一种提高植物抗旱能力的基因及其应用的制作方法
本发明涉及基因工程
技术领域:
,尤其是一种来源于小麦的能够提高植物抗旱能力的基因及其应用。
背景技术:
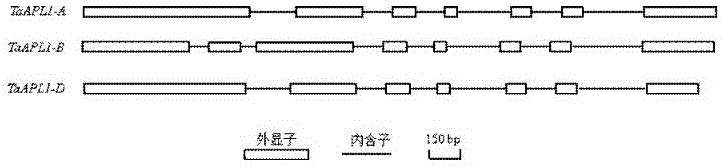
:干旱是影响植物生长、物种分布和限制作物产量提高的重要因素之一。利用基因工程培育抗旱植物,致力于发掘作物抗旱相关的新基因,并将之运用到作物抗旱品种的筛选与改良上,是当今作物抗逆基因工程研究的热点之一。在长期的进化过程中,高等植物逐渐演变产生了一套感受和传导干旱信号的系统,并形成了一系列生理或发育机制来响应环境中的这种胁迫,最大限度的减轻干旱胁迫造成的伤害。植物抗旱相关基因可分为2类。第一类基因是功能基因,包括:(1)渗透调节基因,如吡咯啉-5-羧酸合成酶基因(P5CS)和甜菜碱醛脱氢酶基因(BADH)等;(2)参与活性氧清除的基因,如超氧化物歧化酶基因(SOD)、过氧化物酶基因(POD)、过氧化氢酶(CAT)等;(3)脱水保护基因,如胚胎发生晚期富集蛋白基因(LEA)、水通道蛋白基因(PIP、TIP、NLM和SIP)和渗调蛋白基因(Osmotin)等。第二类基因是调节基因,主要包括:(1)传递信号和调控基因表达的转录因子基因,如DREB、bZIP、MYB/MYC、ERF、WRKY和NAC等;(2)感应和转导胁迫信号的蛋白激酶基因,如CDPK、MAPK、RPK等;(3)与第二信使生成有关的酶类,如磷脂酶C等。目前,在小麦中已分离出一些抗旱相关基因,如吡咯啉-5-羧酸合成酶基因(P5CS)和吡咯啉-5-羧酸还原酶基因(TaP5CR)、甜菜碱醛脱氢酶基因(TaBADH)、超氧化物歧化酶基因(TaSOD)、PMA80、DHN-5、TaDHN1、水通道蛋白基因、DREB转录因子基因(TaDREB1、TaDREB2、TaAIDF)、bZIP转录因子基因(LIP19、EmBP-1)、WRKY、NAC、CDPK、calreticulin、半胱氨酸蛋白酶基因(TaCP)、脂转移蛋白基因(TaLTP1)、小G蛋白基因(TaRab2)、铁蛋白基因(Tafet)、TaPP2Ac、TaABCIL、谷胱甘肽-S-转移酶基因(TaGSTF6)、TaMyB2、TaPIMP1、TaMYB33、TaMYB30、TaMYB19、Na+/H+逆向转运蛋白基因(NHX1)、凝集素基因(WGA)、vacuolarH+-PPase基因(TVP1)等。技术实现要素:本发明要解决的技术问题是提供一种提高植物抗旱能力的基因及其应用,以应对目前抗逆分子育种过程中抗逆基因缺乏的现状。为解决上述技术问题,本发明所采取的技术方案如下。一种提高植物抗旱能力的基因,该基因的核苷酸序列如SEQIDNO:1或SEQIDNO:2或SEQIDNO:3所示。本发明的技术内容还包括上述基因编码的作为植物转录因子的蛋白质。本发明的技术内容还包括含有上述基因的重组表达载体。本发明的技术内容还包括含有上述基因的转化体。本发明的技术内容还包括含有上述基因的转基因细胞系。本发明的技术内容还包括含有上述基因的转基因植物。本发明的技术内容还包括含有上述基因的表达盒,此表达盒至少包含一个启动子、权利要求1所述的基因及一个终止子;进一步的,所述启动子采用来源于烟草花叶病毒的强启动子CaM35S,且权利要求1所述的基因以功能性方式与所述启动子连接,所述终止子选自NOS终止序列或35S终止序列。本发明的技术内容还包括上述基因在培育高抗旱植物中的应用;具体的,首先构建含有权利要求1所述基因的重组表达载体,然后利用此重组表达载体构建转化体,再利用此转化体侵染目的植物,筛选阳性植株,获得与正常植物相比抗旱性能增强的转基因植物。采用上述技术方案所产生的有益效果在于:利用农杆菌将含有本发明基因的重组表达载体pCAMBIA2300-TaAPL1转化拟南芥,阳性转基因拟南芥植株抗旱能力提高,这说明本发明的基因可提高转基因植株中抗旱能力,从而为植物抗逆基因工程提供了强有力的工具。附图说明图1为本发明TaAPL1的基因结构图。图2为植物APL-like蛋白聚类分析图(上部分)与myb_SHAQKYF和Myb_CC_LHEQLE结构域序列比对图(下部分)。图3为本发明TaAPL1-D亚细胞定位,A、明场,B、GFP绿色荧光,C、细胞核DAPI红色荧光,D、叠加图像。图4为本发明TaAPL1-D转录激活载体构建,A、TaAPL1-D氨基酸序列及结构域,B、转录激活载体构建片段,C、TaAPL1-D转录激活载体构建示意图。图5为本发明TaAPL1-D转录激活活性分析。图6为本发明TaAPL1-D植物表达载体构建示意图。图7为本发明石麦15TaAPL1渗透胁迫处理后表达量变化图,描述石麦15小麦幼苗16%PEG8000处理后根和叶片中TaAPL1表达模式,分别于0、1、3、6、9、12、24、48小时取材料,采用实时荧光定量PCR的方法,小麦Actin基因作为内参。图8为本发明野生型拟南芥和转TaAPL1-D拟南芥干旱胁迫反应,A、表型分析,B、萌发率,C、失水率,D、丙二醛含量分析,E、脯氨酸含量分析。图9为本发明转TaAPL1-D拟南芥渗透胁迫处理前后干旱胁迫通路相关基因的表达分析。具体实施方式以下实施例详细说明了本发明。本发明所使用的各种试剂耗材及各项设备均为常规市售产品,均能够通过市场购买直接获得。在各个生化试验例中,若未特别指明,所用的技术手段均为本领域技术人员所熟知的常规手段。实施例1、具有的克隆与序列分析1.1材料处理精选石麦15种子在光照培养箱中用自来水培养至二叶一心期,培养温度22±1℃,每天光照14h。选取生长发育一致幼苗20-25株置培养皿中,16%聚乙二醇(PEG8000)处理,取样期间保持全天光照,分别于0,1,3,6,9,12,24,48h取叶片和根系,液氮速冻后于-70℃冰箱保存;试验分别设置3个重复。1.2小麦总RNA提取和cDNA第一链的合成采用RNAisoPlus(TaKaRa,中国大连)提取小麦总RNA。操作按试剂盒说明进行。紫外分光光度计法测定总RNA的浓度并鉴定纯度;用电泳鉴定其完整性。采用PrimeScriptTM1stStrandcDNASynthesisKit(TaKaRa,中国大连)进行第一链cDNA合成。操作按试剂盒说明进行。1.3基因(TaAPL1)的克隆Affymetrix小麦表达谱芯片分析表明,冬小麦品种石麦15MYB-CC类转录因子基因(GenBankNo.BJ243280)渗透胁迫后在叶中上调表达,在渗透胁迫后3h、9h和27h分别为对照的1.6倍、2.6倍和3.3倍,呈现表达量随胁迫时间延长而提高的趋势。NCBIBlastx比对显示,该基因为MYB-CC类转录因子基因,命名为TaAPL1。通过序列分析比对,设计引物序列如下:基因名称上链(5′-3′)下链(5′-3′)TaAPL1-AGCTTCTGGACGAACACGG(SEQIDNO:4)CACTAGAACTCTACATGGCAAG(SEQIDNO:5)TaAPL1-BGCTTCTGGACGAACACGG(SEQIDNO:6)CACTAGAACTCTACATGGCAAG(SEQIDNO:7)TaAPL1-DGACTGGCGGCTGATTTGG(SEQIDNO:8)CACTAGAACTCTACATGGCAAG(SEQIDNO:9)20μLPCR反应体系包含2×PfuPCRMasterMix10μL(天根生化),引物各1μL(10μmol•L-1),模板cDNA2μL(20ng•L-1),ddH2O6μL。PCR扩增程序:94ºC预变性5min;94℃变性30s,55℃退火30s,72℃延伸3min,30个循环;72℃延伸8min。PCR产物克隆使用DNAA-TailingKit和pMD18-Tvector(TaKaRa,中国大连)。转化菌株使用大肠杆菌DH5α。测序服务由立菲生物技术有限公司提供。TaAPL1序列为SEQIDNo.1(TaAPL1-A)、SEQIDNo.2(TaAPL1-B)和SEQIDNo.3(TaAPL1-D)。TaAPL1-A的编码区长1248bp,编码蛋白由415个氨基酸组成;TaAPL1-B的编码区长1152bp,编码蛋白由383个氨基酸组成;TaAPL1-D的编码区长1161bp,编码蛋白由386个氨基酸组成。TaAPL1-A、TaAPL1-B和TaAPL1-D核苷酸序列一致性分别为92.2%、92.9%、90.4%;氨基酸序列一致性分别为86.1%、86.6%、93.0%(DNAStar;http:/www.DNAStar.com)。聚类分析结果表明,植物APL-like基因分为2组,分别对应单子叶植物和双子叶植物;APL-like的2个结构域myb_SHAQKYF和Myb_CC_LHEQLE在植物中高度保守(图1)。1.5TaAPL1基因结构分析根据TaAPL1-A、TaAPL1-B和TaAPL1-D设计引物筛选石麦15基因组BAC文库,分离出含有TaAPL1-A、TaAPL1-B和TaAPL1-D的BAC单克隆,分别构建10kb亚克隆文库,通过亚克隆测序获得TaAPL1-A、TaAPL1-B和TaAPL1-D的基因组序列。通过比较TaAPL1-A、TaAPL1-B和TaAPL1-D的cDNA和gDNA序列发现,TaAPL1-A和TaAPL1-D具有相同的基因结构,编码区由7个外显子和6个内含子组成;TaAPL1-B基因结构不同于TaAPL1-A和TaAPL1-D,其编码区由8个外显子和7个内含子组成(图2)。TaAPL1-A、TaAPL1-B和TaAPL1-D在其5′非翻译区均含有1个内含子,长度分别为1000bp、1657bp和1333bp。TaAPL1-A、TaAPL1-B和TaAPL1-D基因结构从单基因水平说明,小麦A基因组和D基因组的同源程度高于B基因组,这与目前关于普通小麦3个基因组的起源和进化理论相吻合。1.6TaAPL1染色体定位根据TaAPL1-A、TaAPL1-B和TaAPL1-D基因组序列比对中国春小麦基因组序列信息发现,3个序列与位于染色体6AS、6BS和6DS上的TaAPL序列高度一致,这提示TaAPL1位于小麦第6同源群短臂上(https://urgi.versailles.inra.fr/download/iwgsc/Gene_models)。在此基础上,根据TaAPL1-A、TaAPL1-B和TaAPL1-D基因组序列设计引物,引物序列为:上链5'-GAGCAACTAGAGGTAACAGTGT-3'(SEQIDNO:10),下链5'-CTGGCCTTCTGTTGTTCTAG-3'(SEQIDNO:11)。以中国春缺四体材料(N6AT6B、N6AT6D、N6BT6A、N6BT6D、N6DT6A、N6DT6B)为模板,通过克隆测序分析TaAPL1-A、TaAPL1-B和TaAPL1-D的染色体定位。20μLPCR反应体系包含2×PfuPCRMasterMix10μL(天根生化),引物各1μL(10μmol•L-1),模板DNA2μL(20ng•L-1),ddH2O6μL。PCR扩增程序:94ºC预变性5min;94℃变性30s,60℃退火30s,72℃延伸1min,30个循环;72℃延伸8min。PCR产物克隆使用DNAA-TailingKit和pMD18-Tvector(TaKaRa,中国大连)。转化菌株使用大肠杆菌DH5α。测序服务由立菲生物技术有限公司提供。每个PCR产物随机挑取12个克隆测序,测序结果表明,TaAPL1-A、TaAPL1-B和TaAPL1-D分别位于小麦染色体6A、6B和6D上。实施例2、基因的亚细胞定位2.1TaAPL1基因的亚细胞定位表达载体的构建TaAPL1-D亚细胞定位表达载体构建使用pCAMBIA1300-sGFP(利用限制性内切酶NcoI和EcoRI将35S启动子-sGFP-NOS终止子连接到pCAMBIA1300载体的多克隆位点区)。根据TaAPL1-D序列设计引物,上游引物:5'-GAGAACACGGGGGACTCTAGAATGAGCACACAGAGTGTA-3'(SEQIDNO:12),下游引物:5'-GCCCTTGCTCACCATGGATCCCGGTTCACTTTCAAGATC-3'(SEQIDNO:13)。20μLPCR反应体系包含2×PfuPCRMasterMix10μL(TIANGEN),引物各1μL(10μmol•L-1),模板质粒DNA2μL(20ng•L-1),ddH2O6μL。PCR扩增程序:94ºC预变性5min;94℃变性30s,55℃退火30s,72℃延伸3min,30个循环;72℃延伸8min。采用琼脂糖凝胶电泳回收TaAPL1-DPCR产物。载体pCAMBIA1300-sGFP经XbaI和BamHI酶切后,采用琼脂糖凝胶电泳回收酶切大片段。利用石家庄惠友生物科技有限公司的快速克隆试剂ClonExpressII将PCR产物定向克隆到载体pCAMBIA1300-sGFP上,转化使用大肠杆菌DH5α。2.2TaAPL1的亚细胞定位TaAPL1-D亚细胞定位表达载体经测序正确后,大量提取质粒至浓度达0.8-1.0g•L-1。金粉包埋后,Bio-Rad台式基因枪(PDS-1000/He)轰击洋葱表皮细胞。暗培养24h,激光共聚焦扫描显微镜(LeicaSP8)观察荧光分布情况。结果表明,荧光信号分布在洋葱表皮细胞的细胞核中,这说明TaAPL1在细胞核中表达(图3)。实施例3、基因的转录活性分析3.1石麦15MYB-CC类转录因子基因TaAPL1转录激活载体构建转录激活载体构建使用pGBKT7。转录激活载体pGBKT7-TaAPL1F、pGBKT7-TaAPL1N、pGBKT7-TaAPL1C、pGBKT7-TaAPL1M构建如图4。以含有TaAPL1-DcDNA序列的质粒为模板,通过PCR扩增分别在片段TaAPL1F、TaAPL1N、TaAPL1C、TaAPL1M的5'和3'端引入BamHI和PstI酶切位点。引物序列如下:20μLPCR反应体系包含2×PfuPCRMasterMix10μL(TIANGEN),引物各1μL(10μmol•L-1),模板质粒DNA2μL(20ng•L-1),ddH2O6μL。PCR扩增程序:94ºC预变性5min;94℃变性30s,55℃退火30s,72℃延伸1-3min,30个循环;72℃延伸8min。采用琼脂糖凝胶电泳回收TaAPL1-DPCR产物。载体pGBKT7和PCR产物分别经BamHI和PstI酶切后,采用PCR产物回收试剂盒回收酶切片段(TIANGEN)。PCR产物和和pGBKT7连接使用T4DNA连接酶(NEB)。转化菌株分别使用大肠杆菌DH5α。3.2酵母感受态细胞的制备蘸取酵母AH109菌液于YPDA平板上划线,30℃培养2-3天。挑取单克隆至YPDA液体培养基中,30℃震荡培养16-20h。使用1.5mL离心管收集菌液,4000rpm室温离心5min,弃上清。向上述菌体中加入1mL灭菌的蒸馏水,重悬菌体,4000rpm室温离心5min,弃上清。依次加入:160μL灭菌蒸馏水、20μL10×TE、20μLLiAC,即为AH109酵母感受态细胞。3.3质粒转化酵母感受态在酵母感受态细胞中加入20μL的硅鱼精(10mg/mL)和3-5μL的TaAPL1转录激活载体质粒。按顺序依次加入:960μLPEG3350、120μL10×TE、120μLLiAC震荡混匀。30℃1800rpm震荡培养30min。42℃15min,6000rpm离心15s,弃上清。向上述菌体中加入150μL的灭菌蒸馏水,重悬菌体,然后于-Trp的培养基上,30℃倒置培养2-3天。3.4转录活性定性分析待单菌落长到直径约2mm后,挑取单菌落于YPDA液体培养基中,30℃230rpm振荡培养过夜,6000rpm离心15s,弃上清。在菌体中加入20μL的灭菌蒸馏水中,混匀,点样划线于-Trp-His-Ade的培养基上,30℃倒置培养2-3天。在-Trp-His-Ade培养基上培养2-3天后,取滤纸扣于培养皿上,菌面朝上,放在液氮中1min,室温解冻1min,重复3次,将滤纸放入X-Gal染色液中,30℃温育,实时观察染色情况。在转化载体pGBKT7-TaAPL1F、pGBKT7-TaAPL1N的酵母细胞中观察到β-半乳糖苷酶活性,二在pGBKT7-TaAPL1C、pGBKT7-TaAPL1M中酵母细胞无β-半乳糖苷酶活性(图5)。结果表明,TaAPL1具有转录活性,转录激活域位于蛋白的N端,C端可能具有抑制转录激活活性的元件。实施例4、基因的表达分析4.1材料处理精选石麦15种子在光照培养箱中用自来水培养至二叶一心期,培养温度22±1℃,每天光照14h。选取生长发育一致幼苗20-25株置培养皿中,16%聚乙二醇(PEG8000)处理,取样期间保持全天光照,分别于0,1,3,6,9,12,24,48h取叶片和根系,液氮速冻后于-70℃冰箱保存;试验分别设置3个重复。4.2小麦总RNA提取和cDNA第一链的合成采用RNAisoPlus(TaKaRa,中国大连)提取小麦总RNA。操作按试剂盒说明进行。紫外分光光度计法测定总RNA的浓度并鉴定纯度;用电泳鉴定其完整性。采用PrimeScriptTM1stStrandcDNASynthesisKit(TaKaRa,中国大连)进行第一链cDNA合成。操作按试剂盒说明进行。4.3定量PCR反应1)以一链cDNA为模板,采用SYBRRPremixExTaqTMII(TaKaRa)进行实时荧光定量PCR反应。反应引物如下:2)根据TaKaRaSYBRRPremixExTaqTMII试剂盒说明进行。PCR扩增程序:95℃2min;95℃30s,59℃30s,72℃30s,40个循环。以小麦β-actin基因作为内参,反应在ABIPrism7500荧光定量PCR仪上运行,3次重复。采用2–ΔΔCt法进行定量分析。渗透胁迫下,根和叶中表达量显著提高,根中3h表达量达到峰值,而叶中24h时出现峰值;叶中TaAPL1表达量高于根中;TaAPL1-A、TaAPL1-B和TaAPL1-D分别在小麦幼苗根和叶片中呈现相同的表达模式(图6)。定量PCR结果表明,TaAPL1-A、TaAPL1-B和TaAPL1-D均为干旱诱导表达基因,在小麦干旱诱导反应中承担相似的功能。实施例5、基因的遗传转化5.1石麦15MYB-CC类转录因子基因TaAPL1植物表达载体构建植物表达载体构建使用pCAMBIA2300-35S-OCS。植物表达载体构建pCAMBIA2300-TaAPL1如图7。以TaAPL1-DcDNA序列为模板,通过PCR扩增分别TaAPL1-D的5'和3'端引入BamHI和PstI酶切位点。引物序列如下:上链5′-CGGGATCCGACTGGCGGCTGATTTGG-3(SEQIDNO:28)′,下链5′-TGCACTGCAGCACTAGAACTCTACATGGCAAG-3′(SEQIDNO:29)。20μLPCR反应体系包含2×PfuPCRMasterMix10μL(TIANGEN),引物各1μL(10μmol•L-1),模板质粒DNA2μL(20ng•L-1),ddH2O6μL。PCR扩增程序:94ºC预变性5min;94℃变性30s,55℃退火30s,72℃延伸3min,30个循环;72℃延伸8min。采用琼脂糖凝胶电泳回收TaAPL1-DPCR产物。载体pCAMBIA2300和PCR产物分别经BamHI和PstI酶切后,采用PCR产物回收试剂盒回收酶切片段(TIANGEN)。PCR产物和和pCAMBIA2300连接使用T4DNA连接酶(NEB)。转化菌株分别使用大肠杆菌DH5α。通过BamHI和PstI酶切和测序对构建的植物表达载体进行验证。5.2农杆菌感受态的制备与转化1)农杆菌感受态的制备从新鲜YEB(5g/LTryptone;1g/LYeastextract;5g/LSucrose;0.5g/LMgSO4;琼脂15g/L;50mg/L利福平)平板上挑取农杆菌GV3101的单菌落,接种于5ml液体YEB培养基(含50mg/L利福平)中,28℃250rpm振摇培养过夜;取1ml菌液接种于50ml液体YEB培养基(含50mg/L利福平)中扩大培养,28℃250rpm振摇培养至OD600为0.6-0.8;冰浴30min,4℃5000rpm离心10min收集菌体,重悬浮于10ml预冷的10%甘油中;再次4℃5000rpm离心10min收集菌体,重悬于1ml预冷的10%甘油中,按100μl/管分装;液氮速冻后,放于-70℃冰箱保存。2)农杆菌转化农杆菌GV3101受态细胞(100µl)冰浴解冻,加入2μl重组质粒,混匀,冰浴45min;液氮速冻1min;)37℃水浴3min;加入1mlYEB液体培养基,28℃200rpm恢复培养3h。取20µl农杆菌转化液涂布于YEB固体平板(含50mg/L利福平,50mg/L卡那霉素)上,28℃培养2-3d,挑取单菌落,PCR鉴定阳性转化子。5.3拟南芥转化1)拟南芥培养称取一定数量的拟南芥种子(约50粒/mg),加入适量水,避光4℃春化2-3天。蛭石与营养土按体积比1:1比例混合,分装到花盆中,土层表面撒上薄薄的一层蛭石以抑制真菌的生长,加水使土充分润湿。用100μl移液器播种,每盆大约12-18粒。保鲜膜密封花盆,培养室中培养(22℃,16h光照;16℃,8h黑暗),托盘中的水量以保持湿润为准。待幼苗出土两片子叶充分展开后,揭去保鲜膜。约3周后拟南芥抽出初生苔,剪去初生苔以便使其抽出更多的次生苔,以便增加花的数量。待次生苔上长出一定数量的花蕾(尚未绽开)后用于拟南芥的转化。转化前1天将拟南芥苗浇透。2)转化用农杆菌菌液的制备与拟南芥转化取PCR检测正确的农杆菌菌液5μl接种于5mlYEB(Kan1:100,Rif1:50)液体培养基中,28℃,250rpm培养30h。菌液按1:400转接到300mlYEB液体培养基中,28℃,250rpm培养14h至OD6001.5-2.0。7000rpm,4℃离心15min收集菌液,重悬菌体于2倍体积的转化渗透液中(1/2MS+1.5%Sucrose,6-BA:0.01mg/L,VB1:10mg/L,VB6:1mg/L,SilwetL-77:0.02%)。将拟南芥(生态型Columbia-0)倒置,使花蕾朝下并浸入渗透液中,保持5min(长势强5min,长势弱3min)。转化后的植株平放,盖好保鲜膜。低光强度下生长24-48h后置于正常光照条件下生长,直到开花结荚收集种子。3)转基因植株的鉴定称取25-30mg拟南芥种子于1.5ml离心管中,10%次氯酸钠消毒10min,灭菌水冲洗去除次氯酸钠,加水混匀将种子均匀撒在1/2MS(Kan50mg/L)固体平板上(1/2MS+0.8%琼脂)。避光4℃春化2-3d。具有卡那霉素抗性的幼苗在抗性平板上正常生长呈绿色,根发育正常;非抗性幼苗黄色,但植株较小且无根。平板上的绿苗长至4个叶片时移至土中,盖上保鲜膜保水3d后揭去。幼苗长至8-10个叶片且较健壮时,剪取叶片提取基因组DNA,进行PCR检测。采用同样方法筛选,直至获得T3种子。实施例6转基因植物的抗旱性6.1转TaAPL1基因拟南芥抗旱性鉴定转TaAPL1拟南芥和野生型拟南芥在温室培养3周,所有拟南芥生长良好,未发现明显的表型变化。停水2周后,野生型植株呈现严重的失水和萎蔫症状,而转基因植株叶片仍为绿色,萎蔫症状明显减轻。复水2天后,野生型植株大部分死亡,而不同株系中均有一定比例的转基因植株能够正常生长(图8A)。将转TaAPL1拟南芥和野生型拟南芥播种在含有16%PEG的MS固体培养基上,转基因拟南芥的发芽率远高于野生型(图8B)。通过称量离体叶片鲜重的方法对叶片失水率进行了分析,结果表明,在所有取样时间点上野生型植株失水率均高于转基因植株(图8C)。采用400mmol•L-1甘露醇模拟干旱胁迫,转基因植株的脯氨酸含量高于野生型,而丙二醇含量低于野生型(图8D,8E)。这些结果表明,过量表达TaAPL1能够提高拟南芥的抗旱能力。6.2转TaAPL1基因拟南芥抗旱反应相关基因表达分析TaAPL1的过量表达能够提高拟南芥的抗旱性。为了探讨转基因拟南芥中抗旱相关基因的表达水平是否发生改变,选择了3个基因(DREB2A,P5CS1和RD29A)进行了转录水平分析(图9)。1)材料处理转TaAPL1拟南芥和野生型拟南芥在温室培养3周后停水,待野生型植株呈现明显失水和萎蔫症状时取样。液氮速冻后于-70℃冰箱保存;试验分别设置3个重复。2)拟南芥总RNA提取和cDNA第一链的合成采用RNAisoPlus(TaKaRa,中国大连)提取小麦总RNA。操作按试剂盒说明进行。紫外分光光度计法测定总RNA的浓度并鉴定纯度;用电泳鉴定其完整性。采用PrimeScriptTM1stStrandcDNASynthesisKit(TaKaRa,中国大连)进行第一链cDNA合成。操作按试剂盒说明进行。3)定量PCR反应a.以一链cDNA为模板,采用SYBRRPremixExTaqTMII(TaKaRa)进行实时荧光定量PCR反应。反应引物如下:b.根据TaKaRaSYBRRPremixExTaqTMII试剂盒说明进行。PCR扩增程序:95℃2min;95℃30s,59℃30s,72℃30s,40个循环。以拟南芥β-actin基因作为内参,反应在ABIPrism7500荧光定量PCR仪上运行,3次重复。采用2–ΔΔCt法进行定量分析。实时定量PCR结果显示,DREB2A,P5CS1和RD29A在转基因拟南芥中表达水平均高于野生型。这些基因表达水平的改变说明,基因TaAPL1可能通过提高抗旱相关基因表达水平,从而提高植物的抗旱性。上述描述仅作为本发明可实施的技术方案提出,不作为对其技术方案本身的单一限制条件。序列表<110>石家庄市农林科学研究院<120>一种提高植物抗旱能力的基因及其应用<160>37<210>1<211>1248<212>DNA<213>小麦(Triticumaestivum)<400>1ATGAGCACACAGAGTGTACTTCCTGTGAAAGATATCATTGCTCCTGACAGCATGGCTCAC60ACCTGCAATGTTCCACAACCTTCAGCCCATCAAATGTTCAATGCTAAATCTGAAATTTAC120AGTTCGGCAGATGGTATTTCCCGCGTCTCATATGCTGACCTATCAGACCCGAATTCATCG180AGCTCTTCCACATTCTGTGCAAGCATGTACTCGGCGTCACCGACGAACTCCAAATTATGC240TGGCAAATCAGCGGTTTGCCTTTCCTGCCTCATCCTCCTAAATGTGAGCAGCAGCAGTTT300TCAGCTGCGCAGTCATCGATCTCTGCTCTGTTGTTTGCTGCTGATCACAGCGATGGTAGT360CAAGGTCATGATGAACATTCACATGATCTCAAGGACTTCCTTAACCTCTCCGGCAATGCT420TCTGACAGTAGCTTCCGTGGAGGAGGCAGTTCCATGGATTTCAGTGAGCAGCTGGAGTTT480CAGTTATTGTCTGAACAACTTGGGATTGCCATCACCGACAACGAGGAGAGCCCTCGGTTA540GATGACATATATGGCATAGCGCCGCAATGCTCACCTAGTCTACTATCCCCTTCCTCTGAC600CATGAGGATCTGCGCAGTGGGGGTTCTCCGGTTAAAGTCCAGTTGAGTTCATCACCTTCT660TCATCTGGAGCAACAACATGTAGCAAAACGAGAATGAGATGGACACTTGAGCTCCATGAG720CGTTTTGTGGAGGCTCTGAAAAAGCTCGGAGGACTGGAAAAGGCAACTCCCAAGGGTGTG780CTGAAGCTTATGAAGGTAGAAGGCTTGACGATCTTTCACGTAAAGAGCCATTTGCAGAAC840TATCGACATGTGAAGTATATTCCGGAGAAAAAAGAAGTGAAGAGACCATGTTCAGAAGAT900AACAAGGCAAAATCAACATCTGGAATTGATTCTGGCAAAAAGAAGAGTTTTCAAATGGCT960GAAGCTCTACGGATGCAAATGGAGGTTCAGAAACAGCTCCATGAGCAACTAGAGGTGCAA1020AGGAAATTACAACTGCGCATAGAGGAGCATGCAAGATATTTGCAGCGGATACTAGAACAA1080CAGAAGGCCAGAAAATCTCTGGTACCGAAACCAGAGGAGAAAACAGAGGCCAGCACCACT1140TCAGCTCCGTCGCTGAAGTGTAAAATTTCCGACACCGAAATAGAACAGAACTTGCAAATG1200GATAGCAGAAGGCCAGAGCTACAACTTGATCTTGAAAGTGAACCGTAA1248<210>2<211>1152<212>DNA<213>小麦(Triticumaestivum)<400>2ATGAGCACACAGAATGTAATTCCTATGAAACATATCATTGCTCCTGACATCAGGGCTCAC60ACCTGCAATGCTCCACAACCTTCAGTCCATCAAATGTTCAATGCTAAATCCGATATTTAC120AGTTCGGCAGATGATACTTCCCGAGTCTCGTATGCTGACCTATCAGACCCGAATTCATCC180AGCTCTTCCACATTCTGCACAAGCATGTACTCATCGTCGTCGACAAAACCCAGTGGATTT240TCTTTCCTGCCCCATCCTTCTAAATGTGAGCAGCAGCAGGTATCAGCTGCAAAATCATTG300AGCTCTTCTTTGCTGTTTGCTGCTGATCTGAGCACTGGCGTTCATGGAGGCAATGCCATG360GATTTCAGTGAGCAGCTGGAGTTTCAGTTCTTGTCTGAACAACTTGGGATTGCCATCACC420GACAACGAGGAGATCCCTCGGTTAGATGACATATATGGCATACCGCCGCAATGCTCGCCT480ATTCTTGTATCGCCTTCATCTGACCATGAGGGTCTGCGCAGTGGGGGTTCTCCGGTCAAA540GTCCAGTTGAGTTCATCACCATCATCATCGGGAGCTACAGCATGTAGCAAAACGAGAATG600AGATGGACACTTGAGCTCCATGAGCGTTTTGTGGAGGCTCTGAAAAAGCTCGGAGGACCG660GAAAAGGCAACTCCCAAGGGTGTGCTGAAGCTTATGAAGGTAGAAGGCTTGACAATCTTT720CACGTAAAGAGCCATTTGCAGAACTATCGACATGTGAAGTATATTCCGGAGAAAAAAGAA780GTGAAGAGAACCTGTTCAGAAGATAACAAGGCAAAATCAGCACCTGGAATTGATTCTGGC840AAAAAGAAGAGTTTTCAAATGGCGGAAGCACTACGGATGCAAATGGAGGTTCAGAAACAG900CTCCATGAGCAACTAGAGGTGCAAAGGAAATTACAGCTGCGCATAGAGGAGCATGCAAGA960TATTTGCAGCAGATACTAGAACAACAGAAGGCCAGAAAATCCCCGGTACCGAAACCAAAG1020GAGGAAACAGAGGTCAACACCACTTCAGCTCCGTCGCTGAAGCGTAAACTTTCAGACACC1080AAAATAGAACACAACTCGCAGATGGATAGCAGAAGGCCAGAGCTACAACTTGATCTTGAA1140AGTGAACCATGA1152<210>3<211>1161<212>DNA<213>小麦(Triticumaestivum)<400>3ATGAGCACACAGAGTGTAATTCCTGTGAAACATTTCATTGCTCCTGACATCAGGGCTCAC60ACCTGCAATGCTCCACAACCTTCAGTCCATCAAATGTTCAATGCTAAATCCGATATTTAC120AGTTCGGCAGATGATACTTCCCGAGTCTCGTATGCTGACCTATCAGACCCGAATTCATCC180AGCTCTTCCACATTCTGCACAAGCATGTACTCATCGTCGTCGACAAAACCCAGTGGATTT240TCTTTCCTGCCCCATCCTTCTAAATGTGAGCAGCAGCAGGTATCAGCTGCAAAATCATCG300AGCTCTTCTTTGCTGTTTGCTGCTGATCCAAGCACTGGCGTTCATGGTGATCTTGAACAT360CCACTTGATCTCAAGGACTTCCTTAACCTCTCCGGCAACGCTTCTGACAGTAGCTTCCGT420GGAGGAGGCAATGCCATGGATTTCAGTGAGCAGCTGGAGTTTCAGTTCTTGTCTGAACAA480CTTGGGATTGCCATCACCGACAACGAGGAGAGCCCTCGGTTAGATGACATATATGGCATA540CCGCCGCAATGCTCACCTAGTCTAGTATCCCCTTCCTCTGACCATGAGGATCTGCGCAGT600GGGGGTTCTCCGGTTGAAGCCCAGTTGACGTCATCACATTCTTCATCTGGAGCAACATGT660AGCAAAACGAGAATGAGATGGACACTTGAGCTCCATGAGCGTTTTGTGGAGGCTCTGAAA720AAGCTCGGAGGACCGGAAAAGGCAACTCCCAAGGGTGTGCTGAAGCTTATGAAGGTAGAA780GGCTTGACAATCTTTCACGTAAAGAGCCATTTGCAGAACTATCGACATGTGAAGTATATT840CCGGAGAAAAAAGAAGTGAAGAGACCATGTTCAGAAGATAACAACGCAAAATCAGCATCT900GGAATTGATTCTGGCAACAAGAAGAGTTTTCAAATGGCGGAAACTCTACGGATGCAAATG960GAGGTTCAGAAACAGCTCCATGAGCAACTAGAGGTGCAAAGGGAATTACAGCTGCGCATA1020GAGGAGCATGCAAGATATTTGCAGCAGATACTAGAACAACAGAAGGCCAGAAAATCTACG1080GTGCCGAAACCAGAGGAGAAAACAGAGGTCAACACCACTTCAGCTCCGCCGCTGAAGCGT1140AAAATTTCAGACACCGAATAG1161<210>4<211>18<212>DNA<213>人工序列<400>4GCTTCTGGACGAACACGG18<210>5<211>22<212>DNA<213>人工序列<400>5CACTAGAACTCTACATGGCAAG22<210>6<211>18<212>DNA<213>人工序列<400>6GCTTCTGGACGAACACGG18<210>7<211>22<212>DNA<213>人工序列<400>7CACTAGAACTCTACATGGCAAG22<210>8<211>18<212>DNA<213>人工序列<400>8GACTGGCGGCTGATTTGG18<210>9<211>22<212>DNA<213>人工序列<400>9CACTAGAACTCTACATGGCAAG22<210>10<211>22<212>DNA<213>人工序列<400>10GAGCAACTAGAGGTAACAGTGT22<210>11<211>20<212>DNA<213>人工序列<400>11CTGGCCTTCTGTTGTTCTAG20<210>12<211>39<212>DNA<213>人工序列<400>12GAGAACACGGGGGACTCTAGAATGAGCACACAGAGTGTA39<210>13<211>39<212>DNA<213>人工序列<400>13GCCCTTGCTCACCATGGATCCCGGTTCACTTTCAAGATC39<210>14<211>24<212>DNA<213>人工序列<400>14CGGGATCCATGAGCACACAGAGTG24<210>15<211>24<212>DNA<213>人工序列<400>15TGCACTGCAGCTATTCGGTGTCTG24<210>16<211>26<212>DNA<213>人工序列<400>16TGCACTGCAGGAAATCCATGGCATTG26<210>17<211>26<212>DNA<213>人工序列<400>17CGGGATCCATGAGTGAGCAGCTGGAG26<210>18<211>28<212>DNA<213>人工序列<400>18CGGGATCCATGTCACCTAGTCTAGTATC28<210>19<211>24<212>DNA<213>人工序列<400>19TGCACTGCAGCTTCTTGTTGCCAG24<210>20<211>25<212>DNA<213>人工序列<400>20ACTAGAGGTGCAAAGGAAATTACAA25<210>21<211>24<212>DNA<213>人工序列<400>21AAGTTCTGTTCTATTTCGGTGTCG24<210>22<211>23<212>DNA<213>人工序列<400>22TGAGTTCATCACCATCATCATCG23<210>23<211>21<212>DNA<213>人工序列<400>23TTTGCCAGAATCAATTCCAGG21<210>24<211>22<212>DNA<213>人工序列<400>24GAGCAACTAGAGGTGCAAAGGG22<210>25<211>21<212>DNA<213>人工序列<400>25GTTTTCTCCTCTGGTTTCGGC21<210>26<211>22<212>DNA<213>人工序列<400>26AGGATACTTGGCAAACAAACGA22<210>27<211>21<212>DNA<213>人工序列<400>27CAATGGCTTCTACGAGACCGA21<210>28<211>26<212>DNA<213>人工序列<400>28CGGGATCCGACTGGCGGCTGATTTGG26<210>29<211>32<212>DNA<213>人工序列<400>29TGCACTGCAGCACTAGAACTCTACATGGCAAG32<210>30<211>20<212>DNA<213>人工序列<400>30GCGCATAGTTTCTGATGCAA20<210>31<211>20<212>DNA<213>人工序列<400>31TGCAACTTCGTGATCCTCTG20<210>32<211>23<212>DNA<213>人工序列<400>32ATCACTTGGCTCCACTGTTGTTC23<210>33<211>26<212>DNA<213>人工序列<400>33ACAAAACACACATAAACATCCAAAGT26<210>34<211>20<212>DNA<213>人工序列<400>34CTGGAGAATGGTGCGGAAGA20<210>35<211>23<212>DNA<213>人工序列<400>35CAGATAGCGAATCCTGCTGTTGT23<210>36<211>21<212>DNA<213>人工序列<400>36TCGCTGACCGTATGAGCAAAG21<210>37<211>21<212>DNA<213>人工序列<400>37TGTGAACGATTCCTGGACCTG21当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1