一种基于近红外光谱技术的玉米单倍体籽粒鉴别方法与流程
本发明属于计算机及光学技术应用领域,尤其涉及一种基于近红外光谱技术的玉米单倍体籽粒鉴别方法。
背景技术:
玉米单倍体籽粒鉴别是计算机和光谱应用的一个新的技术领域,由于玉米单倍体籽粒在种子培育过程中产生率极低,通常10%不到,人工筛选玉米单倍体籽粒比较耗时耗力。因此,应用近红外光谱技术和计算机技术目的在于利用模式鉴别的方法,来实现计算机辅助单倍体籽粒筛选功能,从而实现自动化选种,达到优化农业的作用。
基于近红外光谱技术的玉米单倍体鉴别技术,如采用漫透射方法获取籽粒光谱,可以获得非均匀分布的籽粒内部物质信息。但是,由于光谱成分复杂,漫透射机制还没有完善的理论解释,在实际应用中通过光谱来鉴别籽粒种子,还需要结合计算机模式识别算法来尽量提高单倍体种子的正确鉴别率。
计算机模式识别算法设计,一般从特征归一化预处理,特征降维去噪处理,以及特征分类三个方面进行考虑。centernormalization或standardnormalization是目前常用的特征归一化处理方法,然而该方法特征处理后特征之间依然存在较强相关性的缺点。
综上所述,提供合理的模式鉴别方法,可以提高单倍体籽粒光谱的鉴别性能,从而满足实际工作中的需要,为有效实现自动化玉米单倍体籽粒的筛选提供计算方法。
技术实现要素:
(一)要解决的技术问题
本发明提供了一种基于近红外光谱技术的玉米单倍体籽粒鉴别的方法,能够将玉米单倍体籽粒从杂合体籽粒中鉴别出来,同时确保较高的正确鉴别率和模型稳定性。
(二)技术方案
本发明是通过以下技术方案实现的:
一种基于近红外光谱技术的玉米单倍体籽粒鉴别方法,包括以下步骤:
获取光谱数据,并将光谱数据进行划分;
将划分后的光谱数据进行特征归一化;
将归一化后的光谱数据降低维数;
将降维后的光谱数据进行分类。
优选地,所述获取光谱数据,并将光谱数据进行划分的步骤中,采用漫反射或漫透射方式采集玉米单倍体和杂合体籽粒的光谱数据,以及获得对应的玉米单倍体和杂合体籽粒的标签数据。
优选地,所述获取光谱数据,并将光谱数据进行划分的步骤中,将光谱数据分成三个数据集:训练集,验证集和测试集;训练集用于训练模型,验证集用于调节模型参数,测试集用于测试模型性能。
优选地,所述将划分后的光谱数据进行特征归一化的步骤中,采用zero-phasecomponentsanalysis方法将光谱数据进行强度标准化,得到归一化后的光谱数据。
优选地,光谱数据进行特征归一化的计算公式为:
其中,x表示特征矩阵,
优选地,所述将归一化后的光谱数据降低维数的步骤中,采用偏最小二乘回归方法降低光谱数据的维数,得到得分矩阵xs及其变换矩阵st。
优选地,所述采用偏最小二乘回归方法降低光谱数据的维数包括:
其中,
优选地,所述对降维后的光谱数据进行特征分类的步骤包括:
将降维后的光谱数据输入神经网络,调节神经网络参数;
神经网络参数微调及性能评价;
保存神经网络参数。
优选地,所述将降维后的光谱数据输入神经网络,调节神经网络参数的步骤中,采用l2范数正则化反向传播神经网络对降维后的光谱数据进行分类,其代价函数的形式为:
其中,m表示样本数量,xi表示第i个样本,yi表示第i个样本的标签数据的真值,hθ(·)表示神经网络模型假说,λ表示惩罚参数,θ表示模型待学习参数。
优选地,反向神经网络模型学习参数θ采用随机方式初始化,其更新公式为:
其中,ε为学习速率参数,jb为代价函数。
(三)有益效果
与现有技术相比,本发明具有如下优点:
(1)本发明提出的基于近红外光谱技术的玉米单倍体籽粒鉴别方法,实现了单倍体籽粒的鉴别,从高维空间形象几何的角度去设计鉴别方法,有效地提高了模型的识别性能。
(2)本发明所采用的zero-phasecomponentsanalysis特征归一化方法,能够有效地去除光谱特征间的相关性,从而有效地增强光谱特征。
(3)本发明所采用的偏最小二乘回归实现数据特征维数的降低,能够更好地保留数据的弱特征分量,并且通过维数降低实现去除噪声和冗余信息,从而算法效率提高。
(4)本发明所采用的神经网络模型分类器,能够在fpga等嵌入式硬件系统中实现并行计算,从而可以提高模型的训练和预测速度,从保证鉴别运行效率。
附图说明
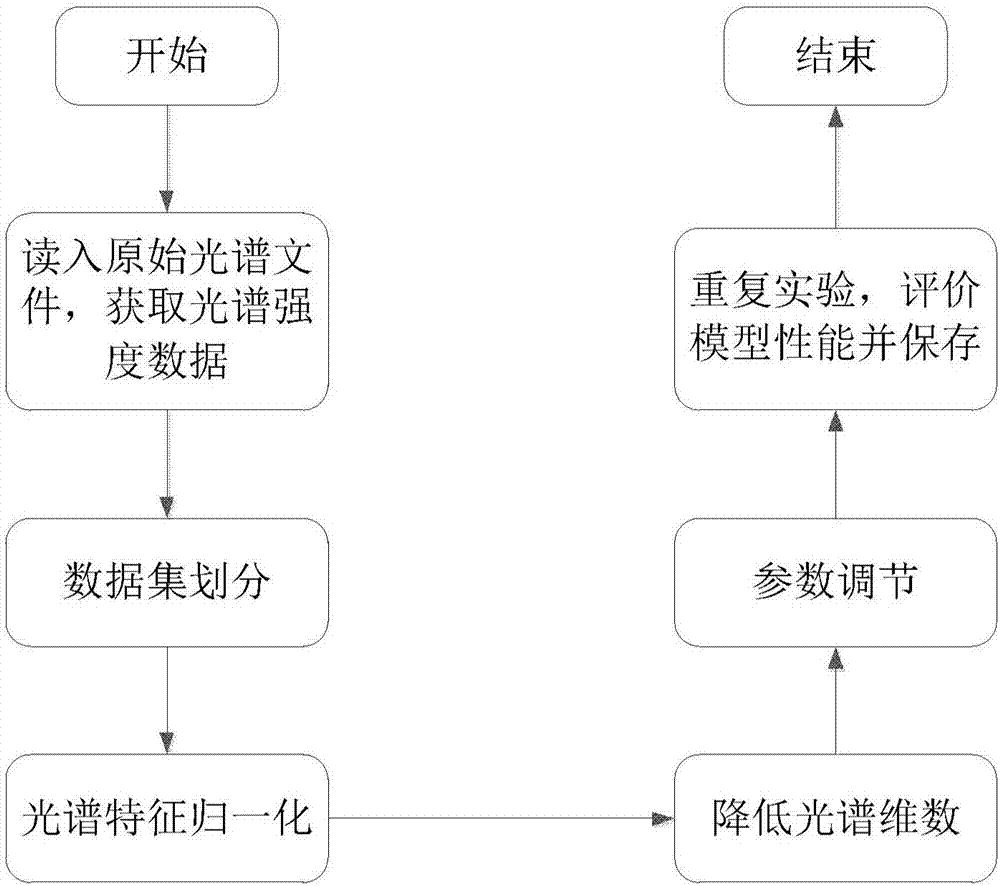
图1是本发明实施例提供的基于近红外光谱技术的玉米单倍体籽粒鉴别的方法流程图;
图2是本发明实施例提供的基于近红外光谱技术的玉米单倍体籽粒鉴别的方法流程总图;
图3是本发明实施例提供的惩罚参数调节对比图;
图4是本发明实施例提供的平均正确识别率与训练集尺寸关系图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明进一步详细说明。应当理解,此处所描述的仅是本发明一部分实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
图1和图2是本发明实施例提供的基于近红外光谱技术的玉米单倍体籽粒鉴别方法的方法流程图,为了便于说明,仅示出了与本发明实施例相关的部分,该鉴别方法主要由光谱特征的归一化,光谱特征维数降低和光谱特征分类组成。如图1和图2所示,该方法包括以下步骤:
步骤s1:获取光谱数据,并将光谱数据进行划分。
步骤s1包括:
子步骤s11,读入原始光谱文件,获取光谱数据,光谱数据包括光谱数据集和光谱标签数据集。
具体的,读入原始光谱文件,获取的光谱数据包括原始光谱强度数据、光谱的标签信息及光谱的尺寸信息,光谱的尺寸信息包括维度和条数,记为n和mt。
本实施例通过漫透射方式采集玉米单倍体和杂合体籽粒的近红外光谱数据集xt以及对应的玉米单倍体和杂合体的光谱标签数据集y。光谱数据集xt包括原始光谱强度数据,光谱尺寸信息等信息,光谱维度n为125维,光谱波长范围为900nm-1700nm之间,浮点数值表示。在光谱标签数据集y中,标签信息为单倍体光谱标记1,杂合体光谱标记0。
子步骤s12,光谱数据集划分。
光谱数据集划分,包括采用随机无放回的方式抽取光谱,生成1到mt随机数集r,将光谱数据和标签数据对应随机数集,按照比例将光谱数据集中的mt条光谱数据分成三个数据集:训练集,验证集和测试集。训练集是用来训练模型,验证集是用来调节参数,测试集是用来测试模型性能。
优选的,训练集,验证集和测试集的比例,可设置为2∶1∶2或3∶1∶1。
步骤s2:将划分后的光谱数据进行特征归一化。
光谱特征归一化,是将近红外光谱仪检测的光谱数据进行强度标准化,本实施例采用的检测仪器为micronir-1700近红外光谱仪。利用zero-phasecomponentanalysis(zca)能很好去除特征之间的相关性。
具体的,本实施例利用子步骤s12中所得的训练集进行zero-phasecomponentsanalysis(zca),获取其归一化矩阵,计算方法:
公式中,特征矩阵x表示训练集的原始光谱数据,大小为n×m,n表示单条光谱特征维数,m为训练样本数量。mean(x)表示训练集光谱的平均值,
以上利用训练集中的光谱数据,根据zero-phasecomponentsanalysis(zca)方法的计算得到了归一化矩阵z,z为
步骤s3:将归一化后的光谱数据降低维数。
光谱特征维数降低,是提取有效光谱特征信息。偏最小二乘回归方法降维去噪相比主成分分析法可以保留一些弱分量的特征,本实施例采用偏最小二乘回归方法对光谱数据进行降维。
具体的,本实施例利用步骤s2中所获得的归一化后的训练集数据和对应的标签数据,同时设定数据的维数k,优选的,k为集合{3,10,20}中值,结合偏最小二乘回归方法,计算形式有:
公式中,
步骤s4:对降维后的光谱数据进行特征分类。
步骤s4包括:
子步骤s41,神经网络分类器参数调节。
光谱特征分类,是将单倍体籽粒光谱与杂合体籽粒光谱识别区分,神经网络分类器可以提取特征中的隐藏特征,适用于一些特征复杂的情况。本实施例采用l2范数正则化反向传播神经网络(backpropagationneuralnetwork)方法,对步骤s3中获得的得分矩阵xs进行二分类,反向神经网络共有三层,输入层,隐藏层和输出层,输入层和隐藏层的神经元个数都为上述的维数k,输出层神经元个数为1或2。
具体的,将训练集数据特征(步骤s3所得得分矩阵xs),接入k-k-1结构的神经网络中。神经网络的代价函数为:
公式中,m表示训练集样本数量,xi表示单条第i个训练样本,yi表示第i个样本对应的光谱标签数据,hθ(·)为神经网络的模型假说,λ为惩罚参数,θ表示反向神经网络中学习参数集,θ采用随机方式初始化,其更新公式为:
公式中,ε为学习速率参数,jb为代价函数。
优选的,设定训练次数n=800次,λ可为集{1,10-1,10-2,10-3,10-4,10-5,10-6}中值,ε为0.05,通过验证集的50次平均准确率为依据得出λ的最佳值,同时根据固定的特征维数确定k大概范围。如图3所示为绘制的λ对验证集平均识别准确率的影响,本具体实施例中λ为10-4,同时确定k的范围在[3,10]之间。
子步骤s42,神经网络分类器微调及性能评价。
将惩罚参数固定,获取训练集和测试集,利用训练集训练得到的神经网络模型,利用测试集进行最终模型性能评估,确定最优隐藏层神经元数目k值,穷举所确定范围内特征维数,重复该流程n次,利用测试集准确率的分布情况来最终确定最优特征维数,同时获得最优模型性能评估,穷举3到10范围内k的值,优选的,重复50次获得测试集的平均准确率和其标准差作为模型性能评判依据。本具体实施例中,如表1所示为训练集平均准确率(averagetrainingaccuracy)、测试集的平均准确率(averagetestaccuracy)和标准差值(sdoftestaccuracy)随k值的变化关系,综合平均准确率和标准差值,本实施例中所得最佳k为6。同时,根据所得参数,我们可以进一步绘制出训练集样本规模对模型性能的影响,如图4所示为训练集尺寸与测试集平均准确率的关系曲线。
表1
子步骤s43,保存神经网络参数。
具体的,固定步骤s42中所得神经网络参数θ,惩罚参数λ以及最优低维空间维数k,重新获取训练集和测试集,利用训练集训练模型,根据上述所确定的参数进行模型训练,保存所得的训练集均值,特征归一化矩阵,偏最小二乘变换矩阵以及神经网络网络参数,同时生成模型参数文件。
本发明实施例通过采用统一的计算体结构,获取近红外光谱不同波长点数据及其维数信息,通过对光谱特征的归一化,降维,再结合神经网络实现了一种玉米单倍体籽粒鉴别的方法,利用从高维仿生信息学几何的角度去设计识别算法,有效地提高了模型识别率和稳定性。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到本发明可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是最佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,以计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台终端设备(可以是个人计算机,服务器,或者嵌入式设备等)执行本发明各个实施例所述的方法。本实施例测试平台:cpu:pentium(r)dual-corecpue5800@3.20ghz;内存:4.00gb;系统windows732位操作系统;软件:matlabr2013a。
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!