一种基于5’连接的单链DNA特异的高通量测序方法
本发明属于生物,具体涉及一种基于5’连接的单链dna特异的高通量测序方法。
背景技术:
1、高通量测序技术(high-throughput sequencing)是对传统sanger测序(称为一代测序技术)革命性的改变,一次对几十万到几百万条核酸分子进行序列测定,因此也称为下一代测序技术(next generation sequencing,ngs,二代测序技术)。高通量测序技术迅猛发展,解析并鉴定了许多人类和动植物正常和致病性状的基因,从全基因组的层面了解到前所未知的生物遗传和发育学问题。
2、许多研究表明,多种dna相关的生物学过程都会产生单链dna,最近发现人血浆中也有游离单链dna的存在。为了探索单链dna的生物学意义,开发出对其特异、灵敏且稳定的测序方法无疑是十分必要。目前已经报道的测序方法都无法特异区分样品中的单链dna与双链dna,从而无法特异性针对单链dna进行测序。
3、高通量测序技术的流程一般可分为四步,测序流程的第一步是dna文库制备,文库制备是在不同目的dna的两端引入测序接头,为后续步骤做准备的过程。文库制备决定了整个测序流程的走向,是各种测序方法有所差异的根源。为特异性针对单链dna进行测序,制备文库的方法仍有待改进。
技术实现思路
1、本发明旨在建立一套高度特异、稳定且灵敏的单链dna高通量测序技术。具体地,本发明提供了以下技术方案:
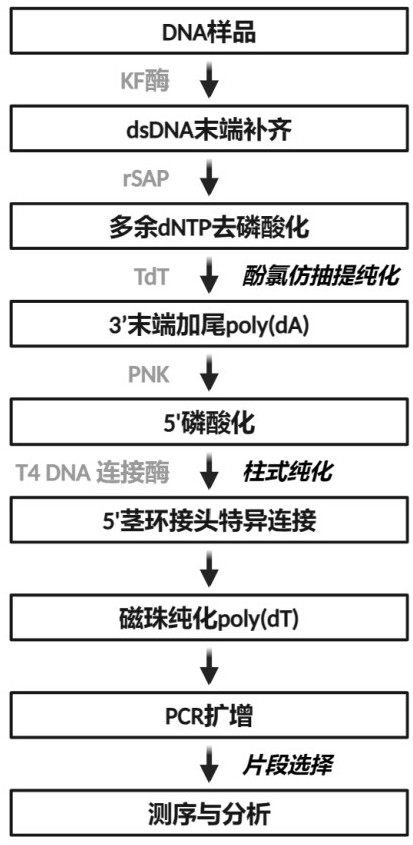
2、一方面,本发明提供了一种制备基于5’末端连接的单链dna测序文库的方法,所述方法包括以下对待测样本处理的步骤:
3、步骤1)使用不含外切酶活性的dna聚合酶补齐双链dna 5’末端;
4、步骤2)3’末端加尾;
5、步骤3)连接复性处理的5’茎环接头,所述5’茎环接头的结构是:突出末端-随机碱基区-第一茎区-环区-第二茎区,所述第一茎区与第二茎区通过复性形成双螺旋结构(形成双链);
6、步骤4)对连接产物进行扩增。所述扩增的产物构成单链dna测序文库。
7、具体地,所述不含外切酶活性是指不含5’→3’外切酶活性和/或3’→5’外切酶活性。
8、优选地,所述不含外切酶活性的dna聚合酶的用量不受限制,在任意浓度下均可以充分补齐5’突出末端,具体例如0.25 -1.5 u/µl。
9、优选地,所述不含外切酶活性的dna聚合酶包括kf酶(klenow fragment-3'→5'exo-)。
10、具体地,所述kf酶是大肠杆菌dna聚合酶i的n端截短片段,不含5’→3’外切酶活性,也不含3’→5’外切酶活性。
11、优选地,步骤2)中具体包括去磷酸化处理、dna纯化后进行加尾的步骤。
12、优选地,所述去磷酸化处理是使用重组虾碱性磷酸酶shrimp alkalinephosphatase (rsap)实现的,可以去除体系中的dntp的影响。
13、优选地,所述dna纯化的方法是本领域所常规熟知的,例如具体实施例中使用酚氯仿异戊醇进行纯化。
14、优选地,所述加尾也即添加poly(da)尾,或者是添加poly(dt)尾、poly(dc)尾和poly(dg)尾。
15、优选地,所述加尾所使用的试剂可以是末端转移酶和datp,从而添加poly(da)尾。
16、优选地,所述末端转移酶是tdt。具体地,所述tdt的中文名称为末端脱氧核糖核酸转移酶,英文名称为terminal deoxynucleotidyl transferase,是一种非模板依赖的dna聚合酶,可以催化在寡核苷酸、单链或双链dna的3’羟基端加上dntp。
17、优选地,所述步骤2)的反应体系中datp/dna的摩尔配比可以根据体系中dna总量进行调整,例如大于100或100-5000,所述datp/dna的配比具体例如100、500、1000、5000,皆有良好的加尾效果。
18、优选地,所述5’茎环接头的5’末端是羟基。
19、优选地,所述5’茎环接头的5’末端与3’末端均为羟基,且不含修饰。
20、优选地,所述第一茎区与第二茎区互补配对,通过不同碱基的对应关系互相以氢键相连形成茎区,通过复性形成双螺旋结构,从而使5’茎环接头形成茎环结构。
21、优选地,所述互补配对包括至少75%、80%、85%、90%、95%或完全的互补。
22、优选地,所述随机碱基区的长度为1-12nt,
23、优选地,所述随机碱基区的长度为6nt。
24、优选地,所述突出末端的长度为0-20nt,具体包括0、1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20nt;更优选为12nt。
25、优选地,所述第一茎区或第二茎区的长度为8-25nt,具体包括8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25nt;更优选为11nt。
26、优选地,所述第一茎区与第二茎区的长度可以相同或不同。
27、优选地,所述环区的长度为0-50nt,具体包括0、1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50nt;更优选为38nt。
28、同时,所述环区中还可以设置分子标签,例如n10。
29、优选地,所述5’茎环接头具有seq id no.1所示序列。
30、优选地,所述5’茎环接头/dna的摩尔配比大于12.5:1,更优选地大于50:1,最优选为50:1或大于50:1。其中,所述dna即为步骤2)处理后得到的dna。
31、优选地,所述步骤3)中还包括对dna 5’末端进行磷酸化处理从而提高连接效果的步骤。具体可以使用t4多聚核苷酸激酶t4 polynucleotide kinase。优选地,磷酸化处理后还进行纯化处理。
32、优选地,所述5’茎环接头连接是通过t4 dna连接酶实现的。
33、优选地,所述步骤3)所述复性指变性dna在适当条件下,二条互补链全部或部分恢复到天然双螺旋结构的过程。在dna热变性后,将温度缓慢降低而使dna逐渐冷却,并维持在低于tm值的一定范围内,变性后的单链dna即可恢复双螺旋结构,所述复性也称退火。
34、优选地,所述步骤4)中扩增前,还包括纯化单链dna连接产物的步骤。
35、优选地,当加尾是添加poly(da)尾时可以使用oligo d(t)25磁珠进行纯化。
36、优选地,所述步骤4)中扩增中可以采用包含标签序列(index)的引物。通过使用包含标签序列的引物对连接产物进行扩增,可以区分测序中不同的样品来源的数据,识别样品来源。
37、具体地,所述“标签序列”可以引入到步骤3)连接产物的5’端,也可以引入到步骤3)连接产物的3’端。所述标签序列的设计方法是本领域技术人员所常规熟知的,设计包含标签序列(index)的引物也是本领域技术人员所常规熟知的。
38、本发明所述“扩增”可分为变温扩增和恒温扩增两大类。变温扩增主要包括经典的聚合酶链式反应(polymerase chain reaction,简称pcr)和连接酶链式反应(ligasechain reaction,简称lcr),而恒温扩增包括链置换扩增(strand displacementamplification,简称sda)、滚环扩增(rolling circle amplification,简称rca)、环介导扩增(loop mediated amplification,简称lamp)、依赖解旋酶恒温扩增(helicase-dependent isothermal dna amplification,简称hda)、依赖核酸序列的扩增(nucleicacid sequence based amplification,简称nasba)、转录依赖的扩增系统(transcription-based amplification system,简称tas)。具体实施例中以pcr为例进行建库。
39、另一方面,本发明提供了一种单链dna高通量测序的方法,所述方法包括根据前述方法制备文库,并对所述测序文库进行测序的步骤。
40、优选地,所述测序可以通过包括illumina novaseq,hiseq x ten, illuminahiseq, illumina miseq、pacbio sequel、10× genomics及mgiseq-2000在内的高通量测序平台进行。
41、另一方面,本发明提供了一种制备基于5’末端连接的单链dna测序文库的装置,所述装置包括:5’突出末端的补齐单元、3’末端加尾单元、5’茎环接头的连接单元和扩增单元。
42、优选地,所述5’突出末端的补齐单元,用于使用不含外切酶活性的dna聚合酶补齐dsdna5’末端。
43、优选地,所述3’末端加尾单元,用于向3’末端加尾,优选加poly(da)。
44、优选地,所述5’茎环接头的连接单元,用于连接5’茎环接头,所述5’茎环接头的结构是:突出末端-随机碱基区-第一茎区-环区-第二茎区,所述第一茎区与第二茎区通过复性形成双螺旋结构。
45、优选地,所述随机碱基区的长度为6nt,所述突出末端的长度为12nt,所述第一茎区或第二茎区的长度为11nt,所述环区的长度为38nt。
46、在本发明中,所使用的术语“dna”可以是任何包含脱氧核糖核苷酸的聚合物,包括但不限于经过修饰的或者未经修饰的dna。本领域的技术人员可以理解,基因组dna的来源不受特别限制,可以从任何可能的途径获得,可以是通过市售直接获得,也可以是从其他实验室直接获取,还可以是直接从样本中提取的。根据本发明实施例,所述单链dna分子可以通过对rna进行逆转录而获得的。根据本发明一个实施例,所述单链dna分子可以是通过对rna进行逆转录而获得的cdna分子。根据本发明实施例,所述单链dna分子是可以通过对双链dna样本进行变性而获得的。根据本发明一个具体实施例,所述单链dna分子可以是通过对双链dna样本进行热变性而获得的。本发明所述单链dna的量不受特别限制,本发明所述单链dna分子的长度不受特别限制,优选大于20nt的单链dna,优选地20-80、80-100 nt的单链dna,具体包括20、40、79、80nt。
47、可选地,所述单链dna分子可以是通过对rna进行逆转录而获得的;可选地,所述单链dna分子可以是通过对rna进行逆转录而获得的cdna分子;可选地,所述单链dna分子可以是由目标待测样本中提取而获得的。优选地,所述待测样本包括取自于动物(尤其是人)的外周血、组织、血液、血清、血浆、尿液、唾液、精液、乳汁、脑脊髓液、泪液、痰、粘液、淋巴、胞液、腹水、胸膜积液、羊水、膀胱冲洗液和支气管肺泡灌洗液等;所述待测样本也可以取自细菌培养物、细菌菌落、病毒悬液、环境浓缩物、粮食、原料、水样或水浓缩物等。所述待测样本中含有单链dna分子,也可以含有其他非目标核酸。所述待测样本中含有至少1 fmol的单链dna分子。
- 还没有人留言评论。精彩留言会获得点赞!