滇重楼胆甾醇C22羟化酶及其编码基因和应用的制作方法
本发明涉及一种滇重楼胆甾醇c22羟化酶及其编码基因,以及滇重楼胆甾醇c22羟化酶及编码基因在植物育种及生物合成中的运用,属于药用成分合成生物学领域。
通过聚合酶链式反应首次克隆得到了滇重楼(parispolyphyllasmithvar.yunnanensis(franch.)hara)中胆甾醇c22羟化酶基因(ppcyp90b27)的cdna全长序列,然后利用合成生物学手段,构建酵母工程菌,在酵母中生产22(r)-羟基胆甾醇。
背景技术
滇重楼(parispolyphyllasmithvar.yunnanensis(franch.)hara)是我国著名的药用植物之一,主要活性成分为根茎中提取的重楼甾体皂苷(约占化合物数目的80%),研究表明其具有强烈的药理活性,以其根茎为主要原料制成的中成药云南白药、宫血宁、热毒清等,临床用于治疗功能性子宫出血、神经性皮炎、外科炎症以及肿瘤等具有显著的疗效,具有极高的经济价值和市场前景。然而由于滇重楼种子有“二次休眠”生理特性,繁殖率低,根茎的自然生长速度也十分缓慢,从种子成长为药用商品一般需要10-15年,严重制约了滇重楼产量,市场缺口较大,货源紧缺,供不应求,价格飞涨。因此,改善滇重楼植物资源,通过科学手段寻找能够高效积累或生产重楼甾体皂苷的途径是重楼当前急需解决的问题。重楼皂苷属于甾体皂苷,其苷元主要为异螺旋甾烷醇类(isospirostanols,c25为r构型)的薯蓣皂苷元(diosgenin)和偏诺皂苷元(pennogenin)(薯蓣皂苷元为主)。胆甾醇(cholesterol)是薯蓣皂苷元(diosgenin)生物合成途径中的一个重要前体。胆甾醇侧链经过c-22的羟基化等一系列反应生成的中间体环化为半缩酮,继而生成薯蓣皂苷元的螺缩酮结构。cyp90b27基因编码的单加氧酶即为负责甾体皂苷途径上胆甾醇下游第一步羟化的p450酶基因。因此cyp90b27的活性能够直接影响薯蓣皂苷的生物合成。滇重楼胆甾醇c22羟化酶基因(ppcyp90b27)基因的克隆,为利用发酵工程大量生产活性成分重楼皂苷提供重要基础。在本发明被公布之前,尚未有任何公开或报道过本发明中所提及的滇重楼胆甾醇c22羟化酶基因及其氨基酸序列。
技术实现要素:
本发明一方面提供了一种分离的蛋白,即胆甾醇c22羟化酶,所述蛋白参与甾体皂苷类化合物的生物合成,尤其是参与薯蓣皂苷类化合物的生物合成,如将胆甾醇转化为22-羟基胆甾醇。
本发明所述羟化酶,是一种参与滇重楼甾体皂苷类化合物合成,尤其是22-羟基胆甾醇合成的关键酶,所述酶具有如下氨基酸序列:
(1)seqidno:2所示氨基酸序列;
(2)seqidno:2所示的氨基酸序列经取代、缺失或增加一个或多个氨基酸且功能相同的蛋白。
本发明中,所述分离的蛋白,即胆甾醇c22羟化酶,是指:具有对胆甾醇c22羟化活性的酶,其序列如seqidno:2所示,当然还包括具有与天然胆甾醇羟化酶相同功能的seqidno:2序列的变异形式。这些变异形式包括(但不限于):若干个(通常为1-50个,较佳地1-30个,更佳地1-20个,最佳地1-10个)氨基酸的缺失、插入和/或取代,以及在c末端和/或n末端添加一个或数个(通常为20个以内,较佳地为10个以内,更佳地为5个以内)氨基酸。例如,在本领域中,用性能相近或相似的氨基酸进行取代时,通常不会改变蛋白的功能。又比如,在c末端和/或n末端添加一个或数个氨基酸通常也不会改变蛋白质的功能。胆甾醇c22羟化酶还包括其活性片段和活性衍生物。
胆甾醇c22羟化酶变体或具有实质上相似的序列一致性的多肽的特征在于具有一个或多个氨基酸替换、缺失或插入。这些改变优选在性质上较小,即保守氨基酸替代(见表1)和不显著影响酶的折叠或活性的其它替代;小的缺失,典型地一个至约30个氨基酸的缺失;氨基或羧基端延伸,例如氨基端甲硫氨酸残基,不超过约20-25个残基的小的接头肽或亲和标签。本发明因此提供包含与seqidno:2至少有70%,优选至少有90%、更优选95%、96%、97%、98%、99%或更多一致的序列的多肽。
表1保守氨基酸替代
可以确定包含对于维持结构完整性关键的区域或域的氨基酸残基。在这些区域中或多或少耐受改变而保持分子的整个三级结构的特定残基。分析序列结构的方法包括,但不限于具有高氨基酸或核苷酸一致性的多个序列的比对、二级结构倾向(propensity)、二级元图(binarypatterns)、互补堆积(complementarypacking)和隐蔽的极性相互作用(barton,currentopin.struct.biol.5:372-376,1995;和cordes等,currentopin.struct.biol.6:3-10,1996)。一般地,当设计分子修饰或鉴定特定片段时,将在确定结构的同时评价修饰的分子的活性。
可以在胆甾醇c22羟化酶中进行氨基酸序列改变以便最少破坏对生物学活性必须的高级结构。例如,当胆甾醇c22羟化酶包含一个或多个螺旋时,将改变氨基酸残基以便不破坏螺旋的几何学和其中的构象改变将使一些关键功能(例如分子与其结合伙伴的结合)减弱的其它分子成分。氨基酸序列改变的效果可以通过例如以上公开的计算机模拟进行预测,或通过晶体结构分析进行测定(见例如lapthorn等,nat.struct.biol.2:266-268,1995)。本领域熟知的其它技术对改变蛋白和标准分子(例如天然蛋白)的折叠进行比较,例如,可以比较变体和标准分子中的半胱氨酸分布情况。质谱和使用还原和烷基化的化学修饰为测定与二硫键相关的或未形成这些键的半胱氨酸残基提供了方法(bean等,anal.biochem.201:216-266,1992;gray,proteinsci.2:1732-1748,1993;和patterson等,anal.chem.66:3727-3732,1994)。一般认为如果修饰的分子与标准分子具有不相同的半胱氨酸分布情况,则折叠受到影响。另一个用于测量这点的被接受的熟知方法是园二色谱(cd)。测量和比较修饰分子和标准分子产生的cd谱是常规的(johnson,proteins7:205-214,1990)。晶体学是另一个分析折叠和结构的熟知方法,核磁共振(nmr)、消化肽作图和表位作图也是分析折叠及蛋白质和多肽之间的结构相似性的已知方法(schaanan等,science257:961-964,1992)。
本发明中,胆甾醇c22羟化酶的变异体形式包括:同源序列、保守性变异体、等位变异体、天然突变体、诱导突变体、在高或低的严谨条件下能与雷公藤三萜合酶基因杂交的dna所编码的蛋白。
本发明的另一方面提供了一种编码本发明所述编码本发明所述分离的蛋白(胆甾醇c22羟化酶)的基因,即滇重楼胆甾醇c22羟化酶基因(parispolyphyllacyp90b27,ppcyp90b27):所述基因,它是下列核苷酸序列之一:
(1)seqidno:1第所示的核苷酸分子;或
(2)seqidno:1第所示的核苷酸分子经取代、缺失或增加一个或多个核苷酸且表达相同功能蛋白的核苷酸序列,或;
(3)在严谨条件下与seqidno:1所示核苷酸分子杂交的核苷酸序列,所述严谨条件为:在含0.1%sds的0.1×sspe或含0.1%的sds的0.1×ssc溶液中杂交。
本发明所述胆甾醇c22羟化酶编码基因是指:编码胆甾醇c22羟化酶的核苷酸序列,如seqidno:1中核苷酸序列及其简并序列。该简并序列指位于seqidno:1序列的编码框核苷酸中,有一个或多个密码子被编码相同氨基酸的简并密码子所取代后而产生的序列。由于密码子的简并性,所以与seqidno:1中核苷酸序列同源性低至约70%的简并序列也能编码出seqidno:2所述的序列。还包括能在中度严谨条件下,更佳的在高度严谨条件下与seqidno:1中核苷酸序列杂交的核苷酸序列。还包括与seqidno:1中核苷酸序列的同源性至少70%,较佳地至少80%,更佳地至少90%,最佳地至少95%的核苷酸序列。还包括能编码具有与天然的胆甾醇c22羟化酶相同功能的蛋白的seqidno:1中开放阅读框序列的变异形式。这些变异形式包括(但不限于)若干个(通常为1-90个,较佳地1-60个,更佳地1-20个,最佳地1-10个)核苷酸的缺失、插入和/或取代,以及在5’和/或3’端添加数个(通常为60个以内,较佳地为30个以内,更佳地为10个以内,最佳地为5个以内)核苷酸。
杂交反应的“严谨度”可以容易的由本领域普通技术人员确定,而且通常根据探针长度、洗涤温度、和盐浓度凭经验计算。通常,较长的探针要求较高的温度以正确退火,而较短的探针需要较低的温度。杂交通常依赖于当互补链存在于低于其解链温度的环境中时变性dna重新退火的能力。探针和可杂交序列之间的期望同源性程度越高,可使用的相对温度也越高。结果是,推断出较高相对温度将趋向于使反应条件更为严格,而较低温度也就较不严格。关于杂交反应严谨度的另外细节和解释,参见ausubel等人,《currentprotocolsinmolecularbiology》,wileyintersciencepublishers,1995。
“严谨条件”或“高严谨条件”,如本文中所定义的,可如下鉴别:(1)采用低离子强度和高温进行洗涤,例如0.015m氯化钠/0.0015m柠檬酸钠/0.1%十二烷基硫酸钠,50℃;(2)在杂交过程中采用变性剂,诸如甲酰胺,例如50%(v/v)甲酰胺及0.1%牛血清清蛋白/0.1%ficoll/0.1%聚乙烯吡咯烷酮/50mm磷酸钠缓冲液ph6.5,含750mm氯化钠,75mm柠檬酸钠,42℃;或(3)在采用50%甲酰胺,5xssc(0.75mnacl,0.075m柠檬酸钠),50mm磷酸钠(ph6.8),0.1%焦磷酸钠,5xdenhardt氏溶液,超声波处理的鲑鱼精dna(50μg/ml),0.1%sds,和10%硫酸右旋糖苷的溶液中于42℃杂交过夜,以及于42℃在0.2xssc(氯化钠/柠檬酸钠)中洗涤10分钟,接着在含edta的0.1xssc中于55℃进行10分钟高严格性洗涤。
本发明的还一目的在于提供一种表达载体,所述表达载体包含编码本发明所述胆甾醇c22羟化酶或其变体的多核苷酸(或称ppcyp90b27基因或其变体),或在严谨条件下可与所述多核苷酸杂交的核苷酸序列,所述表达载体还包含启动子和终止子,其中所述启动子与所述多核苷酸可操作地连接,并且所多核苷酸与所述转录终止子可操作地连接。
本发明中,可选用本领域已知的各种载体,如市售的载体,包括质粒、粘粒等。在生产本发明胆甾醇c22羟化酶时,可以将胆甾醇c22羟化酶基因的核苷酸序列可操作地连接于表达调控序列,从而形成胆甾醇c22羟化酶表达载体。所述“可操作地连连接”当指dna区段时表示这些区段按照一定方式排列以致它们可以协调地为其预期的目的发挥作用,例如在启动子中起始转录并前行通过编码区段到达终止子。也指这样一种状况:即线性dna序列的某些部分能够影响同一线性dna序列其它部分活性,例如,如果信号肽dna作为前提表达并参与多肽的分泌,那么信号肽(分泌前导序列)dna就是可操作地连接接于多肽dna;如果启动子控制序列转录,那么它是可操作地连接于编码序列;如果核糖体结合位点被置于能使其翻译的位置时,那么它是可操作地连于编码序列。一般,“可操作地连接”意味着相邻,而对于分泌前导序列则意味着在阅读框中相邻。优选的情况下,所述表达载体为质粒pesc-leu。
本发明的再一目的,在于提供一种宿主细胞,所述宿主细胞,包含本发明所述编码胆甾醇c22羟化酶或其变体的多核苷酸分子(或称ppcyp90b27基因或其变体),或在严谨条件下可与所述多核苷酸分子进行杂交的核苷酸分子,或包含本发明上述描述的表达载体。所述的宿主细胞选自:细菌、原核细胞(如大肠杆菌、)真菌细胞、酵母细胞、昆虫细胞、哺乳动物细胞或植物细胞,优选地,为酵母细胞或植物细胞。
特别有意义的酵母包括酿酒酵母、巴斯德毕赤酵母和pichiamethanolica。用外源dna转化酿酒酵母细胞和从其中制备重组多肽的方法公开在例如kawassaki,美国专利us4599311,us4931373、us4870008、us5037743、us4845075等中。通过选择标记所确定的表型,通常是药物抗性或在缺少特定养分(例如亮氨酸)时的生长能力,选择转化细胞。用于酿酒酵母的优选载体系统如可以是pesc表达载体。用于酵母的适宜启动子和终止子包括来自糖酵解基因(us4599311、us4615974和us4977092)和醇脱氢酶的那些。用于其它酵母,包括多形汉逊氏酵母、乳克鲁维氏酵母、脆壁克鲁维氏酵母、巴斯德毕赤酵母、pichiamethanolica、季也蒙氏毕赤酵母和麦芽糖假丝酵母的转化系统也是本领域已知的。
在本发明的技术方案中,所述的宿主细胞优选采用能稳定生产胆甾醇的酿酒酵母工程菌rh6829。本发明的另一方面在于公开上文所述ppcyp90b27基因在酿酒酵母发酵中的应用,具体可以应用于发酵工程合成甾体皂苷类生物合成中间体的制备。进一步,所述的甾体皂苷类生物合成中间体为22(r)-羟基胆甾醇。
根据常规方法在含有养分和其它对于所选宿主细胞的生长必须的成分的培养基中培养转化的或转染的宿主细胞。多种适宜的培养基,包括已知成分培养基和复杂培养基,是本领域已知的,一般包括碳源、氮源、必需氨基酸、维生素和矿物质。如果需要,培养基还可以含有诸如生长因子或血清这样的成分。生长培养基一般通过例如药物筛选或缺少可由表达载体携带的或共转染至宿主细胞中的选择标记补充的必需养分来选择含有外源添加dna的细胞。通过常规方式,如振摇小三角瓶或发酵罐喷气给液体培养物提供充足的空气。
本发明的胆甾醇c22羟化酶多核苷酸全长序列或其片段通常可以用pcr扩增法、重组法或人工合成的方法获得。对于pcr扩增法,可根据本发明所公开的有关核苷酸序列,尤其是开放阅读框序列来设计引物,并用市售的cdna库或按本领域技术人员已知的常规方法制备cdna库作为模板,扩增而得有关序列。当序列较长时,常常需要进行两次或多次pcr扩增,然后再讲各次扩增出的片段按正确次序拼接在一起。一旦获得了有关的序列,就可以用重组法来大批量地获得有关序列。这通常是将其克隆入载体,再转入细胞,然后通过常规方法从增殖后的宿主细胞中分离得到有关序列。此外,还可通过化学合成将突变体引入本发明蛋白序列中。除了用重组法产生之外,本发明蛋白的片段还可用固相技术,通过直接合成肽而加以生产(stewart等,solid-phasepedtidesynthesis,j.am.chem.soc.85:2149-2154,1963)。在体外合成蛋白质可以用手工或自动进行。例如,可以用appliedbiosystems的431a型肽合成仪(fostercity,ca)来自动合成肽。可以分别化学合成本发明蛋白的各片段,然后用化学方法加以连接以产生全长的分子。
本发明的又一方面,提供了本发明所述胆甾醇c22羟化酶、或本发明所述胆甾醇c22羟化酶编码基因、或本发明所述重组表达载体、或本发明所述工程菌,在合成22(r)-羟基胆甾醇中的运用。发酵培所得菌株2-3d后,用乙酸乙酯提取发酵菌,经gc-ms检测,可检测到22(r)-羟基胆甾醇。利用本发明可以通过生物合成技术来生成甾体皂苷生物合成中间体22(r)-羟基胆甾醇,具有很好的应用前景。
本发明的还一方面,提供了本发明所述胆甾醇c22羟化酶或编码本发明所述胆甾醇c22羟化酶基因,在含有甾体皂苷化学成分的植物育种中的运用。运用本发明所述胆甾醇c22羟化酶、或其编码基因,通过将其运用到植物细胞中,可改善植物体内甾体皂苷的含量。
本发明seqidno.1的dna序列由1455个碱基组成,最后三个tga为终止密码子,编码序列表中由484个氨基酸残基组成的蛋白质序列seqidno.2。
附图说明
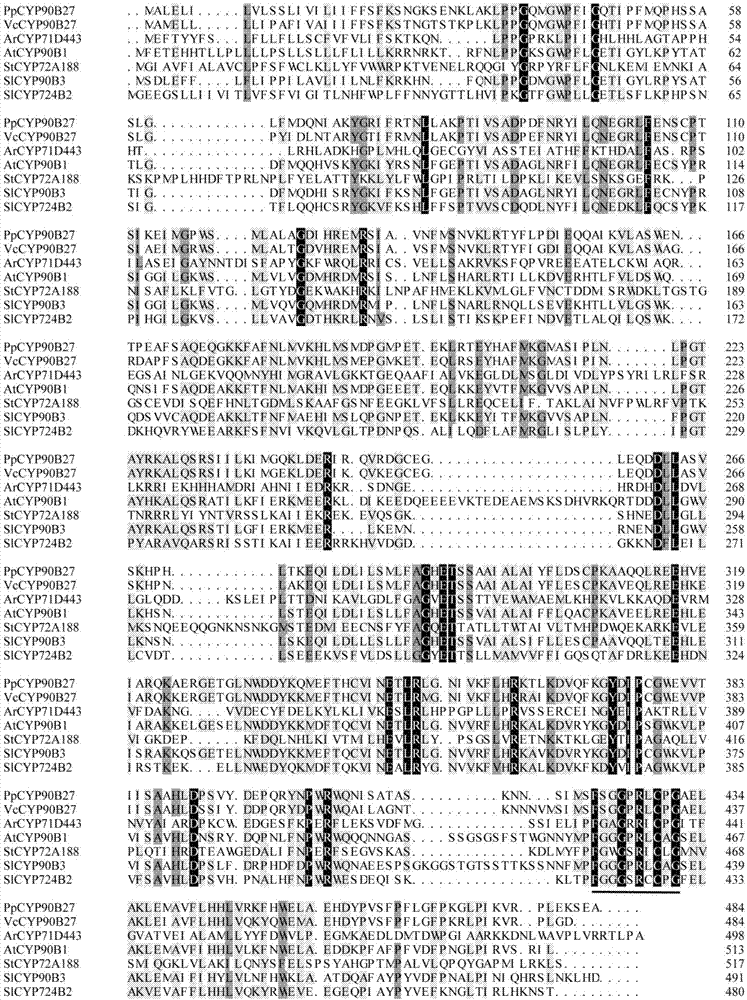
图1为ppcyp90b27与相关功能基因氨基酸水平的多重序列比对分析。arcyp71d443、atcyp90b1、stcyp72a188、slcyp90b3和slcyp724b2的氨基酸序列来自加州藜芦veratrumcalifornicum(ajt59559.1),筋骨草ajugareptans(bas30379.1),拟南芥arabidopsisthaliana(o64989.2),马铃薯solanumtuberosum(bav14872.1),番茄solanumlycopersicum(baf41219.1和baf41218.1)。使用dnamen8.0进行多重序列比对,细胞色素p450半胱氨酸血红素铁配体标签用下划线表示。
图2为ppcyp90b27系统进化树。该分析涉及氨基酸序列分别来自单子叶植物加州藜芦veratrumcalifornicum(ajt59559.1)、日本粳稻oryzasativajaponicagroup(q5cck3.1)、玉米zeamays(abs30431.1),和双子叶植物野大豆glycinesoja(khn36124.1)、木豆cajanuscajan(kyp66752.1)、蒺藜苜蓿medicagotruncatula(aet03943.2)、陆地棉gossypiumhirsutum(abj90340.1)、胡杨populuseuphratica(aer08630.1)、紫锥菊echinaceapurpurea(aih07328.1)和拟南芥arabidopsisthaliana(o64989.2)。进化分析在mega6中使用neighbor-joining方法进行,在分支旁边显示相关类群在自举测试中聚集在一起的重复树的百分比(1000次重复)。
图3为ppcyp90b27重组酵母与空载对照发酵产物gc色谱图,从上到下顺序依次为ppcyp90b27重组酵母、pesc-his空白对照、22(r)-胆甾醇对照品、22(s)-胆甾醇对照品,胆甾醇对照品。
具体实施方式
以下通过优选实施例并结合附图具体说明本发明的各个方面和特征,本领域的技术人员应该理解,这些实施例只是用于说明,而不是限制本发明的范围。在不背离权利要求书范围的条件下,本领域的技术人员可以对本发明的各个方面进行各种修改和改进,这些修改和改进也属于本发明的保护范围。例如,将实施例中所实用表达载体和宿主菌替换为本领域中常用的其它表达载体和宿主菌,是本领域的普通技术人员所能够理解并实现的。
下述实施例中所使用的实验方法如无特殊说明,均为常规方法。
下述实施例中所用的材料、试剂等,如无特殊说明,均可从商业途径得到。
实施例1滇重楼总rna提取、纯化
采用trizol法提取滇重楼根部总rna。利用rna纯化试剂盒(天根生化科技有限公司),对所提rna进行纯化。
实施例2滇重楼胆甾醇c22羟化酶基因的克隆
1.引物设计
根据滇重楼转录组数据注释筛选得到基因全长序列片段,设计上游和下游克隆引物,引物序列如下:
p1:5’atggcgttggagctgatcctggttct3’(seqidno:3)
p2:5’acagaccacataccataccagcctc3’(seqidno:4)
2.pcr扩增
利用quantscriptrtkit(天根生化科技有限公司)将实施例1所得rna反转录成cdna。
以cdna为模板,进行pcr扩增。
扩增体系为:2×kapahifihotstartreadymix25μl,引物p1和p2各1.5μl,模板2μl,双蒸水补足50μl。反应条件:98℃预变性3min,98℃20s,62℃退火15s,72℃延伸1.5min,35个循环后72℃延伸5min,4℃保存。
测序结果表明,pcr扩增产物的序列如seqidno.1所示,将序列1所示的基因命名为ppcyp90b27,此dna序列编码485个氨基酸组成的蛋白质,该蛋白命名为ppcyp90b27,该蛋白的氨基酸序列为seqidno.2。
实施例3ppcyp90b27基因的生物信息学分析
本发明涉及的滇重楼胆甾醇c22羟化酶基因ppcyp90b27的开放阅读框cdna序列长1455bp,编码氨基酸484aa,分子量(mw)54894.74da,理论等电点pi8.36,详细序列分别为序列表中的seqidno.1和seqidno:2。scanprositetool扫描结果显示该基因编码的蛋白序列在422-431aa的位置具有细胞色素p450半胱氨酸血红素铁配位体标记(fsggprlcpg),interproscan分析该序列属于细胞色素p450e家族i组,具有氧化还原酶活性。构建已知甾体类化合物c22位羟化酶的系统进化树(邻接法),结果表明,滇重楼ppcyp90b27(parispolyphylla)与同属于百合科加州藜芦的c22羟化酶(veratrumcalifornicum)的亲缘关系最近。如图1和图2。其中图1为ppcyp90b27与相关功能基因氨基酸水平的多重序列比对;图2为ppcyp90b27系统进化树(邻接法)。
实施例4ppcyp90b27基因酵母表达载体的构建
1.引物设计
以ppcyp90b27cdna为模板,设计特异性上游引物p3和下游引物p4,进行pcr扩增反应,引物中划线部分为载体pesc-leu(购自安捷伦科技)同源臂,引物序列如下:
p3:5’-tcactaaagggcggccgcatggcgttggagctgatcct-3’(seqidno:5)
p4:5’-atccttgtaatccatcgatactagttcaggcttctgacttctcgaggggac-3’(seqidno:6)
2.pcr扩增
pcr反应体系为:2×kapahifihotstartreadymix25μl,引物p3和p4各1.5μl,模板2μl,双蒸水补足50μl。
pcr反应条件:98℃预变性3min,98℃20s,70℃退火15s,72℃延伸1min,35个循环后72℃延伸5min,4℃保存。
3.载体双酶切
利用限制性内切酶noti和spei在37℃下酶切pecs-leu载体1小时。
4.载体连接
扩增产物和线性化质粒分别进行琼脂糖凝胶电泳后,利用dna凝胶回收试剂盒回收。线性化载体及目的片段胶回收产物以1:2的摩尔质量比混合,加入2×easygenoassemblymix50℃连接20min,转化大肠杆菌trans5α化学感受态细胞,在含有氨苄青霉素的lb平板上筛选重组子。含ppcyp90b27克隆的重组质粒经pcr鉴定和测序分析,保存具有正确目标序列的重组质粒pesc-ppcyp90b27用于表达转化,该原核表达载体命名为pesc-ppcyp90b27。
实施例4重组酿酒酵母内酶功能验证
1.重组酿酒酵母培养
目标质粒pesc-ppcyp90b27通过电击转化酿酒酵母工程菌rh6829感受态,sc-trp-his-leu缺陷培养基(含2%葡萄糖,购自北京泛基诺科技有限公司)筛选阳性菌株(rh6829-ppcyp90b27)。将阳性克隆(rh6829-ppcyp90b27)接种于sc-trp-his-leu缺陷培养基(含2%葡萄糖)中,30℃,230rpm振荡培养至od6000.8-1.0。4000×g离心收集菌体,以无菌水漂洗两次后,用ypl(1%酵母提取物,2%蛋白胨,2%半乳糖)重悬,30℃诱导发酵48h。
空载体质粒pesc-leu按照上述方法转化至酿酒酵母工程菌rh6829感受态细胞,同样条件下发酵培养,作为对照。
2.发酵产物提取
发酵液10000×g离心1min,收集菌体,加入乙酸乙酯10ml,超声提取2h,重复两次。合并提取液,n2吹干溶剂,加入200μlbstfa和100μl吡啶,涡旋复溶,80℃衍生化1h。n2吹干衍生化试剂,500μlchcl3复溶,过0.22μmptfe针孔滤膜。
3.发酵产物检测
取1μl提取液进gc-ms检测,以胆甾醇,22(s)-羟基胆甾醇和22(r)-羟基胆甾醇为标准品。gc条件为:180℃1min,以20℃/min升温至280℃,2℃/min升温至300℃,保持2℃/min。载气为氦气,流速为1.0ml/min。质谱采用mrm模式分段扫描,8min开始以15ev碰撞能量轰击m/z为329.1的前级离子,扫描产物离子121.1和95.1,10.7min开始以5ev碰撞能量轰击m/z为173.0的前级离子,扫描产物离子83.1和73.0,扫描驻留时间为150ms。结果发现胆甾醇保留时间为10.2min,22(s)-羟基胆甾醇和22(r)-羟基胆甾醇保留时间约在11.2min,其中22(s)-羟基胆甾醇的保留时间较22(r)-羟基胆甾醇提前约0.15min。如图3。图3为ppcyp90b27重组酵母与空载对照发酵产物gc色谱图。重组酵母发酵产物样品检测到胆甾醇和22(r)-羟基胆甾醇特征峰,而空载体对照样品中只检测到胆甾醇,没有检测到22(r)-羟基胆甾醇峰,因此认定ppcyp90b27具有催化胆甾醇合成22(r)-羟基胆甾醇的活性。
上述说明并非对本发明的限制,本发明也并不限于上述举例。本技术领域的普通技术人员在本发明的实质范围内,作出的变化、改型、添加或替换,也应属于本发明的保护范围,本发明的保护范围以权利要求书为准。
序列表
<110>首都医科大学
<120>滇重楼胆甾醇c22羟化酶及其编码基因和应用
<130>背景文献中
<141>2018-08-08
<160>6
<170>siposequencelisting1.0
<210>1
<211>1455
<212>dna
<213>人工序列()
<400>1
atggcgttggagctgatcctggttctgtcttccttgatcgtcatcctcatcatcttcttc60
agcttcaagagtaatgggaagagtgagaacaaattggccaagctcccaccgggccaaatg120
ggctggcccttcatcggccaaaccatccccttcatgcagccacactcctccgcctccctc180
ggcctcttcatggaccaaaacatagccaagtatgggaggatcttccggactaacttgctg240
gcgaagccgaccatcgtgtcagcggacccggacttcaaccggtacatcctgcagaacgag300
gggcggctgttcgagaacagctgccccacgagcatcaaggagatcatggggccgtggtcg360
atgctcgccctcgcgggcgacatccaccgcgagatgcgatccatcgcggtgaatttcatg420
agcaacgtcaagctccgaacctacttcctccctgacatcgagcagcaggccataaaggtc480
ctcgccagttgggagaacacccccgaggccttctcggcccaagaacaagggaagaagttt540
gcgttcaatctgatggtgaagcatctgatgagcatggatcccgggatgccggagactgag600
aaactgcggacggagtaccacgcattcatgaagggaatggcttcaattcctttgaatttg660
cccggaacggcttatagaaaggccttgcagtcgaggtcaataattttgaagatcatgggg720
caaaagctagacgaaagaattcggcaggtacgtgacgggtgcgagggattggagcaggat780
gatctcctcgcgtccgtctccaagcacccacacctcacaaaggagcagattctcgatctc840
atactcagcatgctcttcgccggtcacgagacttcctcggctgccatcgccctagctatc900
tattttctcgattcgtgccctaaagccgcccaacaattgagggaggagcacgtggagatc960
gcgcgacaaaaggctgagcgaggcgagacgggactcaattgggacgactacaagcaaatg1020
gagttcacccattgtgtcataaatgaaaccctaaggctcggaaacattgtcaagttcttg1080
cataggaaaactcttaaagatgtccaattcaaagggtatgacattccatgtgggtgggag1140
gtggtgacgatcatctcagccgctcatttggatccgtccgtgtatgatgaacctcagcgt1200
tacaatccatggagatggcagaatatctcggcgactgcatcaaagaacaacagcataatg1260
tcgttcagtggcggccctcgcttgtgccctggtgctgagctggcgaagctggagatggca1320
gtttttctgcaccatctcgtccgaaagttccactgggagctggcagagcatgactacccc1380
gtatctttccccttcctcggattccccaagggcctgccaatcaaggttcgtcccctcgag1440
aagtcagaagcctga1455
<210>2
<211>484
<212>prt
<213>人工序列()
<400>2
metalaleugluleuileleuvalleuserserleuilevalileleu
151015
ileilephepheserphelysserasnglylyssergluasnlysleu
202530
alalysleuproproglyglnmetglytrppropheileglyglnthr
354045
ileprophemetglnprohisserseralaserleuglyleuphemet
505560
aspglnasnilealalystyrglyargilepheargthrasnleuleu
65707580
alalysprothrilevalseralaaspproasppheasnargtyrile
859095
leuglnasngluglyargleuphegluasnsercysprothrserile
100105110
lysgluilemetglyprotrpsermetleualaleualaglyaspile
115120125
hisargglumetargserilealavalasnphemetserasnvallys
130135140
leuargthrtyrpheleuproaspilegluglnglnalailelysval
145150155160
leualasertrpgluasnthrproglualapheseralaglnglugln
165170175
glylyslysphealapheasnleumetvallyshisleumetsermet
180185190
aspproglymetprogluthrglulysleuargthrglutyrhisala
195200205
phemetlysglymetalaserileproleuasnleuproglythrala
210215220
tyrarglysalaleuglnserargserileileleulysilemetgly
225230235240
glnlysleuaspgluargileargglnvalargaspglycysglugly
245250255
leugluglnaspaspleuleualaservalserlyshisprohisleu
260265270
thrlysgluglnileleuaspleuileleusermetleuphealagly
275280285
hisgluthrserseralaalailealaleualailetyrpheleuasp
290295300
sercysprolysalaalaglnglnleuargglugluhisvalgluile
305310315320
alaargglnlysalagluargglygluthrglyleuasntrpaspasp
325330335
tyrlysglnmetgluphethrhiscysvalileasngluthrleuarg
340345350
leuglyasnilevallyspheleuhisarglysthrleulysaspval
355360365
glnphelysglytyraspileprocysglytrpgluvalvalthrile
370375380
ileseralaalahisleuaspproservaltyraspgluproglnarg
385390395400
tyrasnprotrpargtrpglnasnileseralathralaserlysasn
405410415
asnserilemetserpheserglyglyproargleucysproglyala
420425430
gluleualalysleuglumetalavalpheleuhishisleuvalarg
435440445
lysphehistrpgluleualagluhisasptyrprovalserphepro
450455460
pheleuglypheprolysglyleuproilelysvalargproleuglu
465470475480
lyssergluala
<210>3
<211>26
<212>dna
<213>人工序列()
<400>3
atggcgttggagctgatcctggttct26
<210>4
<211>25
<212>dna
<213>人工序列()
<400>4
acagaccacataccataccagcctc25
<210>5
<211>38
<212>dna
<213>人工序列()
<400>5
tcactaaagggcggccgcatggcgttggagctgatcct38
<210>6
<211>51
<212>dna
<213>人工序列()
<400>6
atccttgtaatccatcgatactagttcaggcttctgacttctcgaggggac51
- 还没有人留言评论。精彩留言会获得点赞!