确定癌症对卡仑尼替星敏感性的系统和方法与流程
相关申请的交叉引用本申请要求2017年3月29日提交的国际申请pct/cn2017/078548的优先权,其公开的全部内容通过引用并入本申请。发明领域本发明一般地涉及癌症治疗。
背景技术:
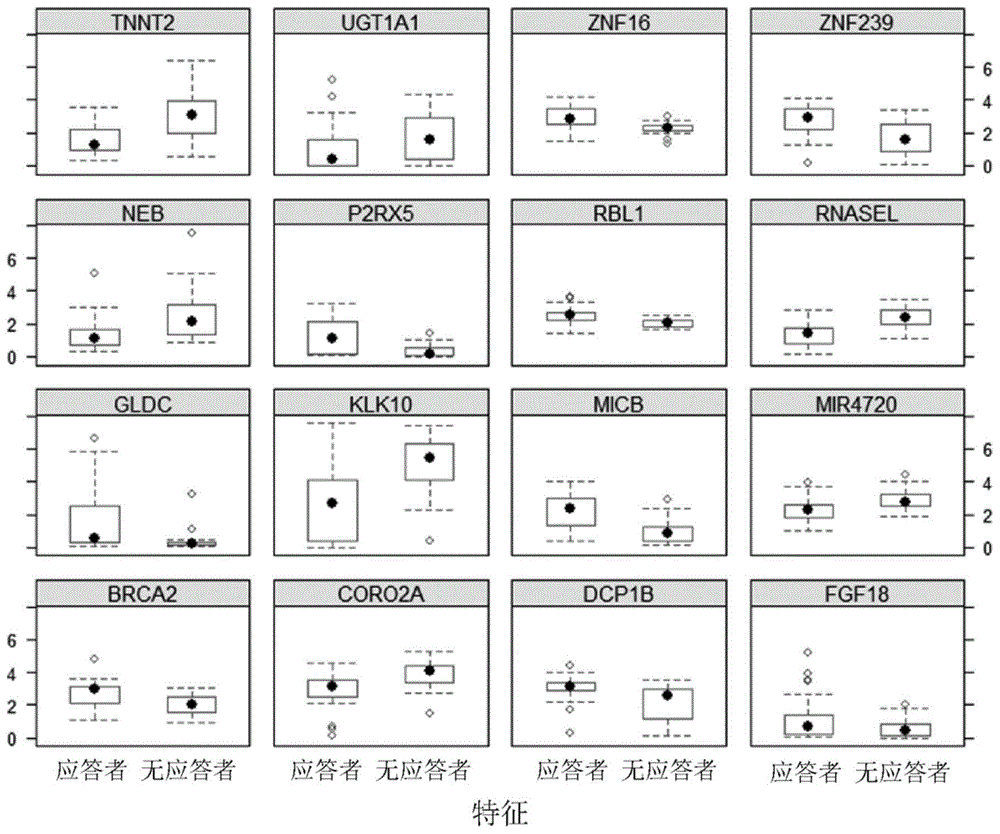
:对抗癌疗法的临床应答通常仅限于一部分患者。为了最大限度地提高抗癌疗法的效率,已提出了基于分子生物标记物的个体化化疗。然而,对于能够预测对癌症化疗应答的预测性生物标记物的鉴定仍是一项挑战。拓扑异构酶(拓扑异构酶i和ii)是通过在正常细胞周期中催化dna链的磷酸二酯骨架的断裂和重新连接来控制dna结构变化的酶。人dna拓扑异构酶i(top1)是在复制和转录过程中松弛dna超螺旋的必需酶。top1-dna中间体,称为裂解复合物,在正常情况下是短暂存在的并且处于低水平。然而,用top1抑制剂治疗会使可裂解复合物稳定,防止dna再连接并诱导致死的dna链断裂。近年来,拓扑异构酶已成为癌症化疗的流行靶标。已提出拓扑异构酶抑制剂阻断细胞周期的连接步骤,产生损害基因组完整性的单链和双链断裂,导致细胞凋亡和细胞死亡。喜树碱(一种top1抑制剂)及其衍生物是最近引入临床实践的最有效的抗癌剂。喜树碱衍生物拓扑替康(glaxosmithkline)被美国fda批准用于治疗卵巢癌和肺癌。另一种喜树碱衍生物伊立替康(cpt11)被批准用于治疗结肠癌。卡仑尼替星(karenitecin),也称为科西特康(cositecan),是与喜树碱有关的合成含硅剂。由于其具有亲脂性,与水溶性喜树碱相比,卡仑尼替星表现出增强的组织渗透性和生物利用度。卡仑尼替星目前正在进行针对晚期卵巢癌患者的国际iii期临床试验。与目前市售的喜树碱药物相比,卡仑尼替星的潜力在于副作用减少,疗效改善,对耐药性机制的敏感性较低以及安全性改善。根据之前的研究,卡仑尼替星的严重腹泻发生率低于市售喜树碱药物伊立替康(pfizer)引起的严重腹泻发生率,且贫血、中性粒细胞减少和血小板减少的发生率和严重程度低于市售喜树碱药物拓扑替康引起的相应副作用的发生率和严重程度。另一方面,先前的临床试验已经证明卡仑尼替星在广泛预处理的卵巢癌中的应答率低(kavanaghjj等人,intjgynecolcancer(2008)18(3):460-4)。因此,需要能够预测对卡仑尼替星应答的生物标记物。技术实现要素:在一个方面中,本公开内容提供了一种用于在癌症患者中预测卡仑尼替星敏感性的方法。在一个实施方式中,所述方法包括:测量在来自所述患者的肿瘤样本中一组生物标记物的rna表达水平,其中所述一组生物标记物包含至少6种基因,所述基因选自下组:micb、rnasel、tnnt2、brca2、p2rx5、rbl1、znf239、znf16、coro2a、neb、gldc、klk10、dcp1b、fgf18、mir4720和ugt1a1;将所述一组生物标记物的每种所检测到的rna表达水平与相应的预定参比水平进行比较;以及确定所述患者对卡仑尼替星具有应答的可能性。在一个实施方式中,所述一组生物标记物包括micb、rnasel、tnnt2、brca2、p2rx5和rbl1。在一个实施方式中,所述一组生物标记物包括micb、rnasel、tnnt2、brca2、p2rx5、rbl1、znf239和znf16。在一个实施方式中,所述一组生物标记物包含micb、rnasel、tnnt2、brca2、p2rx5、rbl1、znf239、znf16、coro2a、neb、gldc和klk10。在一个实施方式中,所述一组生物标记物包含micb、rnasel、tnnt2、brca2、p2rx5、rbl1、znf239、znf16、coro2a、neb、gldc、klk10、dcp1b、fgf18、mir4720和ugt1a1。在某些实施方式中,本申请所述的癌症是胃癌、肺癌或卵巢癌。在某些实施方式中,通过扩增测定、杂交测定、测序测定或阵列测量所述rna的表达水平。在一个实施方式中,通过计算设备的处理器执行所述方法的比较步骤。在一个实施方式中,通过计算设备的处理器执行所述方法的确定步骤。在一个实施方式中,所述确定步骤包括使用机器学习模型。在一个实施方式中,所述机器学习模型是梯度推进机模型。在一个实施方式中,本申请所述的方法还包括推荐向所述患者施用卡仑尼替星。本申请还提供了一种用于检测一组生物标记物的rna表达水平的试剂盒。在一个实施方式中,所述一组生物标记物包括至少6种基因,所述基因选自下组:micb、rnasel、tnnt2、brca2、p2rx5、rbl1、znf239、znf16、coro2a、neb、gldc、klk10、dcp1b、fgf18、mir4720和ugt1a1。本公开内容还提供了一种包括用于检测一组生物标记物的rna表达水平的探针的微阵列。在一个实施方式中,所述一组生物标记物包含至少6种基因,所述基因选自下组:micb、rnasel、tnnt2、brca2、p2rx5、rbl1、znf239、znf16、coro2a、neb、gldc、klk10、dcp1b、fgf18、mir4720和ugt1a1。在另一个方面中,本公开内容提供了一种存储有指令的非暂时性计算机可读介质。在一个实施方式中,所述指令在由处理器执行时使所述处理器:检索一组生物标记物的rna表达水平,所述一组生物标记物包含至少12种基因,所述基因选自下组:micb、rnasel、tnnt2、brca2、p2rx5、rbl1、znf239、znf16、coro2a、neb、gldc、klk10、dcp1b、fgf18、mir4720和ugt1a1,其中所述水平来自癌症患者的肿瘤样本;将所述一组生物标记物的每种的rna表达水平与相应的预定参比水平进行比较;以及确定所述患者对卡仑尼替星具有应答的可能性。在又一个方面中,本公开内容提供了一种在癌症患者中预测卡仑尼替星的敏感性的系统。在一个实施方式中,所述系统包括:体外诊断试剂盒,所述试剂盒包含用于检测一组生物标记物的rna表达水平的引物,所述一组生物标记物包含至少6种基因,所述基因选自下组:micb、rnasel、tnnt2、brca2、p2rx5、rbl1、znf239、znf16、coro2a、neb、gldc、klk10、dcp1b、fgf18、mir4720和ugt1a1;以及存储有指令的非暂时性计算机可读介质。在一个实施方式中,所述指令在由处理器执行时使所述处理器:检索使用所述体外诊断试剂盒检测的所述一组生物标记物的rna表达水平,将所述一组生物标记物的每种的rna表达水平与相应的预定参比水平进行比较,以及确定所述患者对卡仑尼替星具有应答的可能性。附图说明以下附图形成本说明书的一部分并且被包括以进一步说明本公开内容的某些方面。通过参考这些附图中的一个或多个结合本申请中呈现的具体实施方式的详细描述,可以更好地理解本公开内容。图1显示了对卡仑尼替星治疗的应答的基因表达水平分布。图2显示了对每个模型使用交叉验证统计法的平均roc、灵敏度和特异性。图3显示了基于测试数据集的每个模型的平均准确度和κ值。图4显示了基于测试数据集的每个模型的平均灵敏度和特异性。发明详述在对本公开内容更加详细的描述之前,应理解本公开内容不限于所描述的特定实施方式,并且其当然是可以改变的。还应理解本申请中使用的术语仅用于描述特定实施方式,并不旨在限制,因为本公开内容的范围仅由所附的权利要求限定。除非另有定义,本申请中使用的所有科技术语具有的含义与本公开所属领域普通技术人员通常理解的含义相同。虽然与本申请中所述的方法和材料类似或等价的任何方法和材料也可用于本公开内容的实践或试验,但是现在描述优选的方法和材料。在本说明书中引用的所有出版物和专利都通过引用并入本申请,相当于每篇单独的出版物或专利都特别地和单独地被指出通过引用并入,并且其通过引用并入本申请以公开和描述与所引用的出版物有关的方法和/或材料。所引用的任何出版物均在本申请提交日之前公开,并且不应被解释为承认本申请由于在先公开而没有资格早于这些公开。而且,所提供的公开日可能不同于实际的公开日,其可能需要单独确认。在阅读本公开后,对于本领域技术人员显而易见的是,本申请中所描述和解释的各个实施方式均具有离散的组成和特性,在不脱离本公开范围或主旨的前提下,可以容易地将其与任意其他若干实施方式的特性分离或者组合。任何所述的方法均可以所叙述的事件顺序或者逻辑上可能的任何其他顺序进行。定义提供下述定义以帮助读者理解。除非另有定义,否则本申请中使用的所有术语、符号和其他科学或医学术语旨在具有化学和医学领域的技术人员通常理解的含义。在一些情况下,为了清楚起见和/或为了便于参考而在本申请中定义了具有通常理解含义的术语,并且不应将本申请中包含的这种定义解释为表示与本领域通常理解的术语定义具有实质性差异。如在本申请中所使用的,单数形式“一(a)”、“一个(an)”和“该(the)”包括复数引用,除非上下文另有明示。术语“量”或“水平”指样品中的目标多核苷酸或目标多肽的量。这样的量可以以绝对值表示,即样品中多核苷酸或多肽的总量,或者以相对值表示,即样品中多核苷酸或多肽的浓度。如在本申请中所使用的,术语“癌症”指涉及异常细胞生长的任何疾病,并且包括影响身体中任何组织、器官或细胞的疾病的所有阶段和所有形式。该术语包括所有已知的癌症和肿瘤病况,无论其特征为恶性、良性、软组织或是实体,以及包括转移前和转移后癌症在内的所有阶段和分级的癌症。在通常情况下,癌症可以根据癌症位于或来源的组织或器官以及癌组织和细胞的形态来分类。如在本申请中所使用的,癌症类型包括但不限于急性淋巴细胞白血病(all)、急性髓性白血病、肾上腺皮质癌、肛门癌、星形细胞瘤、儿童小脑或脑、基底细胞癌、胆管癌、膀胱癌、骨肿瘤、脑癌、小脑星形细胞瘤、脑星形细胞瘤/恶性胶质瘤、室管膜瘤、成神经管细胞瘤、幕上原始神经外胚层肿瘤、视觉通路和下丘脑神经胶质瘤、乳腺癌、伯基特氏淋巴瘤、宫颈癌、慢性淋巴细胞白血病、慢性粒细胞白血病、结肠癌、肺气肿、子宫内膜癌、室管膜瘤、食管癌、尤因氏肉瘤、视网膜母细胞瘤、胃癌(胃癌)、胶质瘤、头颈癌、心脏癌、霍奇金淋巴瘤、胰岛细胞癌(内分泌胰腺)、卡波西肉瘤、肾癌(肾细胞癌)、喉癌、白血病、肝癌、肺癌、神经母细胞瘤、非霍奇金淋巴瘤、卵巢癌、胰腺癌、咽癌、前列腺癌、直肠癌、肾细胞癌(肾癌)、视网膜母细胞瘤、尤因肿瘤家族、皮肤癌、胃癌、睾丸癌、喉癌、甲状腺癌、阴道癌。值得注意的是,在本公开中,术语如“包含(comprise)”、“包含(comprised)”、“包含(comprising)”、“含有(contain)”、“含有(containing)”等具有美国专利法所赋予的含义;其是包容性的或开放式的并且不排除其他未列举的元素或方法步骤。术语如“基本上由……组成(consistingessentiallyof)”和“基本上由……组成(consistsessentiallyof)”具有美国专利法所赋予的含义;其允许包含不实质影响所要求保护发明的基本和新颖性特征的其他成分或步骤。术语“由……组成(consistsof)”和“由……组成(consistingof)”具有美国专利法所赋予的含义;即这些术语是封闭式的。如在本申请中所使用的,“细胞”可以是原核的或真核的。原核细胞包括,例如,细菌。真核细胞包括,例如,真菌、植物细胞和动物细胞。动物细胞(例如,哺乳动物细胞或人细胞)的类型包括,例如,来自循环/免疫系统或器官的细胞(例如,b细胞、t细胞(细胞毒性t细胞、自然杀伤t细胞、调节性t细胞、t辅助细胞)、自然杀伤细胞、粒细胞(例如,嗜碱性粒细胞、嗜酸性粒细胞、中性粒细胞和过度分泌的中性粒细胞)、单核细胞或巨噬细胞、红细胞(例如,网织红细胞)、肥大细胞、血小板或巨核细胞以及树突状细胞);来自内分泌系统或器官的细胞(例如,甲状腺细胞(例如,甲状腺上皮细胞、滤泡旁细胞)、甲状旁腺细胞(例如,甲状旁腺主细胞、嗜酸细胞)、肾上腺细胞(例如,嗜铬细胞)和松果体细胞(例如,松果腺细胞));来自神经系统或器官的细胞(例如,成胶质细胞(例如,星形胶质细胞和少突胶质细胞)、小胶质细胞、巨细胞神经分泌细胞、星状细胞、卜歇细胞和垂体细胞(例如,促性腺细胞、促皮质激素细胞、促甲状腺素细胞、促生长激素细胞和催乳激素细胞));来自呼吸系统或器官的细胞(例如,肺细胞(i型肺细胞和ii型肺细胞)、克拉拉细胞、杯状细胞和肺泡巨噬细胞);来自循环系统或器官的细胞(例如,心肌细胞和周细胞);来自消化系统或器官的细胞(例如,胃主细胞、壁细胞、杯状细胞、潘氏细胞、g细胞、d细胞、ecl细胞、i细胞、k细胞、s细胞、肠内分泌细胞、肠嗜铬细胞、apud细胞、肝细胞(例如,肝细胞和枯否细胞));来自表皮系统或器官的细胞(例如,骨细胞(例如,成骨细胞、骨细胞和破骨细胞)、牙细胞(例如,成牙骨质细胞和成釉细胞)、软骨细胞(例如,成软骨细胞和软骨细胞)、皮肤/毛发细胞(例如,毛细胞、角质形成细胞和黑素细胞(痣细胞))、肌肉细胞(例如,肌细胞)、脂肪细胞、成纤维细胞和肌腱细胞);来自泌尿系统或器官的细胞(例如,足细胞、肾小球旁细胞、肾小球内系膜细胞、肾小球外系膜细胞、肾近端小管刷状缘细胞和黄斑密度细胞)以及来自生殖系统或器官的细胞(例如,精子、支持细胞、间质细胞、卵子、卵母细胞)。细胞可以是正常的、健康细胞;或者患病或不健康的细胞(例如,癌细胞)。细胞还包括哺乳动物受精卵或干细胞,其包括胚胎干细胞、胎儿干细胞、诱导多能干细胞和成体干细胞。干细胞是一种能够经历细胞分裂周期同时保持未分化状态以及分化成特定细胞类型的细胞。干细胞可以是全能干细胞、多能(pluripotent)干细胞、多能(multipotent)干细胞、寡能干细胞和单能干细胞,其中的任何一种均可由体细胞诱导。干细胞还可以包括癌症干细胞。哺乳动物细胞可以是啮齿动物细胞,例如小鼠、大鼠、仓鼠细胞。哺乳动物细胞可以是兔类细胞,例如兔细胞。哺乳动物细胞还可以是灵长类细胞,例如人细胞。术语“互补性”是指核酸通过传统的watson-crick或其他非传统类型与另一核酸序列形成氢键的能力。互补性百分比指在核酸分子中能够与第二核酸序列形成氢键(例如,watson-crick碱基配对)的残基百分比(例如,10个中的5、6、7、8、9、10个为50%、60%>、70%>、80%>、90%和100%互补)。“完全互补”意指核酸序列的所有连续残基将与第二核酸序列中相同数量的连续残基氢键结合。在本申请中使用的“基本上互补”指在8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、30、35、40、45、50或更多核苷酸的区域中互补程度为至少60%、65%、70%、75%、80%、85%、90%、95%、97%、98%、99%或100%,或者指两个核酸在严格条件下杂交。术语“确定”、“评估”、“测定”、“测量”和“检测”可以互换使用,指定量和半定量测定。在意欲进行定量和半定量测定的情况下,可以使用短语目的多核苷酸或多肽的“水平测定”或“检测”目的多核苷酸或多肽。术语“基因产物”或“基因表达产物”指由基因编码的rna或蛋白。术语“杂交”指核酸分子优先在严格条件下与特定核苷酸序列结合、双螺旋化或杂交。术语“严格条件”指在其下探针将优先与其靶序列,并且以较小程度,或根本不与混合组群(例如,来自组织活检物的细胞裂解物或dna制备物)中的其他序列杂交的条件。“严格杂交”和“严格杂交洗涤条件”在核酸杂交背景下(例如,在阵列、微阵列、southern或northern杂交中)是序列依赖性的,并且在不同的环境参数下是不同的。对核酸杂交广泛的指导参见,例如,tijssenlaboratorytechniquesinbiochemistryandmolecularbiology—hybridizationwithnucleicacidprobesparti,ch.2,“overviewofprinciplesofhybridizationandthestrategyofnucleicacidprobeassays,”(1993)elsevier,n.y.。通常,将高度严格的杂交和洗涤条件选择为在所限定的离子强度和ph下比特定序列的热熔点(tm)低约5℃。tm是50%的靶序列与完全匹配的探针杂交的温度(在所限定的离子强度和ph下)。所选择的非常严格的条件将等于特定探针的tm。在southern或northern印迹中在阵列上或滤器上具有多于100个互补残基的互补核酸杂交严格杂交条件的实例是42℃,使用标准杂交溶液(参见例如,sambrookandrussellmolecularcloning:alaboratorymanual(3rded.)vol.1-3(2001)coldspringharborlaboratory,coldspringharborpress,ny)。高严格洗涤条件的实例是在72℃下在0.15mnacl中约15分钟。严格洗涤条件的实例是在65℃下在0.2×ssc中洗涤15分钟。通常,高严格洗涤之前进行低严格洗涤以除去背景探针信号。用于例如超过100个核苷酸的双螺旋的示例性中等严格洗涤条件为在45℃下在l×ssc中洗涤15分钟。用于例如超过100个核苷酸的双螺旋的低严格洗涤条件的实例为在40℃下在4×ssc至6×ssc中洗涤15分钟。术语“核酸”和“多核苷酸”可以互换使用,指任意长度核苷酸的聚合形式,其可以是脱氧核糖核苷酸或核糖核苷酸或者其类似物。多核苷酸可以具有任何三维结构,并且可以执行已知或未知的任何功能。多核苷酸的非限制性实例包括基因、基因片段、外显子、内含子、信使rna(mrna)、转移rna、核糖体rna、核酶、cdna、shrna、单链短或长rna、重组多核苷酸、分枝多核苷酸、质粒、载体、任意序列分离的dna、控制区、任意序列分离的rna、核酸探针和引物。核酸分子可以是线性的或环状的。术语“总存活”指从诊断时间或治疗开始时患者仍然存活的时间间隔。如在本申请中所使用的术语“预后(prognose)”或“预后(prognosing)”指预测或预报疾病或病况未来的进程或结果。术语“无进展存活”指从患者治疗到患者癌症进展或死亡的时间间隔,以先发生者为准。在通常情况下,“蛋白”是多肽(即,通过肽键将至少两个氨基酸彼此之间连接的串)。蛋白可以包括除氨基酸以外的部分(例如,可以是糖蛋白)和/或可以进行其他加工或修饰。本领域普通技术人员将意识到“蛋白”可以是由细胞产生的完整多肽链(具有或不具有信号序列),或者可以是其功能性部分。本领域普通技术人员还将意识到蛋白有时可以包括例如通过一个或多个二硫键连接的或者以其他方式结合的一条以上的多肽链。术语“推荐”或“建议”在治疗疾病的背景下指针对治疗干预(例如,药物疗法、辅助疗法等)和/或疾病管理提出特别适于患者的建议或推荐。在患者对癌症疗法的应答的背景下使用的术语“应答”、“临床应答”、“阳性临床应答”等可以互换使用,指对治疗产生的有利的患者应答,而不是不利的应答(即,不良事件)。在患者中,可以以多种临床参数表示有益的应答,包括可检测的肿瘤消失(完全应答,cr)、肿瘤尺寸缩小和/或癌细胞数减少(部分应答,pr)、肿瘤生长停滞(病情稳定,sd)、使可能导致肿瘤消退或排斥的抗肿瘤免疫应答增强;在一定程度上缓解与肿瘤相关的一种或多种症状;治疗后存活时间增加;和/或在治疗后的给定时间点死亡率降低。肿瘤尺寸和/或癌细胞数持续增加和/或肿瘤转移提示对治疗缺乏有益的应答。可以基于一个或多个终点评估药物在群体中的临床益处(即,其有效性)。例如,总应答率(orr)的分析将在使用药物治疗后经历cr或pr的那些患者分类为应答者。病情控制(dc)的分析将在使用药物治疗后经历cr、pr或sd的那些患者分类为应答者。可以使用指示对患者有益的任何终点来评估阳性临床应答,包括但不限于:(1)在一定程度上抑制肿瘤生长,包括减缓和使生长完全停滞;(2)减少肿瘤细胞数量;(3)缩小肿瘤尺寸;(4)抑制(即,减少、减慢或完全阻止)肿瘤细胞浸润进入相邻外周器官和/或组织;(5)抑制转移;(6)使可能导致肿瘤消退或排斥的抗肿瘤免疫应答增强;(7)在一定程度上缓解与肿瘤相关的一种或多种症状;(8)治疗后存活时间增加;和/或(9)在治疗后的给定时间点死亡率降低。还可以用多种临床结果指标表示阳性临床应答。还可以在个体结果相对于具有可比较的临床诊断的患者群体结果背景下考虑阳性临床结果,以及可以使用多种终点进行评估,如无复发间隔(rfi)持续时间的增加,与在群体中的总存活(os)相比的存活时间增加,无病存活(dfs)时间增加,远端无复发间隔(drfi)持续时间增加等。其他终点包括任何无事件(ae)存活的可能性、无转移性复发(mr)存活(mrfs)的可能性、无病存活(dfs)的可能性、无复发存活(rfs)的可能性、首次进展(fp)的可能性和无远端转移存活(dmfs)的可能性。阳性临床应答的可能性增加与癌症再发生或复发的可能性降低相对应。如在本申请中所使用的术语“标准对照”指在已建立的正常组织样品(例如,健康的、非癌组织样品,或二倍体、非转化的、非癌、基因组稳定的健康人细胞系)中存在的预定量或浓度的多核苷酸序列或多肽序列。标准对照值适用于本发明的方法以作为比较待测样品中存在的特定mrna或蛋白的量的基准。作为标准对照的已建立的样品提供了在正常组织样品中通常存在的特定mrna或蛋白的平均量。标准对照值可以根据样品的性质以及其他因素如建立这种对照值所基于的受试对象的性别、年龄和种族而改变。如在本申请中所使用的,术语“受试对象”指人或任何非人动物(例如,小鼠、大鼠、兔、犬、猫、牛、猪、绵羊、马或灵长类)。人包括产前和产后形式。在很多实施方式中,受试对象是人。受试对象可以是患者,指呈现给医疗提供者以诊断或治疗疾病的人。术语“受试对象”在本申请中可以与“个体”或“患者”互换使用。受试对象可能患有或易患某种疾病或病症,但是可能已显示出或尚未显示出疾病或病症的症状。术语“肿瘤样品”包括生物样品或来自含有一种或多种肿瘤细胞的生物来源的样品。生物样品包括来自体液(例如,血液、血浆、血清或尿液)的样品,或者细胞、组织或器官衍生(例如,通过组织活检)的样品,优选疑似包括或基本上由癌细胞组成的肿瘤组织。术语“治疗(treatment)”、“治疗(treat)”或“治疗(treating)”指减轻癌症(例如,乳腺癌、肺癌、卵巢癌等)的影响或癌症的症状的方法。因此,在所公开的方法中,治疗可以指将癌症或癌症症状的严重程度降低10%、20%、30%、40%、50%、60%、70%、80%、90%或100%。例如,如果与对照相比受试对象疾病的一种或多种症状减轻10%,则认为治疗疾病的方法是治疗。因此,减轻可以是与自然或对照水平相比减少10%、20%、30%、40%、50%、60%、70%、80%、90%、100%或者减少10至100%之间的任意百分比。应当理解的是,治疗不一定是指治愈或者疾病、病况或疾病或病况的症状的完全消除。用于预测对卡仑尼替星应答的生物标记物本申请所述的方法和组合物部分地基于一组生物标记物的发现,这组生物标记物的表达与在癌症患者中的卡仑尼替星敏感性相关。在一个方面中,本公开内容提供了用于在癌症患者中预测对卡仑尼替星应答的方法。在某些实施方式中,所述方法包括:测量在来自所述患者的肿瘤样本中的一组生物标记物的表达水平,其中所述一组生物标记物包含至少6种基因,所述基因选自下组:micb、rnasel、tnnt2、brca2、p2rx5、rbl1、znf239、znf16、coro2a、neb、gldc、klk10、dcp1b、fgf18、mir4720和ugt1a1;将所述一组生物标记物的每种所检测到的表达水平与相应的预定参比水平进行比较;以及确定所述患者对卡仑尼替星具有应答的可能性。在一些情况下,在使用卡仑尼替星对患者治疗前进行测量。人mhci类多肽相关序列b(micb)mrna(编码)序列如下所示:例如ncbiref.seq.no.nm_001289160。人micb多肽序列如下所示:例如ncbiref.seq.no.np_001276089。人核糖核酸酶l(rnasel)mrna(编码)序列如下所示:例如ncbiref.seq.no.nm_021133。人rnasel多肽序列如下所示:例如ncbiref.seq.no.np_066956。人tnnt2mrna(编码)序列如下所示:例如ncbiref.seq.no.kr709931。人tnnt2多肽序列如下所示:例如ncbiref.seq.no.aki70313。人乳腺癌易感性(brca2)mrna(编码)序列如下所示:例如ncbiref.seq.no.u43746。人brca2多肽序列如下所示:例如ncbiref.seq.no.aab07223。人p2rx5mrna(编码)序列如下所示:例如ncbiref.seq.no.kj891740。人p2rx5多肽序列如下所示:例如ncbiref.seq.no.aic49327。人视网膜母细胞瘤相关蛋白转录共抑制因子样1(rbl1)mrna(编码)序列如下所示:例如ncbiref.seq.nos.nm_002895、nm_183404、nm_001323281和nm_001323282。人rbl1多肽序列如下所示:例如ncbiref.seq.nos.np_002886、np_899662、np_001310210和np_001310211。人锌指蛋白239(znf239)mrna(编码)序列如下所示:例如ncbiref.seq.nos.nm_005674、nm_001099282、nm_001099284、nm_001099283、nm_001324347、nm_001324348、nm_001324349、nm_001324350、nm_001324351、nm_001324352和nm_001324353。人znf239多肽序列如下所示:例如ncbiref.seq.nos.np_005665、np_001092752、np_001092754、np_001092753、np_001311276、np_001311277、np_001311278、np_001311279、np_001311280、np_001311281和np_001311282。人锌指蛋白16(znf16)mrna(编码)序列如下所示:例如ncbiref.seq.nos.nm_006958和nm_001029976。人znf16多肽序列如下所示:例如ncbiref.seq.nos.np_008889和np_001025147。人冠蛋白2a(coro2a)mrna(编码)序列如下所示:例如ncbiref.seq.nos.nm_003389和nm_052820。人coro2a多肽序列如下所示:例如ncbiref.seq.nos.np_003380和np_438171。人伴肌动蛋白(neb)mrna(编码)序列如下所示:例如ncbiref.seq.nos.nm_003389、nm_001164508、nm_004543和nm_001271208。人neb多肽序列如下所示:例如ncbiref.seq.nos.np_001157979、np_001157980、np_004534和np_001258137。人甘氨酸脱羧酶(gldc)mrna(编码)序列如下所示:例如ncbiref.seq.no.nm_000170。人gldc多肽序列如下所示:例如ncbiref.seq.no.np_000161。人激肽释放酶相关的肽酶10(klk10)mrna(编码)序列如下所示:例如ncbiref.seq.nos.nm_002776、nm_145888和nm_001077500。人klk10多肽序列如下所示:例如ncbiref.seq.nos.np_002767、np_665895和np_001070968。人脱帽mrna1b(dcp1b)mrna(编码)序列如下所示:例如ncbiref.seq.nos.nm_152640和nm_001319292。人dcp1b多肽序列如下所示:例如ncbiref.seq.no.np_689853和np_001306221。人成纤维细胞生长因子18(fgf18)mrna(编码)序列如下所示:例如ncbiref.seq.no.nm_003862。人fgf18多肽序列如下所示:例如ncbiref.seq.no.np_003853。人微小rna4720(mir4720)序列如下所示:例如ncbiref.seq.no.nr_039871。人udp葡糖醛酸基转移酶家族1成员a1(ugt1a1)mrna(编码)序列如下所示:例如ncbiref.seq.no.nm_000463。人ugt1a1多肽序列如下所示:例如ncbiref.seq.no.np_000454。对rna水平进行定量的方法本公开内容的方法包括在来自疑似患有癌症或具有患癌风险患者的肿瘤样品中测量预测生物标记物至少一个子集的rna表达水平,例如16个基因中的至少6个基因、至少7个基因、至少8个基因、至少9个基因、至少10个基因、至少11个基因、至少12个基因、至少13个基因、至少14个基因和至少15个基因的子集。在一些实施方式中,患者已被确诊患有癌症。肿瘤样品可以是含有癌细胞的生物样品。在一些实施方式中,肿瘤样品是从肿瘤获得的新鲜或存档的样品,例如通过肿瘤组织活检或细针抽吸获得的。样品还可以是含有癌细胞的任意生物液体。肿瘤样品可以从任意数量的原发肿瘤中分离或获得,包括但不限于乳腺、肺、前列腺、脑、肝、肾、小肠、结肠、脾、胰腺、胸腺、睾丸、卵巢、子宫等的肿瘤。在一些实施方式中,肿瘤样品来自肿瘤细胞系。通常在医院或诊所中根据标准方法(例如,在组织活检过程中)从受试对象中采集肿瘤样品。可以采用本领域普通技术人员公知的任何方法测量rna表达水平。在一些实施方式中,从肿瘤样品中分离rna。可以使用多种方法从肿瘤样品中分离rna。例如在ausubel等人,currentprotocolsofmolecularbiology(1997)johnwiley&sons和sambrookandrussell,molecularcloning:alaboratorymanual3rded.(2001)中描述了从组织或细胞中提取rna的标准方法。还可以使用市售试剂盒(例如,minicolumns(qiagen)、rna微量试剂盒(thermofisherscientific)等)分离rna。可以通过多种方法检测或测量上文所述预测生物标记物的rna(例如,mrna)表达水平,所述方法包括但不限于:扩增测定、杂交测定、测序测定或阵列。此类方法的非限制性实例包括逆转录聚合酶链式反应(rt-pcr);定量实时pcr(qrt-pcr);定量pcr,如northern印迹;原位杂交测定;微阵列分析,例如来自nanostringtechnologies的微阵列;基于多重杂交的测定,例如来自panomics的quantigene2.0多重测定;基因表达的系列分析(sage);cdna介导的退火、选择、延伸和连接;直接测序或焦磷酸测序;大规模平行测序;二代测序;高效液相色谱(hplc)片段分析;毛细管电泳等等。可以使用涉及扩增反应和/或其中探针与固体支持物连接并用于rna定量的反应的各种方法。或者,可以将rna与固体支持物连接并使用探针对目标序列进行定量。在某些实施方式中,通过高通量测序(例如,全转录组鸟枪测序(rna测序))测量上文所述预测生物标记物的rna表达情况。已对rna测序方法进行了描述(参见wangz,gersteinmandsnyderm,naturereviewgenetics(2009)10:57-63;maherca等人,nature(2009)458:97-101;kukurbak&montgomerysb,coldspringharborprotocols(2015)2015(11):951-969)。在一些实施方式中,首先将靶rna逆转录并将所得到的cdna定量。在一些实施方式中,使用rt-pcr或其他定量扩增技术对靶rna进行定量。使用pcr扩增cdna是熟知的方法(参见美国专利4,683,195和4,683,202;pcrprotocols:aguidetomethodsandapplications(innis等人编著,1990))。在例如美国专利号6,180,349;6,033,854和5,972,602,以及在例如gibson等人,genomeresearch(1996)6:995-1001;degraves等人,biotechniques(2003)34(1):106-10,112-5;deimanb等人,molbiotechnol.(2002)20(2):163-79中公开了定量扩增的方法。用于确定样品中目标mrna水平的替代方法可以涉及其他核酸扩增方法,如连接酶链式反应(barany,proc.natl.acad.sci.usa(1991)88:189-193)、自持序列复制(guatelli等人,proc.natl.acad.sci.usa(1990)87:1874-1878)、转录扩增系统(kwoh等人,proc.natl.acad.sci.usa(1989)86:1173-1177)、q-β复制酶(lizardi等人,biotechnology(1988)6:1197)、滚环复制(美国专利号5,854,033)或任意其他核酸扩增方法,随后采用本领域技术人员熟知的技术对扩增分子进行检测。在通常情况下,定量扩增基于在扩增(例如,pcr)反应循环中监测代表模板拷贝数的信号(例如,探针的荧光)。检测扩增产物的一种方法是5-3’核酸外切酶“水解”pcr测定(也称为测定)(美国专利号5,210,015和5,487,972;holland等人,pnasusa(1991)88:7276-7280;lee等人,nucleicacidsres.(1993)21:3761-3766)。该测定通过在扩增反应期间杂交和切割双标记荧光探针(探针)检测特定pcr产物的累积情况。荧光探针由使用荧光报告染料和淬灭剂染料标记的寡核苷酸组成。在pcr过程中,当且仅当与扩增片段杂交时,这种探针才能给被dna聚合酶的5’-核酸外切酶活性所切割。探针的切割使得报告染料的荧光强度增加。依赖于使用能量转移的检测扩增产物的另一种方法是由tyagi和kramer,naturebiotech.(1996)14:303-309描述的“信标探针”法,其也是美国专利号5,119,801和5,312,728的主题。这种方法使用能够形成发夹结构的寡核苷酸杂交探针。杂交探针(5’或3’末端)的一端具有供体荧光团,另一端具有受体部分。在tyagi和kramer方法的情况下,该受体部分是淬灭剂,即受体吸收由供体释放的能量,但其本身不发荧光。因此,当信标处于开放构象时,供体荧光团的荧光是可检测的,而当信标处于发夹(闭合)构象时,供体荧光团的荧光被淬灭。当在pcr中使用时,与pcr产物的一条链杂交的分子信标探针处于“开放构象”并且检测到荧光,而其余未杂交的那些将不发荧光(tyagiandkramer,naturebiotechnol.(1996)14:303-306)。结果,荧光的量将随着pcr产物的量的增加而增加,因此可以将其作为评价pcr进程的指标。本领域技术人员将意识到也可以使用其他定量扩增方法。进行核酸定量扩增的各种其他技术也是已知的。例如,一些方法学采用一种或多种探针寡核苷酸,构建所述探针寡核苷酸以使得当寡核苷酸与靶核酸杂交时产生荧光变化。例如,一个此类方法涉及利用荧光共振能量转移(fret)的双荧光团方法,例如lightcyclertm杂交探针,其中两个寡核苷酸探针对扩增子退火。将寡核苷酸设计成以头对尾的方向与荧光团杂交,寡核苷酸与荧光团之间间隔能够进行有效能量转移的距离。当与核酸结合或嵌入延伸产物时被构造成发出信号的标记寡核苷酸的其他实例包括:scorpionstm探针(例如,whitcombe等人,naturebiotechnology(1999)17:804-807,和美国专利号6,326,145)、sunrisetm(或amplifluortm)探针(例如,nazarenko等人,nuc.acidsres.(1997)25:2516-2521,和美国专利号6,117,635)以及形成不需要淬灭剂就能导致信号减弱和当与靶点杂交时发射信号增强的二级结构的探针(例如,lux探针tm)。在其他实施方式中,可以使用当插入双链dna时产生信号的嵌入剂。示例性的试剂包括sybrgreentm和sybrgoldtm。由于这些试剂不具有模板特异性,因此假定信号是基于模板特异性扩增产生的。可以通过监测作为温度的函数的信号对其进行确证,因为模板序列的熔点通常将比例如引物-二聚体等高得多。在其他实施方式中,将mrna固定在固体表面上并与探针接触,例如以点印记或northern形式。在一个替代实施方式中,将探针固定在固体表面上并将mrna与探针接触,例如在基因芯片阵列中。本领域技术人员可以容易地调整已知的mrna检测方法,以用于检测编码生物标记物或其他目标蛋白的mrna水平。在一些实施方式中,例如使用微阵列。dna微阵列提供了一种用于同时测量大量基因表达水平的方法。每个阵列由附着于固体支持物的可重复模式的捕获探针组成。将标记的rna或dna与阵列上互补的探针杂交,然后通过激光扫描进行检测。确定对阵列上每个探针的杂交强度并将其转化成表示相对基因表达水平的定量值。参见美国专利号6,040,138、5,800,992、6,020,135、6,033,860和6,344,316。高密度寡核苷酸阵列特别适用于确定样品中大量rna的基因表达谱。在例如美国专利号5,384,261中描述了使用机械合成法合成这些阵列的技术。尽管通常采用平面阵列表面,但是可以将阵列制造在几乎任何形状的一个表面上或者甚至多个表面上。阵列可以是在小珠、凝胶、聚合物表面、纤维(如光导纤维)、玻璃或任何其他合适基质上的肽或核酸,参见美国专利号5,770,358、5,789,162、5,708,153、6,040,193和5,800,992。可以以这种方式对阵列进行包装以使得能够对所包装的装置进行诊断或其他操作。在一些实施方式中,在杂交测定中使用基因特异性探针和/或引物以检测rna表达。可以使用任何可检测的部分或化合物(如放射性同位素、荧光团、化学发光剂和酶)对探针和/或引物进行标记。可以使用熟知的技术合成和标记实施本发明所必需的探针和引物。作为探针和引物使用的寡核苷酸可以是根据beaucage和caruthers,tetrahedronletts.(1981)22:1859-1862首先描述的固相亚磷酰胺三酯法,使用needham-vandevanter等人,nucleicacidsres.(1984)12:6159-6168中所描述的自动合成仪化学合成的。在一些实施方式中,该方法还包括检测一个或多个参比基因的表达水平,所述参比基因能够作为对照以确定表达水平。此类基因通常以较高水平组成型表达,并且能够作为用于确定准确基因表达水平估计值的参比。对照基因的非限制性实例包括arpc2、atf4、atp5b、b2m、cdh4、celf1、clta、cltc、copb1、ctbp1、cyc1、cyfip1、dazap2、dhx15、dimt1、eef1a1、flot2、gapdh、gusb、hadha、hdlbp、hmbs、hnrnpc、hprt1、hsp90ab1、mtch1、myl12b、naca、ndufb8、pgk1、ppia、ppib、ptbp1、rpl13a、rplp0、rps13、rps23、rps3、s100a6、sdha、sec31a、set、sf3b1、sfrs3、snrnp200、stard7、sumol、tbp、tfrc、tmbim6、tpt1、tra2b、tuba1c、ubb、ubc、ube2d2、ube2d3、vamp3、xpol、ythdcl、ywhaz和18srrna基因。因此,确定目标基因的rna表达水平(例如,预测生物标记物组的基因表达水平)还可以包括确定上文所公开的一个或多个参比基因的表达水平。可以将本申请所述的每种生物标记物的mrna表达水平归一化至对照基因的参比水平。可以预先确定、同时确定或者在从受试对象中获得样品后确定对照值。可以在相同测定中检测标准品,或者可以是来自此前测定的已知标准品。在通过rna测序确定rna表达水平的情况下,可以将每种生物标记物的rna表达水平归一化至测序的总读数。可以将生物标记物基因归一化的mrna表达水平转化为评分,例如使用本申请所述的方法和模型。对蛋白水平进行定量的方法在一些实施方式中,本申请公开的方法包括确定由生物标记物基因组的至少一个子集编码的多肽水平。可以采用本领域普通技术人员公知的任何方法检测蛋白表达水平。可以在harlow&lane,antibodies:alaboratorymanual(1988)和harlow&lane,usingantibodies(1999)中找到适用技术的一般概述。生产与等位基因变体特异性反应的多克隆和单克隆抗体的方法是本领域技术人员公知的(参见例如,coligan,currentprotocolsinimmunology(1991);harlow&lane,出处同上;goding,monoclonalantibodies:principlesandpractice(第二版,1986);以及kohler&milstein,nature(1975)256:495-497)。此类技术包括通过从噬菌体或类似载体中的重组抗体文库中选择抗体制备抗体,以及通过免疫接种兔或小鼠制备多克隆和单克隆抗体(参见例如,huse等人,science(1989)246:1275-1281;ward等人,nature(1989)341:544-546)。可以通过多种方法检测此类多肽的水平,包括但不限于:western印迹、免疫测定(例如,酶联免疫吸附测定(elisa)、酶免疫测定(eia)、放射免疫测定(ria))、夹心测定、竞争性测定、免疫组化、质谱、2-d凝胶电泳、蛋白阵列、抗体阵列等。关于免疫学和免疫测定方法的综述,参见basicandclinicalimmunology(stites&terreds.,第七版,1991)。而且,可以以几种构型中的任意一种进行免疫测定,在enzymeimmunoassay(maggio,ed.,1980);以及harlow&lane,出处同上,中对其进行了广泛综述。对于一般免疫测定的综述,还参见methodsincellbiology:antibodiesincellbiology,第37卷(asai,ed.1993);basicandclinicalimmunology(stites&terr,eds.,第七版,1991)。与将生物标记物基因的mrna水平归一化类似,也可以对蛋白表达水平进行比较并归一化至标准品的对照值。预测对卡仑尼替星应答的方法在测量生物标记物组的表达水平之后,本申请公开的方法包括确定患者对卡仑尼替星产生应答的可能性。在某些实施方式中,可以基于使用机器学习技术的模型确定可能性,如偏最小二乘法(wolds等人,plsformultivariatelinearmodeling,inhvandewaterbeemd(ed.),chemometricmethodsinmoleculardesign,pp.195–218.vch,weinheim)、弹性网络(zouh等人,regularizationandvariableselectionviatheelasticnet,journaloftheroyalstatisticalsociety,seriesb(2005)67(2):301–320)、支持向量机(vapnikv)、随机森林(breimanl)、神经网络(bishopc,neuralnetworksforpatternrecognition(1995)oxforduniversitypress,oxford)以及梯度推进机(friedmanj,greedyfunctionapproximation:agradientboostingmachine,annalsofstatistics(2001)29(5),1189-1232)。在一种情况下,基于使用梯度推进机的模型确定可能性。如在本申请中所使用的,“机器学习”指计算机实现技术,该技术使计算机系统能够利用数据逐步改进对特定任务的性能,即从数据中学习,而无需明确编程。机器学习技术采用可以通过从样本输入建立模型(即,使用数学概念的系统描述)来学习和预测数据的算法。机器学习的核心目的是从经验中推广,即在经历学习数据集之后准确地执行新数据。在生物医学诊断或预后的背景下,机器学习技术通常涉及监督学习过程,在该过程中向计算机呈现示例输入(例如,基因表达标记)及其所需的输出(例如,应答性)以学习将输入映射到输出的一般规则。可以在一般化过程中采用不同模型(即,假设)。为了在一般化中获得最佳性能,假设的复杂性应与数据潜在功能的复杂性相匹配。计算机实现的方法、系统和设备本申请所述的任何方法可以用包括一个或多个处理器的计算机系统完全或部分地执行,可以将该计算机系统设置为执行这些步骤。因此,实施方式涉及被设置为执行本申请所述任何方法的步骤的计算机系统,其可能具有执行相应步骤或相应步骤组的不同组件。尽管表示为编号的步骤,但是本申请方法的步骤可以同时或以不同顺序执行。另外,可以将这些步骤的一部分与来自其他方法的其他步骤的一部分一起使用。而且,步骤的全部或部分是可选的。可以用模块、电路或用于执行这些步骤的其他装置来执行任何方法的任何步骤。本申请提及的任何计算机系统可以使用任何适宜数量的子系统。在一些实施方式中,计算机系统包括单一计算机设备,其中子系统可以是计算机设备的组件。在其他实施方式中,计算机系统可以包括多个计算机设备,每个计算机设备是具有内部组件的子系统。子系统可以通过系统总线互连。附加子系统包括,例如,打印机、键盘、存储设备、与显示适配器耦合的监视器等。耦合到i/o控制器的外围和输入/输出(i/o)设备可以通过本领域公知的任何方式连接到计算机系统,如串行端口。例如,串行端口或外部接口(例如,以太网、wi-fi等)可以用于将计算机系统连接到广域网(如因特网)、鼠标输入装置或扫描仪。通过系统总线的互连能够使中央处理器与每个子系统连接,以控制来自系统存储器或存储设备(例如,固定磁盘,如硬盘驱动器或光盘)的指令的执行,以及子系统之间的信息交换。系统存储器和/或存储设备可以体现为计算机可读介质。本申请提及的任何数据均可以从一个组件传输到另一个组件并且可以输出给用户。计算机系统可以包括多个相同的组件或子系统,例如通过外部接口或通过内部接口连接到一起。在一些实施方式中,计算机系统、子系统或设备可以通过网络连接。在这种情况下,可以将一台计算机视为客户端,另一台计算机作为服务器,其中每台计算机均可以是同一计算机系统的一部分。客户端和服务器分别可以包括多个系统、子系统或组件。应当理解的是,本公开内容的任何实施方式可以使用硬件(例如,专用集成电路或现成可编程门阵列)和/或使用具有通常是模块化或集成化方式的可编程处理器的计算机软件以控制逻辑形式实现。如在本申请中所使用的,处理器包括在同一集成芯片上的多核处理器,或在单个电路板上或网络上的多个处理单元。基于本申请提供的公开和教导,本领域普通技术人员将知道并理解使用硬件以及硬件和软件的组合来实现本公开内容的实施方式的其他方式和/或方法。本申请所述的任何软件组件或功能可以由使用例如常规或面向对象技术的任意适宜计算机语言(例如,java、c++或perl)的处理器以软件代码的形式执行而实现。软件代码可以作为一系列指令或命令存储在计算机可读介质上以用于存储和/或传输,适宜的介质包括随机存取存储器(ram)、只读存储器(rom)、磁介质(如硬盘或软盘)或光学介质(如光盘(cd)或dvd(数字多用光盘))、闪存等。计算机可读介质可以是这种存储或传输设备的任意组合。还可以使用适于经由符合包括因特网在内的各种协议的有线、光学和/或无线网络传输的载波信号来编码和传输此类程序。这样,可以使用利用此类程序编码的数据信号来创建根据本发明实施方式的计算机可读介质。用程序代码编码的计算机可读介质可以与兼容设备一起打包或者与其他设备分开提供(例如,通过因特网下载)。任意此类计算机可读介质可以存在于单一计算机产品(例如,硬盘驱动器、cd或整个计算机系统)之上或之中,或者可以存在于系统或网络中的不同计算机产品之上或之中。计算机系统可以包括监视器、打印机或其他适宜的显示器,以便向用户提供本申请提及的任何结果。试剂盒和微阵列在另一方面,本公开内容提供了用于上文所述方法中的试剂盒。试剂盒可以包含执行本申请所述方法的任意或全部试剂。在此类应用中,试剂盒可以包括下述中的任意或全部:测定试剂、缓冲液、与本申请所述的至少一种基因结合的核酸、杂交探针和/或引物、与由本申请所述的基因编码的至少一种多肽特异性结合的抗体或其他部分等。此外,试剂盒可以包括与参比基因或参比多肽特异性结合的试剂,如核酸、杂交探针、引物、抗体等。如在本申请中所使用的术语“试剂盒”在检测试剂背景下旨在指多种基因表达产物检测试剂的组合,或者一种或多种基因表达产物检测试剂与一种或多种其他类型的元件或组件的组合(例如,其他类型的生化试剂、容器、包装(如用于商业销售的包装)、附着有基因表达产物检测试剂的基质、电子硬件组件等)。在一些实施方式中,本公开内容提供了附着在固体支持物(如阵列载玻片或芯片)上的寡核苷酸探针,例如在eds.,bowtellandsambrookdnamicroarrays:amolecularcloningmanual(2003)coldspringharborlaboratorypress中所描述的。这种设备的构建是本领域熟知的,例如在下述美国专利和专利公开中所描述的:美国专利号5,837,832;pct申请w095/11995;美国专利号5,807,522;美国专利号7,157,229、7,083,975、6,444,175、6,375,903、6,315,958、6,295,153和5,143,854,2007/0037274、2007/0140906、2004/0126757、2004/0110212、2004/0110211、2003/0143550、2003/0003032和2002/0041420。还在下述参考文件中综述了核酸阵列:biotechnolannurev(2002)8:85-101;sosnowski等人,psychiatrgenet(2002)12(4):181-92;heller,annurevbiomedeng(2002)4:129-53;kolchinsky等人,hum.mutat(2002)19(4):343-60以及mcgail等人,advbiochemengbiotechnol(2002)77:21-42。微阵列可以由大量独特的、单链多核苷酸组成,其通常是固定在固体支持物上的合成反义多核苷酸或cdna片段。典型多核苷酸优选长度约6-60个核苷酸,更优选长度约15-30个核苷酸,以及最优选长度约18-25个核苷酸。对于某些类型的阵列或其他检测试剂盒/系统,使用长度仅为约7-20个核苷酸的寡核苷酸可能是优选的。在其他类型的阵列中,如与化学发光检测技术结合使用的阵列,优选的探针长度可以是例如长度约15-80个核苷酸,优选长度约50-70个核苷酸,更优选长度约55-65个核苷酸,以及最优选长度约60个核苷酸。此外,试剂盒可以包括含有为实施本申请所述的方法而提供的指导的说明材料(即,方案)。尽管说明材料通常包括书面或印刷材料,但其不限于此。本发明涉及能够存储这些说明并将其传送给终端用户的任何介质。此类介质包括但不限于电子存储介质(例如,磁盘、磁带、卡带、芯片)、光学介质(例如,cdrom)等。此类介质可以包括提供此类说明材料的网站地址。提供下述实施例以更好地说明要求保护的发明,而不应将其解释为限制本发明的范围。以下描述的所有具体组合物、材料和方法全部或部分地落入本发明的范围内。这些具体的组合物、材料和方法并非旨在限制本发明,而仅仅是为了说明落入本发明范围的具体实施方式。本领域技术人员可以在不脱离本发明范围的情况下开发出等同的组合物、材料和方法,而无需创造性能力。应当理解的是,可以在本申请所述程序中做出多种变化,同时其仍保持在本发明范围内。发明人的意图是此类变化包括在本发明范围内。实施例1该实施例显示了在来源于患者的异种移植瘤(pdx)模型中对预测对卡仑尼替星应答的生物标记物的鉴定。材料和方法在本研究中使用了8种癌症的48个pdx模型的队列。这些模型使用卡仑尼替星治疗了两周。计算肿瘤生长抑制(tgi)以及auc(曲线下面积)中值之比,后者是一种新开发的用于评价药物疗效的指标(表1)。可以根据tgi以及auc中值之比将这些模型分成两个类别。31个模型对卡仑尼替星治疗有应答(auc<0.5且tgi>0.8)和17个模型对卡仑尼替星治疗无应答(auc>0.5且tgi<0.6)。使用rna-seq测量移植物中的基因组范围内的基因表达水平。除去表达水平较低或表达水平变化较小的基因。然后将归一化的表达水平作为输入用于特征选择和建模过程。基于基因表达水平与药物应答的相关性,选择16个基因构建用于预测对卡仑尼替星治疗的应答目的的模型。建模方案包括下述步骤:以80%:20%的比例将48个pdx模型随机分成训练数据集和测试数据集;将训练数据集用于构建模型,基于10倍交叉验证进行模型调整和模型选择,重复5次性能指标;将测试数据集用于评价模型性能。我们将上述建模方案重复10次,以获得对我们16个基因预测模型准确度的可靠估计。结果基于基因表达水平与对卡仑尼替星治疗应答的相关性,我们选择了16个基因构建预测模型。基因名称及其mann-whitneyu检验相应的p值列于表2中。每种基因的基因表达水平(log2(fpkm+1))对药物应答的箱线图如图1中所示。使用最先进的机器学习技术,如偏最小二乘法、弹性网络、支持向量机、随机森林、神经网络和梯度推进机,基于测试数据集构建了共计14个模型。从10个独立建模运行的平均性能来看,梯度推进机(gbmfit)模型在准确度、κ值、灵敏度和选择性方面是突出的。更具体地,gbmfit模型在10个独立的测试数据集上实现了0.93的平均准确度、0.92的平均灵敏度和0.97的平均选择性(表3,图2,图3,图4)。我们还根据micb、rnasel、tnnt2、brca2、p2rx5、rbl1、znf239、znf16、coro2a、neb、gldc、klk10的排名,使用选自16种基因的1-12种基因构建gbmfit模型。这些模型的准确度如表4所示。表1:48个pdx模型的tgi,auc中值之比表2:标记中包括的16个基因的符号和mann-whitneyu检验的p值表3:最佳模型的平均性能指标统计表4.使用1-12种基因的gbmfit模型的准确度基因数123456789101112准确度0.5920.64130.6970.7210.7670.79430.8010.83170.83670.84070.8370.8497虽然已经参考特定实施方式(其中的一些是优选实施方式)具体示出和描述了本公开内容,但是本领域技术人员应当理解的是,在不脱离本申请公开的宗旨和本公开内容范围的前提下可以对其形式和细节做出各种改变。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1