使用IP-质谱法的抗体验证的制作方法
本发明部分地涉及利用免疫沉淀和质谱法验证抗体的组合物和方法。
背景技术:
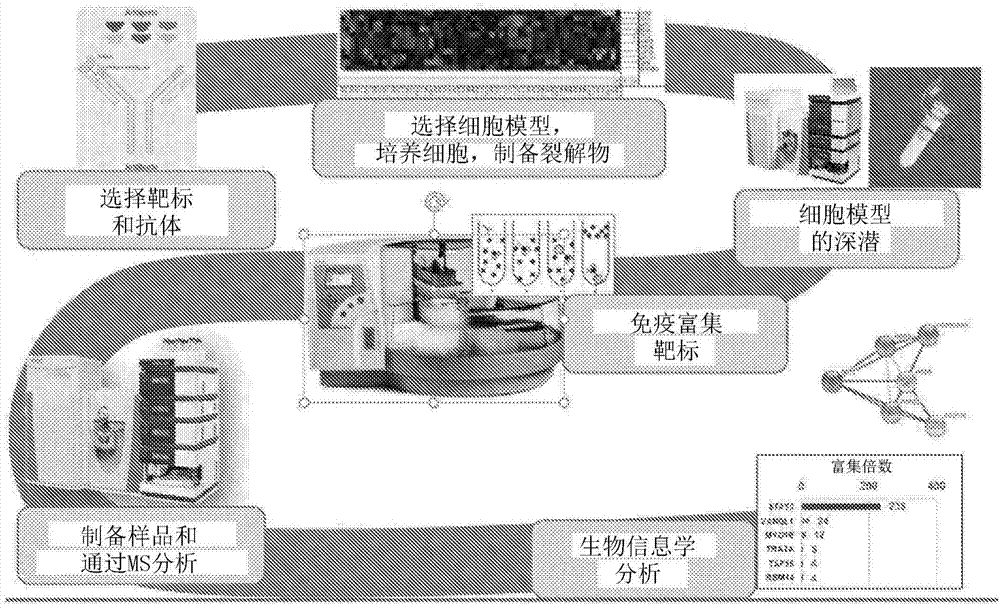
:抗体被用在宽范围的研究和诊断应用中用于蛋白的富集、检测和定量和它们的修饰。针对数千种蛋白的数万种抗体是商购可得的,它们被用在多种应用中,包括蛋白质印迹法(wb)、免疫荧光(if)、免疫沉淀(ip)、流式细胞计量术(fc)、染色质ip(chip)、酶联免疫测定(elisa)和基于珠子的夹心测定(例如luminex)。这些抗体可以是来自不同生物的单克隆抗体或多克隆抗体,且它们可以用于查询生物系统和信号传递途径、诊断疾病和评估对治疗的应答(参见lipman,n.s.等人,ilarjournal46(3):258-268(2005))。不幸的是,在最初和在制备批次之间,大多数抗体被较差地表征。这是由于至少三个挑战:1)蛋白靶标和抗体的绝对数目可以是压倒性的;2)每种抗体靶标、应用和模型系统的独特要求和挑战(诸如天然的相对于变性的表位构象或未刺激的相对于刺激的细胞);和,3)用于评估抗体选择性的一致标准方案和标准的缺乏(参见madhusoodanan,j.validatingantibodies:anurgentneed.2014;和bordeaux,j.等人,biotechniques48(3):197-209(2010))。对改进的抗体验证方案和标准存在巨大需要,以确保所述试剂适合目的。已经提出多种用于抗体验证的推荐,并且巩固的抗体注解和性能“评分”信息的数据库是可自由得到的(例如,antibodypedia,如在bjorling,e.和uhlenm.mol.cell.proteomics7(10):2028-37(2008)中所述)。已经提出了多种抗体验证标准,包括:1)用基因击倒或阻断肽评估抗体特异性;2)用不同的生物系统(靶标定位、模型系统等)验证抗体检测结果;3)方法之间的抗体结果的联系;和4)样品、实验室和制备批次之间的再现性的证实(参见bordeaux,j.等人,biotechniques48(3):197-209(2010),bjorling,e.和uhlenm.mol.cell.proteomics7(10):2028-37(2008),以及pauly,d.和k.hanack,f1000res4:691(2015))。近年来,已经为抗体验证提出质谱测定方案(参见bostrom等人,jproteomeres13(10):4424-35(2014)和marcone.等人,naturemethods12:725-731(2015))。尽管质谱法有成本和技术要求,但是在所有现有的验证方法中,质谱法具有鉴别实际抗体靶标、异形体、修饰和有关蛋白的独特能力。没有其它方法可以以ms的深度和特异性鉴别和表征抗体靶标。但是,不同于蛋白质印迹法、elisa和使用阻断试剂如牛奶或牛血清白蛋白(bsa)的其它标准免疫学方法,为了使背景蛋白结合最小化,质谱法会检测样品中的所有特异性的和非特异性的蛋白。例如,使用固定化在珠子或树脂上的抗体的免疫沉淀是从裂解物或生物流体富集靶蛋白和有关蛋白的常见方案。由于特异性靶标相对于普通背景蛋白的低丰度,当利用质谱法时,非特异性地结合的蛋白可能淹没低丰度靶标并干扰或阻止低丰度靶标的检测。即使使用严谨的洗涤条件和经优化的试剂,通常在通过质谱法分析的免疫沉淀的样品中观察到数十至数百种背景蛋白。因而,来自免疫沉淀的样品的质谱法结果可以难以过滤和解释。具体地,抗体对来自真实生物系统的天然蛋白的选择性的确保是特别难以证实的,部分地因为预期靶标相对于非特异性/背景抗体结合剂的极低丰度。为了解决这些问题,我们已经开发了进行抗体验证的新方案。通过使用经优化的样品制备试剂和方法、现有技术仪器和新颖的数据分析流水线,已经建立了综合工作流来使用与质谱法组合的免疫沉淀(ip-ms,如在图1中所示)针对它们的预期靶标来验证抗体。该ip-ms方案的益处包括:鉴别抗体靶标、异形体和修饰,通过计算靶标的富集倍数和脱靶来定量评估抗体选择性,和准确鉴别和定量靶蛋白修饰和相互作用蛋白。技术实现要素:本发明部分地涉及利用免疫沉淀和质谱法验证抗体的组合物和方法。在某些实施方案中,本发明包括鉴别特异性地结合抗体的蛋白的方法,其中所述方法包括:i)选择试验抗体;ii)从生物样品制备细胞裂解物;iii)使所述细胞裂解物与所述试验抗体接触,和免疫沉淀所述抗体和它的蛋白结合配偶体;iv)通过质谱法分析所述免疫沉淀的抗体和它的蛋白结合配偶体;v)确定与所述试验抗体结合的蛋白相对于所述细胞裂解物中的蛋白的富集倍数;和vi)鉴别特异性地结合所述抗体的蛋白,其中特异性地结合所述抗体的蛋白相对于所述细胞裂解物中的蛋白富集。在某些方面,所述抗体结合超过一种靶蛋白。在某些实施方案中,根据它对它的靶蛋白的特异性表征所述抗体,其中一种靶蛋白相对于另一种靶蛋白更大的富集倍数或更大的信号强度意味着所述抗体对该蛋白的特异性大于具有更小富集倍数或更小信号强度的蛋白。在某些实施方案中,所述鉴别特异性地结合抗体的蛋白的方法包括:i)选择试验抗体;ii)从生物样品制备细胞裂解物的第一和第二制品,其中所述第一和第二制品是几乎相同的;iii)使所述第一细胞裂解物与所述试验抗体接触,并使所述第二细胞裂解物与第二抗体接触,和免疫沉淀所述抗体和它们的蛋白结合配偶体;iv)通过质谱法分析所述免疫沉淀的试验和第二抗体和它们的蛋白结合配偶体;v)在x-或y-轴上绘制通过质谱法鉴别为结合所述试验抗体的每种蛋白的强度和/或富集倍数,和在相对轴上绘制通过质谱法鉴别为结合所述第二抗体的每种蛋白的强度或富集倍数;和vi)鉴别特异性地结合所述试验和第二抗体的蛋白,其中a.特异性地结合所述试验和第二抗体的蛋白是不会表现出与所述试验和第二抗体相等或几乎相等的结合的那些(在绘制时离开对角线的那些);b.特异性地结合所述试验抗体的蛋白在沿着y-轴绘制时在上方离开对角线,或在沿着x-轴绘制时在下方离开对角线;和c.特异性地结合所述第二抗体的蛋白在沿着y-轴绘制时在上方离开对角线,或在沿着x-轴绘制时在下方离开对角线。在某些方面,所述抗体结合超过一种靶蛋白。在某些实施方案中,根据它对它的靶蛋白的特异性来表征所述抗体,其中一种靶蛋白相对于另一种靶蛋白更大的富集倍数或更大的信号强度意味着所述抗体对该蛋白的特异性大于具有更小富集倍数或更小信号强度的蛋白。在某些实施方案中,所述试验和第二抗体是相同的,并在与所述抗体接触之前,将饱和所述试验抗体上的蛋白结合位点所需要的过量蛋白加入所述第一细胞裂解物,但是不加入所述第二细胞裂解物。特异性地结合所述试验和第二抗体的蛋白是不会表现出与所述试验和第二抗体相等或几乎相等的结合的那些(在绘制时离开对角线的那些)。在所述方法中使用的生物样品可以是在细胞培养物、组织、血液、血清、血浆、脑脊液、尿、滑液、腹膜液或其它生物流体中的细胞。所述生物样品在与抗体接触之前可以被刺激或活化,且所述刺激可以是使用生长因子、激素、毒素、抑制剂或其它试验分子。在某些实施方案中,所述细胞培养物中的细胞是原代或二代细胞、永生细胞或干细胞。在某些方面,所述细胞选自a549、bt549、hct116、hek293、hela、hepg2、hs578t、lncap、mcf7、nih3t3、skmel5或sr。在某些实施方案中,所述细胞是在nci60集合中。在某些方法实施方案中,将所述细胞裂解物分级分离。分级分离可以减小所述细胞裂解物的复杂性,从而允许在质谱法中的更准确检测。分级分离可以包括基于通过分子量、大小、疏水性、离子交换结合、亲水相互作用或亲和富集的分离而降低消化的细胞裂解物的复杂性。在某些实施方案中,通过下式确定富集倍数其中靶蛋白是与所述试验抗体结合的蛋白。在某些实施方案中,与在所述细胞裂解物中的蛋白相比,所述特异性地结合所述抗体的蛋白富集了约5倍或更高。在某些方面,与在所述细胞裂解物中的蛋白相比,所述富集倍数是约5、10、15、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95、100、110、120、130、140、150、160、170、180、190、200或大于200倍。在包含两种抗体的方法中使用的第二抗体可以是i)被认为结合与所述试验抗体相同的一种或多种蛋白的子集的抗体;或不被认为结合与所述试验抗体相同的一种或多种蛋白的抗体。在某些方面,所述第二抗体是异形体特异性抗体或泛特异性抗体。在包含绘图的实施方案中,所述图可以是散布图,且可以定量强度。所述定量可以无标记地或经由代谢或化学质量标记技术完成。所述定量可以测量肽信号强度,或使用例如无标记蛋白定量(lfq)、基于强度的绝对蛋白定量(ibaq)、波谱计数、序列覆盖、独特肽的数目或蛋白库。在某些实施方案中,确定和绘制所述富集倍数。在某些实施方案中,通过测序进一步表征所述鉴别的蛋白。在某些实施方案中,将所述鉴别的蛋白翻译后修饰(ptm)。翻译后修饰包括、但不限于磷酸化、糖基化、泛素化、亚硝酰化、甲基化、乙酰化、脂质化和蛋白酶解。在某些实施方案中,所述鉴别的相互作用配偶体、异形体或修饰可以是指不同抗体的可辨别表位。在某些实施方案中,包括一种用于确定超过一种抗体的相对性能的方法。在某些实施方案中,所述方法包括:将所述试验抗体或所述试验和第二抗体的性能彼此对比,和基于信号强度、富集倍数、序列覆盖、独特肽的数目或波谱计数将它们的性能排序,其中在以下情况下就特定靶蛋白而言一种抗体的性能优于另一种抗体:它的信号强度、富集倍数、序列覆盖、独特肽的数目或波谱计数大于另一种抗体。该相对抗体性能对比的结果可能指示对所述靶标的相对抗体亲和力。在某些实施方案中,所述质谱法是串联质谱法,任选地使用数据依赖性获取。在某些实施方案中,所述质谱法使用数据非依赖性获取。在某些方面,在质谱法之前消化所述免疫沉淀的抗体-靶蛋白。所述消化可以包含蛋白酶或化学消化,且可以是单次的或连续的。在某些实施方案中,所述蛋白酶消化使用胰蛋白酶、糜蛋白酶、aspn、gluc、lysc、lysn、argc、蛋白水解酶k、胃蛋白酶、梭菌蛋白酶、弹性蛋白酶、gluc碳酸氢盐、lysc/p、lysnpromisc、蛋白内肽酶、葡萄球菌蛋白酶或嗜热菌蛋白酶。在某些实施方案中,所述化学裂解使用cnbr、氧碘基苯甲酸盐或甲酸。在某些方面,所述方法包括在免疫沉淀之后或在消化之后且在质谱法之前脱盐。本发明进一步包括用于表征抗体(例如,高亲和力抗体)的组合物和方法,所述方法包括:(a)确定所述抗体对抗原的亲和力,和(b)确定所述抗体对所述抗原的选择性,其中使用免疫沉淀-质谱法(ip-ms)确定所述抗体的亲和力和/或所述抗体的选择性,且其中如下产生所述免疫沉淀物:在允许所述抗体和所述抗原之间形成所述免疫沉淀物的条件下使所述抗原与所述抗体接触。在某些情况下,通过检测与细胞裂解物中的分子(例如,蛋白)的结合,可以确定所述抗体对它的结合配偶体的选择性。进一步,所述细胞裂解物可以源自表达所述抗原的所有部分的物种的细胞。另外,通过细胞裂解物的蛋白质印迹可以确定选择性。使用表达来自超过一个物种的抗原的所有部分的细胞可以确定选择性。类似地,通过来自超过一个物种的细胞裂解物的蛋白质印迹可以确定选择性。在某些情况下,可以如下确定选择性:使用所述抗原产生细胞提取物的免疫沉淀物,随后鉴别和/或定量存在于所述免疫沉淀物中的两种或更多种非抗体分子。进一步,可以在所述免疫沉淀物中计算抗原/非抗体分子的比率。本发明进一步包括用于制备匹配的抗体集合、以及匹配的集合本身的方法。这样的方法可以包括:(a)确定每种抗体对在细胞裂解物中的它的各种抗原的亲和力,(b)确定每种抗体对在细胞裂解物中的它的各种抗原的选择性,和(c)选择抗体以形成所述匹配的集合,其中使用免疫沉淀-质谱法(ip-ms)确定所述抗体的亲和力和/或所述抗体的选择性,且其中所述匹配的集合由两种或更多种抗体组成,就存在于所述细胞裂解物中的它的各种抗原而言,每种抗体具有至少100倍(例如,约100倍至约1,000倍、约200倍至约1,000倍、约300倍至约1,000倍、约400倍至约1,000倍、约5倍至约1,000倍、约100倍至约800倍、约100倍至约650倍、约100倍至约500倍、约200倍至约750倍等)富集的选择性。在某些情况下,匹配的集合中的两种或更多种抗体可以具有彼此1个对数(log)的对它们各自的抗原的亲和力。进一步,本发明的匹配的集合可以含有约2至约50(例如,约3至约10、约2至约30、约2至约20、约3至约15、约3至约40等)种抗体。在某些情况下,匹配的集合的抗体可以结合有关的靶抗原。进一步,有关的靶抗原可以是相同蛋白的翻译前和翻译后修饰形式。在特定情况下,有关的靶抗原可以是未磷酸化的蛋白的翻译前修饰形式和磷酸化的蛋白的翻译后修饰形式。在另外的方面,本发明包括用于确定抗体的选择性的方法。在某些情况下,这样的方法包括:(a)在允许所述抗体和细胞提取物中的一种或多种抗原之间形成免疫沉淀物的条件下使所述抗体与细胞提取物接触,(b)收集在步骤(a)中形成的免疫沉淀物,和(c)通过质谱法鉴别存在于所述免疫沉淀物中的一种或多种非抗体分子,其中所述细胞提取物含有来自两个或更多个细胞类型或两个或更多个物种的一个或多个细胞类型的细胞组分。在某些情况下,所述两个或更多个细胞类型可以来自相同物种。进一步,所述细胞类型可以得自两种或更多种以下组织:(a)肌肉组织,(b)结缔组织,c)神经组织,和(d)上皮组织。在特定情况下,所述结缔组织可以是血液。另外,所述两个或更多个细胞类型可以来自不同物种。进一步,来自不同物种的两个或更多个细胞类型可以得自来自每个物种的两种或更多种组织。本发明还包括用于确定抗体的选择性的方法。这样的方法可以包括:(a)在允许所述抗体和所述两种或更多种蛋白中的一种或多种之间形成免疫沉淀物的条件下,使所述抗体与两种或更多种蛋白接触,(b)收集在步骤(a)中形成的免疫沉淀物,和(c)通过质谱法定量存在于所述免疫沉淀物中的各种蛋白的量。本发明还包括组合物,其包含:(a)从一个或多个细胞类型得到的一种或多种细胞提取物,和(b)一种或多种外源地添加的抗体,其中所述细胞类型来自两种或更多种不同物种,以及使用这样的组合物的方法。进一步,可以从细胞裂解物制备所述细胞提取物中的至少一种。另外,通过裂解两种或更多种细胞类型的细胞可以得到所述细胞裂解物,随后离心(例如,在大于或等于10,000xg,至少15分钟)得到的裂解物以除去不溶物。进一步,所述抗体中的至少一种可以对存在于所述细胞提取物中的至少一种蛋白具有亲和力。本发明还包括针对与靶分子(例如,靶抗原)以外的分子的结合活性筛选抗体的方法。这可以通过使用来自不表达所述靶分子的细胞的细胞提取物完成。作为例子,使用从在靶抗原表达方面存在差异的细胞系衍生出的两种细胞提取物,可以筛选针对靶蛋白的抗体。可能已知所述细胞系之一表达靶抗原,且可能相信或已知另一种细胞系不表达所述抗原。作为更具体的例子,可以在一个细胞系中破坏或抑制编码靶抗原的基因。通过rnai的应用,可以执行表达的抑制。通过基因编辑技术(例如,同源重组、锌指-foki核酸酶、crispr核酸酶、tal核酸酶等),可以执行所述基因的破坏。因而,本发明包括用于鉴别对靶分子具有高水平的结合特异性的抗体的组合物和方法,以及通过这样的方法鉴别的抗体。本发明还包括用于鉴别抗体的方法,所述抗体选择性地结合得自不同物种的细胞的靶分子。这样的方法可以包括:(a)在允许所述抗体和存在于每种细胞裂解物中的一种或多种靶分子之间形成形成两种或更多种免疫沉淀物的条件下,使所述抗体与从不同物种的细胞产生的两种或更多种细胞裂解物接触,(b)从每种细胞裂解物收集所述免疫沉淀物,和(c)通过质谱法确定每种免疫沉淀物中的靶分子的纯化倍数。这样的细胞可以源自一个或多个选自以下的物种:(a)智人、(b)穴兔、(c)小家鼠和(d)褐家鼠。进一步,可以响应于在从其得到所述细胞裂解物的不同物种之间保守的表位或蛋白而产生在本发明的方面中使用的抗体。另外,所述表位可以来自选自以下的类别中的蛋白:(a)热激蛋白、(b)聚合酶、(c)细胞表面受体、(d)转录因子、(e)激酶、(f)去磷酸化酶、(g)膜相关的转运蛋白和(h)锌指蛋白。另外的目标和优点将在下面的描述中部分地阐述,且将部分地从所述描述显而易见,或可以通过实践获知。将借助于在所附权利要求中特别指出的要素和组合来实现和得到所述目标和优点。应当理解,前面的一般描述和下面的详细描述仅仅是示例性的和解释性的,且不是权利要求的限制。附图(其并入本说明书并构成本说明书的一部分)图解了几个实施方案,并与描述一起用于解释本文描述的原理。附图说明图1显示了通过免疫沉淀和质谱测定分析(ip-ms)进行抗体验证的实验工作流。图2呈现了通过深质谱测定分析从nci60细胞系集合的hepg2、a549、mcf7、bt549和lncap细胞鉴别出的蛋白的数目的维恩图。图3a-3h提供了细胞系之间的蛋白鉴别和定量。图3a显示了在未分级分离的样品中在12个细胞系之间的e-钙粘着蛋白(cdh1)的对比,而图3b显示了用于更深蛋白质组分析的分级分离的样品中的cdh1的对比。图3c显示了在未分级分离的样品中在12个细胞系之间的n-钙粘着蛋白(cdh2)蛋白表达的对比,而图3d显示了用于更深蛋白质组分析的分级分离的样品中的cdh2的对比。图3e-3h显示了在未分级分离的mcf7样品中(图3e)、在分级分离的mcf7样品中(图3f)、在未分级分离的a549样品中(图3g)和在分级分离的a549样品中(图3h)检测到的表达的蛋白的分布。在图3e-3h中,突显了cdh1和chd2的表达水平,用箭头指示靶蛋白的表达水平。图4a-4b提供了免疫沉淀两种靶标的抗体的对比。在图4a中,在多天从含有指示的抗体的bt549细胞裂解物免疫沉淀p53蛋白并使用三种最强烈肽的ms强度定量。在图4b中,在多天从含有指示的抗体的mcf7细胞裂解物免疫沉淀cdh1并使用鉴别的肽的数目(y-轴和线)和通过使用无标记定量(lfq)值计算的cdh1(来自未分级分离的和分级分离的mcf7细胞裂解物)的富集倍数(垂直条)来定量。星号突显了注解为通过ip/蛋白质印迹进行ip验证的抗体。图5a-5g提供了关于通过ip-ms捕获和定量的特定蛋白的过滤和可视化的信息。图5a显示了在用阳性和阴性对照抗体免疫沉淀之后定量的蛋白簇的散点图。“阴性对照”指示,对照ip(即,使用非特异性抗体的ip)增加了蛋白的丰度。“背景”指示,对于对照ip(即,使用非特异性抗体的ip)和靶ip(即,使用靶标特异性抗体的ip)而言,以类似的方式增加了蛋白的丰度。“阳性对照”指示,靶ip增加了蛋白的丰度,而对照ip没有增加该相同蛋白的丰度。图5b显示了被阳性和阴性对照抗-cdh1抗体捕获并用ms定量的蛋白的散点图结果。将使用ibaq定量相对于mcf7裂解物的富集倍数结果着色。图5c显示了在ip和抗-cdh1抗体以后基于ibaq分析的富集倍数数据。图5d显示了富集>50倍的特异性地捕获的蛋白来自string的相互作用分析。图5e显示了与不会免疫沉淀的泛抗-钙粘着蛋白抗体pa5-16481相比,来自含有泛抗-钙粘着蛋白抗体pa1-37199的a549细胞裂解物的钙粘着蛋白靶标和另外蛋白的富集倍数,一起注解了已知的相互作用物(interactors)。图5f显示了来自string数据库的相互作用简图,所述string数据库突显了在用pa2-37199进行ip以后富集的蛋白。图5g显示了基于特异性地富集的蛋白的列表的geneontology(go)术语富集的分析。图6a-6d提供了几种抗体免疫沉淀cdkn1a的能力的对比。在图6a中,将cdkn1a蛋白从含有指示的抗体的hct116细胞裂解物免疫沉淀,并使用三种最强烈肽的ms强度定量。图6b显示了用抗体pa1-30399对cdkn1a靶标和另外蛋白的富集,并注解了已知的相互作用物。图6c显示了来自string数据库的相互作用简图,所述string数据库突显了在用pa1-30399进行ip以后富集的蛋白。图6d显示了基于特异性地富集的蛋白的列表的geneontology(go)术语富集的分析。图7a和7b呈现了使用多种erbb2-特异性抗体的ms数据。图7a呈现了使用maxquant定量分析软件(thermofisher)相对于未分级分离的样品在抗-erbb2免疫沉淀以后使用各种抗体的富集倍数数据。图7b呈现了使用maxquant定量分析软件相对于proteomediscoverer(pd1.4,thermofisher)软件确定的erbb2肽的数目。在每个条的右侧的数字指示了精确值。posctl=阳性对照。图8a、8b和8c呈现了使用多种ctnnb1-特异性抗体以后的富集倍数结果。图8a呈现了使用maxquant定量分析软件(maxplanckinstitute)相对于分级分离的样品在抗-ctnnb1免疫沉淀以后使用各种抗体的富集倍数数据。图8b呈现了来自string数据库的ctnnb1的已知相互作用物的网络相互作用简图。图8c呈现了对于用每种抗-ctnnb1抗体富集的每种蛋白相互作用物而言肽的数目的二维分级群聚结果。图9a和9b呈现了nfkb1a和它的相互作用配偶体的富集倍数。图9a显示了来自lncap细胞裂解物的nfkb1a和多种相互作用配偶体的富集倍数。图9b显示了在nfkb1a的免疫捕获(带圆圈)以后通过ip-ms检测的蛋白的string数据库网络相互作用简图。图10a和10b呈现了在纯化的抗体中的污染性肽抗原的检测。图10a显示了在ip-ms分析之前与牛血清白蛋白混合的纯抗体制品中的靶蛋白水平。图10b显示了从hek293细胞富集的三种最强烈肽信号的轻和重肽信号强度,所述hek293细胞生长在重赖氨酸(+8da)和精氨酸(+10da)同位素标记的氨基酸中。具体实施方式定义本描述和示例性实施方案不应当视作限制性的。对于本说明书和所附权利要求书的目的来说,除非另有说明,否则在本说明书和权利要求书中使用的所有表达量、百分比或比例的数字和其它数值应理解为在所有情况下被术语“约”修饰,达到它们尚未如此修饰的程度。因此,除非相反说明,否则在以下说明书和所附的权利要求书中阐述的数字参数是近似值,其可以随寻求得到的期望性能而变化。最低限度,且不是企图限制等同原则在权利要求的范围上的应用,每个数值参数应该至少根据记录的有效数字的个数且通过应用普通的舍入技术来解释。应该指出,当用于说明书和所附权利要求书时,单数形式“一个”、“一种”和“所述”和任何词语的任何单数应用包括复数指示物,除非清楚地和明确地限于一种所指物。本文中使用的术语“包括”和它的语法变体意图是非限制性的,使得列表中项目的列举不是可以置换或加入列出的项目的其它类似项目的排除。本文中使用的“蛋白”、“肽”和“多肽”到处互换使用以表示氨基酸的链,其中每个氨基酸通过肽键与下一个连接。在某些实施方案中,当氨基酸的链由约2至40个氨基酸组成时,使用术语“肽”。但是,术语“肽”不应当视作限制性的,除非明确地指出。术语“抗体”以最宽的含义使用且包括各种抗体结构,包括、但不限于单克隆抗体、多克隆抗体、多特异性抗体(诸如双特异性抗体)和抗体片段,只要它们表现出期望的免疫沉淀活性。这样,术语抗体包括、但不限于能够结合抗原的片段,诸如fv、单链fv(scfv)、fab、fab'、二-scfv、sdab(单结构域抗体)和(fab')2(包括化学连接的(fab')2)。抗体的木瓜蛋白酶消化会产生两个相同的抗原结合片段(称为“fab”片段,各自具有单个抗原结合位点)和残留的“fc”片段。胃蛋白酶处理会产生具有两个抗原结合位点的(fab')2片段。术语抗体也包括、但不限于嵌合抗体、人源化抗体和多个物种(诸如小鼠、山羊、马、绵羊、鸡等)的抗体。此外,对于本文提供的所有抗体构建体,也涵盖具有来自其它生物体的序列的变体,诸如cdr-移植抗体或嵌合抗体。抗体片段也包括单链scfv、串联二-scfv、双抗体、串联三-sdcfv、微抗体等的定向。抗体片段也包括纳米抗体(sdab,具有单个单体结构域(诸如一对重链可变结构域)而没有轻链的抗体)。在某些实施方案中,抗体片段乐意被称作是特异性物种(例如,人scfv或小鼠scfv)。这表示非-cdr区域的至少部分的序列,而不是所述构建体的来源。通过参考名称和目录索引来提及所述抗体。掌握该名称和目录信息的熟练技术人员能够确定所述抗体的序列,因此所述方法包括具有参比抗体的至少部分序列的任何抗体,只要所述抗体维持它的免疫沉淀其抗原蛋白的能力。质谱法(ms)是用于基于蛋白的质荷比(m/z)来分析蛋白的主要技术。ms技术通常包括化合物的电离和任选的所得离子的片段化,以及检测和分析离子和/或片段离子的m/z并随后计算对应的离子质量。“质谱仪”通常包括电离器和离子检测器。“质谱法(massspectrometry)”、“质谱(massspec)”、“质谱学(massspectroscopy)”和“ms”通篇互换使用。“靶向质谱法”(在本文中也被称作“靶向质谱”、“靶向ms”和“tms”)会增加质谱分析的速度、灵敏度和定量精确度。非靶向质谱法(有时被称作“数据依赖性的扫描”、“发现ms”和“dms”和靶向质谱)的相似性在于:在每个中,分析物(蛋白、小分子或肽)从与液相色谱仪器连接的反相柱注入或洗脱,并且通过电喷射电离转化成气相离子。将分析物在质谱中片段化(一个被称为串联ms或ms/ms的过程),并且使用片段和母体质量来确定分析物的身份。以数据依赖性方式(dda)基于洗脱肽的强度可以触发发现ms的肽片段化,或可以将片段化程序化为以数据非依赖性方式(dia)通过在一个或多个质量范围内的肽离子的分离和片段化而发生,诸如通过在ms1波谱中扫描、分离和片段化m/z窗口。发现ms会分析ms/ms片段化谱的整个内容。相反,在靶向质谱法中,使用参考谱来引导分析仅仅数个选择的片段离子而不是整个内容。概述本发明部分地涉及利用免疫沉淀和质谱法验证抗体的组合物和方法。根据本发明,可以与其它抗体一起或相对于其它抗体来分析抗体。进一步,通过对特定抗原和/或表位的亲和力和/或特异性可以表征抗体。本发明的一个目标是鉴别具有特定特征的抗体,所述特定特征使得它们在基于超过一种(例如,2、3、4、5种等)抗体的方法(例如,免疫荧光、蛋白质印迹等)中是有用的。另一个目标是鉴别在一种或多种应用(例如,elisa)中具有超过它们的等同物的增强适合性的抗体。本文公开的方法可以应用于任何类型的ms分析。所述方法不受使用的具体设备或分析限制。用于分析样品的m/z的任何设备的应用将被包括在质谱法的定义中。可以使用的ms分析和/或设备的非限制性例子包括电喷射电离、离子迁移率、飞行时间、串联、离子阱、dda、dia和轨道离子阱。所述方法既不受在ms分析中使用的电离器或检测器的类型限制,也不受ms的具体构型限制。所述方法不限于与具体设备或软件一起使用。所述方法不限于在实施例中描述的设备和软件。本发明部分地涉及用于评估抗体对它们的对应配体(例如,蛋白)的亲和力和特异性的组合物和方法。在某些方面,本发明包括在免疫沉淀样品中的配体定量。本发明还包括通过不同样品的免疫沉淀得到的配体的量的对比。在这样的情况下,所述对比经常是通过对比存在于两个免疫沉淀样品中的配体的量,从而导致富集倍数的确定。进一步,在某些情况下,可以确定其它样品与其对比的“基准”。例如,可以将三个样品彼此对比,其中评估三种不同抗体中的每一种所结合的蛋白的量。因而,在该实施例中,可以将单个样品(例如,细胞裂解物)分成三个等分试样。可以在允许形成免疫沉淀物的条件下将已知结合所述蛋白的不同抗体加入每个等分试样。然后可以测量存在于三种免疫沉淀物中的蛋白的量并彼此对比。在这样的情况下的基准可以是三种抗体中的任一种,或它可以是例如产生在其中具有最小量的蛋白的免疫沉淀物的抗体。一个更具体的实施例如下。假定所述配体是p53蛋白,并且所述p53蛋白存在于hela细胞裂解物中(例如,将所述细胞裂解,并将不溶物在4℃在10,000xg沉淀5分钟)。将裂解物分成三个等分试样,并将抗体1、2和3加入每个等分试样以产生免疫沉淀物。然后通过ms确定,在向其中加入抗体1、2和3的每个等分试样中分别存在6.2μg、1.2μg和9.5μgp53。如果使用抗体2作为基准,那么抗体1产生5.2富集倍数且抗体3产生7.9富集倍数。因而,本发明包括通过一个或多个功能特征使抗体彼此对比的方法。在该实施例中,所述功能特征是所述抗体沉淀的抗原的量。进一步,可以执行多个重复来产生用于评估和对比抗体特征的统计数据。另外,使用相同的样品(例如,相同的hela细胞裂解物)或不同的样品(例如,从不同的hela细胞培养物制备的裂解物),可以产生重复。使用以上实施例作为参考点,可以在允许形成免疫沉淀物的条件下用所有三种抗体试验三种不同裂解物,使用p53蛋白的量的平均值来确定富集倍数。本发明因而包括通过ip-ms将两种或更多种抗体彼此对比的组合物和方法。该对比经常针对进行对比的抗体的亲和力和特异性。用于评估抗体亲和力的一个试验系统可能涉及纯化的配体(例如,蛋白)的应用。作为一个例子,使用纯化的蛋白的多个等分试样可以建立免疫沉淀反应,并可以将相同量的已知结合所述蛋白的不同抗体加入每个等分试样。然后可以通过ms分析所述免疫沉淀物以确定存在的蛋白的量和/或各种抗体所结合的蛋白的区域。这样的对比将产生与亲和力有关的数据,但是产生很少与特异性有关的数据。特异性的一种指示是生物信息学,因为所述抗体所结合的蛋白区域的鉴别允许检索蛋白序列数据库以鉴别具有类似或相同氨基酸序列的蛋白、以及含有这样的蛋白的生物体和表达这样的蛋白的细胞。本发明因而部分地包括用于对比不同抗体与纯化的蛋白的结合特征的方法。可以使用这样的对比来确定各种抗体与抗原的对比亲和力。本发明的方法也可以用于单独地或与其它抗体对比地测量抗体从抗原的混合物中沉淀抗原的能力。作为一个例子,可以将靶抗原与类似的分子混合以测量所述抗体从有关的分子区分靶抗原的能力。一个例子是,其中人蛋白是靶抗原。可以将人蛋白与对应的小鼠蛋白或对应的小鼠和大鼠蛋白混合。一个更具体的例子如下。智人(人)p53是393氨基酸蛋白,且小家鼠(小鼠)p53是381氨基酸蛋白。进一步,这两种蛋白具有约71%氨基酸序列同一性,大多数序列同一性是在两种蛋白的中央部分。可以响应于人p53蛋白而产生抗体,且可以如下评估所述抗体的区分该蛋白的人和小鼠形式的能力:混合两种蛋白,并测量所述抗体的沉淀人p53蛋白的能力。假定两种蛋白以1:1比例混合且响应于人p53蛋白而产生的抗体同样地沉淀两种蛋白。换而言之,当使1:1的人和小鼠p53蛋白的混合物与响应于人p53蛋白而产生的抗体接触时,那么沉淀的人:小鼠p53蛋白的比例是所述抗体对两种蛋白的差别亲和力和/或特异性的量度。例如,如果沉淀物中p53蛋白的比例是2:1,那么所述抗体对小鼠p53蛋白具有某种特异性,但是对人p53蛋白具有高2倍的亲和力。本发明因而包括针对具有类似氨基酸序列和/或构象的区域的抗原来评估靶抗原特异性的组合物和方法。本发明包括用于对比抗体的以下能力的组合物和方法:在有关抗原之间和在结合单一抗原的两种或更多种抗体之间区分,和在两种或更多种有关抗原之间区分。例如,使响应于特定抗原而产生的抗体或其子部分(例如,表位)与超过一种有关抗原接触,随后免疫沉淀。然后确定存在于所述沉淀物中的有关抗原的量并彼此对比。由此可以确定所述抗体在两种抗原之间区分的能力。可以以相同比例或以不同比例组合所述抗原和有关的抗原。例如,当所述抗体沉淀比另一种抗原显著更多的一种抗原(例如,约5倍至约50倍、约10倍至约50倍、约15倍至约50倍、约5倍至约40倍、约10至约40倍等)时,可以使用不同比例。在其中抗体对一种抗原的亲和力实质上高于另一种抗原的情况下,可以制备试验溶液来平衡差别亲和力。例如,如果抗体沉淀比第二抗原多10倍的第一抗原,那么所述试验溶液可以含有比第一抗原多10倍的第二抗原。在这样的情况下,预期免疫沉淀物含有大致相同量的两种抗原。这类方法允许抗体亲和力和/或特异性表征的“细调”。因而,本发明包括关于对靶抗原的亲和力和/或特异性而对比两种或更多种抗体的组合物和方法。在某些实施方案中,可以在片段化(例如,消化)之前将所述免疫沉淀的蛋白还原和烷基化。已经被还原和烷基化的样品可以包含修饰,诸如对半胱氨酸残基的修饰(例如,cam)。可以任选地在质谱法分析之前将所述样品脱盐。包括酶消化和化学消化。酶消化包括、但不限于使用蛋白酶(例如,胰蛋白酶、糜蛋白酶、aspn、gluc、lysc、lysn、argc、蛋白水解酶k、胃蛋白酶、梭菌蛋白酶、弹性蛋白酶、glucbiocarb、lysc/p、lysn、蛋白内肽酶、葡萄球菌蛋白酶或嗜热菌蛋白酶)的消化。化学消化包括使用例如cnbr、氧碘基苯甲酸盐和甲酸。在某些实施方案中,所述片段化方案使用ms级商购可得的蛋白酶。可用于消化样品的蛋白酶的例子包括胰蛋白酶、内蛋白酶gluc、内蛋白酶argc、胃蛋白酶、糜蛋白酶、lysn蛋白酶、lysc蛋白酶、gluc蛋白酶、aspn蛋白酶、蛋白水解酶k和嗜热菌蛋白酶。在某些实施方案中,使用不同蛋白酶的混合物,并在消化之后将各个结果组合在一起和分析。在某些实施方案中,所述消化是不完全的,以便看到较大的重叠肽。在某些实施方案中,用ides、idez、胃蛋白酶或木瓜蛋白酶进行抗体消化以产生大的抗体结构域用于“中-下游”蛋白表征。在某些实施方案中,所述片段化方案使用修饰的胰蛋白酶。在某些实施方案中,可以使用10:1、20:1、25:1、50:1、66:1或100:1的蛋白:蛋白酶比例(w/w)。在某些实施方案中,以约100ng/ml-1mg/ml、或约100ng/ml-500μg/ml、或约100ng/ml-100μg/ml、或约lμg/ml-1mg/ml、或约lμg/ml-500μg/ml、或约lμg/ml-100μg/ml、或约l0μg/mg-1mg/ml、或约10μg/mg-500μg/ml、或约l0μg/mg-100μg/ml的浓度使用所述胰蛋白酶。在某些实施方案中,所述消化步骤持续10分钟至48小时、或30分钟至48小时、或30分钟至24小时、或30分钟至16小时、或1小时至48小时、或1小时至24小时、或1小时至16小时、或1-8小时、或1-6小时、或1-4小时。在某些实施方案中,所述消化步骤是在20℃至45℃之间、或在20℃至40℃之间、或在22℃至40℃之间、或在25℃至37℃之间的温度温育。在某些实施方案中,所述消化步骤是在37℃或30℃温育。在某些实施方案中,包括一个步骤来结束所述消化步骤。结束消化方案的步骤可以是加入停止溶液或离心或沉淀样品的步骤。在某些实施方案中,所述消化继之以胍基化。在某些实施方案中,所述片段化方案包括蛋白凝胶的使用。在某些实施方案中,所述片段化方案包括凝胶内消化。用于执行凝胶内消化的一种示例性的商购可得的试剂盒是in-geltrypticdigestionkit(thermofisher目录号89871)。在某些实施方案中,在溶液中进行所述片段化方案。用于执行溶液中消化的一种示例性的商购可得的试剂盒是in-solutiontrypticdigestionandguanidiationkit(thermofisher目录号89895)。在某些实施方案中,所述片段化方案使用珠子。在某些实施方案中,所述片段化方案包含在珠子上消化。在某些实施方案中,使用琼脂糖珠子或蛋白g珠子。在某些实施方案中,使用磁珠。在某些实施方案中,在ms分析之前,使用液相色谱法将蛋白样品分离。在某些实施方案中,在ms分析之前,使用液相色谱法将片段化的样品分离。在某些实施方案中,直接通过ms来分析洗脱的完整蛋白以鉴别完整质量和片段化产物用于完整蛋白鉴别和表征。在某些实施方案中,已知量的对照蛋白和/或肽的同位素标记的(例如,重同位素标记的)形式可以用作内部标准品用于捕获和消化效率的绝对定量和标准化。本发明还包括用于鉴别与其它分子相互作用的分子的组合物和方法。这些分子可以属于多种类型,包括化学实体和生物分子。作为一个例子,地高辛是可以被抗体结合的化学实体。例如,可以将地高辛引入细胞,然后可以将细胞的内容物暴露于抗-地高辛抗体并可以鉴别存在于所述细胞内的分子。与这些内容一致,本发明进一步包括使用例如ip-ms鉴别适合这样的应用的抗体的方法。本发明因而包括用于检测相互作用组和蛋白质组相互作用的组合物和方法,且包括与在特定细胞类型内通常不产生的分子(例如,外源地引入的化学实体)的相互作用。在某些情况下,本发明不包括用于检测在以下途径中的一个或两个中的相互作用组和蛋白质组相互作用的组合物和方法:akt-mtor途径和/或ras途径。在某些情况下,本发明不包括用于检测与在以下文献中阐述的一种或多种蛋白有关的相互作用组和蛋白质组相互作用的组合物和方法:2017年3月13日提交的pct/us2017/022062;2016年3月14日提交的美国临时申请62/308,051;和2017年2月28日提交的美国临时申请62/465,102。已知细胞相互作用(例如,细胞内相互作用)随着细胞条件而变化。这样的细胞条件的例子包括热环境(例如,“热激”)、细胞周期的阶段、细胞表面受体刺激、细胞突变/改变(例如,疾病状态)等。本发明因而包括用于检测细胞相互作用的组合物和方法,以及用于选择适合于检测细胞相互作用的抗体的组合物和方法。作为例子,真核伴侣蛋白tric/cct是参与蛋白折叠的杂寡聚体复合物,且据估计与多达10%的细胞溶质蛋白相互作用(lopez等人,“themechanismandfunctionofgroupiichaperonins,”j.mol.biol.,427:2919-2930(2015)。许多被认为结合tric/cct复合物的蛋白发生细胞周期调节的表达。进一步,认为tric/cct复合物改变(例如,突变)与许多疾病状态(包括亨廷顿病)有关。作为一个例子,cdc20是分裂后期促进复合物的一种组分,其被认为是在不同类型的细胞周期调节(包括细胞周期表达、蛋白酶解和磷酸化)下。进一步,认为该蛋白与tric/cct复合物有关。使用以上作为例子,本发明包括用于鉴别分子和分子复合物之间的细胞内相互作用的组合物和方法。在某些情况下,这样的方法包括:(1)在允许抗体和目标细胞组分之间形成免疫沉淀物的条件下,使细胞裂解物与针对目标细胞组分的抗体接触,和(2)分析所述免疫沉淀物以鉴别存在于其中的一种或多种细胞组分。在许多情况下,两种或更多种细胞组分中的一种将是目标细胞组分。进一步,在许多情况下,可以通过质谱法来执行分析,和/或通过质谱法(例如,使用本文所述的方法)将使用的抗体鉴别为适合所述应用。许多类型的实验落在本发明范围内。例如,在有些实验中,针对分子相互作用物的存在来对比两个细胞样品。作为具体例子,可以使对tric具有特异性的抗体与从两种不同细胞类型衍生出的细胞裂解物接触。这些细胞类型可以是来自罹患亨廷顿病的个体的脑组织细胞(例如,来自黑质)以鉴别与tric/cct复合物相互作用的蛋白和其它细胞分子。然后可以在所述相互作用物和存在于不同样品中的各种相互作用物的量之间做出对比。因而,可以在不同的样品上执行定性和定量对比研究。这样的对比研究可以用于例如鉴别与疾病状态和诊断方法有关的相互作用。在本发明范围内可以进行的另一类实验是在其中研究相同类型的细胞的实验。其一个例子是细胞周期研究,其中将对照细胞裂解物与一种或多种试验细胞裂解物进行对比。作为一个例子,地高辛是结合钠钾腺苷三磷酸酶(na+/k+atp酶)的化学实体,所述钠钾腺苷三磷酸酶是存在于许多组织(包括心肌)中的蛋白复合物。可以使心脏细胞与地高辛接触,然后与抗-地高辛抗体接触,随后鉴别和定量存在于免疫沉淀物中的细胞分子。进一步,可以使心脏细胞与另外的化学实体接触,随后分析以对比总na+/k+atp酶复合物、所述复合物的各种组分、或被所述复合物免疫沉淀的其它蛋白的量是否增加、减小或保持相同。在某些情况下,可以看到一种或多种生物分子可能以增加的或相同的量沉淀,而一种或多种其它生物分子可能以更低的量沉淀。当使细胞与另外的化学实体接触时可以看到该效应,所述另外的化学实体(1)增强或(2)干扰或破坏蛋白-蛋白相互作用。可以执行的另一类实验是,其中基于细胞类型、发育阶段或细胞周期来鉴别蛋白相互作用物。出于例证的目的使用细胞周期,在使细胞同步化的情况下可以产生细胞样品。然后可以从这些细胞产生提取物,随后根据本发明的方法分析。在具体方面,可以在细胞周期的两个或更多个不同部分(例如,g1、s、g2或m)将细胞同步化,此后将从同步化的细胞产生细胞裂解物。然后可以使用例如对tric具有特异性的抗体从细胞裂解物产生免疫沉淀物。然后可以使用例如质谱法鉴别存在于所述沉淀物中的蛋白。进一步,然后可以使用存在于沉淀物中的蛋白来定性和定量测量在细胞周期的不同阶段中存在差异的相互作用物。可以设计类似的另外实验,其中分析从超过两种细胞类型衍生出的样品。作为一个例子,可以分别产生来自同步化(在gl、s、g2和m)的细胞、以及未同步化的细胞的细胞裂解物,随后使用对tric具有特异性的抗体产生免疫沉淀物。然后可以做出存在于所述沉淀物中的蛋白的定性和定量测量并对比以鉴别在细胞周期中差别相互作用。进一步,也可以鉴别“多参数”相互作用。“多参数”相互作用实验的一个例子是,其中采用两种对不同蛋白(其被认为会彼此相互作用)具有特异性的抗体。出于例证的目的,可以采用对tric和cdc20具有特异性的抗体,其中单独地和一起使用每种抗体可以产生免疫沉淀样品。然后可以做出存在于所述沉淀物中的蛋白的定性和定量测量并对比。经修饰的蛋白和肽在某些方面,本发明涉及对翻译后修饰的蛋白和肽、以及在目标基因座处未翻译后修饰的蛋白和肽具有亲和力和/或特异性的抗体的表征和应用。在许多情况下,这样的抗体将对存在于特定蛋白中的翻译后修饰位点具有显著的特异性。这是因为,在许多情况下,使用能够以高亲和力和特异性结合存在于细胞或细胞提取物中的靶表位的抗体将是合乎需要的。翻译后修饰包括、但不限于磷酸化、糖基化、泛素化、亚硝酰化、甲基化、乙酰化和脂质化。作为例子,认为小鼠sox9蛋白在软骨细胞中在位于位置211处的丝氨酸残基处通过涉及tgf-β的过程磷酸化(coricor和serra,sci.rep.6,38616;doi:10.1038/srep38616(2016))。该磷酸化位点的21个氨基酸(以丝氨酸211为中心)如下:naifkalqadsphsssgmsev(seqidno:1)。使用上面提及的sox9区域,本发明包括涉及下述步骤中的一个或多个的方法:1.鉴别合适的抗原(例如,肽)用于产生对所述抗原的磷酸化和/或未磷酸化形式具有亲和力和/或特异性的潜在抗体。2.针对一种或多种这样的抗原的一种或多种抗体的产生和标准(非-ms)筛选。3.使用ip-ms试验和/或对比一种或多种得到的抗体以鉴别对期望的抗原(磷酸化或未磷酸化)具有高水平的亲和力和/或特异性的抗体。出于例证的目的使用以上21个氨基酸的sox9序列,在确定其子部分的肽对于抗体产生的适合性中的一个起始点可以是针对有关的序列检索序列数据库。一个氨基酸序列数据库检索指示,该21个氨基酸的sox9序列是在哺乳动物物种之间高度保守的。进一步,智人特定蛋白检索提示,该氨基酸序列仅存在于sox9中,且仅一个经证实的蛋白具有6个氨基酸的序列同一性区域。该蛋白(锌指蛋白646)具有这样的区域:其序列与seqidno:1的氨基酸13-18相同。由于锌指蛋白646的该区域不含有丝氨酸磷酸化位点,针对具有seqidno:1的氨基酸序列的全部或部分的肽的磷酸化形式产生的抗体不可能对磷酸化的sox9具有显著的亲和力。还鉴别出了含有6氨基酸序列(具有丝氨酸211)的第二种假定物。这些数据提示,具有seqidno:1的氨基酸序列的全部或大部分的肽可以用于制备对在位置211处磷酸化的sox9具有高水平的特异性的抗体。这些数据也提示,具有seqidno:1的氨基酸序列的一部分的肽可以用于制备对在位置211处未磷酸化的sox9具有高水平的特异性的抗体。具体地,这些数据提示,氨基酸13-18的全部或部分可能不适合作为用于制备对未磷酸化的sox9具有高特异性的抗体的抗原。采用sox9的实施例当然仅是可以用于制备和/或鉴别对一种或多种抗原具有高水平的亲和力和/或特异性的抗体的方法的代表。可以使用类似的方法得到针对蛋白的其它翻译后修饰的抗体。因而,本发明包括用于筛选方法的组合物和方法,所述筛选方法制备和/或表征对具有有关和/或类似构象的分子具有亲和力和特异性的抗体。另一种翻译后修饰的一个例子是甲基化。已知许多蛋白会发生甲基化。已经发现蛋白翻译后修饰参与诸如dna修复等过程的调节,并且认为同源重组和精氨酸甲基化参与该过程。进一步,认为精氨酸甲基转移酶prmt5是同源重组(hr)介导的双链断裂(dsb)修复的调节剂,通过它的甲基化ruvbl1(tip60复合物的一种辅因子)的能力来介导。进一步,认为prmt5靶向ruvbl1,其被认为导致tip60的乙酰基转移酶活性,从而促进组蛋白h4k16乙酰化bs。因而,认为发生“级联”过程。本发明提供了用于鉴别酶底物以及表征用于用在这样的方法中的抗体的组合物和方法。关于酶底物,本发明包括酶的ip方法,随后表征与这样的酶结合的底物。在许多情况下,由于酶底物相互作用的经常短的持续时间,存在于ip中的底物的量可以是低的。但是,可以鉴别低普及蛋白,然后产生或纯化用于酶/底物测定。实施例实施例1.用于ip-ms抗体验证的细胞模型和靶标的选择图1呈现了ip-ms抗体验证过程的概要。首先,为验证选择蛋白靶标和抗体。选择被认为含有目标蛋白靶标的适当细胞模型,培养,并制备裂解物。进行许多不同细胞系的“深潜”分析以选择用于与我们的最初ip-ms分析一起使用的适当细胞系。使用被认为对某种靶蛋白特异性的抗体(例如经由ip/蛋白质印迹,但是没有经由ip-ms验证)来从细胞裂解物免疫富集靶蛋白。在ip以后,通过ms分析样品,并进行新颖的生物信息学分析。通过该过程捕获与每种抗体的结合靶蛋白的能力有关的定性和定量数据,并捕获与非靶相互作用蛋白、以及非特异性的相互作用蛋白配偶体有关的数据。使用该过程容易地鉴别和低估背景/非特异性结合。基于文献参考、数据库采集以及信号传递途径和靶向的基因组集合的考虑,诸如用于靶向基因扩增和下一代dna测序的thermoscientificionampliseq集合,将各种抗体的靶标按优先排序。编码p53的tp53基因是在pubmed中最高地参考的基因/蛋白,具有超过7500次参考,且因此被鉴别用于进一步研究。一旦将靶蛋白的列表按优先排序,就使用文献资源以及转录组和蛋白质组学数据库来鉴别可能含有蛋白靶标的最不同和/或综合集合的候选互补细胞系或生物样品。我们最初选择了12个可能表达前1000种最多参考的基因或基因产物中的超过90%的互补细胞系用于基于ms的抗原捕获、富集和蛋白质组学分析:a549、bt549、hct116、hek293、hela、hepg2、hs578t、lncap、mcf7、nih3t3、skmel5和sr。在图2中呈现了hepg2、a549、mcf7、bt549和lncap细胞的数据。包括另外的细胞系和生物样品,并且在这里提及的那些仅仅用于示例目的。根据推荐来培养最初选择的细胞系以产生几百毫克每种细胞蛋白裂解物。使用现有技术样品制备方法和仪器,在两个水平查询每种蛋白质组以鉴别表达这些靶蛋白中的每一种的细胞系。简而言之,将蛋白溶解,用胰蛋白酶蛋白水解地消化,并制备用于lc-ms分析。将未分级分离的和分级分离的蛋白消化物通过lc-ms直接分析。分级分离通过使用基于分子量、大小、疏水性、离子交换结合、亲水相互作用或亲和富集的方法降低蛋白裂解物(肽)的复杂性而提高蛋白质组覆盖的深度。每种未分级分离的蛋白消化物产生约3800-4500个独特蛋白家族鉴别,而每种分级分离的蛋白消化物产生约7500-9000个独特蛋白家族。为了评估总蛋白覆盖和分布,将来自每个细胞系的经鉴别的蛋白进行对比以确定每个不同细胞系之间的逐对关联评分。这些关联在75-99%的范围内。当对比来自5个最少关联的细胞系的总蛋白鉴别时,在这些细胞系中的所有5个中观察到3611种蛋白,在这5个不同细胞系中的每一个中观察到另外的900-1500种独特蛋白。除了提供来自多个细胞系的蛋白鉴别的综合列表以外,还使用多种无标记ms定量方法来定量蛋白,所述方法包括肽信号强度、无标记蛋白定量(lfq)和基于强度的绝对蛋白定量(ibaq)值(来自maxquant)。我们发现,lfq和ibaq提供了有用的互补信息,因为maxquantlfq值涉及样品中的蛋白的相对摩尔浓度,而ibaq考虑蛋白分子量并与蛋白的相对质量更紧密地对应,参见cox,j.和mannm.,natbiotech26(12):1367-1372(2008)。还使用了前3种肽的ms强度、鉴别的独特肽的数目或用thermoscientificproteomediscoverer检测到的波谱计数,因为这些是初步抗体筛选的快速且有效方式。使用这些无标记ms定量措施中的任一种,将靶蛋白表达排序并在这些细胞系之间对比,并将每种靶标的适当细胞系选择用于ip-ms抗体验证研究。例如,当将三种最强烈肽的累加强度定量和绘图时,e-钙粘着蛋白(cdh1)和n-钙粘着蛋白(cdh2)在这12个细胞系之间具有几乎相反的表达谱(图3a-3d)。仅在未分级分离的hct116、lncap和mcf7细胞中检测到e-钙粘着蛋白(cdh1),而仅在未分级分离的a549、bt549、hek293和hs578t细胞中看到cdh2。在分级分离和更深ms分析以后,两种异形体在几个细胞系中是可检测的(图3b和3d),但是任一种钙粘着蛋白异形体都是在nih3t3或sr细胞系中不可检测的。此外,由于具有多个基因拷贝和高过表达的细胞系是抗体验证的不适当模型,基于ms信号强度将每种天然蛋白排序以便选择适当的细胞系用于抗体筛选。例如,cdh1在未分级分离的mcf7裂解物中的约4600种蛋白中排序约1200(图3e),且在分级分离的裂解物中的约7100种蛋白中排序约800(图3f)。cdh2在未分级分离的a549裂解物中的约4500种蛋白中排序约1400(图3g),且在分级分离的裂解物中的约7200种蛋白中排序约1200(图3h),而cdh1仅在分级分离以后的a549裂解物中是可检测的(约7200种蛋白中排序约4000,图3h)。该表达信息对于细胞模型的选择以及异形体特异性抗体和泛特异性抗体选择性的验证而言是无价的。所以,基于ms鉴别和靶蛋白表达水平选择每种靶蛋白的一种或多种细胞系用于验证。在下面描述了图1所示的细胞模型和分级分离方法。表1:使用的细胞模型和生长条件细胞模型组织类型培养基产品编号胰岛素刺激hct116结肠mccoy’s5a16600-082n/a±igfa549肺hamm’sf12k21127-022n/a±igfmcf7乳房dmem11995-04010μg/mln/ahepg2肝脏mem11095-072n/a±胰岛素lncap前列腺rpmi-164011875-085n/a±igfnih3t3成纤维细胞dmem11995-040n/an/abt-549乳房rpmi-164011875-0850.023iu/mln/askmel5皮肤dmem11995-040n/an/ahs578t乳房dmem11995-04010μg/mln/asr淋巴母细胞rpmi-164011875-085n/an/ahela宫颈dmem11995-040n/an/ahek293肾dmem11995-040n/an/a所有细胞系购自atcc并在表1指出的条件下生长。所有培养基和细胞生长产物购自thermofisherscientific(包括胰蛋白酶(pn:25200-056)和hbss(pn:14175-079)),且给所有培养基补充了10%fbs(pn:16000-036)、ix青霉素链霉素(pn:15140-163)和胰岛素(如果需要的话)(pn:12585014)。将细胞培养至-80%汇合并在裂解前用thermofisherscientificip裂解缓冲液(pn:87788)和1:100halt蛋白酶和磷酸酶抑制剂混合液(pn:78445)传代12-18次。如果细胞经历刺激,将细胞在0.1%thermofisherscientificcharcoalstrippedfbs(pn:sh30068.01)中饥饿24小时,然后用100ng/mligf(cellsignalingtechnologypn:8917sf)或100nm胰岛素(tocrispn:87788)刺激15分钟,并然后立即裂解。使用thermofisherscientificmultiskango仪器用于测量,通过piercebcaproteinassaykit(pn:23225)确定蛋白浓度,并将等分试样在-80℃储存备用。用于未分级分离的和分级分离的蛋白质组分析的裂解物样品制备如在说明手册中所述,用试剂的适当放大,使用piercemassspecsampleprepkitforculturedcells(pn:84840),将200-800μg裂解物进一步处理用于通过质谱测定法分析。最终的干燥步骤以后,将样品在0.1%tfa中重构并使用piercehighphreversephasepeptidefractionationkit(pn:84868)清除不相容的盐、去污剂和其它试剂,其定制方案包括柱调节、3次0.1%tfa洗涤和3个使用50%乙腈和0.1%tfa的洗脱步骤。将样品在真空浓缩器中干燥,并在200μl0.1%tfa中重构。将5μl在45μl水中的样品(1:5稀释度)等分并如在说明手册中所述执行piercequantitativefluorometricpeptideassay(pn:23290)以确定肽浓度。对于分级分离,除了如表2所示的定制分级分离方案以外,按照说明手册用piercehighphreverse-phasepeptidefractionationkit(pn:84868)分级分离100μg消化过的肽样品。表2:定制分级分离方案将分级分离的样品在真空浓缩器中干燥并在20μl2%乙腈和0.1%甲酸中重构。使用8μl在16μl水中的样品(1:3稀释度),用piercequantitativefluorometricpeptideassay(pn:23290)测量肽浓度。将未分级分离的和分级分离的样品转移进自动采样瓶用于lc-ms分析。未分级分离的和分级分离的裂解物样品的lc-ms分析使用thermoscientificeasy-spray柱(50cmx75μmid,pepmapc18,2μm颗粒,孔径,pn:es803),在thermoscientifictmdionextmultimatetm3000rslcnanosystem和thermoscientifictmqexactivetmhfhybridquadrupole-orbitrapmassspectrometer上通过纳米lc-ms/ms分析2μg未分级分离的和分级分离的样品。使用与质谱仪在线接口的easysprayionsource(thermoscientific,pn:es081),将柱温度维持在40℃。使用流动相a(在水中的0.1%甲酸,lc-ms级)和流动相b(在乙腈(acn)中的0.1%甲酸,lc-ms级)缓冲两种运行缓冲液中的ph。总梯度是210分钟,继之以30分钟清洗和重新平衡。详细而言,流速开始于300nl/min,并且2%acn在170分钟内线性增加至20%acn,随后在40分钟内线性增加至32%acn。用95%acn在设定至400nl/min的流速清洗4分钟,随后24分钟重新平衡至2%acn。将qexactivehf仪器(thermoscientific,bremen,德国)新清洗,并使用tune(2.5版构造2042)仪器控制软件校准。将喷雾电压设定至1.9kv,s-透镜rf水平在60,且加热的毛细管在275℃。将全扫描分辨率设定至在m/z200的120,000。全扫描靶标是1*106,具有60ms的最大it填充时间。将质量范围设定至400-1600。将片段扫描的靶值设定在1*105,并将强度阈值保持在5x104。将分离宽度设定在2.0th。将归一化的碰撞能设定在27。将肽匹配设定为优选的,并利用同位素排除。使用正极性在分析模式(profilemode)获得所有数据。实施例2.ip/ms方案使用下述方法使用图1所示的ip/ms方案在许多不同细胞系中产生数据。针对tp53、cdh1、cdh2和cdkn1a的抗体购自thermofisherscientific(参考图5a、5b、7a)。如在指导手册中所述使用thermoscientificpiercems-compatiblemagneticipkit(proteina/g)(thermofisherscientific,pn:90409)筛选和验证抗体。将500μg裂解物和5μg抗体用于所有实验。将ip洗脱液在真空浓缩器中干燥,并按照指导手册(thermofisherscientific,pn:90409)中的推荐通过溶液中消化方法处理样品。将干燥的消化的样品重新悬浮在13μl4%乙腈和0.2%甲酸中并转移进自动采样瓶中然后lc-ms分析。ip-ms样品的lc-ms分析使用与thermotmscientifictmqexactivetmhfhybridquadrupole-orbitrapmassspectrometer或thermotmscientifictmqexactivetmplusorbitrapmassspectrometer偶联的thermoscientifictmdionextmultimatetm3000rslcnanosystem,通过纳米lc-ms/ms分析ip-ms样品。将7μl胰蛋白酶消化样品使用thermoscientificnanotrapcolumn(100pmi.d.x2cm,填充了acclaimtmpepmapiootmcl8,5μm,pn:164564)在线脱盐,并使用thermoscientifictmeasy-spraytmpepmaptmc18柱(15cmx75μmid,3μm颗粒,孔径,pn:es803)分离,总梯度时间为62分钟。详细而言,流速开始于300nl/min,并且3%acn在55分钟内线性增加至25%acn,随后在7分钟内线性增加至40%acn。将柱用95%acn在设定至600nl/min的流速清洗3分钟,随后5分钟重新平衡至3%acn。将qexactivehf和qexactiveplus仪器(thermoscientific,bremen,德国)新清洁并校准。将喷雾电压设定至1.9kv,s-透镜rf水平在60,且加热毛细管在275℃。将全扫描分辨率设定至在m/z200的70,000(qexactiveplus)和在m/z200的60000(qexactivehf)。将全扫描自动增益控制(agc)靶标设定至3*106(对于qexactiveplus,具有50ms的最大it填充时间)和1*106(对于qexactivehf,具有60ms的最大it填充时间)。将两个仪器的质量范围设定至400-1600m/z。将片段扫描的靶agc值设定在1*105,并将强度阈值保持在1x104(qexactivehf)和3.3x103(qexactiveplus)。将仪器分离宽度设定在1.2th(对于qexactivehf)和2.0th(对于qexactiveplus)。对于两种仪器,将归一化的碰撞能设定在27。将肽匹配设定为优选的,并利用同位素排除。使用正极性在分析模式(profilemode)获得所有数据。实施例3.通过ms鉴别靶标使用将免疫沉淀与质谱法组合的方案(ip-ms),使用来自实施例1的蛋白表达谱和实施例2的技术辅助抗体的验证。通过ip-ms进行抗体验证的关键益处是天然靶蛋白和它的异形体和修饰的鉴别。如上所述,可以以几种方式评估该靶标鉴别的ms结果,所述方式包括独特肽的数目、蛋白序列覆盖、关于来自靶蛋白的肽观察到的波谱的数目(波谱计数)或来自检测到的肽的子集或全部的积分ms信号强度。不论测量方案,可以容易地对比各种抗体关于相同靶标的相对性能。例如,使用三种最强烈的p53肽的ms信号强度,在天之间和在抗体之间评估使用13种ip/蛋白质印迹验证过的针对p53蛋白的抗体(tp53)的免疫沉淀(图5a)。在天之间的结果是高度可再现的,且这些抗体中的12种表现出强ms信号。该ip-ms抗体验证方案评估了适合目的抗体,提供了靶蛋白捕获的确定证据,并容易地允许可能指示相对抗体亲和力的抗体对比。尽管ip-ms方案提供了在抗体的蛋白靶标鉴别中的可靠性,在样品中也检测到抗体、载体蛋白和丰富的非特异性蛋白。这些另外蛋白可能掩蔽其它蛋白抗原且可以使分析混乱。重要的是,必须证实抗体会富集它的预期靶标,且理想地也相对于背景蛋白共同富集相互作用配偶体。为了更好地定量抗体的性能和选择性以及在天之间归一化针对不同靶标的抗体的结果,我们利用了富集倍数的概念。富集倍数的计算常用于评估和优化蛋白纯化方法,且该方案可以用于评估抗体从生物基质富集它的天然靶标的能力。传统的抗体验证方法利用相互作用蛋白与数据库的对比,且不具有将相互作用蛋白与非特异性结合剂区分开的机制。相反,富集倍数会对比被试验抗体捕获的靶蛋白的丰度和相同靶蛋白的丰度(用阴性对照ip,或不用ip在裂解物样品中)。这样,非特异性结合剂不会被富集或仅轻微富集,且可以有效地检查以支持富集的蛋白。传统的方法不具有“减去”这些非特异性结合剂的方式。用于富集倍数计算的公式如下:其中靶蛋白是与所述试验抗体结合的蛋白。为了评估富集倍数和蛋白定量的其它量度之间的关联,使用来自未分级分离的或分级分离的裂解物的lfq值用17种异形体特异性的和泛-钙粘着蛋白抗体计算cdh1的富集倍数。将富集倍数值与检测的cdh1肽的数目进行对比,且看到非常高的关联(图4b)。所述关联因而证实了富集倍数验证方法。根据是否使用来自未分级分离的或分级分离的总裂解物的ms结果,计算的富集倍数是不同的。因此,如果在未分级分离的裂解物中检测到蛋白,将该总裂解物ms信号用于富集倍数计算。否则,将来自分级分离的裂解物的更深分析的ms结果用于富集倍数计算。质谱数据分析和显影使用proteomediscoverer1.4(1.14版)分析得自未分级分离的裂解物、分级分离的裂解物和ip样品的ms数据。将人、小鼠和大鼠蛋白质组的定制数据库(uniprot,2014年7月组装)用于数据库检索。选择胰蛋白酶作为用于消化的酶。在自动化检索过程中,产生浓缩的靶标/诱饵数据库来验证肽-波谱匹配(psm)和将鉴别过滤至1%假发现率(fdr)。使用20ppm前体质量容差和0.03da片段容差,检索ms波谱。用半胱氨酸残基的脲甲基化的静态修饰和动态修饰(包括蛋白n-末端的乙酰化、甲硫氨酸残基的氧化以及丝氨酸、苏氨酸和酪氨酸残基的磷酸化),检索数据。将未分级分离的、分级分离的和ip-ms样品数据的蛋白组输出,并使用定制软件来提取独特肽序列、psm的数目和每种鉴别的蛋白的前3个肽峰面积。使用前3个肽峰面积来确定多个细胞系之间的特定蛋白的相对丰度。在pd1.4分析以后,使用maxquant1.5.3.51检索样品以得到未分级分离的和分级分离的蛋白质组样品之间的肽和蛋白的相对定量,并将这些蛋白丰度与ip样品对比。鉴别出用于ip样品的一个“集合”(其中所述集合中的每种抗体据报道会识别相同的靶蛋白)的裂解物,并用来自深蛋白质组分析的对应的未分级分离的和分级分离的细胞系数据检索。使用相同的数据库和pd1.4检索的检索参数,执行数据库检索。使用2的最小lfq比例计数和快速lfq执行无标记定量(lfq)。使用20ppm第一检索肽容差和4.5ppm主要检索肽容差检索波谱。用20ppm片段匹配容差分析ms/ms波谱。使用独特的和剃刀(razor)肽进行定量,使用2比率的最小阈值定义蛋白定量。将大lfq值稳定化并需要ms/ms用于lfq对比。为所有数据产生ibaq值并与原始蛋白强度和lfq值对比。将maxquant数据手工分析以对比在未分级分离的、分级分离的和ip-ms样品之间得到的强度、lfq和ibaq值。对于检索的每个ms运行,提取每种蛋白的lfq丰度并除以所有被鉴别的蛋白的累加丰度,以得到该蛋白的相对丰度相对于在样品中鉴别出的每种其它蛋白的“分数”。然后将ip样品中的蛋白的丰度的相对分数与深蛋白质组样品中的蛋白的分数对比以观察该分数是否相对于在每个ip中鉴别出的其它蛋白增加、减小或保持相同。以此方式,为ip样品中的每种蛋白计算富集倍数,且将该计算用于表征假定的抗体靶标和已知的靶标-蛋白相互作用物的富集。使用蛋白lfq和ibaq执行这些富集倍数计算。还使用蛋白lfq和ibaq值产生散点图来表征在ip中使用的抗体的特异性。将lfq和ibaq值绘图以将在“试验”ip中鉴别出的蛋白的相对丰度(绘制在y-轴上)与在阴性对照ip(其中没有鉴别出靶标)中鉴别出的那些蛋白(绘制在x-轴上)进行对比。选择阴性对照抗体用于备选,因为所述抗体识别不同的靶标或不会鉴别被试验ip下拉的靶标。根据它们相对于深蛋白质组样品的富集倍数,将在试验ip中独特地观察到的蛋白排序。将富集倍数和散点图计算并入网络应用程序中以将凸形的产生流线化用于ip验证。使用原始蛋白强度、lfq和ibaq值,使用所述应用程序对比抗体的富集倍数和散点图。将在试验ip中独特地观察到且相对于深蛋白质组分析表现出>1富集倍数的蛋白呈送至string数据库(string-db.org)以探测已知的靶标-蛋白相互作用。针对智人蛋白质组选择蛋白相互作用。使用文本采掘、实验验证、数据库注解、共表达、基因融合和共存数据,根据它们的已知相互作用物绘制蛋白。用代表在试验ip中独特地鉴别出的蛋白的节点和代表蛋白-蛋白相互作用的证据的边描绘数据。根据鉴别出的蛋白是否是假定的抗体靶标或列出为与靶标的直接相互作用物(经由string数据库),将蛋白富集倍数条形图突显了。还将蛋白突显了以代表它们是否是间接相互作用物(即,列出为与注解的靶标相互作用物相互作用)或没有列出为经由string数据库相互作用。将来自string数据库的网络统计与关于细胞组分、生物学过程、分子功能、kegg途径、pfam注解和interpro分类的富集go术语一起下载。实施例4.散布图的背景减去使用固定化的抗体的蛋白免疫沉淀是靶向蛋白富集的常见方法,但是即使在严谨的洗涤条件以后通过质谱法通常鉴别出超过100种背景蛋白。为了更好地理解这些背景蛋白和更容易地鉴别特异性地捕获的蛋白(相对于非特异性地捕获的蛋白),使用ms强度值来定量地对比用特异性抗体相对于阴性对照抗体免疫沉淀的蛋白(图5a)。得到的ms强度散布图显示了三个簇:1)在免疫沉淀之后仅用试验抗体观察到的特异性地捕获的蛋白(图5a,y-轴);2)仅用阴性对照抗体免疫沉淀观察到的非特异性地捕获的蛋白(图5a,x-轴);和,3)沿着对角线轴的蛋白散落,其代表在两次免疫沉淀中观察到的背景蛋白(图5a,对角线区域)。可以容易地反转该方案以对比无关抗体,或来自许多阴性对照抗体的结果可以用于除去常见的非特异性地结合的蛋白。该定量分析和视觉表示快速地过滤用每种抗体鉴别出的捕获蛋白的列表。关于cdh1执行散布图分析,如在图5b中所示。在该实验中,至少由于以下理由,选择135700抗体(其被认为是对cdh1特异性的)作为“靶ip”:以前已经证实它会在ip以后在试验的抗-cdh1抗体中诱导cdh1的强富集(参见图4b)。选择701134抗体作为“对照ip”,因为它没有表现出图4b中的cdh1的任何富集,且因而似乎不具有对cdh1的强选择性或亲和力。尽管选择非特异性的“对照”抗体用于该实验,应当指出,结合相同靶蛋白的抗体可以用作“对照”抗体获得成功的结果。为了提供另外的洞察,相对于这些相同实验和对照抗-cdh1抗体的富集倍数计算对比了散布图结果(图5b,图的右侧)。结果表明,经由使用135700抗体的ip-ms高度富集了cdh1,但是经由使用701134抗体的ip-ms没有富集(参见在y-轴上在7.8附近的cdh1“点”,和沿着x-轴的cdh1“点”的缺失)。令人感兴趣的是,当通过上述富集倍数方法分析时,最常见的背景蛋白中的一些(即,离开对角线的那些)被显著地富集(参见在图5b中作为丰富的“粘性”蛋白指出的“点”)。因此,富集倍数和散布图分析的组合在从丰富的非特异性结合剂区分真实蛋白靶标中是特别有帮助的。丰富的非特异性蛋白的存在可以由与磁珠树脂或抗体同种型的特异性结合造成,且可以依赖于在样品制备中使用的细胞类型。一般而言,散布图方案通常消除超过90%的经鉴别的蛋白作为非特异性结合剂(另外的数据未显示)。在任何特定散布图中离开对角线的许多(但并非所有的)蛋白可以在背景蛋白的数据库中找到,例如,crapome数据库(参见mellacheruvu,d.,等人,natmeth10(8):730-736(2013))。散布图的应用会提供特异性蛋白和背景蛋白的清单的目测评估,且它与富集倍数数据的组合的应用在消除非特异性背景蛋白中是特别有帮助的。用于分析蛋白亲和捕获结果的替代性定量工具(诸如compass、saint和perseus)会提供复杂的评分方法和分析,但是结果对于非专家而言仍然是压倒性的和难以解释。示例性的替代定量方法已经描述在marcone,等人,naturemethods12:725-731(2015);keilhauer,e.c.,等人,molcellproteomics14(1):120-35(2015);teo,g.,等人,journalofproteomics100:37-43(2014);和sowa,m.e.,等人,cell138(2):389-403(2009)。但是,这些工具都没有利用天然样品和免疫富集的样品之间的相对定量结果来确定富集倍数。该富集倍数计算允许直接测量抗体对它们的靶标的绝对和相对特异性。具有富集倍数的散布图分析指示,ip/ms是验证抗体显示出对靶蛋白的选择性(相对于非选择性地结合阴性对照抗体的蛋白)的有力工具。实施例5.用于评估选择性和鉴别相互作用配偶体的富集倍数基于深度的以ms为基础的蛋白质组分析而选择细胞系用于抗体验证,并使用这些数据在全细胞裂解物中鉴别出和定量超过10,000个蛋白家族,通过计算在免疫沉淀的样品中鉴别出的所有蛋白的富集倍数而定量地评估抗体性能。以此方式,可以对比不同抗体对相同靶标的表现,并可以鉴别出脱靶。例如,将用ip/蛋白质印迹验证过的cdh1抗体(抗体135700)从mcf7细胞免疫沉淀的蛋白与用另一种cdh1抗体免疫沉淀的蛋白(其没有针对ip(抗体701134)验证过)进行对比。参见,图5b。cdh1仅被ip-验证过的抗体135700鉴别,且富集倍数计算鉴别出也用该抗-cdh1抗体特异性地富集的蛋白的小子集,包括αl-、α2-和βl-连环蛋白(ctnna1、ctnna2、ctnnb1)和斑珠蛋白(jup,也被称作γ-连环蛋白),如在图5c中所示。这些富集的蛋白被称作在biogrid(http://thebiogrid.org/)和string(http://string-db.org/)蛋白相互作用数据库(具有来自图5d中所示的string的数据)中记录的cdh1相互作用配偶体。这些蛋白没有被对照701134抗体富集。在另一个实验中,将用泛-特异性的抗-钙粘着蛋白抗体(pa1-37199)从a549细胞免疫沉淀的蛋白与用另一种提议的泛-特异性的抗-钙粘着蛋白抗体抗体(pa5-16481)免疫沉淀的蛋白进行对比。图4b显示了相对于这些抗体中的每一种的肽的数目的富集倍数。pa1-37199表现出关于cdh1的富集倍数,而pa5-16481没有(参见图4b)。如在图5e中所示,pa1-37199抗体使r-钙粘着蛋白(cdh4)、e-钙粘着蛋白(cdh1)和n-钙粘着蛋白(cdh2)富集了30-80倍,与trim9蛋白一样好,从而提示与trim9的潜在交叉反应性或新颖的相互作用。以前对trim9和它的有关蛋白的生物信息分析突显了与蛋白的钙粘着蛋白超家族具有结构相似性的区域,这可能解释该泛-特异性的抗钙粘着蛋白抗体对trim9蛋白的捕获(参见short,k.m.和coxt.c.,jbiolchem281(13):8970-80(2006))。特异性地免疫沉淀的和富集的蛋白的进一步生物信息分析鉴别出大量与连环蛋白复合物和细胞粘附有关的已知蛋白相互作用配偶体(图5f-5g)。该数据提示,ip-ms是用于验证抗体ip特异性、以及准确地检测有意义的蛋白-蛋白相互作用的高度特异性的和准确的方法。接着,使用ip-ms相对于三种ip-验证过的阳性对照抗体对比了19种针对p21cipl的抗体,其也被称作细胞周期蛋白依赖性的激酶抑制剂1(cdkn1a)(图7a)。五种以前ip-验证过的抗体中的四种成功地捕获了靶标,且另外11种以前没有ip验证过的抗体也捕获靶标。作为一个例子(显示在图6a中的框中),与许多已知的蛋白相互作用配偶体一起,多克隆抗体pa1-30399使来自hct116细胞的cdkn1a富集了超过300倍(图6b)。例如,细胞周期蛋白依赖性激酶1、2、4和6(cdk1、cdk2、cdk4、cdk6)和细胞周期蛋白a2、bl、d1和el(ccna2、ccnb1、ccnd1、ccne1)都参与调节细胞周期,且cdkn1a是含有锌指的dna结合蛋白,其通过与cdk4相互作用从而抑制它对细胞周期蛋白d的磷酸化而调节细胞周期。令人感兴趣的是,sapcd2是一种含有肿瘤抑制物apc结构域的蛋白,其从未被发现与这些其它蛋白相互作用。该蛋白在胃癌中高度表达(参见xu等人,oncogene26,7371-7379(2007)),且用于该抗体验证的hct116细胞系源自结肠癌。通过试验cdkn1a与抗-sapcd2抗体的共捕获,可以试验该潜在相互作用。还关于sapcd2和其它蛋白的共捕获评估了该组cdkn1a抗体,并且它在许多ip样品中的存在提示,它是普通脱靶或cdkn1a的强相互作用配偶体。对该抗体特异性的三种潜在脱靶包括fam83f(不太了解的磷酰化的和乙酰化的蛋白)以及znf346和baz1a(它们二者是锌指蛋白)。这最后两种锌指蛋白提示,该抗体的表位可能包括cdkn1a的锌指结构域。用每种抗体富集的蛋白的进一步对比提示,蛋白相互作用物和表位的不同模式可能是可检测的,潜在地提示将抗体映射至不同表位和鉴别用于”夹心-型”抗体捕获和检测应用的互补抗体对的能力。特异性地捕获的和富集的蛋白的生物信息分析揭示了细胞周期蛋白依赖性蛋白激酶全酶复合物的许多组分(图6c-6d)。接着,针对它们在ip-ms后富集erbb2肽的能力评价了多种抗-erbb2抗体。图7a显示了相对于未分级分离的样品用多种抗-erbb2抗体富集erbb2肽的ip-ms结果。选择ma514057抗体(thermofisher)作为阳性对照,且两个单独的实验表明,使用maxquant分析用该抗体进行的ip相对于未分级分离的样品产生了94.3和186.2倍富集。使用pa1-12361抗体(thermofisher)的ip-ms也表现出高富集,相对于未分级分离的样品为72.5倍富集。其它抗-erbb2抗体(pa1-37426、ma5-16724、pa5-14632、pa5-14634和pa5-14635;都来自thermofisher)没有表现出ip-ms的显著富集。因而,与使用maxquant的分析偶联的ip-ms过程验证了ma5-14057和pa1-12361与erbb2特异性地相互作用的能力,同时指示其它抗体不具有基于ip-ms分析的实质活性。下面在表3中显示了试验的抗-erbb2抗体的列表,以及以前验证过的每种抗体的应用。应用包括免疫荧光(if)、免疫细胞化学(icc)、使用冷冻的组织或石蜡固定的免疫组织化学(ihc,f或p)、免疫显微术(im)、免疫沉淀(ip)、蛋白质印迹法(wb)、酶联免疫吸附测定(elisa)和荧光活化细胞分选(facs)。另外,图7b显示了在ip-ms分析以后存在于样品中的许多erbb2肽。再次,使用ma5-14057和pa1-12361抗体的ip导致erbb2肽在ip样品中的存在。对于所有组,使用maxquant分析相对于使用pd1.4分析,存在于样品中的肽的数目更大。我们发现使用maxquant的检索用时长于使用pd1.4的检索,但是maxquant检索为每种蛋白鉴别出更多的肽,且lqf和ibaq定量值是更可再现的。所以,初步ip-ms结果通常是首先使用pd1.4作为检索工具的检索,然后检索来自看起来较好地工作的抗体的lc-ms结果并用maxquant定量来评估富集倍数和选择性。其它抗-erbb2抗体在ip-ms和分析以后表明几乎没有或根本没有erbb2肽。这些使用erbb2的数据证实,ip-ms验证过程可以根据亲和力和选择性将多种抗体排列给该靶标。对于erbb2,具有最大亲和力和选择性的抗体是ma514057和pai12361,而其它抗体没有证实足够强以诱导靶蛋白的富集的亲和力和选择性。证实了基于ip-ms的富集倍数是定量抗体选择性的新方式。图8a显示了来自使用8种针对ctnnb1的抗体的ip-ms实验的ctnnb1的富集倍数。ctnnb1的富集倍数随抗体从30倍至370倍变化。这些抗体中的几种对固定化的β-连环蛋白蛋白质的结合性能的表面等离子体共振(spr)分析提示,检测到的ms信号和得到的富集倍数部分地归因于观察到的解离速率常数的范围(未显示)。较高的解离速率常数与较低的ms信号相关。在洗脱之前将在磁珠上的免疫富集的复合物洗涤多次,其可能产生该范围的富集倍数值。除了ctnnb1以外,apc、多种钙粘着蛋白(cdh1、cdh2、cdh4)和其它已知的相互作用物与抗-ctnnb1抗体一起共富集。图8b显示了ctnnb1的已知相互作用物的string网络简图。这些结果补充了图5中所示的结果,其通过反向实验证实了cdh1和ctnnb1之间的蛋白-蛋白相互作用。图8a也表明,针对相同靶蛋白的不同表位区域的独立抗体可以富集相互作用物的共同集合,但是具有独特的富集倍数特性。图8c显示了用每种抗-ctnnb1抗体针对每种相互作用蛋白检测到的独特肽的数目的二维分级群聚的结果。使用cluster3.0(laboratoryofdnainformationanalysis,humangenomecenter,instituteofmedicalscience,universityoftokyo)和javatreeview(https://sourceforge.net/proiects/jtreeview/)软件来确定和绘制不同的相互作用物和不同的抗体之间的关联。该分析提示,不同的抗-ctnnb1抗体可能识别ctnnb1相互作用组的不同亚群,可能是由于独特ctnnb1表位的识别。不同ctnnb1相互作用组亚群的潜在存在也可能促成观察到的ctnnb1的可变富集倍数,因为它们可能指示这些亚群在裂解物中的相对丰度。重要的是,分簇方案(诸如描述的这些)可以用于鉴别互补抗体,所示互补抗体当联合用在夹心型抗体捕获和检测测定(诸如酶联免疫测定(elisa)和基于珠子的免疫测定(例如,luminex测定))中时可以一起使用以提供更大的特异性。图9a显示了使用针对nfkbia蛋白的抗体对nfkbia的360倍富集,以及基于图9b中的string网络相互作用简图预测会与nfkbia相互作用的17种另外的共富集蛋白。这些相互作用物在转录调节、rna结合、rna剪接、rna的核输出和翻译调节中起重要作用。这样多种相互作用物的明显富集的两种可能的解释是,nfkbia是在>1兆道耳顿复合物中,或更可能,nfkbia在转录、核输出和翻译的不同阶段结合至多种rna物质,并且也结合这些rna的其它蛋白可能被共富集。图10a显示了亲和力纯化的抗体的4个实施例,其看起来被肽/蛋白亲和纯化试剂污染。4种抗体在ip-ms洗脱液中表现出可检测的akt3或pakl靶标,尽管实际上在实验中没有使用细胞裂解物。在纯抗体制品(其在ip-ms分析之前与牛血清白蛋白混合)中通过maxquant无标记定量(lfq)确定的靶蛋白水平证实,显著量的抗体靶标可能存在于所述抗体制品中。在描述了用于抗体开发和纯化的抗原的情况下,来自所述抗原序列的多种肽存在于所述抗体制品中。为了进一步验证该观察,图10b显示了从在含有重同位素标记的赖氨酸和精氨酸氨基酸的培养基中培养的细胞的裂解物富集的轻肽的强度。所述轻肽看起来已经存在于用在ip-ms反应中的抗体制品中,但是可以与细胞裂解物中的重天然蛋白共富集。污染可能在纯化的抗体的洗脱过程中来自亲和材料从抗体纯化树脂的浸沥。污染可能与预期的抗原竞争并减小抗体对于抗原结合的可用性,它可能增加免疫测定中的背景信号,且它可能在基于ms的测定中干扰靶向肽检测。这些数据解释了使用ip-ms的抗体验证的一些益处。ip-ms是抗体验证的新方案,其独特地验证抗体捕获性能、评估抗体选择性、鉴别脱靶、并鉴别相互作用配偶体。该抗体验证方案不同于其它蛋白-蛋白方案,因为使用的过滤和富集方案、以及因为靶蛋白、脱靶和相互作用物在它们的天然状态(无n-或c-端标签)被鉴别且在生物学上有关的细胞系或生物样品中与它们的相互作用配偶体一起在天然水平表达。认为前述书面说明书足以使本领域技术人员能够实践实施方案。前述描述和实施例详述了某些实施方案并描述了发明人考虑的最好模式。但是,应当明白,不论详述的前述内容如何出现在文本中,所述实施方案可以以许多方式实践且应当根据所附权利要求及其任何等同方案来解释。本文中使用的术语约表示数字值,包括、例如,整数、分数和百分比,不论是否明确地指出。术语约通常表示被本领域普通技术人员认为与列举的值等同(例如,具有相同的功能或结果)的数值的范围(例如,列举的范围±5-10%)。当术语诸如至少和约位于数值或范围的列表前面时,所述术语修饰在所述列表中提供的所有值或范围。在某些情况下,术语约可能包括被四舍五入至最近的有效数字的数值。下述专利文献通过引用整体并入本文:2017年3月13日提交的pct/us2017/022062;2016年3月14日提交的美国临时申请62/308,051;和2017年2月28日提交的美国临时申请62/465,102。下述条款进一步代表了本发明:条款1.一种用于鉴别特异性地结合抗体的蛋白的方法,所述方法包括:i)选择试验抗体;ii)从生物样品制备细胞裂解物;iii)使所述细胞裂解物与所述试验抗体接触,并且免疫沉淀所述抗体和它的蛋白结合配偶体;iv)通过质谱法分析免疫沉淀的抗体和它的蛋白结合配偶体;v)确定与所述试验抗体结合的蛋白相对于所述细胞裂解物中的蛋白的富集倍数;和vi)鉴别特异性地结合所述抗体的蛋白,其中特异性地结合所述抗体的蛋白相对于所述细胞裂解物中的蛋白富集。条款2.一种用于鉴别特异性地结合抗体的蛋白的方法,所述方法包括:i)选择试验抗体;ii)从生物样品制备细胞裂解物的第一和第二制品,其中所述第一和第二制品是几乎相同的;iii)使第一细胞裂解物与所述试验抗体接触,并使第二细胞裂解物与第二抗体接触,并且免疫沉淀所述抗体和它们的蛋白结合配偶体;iv)通过质谱法分析免疫沉淀的试验和第二抗体和它们的蛋白结合配偶体;v)在x-或y-轴上绘制通过质谱法鉴别为结合所述试验抗体的每种蛋白的强度和/或富集倍数,和在相对轴上绘制通过质谱法鉴别为结合所述第二抗体的每种蛋白的强度或富集倍数;和vi)鉴别特异性地结合所述试验和第二抗体的蛋白,其中a.特异性地结合所述试验和第二抗体的蛋白是不会表现出与所述试验和第二抗体相等或几乎相等的结合的那些(在绘制时离开对角线的那些);b.特异性地结合所述试验抗体的蛋白在沿着y-轴绘制时在上方离开对角线,或在沿着x-轴绘制时在下方离开对角线;和c.特异性地结合所述第二抗体的蛋白在沿着y-轴绘制时在上方离开对角线,或在沿着x-轴绘制时在下方离开对角线。条款3.条款1或条款2的方法,其中所述生物样品是在细胞培养物、组织、血液、血清、血浆、脑脊液、尿、滑液、腹膜液和其它生物流体中的细胞。条款4.条款1或条款2的方法,其中所述生物样品在与抗体接触之前能够被刺激或活化。条款5.条款4的方法,其中所述刺激是使用生长因子、激素、毒素或抑制剂。条款6.条款3的方法,其中所述细胞培养物中的细胞是原代或二代细胞、或永生细胞或干细胞。条款7.条款6的方法,其中所述细胞选自a549、bt549、hct116、hek293、hela、hepg2、hs578t、lncap、mcf7、nih3t3、skmel5和sr。条款8.条款6的方法,其中所述细胞选自在nci60集合中的任何细胞。条款9.条款1或条款2的方法,其中将所述细胞裂解物分级分离。条款10.条款9的方法,其中分级分离包括基于通过分子量、大小、疏水性、离子交换结合、亲水相互作用或亲和富集的分离而降低细胞裂解物或消化的细胞裂解物的复杂性。条款11.条款1或条款2的方法,其中通过下式确定富集倍数其中靶蛋白是与所述试验抗体结合的蛋白。条款12.条款1或条款2的方法,其中与在所述细胞裂解物中的蛋白相比,所述特异性地结合所述抗体的蛋白富集了约5倍或更高。条款13.条款12的方法,其中与在所述细胞裂解物中的蛋白相比,所述富集倍数是约5、10、15、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95、100、110、120、130、140、150、160、170、180、190或200倍高。条款14.条款2的方法,其中所述第二抗体是:a.一种抗体被认为结合与所述试验抗体相同的一种或多种蛋白的子集;或者b.一种抗体不被认为结合与所述试验抗体相同的一种或多种蛋白。条款15.条款14的方法,其中所述第二抗体是异形体特异性抗体或泛特异性抗体。条款16.条款2的方法,其中绘图产生散布图。条款17.条款2的方法,其中定量所述强度。条款18.条款11的方法,其中通过无标记的技术或代谢或化学质量标记技术来定量所述强度。条款19.条款12的方法,其中通过肽信号强度、无标记蛋白定量(lfq)、基于强度的绝对蛋白定量(ibaq)、波谱计数、序列覆盖、独特肽的数目或蛋白库来定量所述强度。条款20.条款2的方法,其中将所述富集倍数绘图。条款21.条款1或条款2的方法,其中通过测序进一步表征鉴别的蛋白。条款22.条款1或条款2的方法,其中翻译后修饰鉴别的蛋白。条款23.条款1或条款2的方法,其中所述抗体特异性地结合超过一种靶蛋白。条款24.条款23的方法,其中根据抗体对它的靶蛋白的特异性来表征所述抗体,其中一种靶蛋白相对于另一种靶蛋白更大的富集倍数或更大的信号强度意味着所述抗体对该蛋白的特异性大于具有更小富集倍数或更小信号强度的蛋白。条款25.条款23的方法,其中一种靶蛋白是另一种靶蛋白的翻译后修饰形式。条款26.一种用于确定超过一种抗体的相对性能的方法,所述方法包括:a.针对超过一种试验抗体执行条款1的方法,或者b.执行条款2的方法,和c.相对于彼此对比条款1的试验抗体、或条款2的试验和第二抗体的性能,并基于信号强度、富集倍数、序列覆盖、独特肽的数目或波谱计数将它们的性能排序,其中在以下情况下就特定靶蛋白而言一种抗体的性能优于另一种抗体:它的信号强度、富集倍数、序列覆盖、独特肽的数目或波谱计数大于另一种抗体。条款27.条款2的方法,其中所述试验和第二抗体是相同的,并且其中在与所述抗体接触之前,将饱和所述试验抗体上的蛋白结合位点所需要的过量蛋白加入所述第一细胞裂解物,但是不加入所述第二细胞裂解物,且其中特异性地结合所述试验和第二抗体的蛋白是不会表现出与所述试验和第二抗体相等或几乎相等的结合的那些(在绘制时离开对角线的那些)。条款28.上述条款中的任一条的方法,其中所述质谱法选自使用数据依赖性获取和数据非依赖性获取的串联质谱法。条款29.上述条款中的任一条的方法,其中所述鉴别的相互作用配偶体、异形体或修饰能够指示不同抗体的可辨别表位。条款30.上述条款中的任一条的方法,其中在质谱法之前消化所述免疫沉淀的抗体-靶蛋白。条款31.条款30的方法,其中所述消化包括蛋白酶或化学消化。条款32.条款30的方法,其中所述消化是单次的或连续的。条款33.条款31或32中的任一条的方法,其中所述蛋白酶消化使用胰蛋白酶、糜蛋白酶、aspn、gluc、lysc、lysn、argc、蛋白水解酶k、胃蛋白酶、梭菌蛋白酶、弹性蛋白酶、glucbiocarb、lysc/p、lysnpromisc、蛋白内肽酶、葡萄球菌蛋白酶或嗜热菌蛋白酶。条款34.条款31或32中的任一条的方法,其中所述化学裂解使用cnbr、氧碘基苯甲酸盐或甲酸。条款35.条款31或32中的任一条的方法,其中所述蛋白酶消化是胰蛋白酶消化。条款36.上述条款中的任一条的方法,所述方法进一步包括在免疫沉淀之后或在消化之后且在质谱法之前脱盐。条款37.一种用于表征抗体的方法,所述方法包括:(a)确定所述抗体对抗原的亲和力,和(b)确定所述抗体对所述抗原的选择性,其中使用免疫沉淀-质谱法(ip-ms)确定所述抗体的亲和力和/或所述抗体的选择性,且其中如下产生所述免疫沉淀物:在允许所述抗体和所述抗原之间形成所述免疫沉淀物的条件下使所述抗原与所述抗体接触。条款38.条款37的方法,其中通过检测与细胞裂解物中的分子的结合,确定所述抗体对它的结合配偶体的选择性。条款39.条款38的方法,其中所述分子是蛋白。条款40.条款38的方法,其中所述细胞裂解物源自表达所述抗原的所有部分的物种的细胞。条款41.条款38的方法,其中通过细胞裂解物的蛋白质印迹来确定选择性。条款42.条款38的方法,其中使用表达来自超过一个物种的抗原的所有部分的细胞来确定选择性。条款43.条款42的方法,其中通过来自超过一个物种的细胞裂解物的蛋白质印迹来确定选择性。条款44.条款37的方法,其中如下确定选择性:使用所述抗原产生细胞提取物的免疫沉淀物,随后鉴别和/或定量存在于所述免疫沉淀物中的两种或更多种非抗体分子。条款45.条款44的方法,其中在所述免疫沉淀物中计算所述抗原/非-抗体分子的比例。条款46.条款37的方法,其中所述抗体是高亲和力抗体。条款47.一种用于制备匹配的抗体集合的方法,所述方法包括:(a)确定每种抗体对在细胞裂解物中的它的各种抗原的亲和力,(b)确定每种抗体对在细胞裂解物中的它的各种抗原的选择性,和(c)选择抗体以形成匹配的集合,其中使用免疫沉淀-质谱法(ip-ms)确定所述抗体的亲和力和/或所述抗体的选择性,且其中所述匹配的集合由两种或更多种抗体组成,就存在于所述细胞裂解物中的它的各种抗原而言,每种抗体具有至少100倍富集的选择性。条款48.条款47的方法,其中所述两种或更多种抗体具有彼此1个对数的对它们各自的抗原的亲和力。条款49.条款47的方法,其中所述匹配的集合含有3-10种抗体。条款50.条款47的方法,其中所述抗体结合有关的靶标。条款51.条款47的方法,其中所述有关的靶标是相同蛋白的翻译前和翻译后修饰形式。条款52.条款51的方法,其中所述蛋白的翻译前修饰形式未磷酸化且所述蛋白的翻译后修饰形式被磷酸化。条款53.一种用于确定抗体的选择性的方法,所述方法包括:(a)在允许所述抗体和细胞提取物中的一种或多种抗原之间形成免疫沉淀物的条件下,使所述抗体与细胞提取物接触,(b)收集在步骤(a)中形成的免疫沉淀物,和(c)通过质谱法鉴别存在于所述免疫沉淀物中的一种或多种非抗体分子,其中所述细胞提取物含有来自两个或更多个细胞类型或两个或更多个物种的一个或多个细胞类型的细胞组分。条款54.条款53的方法,其中所述两个或更多个细胞类型来自相同物种。条款55.条款53的方法,其中所述细胞类型得自两种或更多种以下组织:(a)肌肉组织,(b)结缔组织,(c)神经组织,和(d)上皮组织。条款56.条款53的方法,其中所述结缔组织是血液。条款57.条款53的方法,其中所述两个或更多个细胞类型来自不同物种。条款58.条款57的方法,其中所述来自不同物种的两个或更多个细胞类型得自来自每个物种的两种或更多种组织。条款59.一种用于确定抗体的选择性的方法,所述方法包括:(a)在允许所述抗体和所述两种或更多种蛋白中的一种或多种之间形成免疫沉淀物的条件下,使所述抗体与两种或更多种蛋白接触,(b)收集在步骤(a)中形成的免疫沉淀物,和(c)通过质谱法定量存在于所述免疫沉淀物中的各种蛋白的量。条款60.一种组合物,其包含:(a)从一个或多个细胞类型得到的细胞提取物,和(b)外源地添加的抗体,其中所述细胞类型来自两种或更多种不同物种。条款61.条款60的组合物,其中从细胞裂解物制备所述细胞提取物。条款62.条款61的组合物,其中通过裂解两种或更多种细胞类型的细胞得到所述细胞裂解物,随后离心得到的裂解物以除去不溶物。条款63.条款60的组合物,其中在大于或等于10,000xg执行所述离心至少15分钟。条款64.条款60的组合物,其中所述抗体对存在于所述细胞提取物中的至少一种蛋白具有亲和力。条款65.一种用于鉴别选择性地结合得自不同物种的细胞的靶分子的抗体的方法,所述方法包括:(a)在允许所述抗体和存在于每种细胞裂解物中的一种或多种靶分子之间形成形成两种或更多种免疫沉淀物的条件下,使所述抗体与从不同物种的细胞产生的两种或更多种细胞裂解物接触,(b)从每种细胞裂解物收集所述免疫沉淀物,和(c)通过质谱法确定每种免疫沉淀物中的靶分子的纯化倍数。条款66.条款65的方法,其中所述物种选自:(a)智人,(b)穴兔,(c)小家鼠,和(d)褐家鼠。条款67.条款65的方法,其中响应于在从其得到所述细胞裂解物的不同物种之间保守的表位或蛋白而产生所述抗体。条款68.条款67的方法,其中所述表位来自蛋白或所述蛋白是在选自以下的类别中:(a)热激蛋白,(b)聚合酶,(c)细胞表面受体,(d)转录因子,(e)激酶,(f)去磷酸化酶,(g)膜相关的转运蛋白,和(h)锌指蛋白。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1