基于SDRAM芯片的SAR成像系统矩阵转置装置和图案交织方法与流程
本发明涉及一种基于SDRAM芯片的SAR成像系统矩阵转置装置和图案交织方法,属于SAR成像领域。
背景技术:
SAR是一种强大的高分辨率微波遥感成像雷达,它起源于20世纪50年代,1951年美国Goodyear公司的Wiley首先提出了这一概念。与光学传感器相比,SAR具有全天时、全天候工作能力,并且能够穿透云层和植被。SAR成像系统接收的原始雷达回波是二维的,各种SAR成像处理算法在将二维数据阵列进行“时域-频域”的切换过程中,不可避免的需要进行多次数据转置操作,矩阵转置效率决定着SAR成像系统的处理速度及实时性。
矩阵转置是多维图像和信号处理中常用的处理过程,矩阵转置可以看做是两个矩阵之间的映射:Xi,j→Xj,i。当应用规模比较小时,整个矩阵可以一次读入到高速存储器中,矩阵转置就非常简单。对于大规模的应用,高速内存容量不够,大量的数据必须存储外部存储器中,转置效率在整个处理过程中就显得非常重要。
同步动态随机存取存储器(以下简称SDRAM)芯片由于存储容量大、速度快、功耗低等优点,是目前SAR成像应用中最广泛的存储器之一。常见的基于SDRAM芯片的矩阵转置方法包括二页式、三页式、矩阵分块式等。中科院的卢世祥等人于2005年发表了论文“合成孔径雷达实时成像转置存储器的两页式结构与实现”,介绍了通过循环对两片SDRAM芯片读写的二页式转置工作原理,但其转置效率仅为49.3%。中科院的谢应科等人于2003年发表了论文“实时SAR成像系统中矩阵转置的设计和实现”,介绍了通过循环对两片SDRAM芯片读写的二页式转置工作原理,但其转置效率仅为64%。采用矩阵分块式转置方法的文章比较多,均通过将原始矩阵分割为多个子矩阵的方式,增加离散操作时每次激活后所能连续访问的次数,以减少SDRAM芯片激活和预充电操作次数,以此减小SDRAM芯片控制命令对访问效率的影响程度,但他们的转置效率或多或少都会受到SDRAM芯片控制命令开销的影响。
无论是二页式、三页式或者矩阵分块式,这些方法在数据输入输出平衡转置方面都很有效,它们的不足之处是:SDRAM芯片在页面跳转(即BANK切换)、读/写、刷新等操作均会产生额外的控制命令开销,这些方法都未能将SDRAM芯片器件特性充分利用起来,从而影响到转置效率,使得SAR成像系统的实时性下降。
技术实现要素:
本发明的技术解决问题是:克服现有技术的不足之处,公开了一种基于SDRAM芯片的SAR成像系统矩阵转置装置和图案交织方法,该方法根据SDRAM芯片的器件特性,将SDRAM芯片在页面跳转、读/写、刷新等操作产生额外的控制命令周期充分利用了起来,极大的提升了SAR成像系统转置效率和实时性。
本发明的技术解决方案是:
提供一种基于SDRAM芯片的SAR成像系统矩阵转置装置,存储器管理单元(MMU)、两组SDRAM芯片(SDRAM1~SDRAM4);
存储器管理单元(MMU)按行接收待转置矩阵的数据,连续b行数据划分为N/b个b×b子矩阵;将奇数个b×b子矩阵转置后按行拼接,每个b×b子矩阵存储在第一组SDRAM芯片内BANK的同一行中,每写完一个b×b子矩阵自上而下换行;将偶数个b×b子矩阵转置后按行拼接,每个b×b子矩阵存储在第二组SDRAM芯片内相同编号BANK的同一行中,每写完一个b×b子矩阵自上而下换行;每写入b行数据后进行一次BANK切换,4个BANK遍历后按照间隔N/2b个存储行的方式换行写,并在4个BANK之间循环遍历;
在第一组SDRAM芯片中,依次连续读出每个BANK中的b个数据;每读出b个数据进行一次BANK切换,并在4个BANK之间循环遍历,直至读出原始待转置矩阵的b列数据后进行一次两组SDRAM芯片间切换。
优选的,第一组SDRAM芯片包括SDRAM1芯片和SDRAM2芯片,同时与存储器管理单元(MMU)输出的第一地址总线端口(Addr1)相连;第二组SDRAM芯片包括SDRAM3芯片和SDRAM4芯片,同时与存储器管理单元(MMU)输出的第二地址总线端口(Addr2)相连;SDRAM1芯片的数据总线端口(DQ)和SDRAM3芯片的数据总线端口(DQ)与存储器管理单元(MMU)的高32位数据总线端口对应相连,SDRAM2芯片的数据总线端口(DQ)和SDRAM4芯片的数据总线端口DQ与存储器管理单元(MMU)的低32位数据总线端口对应相连。
优选的,每组SDRAM芯片包括4个BANK,突发长度为b;每个BANK为m行n列,BANK中每个阵列单元可存储32位数据。
优选的,存储器管理单元(MMU)接收M行N列待转置矩阵,矩阵输入输出形式为按行输入,转置后按列输出;待转置矩阵中每个数据为64位浮点数,包括实部32位浮点数和虚部32位浮点数。
优选的,每组SDRAM芯片中各包含两个SDRAM芯片,分别存储实部32位浮点数和虚部32位浮点数。
优选的,突发长度为b满足,M能被4b整除,N能被2b整除;且M×N≤8×m×n。
优选的,所述存储器管理单元(MMU)工作步骤如下:
(1)获取待转置矩阵的行数M,列数N;
(2)按行连续输入待转置矩阵,并将连续b行数据划分为N/b个b×b子矩阵;
(3)将奇数个b×b子矩阵转置后按行拼接,每个b×b子矩阵存储在第一组SDRAM芯片内BANK的同一行中,每写完一个b×b子矩阵自上而下换行;将偶数个b×b子矩阵转置后按行拼接,每个b×b子矩阵存储在第二组SDRAM芯片内相同编号BANK的同一行中,每写完一个b×b子矩阵自上而下换行;
每写入b行数据后进行一次BANK切换,4个BANK遍历后按照间隔N/2b个存储行的方式换行写,并在4个BANK之间循环遍历;
(4)在第一组SDRAM芯片中,依次连续读出每个BANK中的b个数据;每读出b个数据进行一次BANK切换,并在4个BANK之间循环遍历,直至读出原始待转置矩阵的b列数据后进行一次SDRAM芯片组间切换。
优选的,步骤(3)中BANK内部所有行遍历后从左至右从相邻空白处继续写,直至写完。
优选的,步骤(4)中BANK内部数据读取时,每读取b个数据后按照间隔N/2b存储行的方式换行读,行遍历后从左至右从相邻空白处继续读,直至读完。
优选的,待转置矩阵中每个数据为64位浮点数,包括实部32位浮点数和虚部32位浮点数。
本发明与现有技术相比的有益效果是:
(1)与采用二页式、三页式或者矩阵分块式转置方法相比,本发明原理简单,易于实现,将SDRAM芯片在页面跳转、读/写、刷新等操作产生额外的控制命令周期充分利用了起来,数据连续输入输出时可以做到无缝对接,同时避免了刷新操作。
(2)本发明的转置方法,能够保证数据总线上为连续的有效数据,可同时实现数据输入和输出,转置效率可以达到100%。
(3)本发明的转置方法易于实现,处理速度快,特别适合于SAR成像雷达信号处理应用。
附图说明
图1为本发明SAR成像系统矩阵转置装置;
图2为通用SDRAM芯片3D存储结构框图;
图3为SAR成像系统输入矩阵示意图;
图4为写入时S(0)和S’(0)组内交织图案;
图5为写入时S和S’组间交织图案;
图6为读出时输出矩阵示意图;
图7为通用SDRAM芯片刷新操作指令示意图;
图8为本发明写操作数据流图;
图9为本发明读操作数据流图;
图10为本发明实施例写入示意图。
具体实施方式
下面结合本发明实施过程中的附图,对本发明实施过程中的技术方案进行清楚地描述。限于篇幅,所描述的写操作和读操作数据流图仅仅是本发明的一部分,而不是全部的应用实例。基于本发明的应用实例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他应用实例,都属于本发明的保护范围。
图1为本发明SAR成像系统矩阵转置装置,包括:存储器管理单元(MMU)、4片SDRAM芯片(SDRAM1~SDRAM4);
存储器管理单元(MMU)从数据输入端口Din[63:0]接收64位数据,从数据输出端口Dout[63:0]输出64位数据;SDRAM1芯片和SDRAM2芯片共同组成Group1,并同时与存储器管理单元(MMU)输出的地址总线端口Addr1相连;SDRAM1芯片的数据总线端口DQ与存储器管理单元(MMU)的数据总线端口D_Q[63:32]相连,SDRAM2芯片的数据总线端口DQ与存储器管理单元(MMU)的数据总线端口D_Q[31:0]相连;SDRAM3芯片和SDRAM4芯片共同组成Group2,并同时与存储器管理单元(MMU)输出的地址总线端口Addr2相连;SDRAM3芯片的数据总线端口DQ与存储器管理单元(MMU)的数据总线端口D_Q[63:32]相连,SDRAM4芯片的数据总线端口DQ与存储器管理单元(MMU)的数据总线端口D_Q[31:0]相连。
存储器管理单元(MMU)接收M行N列待转置矩阵,矩阵输入输出形式为按行输入,转置后按列输出;待转置矩阵中每个数据为64位浮点数,包括实部32位浮点数和虚部32位浮点数。
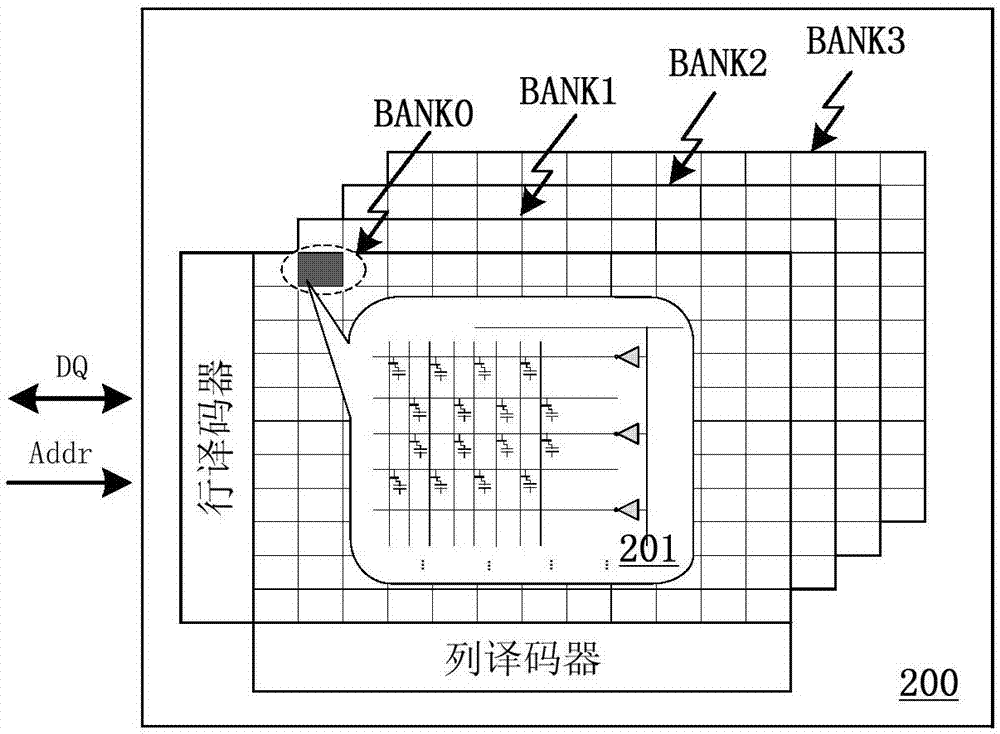
图2为通用SDRAM芯片3D存储结构框图,包括:4个BANK(BANK0~BANK3),双向数据输入输出总线端口DQ,地址输入总线端口Addr,行译码器和列译码器。其中,每个SDRAM芯片包括4个BANK,突发长度为b;每个BANK为m行n列,BANK中每个阵列单元可存储32位数据。通用的SDRAM芯片内部一般有4个BANK,输入和输出共享数据总线DQ和地址总线Addr。
每个Group中各包含两个SDRAM芯片,分别存储实部32位浮点数和虚部32位浮点数。突发长度为b满足,M能被4b整除,N能被2b整除;且M×N≤8×m×n。
在执行读/写操作时,SDRAM芯片的控制命令(COMMAND)顺序为:激活(ACTIVE)—读(READ)/写(WRITE)—预充电(PRECHARGE)。由于存在操作时延,上述控制命令执行期间还需空操作(NOP)指令。为方便说明,下文中的预充电指令用PRE简述。
由于SDRAM芯片的页面跳转、读/写操作均会产生额外的控制命令开销,这些控制命令所占用的总线周期会影响到数据访问效率,从而影响到转置效率。本发明通过设计交织图案,可以有效规避这些影响。
图3为SAR成像系统输入矩阵示意图,矩阵大小为M行N列。矩阵内数据用d(i,j)表示,其中,i为行坐标,j为列坐标,M行N列所有数据用d(0,0)~d(M-1,N-1)表示。
所述存储器管理单元(MMU)在矩阵写入时交织图案设计方法如下:
按行连续输入待转置矩阵,并将连续b行数据划分为N/b个b×b子矩阵;将奇数个b×b子矩阵转置后按行拼接,每个b×b子矩阵存储在第一个Group内BANK的同一行中,每写完一个b×b子矩阵自上而下换行;将偶数个b×b子矩阵转置后按行拼接,每个b×b子矩阵存储在第二个Group内相同编号BANK的同一行中,每写完一个b×b子矩阵自上而下换行;
每写入b行数据后进行一次BANK切换,4个BANK遍历后按照间隔N/2b个存储行的方式换行写,并在4个BANK之间循环遍历;BANK内部所有行遍历后从左至右从相邻空白处继续写,直至写完。
输入矩阵每b行数据被分为2组,M行数据共分为2M/b组,记为S(0)~S(M/b-1)和S’(0)~S’(M/b-1)。图4以S(0)组和S’(0)组为例,设计了写入时S(0)和S’(0)组内交织图案。S(0)组数据写入Group1,S’(0)组数据写入Group2,分别存储在Group1的BANK0中和Group2的BANK0中。图4将第0~b-1行数据的每行数据分为N/b段,每段b个数据在SDRAM芯片内的同一行以b为间隔存储,各段数据在Group1和Group2之间交替存储,每写完2段数据后换行,行遍历后从从相邻空白处继续写。
图5为写入时所有S组和S’组间交织图案。组间交织从BANK0开始,每写完输入矩阵的b行数据意味着将2组(相同编号的S组和S’组)数据分别写入了Group1和Group2,然后进行BANK切换,BANK0~BANK3遍历后先从下方空白处继续写,行遍历后从从相邻空白处继续写。
图6为读出时输出矩阵示意图。所述存储器管理单元(MMU)在矩阵读出时,在第一个Group中,依次连续读出每个BANK中的b个数据;每读出b个数据进行一次BANK切换,并在4个BANK之间循环遍历,直至读出原始待转置矩阵的b列数据后进行一次Group间切换;BANK内部数据读取时,每读取b个数据后按照间隔N/2b存储行的方式换行读,行遍历后从左至右从相邻空白处继续读,直至读完。读出的数据即为图3所示M行N列输入矩阵的转置输出矩阵,大小为N行M列。
图7为通用SDRAM芯片刷新操作指令示意图,控制命令(COMMAND)顺序为:激活(ACTIVE)—空操作(NOP)—预充电(PRECHARGE)。由于SDRAM芯片所存储的数据有一定的时效性,每隔一段时间必须对所有数据全部进行一次刷新。只有保证在特定时间内对SDRAM芯片的所有行进行一次遍历,那么就不需要发送刷新指令,从而可以有效降低刷新时控制命令对转置效率的影响,提高数据总线利用效率。因此,本发明为了将数据转置效率提升至100%,必须规避刷新操作。
图8为采用本发明矩阵转置交织图案方法的写操作数据流图。为方便说明,这里取突发访问长度b值为4。写操作过程中,每4个数据进行一次SDRAM1芯片和SDRAM2芯片之间的切换,从而实现了数据连续写入时的无缝对接,写入时无总线周期浪费。同时,连续4个数据对应的写入地址(Addr)以突发访问长度4为单位跳变,在同一个SDRAM芯片内,每写4个数据就执行换行操作。
将连续4行数据写入2组SDRAM芯片中相同编号BANK,每写4行进行一次BANK切换,如此交替写入不同BANK。
图9为采用本发明矩阵转置方法读操作数据流图。突发访问长度b值为4,读操作只需产生待访问数据的首地址即可。由于写入时4行数据矩阵已进行列切换,可直接依次连续读出每个BANK中的4个数据。每读出4个数据进行一次BANK切换,4个BANK遍历后,进行一次SDRAM芯片间切换。BANK内部数据读取时,每读取4个数据后换行,行遍历后从左至右从相邻空白处继续读,直至读完。从图5中可以看出,数据连续读出时实现了无缝对接,无总线周期浪费。
从图8和图9中可以看出,每次读操作或者写操作均包含了控制命令“激活(ACTIVE)—预充电(PRECHARGE)”过程,这意味着每次读操作或者写操作均对当前操作所在行完成了刷新操作。因此,无需引入额外的刷新操作指令。同时,本发明在数据连续输入输出时可以做到无缝对接,实现了原始矩阵的行入列出,转置效率可以达到100%。
实施例
以8×8的矩阵转置为例,矩阵内的第i行第j列的数据用aij表示,其中i,j的取值为0~7;b的取值为2。
结合图10,首先将第1个2×2子矩阵按{a00a10a01a11}顺序写入第一组SDRAM芯片BANK0的第1行,然后切换至第二组SDRAM芯片,将第2个2×2子矩阵按{a02a12a03a13}顺序写入BANK0的第1行;返回第一组SDRAM芯片中的BANK0,换行后,将{a04a14a05a15}写入,然后切换至第二组SDRAM芯片,换行后写入{a06a16a07a17},依次类推,直至完成前两行的写入。切换至BANK1,完成第3、4行的撰写,切换至BANK2,完成第5、6行的撰写,切换至BANK3,完成第7、8行的撰写。
参见图10,读取过程首先从第一组SDRAM芯片开始,依次连续读出4个BANK第1行中的前2个数据,得到矩阵转置后的第1列数据;然后依次连续读出4个BANK第1行中的后2个数据,得到矩阵转置后的第2列数据;由于已完成2列矩阵转置数据读取,则切换至第二组SDRAM芯片,用同样的方法读出矩阵转置后的第3、4列数据,依次类推。
图8、图9和图10仅为本发明突发访问长度b值为4或4时的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求书的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!