风速误差模型的训练方法、装置及风力发电机组与流程
本发明涉及风电技术领域,尤其涉及一种基于K近邻算法的风速误差模型的训练方法、装置及风力发电机组。
背景技术:
随着风电行业的高速发展,调度电力系统面临着巨大的挑战。在风电行业中,风速预测的准确性将直接影响功率预测结果,进而直接影响电能质量。
目前,预测风速误差的计算方法大多采用BP神经网络和SVM等回归算法建立风速误差预测模型。然而,这些算法均以拟合一条最优曲线为目标,使得所有训练数据的目标值和预测值的均方根误差最小,其训练结果往往需要权衡所有的训练数据。因此,无论采用上述何种方法建立误差预测模型,,其结果均受到输入样本的影响较大,无法确保较高的准确率。
技术实现要素:
本发明提供了一种基于K近邻算法的风速误差模型的训练方法、装置及风力发电机组,能够显著提高预测风速的准确率。
为达到上述目的,本发明实施例提供了一种基于K近邻算法的风速误差模型的训练方法,包括:获取预测风速值,并获取对应的实际风速值;计算所述实际风速值与所述预测风速值之间的实际风速误差;以所述预测风速值及其对应的所述实际风速误差作为训练样本,采用K近邻算法建立风速误差模型。
本发明实施例还提供了一种基于K近邻算法的风速误差模型的训练装置,包括:第一数据获取模块,用于获取预测风速值,并获取对应的实际风速值;误差计算模块,用于计算所述实际风速值与所述预测风速值之间的实际风速误差;模型构建模块,用于以所述预测风速值及其对应的所述实际风速误差作为训练样本,采用K近邻算法建立风速误差模型。
本发明实施例还提供了一种风力发电机组,包括:设置有如上所述的基于K近邻算法的风速误差模型的训练装置。
本发明提供的基于K近邻算法的风速误差模型的训练方法、装置及风力发电机组,通过输入预测风速值和实际风速值,计算得到实际风速误差,并以预测风速值和实际风速误差作为训练样本,采用K近邻算法建立风速误差模型。由于采用K近邻算法,通过确定K值来决定输出结果,其预测结果主要靠周围有限的邻近的样本,不受其他样本的影响,进而减少了训练数据中其它数据对当前数据的影响,提高了模型预测的准确率。
附图说明
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本申请的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
图1为本发明实施例提供的基于K近邻算法的风速误差模型的训练方法流程图一;
图2为本发明实施例提供的基于K近邻算法的风速误差模型的训练方法逻辑示意图;
图3为本发明实施例提供的基于K近邻算法的风速误差模型的训练方法流程图二;
图4为本发明实施例提供的用于K值选择的交叉验证方法流程图;
图5为本发明实施例提供的基于K近邻算法的风速误差模型的训练方法流程图三;
图6为本发明实施例提供的基于K近邻算法的风速误差模型的训练方法流程图四;
图7为本发明实施例提供的风速订正方法流程图;
图8为本发明实施例提供的风速订正方法逻辑示意图;
图9为本发明实施例提供的风速订正效果图;
图10为本发明实施例提供的基于K近邻算法的风速误差模型的训练装置结构示意图一;
图11为本发明实施例提供的基于K近邻算法的风速误差模型的训练装置结构示意图二;
图12为本发明实施例提供的基于K近邻算法的风速误差模型的训练装置结构示意图三;
图13为本发明实施例提供的基于K近邻算法的风速误差模型的训练装置结构示意图四;
图14为本发明实施例提供的风速订正装置结构示意图。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
本发明提供的基于K近邻算法的风速误差模型的训练方法、装置及风力发电机组,通过输入预测风速值和实际风速值,计算得到实际风速误差,并以预测风速值和实际风速误差作为训练样本,采用K近邻算法建立风速误差模型。由于采用K近邻算法,通过确定K值来决定输出结果,其预测结果主要靠周围有限的邻近的样本,不受其他样本的影响,进而减少了训练数据中其它数据对当前数据的影响,提高了模型预测的准确率。
下面通过多个实施例来说明本申请的技术方案。
实施例一
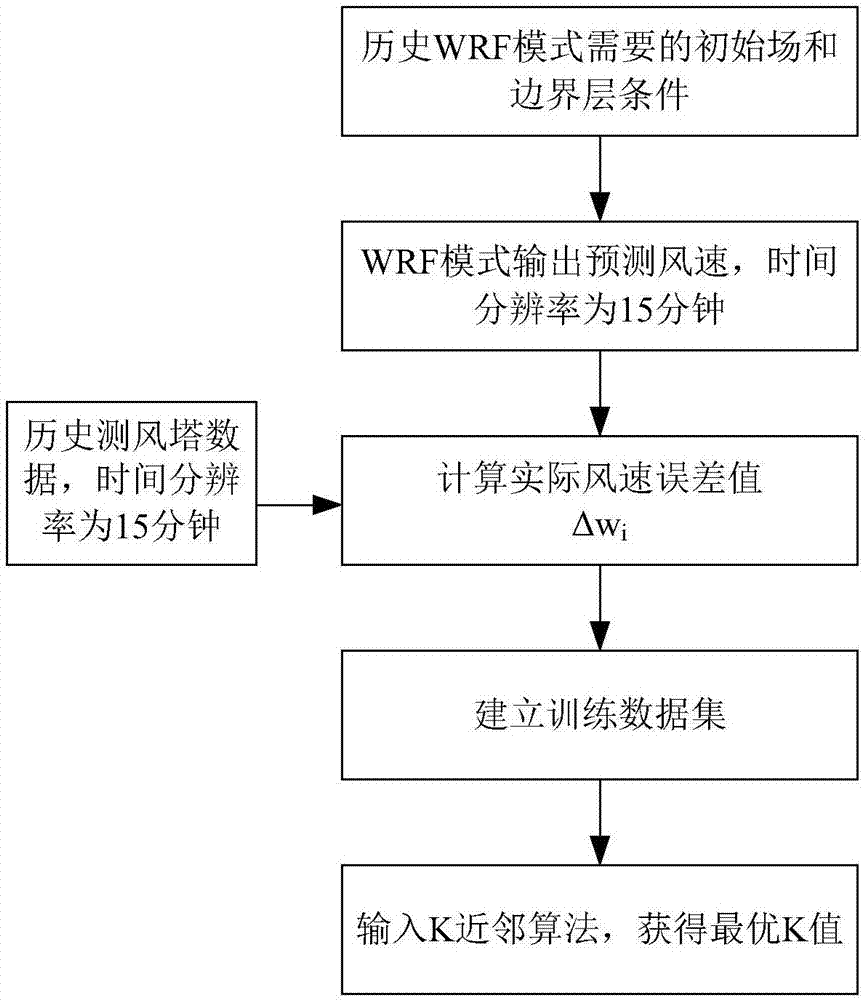
图1为本发明实施例提供的基于K近邻算法的风速误差模型的训练方法流程图一,该模型用于以预测风速值为输入,输出相应的预测风速误差值,如图1所示,该方法包括:
S110,获取预测风速值,并获取对应的实际风速值。
首先,预测风速值的获取可采用中尺度预报模式WRF,具体地,包括但不限于以全球大尺度气象预报数据为中尺度天气预报模式WRF(以下简称“WRF模式”)的初始场和边界条件;然后,采集待测风电场地理信息作为WRF模式下垫面信息,例如海陆分布、地形起伏和地表粗糙度、植被、土壤湿度、雪被面积等信息,从而建立WRF模式;最后,通过WRF模式获得初始预报数据,该初始预报数据包括但不限于预测风速值,例如还可包括该风电场范围内的温度、风向等数据。此外,可通过风机数据或测风塔数据等采集与获取的预测风速值相应的实际风速值。上述数据的采样周期可设置为15分钟。
S120,计算实际风速值与预测风速值之间的实际风速误差。
根据已获得的预测风速值,并结合与该预测风速值在相同时刻、相同位置且相应的实际风速值,计算预测风速值与实际风速值的差值,并将该差值称为实际风速误差。
S130,以预测风速值及其对应的实际风速误差作为训练样本,采用K近邻算法建立风速误差模型。
具体地,在本实施例中,K近邻算法即指将预测风速值及其对应的实际风速误差作为训练样本,确定一个训练数据集,对于一个新的预测风速实例,在确定的训练数据集中找到与该实例最相近的K个实例,其中,K值的确定可采用多种方法,例如交叉验证、欧氏距离、曼哈顿距离等,从而建立风速误差模型。该风速误差模型以预测风速为输入,以预测风速误差值为输出。
图2为本发明实施例提供的基于K近邻算法的风速误差模型的训练方法逻辑示意图,在实际应用场景中,如图2所示,首先以全球大尺度气象数据为WRF模式的初始场和边界层条件,并采集待测风电场的地理信息,以提供给WRF模式作为下垫面信息,该下垫面信息具体可包括海陆分布、地形起伏和地表粗糙度、植被、土壤湿度、雪被面积等信息,通过WRF模式获得该待测风电场范围内的风速、风向、温度等初始预报数据,其中,该初始预报数据中的风速值即本实施例中所述的预测风速值;然后,假设时间分辨率为15分钟,即数据的采样周期为15分钟,以此频率通过风机数据或测风塔数据获得实际风速值,并结合预测风速值计算实际风速误差值,设任意第i时刻的预测风速值为pwi,任意第i时刻的实际风速值为rwi,实际风速误差值为Δwi,则Δwi=pwi-rwi;最后,将预测风速值pwi和与其对应的实际风速误差值Δwi作为训练样本建立训练数据集,采用K近邻算法建立关于预测风速值pwi和实际风速误差值Δwi的风速误差模型,并可采用多种方法,例如交叉验证、欧氏距离、曼哈顿距离等,选择最优K值。
本发明实施例提供的基于K近邻算法的风速误差模型的训练方法,通过输入预测风速值和实际风速值,计算得到实际风速误差,并以预测风速值和实际风速误差作为训练样本,采用K近邻算法建立风速误差模型,减少了训练数据中其它数据对当前数据的影响,从而显著提高了预测风速误差值的准确
实施例二
图3为本发明实施例提供的基于K近邻算法的风速误差模型的训练方法流程图二,本实施例在实施例一所述方法的基础上,对K近邻算法中K值的选取进行进一步限定。如图3所示,该风速误差模型的训练方法包括:
S210,获取预测风速值,及其对应的实际风速值。
S220,计算实际风速值与预测风速值之间的实际风速误差。
上述步骤S210~S220的内容与步骤S110~S120的内容相同。
S230,以预测风速值及其对应的实际风速误差作为训练样本,采用K近邻算法,通过交叉验证方法,选择K值,建立风速误差模型。
具体地,如上述实施例已经提及,在K近邻算法中,K值的确定可采用多种方法,例如交叉验证、欧氏距离、曼哈顿距离等,在本实施例中,通过交叉验证方法,选择K值。
进一步地,图4为本发明实施例提供的用于K值选择的交叉验证方法流程图,如图4所示,通过交叉验证方法,选择K值包括如下步骤:
S310,设置初始K值。
具体地,该K值可设置为2、3、4等任意正整数值。
S320,将训练样本分为训练集和验证集,针对验证集中每个第一预测风速值,遍历训练集中的每个第二预测风速值,选择K个与该第一预测风速值距离最相邻的第二预测风速值,并将与K个第二预测风速值相应的实际风速误差的平均值作为该第一预测风速值的均值误差。
具体地,如上述实施例已提及,以预测风速值及其对应的实际风速误差作为训练样本,将该训练样本随机分为训练集和验证集,训练集和验证集中均包含有预测风速和与该预测风速对应的实际风速误差值。其中,验证集中的预测风速即上述第一预测风速值,训练集中的预测风速即上述第二预测风速值。依次针对验证集中的每个第一预测风速值,遍历训练集中的每个第二预测风速值,并计算每个第一预测风速值和各第二预测风速值的距离。针对验证集中的每个第一预测风速值,在训练集中选择与其距离最近的K个第二预测风速值,进而基于训练样本中预测风速与实际风速误差值的对应关系,得到与被选出的K个第二预测风速值相应的实际风速误差值,计算K个实际风速误差值的平均值,将该平均值作为当前第一预测风速值对应的均值误差。
例如,设初始K值为2,按照一定比例将训练样本S={(pw1,Δw1),…,(pwi,Δwi),…,(pwn,Δwn)}随机分为训练集Ttrain和验证集Tval,其中,设验证集Tval中第一预测风速值变量表示为pwj,训练集Ttrain中第二预测风速值变量表示为pwi,针对验证集Tval中的每个第一预测风速值pwj,遍历训练集Ttrain中的每个第二预测风速值pwi,分别计算各第二预测风速值pwi到第一预测风速值pwj的距离l,以采用欧氏距离算法为例,可得选择距离l最小的两个pwi点,例如距离第一预测风速值pwj的最相邻的两个第二预测风速值为pwi1和pwi2,这两个点与第一预测风速值pwj相应的实际风速误差值分别为Δwi1和Δwi2,对实际风速误差值Δwi1和Δwi2求平均值,该平均值即为第一预测风速值pwj对应的均值误差Δwj,即:Δwj=(Δwi1+Δwi2)/2。
需要说明的是,上述训练样本中除预测风速值之外,还可包含其他维度的参数,例如气象湿度、温度等,当训练样本的输入数据为多维时,上述验证集中的数据与训练集中的数据的距离即为多维空间中两个点的距离。此外,该距离的计算可采用多种方式,例如可采用欧氏距离或者曼哈顿距离。
S330,计算验证集对应的所有均值误差和均值误差的均方根。
具体地,根据已获得的验证集中每个第一预测风速值所对应求得的均值误差,计算验证集中所有第一预测风速值对应的均值误差的均方根。例如,设验证集中第一预测风速值变量为pwj,经上述计算该第一预测风速值pwj对应的均值误差为Δwj,该验证集中第一预测风速值pwj对应的均值误差的平均值为且设验证集中第一预测风速的数据个数为len(Tval),进而计算验证集对应的所有均值误差的均方根RMSE,计算公式如下:
S340,多次不重复的将训练样本分为训练集和验证集,并执行步骤S320至步骤S330,将得到多个均值误差的均方根的平均值作为当前K值的误差。
具体地,将训练样本按照不同的比例随机分为训练集和验证集进行多次训练,例如,假设训练样本中有10组数据,可将10组数据按照不同比例,例如9:1、8:2、7:3等,分为训练集和验证集,并执行上述步骤S320至步骤S330,每一次训练均可得到一个上述均值误差的均方根,对多次训练得到的多个均值误差的均方根求平均值,作为当前K值的误差。
S350,依次改变K值的大小,并针对每个K值执行步骤S320至步骤S340,并将得到的所有K值的误差中的最小值对应的K值作为风速误差模型中的最终K值。
具体地,改变步骤S310中设置的K值大小,并针对不同的K值执行步骤S320至步骤S340,在每一个K值下均可计算得到相应K值的误差,将得到的所有误差中的最小值对应的K值作为最优K值,该最优K值也是风速误差模型中被选择的最终K值。
本发明实施例提供的基于K近邻算法的风速误差模型的训练方法,通过输入预测风速值和实际风速值,计算得到实际风速误差,并以预测风速值和实际风速误差作为训练样本,采用K近邻算法建立风速误差模型,并通过交叉验证方法对K值的选取进行进一步限定,使得输出的近邻K个值之间的差异小于采用其他方法选择的K个值之间的差异,从而显著提高了预测风速误差值的准确率。
实施例三
图5为本发明实施例提供的基于K近邻算法的风速误差模型的训练方法流程图三,本实施例在实施例一所述的方法基础上,对如何确定最终的预测风速误差值进行进一步限定。如图5所示,该风速误差模型的训练方法包括:
S410,获取预测风速值,并获取对应的实际风速值。
S420,计算实际风速值与预测风速值之间的实际风速误差。
上述步骤S410~S420的内容与步骤S110~S120的内容相同。
S430,以预测风速值及其对应的实际风速误差作为训练样本,采用K近邻算法,将被选择出的K个实际风速误差值的平均值作为风速误差模型预测的预测风速误差值,建立风速误差模型。
具体地,风速误差模型在确定最终K值后,还需根据该K值计算得到最终的预测风速误差值,并将该预测风速误差值作为模型的输出数据,针对通过上述方法已经选择出的K个实际风速误差值,可对该K个实际风速误差值求平均值,将该平均值作为风速误差模型预测的预测风速误差值。
进一步地,图6为本发明实施例提供的基于K近邻算法的风速误差模型的训练方法流程图四,如图6所示,在执行完步骤S410和步骤S420之后,还可执行如下步骤:
S510,以预测风速值及其对应的实际风速误差作为训练样本,采用K近邻算法将被选择出的K个实际风速误差值,按其对应的预测风速值与当前输入值的距离进行加权求和,并将和值作为风速误差模型预测的预测风速误差值,建立风速误差模型。
具体地,针对通过上述方法已经选择出的K个实际风速误差值,还可对其进行加权求和以确定最终的预测风速误差值,具体权重可按照被选出的K个实际风速误差值对应的预测风速值与当前输入的预测风速值的距离具体确定,例如,当该距离越近时,设置其权重越大,而该距离越远时,则设置其权重越小,从而对K个实际风速误差值进行加权求和,进一步提高风速误差模型预测风速误差的准确性。
本发明实施例提供的基于K近邻算法的风速误差模型的训练方法,通过输入预测风速值和实际风速值,计算得到实际风速误差,并以预测风速值和实际风速误差作为训练样本,采用K近邻算法建立风速误差模型,并进一步对确定最终的预测风速误差值进行限定,从而显著提高了风速误差模型预测风速误差的准确性。
实施例四
图7为本发明实施例提供的风速订正方法流程图,该风速订正方法可作为补充方法,在执行以上各实施例所述的基于K近邻算法的风速误差模型的训练方法过程中实施。如图7所示,该预测风速订正方法,包括:
S610,获取预测风速值。
具体地,首先获取预测风速值,该预测风速值的获取可采用中尺度天气预报模式,如实施例一中已提及,包括但不限于以全球大尺度气象预报数据为中尺度天气预报模式WRF的初始场和边界条件;然后,采集待测风电场地理信息作为WRF模式下垫面信息,例如海陆分布、地形起伏和地表粗糙度、植被、土壤湿度、雪被面积等信息,从而建立WRF模式;最后,通过WRF模式获得初始预报数据,该初始预报数据包括但不限于预测风速值,例如还可包括该风电场范围内的温度、风向等数据。上述数据的采样周期可设置为15分钟。
S620,将预测风速值经预置的基于K近邻算法的风速误差模型进行预测计算,得到相应的预测风速误差。
具体地,以通过WRF模式获取的预测风速值为输入,经过上述基于K近邻算法的风速误差模型进行计算,输出预测风速误差。
S630,利用预测风速误差对预测风速值进行订正。
根据上述基于K近邻算法的风速误差模型输出的预测风速误差值,对预测风速值进行修正。例如,以上述基于K近邻算法的风速误差模型中,预测风速误差为实际风速值减去预测风速值的差值为例,可将预测风速值与其对应的预测风速误差的和值作为修正后的预测风速结果,以使得该结果更接近于实际风速值。
在实际应用场景中,如图8所示,为本发明实施例提供的风速订正方法逻辑示意图,首先,通过WRF模式获得预测风速值pwi;然后以预测风速值为输入,经过风速误差模型预测,输出风速预测误差值,设该风速预测误差值为Δw;最后,计算预测风速值订正结果ywi,ywi=pwi+Δw。
在实际应用场景中,如图9所示,为本发明实施例提供的风速订正效果图,以新疆地区某风电场为例,应用本发明实施例提供的方案订正未来10日的WRF模式预测风速值,得到的预测订正结果如图9所示,可见,本发明提供的实施例能够有效减小预测风速误差。
本发明的实施例提供的风速订正方法,通过将预测风速值输入预置的风速误差模型,得到预测风速误差,进而利用预测风速误差对风速预测值进行订正,方案简单高效,且显著提高了风速预测的准确性。
实施例五
图10为本发明实施例提供的基于K近邻算法的风速误差模型的训练装置结构示意图一,如图10所示,该装置可用于执行实施例一中所示的方法步骤,包括:
第一数据获取模块111,用于获取预测风速值,并获取对应的实际风速值;
误差计算模块112,用于计算实际风速值与预测风速值之间的实际风速误差;
模型构建模块113,用于以预测风速值及其对应的实际风速误差作为训练样本,采用K近邻算法建立风速误差模型。
进一步地,图11为本发明实施例提供的基于K近邻算法的风速误差模型的训练装置结构示意图二,该装置可用于执行实施例二中所示的方法步骤,如图11所示,上述模型构建模块113中,还可包括:
K值选择单元1131,用于通过交叉验证方法,选择K值。
进一步地,上述K值选择单元1131具体可用于执行如下步骤:
步骤一:设置初始K值;
步骤二:将训练样本分为训练集和验证集,针对验证集中每个第一预测风速值,遍历训练集中的每个第二预测风速值,选择K个与该第一预测风速值距离最相邻的第二预测风速值,并将与K个第二预测风速值相应的实际风速误差的平均值作为该第一预测风速值的均值误差;
步骤三:计算验证集对应的所有均值误差和均值误差的均方根;
步骤四:多次不重复的将训练样本分为训练集和验证集,并执行步骤二至步骤三,将得到多个均值误差的均方根的平均值作为当前K值的误差;
依次改变K值的大小,并针对每个K值执行步骤二至步骤四,并将得到的所有K值的误差中的最小值对应的K值作为风速误差模型中的最终K值。
进一步地,图12为本发明实施例提供的基于K近邻算法的风速误差模型的训练装置结构示意图三,该装置可用于执行实施例三中所示的方法步骤,如图12所示,上述模型构建模块113中,还可包括:
第一结果选择单元1132,用于将被选择出的K个实际风速误差值的平均值作为风速误差模型预测的预测风速误差值。
进一步地,图13为本发明实施例提供的基于K近邻算法的风速误差模型的训练装置结构示意图四,如图13所示,上述模型构建模块113中,还可包括:
第二结果选择单元1133,用于将被选择出的K个实际风速误差值,按其对应的预测风速值与当前输入值的距离进行加权求和,并将和值作为风速误差模型预测的预测风速误差值。
本发明的实施例提供的基于K近邻算法的风速误差模型的训练装置,通过输入预测风速值和实际风速值,计算得到实际风速误差,并以预测风速值和实际风速误差作为训练样本,采用K近邻算法建立风速误差模型,从而显著提高了预测风速误差值的准确率。
实施例六
图14为本发明实施例提供的风速订正装置结构示意图,如图14所示,该装置可内置在上述基于K近邻算法的风速误差模型的训练装置中,可用于执行上述实施例四中所示的方法步骤,包括:
第一数据获取模块111,用于获取预测风速值;
风速误差预测模块114,用于将预测风速值经预置的基于K近邻算法的风速误差模型进行预测计算,得到相应的预测风速误差;
风速订正模块115,用于利用预测风速误差对预测风速值进行订正。
上述预置的风速误差模型为经风速误差模型的训练装置训练得到的风速误差模型。
本发明的实施例提供的风速订正装置,通过将预测风速值输入预置的风速误差模型,得到预测风速误差,进而利用预测风速误差对风速预测值进行订正,方案简单高效,且显著提高了风速预测的准确性。
本发明实施例还提供了一种风力发电机组,包括:设置有上述任一种基于K近邻算法的风速误差模型的训练装置。
本领域普通技术人员可以理解:实现上述各方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成。前述的程序可以存储于一计算机可读取存储介质中。该程序在执行时,执行包括上述各方法实施例的步骤;而前述的存储介质包括:ROM、RAM、磁碟或者光盘等各种可以存储程序代码的介质。
最后应说明的是:以上各实施例仅用以说明本申请的技术方案,而非对其限制;尽管参照前述各实施例对本申请进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本申请各实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!