一种基于阵列雷达的目标波达方向快速估计方法与流程
本发明属于米波雷达信号处理技术领域,特别涉及一种基于阵列雷达的目标波达方向快速估计方法,适用于实际工程应用。
背景技术:
米波雷达测角测高是信号处理领域的重要分支,雷达发射电磁波并接收来自其威力覆盖范围内的目标回波信号,然后从接收的回波信号中提取目标的位置和其他信息,以用于探测、定位以及目标识别;米波雷达因为其工作频段和波长较长的特点,具有良好的反隐身和反辐射导弹能力,但同时因为米波波束较宽,存在波束“打地”以及多径效应等问题,严重影响了米波雷达测角精度。
早期目标的波达方向估计主要采用数字波束形成(dbf)算法,而dbf算法的角度分辨率和天线的孔径成反比,为了达到较好的角度分辨率需要增大雷达天线的阵列孔径,这一点是难以实现的;对于米波雷达而言,在低仰角区域的直达波和多径反射波位于同一波束宽度内,不可分辨,会出现角度模糊;也就是说,采用dbf测角算法简单,运算速度快,能够测出目标方向,但是测角精度不够。
为了达到较高的测角精度,出现了一类子空间拟合算法:最大似然(ml)算法,最大似然(ml)算法在目标信噪比较低、快拍数较少的条件下,相比于其他算法能够达到更好的测角性能;但是ml算法需要进行空域的多维搜索,运算量较大,为了减少运算量,学者们对其进行了改进,最终形成了合成导向矢量(svml)算法,svml算法对直达角和反射角都进行搜索,虽然较好的解决了多径反射波和直达波在一个波束宽度瓣内dbf算法无法进行目标波达方向估计的问题,但却存在两个不足:第一,需要对直达角和反射角分别进行二维估计,计算量偏大,无法确保信号处理的实时性;第二,大量角度的搜索,增大了运算量,很难满足测角的实时性。
技术实现要素:
针对上述现有技术存在的不足,本发明的目的在于提出一种基于阵列雷达的目标波达方向快速估计方法,该种基于阵列雷达的目标波达方向快速估计方法是一种基于cuda架构的dbf与svml结合测向算法,能够根据目标回波信息和地形准确快速估计目标波达方向,进而能够提高米波雷达测角测高的速率和精度。
本发明的主要思路:本发明结合dbf算法与svml算法进行测角,主要是因为米波雷达波束较宽,在低仰角区域的直达波和多径反射波位于同一波束宽度内,不可分辨,虽然采用dbf算法会出现角度模糊,但是dbf测角算法比较简单,运算速度快,而svml算法的波瓣比dbf算法的波瓣更窄,角度分辨率更高;所以将dbf算法与svml算法结合进行测角能够优势互补,dbf算法主要负责粗测,svml算法负责精测,这样就缩小了搜索范围,加快了搜索进程,可以同时计算多个角度的似然值,一方面可以提高测角速率,另一方面,可以进一步减小搜索步进间隔以提高测角精度。
为达到上述技术目的,本发明采用如下技术方案予以实现。
一种基于阵列雷达的目标波达方向快速估计方法,包括以下步骤:
步骤1,确定阵列雷达,所述阵列雷达包含n个阵元;阵列雷达接收雷达模拟信号,并对该雷达模拟信号进行a/d采样和脉冲压缩处理,得到脉冲压缩回波数字信号数据矢量;
设定脉冲压缩回波数字信号数据矢量的来波方向θ,并得到θ方向上的合成导向矢量
步骤2,根据θ方向上的合成导向矢量,得到n个阵元的dbf权矢量;
步骤3,对脉冲压缩回波数字信号数据矢量进行dbf粗测,得到dbf粗测结果,所述dbf粗测结果为脉冲压缩回波数字信号数据矢量的来波方向θ的仰角位置;
步骤4,根据dbf粗测结果对脉冲压缩回波数字信号数据矢量进行svml精测,得到基于阵列雷达的目标波达方向。
本发明的有益效果:
第一,本发明方法实现了将dbf算法和svml算法相结合,使得svml方法搜索范围变小,减小了运算量,加快了运算速率。
第二,本发明在提高目标角度测量精度方面更有优势:一方面,增加dbf算法粗测,即首先采用dbf算法测出目标波达方向的大致范围,提高了测角速率;然后采用svml算法进行精测,从而减少角度搜索范围,提高测角速率,解决了低仰角测角模糊问题;另一方面,采用并行处理的实现方法进行角度测量,不仅加快了运算速率,提高信号处理速率,同时能够利用并行这一特点在同样时间内以更小步进对粗测范围进行搜索,提高测角测高的准确度。
附图说明
下面结合附图说明和具体实施方式对本发明作进一步详细说明。
图1为本发明的一种基于阵列雷达的目标波达方向快速估计方法流程图;
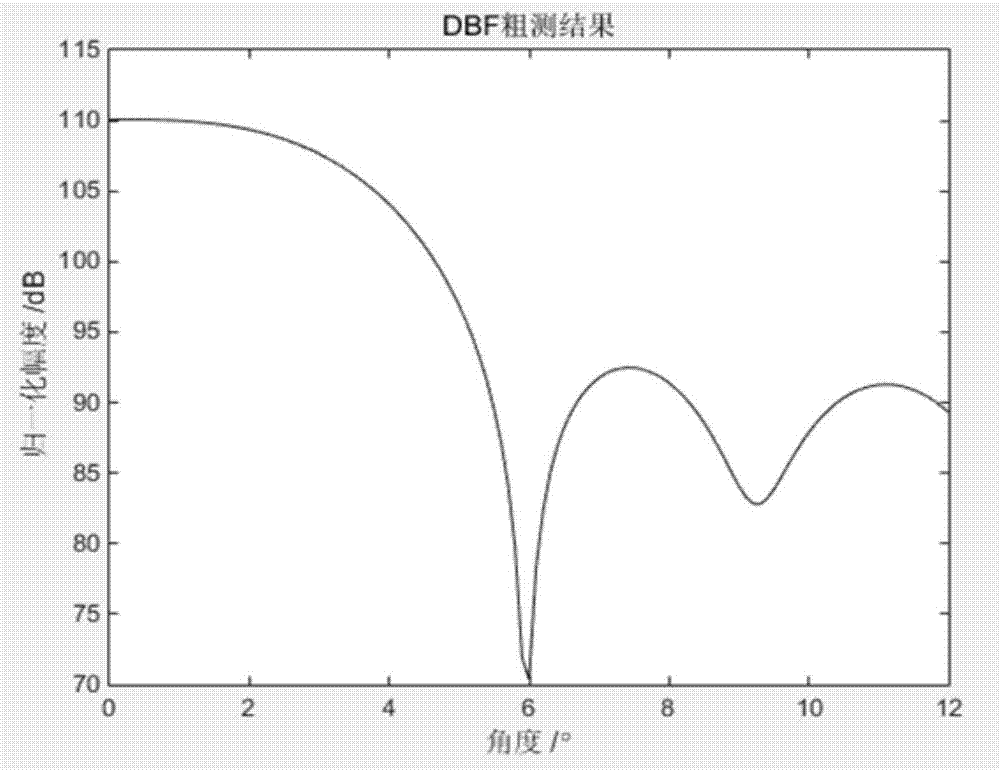
图2(a)为使用本发明方法得到的dbf粗测结果图;
图2(b)为使用本发明方法得到的svml精测结果图;
图2(c)为图2(b)的似然值转换成为单位db的svml谱图。
具体实施方式
参照图1,为本发明的一种基于阵列雷达的目标波达方向快速估计方法流程图;其中所述基于阵列雷达的目标波达方向快速估计方法,包括以下步骤:
步骤1,确定阵列雷达,所述阵列雷达包含n个阵元;阵列雷达接收雷达模拟信号,并对该雷达模拟信号进行a/d采样和脉冲压缩处理,得到脉冲压缩回波数字信号数据矢量。
步骤1的子步骤为:
1a)确定阵列雷达,阵列雷达为米博雷达;所述阵列雷达包含n个阵元;阵列雷达的检测范围内存在目标,且阵列雷达发射电磁波并接收雷达模拟信号,然后对接收到的雷达模拟信号进行a/d采样和脉冲压缩处理,得到脉冲压缩回波数字信号数据矢量;将所述脉冲压缩回波数字信号数据矢量记为x(t),x(t)=[x1(t),x2(t),...,xn(t),...,xn(t)],xn(t)表示第n个阵元的脉冲压缩回波数字信号数据,t表示时间变量;x(t)为n×p维,n表示阵列雷达包含的阵元总个数,p表示阵列雷达发射的脉冲总个数,且n、p分别为大于0的正整数。
1b)假设脉冲压缩回波数字信号数据矢量x(t)的来波方向为θ,则θ方向上的合成导向矢量为
其中,κ表示阵列雷达发射的电磁波波数,κ=2π/λ,λ表示阵列雷达发射的电磁波波长,d表示阵列雷达中相邻阵元的间距,n为阵列雷达包含的阵元总个数,上标t表示转置操作,e表示指数函数,j表示虚数单位,sin表示正弦函数。
步骤2,为了降低阵列的副瓣电平,需要对θ方向上的合成导向矢量
其中,w=[w1,w2,...,wn,...,wn]t,n∈{1,2,…,n},wn表示第n个阵元的dbf权矢量,上标t表示转置操作,wwin表示长度为n的窗函数,上标t表示转置操作。
步骤3,对脉冲压缩回波数字信号数据矢量x(t)进行dbf粗测,得到dbf粗测结果,所述dbf粗测结果为脉冲压缩回波数字信号数据矢量x(t)的来波方向θ的仰角位置。
对脉冲压缩回波数字信号数据矢量x(t)进行dbf粗测,其粗测过程为:
3.1初始化:假设脉冲压缩回波数字信号数据矢量x(t)的来波方向θ估计需要搜索的空间仰角范围为
其中,
3.2计算第
其中,
3.3令
3.4得到dbf粗测结果:在ang_num_cu个测角的输出模值
所述脉冲压缩回波数字信号数据矢量x(t)的来波方向θ的仰角位置
步骤4,对根据dbf粗测结果对脉冲压缩回波数字信号数据矢量进行svml精测,得到基于阵列雷达的目标波达方向。
(4a)确定脉冲压缩回波数字信号数据矢量x(t)的来波方向θ的精测范围,其过程为:如果
为了便于说明,令脉冲压缩回波数字信号数据矢量x(t)的来波方向θ的精测范围为[α1,α2],如果
初始化:令θt表示第t个测角,t∈{1,2,…,ang_num},t的初始值为1,第1个测角θ1为α1,第ang_num个测角θang_num为α2,第t个测角θt为α1+(t-1)△η,α2=α1+(ang_num-1)△η,ang_num表示脉冲压缩回波数字信号数据矢量x(t)的来波方向θ的精测范围[α1,α2]内包含的测角总个数,ang_num为大于0的正整数。
(4b)计算第t个测角θt的直达波和第t个测角θt反射波的波程差△rt,以及第t个测角θt的反射波的角度θtr,其表达式分别为:
△rt=rt1+rt2-rd
其中,第t个测角θt的反射路径包括两段,分别为第t个测角θt经反射点反射前的入射段和第t个测角θt经反射点反射后的反射段,并分别记为第t个测角θt反射路径的入射段和第t个测角θt反射路径的反射段,rt1表示第t个测角θt反射路径的入射段,rt2表示第t个测角θt的反射路径的反射段,rd表示目标和阵列雷达的直线距离,上标-1表示求逆操作,cos表示求余弦操作。
然后计算第t个测角θt的合成导向矢量a(θt),其表达式为:
其中,ad(θt)表示第t个测角θt的直达波导向矢量,ar(θtr)表示第t个测角θt的反射波导向矢量,ρ表示设定的反射系数,常取-0.95;λ表示阵列雷达发射的电磁波波长,上标j表示虚数单位,e表示指数函数,下标r表示反射。
(4c)利用第t个测角θt的合成导向矢量a(θt),构造第t个测角θt的正交投影矩阵p(θt):
p(θt)=a(θt)[ah(θt)a(θt)](-1)ah(θt)
其中,a(θt)表示第t个测角θt的合成导向矢量,上标h表示共轭转置操作。
(4d)令t分别取1至ang_num,并行执行(4b)和(4c),进而同时第1个测角θ1的正交投影矩阵p(θ1)至第ang_num个测角θang_num的正交投影矩阵p(θang_num),记为ang_num个测角的正交投影矩阵p(θ),p(θ)=[p(θ1),p(θ2),...,p(θt),...,p(θang_num)];其中,第1个测角θ1的合成导向矢量a(θ1)至第ang_num个测角θang_num的合成导向矢量a(θang_num)的计算过程为并行计算。
(4e)根据ang_num个测角的正交投影矩阵p(θ),构造关于脉冲压缩回波数字信号数据矢量x(t)的来波方向θ的最大似然函数q(θ),其表达式为:
q(θ)=tr{p(θ)r}
其中,tr{-}表示求迹操作,r表示脉冲压缩回波数字信号数据矢量x(t)的自相关矩阵,θ表示脉冲压缩回波数字信号数据矢量x(t)的来波方向。
(4f)对关于脉冲压缩回波数字信号数据矢量x(t)的来波方向θ的最大似然函数q(θ)进行谱峰搜索,计算得到脉冲压缩回波数字信号数据矢量x(t)的来波方向θ的估计值
其中,
下面结合仿真实验对本发明效果做进一步的验证说明。
1.仿真条件
本实验的操作系统为windows7sp1,显卡是计算能力为2.0的nvidiateslac2050下进行的,该显卡支持双精度浮点运算。通过利用vs2013+cuda7.5作为仿真平台,实现基于阵列雷达的目标波达方向估计;本实验中目标真实角度为1.4°。
2.仿真内容
首先,进行dbf粗测,得到图2(a)的dbf粗测结果图;然后,利用dbf粗测结果,进行svml精测,得到图2(b)的svml谱图;将图2(b)的似然值转换为db为单位,得到图2(c)的结果图。
3.附图说明
图2(a)为使用本发明方法得到的dbf粗测结果图;其中,横坐标表示直达波入射角度,纵坐标表示归一化幅度值,从图2(a)中可看出,当目标处在低仰角区时,dbf波瓣较宽,无法准确测出目标仰角。
图2(b)是在dbf粗测结果上进行svml精测,得到的svml谱图,图2(b)为使用本发明方法得到的svml精测结果图;其中,横坐标表示直达波入射角度,纵坐标表示svml似然函数值,由图2(b)中可看出,在低仰角区时,svml波瓣较窄,依然保持很好的测角精度,可以较为准确的得到目标仰角。
图2(c)为图2(b)的似然值转换成为单位db的svml谱图,其中,横坐标表示直达波入射角度,纵坐标为以db为单位的svml似然函数值。
通过图2(c)与图2(a)进行对比,可以直观的看出低仰角区,svml算法相对dbf算法而言测角精度更高。
4.表格说明
表1为本发明实例中不同测高算法在不同平台上测角时间统计,在本发明实例中,设定低仰角区目标真实仰角为1.4°。
表1为本发明实例中不同测高算法在cpu与gpu所运行时间对比(单位:ms)
从表格数据可以看出,gpu比cpu的数据运算效率更高。要说明的是,表格中dbf粗测一栏括号内数字表示总时间0.242ms内有0.096ms用于gpu和cpu间数据传输,也就是说,gpu有很大一部分时间是用在数据传输上。所以,在gpu运算过程中,应当尽量减数据传输时间。
表1为本发明实例中不同测高算法在cpu与gpu所运行时间对比(单位:ms),其中,最后一列为gpu相对于cpu的加速比,从表格中可以看出,svml算法加速比达到292.444倍,总的加速比达到39.748倍,证明了本方法的有效性。
- 还没有人留言评论。精彩留言会获得点赞!