井漏溢流模型的训练方法、井漏溢流的预测方法及装置与流程
本发明涉及石油勘探开发,特别涉及一种井漏溢流模型的训练方法、井漏溢流的预测方法及装置。
背景技术:
1、在石油勘探开发中各项施工不可能绝对安全,风险总是客观存在的。在钻井复杂事故预警方面,国内外均从两个维度进行了研究,一个是井下预警研究,一个是地面预警研究。井下预警研究,国外注重对高精度流量计和井下随钻测量工具的研制和使用,并且此类工具己经在国内外现场得到了商业化应用;国内对这些工具进行了研制,得到了较大的发展,但其在耐高温高压、数据传输等方面仍落后于国外。除此之外,井下测量工具和高精度流量计的研制成本较高,现场应用较少。地面预警研究方面,主要是依据综合录井公司提供的数据进行预警研究。在处理此方面的实时数据时,国外注重将阈值法与贝叶斯模型等方法相结合,而国内现场主要使用的是阈值法,对人工神经网络和贝叶斯模型的研究目前还处于理论与试验阶段。阈值法虽然简单,不用选取样本,但发现复杂事故的及时性和准确性过于依赖现场工程师的专业素质和经验。若设定的阈值与实际数据的变化值相差太大时,无法及时发现井漏溢流等复杂事故;若设定的阈值与实际数据的变化值相差过小时,井漏溢流预警的准确性将大大降低,故具有很强的主观性;人工智能方法在溢流检测方面的研究越来越多,已经成为行业研发的热点之一。
技术实现思路
1、鉴于上述问题,提出了本发明以便提供一种克服上述问题或者至少部分地解决上述问题的一种井漏溢流模型的训练方法、井漏溢流的预测方法及装置。
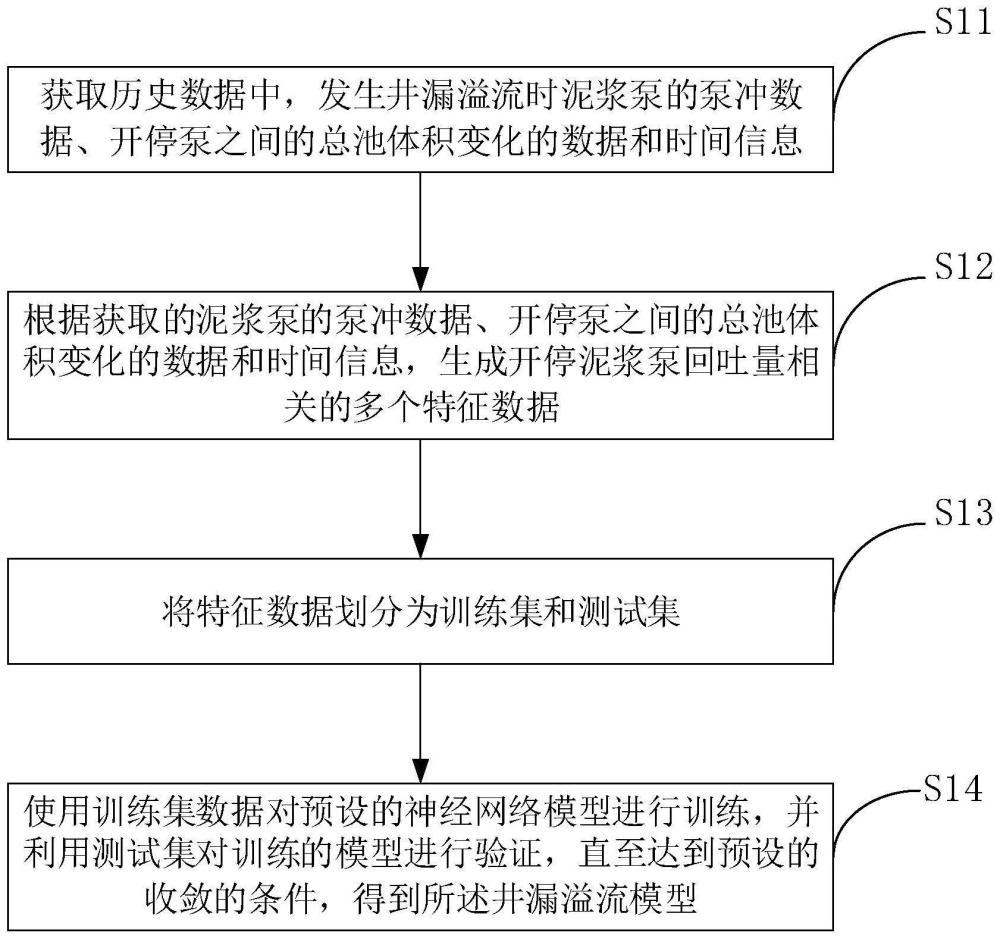
2、第一方面,本发明实施例提供一种井漏溢流模型的训练方法,包括:
3、获取历史数据中,发生井漏溢流时泥浆泵的泵冲数据、开停泵之间的总池体积变化的数据和时间信息;
4、根据获取的泥浆泵的泵冲数据、开停泵之间的总池体积变化的数据和时间信息,生成开停泥浆泵回吐量相关的多个特征数据;
5、将所述特征数据划分为训练集和测试集;
6、使用所述训练集数据对预设的神经网络模型进行训练,并利用测试集对训练的模型进行验证,直至达到预设的收敛的条件,得到所述井漏溢流模型。
7、在一个实施例中,开停泥浆泵回吐量相关的多个特征数据,包括下述任一项或多项特征向量数据:
8、开停泵状态、开停泵前时间、开停泵后时间、开停泵前总池体积变化率、开停泵吞吐量、开停泵后总池体积变化率、与上次开停泵吞吐量的差值、与上次开停泵后总池体积变化率的比值、与之前预设次数开停泵吞吐量均值的差值、与之前预设次数开停泵后总池体积变化率比值的均值。
9、在一个实施例中,所述开停泵状态数据,通过所述泵冲数据确定;
10、所述开停泵前时间为开停泵前获取数据的时间;
11、所述开停泵后时间为开停泵后获取数据的时间。
12、在一个实施例中,所述开停泵前总池体积变化率,通过下述方式得到:对通过对开停泵前的总池体积进行线性拟合,将拟合的斜率作为开停泵总池变化率;
13、所述开停泵后总池体积变化率,通过下述方式得到:通过对开停泵后预设时间段内的总池体积进行线性拟合,获取拟合的斜率作为开停泵后总池体积变化率。
14、在一个实施例中,所述开停泵吞吐量,通过下述方式得到:使用开泵后总池体积的最小值,停泵后总池体积的最大值,分别减去开停泵时的总池体积;
15、所述与上次开停泵吞吐量的差值,通过下述方式得到:将本次开停泵吞吐量减去上次开停泵吞吐量,得到所述与上次开停泵吞吐量的差值;
16、所述与上次开停泵后总池体积变化率的比值,通过下述方式得到:计算本次开停泵后总池体积变化率与上次开停泵后总池体积变化率之间的比值;
17、所述与之前预设次数开停泵吞吐量均值的差值,通过下述方式得到:计算本次开停泵吞吐量与前预设次数的开停泵吞吐量的均值的差值;
18、所述与之前预设次数开停泵后总池体积变化率比值的均值,通过下述方式得到:计算本次开停泵后总池体积变化率与之前预设次数次开停泵后总池体积变化率的均值之间的比值得到。
19、在一个实施例中,获取泥浆泵的泵冲数据、开停泵之间的总池体积变化的数据和时间信息之后,还包括:
20、对获取到的数据进行下述操作:格式转换、空值线性插补和对刺峰进行处理。
21、在一个实施例中,对刺峰进行处理,包括:
22、遍历获取到的数据,当遇到局部极大值点时,分别找到所述局部极大值点之前预设时间内的数据的第一最小值,以及之后预设时间内的数据的第二最小值;若第一最小值与所述局部极大值点的差值,以及第二最小值与所述局部极大值点的差值均大于预设的阈值时,确定从所述第一最小值到第二最小值之间的数据为刺峰;以及
23、当遇到局部极小值点时,分别找到所述局部极小值点之前预设时间内的数据的第一最大值,以及之后预设时间内的数据的第二最大值;若第一最大值与所述局部极小值点的差值,以及第二最大值与所述局部极小值点的差值均大于预设的阈值时,确定从所述第一最大值到第二最大值之间的数据为刺峰;
24、使用线性插补的方法修改所述刺峰的数据。
25、在一个实施例中,使用所述训练集数据对预设的神经网络模型进行训练,并利用测试集对训练的模型进行验证,直至达到预设的收敛的条件,包括:
26、在将所述训练集数据输入至预设的神经网络模型后,使用误差反向传播的方式,对所述神经网络模型的参数值计算损失函数的梯度,并根据所述梯度更新所述参数值以使损失函数收敛,直至达到预设的收敛条件。
27、在一个实施例中,所述损失函数为交叉熵损失函数。
28、第二方面,本发明实施例提供一种井漏溢流的预测方法,包括:
29、获取当前泥浆泵的泵冲数据、开停泵之间的总池体积变化的数据和时间信息;
30、根据获取到的当前的泥浆泵的泵冲数据、开停泵之间的总池体积变化的数据和时间信息,生成开停泥浆泵回吐量相关的多个特征数据;
31、将生成开停泥浆泵回吐量相关的多个特征数据输入至井漏溢流模型中,获取所述井漏溢流模型输出的当前发生井漏溢流事件的概率;
32、所述井漏溢流模型是通过如前述的井漏溢流模型的训练方法得到的。
33、在一个实施例中,井漏溢流的预测方法周期性执行,所述获取所述井漏溢流模型输出的当前发生井漏溢流事件的概率的步骤之后,还包括:
34、将当前发生井漏溢流事件的概率,与预设的阈值相比较;
35、若获取到发生井漏溢流事件的概率大于预设的阈值,且连续若干周期得到的发生井漏溢流事件概率均大于预设的阈值,则判断当前发生了井漏溢流事件。
36、第三方面,本发明实施例提供一种井漏溢流模型的训练装置,包括:
37、第一数据获取模块,用于获取历史数据中,发生井漏溢流时泥浆泵的泵冲数据、开停泵之间的总池体积变化的数据和时间信息;
38、第一特征提取模块,用于根据获取的泥浆泵的泵冲数据、开停泵之间的总池体积变化的数据和时间信息,生成开停泥浆泵回吐量相关的多个特征数据;
39、训练模块,用于将所述特征数据划分为训练集和测试集;使用所述训练集数据分批次对预设的神经网络模型进行训练,并利用测试集对训练的模型进行验证,直至达到预设的收敛的条件,得到所述井漏溢流模型。
40、第四方面,本发明实施例提供一种井漏溢流的预测装置,包括:
41、第二数据获取模块,用于获取当前泥浆泵的泵冲数据、开停泵之间的总池体积变化的数据和时间信息;
42、第二特征提取模块,用于根据获取到的当前的泥浆泵的泵冲数据、开停泵之间的总池体积变化的数据和时间信息,生成开停泥浆泵回吐量相关的多个特征数据;
43、预测模块,用于将生成开停泥浆泵回吐量相关的多个特征数据输入至井漏溢流模型中,获取所述井漏溢流模型输出的发生井漏溢流事件的概率;
44、所述井漏溢流模型是通过如前述井漏溢流模型的训练方法得到的。
45、第五方面,本发明实施例提供一种计算设备,包括:存储器、处理器及存储于存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如前述的井漏溢流模型的训练方法,或实现如前述的井漏溢流的预测方法。
46、第六方面,本发明实施例提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如前述的井漏溢流模型的训练方法,或实现如前述的井漏溢流的预测方法。
47、本发明实施例提供的上述技术方案的有益效果至少包括:
48、本发明实施例提供的上述井漏溢流的预测方法、井漏溢流的预测方法及装置,依据钻井作业现场泥浆泵吞吐量相关数据的采集和特征提取,创建特征数据,然后基于神经网络模型进行机器学习,实现对井漏溢流预警研判,提高井漏溢流事故判断的准确率。通过对井场复杂事故的精准预警研判,其成果可以用于钻井过程期间的参数与工具优化等多个重要环节,为钻井作业减少复杂事故发生率、提升钻井速度、优化钻井效率、节约作业成本提供重要基础数据支撑。
49、本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
50、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
- 还没有人留言评论。精彩留言会获得点赞!