蛋白、跨膜核酸解旋纳米孔及其构建方法与应用与流程
本发明属于生物
技术领域:
,具体涉及一种跨膜核酸解旋纳米孔及其构建方法与应用。
背景技术:
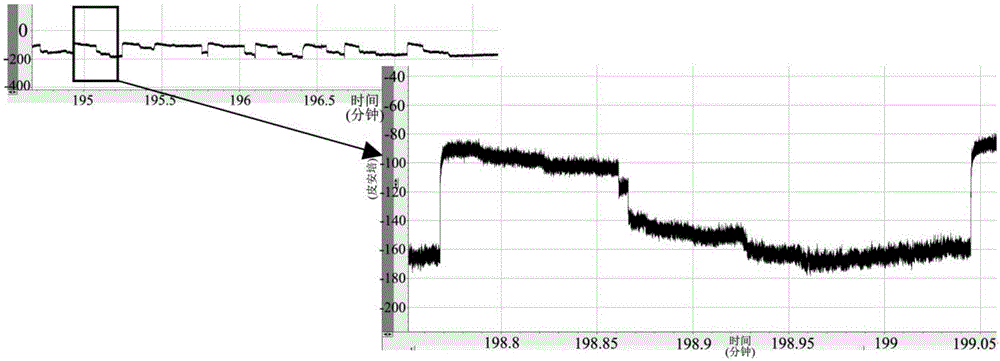
:对于生物和化学活性物质的高精准检测是长久以来工业和科研领域共同关注的目标之一,而这需要强健和稳定的传感装置,从α溶血素α-hl蛋白第一次应用于单分子检测领域开始,纳米孔作为一个单分子检测的技术平台已经越来越在发挥着重要的作用。通过分子与分子间的亲和作用(如共价结合或非共价吸引)来结合或“捕获”检测感兴趣的分析物,如组氨酸插入α-hl的β桶状区来特定区分量化镍、铜、以及锌等二价金属离子;利用基因工程手段在孔内腔部位嵌入特殊的配体分子来检测小的有机分子甚至蛋白质片段;在α-hl孔道的117号半胱氨酸上结合铜离子来区别氨基酸构型。除了α-hl以外,已经研究的其他蛋白质通道包括用于检测聚乙二醇的阿拉霉素、当下被广泛应用于高通量核酸测序研究的耻垢分枝杆菌重组蛋白mspa,以及孔道直径在3.6nm允许双链通过的噬菌体phi29dna包装马达蛋白等。α-hl和mspa这类蛋白纳米孔通常需要其他酶的辅助来完成待测物的检测,限制了其更广泛的应用。对于α-hl纳米孔,从已有的研究报道看,其跨膜β桶状区的直径最小处约1.5nm,但其长度在5.2nm左右,在利用该纳米孔做测序或其他小分子传感研究时,由于孔道最窄处的长度太长而无法使核酸链通过孔道做棘轮运动,即难以完成单碱基的区分,对其他小分子的传感分辨率也因此降低。而mspa虽然跨膜区段长度较α-hl短,但由于其通常只具备纳米孔的功能,在分子传感方面仅相当于人工碳纳米管,作为一个离子流通道而存在,譬如ianm、elizabeth等人利用mspa偶联hel308解旋酶或者φ29dna聚合酶在核酸链中区分单核苷酸的差异。而phi29包装马达蛋白由于自身不良的电压门控特性,在微量检测时电信号容易收到较强干扰。本领域研究人员正在用其他材料诸如合成类金属或硅纳米孔潜在的应用于dna测序,但是这种合成纳米孔目前仍不具备可靠的生产具有一致性质的重复结构能力,并且在化学修饰孔道方面缺乏多样性。所以对寻找更优良的蛋白质纳米孔或其替代物,仍是本领域的研究热点与难点。技术实现要素:本发明要解决的技术问题是克服现有的小孔径蛋白纳米孔在转运双链核酸时需要外接解旋活性组件的不足。本发明解决上述缺陷的技术方案是提供了一种单体蛋白。该单体蛋白:(1)为分离的牛乳头瘤病毒双链dna解旋酶的306-577位氨基酸构成的蛋白,其序列为seqidno.3所示;或(2):在为(1)限定的蛋白的氨基酸序列中经过取代和/或缺失和/或插入至少一个氨基酸所得的变体。进一步的,本发明的单体蛋白为所示(1)限定的蛋白的氨基酸序列中经过取代和/或缺失和/或插入1~20个氨基酸所得的变体。优选的,为所示(1)限定的蛋白的氨基酸序列中经过取代和/或缺失和/或插入1~15个氨基所得的与(1)限定的变体。进一步的。上述蛋白为氨基酸序列为seqidno.3所示的蛋白经过取代和/或缺失和/或插入不多于10个氨基酸所得的与该单体蛋白功能相同或相似的蛋白。更优选的,为所示(1)限定的蛋白的氨基酸序列中经过取代和/或缺失和/或插入1~10个氨基所得的与(1)限定的变体。再优选的,为所示(1)限定的蛋白的氨基酸序列中经过取代和/或缺失和/或插入1~5个氨基所得的与(1)限定的变体。更优选的,为所示(1)限定的蛋白的氨基酸序列中经过取代和/或缺失和/或插入1~3个氨基所得的与(1)限定的变体。进一步的,上述蛋白变体为氨基酸序列为seqidno.3所示的蛋白第421位由k突变为l得到的蛋白变体,或第323位由h突变为w得到的蛋白变体。优选的:上述蛋白变体为氨基酸序列为(1)所示限定的seqidno.3所示的氨基酸序列具有75%以上同源性的变体。优选的:为(1)所示限定的seqidno.3所示的氨基酸序列具有80%以上同源性的变体。更优选的:为(1)所示限定的seqidno.3所示的氨基酸序列具有90%以上同源性的变体。再优选的:为(1)所示限定的seqidno.3所示的氨基酸序列具有95%以上同源性的变体。进一步优选的:为(1)所示限定的seqidno.3所示的氨基酸序列具有98%以上同源性的变体。最优选的:为(1)所示限定的seqidno.3所示的氨基酸序列具有99%以上同源性的变体。本发明同时还提供了编码上述蛋白的基因。进一步的,上述基因的核苷酸序列如seqidno.4所示。同时,本发明还提供了含有上述基因的载体。当然地,本发明也提供了包含上述载体的宿主细胞。本发明同时还提供了另一种蛋白,(1)为分离的牛乳头瘤病毒双链dna解旋酶的306-605位氨基酸构成的蛋白,其序列为seqidno.1所示;或(2):在为(1)限定的蛋白的氨基酸序列中经过取代和/或缺失和/或插入至少一个氨基酸所得的变体。进一步的,所述单体蛋白为所示(1)限定的蛋白的氨基酸序列中经过取代和/或缺失和/或插入1~20个氨基酸所得的变体。优选的,为所示(1)限定的蛋白的氨基酸序列中经过取代和/或缺失和/或插入1~15个氨基所得的与(1)限定的变体。进一步的。上述蛋白为氨基酸序列为seqidno.1所示的蛋白经过取代和/或缺失和/或插入不多于10个氨基酸所得的与该单体蛋白功能相同或相似的蛋白。更优选的,为所示(1)限定的蛋白的氨基酸序列中经过取代和/或缺失和/或插入1~10个氨基所得的与(1)限定的变体。再优选的,为所示(1)限定的蛋白的氨基酸序列中经过取代和/或缺失和/或插入1~5个氨基所得的与(1)限定的变体。更优选的,为所示(1)限定的蛋白的氨基酸序列中经过取代和/或缺失和/或插入1~3个氨基所得的与(1)限定的变体。优选的:上述蛋白变体为氨基酸序列为(1)所示限定的seqidno.1所示的氨基酸序列具有75%以上同源性的变体。优选的:为(1)所示限定的seqidno.1所示的氨基酸序列具有80%以上同源性的变体。更优选的:为(1)所示限定的seqidno.1所示的氨基酸序列具有90%以上同源性的变体。再优选的:为(1)所示限定的seqidno.1所示的氨基酸序列具有95%以上同源性的变体。进一步优选的:为(1)所示限定的seqidno.1所示的氨基酸序列具有98%以上同源性的变体。最优选的:为(1)所示限定的seqidno.1所示的氨基酸序列具有99%以上同源性的变体。进一步的,上述蛋白为氨基酸序列为seqidno.1所示的蛋白第421位由k突变为l得到的蛋白变体,或第323位由h突变为w得到的蛋白变体。进一步的,所述蛋白变体的氨基酸序列分别如seqidno.6和seqidno.7所示。本发明同时还提供了编码上述蛋白的基因。进一步的,上述基因的核苷酸序列如seqidno.2所示。本发明还提供了一种上述蛋白变体的编码基因。核苷酸序列为seqidno.8和seqidno.9所示。同时,本发明还提供了含有上述基因的载体。当然地,本发明也提供了包含上述载体的宿主细胞。此外,本发明还提供了一种多聚体蛋白。该多聚体蛋白为含有两个以上的上述蛋白作为亚基形成的多聚体蛋白。进一步的,上述的构成多聚体蛋白的亚基数为4~8个。优选的,上述的构成多聚体蛋白的亚基数为6个。其中,上述多聚体蛋白为同源多聚体或异源多聚体。本发明还提供了上述的蛋白或者多聚体蛋白在制备纳米孔或者含导电通道的膜中的用途。本发明还提供了一种含导电通道的膜。该含导电通道的膜包括:(1)膜层;和(2)分离的上述多聚体蛋白,且所述多聚体蛋白嵌入到所述膜层以形成孔道,外加跨膜电势时可以经过所述孔道导电。本发明所述的跨膜电势也称作偏置电压。其中,上述纳米孔中所述膜层包括脂层。其中,上述纳米孔中所述脂层包含两亲脂类。其中,上述纳米孔中所述脂层可为平面膜层或脂质体。进一步的,上述纳米孔被施加电势时,所述含导电通道膜能够通过所述孔道易位dna或rna。优选的,上述膜层中所述的单层膜由pmoxa-pdms-pmoxa形成,pmoxa是二甲基二唑林;pdms是聚二甲基硅氧烷。此外,本发明还提供了制作含导电通道的膜的方法,其特性在于包括以下步骤:(a)准备干的两亲脂类;以及(b)将所述干的两亲脂类重悬于溶液中,所述溶液含有水性溶剂、渗透剂和多个分离的上述的蛋白,所述蛋白可作为亚基自行组装成多聚体蛋白,以获取包括脂双分子层的膜,在足以使所述多聚体形成孔道的条件和时间下多聚体蛋白嵌入所述脂双分子层中,得到含导电通道的膜。优选的,所述的多聚体蛋白为六聚体。其中,上述方法中所述的两亲脂类为含磷脂类。其中,上述方法中所述磷脂类选自下列的一种或多种:磷脂酰胆碱、磷脂酰乙醇胺、磷脂酰丝氨酸、磷脂酰肌醇、磷脂酰甘油、心磷脂、1,2-二植烷酰-sn-甘油-3-磷酸胆碱、和1,2-二油酰-sn-甘油-3-磷酸胆碱。本发明还提供了上述的纳米孔在制备单分子传感器件或者试剂盒中的用途中的用途。本发明也提供了一种单分子传感器件或者试剂盒,该单分子传感器件或者试剂盒含有上述的纳米孔作为元件之一。本发明此外还提供了牛乳头瘤病毒双链dna解旋酶蛋白或其同源蛋白在制备纳米孔或者含导电通道的膜中的用途,所述的牛乳头瘤病毒双链dna解旋酶蛋白的氨基酸序列为seqidno.5所示。进一步的,所述牛乳头瘤病毒双链dna解旋酶蛋白的同源蛋白选自以下表1所示。表1同源蛋白表同源蛋白来源ncbi登录号牛乳头瘤病毒病毒-1np_056739.1牛乳头瘤病毒病毒-1aab35071.1牛乳头瘤病毒病毒-1afv52373.1丁型乳头瘤病毒属-4acr78098.1丁型乳头瘤病毒属-4acr78091.1丁型乳头瘤病毒属-4acr78081.1奶牛乳头瘤病毒-13yp_009272574.1牛乳头瘤病毒-13ain81126.1牛乳头瘤病毒-2agr88554.1牛乳头瘤病毒-2amz04139.1毛牛乳头瘤病毒-1afq90258.1牛乳头瘤病毒-14akb94040.1本发明还提供了含导电通道的膜,包括:(1)膜层;和(2)分离的牛乳头瘤病毒双链dna解旋酶蛋白或其同源蛋白,所述多聚体蛋白嵌入到所述膜层以形成孔道,外加跨膜电势时可以经过所述孔道导电;所述的牛乳头瘤病毒双链dna解旋酶蛋白的氨基酸序列为seqidno.5所示。所述牛乳头瘤病毒双链dna解旋酶蛋白的同源蛋白选自表1所示。本发明首次对哺乳动物致病病毒中的关键成分蛋白利用蛋白质工程技术进行了改造,使其能构建出一种新型的蛋白质纳米孔而应用于核酸及其他物质的传感研究。本发明利用原核表达系统体外表达及纯化出该蛋白,同时成功的将其嵌在人工磷脂双分子层膜以及高分子膜上,成为了蛋白质纳米通道。通过研究其在各类电导缓冲体系下的电导分布,以及单链dna和单链rna的转运,以及其解旋酶活性,首创性的构建了全新的结合了纳米孔通道特点和蛋白自身具有的解旋酶活性的纳米孔传感系统,并且在脂质双分子层上实现了带单臂的双链dna的解旋和易位。本发明的有益效果在于:本发明创新性的发现了牛乳头瘤病毒双链dna解旋酶蛋白及其同源蛋白可以用于制备含导电通道膜。为本领域提供了一种新的有效选择。本发明创新性的发现了e1-1(306-577)蛋白,该蛋白单体形成的多聚体可以作为一个新的单纯的含导电通道膜而存在,并且我们验证了其在磷脂双分层膜上可以稳定存在并且易位核酸的特征。本发明进一步创新性的发现了e1-2(306-605)这一新的蛋白,并以之为基础成功构建了一种纳米孔和解旋酶一体化的传感系统,替代了现有的需要将解旋酶和纳米孔偶联的传感方式,可用作生物传感器。相对于目前的phi29和mspa、hel308和mspa以及phi29和α-hl等的偶联传感系统,本发明纳米孔能实现单酶完成待测物的捕获,过孔,传感各个步骤,大大简化了系统的复杂性。尤其是该纳米孔能同步进行双链dna解旋和传感分析,核酸多态性分析,核酸二级结构分析,核酸长度分析等;在药用方面,利用其电势驱动的溶质易位作用,还可以应用于脂质体载药治疗(例如药物靶向递送),该蛋白具有巨大的应用潜力。本发明还进一步的在e1-2蛋白的分子基础上进行了突变研究,得到了e1-2蛋白的突变体。所述突变型e1-1(306-577)单体或e1-2(306-605)单体在人工脂质膜上形成的孔道具有相比野生型多个优势。具体地,由所述突变型单体构建的孔比野生型更容易捕获核酸和其他负电性待测小分子;另外由所述突变型单体构建的孔呈现出电流范围的增加,这使得孔道内腔相比野生型更为狭窄,从而在通道检测电流上更为广泛和灵敏。附图说明图1:以pgex-6p-1为载体构建目的基因e1-1(306-577)重组质粒的琼脂糖凝胶电泳验证(gex-6p-1长度为4984bp,e1-1基因序列长度为816bp,所以酶切后得到两个条带,分别是4990bp和822bp)。图2:e1-1(306-577)蛋白单体(57kd)混杂物过分子筛后用聚丙烯酰胺凝胶电泳检测各出峰中目的蛋白,后续电生理实验使用为第2管。图3:e1-1(306-605)蛋白单体(59kd)混杂物过分子筛后用聚丙烯酰胺凝胶电泳检测各出峰中目的蛋白,后续电生理实验使用为第6管。图4:在70mv跨膜电压下,单孔的电流约为105pa,双孔在200pa左右图5:统计大量孔道电流分析得到单孔电导分布在1.3±0.07ns左右。图6:坡电压下得到i-v曲线斜率约为4.43(四个孔),所以单孔电导约为1.5。图7:在以pbs作为电导缓冲液时,该蛋白的电导分布为0.2±0.02ns,在-70mv的电压下,单孔的电流约为23pa。图8:50mv跨膜电压下,ssdna易位时单孔条件下引起约65pa的阻塞电流。图9:在pbs的缓冲液中,与kcl缓冲液中相似的是ssrna从孔道中易位引起的孔道阻塞率大约在80%。图10:pbs的缓冲液中,在-50mv下ssrna引起的阻塞电流约为8pa,易位时间1-2ms。图11:将一定浓度的合成的80nt的两条互补ssdna10倍稀释成10个浓度梯度,选取其中四个相邻浓度的ssdna来完成q-pcr定量分析实验。图12:如上述,用q-pcr得到的ct值和定浓度的ssdna完成标准曲线的制备。图13:该专利中所有双链核酸的获得均是通过此法:双链的退火在pcr仪上完成,变性温度95℃,时间两分钟,降温过程设置梯度程序(大约每分钟降温1度),耗时1小时20分钟;聚丙烯酰胺凝胶电泳分析得到的核酸产物。图14:利用dsdna中一条链两端的荧光淬灭基团bhq2淬灭荧光基团cy5来检测e1-1(306-577)的解旋酶活性。图15:通过控制合适的体系环境,包括atp浓度,mg2+浓度,体系温度等,我们在分子水平上观测到了双链dna的转运通过e1的现象。图16:在-40mv下我们发现大量的解旋dsdna转运现象,在解旋过程中的双链堵塞状态下我们将电压反转到+40mv下,结果发现孔道堵塞的现象一直持续,当电压回到-50mv下时,解旋现象再次出现,并且从堵塞状态重新开始解旋。图17:e1-2(306-605)随着双链长度的增加解旋时间也加长:随着-100mv电压下,ipore=-400pan=20,当dsdna链长为小于2000bp时解链速度接近匀速,当dsdna的链长越长时,我们发现e1-2的解旋活力有所下降,当链长接近5000bp时,解旋时间达到9s。图18:分别在室温下(21℃),等于、低于37℃和高于37℃的温度梯度下进行实验,结果发现随着温度的升高,解旋发生的次数呈明显正比例增大的趋势,当温度高于37℃时,解旋发生的次数又减少。图19:随着体系温度降低可以看到膜上解旋逐渐减少,当从低温重新回到高温时发现解旋增多。图20:对于同一条双链dna底物,我们发现在-100mv下解链需要大约3s的时间,当电压变成-20mv下时,解链耗时将近30s,从拟合的曲线方向看,电压驱动链移动的方向和e1-2解旋的方向一致。图21:e1-1(306-605,k421l,h323w)蛋白单体(59kd)和wt-e1(306-605)蛋白分别用聚丙烯酰胺凝胶电泳检测。图22、23:图22所示为突变体e1(306-605,k421l,h323w)嵌入巨脂囊泡膜上的电镜照片(talosf200c,标尺90nm);图23所示为突变体e1(306-605,k421l,h323w)嵌入巨脂囊泡膜上的电镜照片(talosf200c,标尺90nm)。图24:六聚体e1-1(306-605,k421l,h323w)蛋白在0.5mkcl,10mmhepes(ph7.5)电导缓冲液,100mv下单孔嵌入引发约75pa的电流瞬时上升。图25:ssdna通过突变体e1(306-605,k421l,h323w)孔道引起的孔道阻塞率约78%和易位时间约为0.5ms。图26:pbs缓冲液下,带单臂的dsdna通过人工脂质膜上的突变体e1(306-605,k421l,h323w)解旋作用引发的解旋电流信号,信号中明显出现三个台阶,分别对应双链的单臂进孔堵塞,解旋过程,单链堵孔以及开孔状态。解旋总耗时270ms。图27:非典型的dsdna通过突变体e1(306-605,k421l)解旋作用引发的解旋电流信号,其中解旋各个步骤所对应的信号台阶不是很明显,从开孔到下一个开孔耗时50ms这和酶的活力以及电导环境相关。图28:非典型的dsdna通过突变体e1(306-605,h323w)解旋作用引发的解旋电流信号,其中解旋各个步骤所对应的信号台阶不是很明显,从开孔到下一个开孔耗时50ms这和酶的活力以及电导环境相关。图29:在1mkcl的电导缓冲液中,50mv的偏置电压下,ssdna易位一个单孔易位时间在0.4ms左右。图30:在1mkcl的电导缓冲液中,50mv的偏置电压下,ssdna易位一个单孔引起约82%的孔道阻塞率。具体实施方式以下结合附图,对本发明进行说明。本发明研究的对象的起始是牛乳头瘤病毒的一种六聚体环状解旋酶,在牛乳头瘤病毒中起辅助基因组dna复制的作用。野生型该蛋白是牛乳头瘤病毒的一种atp依赖的解旋酶,在病毒复制时为解链dna双螺旋而存在。文献报道,在病毒基因组复制起始时该蛋白结合单链dna以六聚体形式附着在基因组dna复制起始位点,在atp酶水解atp供能的条件下发挥解旋作用将双链dna解螺旋成单链,并沿着单链dna从复制叉以3'-5'方向持续解链。野生型牛乳头瘤病毒双链dna解旋酶e1全长蛋白氨基酸序列(seqidno5),共605个氨基酸,斜体并下划线部分为e1-1(306-577):mandkgsnwdsglgcsyllteaecesdkeneepgagvelsvesdrydsqdedfvdnasvfqgnhlevfqalekkageeqilnlkrkvlgssqnssgseasetpvkrrksgakrrlfaeneanrvltplqvqgegegrqelneeqaishlhlqlvksknatvfklglfkslflcsfhditrlfkndkttnqqwvlavfglaevffeasfellkkqcsflqmqkrsheggtcavylicfntaksretvrnlmanmlnvreeclmlqppkirglsaalfwfksslspatlkhgalpewiraqttlnesideeedseedgdsmrtftcsarntnavd。本发明创新性的发现了发现牛乳头瘤病毒双链dna解旋酶蛋白及其同源蛋白可以用于制备纳米孔及含导电通道膜。制备得到的纳米孔及含导电通道膜具有制备表征目标样本的单分子传感器件或者试剂盒的用途。为本领域提供了一种新的有效选择。可以选用的牛乳头瘤病毒双链dna解旋酶蛋白的信息如下表2所示:表2牛乳头瘤病毒双链dna解旋酶蛋白的信息表从该蛋白的晶体结构和功能域我们知道,该蛋白的保守区域分布在1-121号氨基酸、以及166-575号氨基酸。且在两段保守区域内407-557号氨基酸是sf3解旋酶功能域,413-457号氨基酸属于atp水解酶的aaa+家族,142-308号氨基酸是dna结合域,84-86号氨基酸以及105-108号氨基酸分别为核酸定位信号区;我们鉴别了部分该蛋白的同族蛋白,它们具有相似结构,并且具有相同的功能——在atp水解能的作用下解旋双链dna。期望在采用所述的突变方案后,这些同族的同源蛋白也可在人工脂质膜上形成稳定的孔道,并且同e1-1(306-577)一样具有膜上核酸解旋的功能,成为核酸传感以及小分子待测物质传感研究的工具。根据晶体结构解析知道牛乳头瘤病毒双链dna解旋酶蛋白的主要解旋功能域存在于308-577氨基酸段,本发明在体外构建并纯化出了e1的截短体多肽e1-1(306-577),并用短链的双链dna(dsdna)验证了其六聚体在体外特定条件下依赖atp的解旋酶活性。本发明进一步利用该截短体多肽e1-1(306-577)制备纳米孔。如本专利前述利用该结构的六聚体形成的孔道完成了ssdna的转运,单链dna(ssdna)发生转运概率稍有差异。本发明在更进一步的研究中获得e1的另一个截短体e1-2(306-605)。该蛋白出人意料地能在体外各种电导缓冲液条件下,成功地在人工脂质膜上形成稳定的纳米孔道。本发明还利用膜片钳技术进行了上述纳米孔道的后续核酸传感方面的研究。结构解析表明e1-2蛋白形成的孔道内径大约为1.3nm左右,跨膜区长度和开口处直径分别在3.2nm和15nm左右。实验发现,在1m、0.3mmkcl以及pbs的缓冲液条件下,e1(306-605)可以在人工脂质膜上自组装成六聚体,并稳定于膜上形成孔道。在膜两侧施加跨膜电压后,孔道中有电流通过。在随后的ssdna转运实验中,发现短链的ssdna可以引发一系列电流阻断现象,但是利用dsdna重复相同实验,并不能引起类似现象,跨膜电流呈稳定状态,这些现象和e1的孔道内径相符。dsdna的直径大约在2nm左右,而e1的内径限制处约为1.3nm,所以当平末端的dsdna在跨膜电压的驱动下被e1捕获,大多数情况下或是发生孔道持续的完全大于50%的阻塞或是阻塞后随即开放;当在pbs的缓冲液或和pbs等盐浓度的缓冲液条件下带单臂的dsdna在跨膜电压驱动下被e1捕获后,加入特定浓度atp和mg离子时,结合e1本身的解旋酶活性以及作为生物纳米孔的特性,表明了在体外利用该e1-2(306-605)形成的孔道完成了人工脂质膜上的双链解旋。e1-1(306-577)的突变体和e1-2(306-605)的也具有相同或近似的功能,也在本发明的保护范围之内。研究中发现,e1-1(306-577)的突变体和e1-2(306-605)的突变体展现出改善的性质用于后续的孔道嵌膜和抓取负电性核酸以及ssdna易位等。具体来说,所述的突变体令人惊奇的展现出更加容易的人工脂质膜嵌孔特性、稳定的存在于磷脂膜上,且非特异性的电流波动进一步减少,由于孔道自身引起的开放电流的信噪比提高;孔道c端对于ssdna的抓取效率进一步得到提升;在核酸易位过程中孔道内腔对于ssdna的固有作用力减弱,易位电流呈现更加快速规律的峰型;所述突变体另一个优势在于突变后并不影响孔道自身作为一个dna解旋酶的特性。因此,本发明提供了一种突变型的e1-1(306-577)单体或突变型的e1-2(306-605)单体,其包含seqidno:1或seqidno:3所示的氨基酸序列的变体,其中所述变体包含至少一个如下的突变(下述的各突变位点的位数是以牛乳头瘤病毒双链dna解旋酶全长的第1位起算,牛乳头瘤病毒双链dna解旋酶的全长氨基酸序列为seqidno.5所示):(a)第479位为组氨酸(h)、赖氨酸(k);丝氨酸(s)、天冬酰胺(n)、苏氨酸(t);(b)第489位为组氨酸(h)、赖氨酸(k)、天冬酰胺(n)、苏氨酸(t)、丝氨酸(s);(c)第530位为组氨酸(h)、赖氨酸(k);丝氨酸(s)、天冬酰胺(n)、苏氨酸(t);(d)第529位为谷氨酰胺(q)、赖氨酸(k);(e)第525位为组氨酸(h)、赖氨酸(k)、丝氨酸(s)、亮氨酸(l)、苏氨酸(t);(f)第504位为天冬酰胺(n)、赖氨酸(k)、精氨酸(r),丝氨酸(s)、苏氨酸(t)、苯丙氨酸(f)、酪氨酸(y)、色氨酸(w);(g)第328位为谷氨酰胺(q)、赖氨酸(k)、精氨酸(r)、苯丙氨酸(f)、酪氨酸(y)、色氨酸(w);(h)第360位为天冬酰胺(n)、赖氨酸(k)、精氨酸(r)、苯丙氨酸(f)、酪氨酸(y)、色氨酸(w);(i)第322位为天冬酰胺(n)、亮氨酸(l)、异亮氨酸(i)、缬氨酸(v);苯丙氨酸(f)、色氨酸(w)、谷氨酰胺(q);(j)第372位为谷氨酰胺(q)、亮氨酸(l)、异亮氨酸(i)、缬氨酸(v)、脯氨酸(p)、苯丙氨酸(f)、色氨酸(w)、天冬酰胺(n);(k)第342位为天冬酰胺(n)、亮氨酸(l)、异亮氨酸(i)、缬氨酸(v);苯丙氨酸(f)、色氨酸(w)、谷氨酰胺(q);(l)第334位为天冬酰胺(n)、亮氨酸(l)、异亮氨酸(i)、缬氨酸(v);苯丙氨酸(f)、色氨酸(w)、谷氨酰胺(q);(m)第392位为天冬酰胺(n)、亮氨酸(l)、异亮氨酸(i)、缬氨酸(v);苯丙氨酸(f)、色氨酸(w)、谷氨酰胺(q);(n)第408位为天冬酰胺(n)、亮氨酸(l)、异亮氨酸(i)、缬氨酸(v);苯丙氨酸(f)、色氨酸(w)、谷氨酰胺(q);(o)第396位为亮氨酸(l)、异亮氨酸(i)、缬氨酸(v);苯丙氨酸(f)、色氨酸(w);丙氨酸(a)、甘氨酸(g);(p)第570位为缬氨酸(v);苯丙氨酸(f)、色氨酸(w);丙氨酸(a)、甘氨酸(g)、亮氨酸(l)、异亮氨酸(i);(q)第574位为色氨酸(w);丙氨酸(a)、甘氨酸(g)、亮氨酸(l)、异亮氨酸(i)、缬氨酸(v);苯丙氨酸(f);(r)第417位为亮氨酸(l)、异亮氨酸(i)、缬氨酸(v);苯丙氨酸(f)、色氨酸(w);丙氨酸(a)、甘氨酸(g);(s)第421位为缬氨酸(v);苯丙氨酸(f)、色氨酸(w);丙氨酸(a)、甘氨酸(g)、亮氨酸(l)、异亮氨酸(i);(t)第383位为缬氨酸(v);苯丙氨酸(f)、色氨酸(w);丙氨酸(a)、甘氨酸(g)、亮氨酸(l)、异亮氨酸(i);(u)第387位为组氨酸(h)、苯丙氨酸(f)、色氨酸(w);(v)第323位为亮氨酸(l)、异亮氨酸(i)、缬氨酸(v);苯丙氨酸(f)、色氨酸(w);丙氨酸(a)、甘氨酸(g);(w)第324位为亮氨酸(l)、异亮氨酸(i)、脯氨酸(p)、缬氨酸(v);(x)第565位为苏氨酸(t)、丝氨酸(s)、酪氨酸(y);(y)第426位为亮氨酸(l)、异亮氨酸(i)、缬氨酸(v);苯丙氨酸(f)、色氨酸(w);丙氨酸(a)、甘氨酸(g);本发明提供了上述突变型的e1-1(306-577)单体或突变型的e1-2(306-605)单体。上述的e1-1(306-577)变体或e1-2(306-605)变体的单体可用于形成本发明的导电膜通道。突变型e1-1(306-577)单体或e1-2(306-605)单体是序列与野生型e1-1(306-577)单体或e1-2(306-605)单体不同且保留了形成孔道的能力的单体。用于确认突变型单体形成孔的能力的方法同本专利提到的一致。所述突变型e1-1(306-577)单体或e1-2(306-605)单体在人工脂质膜上形成的孔道具有相比野生型多个优势。具体地,由所述突变型单体构建的孔比野生型更容易捕获核酸和其他负电性待测小分子;另外由所述突变型单体构建的孔呈现出电流范围的增加,这使得孔道内腔相比野生型更为狭窄,从而在通道检测电流上更为广泛和灵敏。另外,当所述突变型的e1-1(306-577)或e1-2(306-605)单体在人工脂质膜上形成孔道时,孔道跨膜区更容易稳定的存在于膜上,开孔电流信噪比相比野生型更高。令人惊讶的是,当核酸运动通过一些突变型的e1-1(306-577)或e1-2(306-605)单体构建的孔道时,引起的电流下降更大,这使得利用该孔道来鉴定核酸运动过孔时观察核酸序列与电流下降平台之间的关系成为可能,更进一步,使得该突变型孔道在未来具有成为核酸测序的潜力。所述突变体的核酸阅读性质的改善经三种主要机制实现,即通过改变:1、空间(突变氨基酸残基增大或变小);2、电荷(例如引入了+ev电荷使得核酸与氨基酸相互作用增强);3、非共价键合(例如引入可以以氢键和某些核苷酸结合的氨基酸);这三种机制的任一或多种可能是本发明的孔未来具有核苷酸阅读特性的原因。本发明中所涉及的蛋白位点的突变主要基于以下几个原因:在野生型的e1-1(306-577)或e1-2(306-605)中,n端开口在较窄一端,c端开口在较宽一端,六聚体成一个标准蘑菇状结构;形成孔道内腔分布有大量碱性氨基酸和带有负电磷酸基团ssdna结合。因此,利用野生型的e1-1(306-577)或e1-2(306-605)单体在人工脂质膜上嵌孔形成离子自由通过的导电通道时,发现孔道会在长时间的施加跨膜电压下从磷脂膜上掉落,记录的开孔电流水平基线存在波动,且当无待测分子通过孔道时开孔电流偶尔会出现小的非特异性的峰电流。我们利用突变型的e1-1(306-577)或e1-2(306-605)单体来改良上述缺陷;例如我们在较宽的c端对部分酸性氨基酸进行突变,479号和489号的天冬氨基酸(d)突变为组氨酸(h)或者赖氨酸(k)以提高负电性的核酸被孔道c端抓取的效率;当突变成天冬酰胺(n)时,减弱了c端开口处负电性氨基酸的密度,对于核酸(主要)或者富负电荷的待测物的静电拮抗相应减弱,从而间接使得孔道的捕获率提高。再例如我们在孔道内腔部位对一些酸性氨基酸进行突变,504号天冬氨酸(d),328号谷氨酸(e),分别突变为天冬酰胺(n),赖氨酸(k),精氨酸(r),谷氨酰胺(q)等,从酸性氨基酸(d,e)突变成中性氨基酸一方面可以明显减弱核酸易位过程中的静电拮抗作用,另一方面,当中性氨基酸为空间位阻较大的苯丙氨酸(f)、色氨酸(w)或者酪氨酸(y)时,由于在所形成的孔腔内部占有更大的空间位置,所以孔腔内非限制位点的直径被显著减小,与此同时,当替换后的孔腔内部氨基酸序列中苯环存在密度增大后,π电子堆积造成氨基酸排列更加紧密,孔腔内部收缩明显,当然这两种减小在检测方面具有双刃剑的结果;当中性的氨基酸为羟基类时,譬如丝氨酸(s)或者苏氨酸(t)时,由于羟基氧可以和核苷酸形成氢键键合作用,所以当核酸从c端进孔腔内部后可以更加缓慢的通过,这种机制在后续的核酸测序开发中将有更为有利的价值。在孔道侧部即跨膜区域将322号、342号、334号的天冬氨酸(d),372号谷氨酸(e)以及396号、383号赖氨酸(k)以及323号组氨酸(h)和574号精氨酸(r)突变为中性氨基酸亮氨酸(l)、甘氨酸(g)、丙氨酸(a)等,可以使孔道跨膜区更容易稳定的嵌入由脂肪酸长链构成的磷脂双分子层的疏水层,从而极大减弱孔道嵌入后由于不稳定而造成的开孔电流水平基线波动,低频率较大的噪声,具体的突变位点如下表3所示。表3突变位点以下通过实施例对本发明进行更加细致的说明。实施例一e1蛋白及其突变体重组载体构建和表达纯化:截短体e1-1(306-577)的氨基酸序列(seqidno.3):lqtekfdfgtmvqwaydhkyaeeskiayeyalaagsdsnaraflatnsqakhvkdcatmvrhylraetqalsmpayikarcklatgegswksiltffnyqnielitfinalklwlkgipkknclafigppntgksmlcnslihflggsvlsfanhkshfwlasladtraalvddathacwryfdtylrnaldgypvsidrkhkaavqikappllvtsnidvqaedrylylhsrvqtfrfeqpctdesgeqpfnitdadwksffvrlwgrldl。截短体e1-1(306-577)的编码基因序列(seqidno.4):ttgcagaccgagaaattcgacttcggaactatggtgcaatgggcctatgatcacaaatatgctgaggagtctaaaatagcctatgaatatgctttggctgcaggatctgatagcaatgcacgggcttttttagcaactaacagccaagctaagcatgtgaaggactgtgcaactatggtaagacactatctaagagctgaaacacaagcattaagcatgcctgcatatattaaagctaggtgcaagctggcaactggggaaggaagctggaagtctatcctaactttttttaactatcagaatattgaattaattacctttattaatgctttaaagctctggctaaaaggaattccaaaaaaaaactgtttagcatttattggccctccaaacacaggcaagtctatgctctgcaactcattaattcattttttgggtggtagtgttttatcttttgccaaccataaaagtcacttttggcttgcttccctagcagatactagagctgctttagtagatgatgctactcatgcttgctggaggtactttgacacatacctcagaaatgcattggatggctaccctgtcagtattgatagaaaacacaaagcagcggttcaaattaaagctccacccctcctggtaaccagtaatattgatgtgcaggcagaggacagatatttgtacttgcatagtcgggtgcaaacctttcgctttgagcagccatgcacagatgaatcgggtgagcaaccttttaatattactgatgcagattggaaatctttttttgtaaggttatgggggcgtttagacctg。载体质粒:pgex-6p-1。双酶切:bamhixhoi。引物(小写字母为酶切位点):正向引物:seqidno.10cgggatccttgcagaccgagaaat。反向引物:seqidno.11ccgctcgagttaatgatgatggtgatgatgcaggtctaaacgcccc。(seqidno.1)截短体e1-2(306-605)的氨基酸序列:lqtekfdfgtmvqwaydhkyaeeskiayeyalaagsdsnaraflatnsqakhvkdcamvrhylraetqalsmpayikarcklatgegswksiltffnyqnielitfinalklwlkgipkknclafigppntgksmlcnslihflggsvlsfanhkshfwlasladtraalvddathacwryfdtylrnaldgypvsidrkhkaavqikappllvtsnidvqaedrylylhsrvqtfrfeqpctdesgeqpfnitdadwksffvrlwgrldlideeedseedgdsmrtftcsarn。(seqidno.2)截短体e1-2(306-605)的编码基因序列:ttgcagaccgagaaattcgacttcggaactatggtgcaatgggcctatgatcacaaatatgctgaagagtctaaaatagcctatgaatatgctttggctgcaggatctgatagcaatgcacgggcttttttagcaactaacagccaagctaagcatgtgaaggactgtgcaactatggtaagacactatctaagagctgaaacacaagcattaagcatgcctgcatatattaaagctaggtgcaagctggcaactggggaaggaagctggaagtctattctaactttttttaattatcagaatattgaattaattacctttattaatgctttaaagctctggctaaaaggaattccaaaaaaaaactgtttagcatttattggccctccaaacacaggcaagtctatgctctgcaactcattaattcattttttgggtggtagtgttttatcttttgccaaccataaaagtcacttttggcttgcttccctagcagatactagagctgctttagtagatgatgctactcatgcttgctggaggtactttgacacatacctcagaaatgcattggatggctaccctgtcagtattgatagaaaacacaaagcagcggttcaaattaaagctccacccctcctggtaaccagtaatattgatgtgcaggcagaggacagatatttgtacttgcatagtcgggtgcaaacctttcgctttgagcagccatgcacagatgaatcgggtgagcaaccttttaatattactgatgcagattggaaatctttttttgtaaggttatgggggcgtttagacctgattgacgaggaggaggatagtgaagaggatggagacagcatgcgaacgtttacatgtagcgcaagaaacacaaatgcagttgattga。载体质粒:pgex-6p-1。双酶切:bamhixhoi。所用引物:(小写为酶切位点)正向引物:seqidno.12agttctgttccaggggcccctgggatccttgcagaccgagaaattcgacttcg。反向引物:seqidno.13tcagtcagtcacgatgcggccgctcgagttaatcaactgcatttgtgtttcttgcgctacatgtaaacgttcgca。e1-2突变体1(k421l)的氨基酸序列如seqidno.6所示:lqtekfdfgtmvqwaydhkyaeeskiayeyalaagsdsnaraflatnsqakhvkdcatmvrhylraetqalsmpayikarcklatgegswksiltffnyqnielitfinalklwllgipkknclafigppntgksmlcnslihflggsvlsfanhkshfwlasladtraalvddathacwryfdtylrnaldgypvsidrkhkaavqikappllvtsnidvqaedrylylhsrvqtfrfeqpctdesgeqpfnitdadwksffvrlwgrldlideeedseedgdsmrtftcsarntnavd。e1-2突变体1的核苷酸序列如seqidno.8所示:ggatccttgcagaccgagaaattcgacttcggaactatggtgcaatgggcctatgatcacaaatatgctgaggagtctaaaatagcctatgaatatgctttggctgcaggatctgatagcaatgcacgggcttttttagcaactaacagccaagctaagcatgtgaaggactgtgcaactatggtaagacactatctaagagctgaaacacaagcattaagcatgcctgcatatattaaagctaggtgcaagctggcaactggggaaggaagctggaagtctatcctaactttttttaactatcagaatattgaattaattacctttattaatgctttaaagctctggctactgggaattccaaaaaaaaactgtttagcatttattggccctccaaacacaggcaagtctatgctctgcaactcattaattcattttttgggtggtagtgttttatcttttgccaaccataaaagtcacttttggcttgcttccctagcagatactagagctgctttagtagatgatgctactcatgcttgctggaggtactttgacacatacctcagaaatgcattggatggctaccctgtcagtattgatagaaaacacaaagcagcggttcaaattaaagctccacccctcctggtaaccagtaatattgatgtgcaggcagaggacagatatttgtacttgcatagtcgggtgcaaacctttcgctttgagcagccatgcacagatgaatcgggtgagcaaccttttaatattactgatgcagattggaaatctttttttgtaaggttatgggggcgtttagacctgattgacgaggaggaggatagtgaagaggatggagacagcatgcgaacgtttacatgtagcgcaagaaacacaaatgcagttgattaactcgag。e1-2突变体2(h323w)的氨基酸序列如seqidno.7所示:lqtekfdfgtmvqwaydwkyaeeskiayeyalaagsdsnaraflatnsqakhvkdcatmvrhylraetqalsmpayikarcklatgegswksiltffnyqnielitfinalklwllgipkknclafigppntgksmlcnslihflggsvlsfanhkshfwlasladtraalvddathacwryfdtylrnaldgypvsidrkhkaavqikappllvtsnidvqaedrylylhsrvqtfrfeqpctdesgeqpfnitdadwksffvrlwgrldlideeedseedgdsmrtftcsarntnavd。e1-2突变体2的核苷酸序列如seqidno.9所示:ggatccttgcagaccgagaaattcgacttcggaactatggtgcaatgggcctatgattggaaatatgctgaggagtctaaaatagcctatgaatatgctttggctgcaggatctgatagcaatgcacgggcttttttagcaactaacagccaagctaagcatgtgaaggactgtgcaactatggtaagacactatctaagagctgaaacacaagcattaagcatgcctgcatatattaaagctaggtgcaagctggcaactggggaaggaagctggaagtctatcctaactttttttaactatcagaatattgaattaattacctttattaatgctttaaagctctggctaggaattccaaaaaaaaactgtttagcatttattggccctccaaacacaggcaagtctatgctctgcaactcattaattcattttttgggtggtagtgttttatcttttgccaaccataaaagtcacttttggcttgcttccctagcagatactagagctgctttagtagatgatgctactcatgcttgctggaggtactttgacacatacctcagaaatgcattggatggctaccctgtcagtattgatagaaaacacaaagcagcggttcaaattaaagctccacccctcctggtaaccagtaatattgatgtgcaggcagaggacagatatttgtacttgcatagtcgggtgcaaacctttcgctttgagcagccatgcacagatgaatcgggtgagcaaccttttaatattactgatgcagattggaaatctttttttgtaaggttatgggggcgtttagacctgattgacgaggaggaggatagtgaagaggatggagacagcatgcgaacgtttacatgtagcgcaagaaacacaaatgcagttgattaactcgag。构建突变体重组质粒,使用pcr克隆方法突变载体插入到载体质粒pgex-6p-1中,双酶切位点分别为5’bamhi和3’xhoi。正向引物:seqidno.14agttctgttccaggggcccctgggatccttgcagaccgagaaattcgacttcg。反向引物:seqidno.15tcagtcagtcacgatgcggccgctcgagttaatcaactgcatttgtgtttcttgcgctacatgtaaacgttcgca。利用上述pcr引物(如前述)对完整的牛乳头瘤病毒基因组进行扩增,之后用两个限制性内切酶bamhi和xhoi对载体pgex-6p-1以及得到的pcr产物进行酶切,载体载有gst标签亲和以及分别含有bamhi和xhoi两个限制性位点,最后用t4连接酶将双酶切后的目的基因片段和质粒载体重新连接成环状重组质粒。重组质粒的检测是在转化质粒进大肠杆菌dh5α后利用重组载体带有的氨苄抗性对重组质粒是否成功转化进行初步筛选。菌落pcr后,用核酸凝胶电泳初步验证目的片段是否连接进载体(如图1,pgex-6p-1长度为4984bp,e1-1基因序列长度为816bp,所以酶切后得到两个条带,分别是4990bp和822bp),然后做基因测序得到测序结果比对确认是否完成重组并且未发生突变。具体的e1蛋白的表达和纯化为:重组质粒pgex-6p-1-n-gst转化进大肠杆菌表达菌菌株bl21中进行蛋白质表达。在37℃及220rpm转速下,在11ml含有50μg/ml氨苄青霉素的lb培养基中将上述大肠杆菌培养过夜。随后取10ml培养液注入到1l的新鲜含50μg/ml氨苄青霉素的lb培养基中,并在菌浓度达到0.6-0.8单位(od600)时加入0.5mm(终浓度)iptg(异丙基硫代半乳糖苷)诱导。诱导16个小时(16℃)后,在4000rpm转速下离心20分钟收获细菌,用蛋白缓冲液20mmtris-hcl(ph7.3),200mmnacl重悬菌沉淀,高压破菌四次之后在16000rpm转速下离心40分钟收获破菌上清液,用0.45μm孔径的滤膜过滤上清液后用gst亲和层析柱来纯化目的蛋白,杂蛋白洗脱干净后,psp酶柱上酶切目的蛋白2个小时,后用蛋白缓冲液将目的蛋白洗脱下来。目的蛋白在用gst亲和层析纯化后纯度就很高了,最后利用分子筛将多聚体和单体分离开,收最先出来的峰蛋白即为较纯的e1了,而且从分子筛出峰位置来分析,得到的e1为六聚体形态,野生的e1形态非常相似。留样用聚丙烯酰胺凝胶电泳检测得到的蛋白样品符合预期大小。图2、3分别为e1-1和e1-257的分子筛出峰聚丙烯酰胺凝胶电泳图,对应的单体分子量分别为57kd和59kd,后继的电生理实验中使用第2管和第6管(e1-1用第2管,e1-2用第6管)。两个突变体的基因克隆和表达纯化方法参考野生型e1(306-605),在过完分子筛收最先出现的峰顶管即为突变体的e1。留样用聚丙烯酰胺凝胶电泳检测得到的蛋白样品和wt-e1(306-605)对比,由于只突变了一个位点的氨基酸,所以得到的突变体分子量和wt-e1(306-605)蛋白非常接近,在凝胶电泳条带上看也近乎在一个位置,如图21所示。实施例二、蛋白截短体及其突变体的荧光标记以及膜融合实验:荧光标记截短体e1-2(306-605)蛋白:所用材料为氟标记异硫氰酸荧光素(fitc)共轭试剂盒(sigma,圣路易斯,密苏里州)。具体使用依照试剂盒描述,多余的fitc通过柱层析除去,fitc连接的e1用蛋白缓冲液(20mmtris-hcl(ph7.3),200mmnacl)洗脱。用sds-page验证fitc标记的e1(306-605),(图略,fitc标记的e1-2在sds-page上的位置略高于未标记的e1-2)。包含截短体e1-2(306-605)的(suvs)小囊泡制备:为了制备大小约在0.1微米的包含e1蛋白的小囊泡,将1mg/ml的dopc加入一个小瓶中,用氮气吹干氯仿后加入包含e1蛋白(浓度约为0.5mg/ml)的水溶液,再水化脂质膜制成悬浊液,用迷你挤压器(购自美国avanti公司)挤压和再水化蛋白-脂质复合物通过聚碳酸酯膜(100nm孔内径)形成suvs。短期用存放于4℃下,长期存放于-80℃下,只有未荧光标记的suvs在光学显微镜下的形态和同大小规格的囊泡形态相似,用迷你挤压器制备的suvs均一性良好)。包含截短体e1-2(306-605)的(guvs)巨脂囊泡制备:同时可以制备荧光标记的巨脂囊泡,将1ml1mg/ml的dopc或dphpc和1%的texasred(购自美国thermofiher公司)在小瓶子里混合,将氯仿用氮气吹干,该步也可利用旋转蒸发仪将氯仿抽干,将抽干氯仿的dopc或dphpc放入干燥器中干燥过夜,之后加入混合了大约0.5mg/mle1蛋白的200-300mm蔗糖溶液水化干燥过的脂质分子层得到混合的嵌入了e1蛋白的guvs。被texasred标记的囊泡可以在荧光显微镜下观察到。该步也可以利用上步fitc标记的e1-2来制备荧光标记的囊泡嵌蛋白复合体。在荧光显微镜下观察单标记的巨脂囊泡发现,旋蒸法得到的直径较大的囊泡大小均一性不如挤压器制备的suvs,直径超过50μm的囊泡蛋白复合体在后期的人工脂质膜上嵌孔实验中发现,此直径的囊泡极容易使已形成的磷脂双分子层破裂(人工脂质膜形成于50μm直径孔的聚甲醛树脂材料表面,购自美国warner公司)。用相同的方法对截短体e1-2的突变体进行膜融合实验,结果显示:同wt-e1(306-605)一致也可以稳定的插入到人工脂质双分子层和pmoxa-pdms-pmoxa三嵌段高分子膜上;实验过程同wt-e1(306-605),得到插入了突变体e1的巨脂囊泡后,利用冷冻电镜观察膜上的蛋白嵌入情况,如图22和图23,发现蛋白孔道可以稳定存在于膜上。荧光显微镜下观察双标记的囊泡嵌蛋白复合体发现(红色为texasred标记的囊泡,绿色为fitc标记的e1-2蛋白),部分标记e1-2蛋白在囊泡膜上呈不规则定位,部分如预期“跨膜区”插入磷脂双分子层中形成通道,此结果也证明e1-2可以在电导缓冲液中在电压的驱动下自发聚集在人工脂质膜上并以预期的方向嵌进膜中形成电导通路。实施例三、e1蛋白及其突变体电生理实验:电生理学的测量:仪器为hekaepc-10usb,该仪器集成了放大器和数模转化部分,两根电极分别为施压(电压钳模式)电极和参比电极,为一对银/氯化银电极。用来测量跨磷脂双分子层膜两侧的跨膜电流。所有采样频率均在2khz,低通滤波频率为1khz。数据收集由patch-master软件完成,数据分析由clamfit完成。脂双分子层的构建:利用水平式标准脂质双分子层构建器以及垂直式标准脂质双分子层箱(bch-13a,购自warner.no.64-0451.定制50μmcups)来构建平面脂质双分子层。分别用孔径为0.8-0.24毫米薄聚四氟乙烯材料薄膜(tp-02购自easternsci.llc)和孔径为0.05毫米定制的聚甲醛树脂材料cups将构建器以及双分子层箱分为顺式(工作溶剂250μl)和反式(工作容积为250ml)分隔室。孔径先用0.5μl浓度为1mg/ml的dopc或dphpc(溶剂为正己烷)溶液预涂两次,以确保孔边缘都均匀的被完全覆盖,两个分隔室装满电导缓冲液(5mmhepesph值7.5,不同浓度的kcl溶液,或是pbs溶液),在50μm孔附近加入25mg/ml的dopc或者dphpc溶液(溶剂为正癸烷),此时观察到电流从10.2na回到0pa左右。e1电导分布:e1(306-577)在1mkcl电导液中的电导测量:利用先前制备的囊泡蛋白复合体在水平聚四氟乙烯膜的微孔(如前述)或垂直聚甲醛树脂微孔上形成磷脂双分子层嵌入e1-2蛋白纳米孔的结构。这两种复合体在加入隔室(一般为顺隔室)前需要稀释10-20倍,加入量在2μl左右。另一种简易方法是用2μl枪尖吸取三分之二复合体溶液然后在顺隔室微孔上方吹出一个气泡,用气泡轻缓的涂抹微孔,e1-2孔道蛋白会自发形成于磷脂双分子层上。测量e1-2蛋白孔道电导有两种方法:第一种是在稳定的跨膜电压下(如-70mv)测量多通道嵌入和掉落时的电流跳跃,统计数据计算通道电导的分布。第二种方法是在膜两侧施加一个扫描电压(例如-120mv至120mv),通过计算电流电压曲线斜率来计算通道电导。本发明统计了大量实验数据,证实单孔电导分布在1.34±0.07ns左右,电导缓冲液为5mmhepes和1mkcl,(如图5),在70mv跨膜电压下,单孔的电流约为105pa,双孔在200pa左右(如图4)。在坡型电压下,获得iv曲线计算得到单孔电导约为1.5ns(如图6)。在5mmhepes和0.5mkcl的电导缓冲液液条件下,测得e1的单孔电导分布在0.78ns左右,在50mv跨膜电压下单个e1成孔在人工脂质膜上形成的电流大小大约为40pa,双孔在85pa左右。在i-v曲线下测得单孔电导约为1.57/2ns左右;在以pbs作为电导缓冲液时,该蛋白的电导分布为0.2±0.02ns(如图7),在-70mv的电压下,单孔的电流约为23pa。对e1蛋白突变体采用相同的方法进行电生理实验。结果显示:在0.5mkcl,10mmhepes(ph7.5)的电导缓冲液中,施加+100mv的偏置电压,发现其单孔嵌入引起约75pa的电流上升台阶,如图24所示,在统计了大量的单孔嵌入和掉落信号以及在-200-200mv的扫描电压下,发现其单孔电导分布和wt-e1(306-605)孔道相似,均在1.3±0.07ns左右,并且扫描电压下,电流对电压的散点线性拟合结果较好,离散度低。实施例四、e1蛋白及其突变体孔道稳定性研究:e1-2孔道的稳定性研究:与此同时,本发明分别在正向和负向跨膜电压下检测了该e1孔道在磷脂膜上的稳定性,以及孔道的高电压门控现象。再采用相同的方法测定了e1蛋白突变体形成的孔道在磷脂膜上的稳定性,结果发现:e1孔道在正向300mv下以及负向300mv下孔道不存在门控现象,且在高电压下可以稳定存在于磷脂膜上。与此同时发现当电导缓冲液体系中存在过多的甘油(保存e1蛋白所用)时,膜嵌蛋白复合体变的异常的不稳定,极容易蛋白从膜上脱落或者膜直接破裂。e1蛋白突变体(k421l,h323w)的高电压下稳定性实验中,采用-300-300mv扫描电压,发现在较高电压(±300)下,孔道保持稳定存在于膜上,且电导分布并未发生明显改变,显示出突变体e1(k421l,h323w)也和wt-e1(306-605)一样,具有较为稳定的电导特性。实施例五、e1蛋白及其突变体的ssdna/ssrna易位实验:单链dna易位实验中所用的ssdna(单链dna)为takara公司合成的48nt的单链引物dna,其序列信息如后述。dna易位的缓冲液为hepes/1mkcl。一般情况下有两种方法来实现该条件下的核酸转运。方法1:在孔蛋白插入磷脂双分子层后将电压调至0毫伏然后在顺式面加入待转运核酸;方法2:将待转运核酸预混进电导缓冲液中,顺式和反式面中完全等量混合。dna的易位运动主要依赖外加的跨膜电压。如无特殊说明,本实验中ssdna转运均采取方法1,转运体系中ssdna浓度均为100纳摩尔每升。对于实验中所用的48nt的单链dna,单孔道嵌入膜中,易位时引起的电流阻断大约为65皮安培(跨膜电压约50mv)(如图8),该片段核酸易位引发的电流阻断比约为82%(ib/i,ib为核酸通过时引起的电流阻断,单位pa;i为单个孔蛋白插入磷脂双分子层后引起的电流变化,单位pa)。核酸易位的时间分布在2ms左右,(如图29、30)。在pbs作为电导缓冲液的体系中,我们同样做了ssdna的易位实验,实验过程同上述,结果表明,在+100mv的跨膜电压下,24nt的ssdna从e1-2孔中易位的阻塞率约为80%,易位时间大约为1-2ms(如图9、10)。同时还做了ssrna的纳米孔易位实验,该实验的过程与ssdna一致,仅需要注意的是rna的降解,我们利用depc水溶液以及高温高压灭菌的方法避免rna在实验过程中被降解。实验结果表明,ssrna易位引起的孔道阻塞率大约在80%,与ssdna相似,在-50mv下,pbs的缓冲体系下阻塞电流约为8pa,易位时间1-2ms。作为对照,未加入核酸而只有成孔道的体系内电流轨迹是静态的。该孔道的一个优点为对照组静态电流极少出现干扰性的非特异性阻断.实验中观察到当核酸预先混合进入电导缓冲液中后,蛋白孔道第一次插入磷脂膜后可以立即观察到大量的核酸转运现象,之后阻断现象变的很少发生,此结果显示,当样品槽内缺乏搅拌设备时,dna易位现象延迟发生。采用相同的电导条件和单链核酸对e1蛋白突变体进行ssdna/ssrna易位实验。在1mkcl,10mmhepes(ph7.5)的电导条件下,施加120mv的偏置电压,发现ssdna易位时的孔道阻塞率接近78%左右,易位时间接近0.5ms,(如图26、25),数据和wt-e1(306-605)孔道下得到的近似。实施例六、e1的dsdna易位阻滞实验:双链dna(dsdna)转运实验:将bamh1酶切得到的双链dna(如上述)加入顺式面,易位缓冲液同ssdna为10mmhepes/1mkcl。分别在50mv,70mv,120mv,150mv电压下检测转运信号,结果未观察到双链dna易位现象。实施例七、e1核酸转运验证实验利用q-pcr来制作核酸的扩增标准曲线:由合成的两条单链(80nt)退火成双链后用2%琼脂糖凝胶鉴定,并对双链做胶回收,用qubit○r3.0(thermofisherscientific公司,美国;)测定回收的双链dna浓度(该方法精度高于紫外分光光度计法),将得到的已知浓度的双链核酸稀释成10个10倍的浓度梯度,然后利用q-pcr(premixsybr-takara公司,日本)做该双链核酸的浓度-ct值标准曲线,得到标准关系式,(如图11、12所示;每个浓度梯度下ct值的重复性较好,且r2=0.99+所以该标准关系式可以较好的作为后续单链dna转运实验的计算依据。)q-pcr定量分析通过孔道单链核酸:同上所述,在顺室区成膜并嵌入e1孔道蛋白后,同样在顺室加入50nm80nt-dna(此为第一种方法),或者预先在双室的电导缓冲液中混入等量(25nm)的48nt-dna(此为第二种方法)。作为阴性对照,在不加e1蛋白而成膜的顺室区加入50nm80nt-dna,或者双室加入等量25nm80nt-dna。膜两侧施加-70毫伏电压,分别在10分钟、20分钟、40分钟、60分钟、90分钟后收集双室的电导液用于q-pcr定量分析。核酸转运等实验中涉及到的所有核酸链描述如下:(均购自takara公司)48nt-dna序列为seqidno.16所示:3’-tttttttttaaaaaattttttggggggttttttccccccttttttttt-5’。44nt-dna序列分别为seqidno.17和seqidno.18所示:5'-agctccacccctcctggtaaccagtttttttttttttttttttt-3'(seqidno.17)。5'-ttttttttttttttttttttctggttaccaggaggggtggagct-3'(seqidno.18)。24nt-dna序列为seqidno.19所示:5'-ctggttaccaggaggggtggagct-3'。带标签的核酸链描述如seqidno.20和seqidno.21所示:5’-cctacgccaccagctccgtagg-3’(5’-cy5,3’-bhq2)(seqidno.20)。5’-cctacggagctggtggcgtaggtttttttttttttttttttt-3’(seqidno.21)。带dspacer(dspacer为只有磷酸骨架而没有碱基的核苷酸,所以其空间结构相比正常核苷酸非常的小)的双链核酸为seqidno.22的第11和12位之间插入3个dspacer(具体为5’-tttttttttttxxxttttttttttt-3’(x为dspacer))和seqidno.23所示:5’-tttttttttttttttttttttt-3’(seqidno.22)。5’-aaaaaaaaaaaaaaaaaaaa-3’(seqidno.23)。用于q-pcr定量转运分析核酸序列如seqidno.24和seqidno.25所示:5’-caggcagaggacagatatttgtacttgcatagtcgggtgcaaacctttcgctttgagcagccatgcacagatgaatcgggtttttttttttttttttttt(seqidno.24)。5’-cccgattcatctgtgcatggctgctcaaagcgaaaggtttgcacccgactatgcaagtacaaatatctgtcctctgcctg(seqidno.25)。两条引物分别为seqidno.26和seqidno.27所示:5’-caggcagaggacagatattt(seqidno.26)。5’-cccgattcatctgtgcatgg(seqidno.27)。双链的退火在pcr仪上完成,变性温度95℃,时间两分钟,降温过程设置梯度程序(大约每分钟降温1度),耗时1小时20分钟。琼脂糖凝胶检测得到的核酸产物(如图13)。本发明实验中用到的双链dna来自环状质粒hag-c1由核酸内切酶bamh1单酶切得到,用qiagendna纯化回收试剂盒进行纯化,得到的双链dna长度为3800bp。实施例八e1体外解旋实验本发明利用e1(306-577)在体外验证了该蛋白六聚体的解双链dna螺旋活性。解旋实验采用的缓冲液为20mmhepes(ph7.5),0.7mg/mlbsa,5%glycerol,5mmmgcl2,3mmdtt;反应由2mmatp启动,实验中用到的核酸底物为22bp,5’,3’荧光基团和淬灭基团标记且两端设计存在发夹结构的短链核酸。该解旋酶在体外条件下由于缺少病毒本身所含的起dna复制辅助功能的其他蛋白组分,所以无法直接解链平末端的dsdna。在体外解旋实验以及后面提到的膜上解旋实验均使用合成的带一条单链臂的dsdna,e1蛋白解旋以该单臂核酸链进孔起始。解旋过程中需要激发光和发射光波长分别为643nm和667nm,用bio-tek多功能荧光酶标仪(美国博腾公司)持续监测反应体系中的底物(5nm核酸底物)荧光来直观观察解旋过程,当双链被解旋酶解开双螺旋成单链时由于其中一条单链dna链的前后两端存在发夹结构,发夹结构配对导致荧光集团和荧光淬灭集团相遇,达到荧光淬灭的结果。该实验结果表明,e1-2在体外条件下具有解旋酶活性,可以在atp存在的条件下解开双链核酸,如图14。实施例九e1及其突变体在人工脂质膜上的解旋实验:在验证了e1的体外解旋酶活性后,设计了e1-2在人工脂质膜上的解旋实验:e1人工脂质膜上解旋实验中,把e1蛋白插入到人工脂质膜上,在室温21℃且无atp与mg2+存在的条件下,双链dna无法转运通过e1蛋白,因为双链dna的直径大于e1蛋白孔的直径(如前所述)。但是通过控制合适的体系环境,包括atp浓度,mg2+浓度,体系温度等,我们在分子水平上观测到了双链dna的转运通过e1的现象(如图15)。作为对照,我们选取了另外一种没有解旋酶活性的孔蛋白耻垢分枝杆菌重组蛋白mspa(其孔的直径与e1相当,均小于双链dna的直径)来转运双链dna,结果表明其在非解旋体系(无atp,mg2+)下以及与e1-2解旋相同的温度、atp浓度、mg2+浓度等条件下,双链dna均无法转运通过mspa孔蛋白。由于dna解旋酶发挥催化活性的条件中需要较低的盐浓度,所以在人工脂质膜上的解旋实验采用了pbs作为电导缓冲液(大约相当于0.15mkcl),该环境下e1-2的电导约为0.2±0.02ns。实验方案如下:在pbs的电导缓冲液中行成人工双分子层膜,然后嵌孔(方法如上述),当e1-2孔道嵌膜复合体稳定后,在顺势腔一侧加入带单臂的dsdna终浓度为12.5nm(见上材料描述)用加热板对电导缓冲液升温至37℃,然后加入终浓度为5mm的atp和终浓度为5mm的mg2+。实验结果表明,dsdna在atp的水解作用下被嵌在双分子层膜上的e1-2解螺旋成单链并从孔道中易位至反势腔一侧。在-40mv下发现大量的解旋dsdna转运现象,在解旋过程中的双链堵塞状态下将电压反转到+40mv下,结果发现孔道堵塞的现象一直持续,当电压回到-50mv下时,解旋现象再次出现,并且从堵塞状态重新开始解旋,如图16。不同长度dsdna的膜上解旋:与此同时,本发明探索了不同链长的双链dna在人工脂质膜上的解旋现象。使用xhoi和ecoo109i内切酶将一个重组质粒pet-28b+mspa切成5个长度不等片段(图略),由于该两个酶均可以切出带黏性末端的线性双链,dsdna上具有一条伸出来的单臂(长度为5bp,原因如上述),所以利用这5个长度不等的dsdna来探究不同链长对于膜上解旋的影响,实验过程同上述。实验结果表明,其余条件相同时,随着链长的延长,e1-2孔解旋的时间也随着正比例的延长。如图17,-100mv电压下,ipore=-400pan=20,当dsdna链长为小于2000bp时解链速度接近匀速;当dsdna的链长越长时,发现e1-2的解旋活力有所下降,当链长接近5000bp时,解旋时间达到9s。不同温度下的dsdna膜上解旋:另一方面,本发明尝试在不同的温度下,其余条件均相同时观察膜上解旋的现象,所用24bp核酸链如上所述,分别在室温下(21℃),低于35℃,35℃-37℃,高于37℃的温度梯度下进行实验。结果发现随着温度的升高,解旋发生的次数呈明显正比例增大的趋势,当温度大于37℃时解旋现象又开始减少,这和e1-2作为一个病毒解旋酶的特性相符(如图18、19)。不同跨膜电压下dsdna膜上解旋:本发明还在不同跨膜电压下测定了e1-2解旋同一dsdna底物所需的时间,实验过程同上述。实验结果表明,将核酸底物混合进顺势腔中,在负向电压下,逐渐减小电压绝对值,解旋时间相应的延长,且用电压梯度和解旋时间拟合出一条非直线函数,所得曲线朝向坐标轴,表明且同时侧面证明了除过电压本身的驱动力外,e1-2也在主动解旋,两者的力同向。如图20,对于同一条双链dna底物,在-100mv下解链需要大约3s的时间,当电压变成-20mv下时,解链耗时将近30s,从拟合的曲线方向看,电压驱动链移动的方向和e1-2解旋的方向一致。由于e1是一个蘑菇状结构,在dna复制时,单链从n端的开口处进入蛋白孔道,因此可以知道,该状态下的蛋白n端开口朝向顺势腔负电极。特殊核酸底物的膜上解旋:本发明同时设计了另一种特殊的核酸底物,在寡聚a-t的带单臂dsdna中一条链上插入三个缺失了碱基的dspacer,利用这种底物完成解旋实验。结果发现,在普通的解旋信号中,特定位置出现大小在20-30pa的小台阶。并且该小台阶信号特定出现的位置和dspacer在核酸链中出现的位置相符。e1膜上解旋实验的验证(依赖于mg2+和atp的作用):在验证e1-2膜上解旋现象的实验中,采用了过量edta螯合mg2+,使解旋酶失活的实验原理,实验过程同上述。在解旋现象持续发生的过程中,向反应体系中加入过量的edta螯合剂。结果发现随着edta量的增加,解旋现象逐渐受到抑制,最大抑制效率达到80%以上,此时当我们再次向反应体系中补加过量的mg2+时,可以明显观察到解旋现象重现大量出现,恢复到最高效率时1/2以上。与此同时,当使用atp的另一种类似物atpαs来竞争性替代解旋体系中的atp时,结果发现由于atpαs无法像atp一样水解供能,所以膜上解旋被明显抑制,因为这种抑制并不像edta螯合mg2+那样可逆,所以当过量atpαs加入解旋体系中可以发现,膜上解旋逐渐消失。采用相同的实验方法和条件研究e1蛋白突变体在人工脂质膜上解旋情况,结果发现:e1蛋白突变体由2mmatp起始转运,在-100mv的偏置电压下发现和wt-e1(306-605)相似的解旋信号,如图27,28所示。上述的实施例表明,本发明首次成功将牛乳头瘤病毒的一种六聚体环状解旋酶进行工程改造成为蛋白质纳米孔,嵌入磷脂双层膜及高分子膜中。该纳米孔可在高电压下稳定存在于磷脂双分子层上,无门控现象;并且在人工脂质膜上仍具有解旋酶的特性,譬如温度特异性,被atp类似物竞争抑制作用等。该纳米孔可在膜上被动转运单链rna、单链dna;并可以利用atp水解的作用在膜上主动解旋带有单链臂的dsdna,且解旋时间与底物的长度存在正比例关系。本发明上述的实验证明,本发明创新性的发现了e1-1(306-577)、e1-2(306-605)两种蛋白,e1-1蛋白能够作为一个新的单纯的含导电通道膜而存在,在磷脂双分层膜上可以稳定存在并且可以易位核酸;e1-2还进一步的具有纳米孔和解旋酶的双重功效,本发明构建了纳米孔和解旋酶一体化的传感系统替代了现有的需要将解旋酶和纳米孔偶联的传感方式,具有很好的应用前景。进一步的,本发明还创造性的对e1-2蛋白进行了突变研究,得到了e1-2蛋白的突变体,研究发现该突变型单体构建的孔比野生型更容易捕获核酸和其他负电性待测小分子;另外由所述突变型单体构建的孔呈现出电流范围的增加,这使得孔道内腔相比野生型更为狭窄,从而在通道检测电流上更为广泛和灵敏。序列表<110>四川大学<120>跨膜核酸解旋纳米孔及其构建方法与应用<130>a180035k<141>2018-01-23<150>201710060033.9<151>2017-01-24<160>27<170>siposequencelisting1.0<210>1<211>294<212>prt<213>人工序列(artificialsequence)<400>1leuglnthrglulyspheasppheglythrmetvalglntrpalatyr151015asphislystyralaglugluserlysilealatyrglutyralaleu202530alaalaglyseraspserasnalaargalapheleualathrasnser354045glnalalyshisvallysaspcysalametvalarghistyrleuarg505560alagluthrglnalaleusermetproalatyrilelysalaargcys65707580lysleualathrglygluglysertrplysserileleuthrphephe859095asntyrglnasnilegluleuilethrpheileasnalaleulysleu100105110trpleulysglyileprolyslysasncysleualapheileglypro115120125proasnthrglylyssermetleucysasnserleuilehispheleu130135140glyglyservalleuserphealaasnhislysserhisphetrpleu145150155160alaserleualaaspthrargalaalaleuvalaspaspalathrhis165170175alacystrpargtyrpheaspthrtyrleuargasnalaleuaspgly180185190tyrprovalserileasparglyshislysalaalavalglnilelys195200205alaproproleuleuvalthrserasnileaspvalglnalagluasp210215220argtyrleutyrleuhisserargvalglnthrpheargpheglugln225230235240procysthraspgluserglygluglnpropheasnilethraspala245250255asptrplysserphephevalargleutrpglyargleuaspleuile260265270aspgluglugluaspserglugluaspglyaspsermetargthrphe275280285thrcysseralaargasn290<210>2<211>903<212>dna<213>人工序列(artificialsequence)<400>2ttgcagaccgagaaattcgacttcggaactatggtgcaatgggcctatgatcacaaatat60gctgaagagtctaaaatagcctatgaatatgctttggctgcaggatctgatagcaatgca120cgggcttttttagcaactaacagccaagctaagcatgtgaaggactgtgcaactatggta180agacactatctaagagctgaaacacaagcattaagcatgcctgcatatattaaagctagg240tgcaagctggcaactggggaaggaagctggaagtctattctaactttttttaattatcag300aatattgaattaattacctttattaatgctttaaagctctggctaaaaggaattccaaaa360aaaaactgtttagcatttattggccctccaaacacaggcaagtctatgctctgcaactca420ttaattcattttttgggtggtagtgttttatcttttgccaaccataaaagtcacttttgg480cttgcttccctagcagatactagagctgctttagtagatgatgctactcatgcttgctgg540aggtactttgacacatacctcagaaatgcattggatggctaccctgtcagtattgataga600aaacacaaagcagcggttcaaattaaagctccacccctcctggtaaccagtaatattgat660gtgcaggcagaggacagatatttgtacttgcatagtcgggtgcaaacctttcgctttgag720cagccatgcacagatgaatcgggtgagcaaccttttaatattactgatgcagattggaaa780tctttttttgtaaggttatgggggcgtttagacctgattgacgaggaggaggatagtgaa840gaggatggagacagcatgcgaacgtttacatgtagcgcaagaaacacaaatgcagttgat900tga903<210>3<211>272<212>prt<213>人工序列(artificialsequence)<400>3leuglnthrglulyspheasppheglythrmetvalglntrpalatyr151015asphislystyralaglugluserlysilealatyrglutyralaleu202530alaalaglyseraspserasnalaargalapheleualathrasnser354045glnalalyshisvallysaspcysalathrmetvalarghistyrleu505560argalagluthrglnalaleusermetproalatyrilelysalaarg65707580cyslysleualathrglygluglysertrplysserileleuthrphe859095pheasntyrglnasnilegluleuilethrpheileasnalaleulys100105110leutrpleulysglyileprolyslysasncysleualapheilegly115120125proproasnthrglylyssermetleucysasnserleuilehisphe130135140leuglyglyservalleuserphealaasnhislysserhisphetrp145150155160leualaserleualaaspthrargalaalaleuvalaspaspalathr165170175hisalacystrpargtyrpheaspthrtyrleuargasnalaleuasp180185190glytyrprovalserileasparglyshislysalaalavalglnile195200205lysalaproproleuleuvalthrserasnileaspvalglnalaglu210215220aspargtyrleutyrleuhisserargvalglnthrpheargpheglu225230235240glnprocysthraspgluserglygluglnpropheasnilethrasp245250255alaasptrplysserphephevalargleutrpglyargleuaspleu260265270<210>4<211>816<212>dna<213>人工序列(artificialsequence)<400>4ttgcagaccgagaaattcgacttcggaactatggtgcaatgggcctatgatcacaaatat60gctgaggagtctaaaatagcctatgaatatgctttggctgcaggatctgatagcaatgca120cgggcttttttagcaactaacagccaagctaagcatgtgaaggactgtgcaactatggta180agacactatctaagagctgaaacacaagcattaagcatgcctgcatatattaaagctagg240tgcaagctggcaactggggaaggaagctggaagtctatcctaactttttttaactatcag300aatattgaattaattacctttattaatgctttaaagctctggctaaaaggaattccaaaa360aaaaactgtttagcatttattggccctccaaacacaggcaagtctatgctctgcaactca420ttaattcattttttgggtggtagtgttttatcttttgccaaccataaaagtcacttttgg480cttgcttccctagcagatactagagctgctttagtagatgatgctactcatgcttgctgg540aggtactttgacacatacctcagaaatgcattggatggctaccctgtcagtattgataga600aaacacaaagcagcggttcaaattaaagctccacccctcctggtaaccagtaatattgat660gtgcaggcagaggacagatatttgtacttgcatagtcgggtgcaaacctttcgctttgag720cagccatgcacagatgaatcgggtgagcaaccttttaatattactgatgcagattggaaa780tctttttttgtaaggttatgggggcgtttagacctg816<210>5<211>605<212>prt<213>人工序列(artificialsequence)<400>5metalaasnasplysglyserasntrpaspserglyleuglycysser151015tyrleuleuthrglualaglucysgluserasplysgluasngluglu202530proglyalaglyvalgluleuservalgluseraspargtyraspser354045glnaspgluaspphevalaspasnalaservalpheglnglyasnhis505560leugluvalpheglnalaleuglulyslysalaglyglugluglnile65707580leuasnleulysarglysvalleuglyserserglnasnsersergly859095serglualasergluthrprovallysargarglysserglyalalys100105110argargleuphealagluasnglualaasnargvalleuthrproleu115120125glnvalglnglygluglygluglyargglngluleuasngluglugln130135140alaileserhisleuhisleuglnleuvallysserlysasnalathr145150155160valphelysleuglyleuphelysserleupheleucysserphehis165170175aspilethrargleuphelysasnasplysthrthrasnglnglntrp180185190valleualavalpheglyleualagluvalphepheglualaserphe195200205gluleuleulyslysglncysserpheleuglnmetglnlysargser210215220hisgluglyglythrcysalavaltyrleuilecyspheasnthrala225230235240lysserarggluthrvalargasnleumetalaasnmetleuasnval245250255arggluglucysleumetleuglnproprolysileargglyleuser260265270alaalaleuphetrpphelysserserleuserproalathrleulys275280285hisglyalaleuproglutrpileargalaglnthrthrleuasnglu290295300serleuglnthrglulyspheasppheglythrmetvalglntrpala305310315320tyrasphislystyralaglugluserlysilealatyrglutyrala325330335leualaalaglyseraspserasnalaargalapheleualathrasn340345350serglnalalyshisvallysaspcysalathrmetvalarghistyr355360365leuargalagluthrglnalaleusermetproalatyrilelysala370375380argcyslysleualathrglygluglysertrplysserileleuthr385390395400phepheasntyrglnasnilegluleuilethrpheileasnalaleu405410415lysleutrpleulysglyileprolyslysasncysleualapheile420425430glyproproasnthrglylyssermetleucysasnserleuilehis435440445pheleuglyglyservalleuserphealaasnhislysserhisphe450455460trpleualaserleualaaspthrargalaalaleuileaspaspala465470475480thrhisalacystrpargtyrpheaspthrtyrleuargasnalaleu485490495aspglytyrprovalserileasparglyshislysalaalavalgln500505510ilelysalaproproleuleuvalthrserasnileaspvalglnala515520525gluaspargtyrleutyrleuhisserargvalglnthrpheargphe530535540gluglnprocysthraspgluserglygluglnpropheasnilethr545550555560aspalaasptrplysserphephevalargleutrpglyargleuasp565570575leuileaspgluglugluaspserglugluaspglyaspsermetarg580585590thrphethrcysseralaargasnthrasnalavalasp595600605<210>6<211>300<212>prt<213>人工序列(artificialsequence)<400>6leuglnthrglulyspheasppheglythrmetvalglntrpalatyr151015asphislystyralaglugluserlysilealatyrglutyralaleu202530alaalaglyseraspserasnalaargalapheleualathrasnser354045glnalalyshisvallysaspcysalathrmetvalarghistyrleu505560argalagluthrglnalaleusermetproalatyrilelysalaarg65707580cyslysleualathrglygluglysertrplysserileleuthrphe859095pheasntyrglnasnilegluleuilethrpheileasnalaleulys100105110leutrpleuleuglyileprolyslysasncysleualapheilegly115120125proproasnthrglylyssermetleucysasnserleuilehisphe130135140leuglyglyservalleuserphealaasnhislysserhisphetrp145150155160leualaserleualaaspthrargalaalaleuvalaspaspalathr165170175hisalacystrpargtyrpheaspthrtyrleuargasnalaleuasp180185190glytyrprovalserileasparglyshislysalaalavalglnile195200205lysalaproproleuleuvalthrserasnileaspvalglnalaglu210215220aspargtyrleutyrleuhisserargvalglnthrpheargpheglu225230235240glnprocysthraspgluserglygluglnpropheasnilethrasp245250255alaasptrplysserphephevalargleutrpglyargleuaspleu260265270ileaspgluglugluaspserglugluaspglyaspsermetargthr275280285phethrcysseralaargasnthrasnalavalasp290295300<210>7<211>300<212>prt<213>人工序列(artificialsequence)<400>7leuglnthrglulyspheasppheglythrmetvalglntrpalatyr151015asptrplystyralaglugluserlysilealatyrglutyralaleu202530alaalaglyseraspserasnalaargalapheleualathrasnser354045glnalalyshisvallysaspcysalathrmetvalarghistyrleu505560argalagluthrglnalaleusermetproalatyrilelysalaarg65707580cyslysleualathrglygluglysertrplysserileleuthrphe859095pheasntyrglnasnilegluleuilethrpheileasnalaleulys100105110leutrpleuleuglyileprolyslysasncysleualapheilegly115120125proproasnthrglylyssermetleucysasnserleuilehisphe130135140leuglyglyservalleuserphealaasnhislysserhisphetrp145150155160leualaserleualaaspthrargalaalaleuvalaspaspalathr165170175hisalacystrpargtyrpheaspthrtyrleuargasnalaleuasp180185190glytyrprovalserileasparglyshislysalaalavalglnile195200205lysalaproproleuleuvalthrserasnileaspvalglnalaglu210215220aspargtyrleutyrleuhisserargvalglnthrpheargpheglu225230235240glnprocysthraspgluserglygluglnpropheasnilethrasp245250255alaasptrplysserphephevalargleutrpglyargleuaspleu260265270ileaspgluglugluaspserglugluaspglyaspsermetargthr275280285phethrcysseralaargasnthrasnalavalasp290295300<210>8<211>915<212>dna<213>人工序列(artificialsequence)<400>8ggatccttgcagaccgagaaattcgacttcggaactatggtgcaatgggcctatgatcac60aaatatgctgaggagtctaaaatagcctatgaatatgctttggctgcaggatctgatagc120aatgcacgggcttttttagcaactaacagccaagctaagcatgtgaaggactgtgcaact180atggtaagacactatctaagagctgaaacacaagcattaagcatgcctgcatatattaaa240gctaggtgcaagctggcaactggggaaggaagctggaagtctatcctaactttttttaac300tatcagaatattgaattaattacctttattaatgctttaaagctctggctactgggaatt360ccaaaaaaaaactgtttagcatttattggccctccaaacacaggcaagtctatgctctgc420aactcattaattcattttttgggtggtagtgttttatcttttgccaaccataaaagtcac480ttttggcttgcttccctagcagatactagagctgctttagtagatgatgctactcatgct540tgctggaggtactttgacacatacctcagaaatgcattggatggctaccctgtcagtatt600gatagaaaacacaaagcagcggttcaaattaaagctccacccctcctggtaaccagtaat660attgatgtgcaggcagaggacagatatttgtacttgcatagtcgggtgcaaacctttcgc720tttgagcagccatgcacagatgaatcgggtgagcaaccttttaatattactgatgcagat780tggaaatctttttttgtaaggttatgggggcgtttagacctgattgacgaggaggaggat840agtgaagaggatggagacagcatgcgaacgtttacatgtagcgcaagaaacacaaatgca900gttgattaactcgag915<210>9<211>912<212>dna<213>人工序列(artificialsequence)<400>9ggatccttgcagaccgagaaattcgacttcggaactatggtgcaatgggcctatgattgg60aaatatgctgaggagtctaaaatagcctatgaatatgctttggctgcaggatctgatagc120aatgcacgggcttttttagcaactaacagccaagctaagcatgtgaaggactgtgcaact180atggtaagacactatctaagagctgaaacacaagcattaagcatgcctgcatatattaaa240gctaggtgcaagctggcaactggggaaggaagctggaagtctatcctaactttttttaac300tatcagaatattgaattaattacctttattaatgctttaaagctctggctaggaattcca360aaaaaaaactgtttagcatttattggccctccaaacacaggcaagtctatgctctgcaac420tcattaattcattttttgggtggtagtgttttatcttttgccaaccataaaagtcacttt480tggcttgcttccctagcagatactagagctgctttagtagatgatgctactcatgcttgc540tggaggtactttgacacatacctcagaaatgcattggatggctaccctgtcagtattgat600agaaaacacaaagcagcggttcaaattaaagctccacccctcctggtaaccagtaatatt660gatgtgcaggcagaggacagatatttgtacttgcatagtcgggtgcaaacctttcgcttt720gagcagccatgcacagatgaatcgggtgagcaaccttttaatattactgatgcagattgg780aaatctttttttgtaaggttatgggggcgtttagacctgattgacgaggaggaggatagt840gaagaggatggagacagcatgcgaacgtttacatgtagcgcaagaaacacaaatgcagtt900gattaactcgag912<210>10<211>24<212>dna<213>人工序列(artificialsequence)<400>10cgggatccttgcagaccgagaaat24<210>11<211>46<212>dna<213>人工序列(artificialsequence)<400>11ccgctcgagttaatgatgatggtgatgatgcaggtctaaacgcccc46<210>12<211>53<212>dna<213>人工序列(artificialsequence)<400>12agttctgttccaggggcccctgggatccttgcagaccgagaaattcgacttcg53<210>13<211>75<212>dna<213>人工序列(artificialsequence)<400>13tcagtcagtcacgatgcggccgctcgagttaatcaactgcatttgtgtttcttgcgctac60atgtaaacgttcgca75<210>14<211>53<212>dna<213>人工序列(artificialsequence)<400>14agttctgttccaggggcccctgggatccttgcagaccgagaaattcgacttcg53<210>15<211>75<212>dna<213>人工序列(artificialsequence)<400>15tcagtcagtcacgatgcggccgctcgagttaatcaactgcatttgtgtttcttgcgctac60atgtaaacgttcgca75<210>16<211>48<212>dna<213>人工序列(artificialsequence)<400>16tttttttttaaaaaattttttggggggttttttccccccttttttttt48<210>17<211>44<212>dna<213>人工序列(artificialsequence)<400>17agctccacccctcctggtaaccagtttttttttttttttttttt44<210>18<211>44<212>dna<213>人工序列(artificialsequence)<400>18ttttttttttttttttttttctggttaccaggaggggtggagct44<210>19<211>24<212>dna<213>人工序列(artificialsequence)<400>19ctggttaccaggaggggtggagct24<210>20<211>22<212>dna<213>人工序列(artificialsequence)<400>20cctacgccaccagctccgtagg22<210>21<211>42<212>dna<213>人工序列(artificialsequence)<400>21cctacggagctggtggcgtaggtttttttttttttttttttt42<210>22<211>22<212>dna<213>人工序列(artificialsequence)<400>22tttttttttttttttttttttt22<210>23<211>20<212>dna<213>人工序列(artificialsequence)<400>23aaaaaaaaaaaaaaaaaaaa20<210>24<211>100<212>dna<213>人工序列(artificialsequence)<400>24caggcagaggacagatatttgtacttgcatagtcgggtgcaaacctttcgctttgagcag60ccatgcacagatgaatcgggtttttttttttttttttttt100<210>25<211>80<212>dna<213>人工序列(artificialsequence)<400>25cccgattcatctgtgcatggctgctcaaagcgaaaggtttgcacccgactatgcaagtac60aaatatctgtcctctgcctg80<210>26<211>20<212>dna<213>人工序列(artificialsequence)<400>26caggcagaggacagatattt20<210>27<211>20<212>dna<213>人工序列(artificialsequence)<400>27cccgattcatctgtgcatgg20当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1