控制装置以及机器学习装置的制作方法
本发明涉及输送机的控制装置以及机器学习装置,尤其涉及将输送机控制成能够在没有引起输送物的落下或撞击,洒落、变形、位置偏移的范围更高速地将输送物进行输送的输送机的控制装置以及机器学习装置。
背景技术:
以往,使用传送带或自动输送车等输送机来输送物品。例如,在日本特开2017-065877号公报和日本特开平10-194456号公报中公开了利用传送带来输送物品的输送机。此外,在日本特开平07-061422号公报、登录实用新型第2594275号公报和日本特开2016-069050号公报中公开了对填充了液体的容器进行输送的输送机。并且,在日本特开平09-156497号公报中公开了对工厂内的货物进行输送的自动输送车。
一般情况下,若想要高速地将输送物进行输送,则在加减速时对输送物施加了较强的撞击,或在输送物是注入了液体的容器时液体洒落,或在输送物是易碎的物体时该输送物的形状崩溃,或在输送物是堆积的物体时输送物崩溃,或输送物从装载位置发生偏移。因此,在以往的输送机中,设定适当的输送速度后将输送物进行输送,以便不使输送物发生上述那样的不良。
另一方面,有时根据输送物的输送状态,适当加速/减速来对输送速度进行调整,由此可以更高速地对输送物进行输送。例如,在输送物的输送机上的装载状态或当前位置、因输送机而输送物处于上坡这样状态的情况下,有时即使向更高的速度加速输送物的状态也不会发生不良。但是,在现有技术中,由于没有这样进行考虑了输送物的状态的动态的速度调整,因此存在无法实现充分的输送速度的高效化。
技术实现要素:
因此,本发明的目的在于提供一种将输送机控制成能够在不对输送物引起不良的范围内更高速地对输送物进行输送的控制装置以及机器学习装置。
本发明的控制装置以机器学习针对输送机输送的输送物的状态的输送机的输送动作的控制,根据机器学习的结果,将输送机的输送动作控制成在不对输送物产生不良的范围内更高速地对输送物进行输送,由此来解决上述课题。
本发明的一方式的控制装置控制将输送物进行输送的输送机,所述控制装置具有具有:机器学习装置,其学习针对输送物的状态的输送机的输送动作的控制。并且,该机器学习装置具有:状态观测部,其观测表示所述输送机的输送动作的状态的输送动作数据以及表示所述输送物的状态的输送物状态数据作为表示环境的当前状态的状态变量;判定数据取得部,其取得表示所述输送物的输送速度的适当与否判定结果的输送速度判定数据以及表示输送物的状态变化的适当与否判定结果的输送物状态判定数据作为判定数据;以及学习部,其使用所述状态变量和所述判定数据,将所述输送动作数据与所述输送物状态数据关联起来进行学习。
所述输送动作数据还可以包含所述输送物的姿势变更的状态。
所述状态观测部还观测表示所述输送机或者所述输送物的位置的输送位置数据作为状态变量。
所述状态观测部还观测表示所述输送物的性质的输送物性质数据作为状态变量。
所述学习部具有:回报计算部,其求出与所述适当与否判定结果相关的回报;以及价值函数更新部,其使用所述回报,来更新表示针对所述输送物的状态的所述输送机的输送动作的价值的函数。
所述学习部可以通过多层结构来运算所述状态变量和所述判定数据。
所述机器学习装置还具有:决策部,其根据所述学习部的学习结果,输出决定所述输送机的输送动作的控制的指令值。
所述学习部使用针对多个所述控制装置的每一个获得的所述状态变量和所述判定数据,来学习该多个控制装置的每一个中的所述输送机的输送动作的控制。
所述机器学习装置存在于云服务器。
本发明的一方式的机器学习装置学习将输送物进行输送的输送机的输送动作中的、针对所述输送物的状态的所述输送机的输送动作的控制,其中,所述机器学习装置具有:状态观测部,其观测表示所述输送机的输送动作的状态的输送动作数据以及表示所述输送物的状态的输送物状态数据作为表示环境的当前状态的状态变量;判定数据取得部,其取得表示所述输送物的输送速度的适当与否判定结果的输送速度判定数据以及表示输送物的状态变化的适当与否判定结果的输送物状态判定数据作为判定数据;以及学习部,其使用所述状态变量和所述判定数据,将所述输送动作数据与所述输送物状态数据关联起来进行学习。
本发明的一方式的已学习模型,使计算机发挥如下功能:输出将输送物进行输送的输送机的输送动作中的、针对所述输送物的状态的所述输送机的输送动作的控制行为的选择价值,其中,所述已学习模型包含:价值函数,其针对根据输送动作数据以及输送物状态数据定义的环境的状态,输出在该环境的状态下能够选择的所述输送机的输送动作的控制行为的选择价值,其中,输送动作数据是表示所述输送机的输送动作的状态的数据,输送物状态数据是表示所述输送物的状态的数据。并且,所述价值函数是根据在预定环境的状态下执行预定的所述输送机的输送动作的控制行为时的所述输送物的输送速度的适当与否判定结果以及所述输送物的状态变化的是否与否判定结果,来学习所述预定环境的状态下的所述预定的控制行为的选择价值的函数。并且,该已学习模型使计算机发挥如下功能:使用所述价值函数,以环境的状态和所述输送机的输送动作的控制行为为输入来进行运算,并根据运算结果输出针对该环境的状态的所述输送机的输送动作的控制行为的价值。
所述价值函数通过多层结构的神经网络被安装。
本发明的一方式的蒸馏模型,使计算机发挥如下功能:输出将输送物进行输送的输送机的输送动作中的、针对所述输送物的状态的所述输送机的输送动作的控制行为的选择价值,,其中,所述蒸馏模型包含:价值函数,其是针对根据输送动作数据以及输送物状态数据定义的环境的状态,学习从该已学习模型输出的该环境的状态下能够选择的所述输送机的输送动作的控制行为的选择价值的函数,其中,输送动作数据是表示输入到其他已学习模型的所述输送机的输送动作的状态的数据,输送物状态数据是表示所述输送物的状态的数据。并且,使计算机发挥如下功能:使用所述价值函数,以环境的状态和所述输送机的输送动作的控制行为为输入来进行运算,并根据运算结果输出针对该环境的状态的所述输送机的输送动作的控制行为的价值。
通过本发明可以将输送机的输送动作控制成能够在不对输送物引起不良的范围内更高速地对输送物进行输送。
附图说明
图1是第一实施方式涉及的输送机的控制装置的概略硬件结构图。
图2是第一实施方式涉及的输送机的控制装置的概略功能框图。
图3是表示输送机的输送动作的状态的示例的图。
图4是表示输送机的控制装置的一方式的概略功能框图。
图5是表示机器学习方法的一方式的概略流程图。
图6a是说明神经元的图。
图6b是说明神经网络的图。
图7是第二实施方式涉及的输送机的控制装置的概略功能框图。
图8是表示组入了输送机的控制装置的系统的一方式的概略功能框图。
图9是表示组入了输送机的控制装置的系统的其他方式的概略功能框图。
图10是例示控制装置控制的输送机的图。
图11是例示控制装置控制的输送机的图。
图12是例示控制装置控制的输送机的图。
图13是例示控制装置控制的输送机的图。
图14是例示控制装置控制的输送机的图。
图15是例示控制装置控制的输送机的图。
图16是例示控制装置控制的输送机的图。
具体实施方式
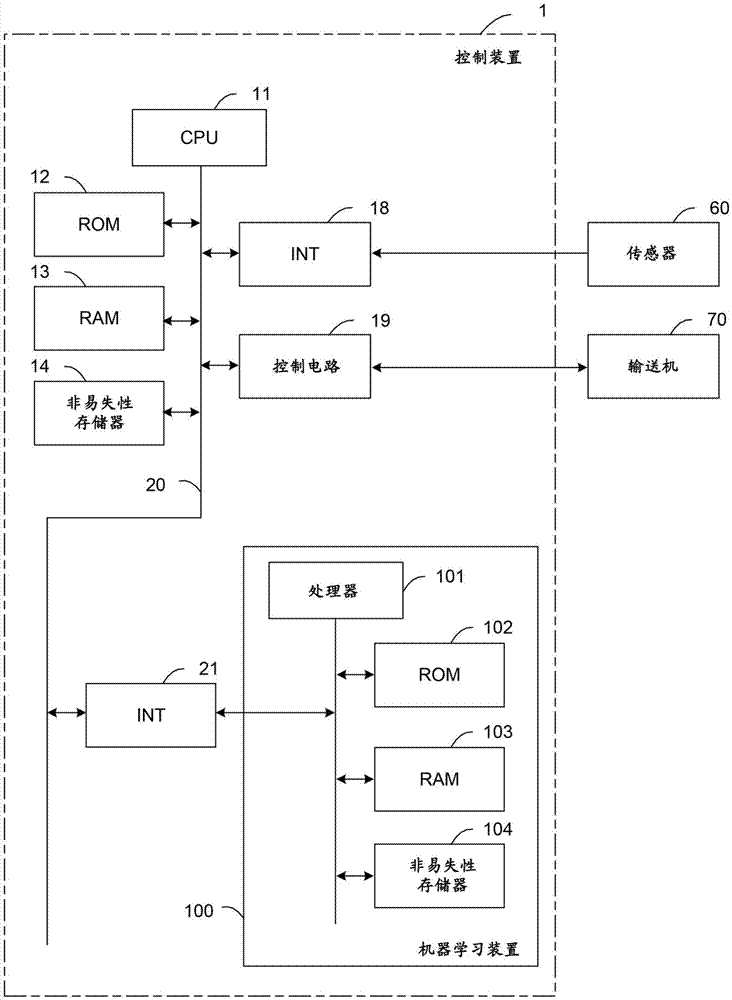
图1是表示第一实施方式涉及的、输送机的控制装置的主要部分的概略硬件结构图。
输送机的控制装置1例如可以作为对将输送物进行输送的传送带(未图示)或输送填充了液体的容器、包装物等的机械(未图示)、将输送物从规定位置向其他位置运送的自动输送车(未图示)、机器人(未图示)等输送机进行控制的控制装置而实装。本实施方式涉及的控制装置1具有的cpu11是对控制装置1进行整体控制的处理器。cpu11经由总线20读出存储于rom12的系统程序,按照该系统程序来对控制装置1整体进行控制。临时的计算数据、操作员经由未图示的输入部输入的各种数据等暂时存储于ram13中。
非易失性存储器14构成为如下存储器:例如通过未图示的电池而进行备份等,即使断开输送机的控制装置1的电源也可以保持存储状态。在非易失性存储器14中存储有操作员经由未图示的输入部输入的各种数据(例如,用于控制输送机70的输送动作的设定值等)、经由未图示的接口输入的控制用的程序等。存储于非易失性存储器14的程序或各种数据可以在执行时/利用时在ram13中被展开。此外,在rom12中预先写入系统程序,所述系统程序包含根据传感器60检测输送物的状态而得的检测值来进行解析的众所周知的解析程序和控制与后述的机器学习装置100的交换的系统程序等。
传感器60对输送机输送的输送物的状态进行检测。传感器60例如可以是对作为液体的输送物是否是从容器洒落的状态进行检测的液面传感器或光学传感器,还可以是对输送物的重心位置进行检测的载荷传感器,此外,也可以是对输送物的姿势或落下状态进行拍摄的照相机等拍摄单元。此外,传感器60也可以是用于检测输送机输送的输送物的位置、输送机其本身的位置的传感器。传感器60经由接口18将检测出的检测值转发给cpu11。
控制电路19接收来自cpu11的指令对输送机70的输送动作进行控制。控制电路19可以控制输送机70的输送速度(在输送机70可以将输送物向多个方向输送时包含输送方向的速度),此外,还可以在输送机70可以控制输送物的姿势时,可以控制输送机70输送的输送物的姿势。接口21是用于将控制装置1与机器学习装置100连接的接口。
机器学习装置100具有:统一控制机器学习装置100整体的处理器101、存储系统程序等的rom102、用于进行机器学习涉及的各处理中的临时的存储的ram103、以及用于存储学习模型等的非易失性存储器104。机器学习装置100可以经由接口21利用控制装置1来观测能够取得的各信息(由传感器60检测出的输送物的状态、输送物的位置、输送机的位置、输送机70的输送动作的参数等)。此外,控制装置1接收从机器学习装置100输出的、控制输送机70的输送动作的指令,控制输送机70的输送动作。
图2是第一实施方式涉及的输送机的控制装置1与机器学习装置100的概略功能框图。
机器学习装置100包含通过所谓的机器学习来自学输送机70相对于输送机70输送的输送物的状态的输送动作的控制的软件(学习算法等)和硬件(处理器101等)。控制装置1具有的机器学习装置100学习的内容相当于表示输送机70输送的输送物的状态与输送机70的输送动作的相关性的模型结构。
如图2的功能模块所示,控制装置1具有的机器学习装置100具有:状态观测部106,其对表示环境的当前状态的状态变量s进行观测,所述状态变量s包含表示输送机70的输送动作的状态的输送动作数据s1和表示输送物的状态的输送物状态数据s2;判定数据取得部108,其取得判定数据d,所述判定数据d包含表示按照从机器学习装置100输出的指令控制了输送机70的输送动作时的该输送动作涉及的输送物的输送速度的适当与否判定结果的输送速度判定数据d1和表示该输送动作涉及的输送物的状态变化的适当与否判定结果的输送物状态判定数据d2;以及学习部110,其使用状态变量s和判定数据d,将输送动作数据s1与输送机输送的输送物的状态关联起来进行学习。
状态观测部106例如可以构成为处理器101的一功能,还可以构成为用于使处理器101发挥功能的存储于rom102的软件。状态观测部106观测的状态变量s中的输送动作数据s1例如可以作为用于控制输送机70的输送动作的参数的设置而取得。作为用于控制输送机70的输送动作的参数,包含输送机的输送速度和加速度(输送机70可以将输送物向多个方向输送时包含输送方向的速度、加速度)等,但是用于控制这样的输送机70的输送动作的参数因输送机70的种类(传送带、机器人、自动输送车等)而不同,因此,可以根据各自的输送机70来取得适当的参数。
输送动作数据s1在学习的初期,例如可以使用由熟练的作业员申报而提供给控制装置1的、控制输送机70的输送动作涉及的参数。此外,输送动作数据s1在学习进展到某种程度的阶段,可以利用机器学习装置100根据学习部110的学习结果在前一个学习周期中决定的控制输送机70的输送动作所使用的参数。这样的情况下,机器学习装置100可以按学习周期将决定的用于控制输送机70的输送动作的参数暂时存储于ram103中,状态观测部106可以从ram103中取得在前一学习周期中机器学习装置100决定的用于控制输送机70的输送动作的参数。
在状态变量s的输送物状态数据s2中,例如可以使用对传感器60检测出的检测值进行解析而获得的、输送物的状态涉及的数据。这里,在输送物状态数据s2表示的输送物的状态中可以包含由载荷传感器检测出的输送物的重心位置的偏移(从输送台的中心位置起的输送物的重心位置的偏移量等)、液面传感器检测出的液体的输送物的洒落状态(液面的最大高度是否超过了预定高度等)、输送物的姿势(输送台上的输送物从理想的装载状态起变化了何种程度,或倾斜了何种程度等),输送物的落下状态(输送物是否落下,落下的输送物的个数等)、施加于输送物上的撞击等。
判定数据取得部108例如可以构成为处理器101的一功能,还可以构成为用于使处理器101发挥功能的存储于rom102的软件。判定数据取得部108可以使用输送速度判定数据d1作为判定数据d,所述输送速度判定数据d1是进行了输送机70的输送动作的控制时的该输送动作涉及的输送物的输送速度的适当与否判定值。判定数据取得部108可以使用输送物移动预先设定的预定距离所花费的时间(周期时间)、预先设定的预定时间内的输送物的输送距离等作为输送速度判定数据d1。输送速度判定数据d1是表示在状态变量s下进行了输送机70的输送动作控制时的输送效率的结果的指标。
此外,判定数据取得部108还可以使用输送物状态判定数据d2作为判定数据d,所述输送物状态判定数据d2表示进行了输送机70的输送动作的控制时该输送动作涉及的输送物的状态变化的适当与否判定结果。判定数据取得部108可以使用基于进行了输送动作的控制前后的输送物状态数据s2的变化的好坏判定的结果(例如,从输送台的中心位置起的输送物的重心位置的偏移量的增减、液面的最大高度的增减、输送台上的输送物从理想的装载状态起的变化量的增减、倾斜的增减、落下物的增减等)用作输送物状态判定数据d2。输送物状态判定数据d2是表示状态变量s下进行了输送机70的输送动作的控制时的输送物的状态好坏的指标。
在按学习部110涉及的学习周期考虑的情况下,同时输入到学习部110的状态变量s是基于取得了判定数据d的1个学习周期前的数据的变量。这样,在控制装置1具有的机器学习装置100推进学习的期间,在环境下,重复执行输送物状态数据s2的取得、基于输送动作数据s1的输送机的输送动作的控制、判定数据d的取得。
学习部110例如可以构成为处理器101的一功能,还可以构成为用于使处理器101发挥功能的存储于rom102的软件。学习部110按照统称为机器学习的任意学习算法,学习针对输送物的状态的输送动作数据s1。学习部110可以反复执行基于包含上述的状态变量s和判定数据d的数据集合的学习。在针对输送物的状态的输送动作数据s1的学习周期的反复中,如上所述,从1个学习周期前由传感器60检测出的检测值的解析结果取得状态变量s中的输送物状态数据s2,将输送动作数据s1设为根据前次的学习结果决定的输送机70的输送动作。此外,将判定数据d设为根据输送动作数据s1设定了输送机70的输送动作之后执行的本次的学习周期中的输送速度、输送物的状态的适当与否判定结果。
通过重复这样的学习周期,学习部110可以自动识别暗示输送物的状态(输送物状态数据s2)与针对该状态的输送机70的输送动作的相关性的特征。在开始学习算法时,输送物状态数据s2与输送机70的输送动作的相关性实际上是未知的,但是学习部110随着学习的推进逐渐地识别特征并解释相关性。若输送物状态数据s2与输送机70的输送动作的相关性解释为达到某种可以信赖的水平的话,学习部110反复输出的学习结果可以用于针对当前状态(也就是说输送机输送的输送物的状态)选择应如何控制输送机70的输送动作的行为(也就是说决策)。也就是说,学习部110随着学习算法的推进,可以使输送机输送的输送物的状态与针对该状态的输送机70的输送动作的控制这样的行为的相关性逐渐接近最佳解。
如上所述,在输送机的控制装置1具有的机器学习装置100中,使用状态观测部106观测到的状态变量s和判定数据取得部108取得的判定数据d,学习部110按照机器学习算法,学习输送机70的输送动作的控制。状态变量s由输送动作数据s1和输送物状态数据s2的能够测量或取得的数据构成,此外判定数据d通过控制装置1对传感器60检测出的检测值进行解析而被唯一地求出。因此,根据控制装置1具有的机器学习装置100,通过使用学习部110的学习结果,不论运算或估算都可以自动且准确地求出输送机输送的输送物的状态对应的输送机70的输送动作。
并且,如果可以不论运算或估算而自动求出输送机70的输送动作,则可以只掌握输送物的状态(输送物状态数据s2),来迅速地决定输送机70的输送动作的适当值。因此,可以高效地决定输送机70的输送动作。
作为输送机的控制装置1具有的机器学习装置100的第一变形例,状态观测部106除了输送机70的输送速度、加速度之外,还可以使用输送机70的输送物的姿势变更涉及的状态作为输送动作数据s1。根据输送机70的种类,例如如图3所示,还具有将装载了输送物25(例如,收纳了液体的容器26)的输送台28倾斜的斜率控制单元27。在以这样的输送机70为对象的情况下,可以向输送动作数据s1追加输送物25的姿势变更涉及的状态来进行观测。
根据上述第一变形例,机器学习装置100除了输送机的输送速度、加速之外,还针对可以控制姿势的输送机70进行包含输送物的姿势变更涉及的状态的学习,因此可以进行更有效的输送机的输送动作的控制。
作为输送机的控制装置1具有的机器学习装置100的第二变形例,状态观测部106除了输送动作数据s1和输送物状态数据s2之外,还可以观测表示输送物或输送机70的位置的输送位置数据s3作为状态变量s。输送物或输送机70的位置可以使用利用了设置于各位置的无线基站、信标等的测量方法,也可以使用gps等位置测量单元。此外,还可以通过设置于输送路径的各位置的固定相机来确定输送物或输送机70的位置。此外,在输送机70是机器人时,也可以根据驱动机器人的各关节的伺服电动机的位置(伺服电动机的旋转角度)来确定输送物的位置。
在输送机70进行的输送物的输送过程中,有时与输送物或输送机70的位置对应地,因某些外在内在原因输送状态发生变化。例如,在输送机70是传送带等时,在特定的位置产生部品的磨耗造成的振动,或在输送机70是自动输送车辆时,在移动中的特定的位置因存在凹凸、斜坡而产生振动,或在输送物上向特定的方向产生加速度。根据上述第二变形例,机器学习装置100可以与输送物或输送机70的位置对应地适当控制输送机70的输送动作,因此,可以与上述那样的外在内在原因造成的输送状态的变化相对应。
作为输送机的控制装置1具有的机器学习装置100的第三变形例,状态观测部106还可以观测表示输送物的性质的输送物性质数据s4作为状态变量s。作为输送物的性质,例如可以使用输送物的重量或大小、在输送物为液体时可以使用输送物的粘性等。
根据上述第三变形例,机器学习装置100可以考虑输送物的性质来进行输送机70的输送动作的学习。
作为输送机的控制装置1具有的机器学习装置100的第四变形例,学习部110可以使用针对进行相同作业的多个输送机70的控制装置1的每一个获得的状态变量s和判定数据d,学习控制装置1中的输送机70的输送动作的控制。根据该结构,可以增加包含在固定时间获得的状态变量s和判定数据d的数据集合的量,因此可以将更多样的数据集合作为输入,提升输送机70的输送动作的学习的速度、可靠性。
在具有上述结构的机器学习装置100中,学习部110执行的学习算法没有特别限定,作为机器学习可以采用众所周知的学习算法。图4是图1所示的控制装置1的一方式,表示作为学习算法的一例而具有执行强化学习的学习部110的结构。强化学习是这样的方法:对学习对象存在的环境的当前状态(即输入)进行观测,并且在当前状态下执行预定的行为(即输出),试错性地反复进行针对该行为给予何种回报的周期,将回报的总计为最大化那样的对策(本申请的机器学习装置中是输送机70的输送动作的决定)作为最佳解来进行学习。
在图4所示的控制装置1具有的机器学习装置100中,学习部110具有:回报计算部112,其求出与根据状态变量s控制了输送机70的输送动作时的输送速度、输送物的状态的适当与否判定结果(相当于取得了状态变量s的下一个学习周期中使用的判定数据d)相关联的回报r;以及价值函数更新部114,其使用该求出的回报r来更新表示输送机70的输送动作的价值的函数q。在学习部110中,价值函数更新部114反复更新函数q来学习针对输送机70输送的输送物的状态的输送机70的输送动作的控制。
对学习部110执行的强化学习的算法的一例进行说明。
该示例涉及的算法已知为q学习(q-learning),是这样的方法:将行为主体的状态s和该状态s下行为主体能够选择的行为a(输送动作中的输送速度(也可以包含输送方向)的增加/减少,加速度的增加/减少,输送物的姿势变更等)作为独立变量,学习表示在状态s下选择行为a时的行为的价值的函数q(s、a)。状态s下选择价值函数q最高的行为a为最佳解。在状态s与行为a的相关性未知的状态下开始q学习,反复进行在任意的状态s下选择各种行为a的试错,由此反复更新价值函数q,接近最佳解。这里,通过引导学习以使作为状态s下选择了行为a的结果在环境(即状态s)发生变化时,获得与该变化对应的回报(即行为a的权值)r,选择获得更高的回报r的行为a,由此,可以在比较短的时间内使价值函数q接近最佳解。
价值函数q的更新式一般情况下可以像下述的数学式(1)那样表示。在该数学式(1)中,st和at分别是时刻t的状态和行为,通过行为at状态变化为st+1。rt+1是通过状态从st变化为st+1而得到的回报。maxq的项是在时刻t+1进行了成为最大的价值q的(与在时刻t下认为的)行为a时的q。α和γ分别是学习系数和折扣率,以0<α≤1、0<γ≤1被任意设定。
在学习部110执行q学习时,状态观测部106观测到的状态变量s和判定数据取得部108取得的判定数据d相当于更新式(上述数学式(1))的状态s,应该如何决定针对当前状态(即,输送机输送的输送物的状态)的输送机70的输送动作的行为相当于更新式的行为a,回报计算部112求出的回报r相当于更新式的回报r。因此,价值函数更新部114通过使用了回报r的q学习来反复更新表示针对当前状态的输送机70的输送动作的价值的函数q。
关于回报计算部112求出的回报r,例如在根据决定了输送机70的输送动作之后决定的输送动作的参数进行了实际的输送动作时,将输送速度、输送物的状态的适当与否判定结果判定为“适当”的情况下(例如,预定时间内的输送物的输送距离是可允许的范围内时,输送物的重心的偏移收敛于可允许的范围内时、输送动作的控制后的输送物的液面的高度的最大值低时、没有引起输送物的落下时等),设为正(plus)的回报r,在根据决定了输送机70的输送动作之后决定的输送动作的参数进行了实际的输送动作时,将输送速度、输送物的状态的适当与否判定结果判定为“不适当”的情况下(例如,预定时间内的输送物的输送距离比可允许的范围短时,输送物的重心的偏移为可允许的范围外时、输送动作的控制后的输送物的液面的高度的最大值高时、引起输送物的落下时等),设为负(minus)的回报r。正负的回报r的绝对值既可以彼此相同,也可以不同。此外,作为判定的条件,也可以将判定数据d所包含的多个值进行组合来进行判定。
此外,并非只有“适当”和“不适当”这两种,还可以将输送速度、输送物的状态的适当与否判定结果设定为多个阶段。作为示例,可以设为如下结构:在预定时间内的输送物的输送距离的允许范围的最小值为lmin时,供给预定个数的部品的周期时间l为0≤t≤lmin/5时给予回报r=-5,在lmin/5≤l<lmin/2时给予回报r=-2,在lmin/2≤l≤lmin时给予回报r=-1。并且,还可以设为如下结构:学习的初始阶段将lmin设定得比较小,随着学习推进而将lmin设定得大。
价值函数更新部114可以具有将状态变量s、判定数据d、回报r与函数q所表示的行为价值(例如数值)关联起来整理而得的行为价值表。该情况下,价值函数更新部114更新函数q这样的行为与价值函数更新部114更新行为价值表这样的行为一样。在开始q学习时由于环境的当前状态与输送机70的输送动作的相关性是未知的,因此在行为价值表中,以与设定为无作为的行为价值的值(函数q)关联起来的形式准备了各种状态变量s、判定数据d、回报r。另外,回报计算部112如果知晓判定数据d则可以立即计算与之对应的回报r,计算出的值r被写入到行为价值表中。
若使用与输送速度、输送物的状态的适当与否判定结果对应的回报r来进行q学习,则向选择获得更高的回报r的行为的方向引导学习,与在当前状态下执行了选择出的行为的结果而变化的环境的状态(即状态变量s和判定数据d)对应地,改写针对当前状态下进行的行为的行为价值的值(函数q)来更新行为价值表。通过反复进行该更新,显示于行为价值表的行为价值的值(函数q)以越是适当的行为越是较大的值的方式被改写。这样,未知的环境的当前状态(输送机输送的输送物的状态)和与之相对的行为(输送机70的输送动作的决定)的相关性逐渐明确。即,通过行为价值表的更新,输送机输送的输送物的状态与输送机70的输送动作的关系逐渐接近最佳解。
参照图5,进一步对学习部110执行的上述q学习的流程(即机器学习方法的一方式)进行说明。
首先,通过步骤sa01,价值函数更新部114一边参照该时间点的行为价值数据,一边随机选择输送机70的输送动作作为在状态观测部106观测到的状态变量s所示的当前状态下进行的行为。接下来,价值函数更新部114通过步骤sa02,取入状态观测部106观测的当前状态的状态变量s,通过步骤sa03,取入判定数据取得部108取得的当前状态的判定数据d。接下来,价值函数更新部114通过步骤sa04,根据判定数据d来判断输送机70的输送动作是否适当,适当时,通过步骤sa05将回报计算部112求出的正的回报r应用于函数q的更新式,接下来,通过步骤sa06,使用当前状态下的状态变量s、判定数据d、回报r、行为价值的值(更新后的函数q)来更新行为价值表。通过步骤sa04,在判断为输送机70的输送动作不适当时,通过步骤sa07将回报计算部112求出的负的回报r应用于函数q的更新式,接下来,通过步骤sa06,使用当前状态下的状态变量s、判定数据d、回报r、行为价值的值(更新后的函数q)来更新行为价值表。
学习部110通过反复进行步骤sa01~sa07来反复更新行为价值表,推进输送机70的输送动作的学习。另外,针对判定数据d所包含的各数据,执行从步骤sa04到步骤sa07的求出回报r的处理和价值函数的更新处理。
在推进所述强化学习时,例如可以应用神经网络。图6a示意性地表示神经元的模型。图6b示意性地表示将图6a所示的神经元组合而构成的三层神经网络的模型。神经网络例如由模拟了神经元的运算装置、存储装置等来构成。
图6a所示的神经元输出针对多个输入x(这里作为一例,输入x1~输入x3)的结果y。对各输入x1~x3乘以与该输入x对应的权值w(w1~w3)。由此,神经元输出由如下数学式(2)表现的结果y。另外,在数学式(2)中,输入x、结果y和权值w都是向量。此外,θ是偏置(bias),fk是激活函数(activationfunction)。
图6b所示的三层神经网络,从左侧输入多个输入x(这里作为一例是输入x1~输入x3),从右侧输出结果y(这里作为一例,结果y1~结果y3)。在图示的示例中,输入x1、x2、x3分别被乘以对应的权值(统称为w1),各输入x1、x2、x3都被输入到三个神经元n11、n12、n13。
在图6b中,将神经元n11~n13的每一个的输出统称为z1。z1可以被看作是提取输入向量的特征量而得的特征向量。在图示的示例中,特征向量z1分别被乘以对应的权值(统称为w2),各特征向量z1都被输入到两个神经元n21、n22。特征向量z1表示权值w1与权值w2之间的特征。
在图6b中,将神经元n21~n22的每一个的输出统称为z2。z2可以被看作是提取特征向量z1的特征量而得的特征向量。在图示的示例中,特征向量z2分别乘以对应的权值(统称为w3),各特征向量z2都被输入到三个神经元n31、n32、n33。特征向量z2表示权值w2与权值w3之间的特征。最后神经元n31~n33分别输出结果y1~y3。
另外,还能够使用所谓的深层学习的方法,所述深层学习使用了形成三层以上的层的神经网络。
在控制装置1具有的机器学习装置100中,将神经网络用作q学习中的价值函数,将状态变量s与行为a设为输入x,学习部110进行按照上述神经网络的多层结构的运算,由此可以输出该状态下的该行为的价值(结果y)。另外,在神经网络的动作模式中有学习模式和价值预测模式,例如,在学习模式中使用学习数据集来学习权值w,在价值预测模式中使用学习到的权值w来进行行为的价值判断。另外,在价值预测模式中,可以进行检测、分类、推论等。
在机器学习装置100的学习部110中学习到的价值函数,作为已学习模型能够用作机器学习涉及的软件的一部分的程序模块。本发明的已学习模型可以用于具有cpu或gpgpu等处理器和存储器的计算机。更具体来说,以如下方式来进行动作:计算机的处理器按照存储于存储器的来自已学习模型的指令,将环境的状态与输送机的输送动作的控制行为设为输入来进行运算,根据运算结果输出针对该环境的状态的输送机的输送动作的控制行为的价值。本发明的已学习模型能够经由外部存储介质、网络等,针对其他计算机进行复制而利用。
此外,本发明的已学习模型被其他计算机复制而在新的环境下利用时,根据该环境下获得的新的状态变量、判定数据,针对该已学习模型进行进一步的学习。这样的情况下,能够获得从该环境涉及的已学习模型派生的已学习模型(以下,称为派生模型)。本发明中的派生模型在输出预定状态下的行为的选择的价值这方面与原本的已学习模型相同,但是在输出比原本的已学习模型更适合于新的环境的结果这方面不同。此外,该派生模型也能够经由外部存储介质、网络等被其他计算机复制并利用。
并且,使用针对装入了本发明的已学习模型的机器学习装置的输入(预定状态下的行为的选择)获得的输出(价值),制作在其他机器学习装置中从1起进行学习而获得的已学习模型(以下,设为蒸馏模型),还能够对其进行利用(将这样的学习工序称为蒸馏)。在蒸馏中,将原本的已学习模型称为教师模型,将重新制作的蒸馏模型称为学生模型。一般情况下,蒸馏模型的尺寸比原本的已学习模型小,尽管如此由于输出与原本的已学习模型相同的准确,因此比经由外部存储介质或网络等的针对其他计算机的发布更适当。
上述输送机的控制装置1的结构可以记述为处理器101执行的机器学习方法(或者软件)。该机器学习方法是学习输送机70的输送动作的控制的机器学习方法,
具有如下步骤:计算机的cpu观测输送动作数据s1和输送物状态数据s2,作为表示进行输送机70的输送动作的控制的环境的当前状态的状态变量s的步骤;
取得判定数据d的步骤,所述判定数据d表示作为基于决定的输送机70的输送动作的输送机70的控制的结果的输送速度和输送物的状态的适当与否判定结果;和
使用状态变量s与判定数据d,将输送物状态数据s2与输送机70的输送动作关联起来进行学习的步骤。
图7表示第二实施方式涉及的输送机的控制装置2。
该第二实施方式涉及的输送机的控制装置2具有与所述的第一实施方式一样的硬件结构。控制装置2具有:机器学习装置120、取得状态观测部106观测的状态变量s的输送动作数据s1和输送物状态数据s2作为状态数据s0的状态数据取得部3。状态数据取得部3可以从控制装置2的各部、由传感器60检测出的检测值的解析结果、由输送机70取得的值、作业员的适当的数据输入等取得状态数据s0。
控制装置2具有的机器学习装置120除了通过机器学习来自学输送机70的输送动作的软件(学习算法等)和硬件(处理器101等)之外,还包含将根据学习结果求出的输送机70的输送动作作为对控制装置2的指令而输出的软件(运算算法)和硬件(处理器101等)。控制装置2包含的机器学习装置120还可以由一个共通的处理器执行学习算法、运算算法等所有软件。
决策部122例如可以构成为处理器101的一功能,此外还可以构成为用于使处理器101发挥功能的存储于rom102的软件。决策部122根据学习部110学习到的结果,生成包含决定输送机70针对输送机输送的输送物的状态的输送动作的指令在内的指令值c,输出生成的指令值c。在决策部122将指令值c输出给输送机的控制装置2时,与之对应地环境的状态发生变化。决策部122输出的指令值c中例如可以包含变更或指示输送机70的输送速度(根据需要包含输送的方向)的指令、变更或指示输送机70的加速度(根据需要包含加速的方向)的指令。此外,在决策部122输出的指令值c中例如还可以包含基于输送机70的输送物的姿势变更或指示所涉及的指令。
状态观测部106在下一学习周期观测决策部122输出了对环境的指令值c之后变化的状态变量s。学习部110使用变化后的状态变量s,例如通过更新价值函数q(即,行为价值表),来学习输送机70的输送动作的控制。另外,此时状态观测部106不是从状态数据取得部3取得的状态数据s0取得输送动作数据s1,也可以像第一实施方式所说明那样从机器学习装置120的ram103取得。
决策部122将指示根据学习结果决定的输送机70的输送动作的设定的指令值c输出给输送机的控制装置2。通过反复进行该学习周期,机器学习装置120推进输送机70的输送动作的学习,使得自身决定的输送机70的输送动作的信赖性逐渐上升。
具有上述结构的输送机的控制装置2具有的机器学习装置120获得与上述的机器学习装置100(图2和图4)同样的效果。尤其,机器学习装置120可以通过决策部122的输出使环境的状态发生变化。另一方面,在机器学习装置100中,可以向外部装置请求相当于将学习部110的学习结果反映给环境的决策部的功能。
图8表示具有输送机的控制装置160的一实施方式涉及的系统170。
系统170至少具有进行相同作业的多个控制装置160、160’、将这些控制装置160、160’相互连接的有线/无线网络172,这些多个控制装置160、160’中的至少一个构成为具有上述机器学习装置120的控制装置160。此外系统170可以包含不具有机器学习装置120的控制装置160’。这些控制装置160、160’具有进行相同目的的作业所需的机构。
关于具有上述结构的系统170,多个输送机的控制装置160、160’中具有机器学习装置120的控制装置160使用学习部110的学习结果,不论运算或估算都自动且准确地求出输送机70针对输送机70输送的输送物的状态的输送动作的控制。此外,可以构成为:至少一个控制装置160的机器学习装置120根据针对其他多个控制装置160、160’的每一个而获得的状态变量s和判定数据d,来学习所有控制装置160、160’通用的输送机70的输送动作的控制,所有控制装置160、160’共享该学习结果。因此,根据该系统170,可以将更多样的数据集合(包含状态变量s和判定数据d)设为输入,提高学习输送机70的输送动作的控制的速度和可靠性。
图9表示具有输送机的控制装置160’的其他实施方式涉及的系统170’。
系统170’具有:机器学习装置120(或100)、具有相同机械结构的多个控制装置160’、将这些控制装置160’与机器学习装置120(或100)相互连接的有线/无线的网络172。
关于具有上述结构的系统170’,机器学习装置120(或100)根据针对多个控制装置160’的每一个而获得的状态变量s和判定数据d,来学习输送机70所有控制装置160’通用的、针对输送机输送的输送物的状态的输送机70的输送动作的控制,使用该学习结果,可以不论运算或估算都自动且准确地求出针对输送机输送的输送物的状态的输送机70的输送动作。
该系统170’中,机器学习装置120(或100)可以具有存在于在网络172上准备的云处服务器等的结构。根据该结构,不论多个控制装置160’的每一个所在的场所或时间日期,都可以在需要时将所需数量的控制装置160’连接到机器学习装置120(或100)。
从事系统170、170’的作业员在机器学习装置120(或100)涉及的学习开始后的适当时间日期,可以执行如下判断:基于机器学习装置120(或100)的输送机70的输送动作的控制的学习的到达度(即输送机70的输送动作的控制的可靠性)是否达到了请求标准的判断。
本发明的输送机的控制装置1(或2或160)控制的输送机70用于将输送物进行输送,能够控制输送速度,能够使用任何传感器来检测输送物的状态。
例如,如图10所示,可以是对装载于输送台28且填充了液体25的容器26进行输送的输送机70(传送带)。在这样的输送机70中,作为检测输送物(液体25)的状态的传感器60,例如可以使用设置于容器内的浮球开关等液面传感器。
机器学习装置100(或120)进行将传感器60检测到的液面的高度检测为液体25(输送物)的状态、在液面的高度的最大值超过预先设定的规定的允许值时给予负回报那样的学习,可以进行在不引起输送物即液体25从容器26洒落这样的不良的范围内将输送的周期时间设为最大的输送速度、加速度的控制。
此外,如图11所示,也能够同样地应用于对多个填充了液体40的容器41进行输送的输送机70。该情况下,作为传感器60(图1)可以利用设置于多个容器41的每一个的浮球开关等液面传感器,这样的情况下,可以从各传感器60检测出的各容器41中的液面的高度分别计算出输送物(液体40)的状态的适当与否判定结果,将这些进行累计而求出回报。
如图12所示,还考虑对这样的输送机70的应用:对填充到吊挂的透明的包装51的液体50进行输送。在这样的输送机70中,作为对输送物(液体50)的状态进行检测的传感器60,例如在包装51通过的左右位置设置光学传感器60,可以通过液体50是否遮光来检测液面的高度。
机器学习装置100(或120)中,将由传感器60检测的液面的高度检测为输送物(液体50)的状态,在液面的高度的最大值超过预先设定的预定允许值时进行给予负回报的学习,可以进行在不引起输送物即液体50从包装51洒落的不良的范围内将输送的周期时间设为最大的输送速度、加速度的控制。
此外,即使应用于图13所示那样的自动输送机,本发明的控制装置也充分地发挥效果。
在这样的输送机70中,作为传感器60可以利用设置于输送机70本身的照相机71、设置于输送路径的各位置的固定照相机72等。通过各照相机来拍摄输送物堆积的状态,通过解析拍摄到的图像而取得输送物73(图13的示例中,没有固定的箱子)的装载值状态(从理想状态的偏移)而可以用作表示输送物73的状态的数据,由于输送物73的落下等也可以检测,因此可以进行在不引起这样的不良的范围内将输送中的周期时间设为最大的输送速度、加速度的控制。并且,通过利用作为传感器60的固定照相机72来检测输送机70的位置,也能够观测为输送位置数据s3,能够将此用于学习。
即使在进行图14所示那样的、基于机器人的输送物的置换时,也能够利用本发明的控制装置。
在这样的输送机70中,作为传感器60可以利用设置于输送机70(在图14的示例中是机器人)本身的照相机71、设置于输送机70的附近的固定照相机72等,对机械手把持或者装载于手臂上的输送物74(在图14的示例中是面板)进行拍摄,解析拍摄到的图像而取得输送物74的装载值状态(输送物74的姿势或重心的偏移等)而可以用作表示输送物74的状态的数据,由于输送物74的落下等也可以检测,因此可以进行在不引起这样的不良的范围内将输送中的周期时间设为最大的输送速度、加速度的控制。此外,在输送机70(机器人)的输送动作的控制中还可以指示输送物的姿势变更等。
本发明的控制装置控制的输送机70也可以是图15所示那样的、对搭载于输送台82的输送物83进行输送的输送机70(传送带),输送台8具有2作为传感器60的载荷传感器81(力传感器)。
并且,本发明的控制装置控制的输送机70也可以是图16所示那样的、对装载于具有载荷传感器91(力传感器)的输送台92上的、收纳于收纳容器93的多个输送物94进行输送的输送带。在所获得的这样的输送机70(传送带)中,作为检测输送物94的状态的传感器60,可以利用设置于输送台92的载荷传感器91。另外,在图16中,符号95表示设置于输送台92的面板等弹性体。
机器学习装置100(或120)进行这样的学习:作为输送物94的状态而从由该传感器60(载荷传感器91)检测的力的作用情况检测输送物94的装载位置的偏移、重心的偏移,在偏移大时给予负回报的学习,通过进行这样的学习,可以进行在不引起输送物94在输送台92上偏移或从收纳容器93落下这样的不良的范围内将输送中的周期时间设为最大那样的输送速度、加速度的控制。
以上,对本发明的实施方式进行了说明,但是本发明并不只限定于上述实施方式的示例,可以通过增加适当的变更以各种方式来实施。
例如,机器学习装置100、120执行的学习算法、机器学习装置120执行的运算算法、输送机的控制装置1、2执行的控制算法等并不限定于上述,可以采用各种算法。
此外,在上述实施方式中,将输送机的控制装置1(或2)与机器学习装置100(或120)作为具有不同的cpu的装置而进行了说明,但是机器学习装置100(或120)也可以通过输送机的控制装置1(或2)具有的cpu11、存储于rom12的系统程序来实现。
- 还没有人留言评论。精彩留言会获得点赞!