基酸任选地修饰了下面的性质:毒性、生物分布、结构性质、光谱性质、化学和/或光化学性质、催化能力、半衰期(例如、血清半衰期)、与其它分子反应的能力、例如、共价或非共价等。含有包括至少一种非天然氨基酸的蛋白的组合物可用于,例如,新治疗、诊断、催化酶、工业酶、结合蛋白(例如,抗体)和例如,蛋白结构和功能的研究。参见,例如,Dougherty,(2000)非天然氨基酸用作蛋白结构和功能的探针(UnnaturalAminoAcidsasProbesofProteinStructureandFunction),CurrentOpinioninChemicalBiology,4:645-652。在本发明的一个方面,组合物包括至少一种具有至少一个,例如,至少两个、至少三个、至少四个、至少五个、至少六个、至少七个、至少八个、至少九个或至少十个或更多的非天然氨基酸的蛋白。非天然氨基酸可以是相同或不同的,例如,在蛋白中可以有1、2、3、4、5、6、7、8、9或10或更多不同位点包含1、2、3、4、5、6、7、8、9或10或更多不同非天然氨基酸。在另一方面,组合物包括蛋白中存在的至少一种,但少于全部的具体氨基酸被非天然氨基酸取代的蛋白。对于给定的具有多于一个非天然氨基酸的蛋白来说,非天然氨基酸可以是相同或不同的(例如,该蛋白可包括两种或多种不同类型的非天然氨基酸,或可包括两种相同的非天然氨基酸)。对于给定的具有多于两个非天然氨基酸的蛋白来说,非天然氨基酸可以是相同、不同或同种的多个非天然氨基酸与至少一种不同的非天然氨基酸的组合。从本质上说,可以用本文的组合物和方法生产任何包括非天然氨基酸(和任意相应的编码核酸,例如,该核酸包括一种或多种选择密码子)的蛋白(或其部分)。没有对几十万的已知蛋白进行鉴定的尝试,这些蛋白中任意一个都可被修饰为包括一种或多种非天然氨基酸,例如,通过修改任何可用的突变方法在相关翻译系统中包括一种或多种合适的选择密码子。已知蛋白的普通序列库包括GenBankEMBL、DDBJ和NCBI。通过搜索因特网可容易地识别其它库。一般地,蛋白与任意可用蛋白(例如,治疗蛋白、诊断蛋白、工业酶或它们的一部分等),例如,至少60%、至少70%、至少75%、至少80%、至少90%、至少95%或至少99%或更多相同,它们包含一个或多个非天然氨基酸。可以修饰包括一种或多种非天然氨基酸的治疗、诊断和其它蛋白的例子包括但不限于,例如,α-1抗胰蛋白酶、血管生成抑制素、抗溶血因子、抗体(抗体的进一步详述见下)、载脂蛋白、脱辅蛋白质、心钠素、心房钠尿多肽、心房肽、C-X-C趋化因子(例如,T39765,NAP-2,ENA-78,Gro-a,Gro-b,Gro-c,IP-10,GCP-2,NAP-4,SDF-1,PF4,MIG)、降钙素、CC趋化因子(例如,单核细胞趋化蛋白-1、单核细胞趋化蛋白-2、单核细胞趋化蛋白-3、单核细胞炎症蛋白-1α、单核细胞炎症蛋白-1β、RANTES、I309、R83915、R91733、HCC1、T58847、D31065、T64262)、CD40配体、C-kit配体、胶原、集落刺激因子(CSF)、补体因子5α、补体抑制剂、补体受体1、细胞因子、(例如,上皮嗜中性粒细胞激活肽-78、GROα/MGSA、GROβ、GROγ、MIP-lα、MIP-1δ、MCP-1)、表皮生长因子(EGF)、促红细胞生成素(“EPO”,代表通过掺入一种或多种非天然氨基酸进行修饰的优选靶)、剥脱性毒素A和B、因子IX、因子VII、因子VIII、因子X、成纤维细胞生长因子(FGF)、纤维蛋白原、纤连蛋白、G-CSF、GM-CSF、葡糖脑苷脂酶、促性腺素、生长因子、Hedgehog蛋白(例如,Sonic,Indian,Desert)、血红蛋白、肝细胞生长因子(HGF)、水蛭素、人血清白蛋白、胰岛素、胰岛素-样生长因子(IGF)、干扰素(例如,IFN-α、IFN-β、IFN-Y)、白介素(例如,IL-1、IL-2、IL-3、IL-4、IL-5、IL-6、IL-7、IL-8、IL-9、IL-10、IL-11、IL-12等)、角质形成细胞生长因子(KGF)、乳铁蛋白、白血病抑制因子、荧光素酶、Neurturin、嗜中性粒细胞抑制因子(NIF)、制瘤素M、成骨蛋白、甲状旁腺激素、PD-ECSF、PDGF、肽激素(例如,人生长激素)、多效营养因子、蛋白A、蛋白G、热源性外毒素A、B和C、松弛素、肾素、SCF、可溶性补体受体I、可溶性I-CAM1、可溶性白介素受体(IL-1、2、3、4、5、6、7、9、10、11、12、13、14、15)、可溶性TNF受体、生长调节素、促生长素抑制素、促生长素、链激酶、超抗原即葡萄球菌肠毒素(SEA、SEB、SEC1、SEC2、SEC3、SED、SEE)、超氧化物歧化酶(SOD)、中毒性休克综合征毒素(TSST-1)、胸腺素α1、组织纤溶酶原激活物、肿瘤坏死因子β(TNFβ)、肿瘤坏死因子受体(TNFR)、肿瘤坏死因子-α(TNFα)、血管内皮生长因子(VEGEF)、尿激酶和许多其它物质。一类可用本文描述的用于体内掺入非天然氨基酸的组合物和方法制成的蛋白包括转录调节剂或其部分。转录调节剂的例子包括调节细胞生长、分化、调节等的基因和转录调节蛋白。在原核生物、病毒和真核生物包括真菌、植物、酵母、昆虫和动物包括哺乳动物中发现了转录调节剂,这提供了大量的治疗靶。应理解表达和转录激活物通过很多机制,例如,通过与受体结合、刺激信号转导级联反应、调节转录因子的表达、与启动子和增强子结合、与结合到启动子和增强子的蛋白结合、解旋DNA、剪接前mRNA、聚腺苷化RNA和降解RNA来调节转录。例如,真核细胞中的GAL4蛋白或其部分的组合物也是本发明的特征。一般地,GAL4蛋白或其部分含有至少一个非天然氨基酸。也参见本文中题为“正交氨酰基-tRNA合成酶”的部分。一类本发明的蛋白(例如,具有一种或多种非天然氨基酸的蛋白)包括表达激活物,如细胞因子、炎症分子、生长因子、它们的受体和癌基因产物,例如,白介素(例如,IL-1、IL-2、IL-8等)、干扰素、FGF、IGF-I、IGF-II、FGF、PDGF、TNF、TGF-α、TGF-β、EGF、KGF、SCF/c-Kit、CD40L/CD40、VLA-4/VCAM-1、ICAM-1/LFA-1和透明质酸苷/CD44;信号转导分子和相应的癌基因产物,例如,Mos、Ras、Raf和Met;以及转录激活物和抑制物,例如,p53、Tat、Fos、Myc、Jun、Myb、Rel和甾类激素受体如雌激素、孕酮、睾酮、醛固酮、LDL受体配体和皮质酮受体。本发明也提供了具有至少一个非天然氨基酸的酶(例如,工业酶)或其部分。酶的例子包括但不限于,例如,酰胺酶、氨基酸消旋酶、酰化酶、脱卤素酶、加双氧酶、二芳基丙烷过氧化物酶、差向异构酶、环氧化物水解酶、酯酶、异构酶、激酶、葡萄糖异构酶、糖苷酶、糖基转移酶、卤素过氧化物酶、单加氧酶(如p450)、脂肪酶、木质素过氧化物酶、腈水合酶、腈水解酶、蛋白酶、磷酸酶、枯草杆菌蛋白酶、转氨酶和核酸酶。很多这些蛋白可从市场上购得(参见,例如,SigmaBioSciences2002目录和价格表),相应的蛋白序列和基因一般还有它们的很多变体是熟知的(参见,例如,Genbank)。可以根据本发明通过插入一个或多个非天然氨基酸对它们中的任一进行修饰,例如,根据一种或多种治疗、诊断或感兴趣的的酶性质改变蛋白。治疗相关性质的例子包括血清半衰期、储存半衰期、稳定性、免疫原性、治疗活性,可检测性(例如,在非天然氨基酸中包括报道基团(例如,标记或标记结合位点))、LD50的降低或其它副作用、通过消化道进入身体的能力(例如口服利用度)等。诊断性质的例子包括储存半衰期、稳定性、诊断活性,可检测性等。相关酶性质的例子包括储存半衰期、稳定性、酶活性、生产能力等。也可以修饰各种其它蛋白,以包括本发明的一个或多个非天然氨基酸。例如,本发明可包括例如,在来自感染性真菌,例如,曲霉,假丝酵母种;细菌,具体是作为病原菌模型的大肠杆菌,和医学上重要的细菌如葡萄球菌属(例如,金黄色(葡萄球菌))或链球菌属(例如,肺炎(链球菌));原生动物如孢子虫纲(例如疟原虫)、根足虫类(例如内变形虫属)和鞭毛虫类(锥虫属、利什曼虫属、毛滴虫属、贾第虫属等);病毒如(+)RNA病毒(例子包括痘病毒,如牛痘病毒;细小核糖核酸病毒,例如脊髓灰质炎病毒;被膜病毒,例如风疹病毒;黄病毒,例如HCV;和冠状病毒),(-)RNA病毒(例如,弹状病毒,例如VSV;副粘病毒,例如RSV;正粘病毒,例如流感病毒;布尼亚病毒和沙粒病毒),dsDNA病毒(例如呼肠弧病毒),RNA至DNA病毒,即逆转录病毒,如HIV和HTLV,以及某些DNA至RNA病毒,如乙肝病毒的蛋白中,用非天然氨基酸在一种或多种疫苗蛋白中取代一个或多个天然氨基酸。农业相关蛋白,如昆虫抗性蛋白(例如,Cry蛋白)、淀粉和脂质生产酶、植物和昆虫毒素、毒素抗性蛋白、真菌毒素解毒蛋白、植物生长酶(例如,核酮糖1,5-二磷酸羧化酶/加氧酶“RUBISCO”)、脂肪氧合酶(LOX)和磷酸烯醇丙酮酸(PEP)羧化酶也是非天然氨基酸修饰的合适靶。本发明也提供在真核细胞中生产至少一种含有至少一个非天然氨基酸的蛋白的方法(和该方法生产的蛋白)。例如,方法包括:在合适的培养基中培养含有核酸的真核细胞,该核酸包含至少一个选择密码子并编码该蛋白。该真核细胞也包含:在细胞中起作用并识别选择密码子的正交tRNA(O-tRNA);和优选地氨酰化具有非天然氨基酸的O-tRNA的正交氨酰基tRNA合成酶(O-RS)和含有非天然氨基酸的培养基。在一个实施方式中,该方法还包括将非天然氨基酸掺入该蛋白中,其中非天然氨基酸包含第一活性基团;然后将该蛋白与含有第二活性基团的分子(例如,染料、聚合物如聚乙二醇的衍生物、光交联剂、细胞毒化合物、亲和标记、生物素的衍生物、树脂、第二个蛋白或多肽、金属螯合剂、辅因子、脂肪酸、碳水化合物、多核苷酸(例如,DNA、RNA等)等)接触。第一活性基团与第二活性基团反应,使该分子通过[3+2]环加成附着到非天然氨基酸上。在一个实施方式中,第一活性基团是炔基或叠氮基部分,第二活性基团是叠氮基或炔基部分。例如,第一活性基团是炔基部分(例如,在非天然氨基酸对-炔丙基氧基苯丙氨酸),第二活性基团是叠氮基部分。在另一实施例中,第一活性基团是叠氮基部分(例如,在非天然氨基酸对-叠氮基-L-苯丙氨酸),第二活性基团是炔基部分。在一个实施方式中,O-RS氨酰化具有非天然氨基酸的O-tRNA的效率相当于具有例如,SEQIDNO.:86或45中所列氨基酸序列的O-RS的效率的至少50%。在另一实施方式中,O-tRNA包含SEQIDNO.:65或64,加工而来或由编码的,或它们的互补多核苷酸序列。在又一实施方式中,O-RS包含SEQIDNO.:36-63(例如,36-47、48-63或36-63的任意其它亚组)和/或86中任意一个所列的氨基酸。该编码蛋白可包括,例如,治疗蛋白、诊断蛋白、工业酶或它们的一部分。任选地,通过非天然氨基酸进一步修饰该方法生产的蛋白。例如,通过至少一个翻译后修饰在体内任选地修饰该方法生产的蛋白。也提供了生产筛选或选择转录调节蛋白的方法(和用这种方法生产的筛选或选择转录调节蛋白)。例如,方法包括:选择第一个多核苷酸序列,其中的多核苷酸序列编码核酸结合域;并将第一个多核苷酸序列突变以包括至少一个选择密码子。这提供筛选或选择多核苷酸序列。该方法也包括:选择第二个多核苷酸序列,其中第二个多核苷酸序列编码转录激活域;提供含有可操作地连接于第二个多核苷酸序列的筛选或选择多核苷酸序列的构建物;和将该构建物、非天然氨基酸、正交tRNA合成酶(O-RS)和正交tRNA(O-tRNA)引入细胞。响应于筛选或选择多核苷酸序列中的选择密码子,O-RS凭借这些组件优选地氨酰化具有非天然氨基酸的O-tRNA,O-tRNA识别选择密码子并将非天然氨基酸掺入核酸结合域中,从而提供筛选或选择转录调节蛋白。在某些实施方式中,本方法中感兴趣的蛋白或多肽(或其部分)和/或本发明组合物由核酸编码。一般地,该核酸包含至少一个选择密码子、至少两个选择密码子、至少三个选择密码子、至少四个选择密码子、至少五个选择密码子、至少六个选择密码子、至少七个选择密码子、至少八个选择密码子、至少九个选择密码子、十个或更多选择密码子。可以用本领域技术人员熟知的方法以及本文描述的“诱变和其它分子生物学技术”诱变编码感兴趣的蛋白或多肽的基因,以包括,例如,一个或多个用于掺入非天然氨基酸的选择密码子。例如,将用于感兴趣的蛋白的核酸突变,以包括一个或多个选择密码子,提供一个或多个非天然氨基酸的插入。本发明包括任意所述变体,例如,突变体,任意蛋白的形式,例如,包括至少一个非天然氨基酸。类似地,本发明也包括相应的核酸,即任何具有一个或多个选择密码子的核酸,该核酸编码一种或多种非天然氨基酸。在一个示例性实施方式中,本发明提供了组合物(和本发明方法生产的组合物),包括Thr44、GAL4的Arg110TAG突变体,其中GAL4蛋白包括至少一个非天然氨基酸。在另一实施方式中,本发明提供了包括人超氧化物歧化酶(hSOD)的Trp33TAG突变体的组合物,其中hSOD蛋白包括至少一个非天然氨基。纯化含有非天然氨基酸的重组蛋白可以根据本领域技术人员已知和使用的标准步骤纯化本发明的蛋白,例如,含有非天然氨基酸的蛋白,含有非天然氨基酸的蛋白的抗体等,达到部分或基本同质性。因此,可以通过本领域熟知的许多方法中任意一种回收并纯化本发明多肽,包括,例如,硫酸铵或乙醇沉淀、酸或碱抽提、柱层析、亲和柱层析、阴离子或阳离子交换层析、磷酸纤维素层析、疏水作用层析、羟基磷灰石层析、凝集素层析、凝胶电泳等。在生成正确折叠的成熟蛋白中可以按需使用蛋白再折叠步骤。在最后需要高纯度的纯化步骤中,可以使用高效液相层析(HPLC)、亲和层析或其他合适方法。在一个实施方式中,将抗非天然氨基酸(或含有非天然氨基酸的蛋白)的抗体用作纯化试剂,例如,用于基于亲和力的蛋白纯化,该蛋白含有一个或多个非天然氨基酸。一旦纯化,按需达到部分同质性或同质性,则将多肽任选地用作,例如测定组件、治疗剂或用作生产抗体的免疫原。除了本文中引用的其它参考文献外,各种纯化/蛋白折叠方法都是本领域熟知的,这些方法包括,例如,R.Scopes,《蛋白纯化》(ProteinPurification),Springer-Verlag,N.Y.(1982);Deutscher,《酶学方法》(MethodsinEnzymology)第182卷:“蛋白纯化指南”(GuidetoProteinPurification),AcademicPress,Inc.N.Y.(1990);Sandana(1997)《蛋白的生物分离》(BioseparationofProteins),AcademicPress,Inc.;Bollag等(1996)《蛋白方法》(ProteinMethods)第2版,Wiley-Liss,NY;Walker(1996)《蛋白操作程序手册》(TheProteinProtocolsHandbook)HumanaPress,NJ,Harris和Angal(1990)《蛋白纯化应用:实用方法》(ProteinPurificationApplications:APracticalApproach)Oxford的IRLPress,Oxford,England;Harris和Angal《蛋白纯化方法:实用方法》(ProteinPurificationMethods:APracticalApproach)Oxford的IRLPress,Oxford,England;Scopes(1993)《蛋白纯化:原理和实践》(ProteinPurification:PrinciplesandPractice)第3版SpringerVerlag,NY;Janson和Ryden(1998)《蛋白纯化:原理、高分辨率方法和应用》(ProteinPurification:Principles,HighResolutionMethodsandApplications),第二版,Wiley-VCH,NY;和Walker(1998)《CD-ROM上的蛋白操作程序》(ProteinProtocolsonCD-ROM)HumanaPress,NJ;和其中引用的参考文献中所列方法。在真核细胞中用非天然氨基酸生产感兴趣的蛋白或多肽的一个优点是该蛋白或多肽一般以它们的原始构象折叠。然而,在本发明的某些实施方式中,本领域技术人员将认识到,合成、表达和/或纯化后,蛋白可具有与相关多肽所需构象不同的构象。在本发明的一个方面,表达蛋白任选地变性,然后复性。这是通过例如,将侣伴蛋白加入感兴趣的蛋白或多肽和/或通过在离液剂如盐酸胍中使蛋白溶解等完成的。通常,偶而需要将表达多肽变性并还原,然后使多肽再折叠成优选构象。例如,可以将胍、尿素、DTT、DTE和/或侣伴蛋白加入感兴趣的的翻译产物。还原、变性和复性蛋白的方法是本领域技术人员熟知的(参见上述参考文献,以及Debinski,等(1993)J.Biol.Chem.,268:14065-14070;Kreitman和Pastan(1993)Bioconjug.Chem.,4:581-585;和Buchner,等,(1992)Anal.Biochem.,205:263-270)。例如,Debinski,等描述了在胍-DTE中变性和还原内含体蛋白。该蛋白可以在含有,例如氧化谷胱甘肽和L-精氨酸的氧化还原缓冲液中再折叠。再折叠试剂可以流动或移动至与一种或多种多肽或其它表达产物接触,反之亦然。抗体在一个方面,本发明提供了本发明分子,例如合成酶、tRNA和包含非天然氨基酸的蛋白的抗体。将本发明分子的抗体用作纯化试剂,例如,用于纯化本发明分子。此外,抗体可用作指示实际来指示合成酶、tRNA或包含非天然氨基酸的蛋白的存在,例如,以追踪分子的存在或定位(例如,体内或原位)。本发明的抗体可以是包含一个或多个基本或部分由免疫球蛋白基因或免疫球蛋白基因的片段编码多肽的蛋白。公认的免疫球蛋白基因包括κ、λ、α、γ、δ、ε和υ恒定区基因,以及无数的免疫球蛋白可变区基因。轻链分类为κ或λ。重链归类为γ、υ、α、δ或ε,它们分别依次定义免疫球蛋白类型IgG、IgM、IgA、IgD和IgE。一种典型的免疫球蛋白(如抗体)的结构单位包含四聚体。各四聚体由两个相同的多肽链对组成,各对有一条“轻链”(约25kD)和一条“重链”(约50-70kD)。各链的N末端确定约100-110或更多氨基酸的可变区,主要负责抗原识别。术语可变轻链(VL)和可变重链(VH)分别指这些轻链和重链。抗体以完整的免疫球蛋白或用不同肽酶消化产生许多良好表征的片段存在。因此,例如,胃蛋白酶在铰链区中的二硫连接下面消化抗体,产生F(ab')2,Fab的二聚体,其本身是由二硫键连接于VH-CH1的轻链。可在温和条件下还原F(ab')2以打断铰链区中的二硫连接,从而将F(ab')2二聚体转化为Fab'单体。Fab'单体实质上是具有部分铰链区的Fab(对其它抗体片段的更详细描述参见,《基础免疫学》(FundermentalImmunology),第四版,W.E.Paul编,RavenPress,N.Y.(1999))。虽然根据完整抗体的消化定义了不同抗体片段,但是本领域技术人员将理解,也可用化学方法或通过重组DNA的方法从头合成所述Fab'片段等。因此,本文中所用术语抗体,也任选地包括通过全抗体修饰或用重组DNA方法从头合成所产生的抗体片段。抗体包括单链抗体,包括单链Fv(sFv或scFv)抗体,其中由可变重链和可变轻链连接在一起(直接或经由肽接头)形成连续的多肽。本发明抗体可以是,例如,多克隆、单克隆、嵌和、人源化、单链、Fab片段、由Fab表达文库产生的片段等。通常,本发明抗体在各种分子生物或药学方法中用作常用试剂和治疗试剂中是有价值的。生产多克隆和单克隆抗体的方法是可用的,可以应用于生产本发明抗体。许多基础教科书描述了标准的抗体生产方法,包括,例如,Borrebaeck(编)(1995)《抗体工程》(AntibodyEngineering),第二版,FreemanandCompany,NY(Borrebaeck);McCafferty等(1996)《抗体工程,实用方法》(AntibodyEngineering,APracticalApproach)OxfordPress的IRL,Oxford,England(McCafferty),和Paul(1995)《抗体工程方案》(AntibodyEngineeringProtocols)Humanapress,Towata,NJ(Paul);Paul(编),(1999)《基础免疫学》(FundamentalImmunology),第五版RavenPress,N.Y.;Coligan(1991)《新编免疫学实验指南》(CurrentProtocolsinImmunology)Wiley/Greene,NY;Harlow和Lane(1989)《抗体:实验室手册》(Antibodies:ALaboratoryManual)ColdHarborPress,NY;Stites等(编)《基础和临床免疫学》(BasicandClinicalImmunology)(第四版)LangeMedicalPublications,LosAltos,CA,和其中引用的参考文献;Goding(1986)《单克隆抗体:原理和实践》(MonoclonalAntibodies:PrinciplesandPractice)(第二版)AcademicPress,NewYork,NY;以及Kohler和Milstein(1975)Nature256:495-497。已经开发了用于不依赖于如向动物注射抗原的抗体制备的各种重组技术,它们可以用于本
技术实现要素:
中。例如,可能在噬菌体或类似载体中产生并选择重组抗体文库。参见,例如,Winter等(1994)通过噬菌体展示技术生产抗体(MakingAntibodiesbyPhageDisplayTechnology),Annu.Rev.Immunol.12:433-455及其引用作综述的参考文献。也参见,Griffiths和Duncan(1998)通过噬菌体展示选择抗体的策略(Strategiesforselectionofantibodiesbyphagedisplay),CurrOpinBiotechnol9:102-108;Hoogenboom等(1998)抗体噬菌体展示技术及其应用(Antibodyphagedisplaytechnologyanditsapplications),Immunotechnology4:1-20;Gram等(1992)从幼稚的组合免疫球蛋白文库中体外选择和亲和成熟抗体(invitroselectionandaffinitymaturationofantibodiesfromanaivecombinatorialimmunoglobulinlibrary)PNAS89:3576-3580;Huse等(1989)Science246:1275-1281;和Ward等(1989)Nature341:544-546。在一个实施方式中,抗体文库可包含V基因的所有组成成分(如,从淋巴细胞群中收集或体外组装),将其克隆,用于在丝状噬菌体的表面展示相关重链和轻链可变域。通过与抗原结合选择噬菌体。由感染噬菌体的细菌表达可溶性抗体,例如通过诱变来改良该抗体。参见,如Balint和Larrick(1993)通过简约诱变进行的抗体工程(AntibodyEngineeringbyParsimoniousMutagenesis)Gene137:109-118;Stemmer等(1993)通过酶反向PCR从蛋白接头文库制备活性单链Fv抗体的选择(SelectionofanActiveSingleChainFvAntibodyFromaProteinLinkerLibraryPreparedbyEnzymaticInversePCR)Biotechniques14(2):256-65;Crameri等(1996)通过DNA改组构建并发展抗体-噬菌体文库(Constructionandevolutionofantibody-phagelibrariesbyDNAshuffling)NatureMedicine2:100-103;和Crameri和Stemmer(1995)组合的多盒式诱变建立了突变型和野生型盒的所有变换(Combinatorialmultiplecassettemutagenesiscreatesallthepermutationsofmutantandwildtypecassettes)BioTechniques18:194-195。用于克隆和表达重组抗体噬菌体系统的试剂盒也是已知的和可用的,例如,产自Amersham-PharmaciaBiotechnology(Uppsala,Sweden)的“重组噬菌体抗体系统,小鼠ScFv模块”(recombinantphageantibodysystem,mouseScFvmodule)。噬菌体抗体文库也用于通过链改组生产高亲和人源抗体(参见,例如,Marks等(1992)旁路免疫:通过链改组构建高亲和人抗体(By-PassingImmunization:BuildingHighAffinityHumanAntibodiesbyChainShuffling)Biotechniques10:779-782。也公认的是,可通过许多商业服务的任何一个制备抗体(如BethylLaboratories(Montgomery,TX)、Anawa(Switzerland)、Eurogentec(比利时和在美国宾夕法尼亚州费城等)和许多其它公司。在某些实施方式中,本发明“人源化“抗体是有用的,如,抗体用于治疗性给药时。人源化抗体的使用趋于减少对治疗抗体的不需要的免疫反应的发生率(如,当患者是人时)。上述抗体参考文献描述了人源化策略。除了人源化抗体外,人抗体也是本发明的特征。人抗体由特征性的人免疫球蛋白序列组成。人抗体可通过各种方法生产(参见,例如,Larrick等,美国专利5,001,065作以综述)。通过三体杂交瘤(trioma)技术生产人抗体的一般方法由Ostberg等,(1983),Hybridoma2:361-367,Ostberg,美国专利4,634,664,和Engelman等,美国专利4,634,666描述。已知在纯化和检测蛋白中使用抗体的各种方法,这些方法可以应用于检测和纯化如本文所述含有非天然氨基酸的蛋白质。通常,抗体对酶联免疫吸附反应、Western印迹、免疫化学、亲和层析法、SPR和很多其他方法是有用的试剂。上述参考文献提供如何进行酶联免疫吸附反应、Western印迹、表面胞质团共振(SPR)等的细节。在本发明的一个方面,本发明抗体本身包括非天然氨基酸,提供了具有感兴趣的性质的抗体(例如改进的半衰期、稳定性、毒性等)。亦参见,本文中题为“具有非天然氨基酸的多肽”部分。抗体占目前临床试验中所有化合物的接近50%(Wittrup,(1999)噬菌体展示Tibtech17:423-424,抗体普遍用作诊断试剂。因此,用非天然氨基酸修饰抗体的能力为修饰这些有价值的试剂提供了重要的工具。例如,Mab在诊断领域有很多应用。从简单的斑点试验到涉及面更广的测定方法如来自DuPontMerckCo.的放射性标记的NR-LU-10Mab,它用于肿瘤成像(Rusch等(1993)NR-LU-10单克隆抗体扫描。计算断层显像评价非小细胞肺癌的有用新手段(NR-LU-10monoclonalantibodyscanning.Ahelpfulnewadjuncttocomputedtomographyinevaluatingnon-small-celllungcancer),JThoracCardiovascSurg106:200-4)。如上所述,Mab是ELISA、Westerm印迹、免疫化学、亲和层析法等的中心试剂。可以修饰任何所述诊断抗体,包括一个或多个非天然氨基酸,改变,例如Ab对靶的特异性或亲合力,或例如,通过在非天然氨基酸中包括可检测标记(如光谱、荧光、发光等)改变一种或多种可检测的性质。一类有价值的抗体试剂是治疗抗体。例如,抗体可以是肿瘤特异性的Mab,它能够通过靶向肿瘤细胞,通过抗体依赖的细胞介导的细胞毒性(ADCC)或补体介导的裂解(CML)抑制肿瘤生长(这些通用型Ab有时称为”魔弹”)。一个例子是利妥昔(Rituxan),一种抗CD20Mab,用于治疗非霍其金氏淋巴瘤(Scott(1998)利妥昔:一种治疗非霍其金氏淋巴瘤的新单克隆抗体(Rituximab:anewtherapeuticmonoclonalantibodyfornon-Hodgkin'slymphom),CancerPract6:195-7)。第二个例子涉及干扰肿瘤生长的关键组分的抗体。贺赛汀(herceptin)是一种抗HER-2单克隆抗体,用于治疗转移型乳腺癌,并提供具有此种作用机制的抗体的例子(Baselga等,(1998)重组人源化抗HER2抗体(贺赛汀)增强紫杉醇和阿霉素对过表达HER2/neu的人乳腺癌异种移植瘤的抗肿瘤活性(Recombinanthumanizedanti-HER2antibody(Herceptin)enhancestheantitumoractivityofpaclitaxelanddoxorubicinagainstHER2/neuoverexpressinghumanbreastcancerxenografts)[排错出版于CancerRes(1999)59(8):2020],CancerRes58:2825-31)。第三个例子涉及直接将细胞毒化合物(毒素、放射性核素等)输送至肿瘤或其他感兴趣的部位的抗体。例如,一种应用Mab是CYT-356,90Y连接的抗体,它直接将放射靶向前列腺肿瘤细胞(Deb等(1996)用90Y-CYT-356单克隆抗体治疗激素耐治的前列腺癌(Treatmentofhormone-refractoryprostatecancerwith90Y-CYT-356monoclonalantibody)ClinCancerRes2:1289-97。第四个应用是抗体导向的酶前药疗法,其中共定位至肿瘤的酶在肿瘤附近激活全身给予的前药。例如,开发了连接于羧肽酶A的抗Ep-CAM1抗体,用于治疗结直肠癌(Wolfe等,(1999)用人羧肽酶A1的T268G突变体的进行的抗体导向的酶前药疗法:前药氨甲蝶呤和胸苷酸抑制剂GW1031和GW1843的体内外研究(Antibody-directedenzymeprodrugtherapywiththeT268GmutantofhumancarboxypeptidaseAl:invitroandinvivostudieswithprodrugsofmethotrexateandthethymidylatesynthaseinhibitorsGW1031andGW1843),BioconjugChem10:38-48)。将其它Ab(如拮抗剂)设计为特异性抑制正常细胞功能,以获得疗效。一个例子是OrthocloneOKT3,一种由JohnsonandJohnson提供的抗CD3Mab,用于降低器官移植的急性排斥反应(Strate等(1990)OrthocloneOKT3作为一线治疗用于肾脏同种异体移植的急性排斥反应(OrthocloneOKT3asfirst-linetherapyinacuterenalallograftrejection),TransplantProc22:219-20。另一类抗体制品为激动剂。将这些单克隆抗体设计为特异性增强正常细胞功能,以获得疗效。例如,用于精神病治疗的基于单抗的乙酰胆碱受体激动剂正在开发之中(Xie等(1997)通过鉴定激动剂ScFv直接证明MuSK参与乙酰胆碱受体簇集(DirectdemonstrationofMuSKinvolvementinacetylcholinereceptorclusteringthroughidentificationofagonistScFv),Nat.Biotechnol.15:768-71。可将这些抗体中任意一种修饰成包含一个或多个非天然氨基酸,以增强一种或多种治疗性质(特异性、亲和力、血清半衰期等)。另一类抗体产品提供了新功能。这组中主要抗体是催化抗体,如工程改造以模拟酶催化能力的Ig序列(Wentworth和Janda(1998)催化抗体(Catalyticantibodies)CurrOpinChemBiol2:138-44)。例如,一项有趣的应用是在体内用催化抗体mAb-15A10水解可卡因以治疗成瘾(Mets等(1998)一种抗可卡因的催化抗体防止可卡因在大鼠中加强和毒性效应(Acatalyticantibodyagainstcocainepreventscocaine'sreinforcingandtoxiceffectsinrats),ProcNatlAcadSciUSA95:10176-81)。也可修饰催化抗体,使其包含一个或多个非天然氨基酸,以改进一种或多种感兴趣的的性质。通过免疫反应性定义多肽因为本发明多肽提供了各种新多肽序列(如本文翻译系统中合成蛋白的情况下包含非天然的氨基酸,或如在本文新合成酶的情况下,标准氨基酸的新序列),这些多肽也提供了能够被例如免疫测定所识别的新结构特性。抗体或特异性结合本文发明多肽的抗体的产生,以及抗体或抗血清结合的多肽,均为本发明的特征。例如,本发明包括与抗体或抗血清特异性结合的合成酶蛋白或它们与抗体或抗血清特异地免疫反应,产生包含选自(SEQIDNO:36-63(例如,36-47、48-63或36-63的任何其它亚组)和/或86)中一个或多个的氨基酸序列的免疫原。为了减少与其他同源物的交叉反应性,用可用的对照合成酶同源物,例如野生型大肠杆菌酪氨酰合成酶(TyrRS)(如,SEQIDNO.2)消减抗体或抗血清。在一种典型形式中,免疫测定使用多克隆抗血清,该抗血清通过抗一种或多种多肽产生,所述多肽包含对应于SEQIDNO:36-63(如36-47、48-63或36-63的任意其它亚组)和/或86,或它们的实质性亚序列(如,提供至少是全长序列的约30%)中一个或多个的一个或多个序列。这组来自SEQIDNO:36-63和86的潜在多肽免疫原在下文中统称为”免疫原性多肽”。任选地选择所得的抗血清,以与对照合成酶同源物具有低交叉反应性,在多克隆抗血清用于免疫测定前,例如,通过用一种或多种合成酶同源物免疫吸附去除任何这种交叉反应性。为了生产用于免疫测定的抗血清,如本文所述生产并纯化一种或多种免疫原性多肽。例如,可以在重组细胞中生产重组蛋白。用与标准佐剂,如弗氏佐剂结合的免疫原性蛋白和标准小鼠免疫方案免疫(有关可用于确定特异性免疫反应的抗体产生、免疫测定形式和条件的标准描述参见,例如,Harlow和Lane(1988)《抗体,实验室手册》(Antibodies,ALaboratoryManual),ColdSpringHarborPublications,NewYork。本文也描述了抗体的附加参考和讨论,本文可应用于通过免疫反应性定义/检测多肽生产抗体)近交品系的小鼠(因为小鼠的实际遗传一致性,结果更可重复,所以本测定使用这种小鼠)。或者,将来自本文公开序列的异种或多种合成或重组多肽共轭到载体蛋白,并用作免疫原。在免疫测定中,收集多克隆抗血清,并滴定抗免疫原性多肽,例如,用固体支持物上固定的一种或多种免疫原性蛋白进行固相免疫测定。选择、集中并用对照合成酶多肽消减滴度为106或更大的多克隆抗血清,以产生消减的、集中的、滴定的多克隆抗血清。测试消减的、集中的、滴定的多克隆抗血清在比较免疫测定中与对照同源物的交叉反应。在这个比较测定中,为消减的、集中的、滴定的多克隆抗血清测定差别结合条件,使滴定的多克隆抗血清结合到免疫原性合成酶的信噪比与结合到对照合成酶同源物相比高至少约5-10倍。也就是说,通过加入非特异性的竞争剂如清蛋白或脱脂奶粉,和/或通过调节盐条件、温度,和/或其他方面来调节结合/洗涤反应的严格性。在后续测定中将这些结合/洗涤条件用以确定测试多肽(相比免疫原性多肽和/或对照多肽的多肽)是否被集中的、消减的多克隆抗血清特异性结合。具体地,测试多肽在差别结合条件下显示,比对照合成酶同源物的信噪比至少高2-5倍,并且与免疫原性多肽相比其信噪比至少是约1/2,与已知合成酶相比,该测试多肽与免疫原性多肽共有基本结构相似性,因此是本发明的多肽。在另一实施例中,将竞争结合式的免疫测定用于测试多肽的检测。例如,如上所述,通过用对照多肽免疫吸附从集中的抗血清混合物中去除交叉反应抗体。然后,将免疫原性多肽固定在与消减的集中的抗血清接触的固体支持物上。加入受试蛋白,以测定竞争性结合集中的消减的抗血清。与固定蛋白相比,受试蛋白与集中的消减的抗血清竞争性结合的能力,与加入测定以竞争性结合免疫原性多肽的能力(免疫原性多肽与固定的免疫原性多肽有效竞争,以结合集中的多克隆抗血清)相当。用标准计算方法计算受试蛋白交叉反应性百分数。在平行测定中,通过与免疫原性多肽竞争性结合抗血清的能力比较,任选地测定对照蛋白竞争性结合集中的消减的抗血清的能力。再次用标准计算方法计算对照多肽的交叉反应百分数。当测试多肽的交叉反应性百分数比对照多肽高至少5-10倍时,或测试多肽的结合大约在免疫原性多肽的结合范围内时,一般认为测试多肽特异地结合集中的消减的抗血清。通常,免疫吸附的和集中的抗血清可用于本文描述的竞争性结合免疫测定,以比较任何测试多肽与免疫原性和/或对照多肽。为了进行此比较,在宽浓度范围中测定各免疫原性、测试和对照多肽,各多肽的量需要能够抑制消减抗血清与,例如固定对照的50%结合,用标准技术测定测试或免疫原性蛋白。如果竞争性测定中测试多肽结合的所需量少于所需免疫原性多肽的量的两倍,一般认为测试多肽与产生的抗免疫原性蛋白的抗体特异地结合,提供的量是对照多肽的至少约5-10倍。作为特异性的附加测定,用免疫原性多肽(而非对照多肽)任选地完全免疫吸附集中的抗血清,直到几乎没有或所得的免疫原性多肽消减的集中的抗血清与用于免疫吸附的免疫原性多肽的不结合可被探测到。然后,测试完全免疫吸附的抗血清与测试多肽的反应性。如果几乎没有或没有观察到反应性(即,观察到完全吸附的抗血清与免疫原性多肽的结合信噪比不高于2倍),那么由免疫原性蛋白得到的抗血清特异地结合测试多肽。药物组合物任选地将本发明中的多肽或蛋白(如合成酶、包含一个或多个非天然氨基酸的蛋白)用于治疗性用途,如与合适的药物载体结合。这种组合物,例如,包含治疗有效量的化合物和药学上可接受的载体或赋形剂。所述载体或赋形剂包括但不限于,盐水、缓冲盐水、葡萄糖、水、甘油、乙醇和/或它们的组合。使剂型适应给药方式。通常,蛋白给药方式是本领域公知的,可以应用于本发明多肽的给药。在一种或多种体外和/或体内疾病的动物模型中任选地测试包含一种或多种本发明多肽的治疗组合物,根据本领域中公知的方法确证效能、组织代谢和估计剂量。具体地,最初可通过活性、稳定性或本文中非天然氨基酸到天然氨基酸同源物的其它合适测量方法(如,修饰以包括一个或多个非天然氨基酸的EPO与天然氨基酸EPO相比),即在一个相关的实验中确定剂量。给药是通过通常用于引入分子使之最终与血液或组织细胞接触的任意途径进行的。任选地用一种或多种药学上可接受的载体,以任意合适方式给予本发明的非天然氨基酸多肽。本发明内容中给予病人所述多肽的合适方法是可用的,并且,虽然可用多于一种途径给予具体组合物,但具体途径可经常提供比另一途径更快速和更有效的作用或反应。通过给予的具体组合物,以及用于给予该组合物的具体方法部分决定药学上可接受的载体。因此,本发明药物组合物有各种合适的剂型。可以通过许多途径,包括但不限于:经口、静脉内、腹腔内、肌内、透皮、皮下、局部、舌下或直肠方式给予多肽组合物。也可通过脂质体给予非天然氨基酸多肽组合物。这种给药途径和合适剂型通常为本领域技术人员所公知。也可将非天然氨基酸多肽单独或与其他合适成分联合制成气雾剂(即它们可“雾化”)以通过吸入给药。可将气雾剂置入加压的可接受压缩气体,如二氯二氟甲烷、丙烷、氮气等。适合胃肠道外给药的剂型,例如关节内(在关节中)、静脉内、肌内、皮内、腹腔内和皮下途径包括可含有抗氧化剂、缓冲液、抑菌剂和使剂型与计划中的受者血液等渗的溶质的水性和非水性等渗无菌注射液,和可包含悬浮剂、增溶剂、增稠剂、稳定剂和防腐剂的水相和非水相无菌悬液。包装核酸的剂型可以单位剂量或多剂量密封容器,如安瓿瓶和小瓶的形式呈现。胃肠道外给药和静脉内给药是优选的给药方式。具体地,已用于天然氨基酸同源物治疗(如,一般用于EPO、GCSF、GMCSF、IFN、白介素、抗体和/或任何药学输送的蛋白)的给药途径,与当前使用的剂型一起为包括本发明非天然氨基酸的蛋白提供优选的给药途径和剂型(如当前治疗蛋白的加入聚乙二醇的变体等)。在本发明内容中,随时间推移,给予病人的剂量足以对病人产生有益的治疗反应,或例如,根据本申请,抑制病原体感染,或其他合适的活性。剂量由具体的组合物/剂型效能和所用非天然氨基酸多肽的活性、稳定性或血清半衰期,病人病情,以及所治疗病人的体重或体表面积确定。剂量的大小也由具体病人中存在、性质以及伴随给予具体组合物/剂型的任何不良副作用的程度等决定。在确定治疗或预防疾病(如癌症、遗传病、糖尿病、艾滋病等)中施用有效量的组合物/剂型,医生评价循环血浆浓度、剂型毒性、疾病进展和/或相关部位抗非天然氨基酸多肽抗体的产生。给予如70千克病人的剂量一般在与当前使用的治疗蛋白剂量相当的范围内,并根据相关组合物的活性或血清半衰期改变作出调整。本发明组合物/剂型可以通过任何已知的常规疗法,包括抗体给药,疫苗给药,细胞毒剂、天然氨基酸多肽、核酸、核酸类似物、生物反应调节剂等的给药来补充治疗病症。对于给药,以相关剂型的LD-50和/或对非天然氨基酸在不同浓度下任何副作用的观察确定的速率给予本发明剂型,例如根据病人体重和总体健康状况。可通过单剂量和均分剂量完成给药。如果进行输注某剂型的病人发生发热、寒战或肌肉疼痛,那么他/她应接受合适剂量的阿司匹林、布洛芬、对乙酰氨基酚或其他疼痛/发热控制药物。对于经历输注反应,如发热、肌肉疼痛和寒战的病人,应在输注前30分钟预先给予阿司匹林、对乙酰氨基酚或如苯海拉明。产生不对解热药和抗组胺药迅速反应的更严重寒战和肌肉疼痛,则使用杜冷丁。根据反应的严重程度,减慢或中断治疗。核酸和多肽序列及变体如上下文所述,本发明提供了核酸多核苷酸序列和多肽氨基酸序列,如0-tRNA和O-RS,和,如包含所述序列的组合物和方法。本文中公开了所述序列的例子,如0-tRNA和O-RS(参见表5,如除了SEQIDNO.:1和2外的SEQIDNO.3-65、86)。然而,本领域技术人员将理解本发明并不局限于本文公开的序列,例如,实施例和表5。本领域技术人员将理解,本发明也提供了许多相关和甚至不相关的具有本文所述功能的序列,如编码O-tRNA或O-RS。本发明也提供多肽(O-RS)和多核苷酸,如O-tRNA,编码O-RS或其部分(如合成酶的活性位点)的多核苷酸,用于构建氨酰基tRNA合成酶突变体的寡核苷酸等。例如,本发明的多肽包括包含SEQIDNO.:36-63(如36-47、48-63或36-63的任何其它亚组)和/或86中任一所列的氨基酸序列的多肽,包含由SEQIDNO.:3-35(如3-19、20-35或3-35的任何其它亚组)中任一所列的多核苷酸序列编码的氨基酸序列的多肽,和与对多肽的特异性抗体特异地免疫反应的多肽,该多肽包含SEQIDNO.:36-63,和/或86中任一个所列氨基酸序列的多肽或包含SEQIDNO.:3-35(例如,3-19,20-35,或序列3-35的任何其它亚组)中所列任一个多核苷酸序列编码的氨基酸序列的多肽。本发明的多肽也包括与天然产生的酪氨酰氨酰基-tRNA合成酶(TyrRS)(例如,SEQIDNO.:2)具有至少90%相同氨基酸序列的多肽,和包含A-E族中两种或多种氨基酸的多肽。例如,A族包括与大肠杆菌TyrRS的Tyr37相对应位置上的缬氨酸、异亮氨酸、亮氨酸、甘氨酸、丝氨酸、丙氨酸或苏氨酸。B族包括与大肠杆菌TyrRS的Asn126相对应位置上的天冬氨酸;C族包括与大肠杆菌TyrRS的Asp182相对应位置上的苏氨酸、丝氨酸、精氨酸、天冬酰胺或甘氨酸;D族包括与大肠杆菌TyrRS的Phel83相对应位置上的甲硫氨酸、丙氨酸、缬氨酸或酪氨酸;E族包括与大肠杆菌TyrRS的Leul86相对应位置上的丝氨酸、甲硫氨酸、缬氨酸、半胱氨酸、苏氨酸或丙氨酸。任何这些族组合的亚组也是本发明的特征。例如,在一个实施方式中,O-RS具有两种或多种选自与大肠杆菌TyrRS的Tyr37相对应位置上出现的缬氨酸、异亮氨酸、亮氨酸、或苏氨酸;与大肠杆菌TyrRS的Asp182相对应位置上的苏氨酸、丝氨酸、精氨酸、或甘氨酸;与大肠杆菌TyrRS的Phel83相对应位置上的甲硫氨酸、或酪氨酸;和与大肠杆菌TyrRS的Leul86相对应位置上的丝氨酸、或丙氨酸的氨基酸。在另一实施方式中,O-RS包括两种或多种选自与大肠杆菌TyrRS的Tyr37相对应位置上的甘氨酸、丝氨酸、或丙氨酸,与大肠杆菌TyrRS的Asnl26相对应位置上的天冬氨酸,与大肠杆菌TyrRS的Aspl82相对应位置上的天冬酰胺,与大肠杆菌TyrRS的Phel83相对应位置上的丙氨酸或缬氨酸和/或和与大肠杆菌TyrRS的Leul86相对应位置上的甲硫氨酸、缬氨酸、半胱氨酸、或苏氨酸。类似地,本发明多肽也包括含有SEQIDNO.:36-63(例如,36-47、48-63或36-63的任意其它亚组)和/或86中至少20个连续氨基酸的多肽,和如上述A-E族中的两个或多个氨基酸取代。也参见本文表4、6和/或表8。本发明多肽也包括包含任一上述多肽的保守变异的氨基酸序列。在一个实施方式中,组合物包括本发明多肽和赋形剂(例如,缓冲液、水、药学上可接受的赋形剂等)。本发明也提供与本发明多肽特异地免疫反应的抗体或抗血清。本发明也提供多核苷酸。本发明多核苷酸包括编码本发明感兴趣的蛋白或多肽或包括一个或多个选择密码子,或二者的多核苷酸。例如,本发明的多核苷酸包括,例如,含有SEQIDNO.:3-35(例如,3-19、20-35或序列3-35的任意其它亚组)、64-85中任意一个所列核苷酸序列的多核苷酸;与该多核苷酸序列互补或编码该多核苷酸序列的多核苷酸;和/或编码含有SEQIDNO.:36-63和/或86中任意一个所列氨基酸序列或其保守变异的多肽的多核苷酸。本发明的多核苷酸也包括编码本发明多肽的多核苷酸。类似地,在高严谨条件下与上述多核苷酸杂交的核酸超过基本上全长的核酸是本发明的多核苷酸。本发明的多核苷酸也包括编码多肽的多核苷酸,该多肽包含与天然产生的酪氨酰氨酰基-tRNA合成酶(TyrRS)(例如,SEQIDNO.:2)至少90%相同的氨基酸序列,和包含A-E族(上述)中所述的两个或多个突变。与上述多核苷酸和/或含有任一上述多核苷酸的保守变异的多核苷酸至少70%(或至少75%、至少80%、至少85%、至少90%、至少95%、至少98%、或至少99%或更多)相同的多核苷酸也包括在本发明的多核苷酸中。也参见本文的表4、表6和/或表8。在某些实施方式中,载体(例如,质粒、粘粒、噬菌体、病毒等)包含本发明的多核苷酸。在一个实施方式中,载体是表达载体。在另一实施方式中,表达载体包括可操作地连接于一种或多种本发明的多核苷酸的启动子。在另一实施方式中,细胞含有包括本发明的多核苷酸的载体。本领域技术人员也将理解,本发明包括公开序列的很多变体。例如,本发明包括产生功能相同序列的公开序列的保守变体。认为本发明包括与至少一种公开序列杂交的核酸多核苷酸序列的变体。本文公开序列的独特亚序列,如通过例如,标准序列对比技术确定的亚序列也包括在本发明中。保守变异由于遗传密码的简并,”沉默取代”(即不导致编码多肽改变的核酸序列中的取代)是每个编码氨基酸的核酸序列的暗指特征。类似地,用性质高度相似的不同氨基酸取代氨基酸序列的一种或几种氨基酸中的”保守氨基酸取代”,也容易地鉴定为与公开构建物高度相似。各公开序列的这种保守变异是本发明的特征。具体核苷酸序列的”保守变异”指编码相同或基本相同的氨基酸序列的核酸,或该核酸并不将氨基酸序列编码成基本相同的序列。本领域技术人员将认识到,在编码序列中改变、加入或去除单个氨基酸或小百分比(一般小于5%,更一般小于4%、2%或1%)的氨基酸进行的单独取代、缺失或加入是”保守的修饰变异”,其中改变导致氨基酸的缺失、氨基酸的加入或用化学上相似的氨基酸取代氨基酸。因此,本发明所列多肽序列的”保守变异”包括用相同保守取代基的保守选择氨基酸以小百分比,一般小于5%,更一般小于2%或1%取代多肽序列氨基酸。最后,加入并不改变核酸分子编码活性的序列,如非功能序列的加入,是基本核酸的保守变异。提供功能类似的氨基酸的保守取代表是本领域公知的。下面列出了包含互相”保守取代”的天然氨基酸的例子组。保守取代组1丙氨酸(A)丝氨酸(S)苏氨酸(T)2天冬氨酸(D)谷氨酸(E)3天冬酰胺(N)谷胺酰胺(Q)4精氨酸(R)赖氨酸(K)5异亮氨酸(I)亮氨酸(L)甲硫氨酸(M)缬氨酸(V)6苯丙氨酸(F)酪氨酸(Y)色氨酸(W)核酸杂交可以用比较杂交鉴定本发明核酸,包括本发明核酸的保守变异,该比较杂交法是区别本发明核酸的优选方法。此外,在高、超高和超超高严谨条件下与SEQIDNO:3-35(例如,3-19、20-35或序列3-35的任意其它亚组)、64-85代表的核酸杂交的靶核酸是本发明的特征。与给定核酸序列相比,所述核酸的例子包括具有一个或几个沉默或保守核酸取代的核酸。当测试核酸与探针的杂交至少相当于完美匹配的互补靶的1/2,即信噪比至少相当于探针与靶在下述条件下杂交信噪比的1/2时,认为测试核酸与探针核酸特异性杂交,在所述条件下,完美匹配探针与完美匹配互补靶结合的信噪比比杂交到任意不匹配靶核酸时观察到的信噪比至少高约5-10倍。当核酸一般在溶液中结合时,它们“杂交”。核酸因为各种良好表征的物理-化学力,如氢键、溶剂排斥、碱基堆积等杂交。在Tijssen(1993)《生物化学和分子生物学中的实验室技术--用核酸探针杂交》(LaboratoryTechniquesinBiochemistryandMolecularBiology--HybridizationwithNucleicAcidProbes)第2章第I部分,“杂交原理和核酸探针测定的策略概要”(Overviewofprinciplesofhybridizationandthestrategyofnucleicacidprobeassays)(Elsevier,NewYork),和Ausubel(上述)中发现了核酸杂交的广泛指南。Hames和Higgins(1995)《基因探针1》(GeneProbes1)IRLPressatOxfordUniversityPress,Oxford,England,(Hames和Higgins1)以及Hames和Higgins(1995)《基因探针2》(GeneProbes2)IRLPressatOxfordUniversityPress,Oxford,England(Hames和Higgins2)提供了合成、标记、检测和定量DNA和RNA,包括寡核苷酸的细节。在Southern或Northern印迹中用于具有多于100个互补残基的互补核酸在滤膜上杂交的严谨杂交条件的例子是在含有1毫克肝素的50%福尔马林中42℃杂交过夜。严谨洗涤条件的例子是0.2xSSC在65℃下洗涤15分钟(SSC缓冲液的描述参见,Sambrook,上述)。高严谨洗涤之前是低严谨洗涤,以去除背景探针信号。低严谨洗涤的例子是2xSSC在40℃下洗涤15分钟。通常具体杂交测定中,信噪比比不相关探针中观察到的高5倍(或更高)表明检测到了特异性杂交。核酸杂交实验,如Southern和Northern杂交的内容中“严谨杂交洗涤条件”是序列依赖性的,而且在不同环境参数下是不同的。在Tijssen(1993)(上述)和Hames和Higgins,1和2中发现了核酸杂交的广泛指南。可以容易地经验性确定任何测试核酸的严谨杂交和洗涤条件。例如,在确定高严谨杂交和洗涤条件时,逐渐增加杂交和洗涤条件(例如,通过提高温度、降低盐浓度、提高去垢剂浓度和/或提高有机溶剂,如杂交或洗涤中的福尔马林的浓度),直到负荷一组选择标准。例如,杂交和洗涤条件逐渐增加,直到探针与完美配对互补靶结合的信噪比比探针与不匹配靶杂交时所观察到的信噪比至少高约5倍。选择“非常严谨”条件,以等于具体探针的热熔点(Tm)。Tm是50%测试序列与完美匹配探针杂交的温度(在限定的离子强度和pH下)。为本发明目的,通常将“高严谨”杂交和洗涤条件选择为低于具体序列在限定的离子强度和pH下的Tm约5℃。“超高严谨”杂交和洗涤条件是增加了杂交和洗涤条件的严谨性,直到探针与完美匹配互补靶核酸的结合信噪比是与任意不匹配靶核酸杂交中所观察到的信噪比至少高10倍的条件。在这种条件下与探针杂交的靶核酸,其信噪比是完美匹配互补靶核酸的至少1/2,认为在超高严谨条件下与探针结合。类似地,甚至可以通过逐渐增加相关杂交测定的杂交和/或洗涤条件确定更高水平的严谨性。例如,在那些条件中,增加了杂交和洗涤条件的严谨性,直到探针和完美匹配互补靶核酸结合的信噪比是与任意不匹配靶核酸杂交中所观察到的信噪比至少高lO倍、20倍、50倍、100倍或500倍或更高。与探针在所述条件下杂交的靶核酸,其信噪比是完美匹配互补靶核酸的至少1/2,认为在超超高严谨条件下与探针结合。如果它们编码的多肽基本相同,那么在严谨条件下不互相杂交的核酸仍是基本相同的。这发生在,例如,用遗传密码允许的最大密码子简并产生核酸的拷贝时。独特的亚序列在一个方面,本发明提供了核酸,该核酸包含选自本文公开的0-tRNA和O-RS序列的核酸中独特的亚序列。与任何已知O-tRNA或O-RS核酸序列相对应的核酸相比,该独特的亚序列是独特的。可以用,例如,设置为默认参数的BLAST进行对比。任何独特亚序列都是有用的,例如,作为探针鉴定本发明核酸。类似地,本发明包括多肽,该多肽包含选自本文公开的O-RS序列的多肽中独特的亚序列。这里,与任何已知多肽序列相对应的多肽相比,独特的亚序列是独特的。本发明也提供在严谨条件下与独特的编码寡核苷酸杂交的靶核酸,该寡核苷酸编码选自O-RS序列的多肽中独特的亚序列,其中与任意对照多肽(例如,从其例如,通过突变获得本发明合成酶的亲代序列)相对应的多肽相比,独特的亚序列是独特的。如上所述地确定独特的序列。序列比较,同一性和同源性当采用,如下述序列比较算法之一(或本领域技术人员可用的其它算法)或通过视觉检查测量以比较和对比最大一致性时,在两种或多种核酸或多肽序列内容中的术语“相同”或“同一性”百分数指两种或多种相同或具有特定的氨基酸残基或核苷酸相同百分数的序列或亚序列。当用序列比较算法或通过视觉检查测量以比较和对比最大一致性时,在两种核酸或多肽(例如,编码O-tRNA或O-RS的DNA,或O-RS的氨基酸序列)内容中的术语“基本相同”指两种或多种具有至少约60%,优选80%,最优选90-95%核苷酸或氨基酸残基同一性的序列或亚序列。在没有参考实际祖先的情况下,一般认为“基本相同”的序列是“同源”的。优选地,在长度至少约50个残基的序列区域上,更优选在至少约100个残基的区域上存在“基本同一性”,最优选地,在至少约150个残基,或待比较的两个全长序列上存在“基本同一性”。对于序列比较和同源性确定来说,一般将一个序列用作参比序列,将测试序列序列与它作比较。当使用序列比较算法时,将测试和参比序列输入计算机,如果需要的话指定亚序列坐标,指定序列算法程序参数。然后该序列比较算法根据指定的程序参数,计算测试序列相对于参比序列的序列同一性百分数。可以通过,例如,Smith和Waterman的局部同源算法,Adv.Appl.Math.2:482(1981),Needleman和Wunsch的同源对比算法,J.Mol.Biol.48:443(1970),Pearson和Lipman的搜索相似性方法,Proc.Nat'l.Acad.Sci.USA85:2444(1988),这些算法的计算机化执行(Wisconsin遗传学软件包中的GAP、BESTFIT、FASTA和TFASTA,遗传学计算机组(GeneticsComputerGroup),575ScienceDr.,Madison,WI)或视觉检查(通常参见,Ausubel等,下述)为比较进行最优化的序列对比。一个适合于确定序列同一性百分数和序列相似性的算法例子是BLAST算法,Altschul等,J.Mol.Biol.215:403-410(1990)中描述了这种算法。可通过国家生物技术信息中心(www.ncbi.nlm.nih.gov/)公开地得到进行BLAST分析的软件。该算法包括,首先通过鉴定查询序列中长度W的短字鉴定高分的序列对(HSP),当与数据库序列中相同长度的字对比时,查询序列匹配或满足一些正评价的阈值分数T。T称为邻近字分数阈值(Altschul等,上述)。这些起始邻近字命中(wordhits)用作起始搜索寻找含有它们的更长HSP的种子。然后字命中在沿各序列的两个方向上延伸,以尽量增加累积对比分数。对于核苷酸序列,用参数M(匹配残基对的奖励分数;总是>0)和N(错配残基的惩罚分数;总是<0)计算累积分数。对于氨基酸序列,用计分矩阵计算累积分数。当:累积对比分数通过来自其最大获得值的参数X下降时;由于一种或多种负得分残基对比使累积分数达到零或零以下;或达到各序列的末端时,停止延伸各方向上的字命中。BLAST算法参数W、T和X确定对比的灵敏性和速度。BLASTN程序(用于核苷酸序列)使用的默认设置为字长(W)11、期望值(E)10、截断值100、M=5、N=-4和两条链的比较。对于氨基酸序列,BLASTP程序使用的默认设置为字长(W)3、期望值(E)10和BLOSUM62计分矩阵(参见Henikoff和Henikoff(1989)Proc.Natl.Acad.Sci.USA89:10915)。除了计算序列同一性百分数之外,BLAST算法也对两种序列之间的相似性进行统计分析(参见,例如,Karlin&Altschul,Proc.Nat'1.Acad.Sci.USA90:5873-5787(1993))。BLAST算法提供的一种测量相似性的方法是最小总和概率(P(N)),它提供了概率说明,这种概率下两种核苷酸或氨基酸序列之间偶然发生匹配。例如,如果在测试核酸和参比核酸的比较中最小总和概率小于约0.1、更优选小于约0.01、最优选小于约0.001,则认为核酸与参比序列相似。诱变和其他分子生物学技术描述分子生物学技术的普通教科书包括Berger和Kimmel,分子克隆技术指南,《酶学方法》第152卷(GuidetoMolecularCloningTechniques,MethodsinEnzymology)AcademicPress,Inc.,SanDiego,CA(Berger);Sambrook等,《分子克隆-实验室手册》(MolecularCloning-ALaboratoryManual)(第二版),第1-3卷,ColdSpringHarborLaboratory,ColdSpringHarbor,NewYork,1989(“Sambrook”)和《新编分子生物学实验指南》(CurrentProtocolsinMolecularBiology),F.M.Ausubel等编,CurrentProtocols,它是GreenePublishingAssociates,Inc.和JohnWiley&Sons,Inc.的合资公司,(1999年起增补)(“Ausubel”))。这些教科书描述了诱变、载体的用途、启动子和很多其它与,如基因产生相关的主题,包括用于生产包括非天然氨基酸、正交tRNA、正交合成酶和它们的对在内的蛋白的选择密码子。本发明使用各种类型的诱变,例如,以产生tRNA文库,以产生合成酶文库,以将编码非天然氨基酸的选择密码子插入感兴趣的蛋白或多肽。它们包括但不限于定位诱变、随机点诱变,同源重组、DNA改组或其它递归诱变方法,嵌合构建,用含有尿嘧啶模板的诱变,寡核苷酸-导向的诱变,硫代磷酸-修饰的DNA诱变,用缺口双链体DNA诱变等,或它们的任意组合。其它合适的方法包括点错配修复、用修复缺陷型宿主株诱变、限制性选择和限制性纯化、缺失诱变、通过全基因合成诱变、双链断裂修复等。本发明也包括例如,包括嵌合构建物的诱变。在一个实施方式中,可以根据天然产生分子或改变的或突变的天然产生分子的已知信息指导诱变,例如,序列,序列比较、物理性质、晶体结构等。本文的上述内容和例子描述了这些步骤。在下面的出版物和引用参考文献中可以找到附加信息:Ling等,DNA诱变方法:概要(ApproachestoDNAmutagenesis:anoverview),AnalBiochem.254(2):157-178(1997);Dale等,用硫代磷酸法进行寡核苷酸-导向的随机诱变(Oligonucleotide-directedrandommutagenesisusingthephosphorothioatemethod),MethodsMol.Biol.57:369-374(1996);Smith,体外诱变(Invitromutagenesis),Ann.Rev.Genet.19:423-462(1985);Botstein&Shortle,体外诱变的策略和应用(Strategiesandapplicationsofinvitromutagenesis),Science229:1193-1201(1985);Carter,定位诱变(Site-directedmutagenesis),Biochem.J.237:1-7(1986);Kunkel,寡核苷酸导向的诱变效率(Theefficiencyofoligonucleotidedirectedmutagenesis),刊于《核酸和分子生物学》(Acids&MolecularBiology)(Eckstein,F.和Lilley,D.M.J.编,SpringerVerlag,Berlin))(1987);Kunkel,无需表型选择的快速和有效的定位诱变(Rapidandefficientsite-specificmutagenesiswithoutphenotypicselection),Proc.Natl.Acad.Sci.USA82:488-492(1985);Kunkel等,无需表型选择的快速和有效的定位诱变(Rapidandefficientsite-specificmutagenesiswithoutphenotypicselection),MethodsinEnzymol.154,367-382(1987);Bass等,具有新DNA-结合特异性的突变Trp抑制物(MutantTrprepressorswithnewDNA-bindingspecificities),Science242:240-245(1988);MethodsinEnzymo.100:468-500(1983);MethodsinEnzymol.154:329-350(1987);Zoller&Smith,用来自Ml3的载体进行寡核苷酸-导向的诱变:在任意DNA片段中产生点突变的有效和通用方法(Oligonucleotide-directedmutagenesisusingMl3-derivedvectors:anefficientandgeneralprocedurefortheproductionofpointmutationsinanyDNAfragment),NucleicAcidsRes.10:6487-6500(1982);Zoller&Smith,克隆到M13载体中DNA片段的寡核苷酸-导向的诱变(Oligonucleotide-directedmutagenesisofDNAfragmentsclonedintoM13vectors),MethodsinEnzymol.100:468-500(1983);Zoller&Smith,寡核苷酸-导向的诱变:使用两种寡核苷酸引物和单链DNA模板的简单方法(Oligonucleotide-directedmutagenesis:asimplemethodusingtwooligonucleotideprimersandasingle-strandedDNAtemplate),MethodsinEnzymol.154:329-350(1987);Taylor等,硫代磷酸修饰的DNA在限制性酶反应制备缺口DNA中的用途(Theuseofphosphorothioate-modifiedDNAinrestrictionenzymereactionstopreparenickedDNA),Nucl.AcidsRes.13:8749-8764(1985);Taylor等,用硫代磷酸修饰的DNA高频率快速产生寡核苷酸-导向的突变(Therapidgenerationofoligonucleotide-directedmutationsathighfrequencyusingphosphorothioate-modifiedDNA),Nucl.AcidsRes.13:8765-8787(1985);Nakamaye&Eckstein,硫代磷酸基团抑制限制性核酸内切酶NciI切割及其在寡核苷酸-导向的诱变中的应用(InhibitionofrestrictionendonucleaseNciIcleavagebyphosphorothioategroupsanditsapplicationtooligonucleotide-directedmutagenesis),Nucl.AcidsRes.14:9679-9698(1986);Sayers等,在基于硫代磷酸的寡核苷酸-导向的诱变中的Y-T核酸外切酶(Y-TExonucleasesinphosphorothioate-basedoligonucleotide-directedmutagenesis),Nucl.AcidsRes.16:791-802(1988);Sayers等,通过在溴乙锭的存在下与限制性核酸内切酶反应链特异性切割含有硫代磷酸的DNA(Strandspecificcleavageofphosphorothioate-containingDNAbyreactionwithrestrictionendonucleasesinthepresenceofethidiumbromide),(1988)Nucl.AcidsRes.16:803-814;Kramer等,构建寡核苷酸-导向的突变的缺口双链体DNA方法(ThegappedduplexDNAapproachtooligonucleotide-directedmutationconstruction),Nucl.AcidsRes.12:9441-9456(1984);Kramer&Fritz通过缺口双链体DNA寡核苷酸-导向的构建突变(Oligonucleotide-directedconstructionofmutationsviagappedduplexDNA),MethodsinEnzymol.154:350-367(1987);Kramer等,用于寡核苷酸-导向的构建突变的缺口双链体DNA方法中改进的酶促体外反应(ImprovedenzymaticinvitroreactionsinthegappedduplexDNAapproachtooligonucleotide-directedconstructionofmutations),Nucl.AcidsRes.16:7207(1988);Fritz等,寡核苷酸-导向的构建突变:无需酶促体外反应的缺口双链体DNA方法(Oligonucleotide-directedconstructionofmutations:agappedduplexDNAprocedurewithoutezymaticreactionsinvitro),Nucl.AcidsRes.16:6987-6999(1988);Kramer等,点错配修复(PointMismatchRepair),Cell38:879-887(1984);Carter等,用M13载体改进的寡核苷酸定位诱变(Improvedoligonucleotidesite-directedmutagenesisusingM13vectors),Nucl.AcidsRes.13:4431-4443(1985);Carter,用M13载体改进的寡核苷酸-导向的诱变(Improvedoligonucleotide-directedmutagenesisusingM13vectors),MethodsinEnzymol.154:382-403(1987);Eghtedarzadeh&Henikoff,寡核苷酸用于产生大缺失(Useofoligonucleotidestogeneratelargedeletions),Nucl.AcidsRes.14:5115(1986);Wells等,在稳定枯草杆菌蛋白酶的过渡态中氢键形成的重要性(Importanceofhydrogen-bondformationinstabilizingthetransitionstateofsubtilisin),Phil.Trans.R.Soc.Lond.A317:415-423(1986);Nambiar等,编码核糖核酸酶S蛋白的基因全合成和克隆(TotalsynthesisandcloningofagenecodingfortheribonucleaseSprotein),Science223:1299-1301(1984);Sakamar和Khorana,牛杆菌外节段鸟嘌呤核苷酸-结合蛋白(转导蛋白)的α-亚基的基因全合成和表达(Totalsynthesisandexpressionofagenefortheα-subunitofbovinerodoutersegmentguaninenucleotide-bindingprotein(transducin)),Nucl.AcidsRes.14:6361-6372(1988);Wells等,盒式诱变:在限定位点产生多突变的有效方法(Cassettemutagenesis:anefficientmethodforgenerationofmultiplemutationsatdefinedsites),Gene34:315-323(1985);等,通过微量的‘鸟枪法’基因合成进行寡核苷酸-导向的诱变(Oligonucleotide-directedmutagenesisbymicroscale'shot-gun'genesynthesis),Nucl.AcidsRes.13:3305-3316(1985);Mandecki,大肠杆菌质粒中寡核苷酸-导向的双链断裂修复:定位诱变方法(Oligonucleotide-directeddouble-strandbreakrepairinplasmidsofEscherichiacoli:amethodforsite-specificmutagenesis),Proc.Natl.Acad.Sci.USA,83:7177-7181(1986);Arnold,用于不平常环境的蛋白工程(Proteinengineeringforunusualenvironments),CurrentOpinioninBiotechnology4:450-455(1993);Sieber等,NatureBiotechnology,19:456-460(2001).W.P.C.Stemmer,Nature370,389-91(1994);和I.A.Lorimer,I.Pastan,NucleicAcidsRes.23,3067-8(1995)。上述很多方法的其它详情可参见MethodsinEnzymology第154卷,它也描述了有用的措施,以解决各种诱变方法中出现的故障问题。本发明也涉及真核宿主细胞和生物,用于通过正交tRNA/RS对体内掺入非天然氨基酸。用本发明的多核苷酸或包括本发明的多核苷酸的构建物,例如本发明载体,可以是,如克隆载体或表达载体遗传改造的(例如,转化、转导或转染)宿主细胞。载体可以是,如质粒、细菌、病毒、裸露的多核苷酸或共轭多核苷酸的形式。通过标准方法,包括电穿孔(From等,Proc.Natl.Acad.Sci.USA82,5824(1985))、病毒载体感染、在小珠或颗粒的基质内或表面上通过具有核酸的小颗粒高速弹道渗透(Klein等,Nature327,70-73(1987))将载体引入细胞和/或微生物。可以在为适用于,如筛选步骤、激活启动子或选择转化株的活性而修改的常规营养培养基中培养改造的宿主细胞。可以将这些细胞任选地培养成转基因生物。其它用于,例如细胞分离和培养(如后续核酸分离)的有用参考文献包括Freshney(1994)《动物细胞培养,基本技术手册》(CultureofAnimalCells,aManualofBasicTechnique),第三版,Wiley-Liss,NewYork及其引用的参考文献;Payne等(1992)《在液体系统中培养植物细胞和组织》(PlantCellandTissueCultureinLiquidSystems)JohnWiley&Sons,Inc.NewYork,NY;Gamborg和Phillips(编)(1995)《植物细胞、组织和器官培养》(PlantCell,TissueandOrganCulture);《基本方法施普林格实验室手册》(FundamentalMethodsSpringerLabManual),Springer-Verlag(BerlinHeidelbergNewYork)和Atlas和Parks(编)《微生物培养基手册》(TheHandbookofMicrobiologicalMedia)(1993)CRCPress,BocaRaton,FL。将靶核酸引入细胞的几种公知方法是可用的,其中任何一个均可用于本发明。这些方法包括:将含有DNA的细菌原生质体与受体细胞融合、电穿孔、抛射体轰击和用病毒载体感染(下面进一步讨论)等。可将细菌细胞用于扩增含有本发明DNA构建物的质粒的数目。细菌生长到对数期,可通过本领域已知的各种方法分离细菌中的质粒(参见,例如,Sambrook)。此外,可从市场购得很多用于从细菌中纯化质粒的试剂盒(参见,例如,PharmaciaBiotech的EasyPrepTM、FlexiPrepTM;Stratagene的StrataCleanTM;和Qiagen的QIAprepTM)。然后进一步操纵分离和纯化的质粒,以生产其它质粒,用于转染细胞或掺入相关载体以感染生物体。典型载体包含用于调节具体靶核酸表达的转录和翻译终止子、转录和翻译起始序列,和启动子。载体任选地包含含有至少一个独立终止子序列、允许该盒在真核生物或原核生物或二者中复制的序列(如穿梭载体)和用于原核和真核系统的选择标记的普通表达盒。载体适合于在原核生物、真核生物或优选二者中复制和整合。参见,Giliman&Smith,Gene8:81(1979);Roberts,等,Nature,328:731(1987);Schneider,B.,等,ProteinExpr.Purif.6435:10(1995);Ausubel,Sambrook,Berger(上述)。例如ATCC,如《ATCC细菌和噬菌体目录》(TheATCCCatalogueofBacteriaandBacteriophage)(1992)Gherna等(编)ATCC出版,提供了用于克隆的细菌和噬菌体目录。用于测序、克隆和分子生物学其它方面的附加基本方法和基础理论考虑也参见Watson等(1992)《重组DNA》(RecombinantDNA)第二版ScientificAmericanBooks,NY。此外,实质上可从各种商业来源中任意一家定制或规范订购任意核酸(实际上任意贴商标的核酸,无论标准或非标准),如MidlandCertifiedReagentCompany(Midland,TXmcrc.com)、TheGreatAmericanGeneCompany(Ramona,CA可登录万维网genco.com)、ExpressGenInc.(Chicago,IL,可登录万维网expressgen.com)、OperonTechnologiesInc.(Alameda,CA)和很多其它公司。试剂盒试剂盒也是本发明特征。例如,提供了在细胞中生产含有至少一个非天然氨基酸的蛋白的试剂盒,其中该试剂盒包括含有编码O-tRNA的多核苷酸序列和/或O-tRNA,和/或编码O-RS的多核苷酸序列和/或O-RS的容器。在一个实施方式中,该试剂盒还包括至少一种非天然氨基酸。在另一实施方式中,该试剂盒还包含生产蛋白的说明材料。实施例提供下面的实施例是为了说明,而非限制本发明。本领域技术人员将认识到,可以在不背离本发明所要求保护的范围的情况下改变各种非重要的参数。实施例1:在真核细胞中掺入非天然氨基酸的氨酰基-tRNA合成酶的生产方法和组合物扩展真核生物遗传密码以包括具有新的物理、化学或生物性质的非天然氨基酸,为在这些细胞中分析和控制蛋白功能提供有力工具。为此目的,描述了在酿酒酵母(S.cerevisiae)中用于分离响应于琥珀密码子以高保真度将非天然氨基酸掺入蛋白中的氨酰基-tRNA合成酶。该方法基于通过在GAL4的DNA结合域和转录激活域之间抑制琥珀密码子,激活GAL4反应性报道基因HIS3、URA3或LacZ。描述了用于正选择活性大肠杆菌酪氨酰-tRNA合成酶(EcTyrRS)变体的GAL4报道基因的最优化。也开发了用URA3报道基因进行失活EcTyrRS变体的负选择,该报道基因使用加入生长培养基作为‘有毒等位基因’的小分子(5-氟乳清酸(5-FOA))。重要的是,可以在单细胞上以一定范围的严格性进行正和负选择。这可有助于从大的突变体合成酶文库中分离一定范围的氨酰基-tRNA合成酶(aaRS)活性。模型选择证明了该方法用于分离所需aaRS表型的功效。最近,将非天然氨基酸加入大肠杆菌(E.coli)的遗传密码中提供了在体外和体内分析和操纵蛋白质结构和功能的有效的新手段。以与普通的二十种氨基酸相匹敌的效率和保真度,将具有光亲和标记、重原子、酮和烯烃基的氨基酸和生色团掺入大肠杆菌中的蛋白质中。参见,例如,Chin,等,(2002),将光交联剂加入到大肠杆菌的遗传密码中(AdditionofaPhotocrosslinkertotheGeneticCodeofEscherichiacoli),Proc.Natl.Acad.Sci.U.S.A.99:11020-11024;Chin和Schultz,(2002),体内用非天然氨基酸诱变进行光交联(InvivoPhotocrosslinkingwithUnnaturalAminoAcidMutagenesis),ChemBioChem11:1135-1137;Chin等,(2002),将对-叠氮基-L-苯丙氨酸加入大肠杆菌的遗传密码中(Additionofp-Azido-L-phenylalaninetotheGeneticcodeofEscherichiacoli),J.Am.Chem.Soc.124:9026-9027;Zhang等,(2002),将链烯选择性掺入大肠杆菌中的蛋白(TheselectiveincorporationofalkenesintoproteinsinEscherichiacoli),Angew.Chem.Int.Ed.Engl.41:2840-2842;以及Wang和Schultz,(2002),扩展遗传密码(ExpandingtheGeneticCode),Chem.Comm.1-10。以前,已经通过显微注射化学错酰化的嗜热四膜虫tRNA(例如,M.E.Saks,等(1996),用于通过无义抑制将非天然氨基酸体内掺入蛋白质的工程四膜虫tRNAGln(AnengineeredTetrahymenatRNAGlnforinvivoincorporationofunnaturalaminoacidsintoproteinsbynonsensesuppression),J.Biol.Chem.271:23169-23175)和相关mRNA,将非天然氨基酸引入爪蟾卵母细胞中的烟碱性乙酰胆碱受体中(例如,M.W.Nowak,等(1998),将非天然氨基酸体内掺入爪蟾卵母细胞表达系统的离子通道中(InvivoincorporationofunnaturalaminoacidsintoionchannelsinXenopusoocyteexpressionsystem),MethodEnzymol.293:504-529)。这允许了通过引入含有具独特物理或化学性质的侧链的氨基酸对卵母细胞中的受体进行详细的生物物理学研究。参见,例如,D.A.Dougherty(2000),作为蛋白结构和功能探针的非天然氨基酸(Unnaturalaminoacidsasprobesofproteinstructureandfunction),Curr.Opin.Chem.Biol.4:645-652。不幸的是,该方法仅限于可以进行显微注射的细胞中的蛋白质,因为tRNA在体外被化学酰化,不能被再酰化,所以蛋白产率非常低。这反过来使测定蛋白功能的灵敏技术成为必需。在真核细胞中响应于琥珀密码子,将非天然氨基酸遗传掺入蛋白质中引起了大家的兴趣。也参见,H.J.Drabkin等,(1996),哺乳动物细胞中的琥珀抑制取决于大肠杆菌氨酰基-tRNA合成酶基因的表达(AmbersuppressioninmammaliancellsdependentuponexpressionofanEscherichiacoliaminoacyl-tRNAsynthetasegene),Molecular&CellularBiology16:907-913;A.K.Kowal,等,(2001),第二十一个氨酰基-tRNA合成酶-抑制型tRNA对在真核生物和真细菌中将氨基酸类似物位点特异性掺入蛋白中的可能用途(Twenty-firstaminoacyl-tRNAsynthetase-suppressortRNApairsforpossibleuseinsite-specificincorporationofaminoacidanaloguesintoproteinsineukaryotesandineubacteria),[评论],Proc.Natl.Acad.Sci.U.S.A.98:2268-2273;和K.Sakamoto,等,(2002),在哺乳动物细胞中将非天然氨基酸位点特异性掺入蛋白质中(Site-specificincorporationofanunnaturalaminoacidintoproteinsinmammaliancells),NucleicAcidsRes.30:4692-4699。这将具有显著的技术和实践优点,因为tRNA的关联合成酶将对其进行再酰化-导致产生大量突变蛋白。而且,遗传编码的氨酰基-tRNA合成酶和tRNA原则上是可遗传的,允许非天然氨基酸通过很多代细胞分裂掺入蛋白中,而没有指数稀释。已经描述了将新氨基酸加入到大肠杆菌的遗传密码中的必需步骤(参见,例如,D.R.Liu和P.G.Schultz,(1999),具有扩展遗传密码的生物进化的进展(Progresstowardtheevolutionofanorganismwithanexpandedgeneticcode),Proc.Natl.Acad.Sci.U.S.A.96:4780-4785;类似原理可用于扩展真核生物的遗传密码。第一步,鉴定正交氨酰基-tRNA合成酶(aaRS)/tRNACUA对。该对需要与宿主细胞翻译机器一起作用,但是aaRS不应该使任何内源性tRNAs具有氨基酸,tRNACUA不应该被任何内源性合成酶氨酰化。参见,例如,D.R.Liu,等,设计用于在体内将非天然氨基酸位点特异性掺入蛋白质中的tRNA和氨酰基-tRNA合成酶(EngineeringatRNAandaminoacyl-tRNAsynthetaseforthesite-specificincorporationofunnaturalaminoacidsintoproteinsinvivo),Proc.Natl.Acad.Sci.U.S.A.94:10092-10097。第二步,从突变体aaRS文库中选择那些能够仅用非天然氨基酸的aaRS/tRNA对。在大肠杆菌中,利用MjTyrRS的变体选择非天然氨基酸是通过采用两步‘双筛’选择进行的。参见,例如,D.R.Liu和P.G.Schultz,(1999),具有扩展遗传密码的生物进化的进展(Progresstowardtheevolutionofanorganismwithanexpandedgeneticcode),Proc.Natl.Acad.Sci.U.S.A.96:4780-4785。在真核细胞中使用修饰的选择方法。将酿酒酵母(S.cerevisiae)选作真核宿主生物,因为它是单细胞,具有快速的世代时间,并且已相当良好地表征了遗传学特征。参见,例如,D.Burke,等,(2000)《酵母遗传学方法》(MethodsinYeastGenetics),ColdSpringHarborLaboratoryPress,ColdSpringHarbor,NY。而且,因为真核生物的翻译机器是高度保守的(参见,例如,(1996)《翻译控制》(TranslationalControl),ColdSpringHarborLaboratoryPress,ColdSpringHarbor,NY;Y.Kwok和J.T.Wong,(1980),用氨酰基-tRNA合成酶作为系统发育探针确定红皮盐杆菌和真核生物之间的进化关系(EvolutionaryrelationshipbetweenHalobacteriumcutirubrumandeukaryotesdeterminedbyuseofaminoacyl-tRNAsynthetasesasphylogeneticprobes),CanadianJournalofBiochemistry58:213-218;和(2001)《核糖体》(TheRibosome),ColdSpringHarborLaboratoryPress,ColdSpringHarbor,NY),很可能,发现于酿酒酵母用于掺入非天然氨基酸的aaRS基因可被‘切割和粘贴’到高级真核生物中,与关联tRNAs合作使用(参见,例如,K.Sakamoto,等,(2002)在哺乳动物细胞中将非天然氨基酸位点特异性掺入蛋白质中(Site-specificincorporationofanunnaturalaminoacidintoproteinsinmammaliancells),NucleicAcidsRes.30:4692-4699;和C.Kohrer,等,(2001),将琥珀和赭石抑制型tRNAs输入哺乳动物细胞:将氨基酸类似物位点特异性插入蛋白质中的通用方法(ImportofamberandochresuppressortRNAsintomammaliancells:ageneralapproachtosite-specificinsertionofaminoacidanaloguesintoproteins),Proc.Natl.Acad.Sci.U.S.A.98:14310-14315)以掺入非天然氨基酸。因此,酿酒酵母遗传密码的扩展是扩展复杂多细胞真核生物的遗传密码的途径。参见,例如,M.Buvoli,等,(2000),在细胞培养和小鼠中通过多聚体化的抑制型tRNA基因抑制无义突变(SuppressionofnonsensemutationsincellcultureandmicebymultimerizedsuppressortRNAgenes),Molecular&CellularBiology20:3116-3124。来源于以前用于扩展大肠杆菌遗传密码的詹氏甲烷球菌TyrRS(MjTyrRS)/tRNA(参见例如,L.Wang和P.G.Schultz,(2002),扩展遗传密码(ExpandingtheGeneticCode),Chem.Comm.1-10)的酪氨酰对在真核生物中不是正交的(例如,P.Fechter,等,(2001),詹氏甲烷球菌和酿酒酵母tRNA(Tyr)中的主要酪氨酸决定子是保守的但表达不同(MajortyrosineidentitydeterninantsinMethanococcusjannaschiiandSaccharomycescerevisiaetRNA(Tyr)areconservedbutexpresseddifferently),Eur.J.Biochem.268:761-767),需要新的正交对以扩展真核生物遗传密码。Schimmel和同事们指出,在酿酒酵母中,大肠杆菌酪氨酰-tRNA合成酶(EcTyrRS)/tRNACUA对抑制琥珀密码子;以及在酵母细胞溶胶中,内源性氨酰基tRNA合成酶不载有大肠杆菌tRNACUA(图2)。也参见,例如,H.Edwards,等,(1991),大肠杆菌酪氨酸转移RNA在酿酒酵母中是亮氨酸-特异性转移RNA(AnEscherichiacolityrosinetransferRNAisaleucine-specifictransferRNAintheyeastSaccharomycescerevisiae),Proc.Natl.Acad.Sci.U.S.A.88:1153-1156;以及H.Edwards和P.Schimmel(1990),细菌氨酰基-tRNA合成酶选择性识别酿酒酵母中的细菌琥珀抑制子(AbacterialambersuppressorinSaccharomycescerevisiaeisselectivelyrecognizedbyabacterialaminoacyl-tRNAsynthetase),Molecular&CellularBiology10:1633-1641。此外,EcTyrRS已显示并不在体外载有酵母tRNA。参见,例如,Y.Kwok和J.T.Wong,(1980),用氨酰基-tRNA合成酶作为系统发育探针确定红皮盐杆菌和真核生物之间的进化关系(EvolutionaryrelationshipbetweenHalobacteriumcutirubrumandeukaryotesdeterminedbyuseofaminoacyl-tRNAsynthetasesasphylogeneticprobes),CanadianJournalofBiochemistry58:213-218;B.P.Doctor,等,(1966),酵母和大肠杆菌酪氨酸tRNA的种特异性的研究(StudiesonthespeciesspecificityofyeastandE.colityrosinetRNAs),ColdSpringHarborSymp.Quant.Biol.31:543-548;和K.Wakasugi,等,(1998),进化中的遗传密码:将种特异性氨酰化与肽移植物交换(Geneticcodeinevolution:switchingspecies-specificaminoacylationwithapeptidetransplant),EMBOJournal17:297-305。因此,EcTyrRS/tRNACUA对是酿酒酵母以及高级真核生物中正交对的候选物(例如,A.K.Kowal,等,(2001),第二十一个氨酰基-tRNA合成酶-抑制型tRNA对在真核生物和真细菌中将氨基酸类似物位点特异性掺入蛋白中的可能用途(Twenty-firstaminoacyl-tRNAsynthetase-suppressortRNApairsforpossibleuseinsite-specificincorporationofaminoacidanaloguesintoproteinsineukaryotesandineubacteria),[评论],Proc.Natl.Acad.Sci.U.S.A.98(2001)2268-2273)。为了扩展大肠杆菌中EcTyrRS的底物特异性,Nishimura和同事们筛选了易出错的PCR产生的EcTyrRS突变体文库,发现了具有改进的掺入3-氮酪氨酸能力的突变体。参见,例如,F.Hamano-Takaku,等,(2000),突变大肠杆菌酪氨酰tRNA合成酶利用非天然氨基酸氮酪氨酸比利用酪氨酸更有效率(AmutantEscherichiacolityrosyltRNAsynthetaseutilizestheunnaturalaminoacidazatyrosinemoreefficientlythantyrosine),J.Biol.Chem.275:40324-40328。然而,该氨基酸掺入整个大肠杆菌蛋白质组中,产生的酶仍然优选酪氨酸作为底物。Yokoyama和同事们在麦胚翻译系统中筛选了一小部分设计的EcTyrRS活性位点变体,发现了利用3-碘化酪氨酸比利用酪氨酸更有效率的EcTyrRS变体。参见,D.Kiga,等,(2002),在真核翻译中将非天然氨基酸位点特异性掺入蛋白中的工程大肠杆菌酪氨酰-tRNA合成酶及其在麦胚无细胞体系中的应用(AnengineeredEscherichiacolityrosyl-tRNAsynthetaseforsite-specificincorporationofanunnaturalaminoacidintoproteinsineukaryotictranslationanditsapplicationinawheatgermcell-freesystem),Proc.Natl.Sci.U.S.A.99:9715-9720。与我们在大肠杆菌中开发的酶相反(例如,J.W.Chin,等,(2002),将光交联剂加入到大肠杆菌的遗传密码中(AdditionofaPhotocrosslinkertotheGeneticCodeofEscherichiacoli),Proc.Natl.Acad.Sci.U.S.99:11020-11024;J.W.Chin,等,(2002),将对-叠氮基-L-苯丙氨酸加入大肠杆菌的遗传密码中(Additionofp-Azido-L-phenylalaninetotheGeneticcodeofEscherichiacoli),J.Am.Chem.Soc.124:9026-9027;L.Wang,等,(2001),扩展大肠杆菌的遗传密码(ExpandingtheGeneticCodeofEscherichiacoli),Science292:498-500;和L.Wang,等,(2002),将L-3-(2-萘基)丙氨酸加入大肠杆菌的遗传密码中(AddingL-3-(2-naphthyl)alaninetothegeneticcodeofE-coli),J.Am.Chem.Soc.124:1836-1837),该酶在没有非天然氨基酸的情况下仍然掺入酪氨酸。参见,例如,D.Kiga等,(2002),在真核翻译中将非天然氨基酸位点特异性掺入蛋白中的工程大肠杆菌酪氨酰-tRNA合成酶及其在麦胚无细胞体系中的应用(AnengineeredEscherichiacolityrosyl-tRNAsynthetaseforsite-specificincorporationofanunnaturalaminoacidintoproteinsineukaryotictranslationanditsapplicationinawheatgermcellfreesystem),Proc.Natl.Acad.Sci.U.S.A.99:9715-9720。最近,Yokoyama和同事们也证明在哺乳动物细胞中该EcTyrRS突变体与来自嗜热脂肪芽孢杆菌的tRNACUA一起作用以抑制琥珀密码子。参见,K.Sakamoto,等,(2002),在哺乳动物细胞中将非天然氨基酸位点特异性掺入蛋白中,NucleicAcidsRes.30:4692-4699。要求任何加入真核遗传密码的氨基酸以类似于普通的二十种氨基酸的保真度掺入。为了完成这个目的,用通常体内选择方法以发现在酿酒酵母中起作用响应于琥珀密码子TAG,掺入非天然氨基酸而非普通氨基酸的EcTyrRS/tRNACUA变体。选择的主要优点是可以从108EcTyrRS活性位点变体文库中迅速选择并富集选择性掺入非天然氨基酸的酶,这比体外筛选的多样性多6-7个数量级。参见,例如,D.Kiga,等,(2002),在真核翻译中将非天然氨基酸位点特异性掺入蛋白中的工程大肠杆菌酪氨酰-tRNA合成酶及其在麦胚无细胞体系中的应用(AnengineeredEscherichiacolityrosyl-tRNAsynthetaseforsite-specificincorporationofanunnaturalaminoacidintoproteinsineukaryotictranslationanditsapplicationinawheatgermcell-freesystem),Proc.Natl.Acad.Sci.U.S.A.99:9715-9720。这种多样性的增加大大增加了分离EcTyrRS变体的可能性,变体用于以非常高的保真度掺入各种不同的有用功能。参见,例如,L.Wang和P.G.Schultz,(2002),扩展遗传密码(ExpandingtheGeneticCode),Chem.Comm.1-10。为了延伸酿酒酵母的选择方法,使用了转录激活蛋白、GAL4(参见图1)。参见,例如,A.Laughon,等,(1984),鉴定两种通过酿酒酵母GAL4基因编码的蛋白(IdentificationoftwoproteinsencodedbytheSaccharomycescerevisiaeGAL4gene),Molecular&CellularBiology4:268-275;A.Laughon和R.F.Gesteland,(1984),酿酒酵母GAL4基因的一级结构(PrimarystructureoftheSaccharomycescerevisiaeGAL4gene),Molecular&CellularBiology4:260-267;L.Keegan,等,(1986),从真核调节蛋白的转录-激活功能中分离DNA结合(SeparationofDNAbindingfromthetranscription-activatingfunctionofaeukaryoticregulatoryprotein),Science231:699-704;和M.Ptashne,(1988),真核转录激活物是如何工作的(Howeukaryotictranscriptionalactivatorswork),Nature335:683-689。该881个氨基酸的蛋白N-末端147个氨基酸形成DNA结合域(DBD),它与DNA序列特异地结合。参见,例如,M.Carey,等,(1989),GAL4的氨基-末端片段与DNA结合成二聚体(Anamino-terminalfragmentofGAL4bindsDNAasadimer),J.Mol.Biol.209:423-432;和E.Giniger,等,(1985),GAL4,一种酵母阳性调节蛋白的特异性DNA结合(SpecificDNAbindingofGAL4,apositiveregulatoryproteinofyeast),Cell40:767-774。由间插蛋白序列将DBD连接到C-末端113个氨基酸的激活域(AD),当该激活域与DNA结合时可激活转录。参见,例如,J.Ma和M.Ptashne,(1987),GAL4的缺失分析限定了两种转录激活节段(DeletionanalysisofGAL4definestwotranscriptionalactivatingsegments),Cell48:847-853:和J.Ma和M.Ptashne,(1987),GAL80识别GAL4羧基-末端的30个氨基酸(Thecarboxy-terminal30aminoacidsofGAL4arerecognizedbyGAL80),Cell50:137-142。我们想像,通过将琥珀密码子置于含有GAL4的N-末端DBD和它的C-末端AD的单个多肽的N-末端DBD处,通过EcTyrRS/tRNACUA对的琥珀抑制可以与通过GAL4的转录激活连接(图1,A组)。通过选择合适的GAL4激活的报道基因,正和负选择都可以用该基因进行(图1,B组)。虽然很多基于补充细胞的氨基酸营养缺陷型报道基因可以用于正选择(如URA3,LEU2,HISS,LYS2),但HISS基因是吸引人的报道基因,因为可以通过加入3-氨基三唑(3-AT)以剂量依赖方式调节它编码的蛋白的活性(咪唑甘油磷酸脱氢酶)。参见,例如,G.M.Kishore和D.M.Shah,(1988),作为除草剂的氨基酸生物合成抑制剂(Aminoacidbiosynthesisinhibitorsasherbicides),AnnualReviewofBiochemistry57:627-663。在酿酒酵母中,较少基因已用于负选择。已经成功使用的几种负选择策略之一(参见,例如,A.J.DeMaggio,等,(2000),酵母分裂-杂交系统(Theyeastsplit-hybridsystem),MethodEnzymol.328:128-137;H.M.Shih,等,(1996),阳性遗传选择破坏蛋白-蛋白相互作用:鉴定阻止与辅激活物CBP结合的CREB突变(Apositivegeneticselectionfordisruptingprotein-proteininteractions:identificationofCREBmutations,thatpreventassociationwiththecoactivatorCBP),Proc.Natl.Acad.Sci.U.S.A.93:13896-13901;M.Vidal,等,(1996),用酵母反向双杂交系统遗传表征哺乳动物蛋白-蛋白相互作用域的遗传特征(Geneticcharacterizationofamammalianprotein-proteininteractiondomainbyusingayeastreversetwo-hybridsystem),[评论],Proc.Natl.Acad.Sci.U.S.A.93:10321-10326;和M.Vidal,等,(1996),反向双杂交和单杂交系统检测蛋白-蛋白解离和DNA-蛋白相互作用(Reversetwo-hybridandone-hybridsystemstodetectdissociationofprotein-proteinandDNA-proteininteractions),[评论],Proc.Natl.Acad.Sci.U.S.A.93:10315-10320)是在Vidal和同事们开发的‘反向双杂交’系统中描述的URA3/5-氟乳清酸(5-FOA)负选择(例如,J.D.Boeke,等,(1984),在酵母中正选择缺少乳清酸核苷-5'-磷酸脱羧酶活性的突变体:5-氟乳清酸抗性(Apositiveselectionformutantslackingorotidine-5’-phosphatedecarboxylaseactivityinyeast:5-fluorooroticacidresistance),Molecular&GeneralGenetics197:345-346)系统。参见,M.Vidal,等,(1996),用酵母反向双杂交系统遗传表征哺乳动物蛋白-蛋白相互作用域(Geneticcharacterizationofamammalianprotein-proteininteractiondomainbyusingayeastreversetwo-hybridsystem),[评论],Proc.Natl.Acad.Sci.U.S.A.93:10321-10326;和M.Vidal,等,(1996),反向双杂交和单杂交系统检测蛋白-蛋白解离和DNA-蛋白相互作用(Reversetwo-hybridandone-hybridsystemstodetectdissociationofprotein-proteinandDNA-proteininteractions),[评论],Proc.Natl.Acad.Sci.U.S.93:10315-10320)。在反向双杂交系统中,将基因组整合的URA3报道基因置于严密控制的启动子下,该启动子含有GAL4DNA结合位点。当相互作用的两种蛋白与GAL4DBD和GAL4AD产生融合时,它们就重建了GAL4的活性,并激活URA3的转录。在5-FOA存在下,URA3基因产物将5-FOA转化成有毒产物,杀死细胞。参见,J.D.Boeke,等,上述。将该选择用于选择破坏蛋白-蛋白相互作用的蛋白和选择破坏蛋白-蛋白相互作用的突变。也描述了用于筛选蛋白-蛋白相互作用的小分子抑制剂的变体。参见,例如,J.Huang和S.L.Schreiber,(1997)用于在纳米滴中选择蛋白-蛋白相互作用的小分子抑制剂的酵母遗传体系(Ayeastgeneticsystemforselectingsmallmoleculeinhibitorsofprotein-proteininteractionsinnanodroplets),Proc.Natl.Acad.Sci.U.S.A.94:13396-13401.在全长GAL4中琥珀密码子的合适选择允许用HIS3或URA3GAL4激活的报道基因有效正选择活性EcTyrRS变体,以在酵母细胞中补充组氨酸或尿嘧啶营养缺陷型。而且,URA3报道基因可以用于在5-FOA存在下负选择失活EcTyrRS变体。此外,可以将使用lacZ的比色测定用于读出酵母细胞中氨酰基-tRNA合成酶活性。结果和讨论在构建的ADH1启动子的控制下表达EcTyrRS基因,从相同的高拷贝酵母质粒(pEcTyrRStRNACUA,图1,C组)中表达tRNACUA基因。在pEcTyrRStRNACUA和低拷贝报道基因的共转化时,该报道基因在嵌入MaV203的GAL4构建物的DNA结合域和激活域之间含有单琥珀突变,细胞在缺少组氨酸和含有10-20mM3-AT的选择性培养基上生长(图2)。当MaV203细胞转染了相同的GAL4构建物和失活合成酶突变体(A5)或缺少EctRNA基因的构建物时,在10mM3-AT上没有观察到生长(图2)。这些实验确定EcTyrRS可以从ADH1启动子开始以功能形式构成地表达,在MaV203中有最小的内源性琥珀抑制,和在该系统中酵母合成酶几乎没有载有EctRNACUA。参见,例如,H.Edwards,等,(1991),大肠杆菌酪氨酸转移RNA在酿酒酵母中是亮氨酸-特异性转移RNA(AnEscherichiacolityrosinetransferRNAisaleucine-specifictransferRNAintheyeastSaccharomycescerevisiae),Proc.Natl.Acad.Sci.U.S.A.88:1153-1156;以及H.Edwards和P.Schimmel,(1990),细菌氨酰基-tRNA合成酶选择性识别酿酒酵母中的细菌琥珀抑制子(AbacterialambersuppressorinSaccharomycescerevisiaeisselectivelyrecognizedbyabacterialaminoacyl-tRNAsynthetase),Molecular&CellularBiology10:1633-1641。因为EcTyrRS不载有酿酒酵母tRNA(例如,Y.Kwok和J.T.Wong,(1980),用氨酰基-tRNA合成酶作为系统发育探针确定红皮盐杆菌和真核生物之间的进化关系(EvolutionaryrelationshipbetweenHalobacteriumcutirubrumandeukaryotesdeterminedbyuseofaminoacyl-tRNAsynthetasesasphylogeneticprobes),CanadianJournalofBiochemistry58:213-218;B.P.Doctor,等,(1966),酵母和大肠杆菌酪氨酸tRNA的种特异性的研究(StudiesonthespeciesspecificityofyeastandE.colityrosinetRNAs),ColdSpringHarborSymp.Quant.Biol.31:543-548;和K.Wakasugi,等,(1998),进化中的遗传密码:将种特异性氨酰化与肽移植物交换(Geneticcodeinevolution:switchingspecies-specificaminoacylationwithapeptidetransplant),EMBOJournal17:297-305),这些实验证实EcTyrRS/EctRNACUA在酿酒酵母中是正交对。虽然第一代GAL4嵌合体能够激活弱HIS3报道基因的转录,但是它不能在MaV203中激活URA3报道基因的转录足以在大于20mM的3-AT浓度上或在-URA平板上明显生长(图2)。为了选择EcTyrRS的目的,制成了变体第二代GAL4构建物。该GAL4报道基因被设计得更有活性,具有更大的动态范围,避免了回复体聚集。为了提高GAL4报道基因的活性,在强ADH1启动子的控制下使用全长GAL4(它的转录激活活性是DBD-AD融合体的两倍(参见,例如,J.Ma和M.Ptashne,(1987),GAL4的缺失分析限定了两种转录激活节段(DeletionanalysisofGAL4definestwotranscriptionalactivatingsegments),Cell48:847-853),并使用了高拷贝的2-微米质粒(拷贝数是起始GAL4嵌合体的着丝粒质粒的10-30倍)。质粒拷贝数和它编码的蛋白活性的增加应该延伸了报道基因的动态范围。琥珀突变是靶向编码氨基酸残基2和147的GAL4基因区域(图3)。该区域足够序列特异性DNA结合(参见,例如,M.Carey,等,(1989),GAL4的氨基-末端片段与DNA结合成二聚体(Anamino-terminalfragmentofGAL4bindsDNAasadimer),J.Mol.Biol.209:423-432),位于GAL4基因中第一隐蔽激活域的5'侧(参见,例如,J.Ma和M.Ptashne,(1987)GAL4的缺失分析限定了两种转录激活节段(DeletionanalysisofGAL4definestwotranscriptionalactivatingsegments),Cell48:847-853),Cell48:847-853),以使不预计在琥珀抑制不存在的情况下产生的截短产物能激活转录。氨基酸密码子的选择诱变由以前对GAL4的饱和诱变选择指导(参见,例如,M.Johnston和J.Dover,(1988),酿酒酵母GAL4-编码的转录激活蛋白的突变分析(MutationalanalysisoftheGAL4-encodedtranscriptionalactivatorproteinofSaccharomycescerevisiae),Genetics120:63-74),以及GAL4的N-末端DNA结合域的X射线结构(参见,例如,R.Marmorstein,等,(1992),通过GAL4进行DNA识别:蛋白-DNA复合物的结构(DNArecognitionbyGAL4:structureofaprotein-DNAcomplex),[评论],Nature356:408-414;和J.D.Baleja,等,(1992),酿酒酵母Cd2-GAL4的DNA-结合域的溶液结构(SolutionstructureoftheDNA-bindingdomainofCd2-GAL4fromS.cerevisiae),[评论],Nature356:450-453)和它的二聚化区域的NMR结构。参见,例如,P.Hidalgo,等,(2001),通过GAL11P募集转录机器:GAL4二聚化域的结构和相互作用(RecruitmentofthetranscriptionalmachinerythroughGAL11P:structureandinteractionsoftheGAL4dimerizationdomain),Genes&Development15:1007-1020。将全长GAL4克隆到基于小pUC的载体中,以通过定位诱变迅速构建10个单琥珀突变体(在氨基酸L3、I13、T44、F68、R110、V114、T121、I127、S131、T145的密码子处)。然后,在全长ADH1启动子的控制下将GAL4和产生的琥珀突变体亚克隆到2-微米的酵母载体中,以建立pGADGAL4和一系列称为pGADGAL4(xxTAG)的琥珀突变体(图1,C组),其中xx指GAL4基因中的突变为琥珀密码子的氨基酸密码子。用EcTyrRS/tRNACUA或A5/tRNACUA将各GAL4突变体共转化到MaV203细胞中,将转化子转化为亮氨酸和色氨酸原养型(protrophy)。pGADGAL4本身以非常低的效率转化(<GAL4琥珀突变体的10-3倍),在如此高拷贝下对MaV203细胞可能有毒;用GAL4的琥珀突变体没有观察到如此效果。在活性或死亡合成酶的存在下,在-URA平板和0.1%5-FOA平板上测定GAL4报道基因的表型(图3,A组)。在野生型或失活EcTyrRS存在下,五个GAL4突变体(L3TAG、I13TAG、T44TAG、F68TAG、S131TAG)在-URA平板上生长,不能在0.1%5-FOA上生长。在这些琥珀突变体中,内源性抑制明显足够将EcTyrRS/tRNACUA介导的抑制推进到MaV203中URA3报道基因的动态范围以外。五个GAL4单琥珀突变体(R110TAG,V114TAG,T121TAG,I127TAG,T145TAG)在没有尿嘧啶和存在EcTyrRS/tRNACUA的情况下生长(但不是A5/tRNACUA),在5-FOA上显示了反向表型。这些突变体显示了EcTyrRS依赖性表型,属于MaV203中URA3报道基因的动态范围内。用GAL4的R110TAG突变体观察到在-URA和0.1%5-FOA上最洁净的EcTyrRS依赖性表型。当与A5共转化时,该突变体在X-GAL测定中显示一些蓝色。为了进一步改进动态范围,使一系列六个GAL4的双琥珀突变体含有R110TAG(图3,B组),(L3TAG、R110TAG;I13TAG、R110TAG;T44TAG、R110TAG;R110TAG、T121TAG;R110TAG、I127TAG;R110TAG、T145TAG)。这些双突变体中的四个(I13TAG、R110TAG;R110TAG、T121TAG;R110TAG、I127TAG和T145TAG、R110TAG)不能在没有尿嘧啶的条件下生长,而能够在0.1%5-FOA上生长。这些双突变体具有平板测定的动态范围以外的活性。双突变体中的两个(L3TAG、R110TAG和T44TAG、R110TAG)能够在存在野生型EcTyrRS/tRNACUA而非A5/tRNACUA的条件下在-URA平板上生长;这些突变体在5-FOA上也显示预期的交互表型。选择pGADGAL4(T44TAG、R110TAG),这两个GAL4突变体中更有活性的进行更详细的表征(图4)。含有pGADGAL4(T44TAG、R110TAG)/pEcTyrRS-tRNACUA的MaV203在X-GAL上是蓝色的,但是相应的含有pA5/tRNACUA的株则不是。类似地,含有pGADGAL4(T44TAG,R110TAG)/pEcTyrRS/tRNACUA的MaV203在具有浓度高达75mM的3-AT的平板和-URA平板上茁壮生长,但是相应的含有pA5/tRNACUA的株不能在10mM3AT或没有尿嘧啶的情况下生长。总之,pGADGAL4的EcTyrRS依赖性表型(T44TAG,R110TAG)可以跨越MaV203中URA3,HIS3和lacZ报道基因的动态范围。感兴趣的是确定GAL4突变体的活性,其中T44或R110被除了酪氨酸的氨基酸取代,因为在不改变GAL4活性的情况下取代不同氨基酸的能力可能在选择可以将非天然氨基酸掺入蛋白的突变氨酰基-tRNA合成酶中有用。参见,例如,M.Pasternak,等,(2000),用于衍生具有扩展遗传密码的生物的新正交抑制tRNA/氨酰基-tRNA合成酶对(AneworthogonalsuppressortRNA/aminoacyl-tRNAsynthetasepairforevolvinganorganismwithanexpandedgeneticcode),HelveticaChemicaActa83:2277。将GAL4中残基T44的一系列五个突变体(T44Y,T44W,T44F,T44D,T44K)构建到pGADGAL4(R110TAG)中,因为pGADGAL4本身是有毒的。将GAL4中R110位的类似系列的突变体(R110Y,R110W,R110F,R110D,R110K)构建到pGADGAL4(T44TAG)中。这些突变体与我们在掺入蛋白中感兴趣的大疏水氨基酸侧链是有偏差的,但也包含带正电荷和负电荷的残基,作为允许的严格测试。用pEcTyrRS/tRNACUA将各突变体共转化到MaV203细胞中,用邻-硝基苯基-β-D-半乳糖吡喃糖苷(ONPG)水解在leu+trp+分离物中测定lacZ产生(图5)。在所有情况中,细胞间活性差异小于3倍,该细胞含有取代了T44或R110的不同氨基酸的GAL4。这种最小的可变性证明了这些位点允许在不改变GAL4的转录活性的情况下进行氨基酸取代。正如由选择性平板上测定的单琥珀突变体活性所料,在GAL4(R110TAG)背景中制成的T44突变体导致ONPG的水解比在GAL4(T44TAG)背景中制成的R110突变体更慢。进行模型富集研究以检测该系统从大过量的失活合成酶中选择活性合成酶的能力(表1,表2,图6)。该选择模仿了在非天然氨基酸存在下从变体文库中选择活性合成酶的能力。将含有GAL4(T44、R110)和EcTyrRS/tRNACUA的MaV203细胞与由OD660确定过量10至106倍的GAL4(T44TAG,R110TAG)和A5/tRNACUA,以及当铺板于非选择性-leu,-trp培养基上通过X-Gal覆盖测定变蓝的菌落部分混合。选择那些能够在50mM3-AT或在没有尿嘧啶的情况下存活的细胞。在3-AT或-URA上存活的细胞在X-Gal测定中蓝色和白色的比例,与不存在选择下的相同比例比较,清楚地证明正选择可以从死合成酶中富集活性合成酶(表1),系数>105。在起始比例大于1:105的情况下,测定准确富集一般是不可能的,因为可以方便的铺板而没有显著细胞间串话导致不可靠表型的细胞是不多于106个细胞。表1.模型正选择功能性EcTyrRS。a)通过OD660测定b)在X-Gal上表2.模型负选择无功能EcTyrRS(A5)。a)通过OD660测定b)在X-Gal上在非天然氨基酸存在下进行正选择后,选择的细胞将含有能够使用天然氨基酸和能够使用加入的非天然氨基酸的合成酶。为分离仅能够使用非天然氨基酸的合成酶,必须从选择的克隆中除去编码使用天然氨基酸的合成酶的细胞。这可以用负选择完成,负选择中,非天然氨基酸被保留,而那些与天然氨基酸一起发挥作用的合成酶被去除。以与模型正选择类似的方式进行模型负选择。将EcTyrRS/tRNACUA与过量10至105倍的A5/tRNACUA混合,在0.1%5-FOA上进行选择。将在0.1%5-FOA存活细胞在X-GAL测定中是白色和蓝色的比例,与非选择性条件下的相同比例进行比较(参见表2),清楚的是负选择可以从活性合成酶中富集死合成酶,系数至少0.6x104。在起始比例大于1:104的情况下,测定准确富集一般是不可能的,因为可以方便的铺板而没有显著细胞间串话导致不可靠表型的细胞是不多于105个细胞。开发了一种通用方法,进行识别非天然氨基酸的aaRS正选择和识别天然氨基酸的aaRS负选择。通过改变选择的严格性,可以分离各种合成酶活性。将该方法应用于用EcTyrRS变体的模型选择中显示在单轮正选择中富集大于105,在单轮负选择中大于0.6x104。这些发现提示该方法可以提供快速到达正交氨酰基-tRNA合成酶,其功能是将具有各种侧链的非天然氨基酸位点特异地掺入酿酒酵母的蛋白中。而且,酿酒酵母中产生的酶可以用于高等真核生物。材料和方法载体构建用引物tRNA5':GGGGGGACCGGTGGGGGGACCGGTAAGCTTCCCGATAAGGGAGCAGGCCAGTAAAAAGCATTACCCCGTGGTGGGTTCCCGA(SEQIDNO:89)和tRNA3':GGCGGCGCTAGCAAGCTTCCCGATAAGGGAGCAGGCCAGTAAAAAGGGAAGTTCAGGGACTTTTGAAAAAAATGGTGGTGGGGGAAGGAT(SEQIDNO:90)从pESCSU3URA中PCR扩增tRNACUA基因。这个以及其它所有PCR反应都用Roche的ExpandPCR试剂盒,根据生产商说明书进行。限制性核酸内切酶NheI和AgeI消化后,将该tRNA基因插入2微米载体pESCTrp(Stratagene)中的相同位点之间,产生ptRNACUA。用引物PADHf:IGGGGGGACCGGTIGGGGGGACCGGTCGGGATCGAAGAAATGATGGTAAATGAAATAGGAAATCAAGG(SEQIDNO:91)和pADHR:GGGGGGGAATTCAGTTGATTGTATGCTTGGTATAGCTTGAAATATTGTGCAGAAAAAGAAAC(SEQIDNO:92)从pDBLeu(Invitrogen)中PCR扩增全长ADH1启动子,用AgeI和EcoRI消化。用引物pESCTrp1:TCATAACGAGAATTCCGGGATCGAAGAAATGATGGTAAATGAAATAGGAAATCTCATAACGAGAATTCATGGCAAGCAGTAACTTG(SEQIDNO:93)和pESCTrp2:TTACTACGTGCGGCCGCATGGCAAGCAGTAACTTGTTACTACGTGCGGCCGCTTATTTCCAGCAAATCAGAC(SEQIDNO:94)扩增EcTyrRS。用EcoRI和NotI消化EcTyrRSPCR产物。然后用AgeI和NotI消化ptRNACUA。将这三个DNA三连接产生pEcTyrRS-tRNACUA。用寡核苷酸F37Afwd:CCGATCGCGCTCGCTTGCGGCTTCGATC(SEQIDNO:95)、N126Afwd:ATCGCGGCGAACGCCTATGACTGGTTC(SEQIDNO:96)、182、183、186A、GTTGCAGGGTTATGCCGCCGCCTGTGCGAACAAACAGTAC(SEQIDNO:97)和它们的反向补体,以及侧翼的寡核苷酸4783:GCCGCTTTGCTATCAAGTATAAATAG(SEQIDNO:98)、3256:CAAGCCGACAACCTTGATTGG(SEQIDNO:99)和作为模板的pEcTyrRS-tRNACUA进行重叠PCR,建立具有氨基酸残基(活性位点中37、126、182、183和186位突变为丙氨酸)的质粒pA5-tRNACUA。用EcoRI和NotI消化PCR产物,连接到用相同酶消化时释放的pEcTyrRS-tRNACUA的大片段中。为构建第一代DB-AD报道者,用正向引物pADfwd:GGGGACAAGTTTGTACAAAAAAGCAGGCTACGCCAATTTTAATCAAAGTGGGAATATTGC(SEQIDNO:100)或pADfwd(TAG)GGGGACAAGTTTGTACAAAAAAGCAGGCTAGGCCAATTTTAATCAAAGTGGGAATATTGC(SEQIDNO:101)和ADrev:GGGGACCACTTTGTACAAGAAAGCTGGGTTACTCTTTTTTTGGGTTTGGTGGGGTATC(SEQIDNO:102)从pGADT7(Clontech)中PCR扩增GAL4DNA结合域。用Clonase步骤,根据生产商的说明书将这些PCR产物克隆到载体pDEST3-2(invitrogen)中,产生pDB-AD和pDB-(TAG)-AD。为构建PGADGAL4和变体,用引物ADH1428-1429AAGCTATACCAAGCATACAATC(SEQIDNO:103)和GAL4C:ACAAGGCCTTGCTAGCTTACTCTTTTTTTGGGTTTGGTGGGGTATCTTC(SEQIDNO:104)从pCL1(Clontech)中PCR扩增GAL4基因。根据生产商的说明书将该片段克隆到载体pCR2.1TOPO(Invitrogen)中。用HindIII消化含有GAL4基因的克隆(pCR2.1TOPOGAL4),将2.7kbGAL4片段凝胶纯化并连接到用HindIII消化的pGADT7的大片段中,用小牛肠磷酸酶处理,凝胶纯化。根据生产商说明书进行Quikchange反应(Stratagene),用列在补充信息中的引物将GAL4基因的变体建立在pCR2.1上。以与野生型GAL4基因相同的方式将GAL4突变体克隆到pGADT7中。所有最终构建物都经过DNA测序确认。酵母培养基和操作酿酒酵母株MaV203(Invitrogen)是MATα;leu2-3,112;trp1109;his3Δ200;ade2-101;cyh2R;cyh1R;GAL4Δ;gal80Δ;GAL1::lacZ;HIS3UASGAL1::HIS3@LYS2;SPALlOUASGALl::URA3。酵母培养基购自Clontech,5-FOA和X-GAL购自Invitrogen,3-AT购自BIO101。YPER(酵母蛋白抽提试剂)和ONPG购自PierceChemicals。通过PEG/醋酸锂法(参见,例如,D.Burke,等,(2000)《酵母遗传学方法》(MethodsinYeastGenetics),ColdSpringHarborLaboratoryPress,ColdSpringHarbor,NY)进行质粒转化,在合适的合成完全撤除成分培养基上选择转化子。为了在MaV203上测试各种质粒组合给予的表型,将来自各转化的合成完全撤除成分平板的酵母菌落重悬于15微升无菌水中,然后在感兴趣的选择性培养基上划线。各表型至少用五个独立菌落确认。通过凝胶覆盖法进行X-GAL测定。参见,I.G.Serebriiskii和E.A.Golemis,(2000),lacZ在研究基因功能中的用途:用于酵母双杂交系统的β-半乳糖苷测定的评价(UsesoflacZtostudygenefunction:evaluationofbeta-galactosidaseassaysemployedintheyeasttwo-hybridsystem),AnalyticalBiochemistry285:1-15。简要说,在琼脂平板上通过加入几次纯氯仿裂解菌落或细胞小块。氯仿蒸发后,将含有0.25克/升XGAL的1%琼脂糖和含有0.1MNa2P04的缓冲液加于平板表面。琼脂糖一凝固,就将平板置于37℃孵育12小时。通过将单菌落接种到含有1毫升SD-leu、-trp的96孔板中,并在30℃振荡孵育进行ONPG测定。在96孔微量滴定板中平行记录100微升细胞以及几个细胞稀释液的OD660。将细胞(100微升)与100微升YPER:ONPG(1xPBS、50%v/vYPER、20mMMgCl2、0.25%v/vβ-巯基乙醇和3mMONPG)混合,在37℃振荡孵育。在显色时,离心沉淀细胞,将上清转移到洁净的96孔微量滴定板(Nunclon,目录号167008),记录A420。所有数据表示至少4个独立克隆试验的平均值,误差条表示标准差。用等式:β-半乳糖苷酶单位=1000.A420/(V.t.OD660)计算ONPG水解,其中V是以微升表示的细胞体积,t是以分钟表示的孵育时间。参见,例如,I.G.Serebriiskii和E.A.Golemis,(2000),lacZ在研究基因功能中的用途:用于酵母双杂交系统的β-半乳糖苷测定的评价(UsesoflacZtostudygenefunction:evaluationofbeta-galactosidaseassaysemployedintheyeasttwo-hybridsystem),AnalyticalBiochemistry285:1-15。一个β-半乳糖苷酶单位相当于每细胞每分钟水解1微摩尔ONPG。参见,Serebriiskii和Golemis,上述。在SPECTRAmaxl90板阅读器上进行分光光度读数。模型选择正选择:将两个过夜培养物培养在SD-Leu、-Trp中。一个包含载有pEcTyrRS-tRNACUA/pGADGAL4(T44、R110TAG)的MaV203,另一个载有pA5-tRNASU3/pGADGAL4(T44、R110TAG)。离心收集这些细胞,通过涡旋重悬于0.9%NaCl。然后将这两个细胞溶液稀释到相同的OD660。将载有pEcTyrRS-tRNACUA/pGADGAL4(T44、R110TAG)的MaV203连续稀释为7个数量级,然后将各溶液与未稀释的载有pA5-tRNACUA/pGADGAL4(T44、R110TAG)的MaV2031:1体积:体积混合,以提供确定比例的含有活性和失活酪氨酰-tRNA合成酶的细胞。对各比列稀释液进行第二次连续稀释,其中细胞数量减少,但保持载有pEcTyrRS-tRNACUA/pGADGAL4(T44、R110TAG)和pA5-tRNACUA/pGADGAL4(T44。R110TAG)的细胞比例。将这些稀释液铺平板于SD-Leu、-trp、SD-Leu、-Trp、-URA和SD-Leu、-Trp、-His+50mM3-AT。60小时后,用EagleEyeCCD相机(Stratagene)对各平板上的菌落计数,用X-GALβ-半乳糖苷酶测定确认存活细胞的表型。分离来自几个单独蓝色或白色菌落的细胞并在SD-leu、-trp中培养至饱和,用标准方法分离质粒DNA。用DNA测序确认EcTyrRS变体的身份。负选择:以与正选择类似的方式进行模型负选择,除了将载有pA5-tRNACUA/pGADGAL4(T44、R110TAG)的MaV203连续稀释并与固定密度的载有pEcTyrRS-tRNACUA/pGADGAL4(T44、R110TAG)的MaV203混合。将细胞铺平板于SD-leu、-trp+0.1%5-FOA,48小时后计算菌落数量,平板处理如上所述。下面的寡核苷酸(表3)与它们的反向补体联用,以通过Quikchange诱变构建定位突变体。突变位置用粗体文字表示。表3:用于构建定位突变体的寡核苷酸。琥珀突变体寡核苷酸序列L3TAG5'-ATGAAGTAGCTGTCTTCTATCGAACAAGCATGCG-3'(SEQIDNO:66)I13TAG5'-CGAACAAGCATGCGATTAGTGCCGACTTAAAAAG-3'(SEQIDNO:67)T44TAG5'-CGCTACTCTCCCAAATAGAAAAGGTCTCCGCTG-3'(SEQIDNO:68)F68TAG5'-CTGGAACAGCTATAGCTACTGATTTTTCCTCG-3'(SEQIDNO:69)R110TAG5'-GCCGTCACAGATTAGTTGGCTTCAGTGGAGACTG-3'(SEQDNO:70)V114TAG5'-GATTGGCTTCATAGGAGACTGATATGCTCTAAC-3'(SEQIDNO:71)T121TAG5'-GCCTCTATAGTTGAGACAGCATAGAATAATGCG-3'(SEQIDNO:72)I127TAG5'-GAGACAGCATAGATAGAGTGCGACATCATCATCGG-3'(SEQIDNO:73)S131TAG5'-GAATAAGTGCGACATAGTCATCGGAAGAGAGTAGTAG-3'(SEQIDNO:74)T145TAG5'-GGTCAAAGACAGTTGTAGGTATCGATTGACTCGGC-3'(SEQIDNO:75)允许位点突变体寡核苷酸序列T44F5'-CGCTACTCTCCCCAAATTTAAAAGGTCTCCGCTG-3'(SEQIDNO:76)T44Y5'-CGCTACTCTCCCCAAATATAAAAGGTCTCCGCTG-3'(SEQIDNO:77)T44W5'-CGCTACTCTCCCCAAATGGAAAAGGTCTCCGCTG-3'(SEQIDNO:78)T44D5'-CGCTACTCTCCCCAAAGATAAAAGGTCTCCGCTG-3'(SEQIDNO:79)T44K5'-CGCTACTCTCCCCAAAAAAAAAAGGTCTCCGCTG-3'(SEQIDNO:80)R110F5'-GCCGTCACAGATTTTTTGGCTTCAGTGGAGACTG-3'(SEQIDNO:81)R110Y5'-GCCGTCACAGATTATTTGGCTTCAGTGGAGACTG-3'(SEQIDNO:82)R110W5'-GCCGTCACAGATTGGTTGGCTTCAGTGGAGACTG-3'(SEQIDNO:83)R110D5'-GCCGTCACAGATGATTTGGCTTCAGTGGAGACTG-3'(SEQIDNO:84)R110K5'-GCCGTCACAGATAAATTGGCTTCAGTGGAGACTG-3'(SEQIDNO:85)实施例2:扩展的真核生物遗传密码描述了将非天然氨基酸加入到酿酒酵母遗传密码中的通常和快速的途径。响应于无义密码子TAG,将五个氨基酸以高保真度有效掺入蛋白质中。这些氨基酸的侧链含有酮基,可以在体外或体内用广范围的化学探针和试剂将其独特地修饰;含有重原子的氨基酸用于结构研究;以及光交联剂用于蛋白质相互作用的细胞研究。该方法不仅去除遗传密码对我们在酵母中操纵蛋白质结构和功能的强加的限制,它提供了系统性扩展多细胞真核生物的遗传密码的途径。虽然化学家已经开发了合成和操纵小分子结构的有效方法和策略(参见,例如,E.J.Corey和X.-M.Cheng,《化学合成的逻辑》(TheLogicofChemicalSynthesis)(Wiley-Interscience,NewYork,1995)),但是合理控制蛋白质结构和功能的能力仍处于萌芽状态。虽然在很多情况下已经可能在整个蛋白质组中竞争性掺入与普通氨基酸接近的结构类似物,但是诱变方法限于普通的20个氨基酸构件。参见,例如,K.Kirshenbaum,等,(2002),ChemBioChem3:235-7;和V.Doring等,(2001),Science292:501-4。全合成(参见,例如,B.Merrifield,(1986),Science232:341-7(1986))和半合成方法(参见,例如,D.Y.Jackson等,(1994)Science266:243-7;和P.E.Dawson和S.B.Kent,(2000),AnnualReviewofBiochemistry69:923-60,已经使合成肽和小蛋白成为可能,但对于超过10千道尔顿(kDa)的蛋白,其用途受到更多限制。包括化学酰化的正交tRNA的生物合成方法(参见,例如,D.Mendel,等,(1995),AnnualReviewofBiophysicsandBiomolecularStructure24:435-462;和V.W.Cornish,等(1995年3月31日),AngewandteChemie-InternationalEditioninEnglish34:621-633已经允许在体外(参见,例如,J.A.Ellman,等,(1992),Science255:197-200)或在显微注射的细胞中(参见,例如,D.A.Dougherty,(2000),CurrentOpinioninChemicalBiology4:645-52)将非天然氨基酸掺入较大的蛋白质中。然而,化学酰化的化学计量特性严重限制了可以产生的蛋白质的量。因此,尽管作出了很大努力,但是在整个进化中,二十个遗传编码的氨基酸(除吡咯赖氨酸和硒半胱氨酸(参见,例如,A.Bock等,(1991),MolecularMicrobiology5:515-20;和G.Srinivasan,等,(2002),Science296:1459-62)以外)已经限制蛋白、可能是整个生物的性质。为了克服该限制,将新组件加入到原核生物大肠杆菌(E.coli)的蛋白质生物合成机器中(例如,L.Wang,等,(2001),Science292:498-500),这使体内遗传编码非天然氨基酸成为可能。响应于琥珀密码子TAG,将一些具有新化学、物理或生物学性质的新氨基酸有效和选择性地掺入蛋白质中。参见,例如,J.W.Chin等,(2002),JournaloftheAmericanChemicalSociety124:9026-9027;J.W.Chin和P.G.Schultz,(2002),ChemBioChem11:1135-1137;J.W.Chin,等,(2002),PNASUnitedStatesofAmerica99:11020-11024:和L.Wang和P.G.Schultz,(2002),Chem.Comm.,1:1-10。然而,因为翻译机器在原核生物和真核生物间并不是非常保守的,加入大肠杆菌的生物合成机器的组件通常不能用于在真核细胞中将非天然氨基酸位点特异地掺入蛋白质中,以研究或操纵细胞过程。因此,建立在真核细胞中会扩展遗传编码的氨基酸数目的翻译组件。选择酿酒酵母作为起始真核宿主生物,因为它是有用的模式真核生物,容易进行遗传操纵(参见,例如,D.Burke,等,(2000),《酵母遗传学方法》(MethodsinYeastGenetics)(ColdSpringHarborLaboratoryPress,ColdSpringHarbor,NY),它的翻译机器与高等真核生物的翻译机器高度同源(参见,例如,T.R.Hughes,(2002),Funct.Integr.Genomics2:199-211)。新构件加入酿酒酵母遗传密码需要不与酵母翻译机器的任何组件交叉反应的独特的密码子、tRNA和氨酰基-tRNA合成酶(‘aaRS’)(参见,例如,Noren等,(1989)Science244:182;Furter(1998)ProteinSci.7:419;和Liu等,(1999)PNASUSA96:4780)。一个候选正交对是来自大肠杆菌的琥珀抑制酪氨酰-tRNA合成酶-tRNACUA对(参见,例如,H.M.Goodman,等,(1968),Nature217:1019-24;和D.G.Barker,等,(1982),FEBSLetters150:419-23)。当大肠杆菌酪氨酰-tRNA合成酶(TyrRS)和大肠杆菌tRNACUA在酿酒酵母中遗传编码但不氨酰化酿酒酵母胞质tRNA时,大肠杆菌酪氨酰-tRNA合成酶(TyrRS)有效氨酰化大肠杆菌tRNACUA。参见,例如,H.Edwards和P.Schimmel,(1990),Molecular&CellularBiology10:1633-41;和H.Edwards,等,(1991),PNASUnitedStatesofAmerica88:1153-6。此外,对于酿酒酵母氨酰基-tRNA合成酶来说,大肠杆菌酪氨酰tRNACUA是差的底物(参见,例如,V.Trezeguet,等,(1991),Molecular&CellularBiology11:2744-51),但是它在酿酒酵母中加工,从核输出到胞质(参见,例如,S.L.Wolin和A.G.Matera,(1999)Gene&Development13:1-10)并有效作用于蛋白翻译。参见,例如,H.Edwards和P.Schimmel,(1990)Molecular&CellularBiology10:1633-41;H.Edwards,等,(1991),PNASUnitedStatesofAmerica88:1153-6;和V.Trezeguet,等,(1991),Molecular&CellularBiology11:2744-51。而且,大肠杆菌TyrRS不具有编辑机制,因此不应该校正与tRNA连接的非天然氨基酸。为了改变正交TyrRS的氨基酸特异性以使它用所需非天然氨基酸和没有任何内源性氨基酸氨酰化tRNACUA,产生TyrRS突变体的一个大文库,并进行遗传选择。根据来自嗜热脂肪芽孢杆菌的同源TyrRS的晶体结构(参见,例如,P.Brick,等,(1989),JournalofMolecularBiology208:83),将位于结合酪氨酸芳环的对位内的大肠杆菌TyrRS活性位点中的五个残基(嗜热脂肪芽孢杆菌,图7,A组)突变。例如,为建立突变体EcTyrRS文库,将五个靶向突变的位置首先转化为丙氨酸密码子以产生A5RS基因。这在基因中两个质粒之间独特的PstI位点上分开。基本上根据本领域已知技术(参见,例如,Stemmer等,(1993)Biotechniques14:256-265)的描述建立该文库。一个质粒含有A5RS基因的5'半,另一质粒含有A5RS基因的3'半。通过用扩增整个质粒的寡核苷酸引物进行PCR,对各片断进行诱变。掺入的引物含有NNK(N=A+G+T+C,K=G+T)和BsaI限制性核酸内切酶识别位点。用BsaI消化,连接产生的两种环形质粒,各含有EcTyrRS基因一半的突变拷贝。然后用PstI消化这两种质粒,并通过连接组装成单一质粒,导致全长突变基因的组装。将突变EcTyrRS基因从该质粒中切下并连接入pA5RS/tRNACUA中的EcoRI和NotI位点之间。用PEG-醋酸锂法将该文库转化到酿酒酵母Mav203:pGADGAL4(2TAG)中,产生~108个独立的转化子。用该文库转化酿酒酵母的选择株[MaV203:pGADGAL4(2TAG)(参见,例如,M.Vidal,等,(1996),PNASUnitedStatesofAmerica93:10321-6;M.Vidal,等,(1996),PNASUnitedStatesofAmerica93:10315-201和Chin等,(2003)Chem.Biol.10:511)]以提供108个独立的转化子,在1mM非天然氨基酸的存在下生长(图8,C组)。在转录激活物GAL4中抑制两种允许琥珀密码子导致全长GAL4的产生和GAL4-反应性HIS3、URA3和lacZ报道基因的转录激活(图8,A组)。例如,允许密码子是用于Gal4的T44和R110。HIS3和URA3在缺少尿嘧啶(-ura)或含有20mM3-氨基三唑(参见,例如,G.M.Kishore和D.M.Shah,(1988),AnnualReviewofBiochemistry57,627-63)(3-AT,His3蛋白的竞争性抑制剂)以及缺少组氨酸(-his)的培养基中的表达允许正选择表达活性aaRS-tRNACUA对的克隆。如果突变TyrRS载上具有氨基酸非tRNACUA,那么细胞能够生物合成组氨酸和尿嘧啶,且存活。在没有3-AT和非天然氨基酸的情况下扩增存活细胞,从选择性掺入非天然氨基酸的细胞中去除全长GAL4。为去除响应于琥珀密码子掺入内源性氨基酸的克隆,将细胞培养于含有0.1%5-氟乳清酸(5-FOA)而缺少非天然氨基酸的培养基上。作为用天然氨基酸抑制GAL4琥珀突变的结果,表达URA3的那些细胞将5-FOA转化为有毒产物,杀死细胞。参见,例如,J.D.Boeke,等,(1984),Molecular&GeneralGenetics197:345-6。在非天然氨基酸存在下扩增存活克隆,再应用于正选择。LacZ报道基因允许用比色方法区别活性和失活合成酶-tRNA对(图8,B组)。通过使用该方法,将五个具有不同空间和电子性质的新氨基酸(图7,B组)独立地加入酿酒酵母的遗传密码中。这些氨基酸包括对-乙酰基-L-苯丙氨酸(1)、对-苯甲酰基-L-苯丙氨酸(2)、对-叠氮基-L-苯丙氨酸(3)、氧-甲基-L-酪氨酸(4)和对-碘代-L-苯丙氨酸(5)(在图7,B组中以数字表示)。对-乙酰基-L-苯丙氨酸的酮官能团的独特反应性允许用一系列含肼或羟胺的试剂在体外和体内进行蛋白的选择性修饰(参见,例如,V.W.Cornish,等,(1996年8月28日),JournaloftheAmericanChemicalSociety118:8150-8151;和Zhang,Smith,Wang,Brock,Schultz,准备中)。可以证明,对-碘代-L-苯丙氨酸的重原子可用于定相X射线结构数据(用多波长不规则衍射)。对-苯甲酰基-L-苯丙氨酸和对-叠氮基-L-苯丙氨酸的二苯甲酮和叠氮苯侧链允许蛋白在体内和体外有效的光交联(参见例如,Chin等,(2002)J.Am.Chem.Soc.,124:9026;Chin和Schultz,(2002)Chem.Bio.Chem.11:1135;和Chin等,(2002)PNAS,USA99:11020)。可用同位素标记的甲基容易地取代氧-甲基-L-酪氨酸的甲基,在使用核磁共振和振动光谱学中用作局部结构和动力学的探针。三轮选择(正-负-正)后,分离几个菌落,它们在-ura或在20mM3-AT-his培养基上的存活严格依赖于选择的非天然氨基酸的加入。参见,图8,D组。相同克隆仅在存在1mM非天然氨基酸的x-gal上是蓝色的。这些实验证明观察的表型由演化的氨酰基-tRNA合成酶-tRNACUA对和它们的关联氨基酸的组合产生(参见,表4)。例如,为选择突变体合成酶,将细胞(~109)在液体SD-leu、-trp+1mM氨基酸中培养4小时。然后离心收集细胞,重悬于0.9%NaCl,铺平板于SD-leu、-trp、-his+20mM3-AT、+1mM非天然氨基酸或SD-leu、-trp、-ura、+1mM非天然氨基酸上。30℃48至60小时后,从板上刮下细胞,移入液体SD-leu、-trp中,在30℃培养15小时。离心收集细胞,重悬于0.9%NaCI,铺平板于SD-leu、-trp+0.1%5-FOA。30℃48小时后,将细胞刮下,移至液体SD-leu、-trp+1mM非天然氨基酸中,培养15小时。然后离心收集细胞,重悬于0.9%NaCl,铺平板于SD-leu、-trp、-his+20mM3-AT、+1mM非天然氨基酸或SD-leu,-trp,-ura,+1mM非天然氨基酸上。为筛选选择细胞的表型,将来自各选择的菌落(192)转移到含有0.5毫升SD-leu、-trp的96孔板的孔中,在30℃培养24小时。向每孔加入甘油(50%v/v;0.5毫升),存在或没有1mM非天然氨基酸的情况下,将细胞复制铺板于琼脂(SD-leu、-trp;SD-leu、-trp、-his、+20mM3-AT;SD-leu、-trp、-ura)上。用琼脂糖覆盖法在SD-leu、-trp平板上进行X-Gal测定。为了进一步证明观察的表型是由于正交突变体TyrRS/tRNA对位点特异性掺入非天然氨基酸,产生并表征含有各非天然氨基酸的人超氧化物歧化酶1(hSOD)的突变体(参见,例如,H.E.Parge,等,(1992),PNASUnitedStatesofAmerica89:6109-13)。例如,用PS356(ATCC)作为模板,通过重叠PCR进行加入编码C-末端六组氨酸标记的DNA和将人超氧化物歧化酶基因中的Trp33密码子突变为琥珀密码子。将hSOD(Trp33TAG)HIS在来自pYES2.1(Invitrogen,Carlsbad,CAUSA)的GAL1启动子和CYC1终止子之间克隆。用pYES2.1hSOD(Trp33TAG)HIS将pECTyrRS-tRNACUA衍生质粒上的突变体合成酶和tRNA基因共转化到InvSc株(Invitrogen)中。对于蛋白表达,将细胞培养于SD-trp,-ura+棉子糖中,通过加入半乳糖诱导表达使OD660达到0.5。通过Ni-NTA层析(Qiagen,Valencia,CA,USA)纯化HSOD突变体。从33位上含有琥珀密码子的基因生产六-组氨酸-标记的hSOD严格依赖于对-乙酰基PheRS-1-tRNACUA和1mM对-乙酰基-L-苯丙氨酸(密度测定<0.1%,在没有任何一个组件的情况下)(参见图9)。纯化含有全长hSOD的对-乙酰基-L-苯丙氨酸(例如,通过Ni-NTA亲和层析),产率为50纳克/毫升,与从含有大肠杆菌TyrRStRNACUA的细胞中纯化的产率相差不大。为了比较,在相同条件下,野生型hSODHIS的纯化产率为250纳克/毫升。图9说明遗传编码非天然氨基酸的hSOD(33TAG)HIS在酿酒酵母中的蛋白表达(如图7B组所示,在图9中以它们在图7B组中的编号表示)。图9的上部说明从存在(+)和没有(-)非天然氨基酸情况下的酵母中纯化的hSOD的SDS-聚丙烯酰胺凝胶电泳,非天然氨基酸以数字表示,与图7B组中用考马斯蓝染色的非天然氨基酸相一致。细胞含有为所示氨基酸选择的突变体合成酶-tRNA对。图9的中部说明用抗hSOD抗体探测的Western印迹。图9的下部说明用抗C-末端His6标记的抗体探测的Western印迹。通过将突变蛋白的胰蛋白酶消化物进行液相色谱和串联质谱分析确定掺入氨基酸的身份。例如,用胶体考马斯染色使质谱蛋白条带显色。将与野生型和突变型SOD相对应的凝胶条带从聚丙烯酰胺凝胶上切下,切成1.5毫米的立方体,还原并烷化,然后进行基本如上所述的胰蛋白酶水解。参见,例如,A.Shevchenko,等,(1996),AnalyticalChemistry68,850-858。通过纳米流反相HPLC/μESI/MS与LCQ离子阱质谱仪分析含有非天然氨基酸的胰蛋白酶肽。在装有纳米喷雾HPLC(Agilent1100系列)的FinniganLCQDeca离子阱质谱仪(ThermoFinnigan)上进行液相色谱串联质谱(LC-MS/MS)分析。参见,例如,图10,A-H组。用离子阱质谱仪分离并片段化前体离子,它与带单电荷或双电荷离子的含有非天然氨基酸(标为Y*)的肽Val-Y*-Gly-Ser-Ile-Lys(SEQIDNO:87)对应。片段离子质量可以是明确指定的,确认了对-乙酰基-L-苯丙氨酸的位点特异性掺入(参见,图10,A组)。没有观察到酪氨酸或其它氨基酸代替对-乙酰基-L-苯丙氨酸,从肽谱的信噪比获得最小99.8%的掺入纯度。当对-苯甲酰基PheRS-1、对-叠氮基PheRS-1、氧-meTyrRS-1或对-碘代PheRS-1用于将对-苯甲酰基-L-苯丙氨酸、对-叠氮基-L-苯丙氨酸、氧-甲基-L-赖氨酸或对-碘代-L-苯丙氨酸掺入hSOD中时(参见,图9和图10,A-H组),观察到类似的蛋白表达保真度和效率。在实验的样品制备中,对-叠氮基-L-苯丙氨酸被还原成对-氨基-L-苯丙氨酸,在质谱中观察到了后者。该还原并不通过含有对-叠氮基-L-苯丙氨酸的纯化SOD的化学衍生在体内发生。在对照实验中,制备在33位含有色氨酸、酪氨酸和亮氨酸的六-组氨酸-标记的hSOD,进行质谱测定(参见图10,F、G和H组)。含有氨基酸33的离子在这些样品的质谱中清晰可见。将5个非天然氨基酸独立地加入酿酒酵母的遗传密码证明了我们方法的通用性,提示它可应用于其它非天然氨基酸,包括自旋标记的、金属结合的或可光异构的氨基酸。该方法可产生具有新的或提高性质的蛋白,以及在酵母中易于控制蛋白功能。而且,在哺乳动物细胞中,大肠杆菌酪氨酰-tRNA合成酶与嗜热脂肪芽孢杆菌tRNACUA形成正交对。参见,例如,Sakamoto等,(2002)NucleicAcidsRes.30:4692。因此人们可以使用在酵母中开发的氨酰基-tRNA合成酶将非天然氨基酸加到高等真核生物的遗传密码中。表4.选择的氨酰基-TRNA合成酶的序列a这些克隆也含有Asp165Gly突变实施例3:将具有新反应性的氨基酸加到真核生物的遗传密码中证明了一个基于[3+2]环加成与蛋白生物共轭的方法,该方法是位点特异性,快速,可靠和可逆的。非常需要在生理条件下以高度选择方式修饰蛋白的化学反应。参见,例如,Lemineux和Bertozzi,(1996)TIBTECH,16:506-513。目前用于蛋白选择性修饰的大部分反应都包括亲核和亲电子反应配偶之间形成共价键,例如α-卤代酮与组氨酸或半胱氨酸侧链的反应。在这些情况下,选择性由蛋白中亲核残基的数量和可及性决定。在合成或半合成蛋白的情况下,可以使用其它更具选择性的反应,如非天然酮式-氨基酸与酰肼或氨氧基化合物的反应。参见,例如,Cornish,等,(1996)Am.Chem.Soc.,118:8150-8151;和Mahal,等,(1997)Science,276:1125-1128。最近,在细菌和酵母中用具有改变氨基酸特异性的正交tRNA-合成酶对已可能遗传编码非天然氨基酸(参见,例如,Wang,等,(2001)Science292:498-500;Chin,等,(2002)Am.Chem.Soc.124:9026-9027;和Chin,等,(2002)Proc.Natl.Acad.Sci.,99:11020-11024),包括含有酮的氨基酸(参见,例如,Wang,等,(2003)Proc.Natl.Acad.Sci.,100:56-61;Zhang,等,(2003)Biochemistry,42:6735-6746;和Chin,等,(2003)Science,印刷中)。该方法已使得用包括荧光团、交联剂和细胞毒分子在内的大量试剂选择性标记基本上任何蛋白质成为可能。描述了用于蛋白选择性修饰的一种高效方法,它包括响应于,例如,琥珀无义密码子TAG,将含有叠氮化物或乙炔的非天然氨基酸遗传掺入蛋白质中。然后可以分别用炔基(乙炔)或叠氮化物衍生物通过Huisgen[3+2]环加成反应(参见,例如,Padwa,A.《综合有机合成》(ComprehensiveOrganicSynthesis),第4卷,(1991)Trost,B.M.编,Pergamon,Oxford,第1069-1109页;和Huisgen,《R.1.3-双极环加成化学》(1,3-DipolarCycloadditionChemistry),(1984)Padwa,A.编,Wiley,NewYork,第1-176页)修饰这些氨基酸侧链。因为该方法包括环加成而非亲核取代,所以可以以极高的选择性来修饰蛋白质(可以使用的另一方法具有四半胱氨酸基序的双砷化合物上的配体交换,参见,例如,Griffin,等,(1998)Science281:269-272)。该反应可以在室温下、含水条件下以极好的区域选择性(1,4>1,5)通过将催化量的Cu(I)盐加入到反应混合物中进行。参见,例如,Tornoe,等,(2002)Org.Chem.67:3057-3064;和Rostovtsev,等,(2002)Angew.Chem.Int.Ed.Engl.41:2596-2599。实际上,Finn和同事们已经证明此叠氮化物-炔[3+2]环加成可以在完整的豇豆花叶病毒表面上进行。参见,例如,Wang,等,(2003)J.Am.Chem.Soc.,125:3192-3193。另一最近实施例将叠氮基亲电子引入蛋白,和随后的[3+2]环加成,参见,例如,Speers,等,(2003)J.Am.Chem.Soc.,125:4686-4687。为了将炔基(乙炔)或叠氮化物官能团选择性引入真核蛋白的独特位点,在酵母中产生演化的正交TyrRS/tRNACUA对,它遗传编码乙炔和叠氮基氨基酸,分别如图11的1和2所示。可以在后续的还加成反应中,在生理条件下用荧光团有效并选择地标记所得的蛋白。之前,在酵母中证明大肠杆菌酪氨酰tRNA-tRNA合成酶对是正交的,即,tRNA或合成酶均不与内源性酵母tRNA或合成酶交叉反应。参见,例如,Chin,等,(2003)Chem.Biol.,10:511-519。该正交tRNA-合成酶对已经用于响应于TAG密码子,将许多非天然氨基酸选择和有效地掺入酵母中(例如,Chin,等,(2003)Science,印刷中)。为了改变大肠杆菌酪氨酰-tRNA合成酶的氨基酸特异性,以接受图11的氨基酸1或2,通过随机化Tyr37、Asn126、Asp182、Phe183和Leu186的密码子产生~107突变体的文库。根据来自嗜热脂肪芽孢杆菌的同源合成酶的晶体结构选择这五个残基。为获得具体氨基酸用作底物的合成酶,使用了一种选择方案,其中将转录激活物GAL4的基因的Thr44和Arg110的密码子转化为琥珀无义密码子(TAG)。参见,例如,Chin,等,(2003)Chem.Biol.,10:511-519。在MaV203:pGADGAL4(2TAG)酵母株中抑制这些琥珀密码子导致产生全长GAL4(参见,例如,Keegan,等,(1986)Science,231:699-704;和Ptashne,(1988)Nature,335:683-689),它反过来驱动HIS3和URA3报道基因的表达。后一个基因产物补充组氨酸和尿嘧啶营养缺陷,允许在图11中1或2的存在下选择载有活性合成酶突变体的克隆。通过在缺乏图11中1或2却含有5-氟乳清酸的培养基上生长去除装载内源性氨基酸的合成酶,URA3将5-氟乳清酸转化为有毒产物。通过对该文库进行三轮选择(正、负、正),我们鉴定了选择性针对图11的1(pPR-EcRS1-5)和针对图11的2(pAZ-EcRS1-6)的合成酶,如表8所示。所有合成酶都显示了强的高序列相似性,包括保守的Asn126,这提示该残基具有重要的功能作用。令人惊讶的是,合成酶pPR-EcRS-2和pAZ-EcRS-6,衍生以分别结合图11的1和2,会聚成相同序列(Tyr37→Thr37、Asn126→Asn126、Asp182→Ser182和Phe183→Ala183、Leu186→Leu186)。结合酪氨酸的酚羟基与Tyr37和Asp182之间的氢键由于分别突变成Thr和Ser而被破坏。Phe183转化为Ala,可能为容纳非天然氨基酸提供更多空间。为证实该合成酶(和其它合成酶)接受氨基酸作为底物的能力,将载有合成酶质粒的选择株培养于缺乏尿嘧啶(从缺乏组氨酸的培养基中获得了相同结果)但补充有图11的1或2的培养基上。生长结果揭示五个炔合成酶中的四个能够将两种非天然氨基酸加到其tRNA上。叠氮基合成酶似乎更具选择性,因为只有pAZ-EcRS-6(与pPR-EcRS-2相同)能够用图11的1和2氨酰化其tRNA。没有图11中1或2的情况下未检测到生长的事实提示,合成酶并不接受20种普通氨基酸中任意一种作为底物。参见图14。对于所有其它使用pPR-EcRS-2(pAZ-EcRS-6)的实验,允许人们简单地通过将图11中1或2加入含有表达株的培养基来控制将哪个非天然氨基酸掺入。对于蛋白质生产,将融合了C-末端6xHis标记的人超氧化物歧化酶-1(SOD)的允许残基Trp33的密码子突变为TAG。例如,将人超氧化物歧化酶(Trp33TAG)HIS在pYES2.1(Invitrogen,Carlsbad,CAUSA)的GAL1启动子和CYC1终止子之间克隆。用pYES2.1SOD(Trp33TAG)HIS将pECTyrRS-tRNACUA衍生质粒上的突变体合成酶和tRNA基因共转化到InvSc株(Invitrogen)中。对于蛋白质表达,将细胞培养于SD-tr、-ura+棉子糖上,通过加入半乳糖诱导表达使OD660达到0.5。在存在或没有图11中1mM1或2的情况下表达蛋白,通过Ni-NTA层析(Qiagen,Valencia,CA,USA)纯化。SDS-PAGE和Western印迹分析揭示非天然氨基酸依赖性蛋白表达,与没有图11中1或2情况下的蛋白表达相比,密度测定确定其保真度>99%。参见图12。为进一步确认掺入氨基酸的身份,将胰蛋白酶消化物进行液相色谱和串联质谱分析。例如,用镍亲和柱纯化野生型和突变型hSOD,用胶体考马斯染色使蛋白条带显色。将与野生型和突变型SOD相对应的凝胶条带从聚丙烯酰胺凝胶上切下,切成1.5毫米的立方体,还原并烷化,然后进行基本如上所述的胰蛋白酶水解。参见,例如,Shevchenko,A等,(1996)Anal.Chem.68:850-858。通过纳米流反相HPLC/μESI/MS与LCQ离子阱质谱仪分析含有非天然氨基酸的胰蛋白酶肽。参见,图15,A和B组。在装有纳米喷雾HPLC(Agilent1100系列)的FinniganLCQDeca离子阱质谱仪(ThermoFinnigan)上进行液相色谱串联质谱(LC-MS/MS)分析。用离子阱质谱仪分离并片段化前体离子,它与带单电荷或双电荷的含有非天然氨基酸(标为Y*)的肽VY*GSIK(SEQIDNO:87)前体离子对应。片段离子质量可以是明确指定的,确认了各非天然氨基酸的位点特异性掺入。LCMS/MS并未表明在此位置掺入任何天然氨基酸。所有突变体肽的信噪比>1000,这提示掺入的保真度优于99.8%。参见,图15,A和B组。为证明可以通过叠氮-炔[3+2]环加成反应将小有机分子共轭至蛋白质,合成图13中A组所示的染料3-6,它们含有乙炔基或叠氮基并具有丹磺酰或荧光素荧光团(参见本文的实施例5)。环加成本身用0.01mM蛋白在pH8的磷酸盐缓冲液(PB)中,在图13A组中所示2mM3-6、1mMCuS04和~1毫克铜线的存在下,37℃反应4小时(参见图13,B组)进行的。例如,向45微升蛋白的PB缓冲液(pH=8)中加入1微升CuS04(在H20中50mM)、2微升染料(在EtOH中50mM)、2微升三(1-苯甲基-1H-[1,2,3]三唑-4-基甲基)胺(在DMSO中50mM)和铜线。室温或或37℃下4小时或4℃过夜后,加入450微升H20,将混合物离心通过透析膜(10kDa截断)。用2x500微升通过离心洗涤上清后,溶液体积为50毫升。通过SDS-PAGE分析20毫升的样品。可以通过在H20/MeOH/AcOH(5:5:1)中浸泡过夜从凝胶中去除偶尔剩余的染料。将三(羧乙基)膦用作还原剂通常导致标记效率更低。与较早的观察(例如,Wang,Q.等,(2003)J.Am.Chem.Soc.125:3192-3193)不同,存在或没有三(三唑基)胺配体并不实质性影响反应的结果。透析后,用SDS-PAGE分析标记蛋白,在图13A组中所示3-4丹磺酰染料(λex=337纳米,λem=506纳米)的情况下用光密度计或在图13A组中所示5-6荧光素染料(λex=483纳米,λem=516纳米)的情况下用感光成像仪在凝胶内成像。参见,例如,Blake,(2001)Curr.Opin.Pharmacol.,1:533-539;Wouters,等,(2001)TrendsinCellBiology11:203-211;和Zacharias,等,(2000)Curr.Opin.Neurobiol.,10:416-421。通过LCMS/MS分析胰蛋白酶消化物表征标记蛋白,显示了荧光团的位点特异性附着,转化率平均为75%(例如,通过比较用图13,A组中所示5或6标记的SOD的A280/A495值确定)。图13,A组中所示3和炔蛋白或图13,A组中所示4和叠氮基蛋白之间没有可观察的反应的事实确证了此生物共轭的选择性。表8进化形成的合成酶为1选择的pPR-EcRS和为2选择的pAZEcRS(如图11所示)实施例4:炔氨基酸的合成在本发明的一个方面,本发明提供了炔基氨基酸。式IV说明了炔氨基酸的一个结构的例子:炔氨基酸一般是具有式IV的任意结构,其中R1是二十种天然氨基酸之一使用的取代基,R2是炔基取代基。例如,图11中1说明对-炔丙基氧基苯丙氨酸的结构。可以合成对-炔丙基氧基苯丙氨酸,例如,如下所述。在这个实施方式中,对-炔丙基氧基苯丙氨酸的合成可以在起始于市售N-Boc-酪氨酸的三个步骤中完成。例如,将N-叔-丁氧基羰基-酪氨酸(2克,7毫摩尔,1当量)和K2C03(3克,21毫摩尔,3当量)悬浮于无水DMF(15毫升)。将炔丙基溴(2.1毫升,21毫摩尔,3当量,80%甲苯溶液)缓慢加入,室温下搅拌反应混合物18小时。加入水(75毫升和Et20(50毫升),分层,用Et20(2x50毫升)提取水相。干燥(MgS04)混合的有机层,减压去除溶剂。获得黄色油状产物(2.3克,91%),无需进一步纯化就用于下一步骤。以下面的化学结构8说明Boc-保护的产物:2-叔-丁氧基羰基氨基-3-[4-(丙-2-炔基氧基)苯基]-丙酸炔丙基酯在0℃下,小心地将乙酰氯(7毫升)加入甲醇(60毫升)中,以产生5M无水HCl的甲醇溶液。加入前一步骤的产物(2克,5.6毫摩尔),搅拌反应物4小时,此时允许加热到环境温度。减压去除挥发性物质后,获得淡黄色固体(1.6克,98%)(参见化学结构9),将它直接用于下一步骤。2-氨基-3-[4-(丙-2-炔基氧基)苯基]-丙酸炔丙基酯将来自前一步骤的炔丙基酯(1.6克,5.5毫摩尔)溶解于2NNaOH(14毫升)和MeOH(10毫升)的含水混合物中。室温下搅拌1.5小时后,通过加入浓HCI将pH调整到7。加入水(20毫升),将混合物置于4℃过夜。过滤沉淀,用冰冷的H20洗涤,真空干燥,产生1.23克(90%)图11中的1(2-氨基-3-苯基丙酸(1)(也称为对-炔丙基氧基苯丙氨酸),白色固体。1HNMR(400MHz,D20)(如D20中的钾盐)δ7.20(d,J=8.8Hz,2H),6.99(d,J=8.8Hz,2H),4.75(s,2H),3.50(dd,J=5.6,7.2Hz,1H),2.95(dd,J=5.6,13.6Hz,1H),2.82(dd,J=7.2,13.6Hz,1H);13CNMR(100MHz,D20)δ181.3,164.9,155.6,131.4,130.7,115.3,57.3,56.1,39.3;HRMS(CI)m/z220.0969[C12H13NO3(M+1)需要220.0968]。实施例5:通过[3+2]环加成将分子加入到具有非天然氨基酸的蛋白中在一个方面,本发明提供了将含有非天然氨基酸的蛋白质与附加取代分子偶联的方法和相关组合物。例如,可以通过[3+2]环加成将附加取代基加入非天然氨基酸。参见,例如,图16。例如,可根据下面公开的[3+2]环加成反应的条件将所需分子的[3+2]环加成(例如,包括第二活性基团,如炔三键或叠氮基)到具有非天然氨基酸的蛋白(例如,具有第一活性基团,如叠氮基或三键)中。例如,将包含非天然氨基酸的蛋白的PB缓冲液(pH=8)加入CuS04、所需分子和铜线中。混合物孵育后(例如,室温或37℃下约4小时,或4℃过夜),加入H2O,通过透析膜过滤混合物。可以通过,例如凝胶分析来分析加入样品。所述分子的例子包括但不限于,例如,具有三键或叠氮基的分子,如具有图13,A组的式3、4、5和6等结构的分子。而且,可以将三键或叠氮基掺入其它感兴趣的分子,例如聚合物(如聚(乙二醇)和衍生物)、交联剂、附加染料、光交联剂、细胞毒化合物、亲和标记、生物素、糖、树脂、珠、第二种蛋白或多肽、金属螯合剂、辅因子、脂肪酸、碳水化合物、多核苷酸(例如DNA、RNA等)等的结构中,然后也可用于[3+2]环加成。在本发明的一个方面,可以如下所述合成具有图13,A组的式3、4、5或6的分子。例如,通过在0℃下将炔丙基胺(250微升,3.71毫摩尔,3当量)加入丹磺酰氯(500毫克,1.85毫摩尔,1当量)和三乙胺(258微升,1.85毫摩尔,1当量)的CH2Cl2(10毫升)溶液合成图13,A组的3中和下面的化学结构3中所显示的炔染料。搅拌1小时后,将反应混合物加热到室温,再搅拌1小时。真空去除挥发物,通过硅胶层析(Et20/己烷=1:1)纯化粗产物,产生黄色固体的图13,A组的3(418毫克,78%)。分析数据与文献中报道的相同。参见,例如,Bolletta,F等,(1996)Organometallics15:2415-17。化学结构3中显示了本发明中可使用的炔染料的结构的例子:通过在0℃下将3-叠氮基丙胺(例如,如Carboni,B等,(1993)J.Org.Chem.58:3736-3741中所述)(371毫克,3.71毫摩尔,3当量)加入丹磺酰氯(500毫克,1.85毫摩尔,1当量)和三乙胺(258微升,1.85毫摩尔,1当量)的CH2Cl2(10毫升)溶液合成图13,A组的4中和下面的化学结构4中所显示的叠氮基染料。搅拌1小时后,将反应混合物加热到室温,再搅拌1小时。真空去除挥发物,通过硅胶层析(Et20/己烷=1:1)纯化粗产物,产生黄色油状的图13,A组的4(548毫克,89%)。1HNMR(400MHz,CDCl3)δ8.55(d,J=8.4Hz,1H),8.29(d,J=8.8Hz,1H),8.23(dd,J=1.2,7.2Hz,1H),7.56-7.49(comp,2H),7.18(d,J=7.6Hz,1H),5.24(brs,1H),3.21(t,J=6.4Hz,2H),2.95(dt,J=6.4Hz,2H),2.89(s,6H),1.62(quin,J=6.4Hz,2H);13CNMR(100MHz,CDCl3)δ134.3,130.4,129.7,129.4,128.4,123.3,118.8,115.3,48.6,45.4,40.6,28.7(在13CNMR谱中并非所有的季碳原子信号都可见);HRMS(CI)m/z334.1336[C15H20N5O2S(M+1)需要334.1332]。化学结构4中显示了叠氮基染料的结构的例子:通过在室温下将EDCI(1-乙基-3-(3-二甲基氨丙基)碳二亚胺盐酸盐)(83毫克,0.43毫摩尔,1当量)加入荧光素胺(150毫克,0.43毫摩尔,1当量)和10-十一碳一炔酸(79毫克,0.43毫摩尔,1当量)的吡啶(2毫升)溶液合成图13,A组的5中和下面的化学结构5中所显示的炔染料。将悬液搅拌过夜,将反应混合物倾入H20(15毫升)中。通过加入浓HCl将该溶液酸化(pH<2)。搅拌1小时后,过滤掉沉淀,用H2O(5毫升)洗涤,溶解于少量的EtOAc。己烷的加入导致图13,A组的5以橙色晶体析出,收集并在真空下干燥(138毫克,63%)。分析数据与文献中报道的相同。参见,例如,Crisp,G.T.和Gore,J.(1997)Tetrahedron53:1505-1522。化学结构5中显示了炔染料的结构的例子:通过在室温下将EDCI(1-乙基-3-(3-二甲基氨丙基)碳二亚胺盐酸盐)(83毫克,0.43毫摩尔,1当量)加入荧光素胺(150毫克,0.43毫摩尔,1当量)和4-(3-叠氮基丙基氨基甲酰基)-丁酸(例如,通过3-叠氮基丙胺与戊二酸酐的反应合成)(92毫克,0.43毫摩尔,1当量)的吡啶(2毫升)溶液合成图13,A组的6中和下面的化学结构6中所显示的叠氮基染料。将悬液搅拌过夜,将反应混合物倾入H20(15毫升)中。通过加入浓HCl将该溶液酸化(pH<2)。搅拌1小时后,过滤掉沉淀,用1NHC1(3x3毫升)洗涤,溶解于少量的EtOAc。己烷的加入导致图13,A组的6以橙色晶体析出,收集并在真空下干燥(200毫克,86%)。1HNMR(400MHz,CD30D)δ8.65(s,1H),8.15(d,J=8.4Hz,1H),7.61-7.51(comp,2H),7.40(d,J=8.4Hz,1H),7.35(brs,2H),7.22-7.14(comp,2H),6.85-6.56(comp,3H),3.40-3.24(comp,4H),2.54(t,J=7.2Hz,2H),2.39-2.30(comp,2H),2.10-1.99(comp,2H),1.82-1.72(comp,2H);13CNMR(100MHz,CD30D)δ175.7,174.4,172.4,167.9,160.8,143.0,134.3,132.9,131.8,129.6,124.4,123.3,121.1,118.5,103.5,50.2,38.0,37.2,36.2,29.8,22.9(在13CNMR谱中并非所有的季碳原子信号都可见);HRMS(CI)m/z544.1835[C28H25N507(M+1)需要544.1827]。化学结构6中显示了叠氮基染料的结构的例子:在一个实施方式中,也可以将PEG分子加入到具有非天然氨基酸,例如叠氮基氨基酸或炔丙基氨基酸的蛋白质中。例如,可以通过[3+2]环加成将炔丙基酰胺PEG(如图17,A组中所示)加入到具有叠氮基氨基酸的蛋白质中。参见例如,图17,A组。图17,B组说明了具有加入的PEG取代基的蛋白质的凝胶分析。在本发明的一个方面,可如下所述合成炔丙基酰胺PEG(如图17,A组中所示)。例如,将炔丙基胺(30微升)的CH2Cl2(1毫升)溶液加入20kDaPEG-羟基琥珀酰亚胺酯(120毫克,购自Nektar)中。室温下搅拌反应4小时。然后加入Et20(10毫升),过滤掉沉淀,通过加入Et20(10毫升)从MeOH(1毫升)中二次再结晶。将产物在真空下干燥,产生白色固体(105毫克,产率88%)。参见,例如,图17,C组。实施例6:示例性O-RS和0-tRNA示例性O-tRNA包含SEQIDNO.:65(参见,表5)。O-RS例子包括SEQIDNOs.:36-63、86(参见,表5)。编码O-RS或其部分(如活性位点)的多核苷酸包括SEQIDNOs.:3-35。此外,表6中说明了示例性O-RS的氨基酸改变。表6:进化形成的EcTyrRS变体a这些克隆也含有Asp165Gly突变可以理解,本文描述的实施例和实施方式仅作为示例性目的,本领域技术人员能够对它们进行各种的修改或改变,而仍然包括在本申请的范围和精神以及所附权利要求的范围之内。虽然为阐明和理解已经在一些细节方面详述了前述发明,但是对于本领域技术人员来说,能够通过阅读本公开作出各种形式和细节上的改变,而并不背离本发明的范围。例如,本文描述的所有技术和装置都可以用于不同组合。本申请中引用的所有出版物、专利、专利申请和/或其它文件均为所有目的以相同程度整体引入本文作为参考,似乎各单独出版物、专利、专利申请和/或其它文件为所有目的单独引入作为参考。表5a这些克隆也含有Asp165Gly突变。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1