一种剔除校正集异常样本的方法与流程
本发明主要用于油品性质快速检测领域,具体为一种基于近红外光谱的油品性质检测前剔除校正集异常样本的方法。
背景技术:
在汽油性质快速检测过程中,业界广泛采用基于近红外光谱的建模预测技术。目前,存在两类最常用的建模方法,一是全局建模,二是局部建模。全局建模方法虽具有较好的通用性,但其对校正集样本分布均匀性要求严格,且模型的预测精度普遍不高;局部建模方法选择校正集中相似样本建模,预测更准。特别是在计算机速度日益提升的情况下,局部建模近年来发展很快。
然而,在校正集中可能会出现两类异常样本,一类是化验值与预测值存在显著性差异的校正样本,这可能是由化验值测定误差较大、光谱测量误差较大或化验值录入错误等原因导致的,这类样本不管是全局建模还是局部建模在建模前必须剔除;另一类是高杠杆值样本,与校正集中其他样本相比,含有极端组成,远离模型整体样本的平均值,这类样本显然对全局建模无益,因为破坏了样本分布的均匀性,但对局部建模不但无害,反而有利于丰富校正集,提升后续类似待测样本的预测精度。因此,准确识别并剔除异常样本对提高模型预测精度具有重要的意义。
技术实现要素:
为了准确识别并剔除校正集中的异常样本,提高油品性质的模型检测精度,本发明提出了一种剔除校正集异常样本的方法。该方法首先利用局部建模的方法将留一交叉验证预测值超出再现性指标的样本列为可疑异常样本,然后利用主成分分析(PCA)坐标图以及性质间的相关性分析,最终确定异常样本;其中:主成分分析坐标图用于判断可疑异常样本是否是由于建模样本不足造成:若可疑异常样本分布在坐标图的边缘,则认为是建模样本不足造成,将其暂列为正常样本;若可疑异常样本分布在坐标图密集区,则利用性质间的相关性分析确定其是否为异常样本。
该方法具体包括以下步骤:
(1)获取汽油初始校正集样本的近红外光谱和性质化验值;
(2)对校正集样本的光谱进行常规预处理;
(3)采用留一交叉验证法对校正集中样本逐一进行偏最小二乘(PLS)建模预测,分别得到预测值,以及预测值与化验值之间的偏差;
(4)筛选出预测偏差超出再现性指标的校正样本,将其列为可疑异常样本;
(5)从校正集中筛选出可疑异常样本,剩下的样本继续作为下一轮建模的校正集;
(6)继续重复步骤(3)~(5),直至预测偏差全部在相应的再现性指标范围内;
(7)将可疑异常样本逐一和剩余校正集样本进行主成分分析,绘制PCA坐标图;
(8)观察PCA坐标图,如果可疑异常样本分布在坐标图的边缘,极有可能是建模样本不足造成的,将该可疑异常样本视为正常样本;如果可疑异常样本分布在坐标图密集区,则利用性质之间的相关性分析确定其是否为异常样本。
根据国家油品性质检测相关条文规定,对于汽油性质的再现性指标,研究法辛烷值(RON)的再现性为0.6,马达法辛烷值的再现性为0.8,密度(20℃)的再现性为5.0kg/m3,饱和蒸气压(RVP)的再现性为5.0kPa,等等。
对于特定汽油,各个性质之间的相关性情况一般为:密度和RON、50%蒸发温度之间具有良好的正相关性,密度和RVP间具有负相关性,这为异常样本的进一步分析提供了参考依据。
有益效果:
本发明提出了一种剔除校正集异常样本的方法,首先利用局部建模的方法,对校正集中的样本逐一进行留一交叉验证预测,将预测值超出再现性指标的样本列为可疑异常样本,然后利用主成分分析坐标图以及性质间的相关性分析,最终确定异常样本。该方法能有效剔除校正集中的异常样本,有助于提高模型预测精度。
附图说明
图1校正集异常样本剔除方法的实施流程图
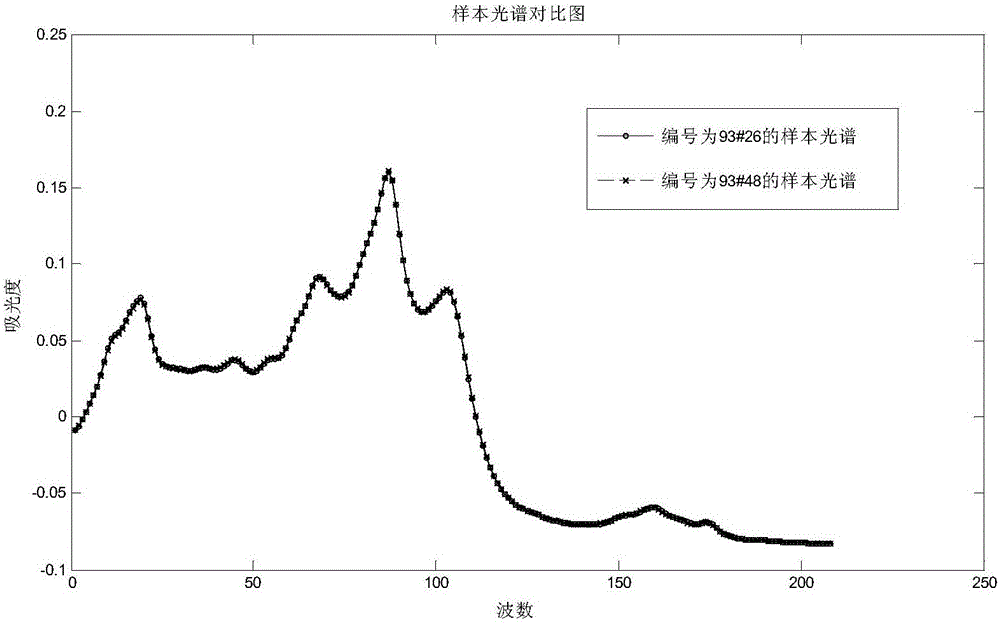
图2编号为93#_26与编号为93#_48样本的光谱对比图
图3编号为93#_132的可疑异常样本与校正集样本的PCA坐标图
具体实施过程
下面结合附图和实施案例对本发明作进一步的说明。
本发明以某93#汽油为例,介绍汽油校正集异常样本的剔除方法。本案例是针对汽油RON的测试,选择2014年10月至2016年9月的共计136个样本作为初始校正集,编号分别为93#-1~93#-136。采用留一交叉验证预测法对校正集中的样本逐一进行局部建模预测,选择的建模谱段为4000~4800cm-1,在三维主成分分析坐标图中,利用长宽高比为3:2:1的长方体(以第一主成分为横轴3,第二主成分为纵轴2,第三主成分为竖轴1,绘制三维主成分分析图)选择50±5个校正样本作为相似样本建立模型。初始校正集中样本的建模预测结果如表1所示。
表1初始校正集中样本留一交叉预测结果
由于汽油RON的再现性为0.6,则筛选出预测偏差绝对值大于0.6的样本,由表1可知共有9个样本的预测偏差超出再现性指标,分别为93#_1、93#_26、93#_38、93#_47、93#_55、93#_64、93#_84、93#_123、93#_132,将其列为可疑异常样本,继续对剩余校正集样本再次进行留一交叉验证,又筛选出1个样本93#_45,将其放入可疑异常样本集。表2所示为可疑异常样本集的样本预测情况。
表2可疑异常样本集的样本预测情况
筛选出可疑异常样本后,校正集中剩余的126个样本为正常样本。下面利用PCA坐标图以及各性质间的相关性,对表2中给出的可疑异常样本进行分析。以编号为93#_26的可疑异常样本为例,对校正集中剩余126个样本和93#_26样本进行PCA分析:
首先,发现编号为93#_26的样本处于PCA坐标图的样本分布密集区域,不存在相似样本不足的问题;接着基于汽油各个性质之间的相关性,发现其与编号为93#_48的样本比较,二者光谱曲线基本重合,如图2所示。而且由表1可知,93#_26样本预测值为93.67,预测偏差为0.83;93#_48样本预测值为93.81,预测偏差为-0.01,预测情况较好。查看表3,根据50%蒸发温度和RON间的正相关性,93#_26样本的50%蒸发温度值比93#_48样本的50%蒸发温度值小,则93#_26样本的RON值理应比93#_48样本的RON值小,实际上却比93#_48样本的RON值更大。因此,认为93#_26样本的RON化验值存在正偏差,进一步的实验室化验也证实了上述分析,确定其为异常样本。
表3编号分别为93#_26和93#_48的样本性质表
采用上述相同方法分析,可以判定编号为93#_38、93#_45和93#_47的样本均为异常样本。
再以编号为93#_132的可疑异常样本为例,对这126个样本和编号为93#_132的样本进行PCA分析,并绘制三维坐标图,如图3所示。在图3中,编号为93#_132的样本分布在边缘,且其预测偏差高达-1.92,远超出0.6的再现性,极有可能存在相似样本不足的问题。因此,暂且将其视为正常样本,等待后续样本的补足。然而,如果采用常规的主成分分析结合马氏距离方法,该样本的马氏距离在规定范围外,则被视为异常样本,剔除后造成样本集中的样本越来越少,极值范围缩小,不利于样本库的完善,对后期建模造成不利影响。
可见,采用本发明提出的方法,能有效剔除校正集异常样本,为建立油品性质预测模型打下良好基础。
- 还没有人留言评论。精彩留言会获得点赞!