一种基于天气雷达数据的强对流风力等级预测方法与流程
本发明涉及电力气象技术领域,尤其涉及一种预测强对流风力的方法。
背景技术:
雷达应用于气象行业至今已有半个多世纪的历史,新一代多普勒天气雷达为强对流等灾害性天气的监测、预报、预警等气象学难题提供了有效的途径。强对流天气是指出现短时强将水、雷雨大风、龙卷风、冰雹和飑线等现象的灾害性天气,它发生在对流云系或单体对流云块中,在气象上属于中小尺度天气系统。强对流天气的根源是空气强烈的垂直运动,在强对流天气下,输电线路极容易发生安全故障,尤其是发生线路风偏。由于强对流天气持续时间很短,常规的风速预报是整点预报,预报周期最短只能达到1小时,采用风速预报无法准确的反映出强对流天气下的风力情况,例如:10:10~10:50发生强对流天气,那么11:00时的常规风速预报仍很低,仅凭常规风预报无法判断是否已发生过强对流天气。
雷达回波特征是进行预报强对流天气的重要依据,例如强冰雹天气在雷达上表现为“高悬的强回波”特征,雷暴大风天气表现为“中层径向辐合”和“弓形回波”等,基于这些雷达特征衍生出众多强对流天气的预报方法,但大都是关于强对流天气发生与否、发生类型以及落区等的定性预报。对电网部门来说,往往更希望了解并量化“强对流天气将带来的风险”以制定科学合理的防控决策,相比于定性预报,强对流天气的定量预报或预测能为电网提供更多有价值的信息,也是进行电网气象预警不可或缺的一部分。尤其是,针对强对流天气下的线路风偏放电预警,气象部门发布的常规气象预报往往难以满足其需求。
技术实现要素:
针对上述现有技术的不足,本发明提供一种基于天气雷达数据的强对流风力等级预测方法,解决现有技术中不能对强对流风力进行定量预测的技术问题,目的在于实现对强对流天气下的风力等级的预测。
为了解决上述技术问题,本发明采用了如下的技术方案:一种基于天气雷达数据的强对流风力等级预测方法,其特征在于:包括以下步骤:
步骤101:根据风速阈值将风力等级划分为0到m级,风力等级用lv表示,则lv∈{lv0,lv1,....,lvj,...,lvm},j∈{0,1,...,m};
步骤102:以支持矢量机svm作为子分类器,采用n个子分类器从第1个到第n个依次串联的方式构造多分类器,其中n=m;每一个子分类器能够将风力等级分为两类;为每一个子分类器设置一个对应的标签,第i个子分类器的标签为
步骤103:利用天气雷达对强对流的历史监测数据构造若干个输入矢量,并根据气象站风速的历史监测数据为每个输入矢量确定风力等级;其中,t时刻的输入矢量为x(t);t时刻的输入矢量x(t)对应的风力等级根据气象站t′时刻的风速监测数据确定,其中,时刻t′为时刻t的下一整点时刻;
步骤104:利用气象站风速的历史监测数据为每一个输入矢量构造对应的矢量标签,其中,t时刻的输入矢量x(t)所对应的矢量标签为yl(t),矢量标签yl(t)根据时刻t所对应的风力等级进行确定,yl(t)=(l1(t),...,li(t),...,ln(t));
步骤105:根据步骤103以及步骤104的输入矢量以及矢量标签构造样本集,样本集中单个样本表示为(x(t),yl(t));
步骤106:筛选样本集,构造训练集tr={(x(t),yl(t))|t′-t≤δt},其中,δt表示时刻t与时刻t′的时距阈值;
步骤107:利用训练集tr对多分类器进行训练,使得多分类器具备能够根据输入矢量,预测出对应风力等级的能力;
步骤108:采集天气雷达对强对流的实时监测数据,重新构造输入矢量,将输入矢量输入训练完成后的多分类器中,多分类器根据输入矢量输出对应时刻的风力等级,实现对风力的多级预测。
优选的,t时刻的输入矢量x(t)按如下步骤构造:
步骤201:提取天气雷达对强对流的监测数据中的14种雷达数据,构造基本雷达回波数据矢量xb(t),如下:
xb(t)=(平均反射率因子,最大反射率因子,最大反射率因子对应高度,风暴高度,垂直液态水含量,平均反射率因子梯度,最大反射率因子梯度,风暴质量,平均面积,风暴顶高度,风暴底高度,移动速度,长轴长,短轴长);
步骤202:计算基本雷达回波数据矢量增量:xb(t)-xb(t-1),其中,t-1表示雷达的上一体扫时刻;
步骤203:以天气雷达对强对流的监测数据中的剩余数据构造矢量xr(t),如下:
xr(t)=(降雹概率,强降雹概率,降水面积,二维风暴个数);
步骤204:构造输入矢量x(t),如下:
x(t)=(xb(t),xb(t)-xb(t-1),xr(t))。
优选的,在步骤107与步骤108之间进行步骤301:采用测试集对多分类器的预测准确率进行测试,其中,测试集为样本集中随机选取的部分样本,样本集余下部分作为训练集的来源。采用测试集对多分类器进行测试的工作流程:子分类器svm-1根据测试集中的输入矢量预测风力等级是否为lv0,若是,则输出预测结果,若否,则将测试集继续传递到子分类器svm-2中,进行正类样本的分类,
优选的,子分类器的个数n=2,第一个子分类器表示为svm-1,第二个子分类器表示为svm-2;风力等级lv∈{lv0,lv1,lv2},样本集中与风力等级lv0对应的样本为负类样本,其余为正类样本;在多分类器的训练过程中子分类器svm-1用于筛选出负类样本,子分类器svm-2用于对正类样本进行进一步分类,以将正类样本分成分别与风力等级lv1、风力等级lv2对应的两类正类样本。
优选的,子分类器svm-1与子分类器svm-2分别采用不同的子训练集tr-1、tr-2进行训练,并且,tr-1∈tr,tr-2∈tr;
子训练集tr-1由训练集tr中的正类样本以及对训练集tr中负类样本随机下采样所获得的负类样本组成,并且子训练集tr-1中负类样本数量与正类样本数量的最佳比值为p,使得子分类器svm-1具有最优分类界面;
子训练集tr-2为训练集tr中全部正类样本的集合。
与现有技术相比,本发明具有以下有益效果:
1、本发明以天气雷达对强对流的监测数据作为预测信息源,采用多分类器将对强对流风力的预测问题转化为“有监督学习下的分类问题”,根据天气雷达的历史监测数据构造输入矢量(输入矢量与风力等级的对应关系为已知),并根据气象站的历史风速监测数据构造矢量标签,利用输入矢量与矢量标签的对应关系构成训练集对多分类器进行训练,使得多分类器能够根据输入矢量输出预测结果即风力等级。
2、从气象站记录的强对流天气对应的风速数据来看,高风速数据只占很小比例,可生成的高风速训练样数量将很少,并且输入矢量的维数较大(共计32维),因此,属于小样本、高维输入的分类问题,采用支持矢量机svm作为分类器在解决小样本、高维输入的分类问题上具有较大优势,而且svm基于结构风险最小化设计,对新的、未知的样本同样有较好的分类效果,有较强的泛化能力。
3、多分类器为串行结构,通过逐层筛选实现多分类,具有较高的分类效率。由于串行结构的多分类器中每层子分类器的效果都建立在上层子分类器的效果上,多分类器的分类效果随层数增多而下降,本发明采用两个子分类器能够提高分类的准确性,对风力等级进行三级预测。
4、由于负类样本的数量远大于正来样本的数量,这种数据不平衡性会严重影响子分类器svm-1的分类效果,并且这种不利影响会传递至下一层的子分类器svm-2,为了降低数据不平衡性对风力预测效果的不利影响,对子分类器svm-1的子训练集进行最佳比值pbest下的随机下采样。
附图说明
图1是基于天气雷达数据对强对流风力等级预测的原理图;
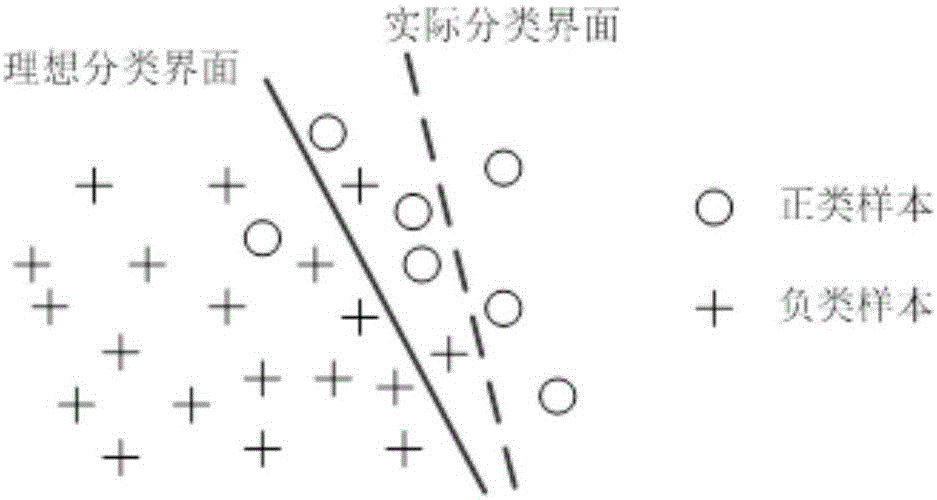
图2是数据不平衡性对支持矢量机svm分类效果的影响示意图;
图3是某省电网历史风偏事件对应自动气象站风速分布图;
图4是某省2013~2014年夏季强对流天气对应自动气象站风速分布情况拟合图;
图5是各个比值p下综合评价指标zc的变化图;
具体实施方式
下面结合附图和优选实施方式对本发明作进一步的详细说明。
为了使本发明更容易理解,首先对本发明的原理进行说明,本发明的多分类器可以看作为“黑箱”,输入矢量作为信息刺激,多分类器的输出(风力等级的预测结果)是对信息刺激的反应,多分类器在训练过程中输入(输入矢量)与输出(风力等级的预测结果)的关系为已知的,通过训练集(训练模型)对多分类器进行训练后,多分类器便能够对输入矢量这一信息刺激进行反应,从而输出对风力等级的预测。
一种基于天气雷达数据的强对流风力等级预测方法,包括以下步骤:
步骤101:根据风速阈值将风力等级划分为0到m级,风力等级用lv表示,则lv∈{lv0,lv1,....,lvj,...,lvm},j∈{0,1,...,m};
本具体实施方式中将风力等级划分为3级,风力等级划分规则如下:
其中,v表示风速,v1、v2表示风速阈值;
步骤102:以支持矢量机svm作为子分类器,采用n个子分类器从第1个到第n个依次串联的方式构造多分类器,本具体实施方式中,子分类器的个数为2个,其中n=m=2;每一个子分类器能够将风力等级分为两类;为每一个子分类器设置一个对应的标签,第i个子分类器的标签为
本具体实施方式中,第一个子分类器的标签为:
步骤103:利用天气雷达对强对流的历史监测数据构造若干个输入矢量,并根据气象站风速的历史监测数据为每个输入矢量确定风力等级;其中,t时刻的输入矢量为x(t);t时刻的输入矢量x(t)对应的风力等级根据气象站t′时刻的风速监测数据确定,其中,时刻t′为时刻t的下一整点时刻;
步骤104:利用气象站风速的历史监测数据为每一个输入矢量构造对应的矢量标签,其中,t时刻的输入矢量x(t)所对应的矢量标签为yl(t),矢量标签yl(t)根据时刻t所对应的风力等级进行确定,yl(t)=(l1(t),...,li(t),...,ln(t));本具体实施方式中,yl(t)=(l1(t),l2(t));
步骤105:根据步骤103以及步骤104的输入矢量以及矢量标签构造样本集,样本集中单个样本表示为(x(t),yl(t));
步骤106:筛选样本集,构造训练集tr={(x(t),yl(t))|t′-t≤δt},其中,δt表示时刻t与时刻t′的时距阈值;
步骤107:利用训练集tr对多分类器进行训练,使得多分类器具备能够根据输入矢量,预测出对应风力等级的能力;
步骤108:采集天气雷达对强对流的实时监测数据,重新构造输入矢量,将输入矢量输入训练完成后的多分类器中,多分类器根据输入矢量输出对应时刻的风力等级,实现对风力的多级预测。
上述步骤中,步骤108之前的步骤均是为了构建基于天气雷达数据对强对流风力等级进行预测的预测模型,其原理如图1所示,本具体实施方式中采用了天气雷达scit产品历史数据来构造的输入矢量x,风力等级为预测结果y,在采用训练集(训练模型)对分类器进行训练完成后,得到预测模型,利用测试集对预测模型进行测试,能够修正预测模型,提高预测模型的准确性。
本具体实施方式中,t时刻的输入矢量x(t)按如下步骤构造:
步骤201:提取天气雷达对强对流的监测数据中的14种雷达数据,构造基本雷达回波数据矢量xb(t),如下:
xb(t)=(平均反射率因子,最大反射率因子,最大反射率因子对应高度,风暴高度,垂直液态水含量,平均反射率因子梯度,最大反射率因子梯度,风暴质量,平均面积,风暴顶高度,风暴底高度,移动速度,长轴长,短轴长);
步骤202:计算基本雷达回波数据矢量增量:xb(t)-xb(t-1),其中,t-1表示雷达的上一体扫时刻;
步骤203:以天气雷达对强对流的监测数据中的剩余数据构造矢量xr(t),如下:
xr(t)=(降雹概率,强降雹概率,降水面积,二维风暴个数);
步骤204:构造输入矢量x(t),如下:
x(t)=(xb(t),xb(t)-xb(t-1),xr(t))。
本具体实施方式中,在步骤107与步骤108之间进行步骤301:采用测试集对多分类器的预测准确率进行测试,其中,测试集为样本集中随机选取的部分样本,样本集余下部分作为训练集的来源,即训练集是对样本集余下部分进行筛选得到,筛选的规则即步骤106中只选取时刻t与时刻t′的时距小于等于时距阈值δt的输入矢量,本具体实施方式中δt=20min,例如,样本集中有以下时刻:10:10、10:15、10:30、10:40、10:45以及10:50的输入矢量x(10:10)、x(10:15)、x(10:30)、x(10:40)、x(10:45)、x(10:55),上述时刻的下一整点时刻均为11:00,那么只选取与下一整点时刻的时距小于等于20min的输入矢量,即x(10:40)、x(10:45)、x(10:55)。
采用测试集对多分类器进行测试的工作流程:子分类器svm-1根据测试集中的输入矢量预测风力等级是否为lv0,若是,则输出预测结果,若否,则将测试集继续传递到子分类器svm-2中,进行正类样本的分类。
本具体实施方式中,子分类器的个数n=2,第一个子分类器表示为svm-1,第二个子分类器表示为svm-2;风力等级lv∈{lv0,lv1,lv2},样本集中与风力等级lv0对应的样本为负类样本,其余为正类样本;在多分类器的训练过程中子分类器svm-1用于筛选出负类样本,子分类器svm-2用于对正类样本进行进一步分类,以将正类样本分成分别与风力等级lv1、风力等级lv2对应的两类正类样本。
本具体实施方式中,子分类器svm-1与子分类器svm-2分别采用不同的子训练集tr-1、tr-2进行训练,并且,tr-1∈tr,tr-2∈tr;
由于负类样本的数量远大于正来样本的数量,如图2所示,这种数据不平衡性会严重影响子分类器svm-1的分类效果,并且这种不利影响会传递至下一层的子分类器svm-2,为了降低数据不平衡性对风力预测效果的不利影响,对子分类器svm-1的子训练集进行最佳比值pbest下的随机下采样。
子训练集tr-1由训练集tr中的正类样本以及对训练集tr中负类样本随机下采样所获得的负类样本组成,并且子训练集tr-1中负类样本数量与正类样本数量的最佳比值为p,使得子分类器svm-1具有最优分类界面;
子训练集tr-2为训练集tr中全部正类样本的集合。
本具体实施方式中,最佳比值p采用z分综合评价法进行确定,z分综合评价法包括以下步骤:
步骤701:随机选取样本集中部分样本作为测试集,样本集余下部分作为训练集的来源,筛选样本集构造训练集tr;
步骤702:令p依次取1到10的自然数;在p的每次取值下构造子训练集,使得子训练集tr-1中负类样本数量与正类样本数量的比值为p;然后利用当前比值p下的子训练集tr-1对子分类器svm-1进行训练;
步骤703:利用测试集依次对各个比值p下的子训练集tr-1训练后的多分类器进行测试,并根据对测试集的实际分类结果计算各个比值p下的以下3类指标,每个比值p下的3类指标均按如下公式计算:
步骤703:获取各个比值p下的空报率、漏报率以及g-mean指标;
步骤704:依次计算各个比值p下三类指标各自对应的z分数,其中,当前比值p下的各类指标对应的z分数分别按如下公式:
与空报率对应的z分数zp1:
与漏报率对应的z分数zp2:
与g-mean指标对应的z分数zp3:
步骤705:计算各个比值p下的综合评价指标zc:
zc=zp3-zp2-zp1;
步骤706:比较各个比值p下的综合评价指标zc的大小,以最大的综合评价指标zc所对应的比值p作为最佳比值pbest。
按比值对训练集进行下采样,构造出子训练集tr-1以消除数据不平衡性对子分类器svm-1的分类效果的影响,并且利用测试集对每个比值p下训练出的子分类器svm-1进行测试,比较各个比值p下的综合评价指标zc,从而选择出最佳比值pbest,保证子分类器svm-1具有最佳的分类效果。另外,由于正类样本不存在明显的数据不平衡性,因此本具体实施方式中采用训练集tr中全部正类样本的集合作为训练子分类器svm-2的子训练集tr-2,最终仍然能够获得良好的分类效果。
为了更好的说明本发明对强对流风力等级的预测效果,对我国某省的强对流风力等级的预测案例如下:
首先,对某省电网历史风偏事件对应的自动气象站的风速进行统计,如图3所示:95%的风偏事件发生时,附近自动气象站的观测风速均在8m/s以上。并且,根据某省2013—2014年夏季强度对流天气对应的自动气象站风速分布情况进行拟合,如图4所示,从图中的风速分布不难看出,如果lv1和lv2间的阈值太大,会导致lv2的样本过少,从而影响子分类器svm-2对lv1和lv2的分类效果。综合上述原因,选择11m/s作为lv1、lv2的划分阈值,因此,基于天气雷达数据的强对流大风预测模型的风力等级划分规则如下:
然后,构造训练集对多分类器进行训练,其中,按照步骤701~706计算最佳比值pbest,为了更加直观的选取最佳比值pbest绘制了综合评价指标指标zc的分布图,如图5所示,当p=3时,综合评价指标指标zc为最大值,因此,最佳比值pbest=3。
在该省2013—2014年历史夏季强对流天气雷达数据及对应自动气象站风速数据的基础上,对模型进行了测试及验证。选取历史某天185条样本作为测试集,其余样本按上述步骤构造训练集,对模型进行训练及测试;更换测试集,选取另一天的107条样本,重复上述步骤。两次测试的结果见表1。
表1
根据表1结果,子分类器svm-1两次测试的g-menas指标分别为90.5%和86.8%,对不平衡风速样本有较好的分类效果;而子分类器svm-2也能正确识别出高风速lv2的样本。如表1所示,对角线元素代表正确预测的情况,测试结果表明整体模型对强对流大风的风力情况有较好的预测效果。
- 还没有人留言评论。精彩留言会获得点赞!