一种基于神经网络的声源定位方法和装置与流程
本发明涉及声源定位领域,特别涉及一种基于神经网络的声源定位方法和装置。
背景技术:
随着科技的发展和社会的进步,语音识别技术得到了广泛应用,极大了方便了人们的日常生活,提高了用户体验。语音识别首先要处理的是针对采集的语音信号进行回声消除,而回声消除过程中最关键的是一点就是声源定位。
通常,音源与麦克风之间存在着一个二维矩阵关系,即距离和角度。即使是同一个音源,如果其与麦克风之间的距离和角度是不断变化的,那么麦克风采集得到的音源信息也实时在变化着。为了能够准确进行语音识别,需要有绘制音源信号与二维矩阵的关系,为此,传统的语音识别设备就要求音源在发出语音时,需要让麦克多次采集一个二维数据,并利用波束成形算法达到构造音源信号与二维矩阵的关系,以便作为后续继续识别相同音源的依据。
然而,传统的声源定位存在着诸多问题,首先是样本采集上,用户不可能不断尝试在不同角度、距离发出声源,这就导致麦克风无法采集到足够多的二维数据,在绘制音源信号与二维矩阵的关系时往往存在偏差;其次,波束成形算法是一种基于经验的算法,其在构造音源信号与二维矩阵的关系时准确度存在偏差,这将影响到声源定位的准确性。
技术实现要素:
为此,需要提供一种基于神经网络的声源定位的技术方案,用于解决现有的声源定位算法音频采集复杂度高、定位准确性差等问题。
为实现上述目的,发明人提供了一种基于神经网络的声源定位装置,其特征在于,所述装置包括麦克风阵列、处理器、神经网络电路和计算机程序;所述麦克风阵列包括阵列排布的多个麦克风;处理器与各个麦克风连接,所述计算机程序被处理器执行时实现以下步骤:
控制麦克风阵列采集多组声源信息,并将其传输给神经网络电路;所述声源信息包括声源信号强度和声源位置信息;
控制神经网络电路进行神经网络训练,直至训练完成;
将麦克风采集到的声源信号强度传输至训练好的神经网络电路,并接收神经网络电路输出的声源位置信息。
进一步地,麦克风阵列采集到的多组声源信息中的声源信号强度符合正态分布。
进一步地,所述声源位置信息包括声源角度信息和声源距离信息,所述声源角度信息与声源距离信息以二维矩阵标签的方式进行存储,每一声源对应一个二维矩阵标签;所述声源距离信息为当前声源位置与识别该声源的麦克风之间的距离。
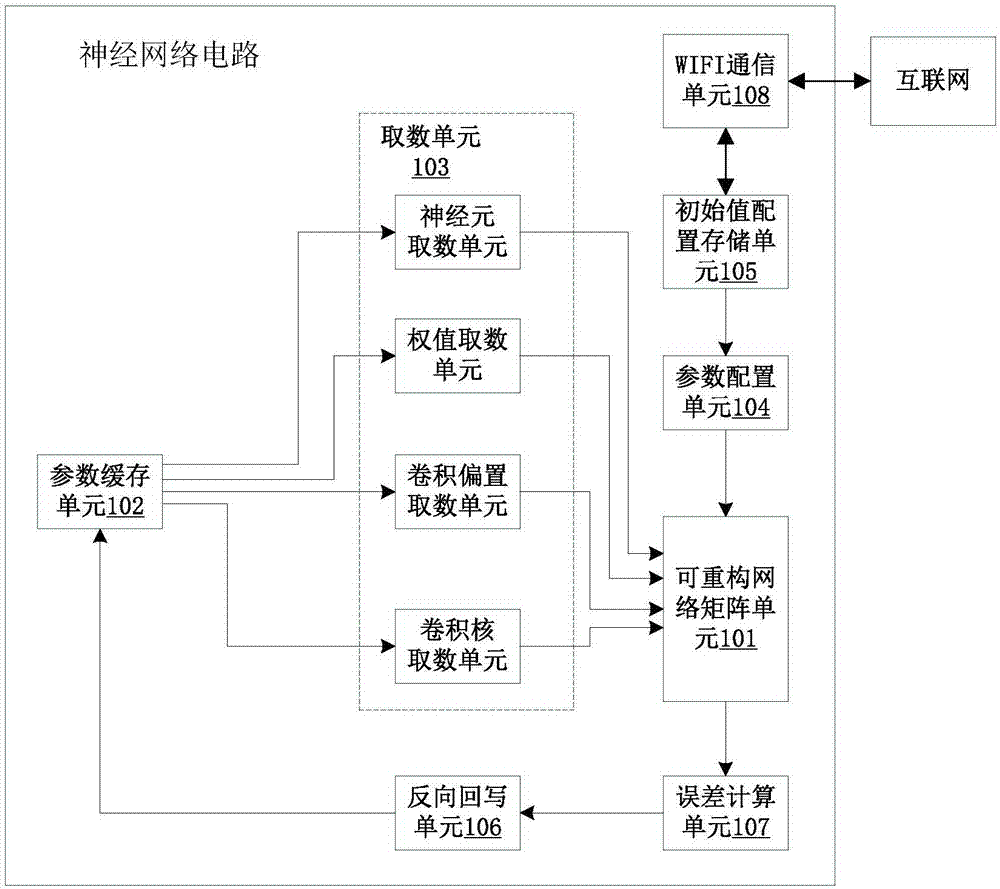
进一步地,神经网络电路包括可重构网络矩阵单元、参数缓存单元、取数单元、参数配置单元、初始值存储单元、反向回写单元和误差计算单元;
所述初始值存储单元用于存储各个参数初始值;
所述参数配置单元用于根据各个参数初始值控制取数单元从参数缓存单元中获取相应数量的各个参数元素,对可重构网络矩阵单元进行配置;
所述可重构网络矩阵单元用于根据配置的各个参数元素的初始值进行神经网络计算,所述误差计算单元用于判断本次计算结果与标准信息的匹配度的误差是否小于预设误差,若是则判定为训练完成,可重构神经网络矩阵单元用于将各个参数元素的参数值更新为当前的各个参数值,并将更新后的各个参数值写入参数缓存单元中;否则可重构神经网络矩阵单元用于根据本次训练结果的匹配度相较于上一次训练结果的匹配度的差异,调整各个参数元素的配置参数值,并通过反向回写单元将调整后的参数值写入参数缓存单元中,以及控制取数单元根据调整后的参数值从获取相应数量的各个参数元素,并再次进行神经网络计算,直至训练完成。
进一步地,神经网络网络的配置参数包括神经网络层数、各层神经网络的神经元数量、各层神经网络的卷积核值、卷积配置值以及权值。
发明人还提供了一种基于神经网络的声源定位方法,所述方法应用于基于神经网络的声源定位装置,所述装置包括麦克风阵列、处理器、神经网络电路;所述麦克风阵列包括阵列排布的多个麦克风;处理器与各个麦克风连接,所述方法包括以下步骤:
控制麦克风阵列采集多组声源信息,并将其传输给神经网络电路;所述声源信息包括声源信号强度和声源位置信息;
控制神经网络电路进行神经网络训练,直至训练完成;
将麦克风采集到的声源信号强度传输至训练好的神经网络电路,并接收神经网络电路输出的声源位置信息。
进一步地,麦克风阵列采集到的多组声源信息中的声源信号强度符合正态分布。
进一步地,所述声源位置信息包括声源角度信息和声源距离信息,所述声源角度信息与声源距离信息以二维矩阵标签的方式进行存储,每一声源对应一个二维矩阵标签;所述声源距离信息为当前声源位置与识别该声源的麦克风之间的距离。
进一步地,神经网络电路包括可重构网络矩阵单元、参数缓存单元、取数单元、参数配置单元、初始值存储单元、反向回写单元和误差计算单元;所述方法包括以下步骤:
初始值存储单元存储各个参数初始值;
参数配置单元根据各个参数初始值控制取数单元从参数缓存单元中获取相应数量的各个参数元素,对可重构网络矩阵单元进行配置;
可重构网络矩阵单元根据配置的各个参数元素的初始值进行神经网络计算,误差计算单元判断本次计算结果与标准信息的匹配度的误差是否小于预设误差,若是则判定为训练完成,可重构神经网络矩阵单元将各个参数元素的参数值更新为当前的各个参数值,并将更新后的各个参数值写入参数缓存单元中;否则可重构神经网络矩阵单元根据本次训练结果的匹配度相较于上一次训练结果的匹配度的差异,调整各个参数元素的配置参数值,并通过反向回写单元将调整后的参数值写入参数缓存单元中,以及控制取数单元根据调整后的参数值从获取相应数量的各个参数元素,并再次进行神经网络计算,直至训练完成。
进一步地,神经网络网络的配置参数包括神经网络层数、各层神经网络的神经元数量、各层神经网络的卷积核值、卷积配置值以及权值。
本发明提供了一种基于神经网络的声源定位方法和装置,所述方法包括以下步骤:控制麦克风阵列采集多组声源信息,并将其传输给神经网络电路;所述声源信息包括声源信号强度和声源位置信息;控制神经网络电路进行神经网络训练,直至训练完成;将麦克风采集到的声源信号强度传输至训练好的神经网络电路,并接收神经网络电路输出的声源位置信息。本发明利用深度学习和麦克风阵列,对音源样本与声源位置信息进行训练,构建两者之间关系,相较于传统的采用波束成形算法构建音源与麦克风之间二维矩阵关系的方式,有效降低样本采集的复杂度,提高了二维矩阵关系的准确性,进而提高了声源定位的精确度。
附图说明
图1为本发明一实施方式涉及的神经网络电路的示意图;
图2为本发明一实施例涉及的误差计算单元的电路结构图;
图3为本发明一实施例涉及的升级单元的电路结构图;
图4为本发明一实施例涉及的累加器单元的电路结构图;
图5为本发明一实施例涉及的可重构神经网络矩阵的电路结构图;
图6为本发明一实施方式涉及的基于神经网络的声源定位方法的流程图;
图7为本发明一实施方式涉及的神经网络电路进行训练的流程图;
附图标记说明:
101、可重构网络矩阵单元;1011、升级单元;1012、激活函数单元;1013、计算缓存单元;1014、乘加器单元;1015、互联矩阵单元;
102、参数缓存单元;
103、取数单元;
104、参数配置单元;
105、初始值存储单元;
106、反向回写单元;
107、误差计算单元;
108、wifi通信单元;
具体实施方式
为详细说明技术方案的技术内容、构造特征、所实现目的及效果,以下结合具体实施例并配合附图详予说明。
发明人还提供了一种基于神经网络的声源定位装置,所述装置包括麦克风阵列、处理器、神经网络电路和计算机程序;所述麦克风阵列包括阵列排布的多个麦克风;处理器与各个麦克风连接。
所述计算机程序被处理器执行时实现以下步骤:
控制麦克风阵列采集多组声源信息,并将其传输给神经网络电路;所述声源信息包括声源信号强度和声源位置信息。在采集声源信息过程中,可以先将麦克风阵列对准音源(如某一发声用户),由于麦克风阵列中的各个麦克风与音源的距离、角度不尽相同,因而各个麦克风所采集到声源信号强度也相应不同。
在本实施方式中,所述声源位置信息包括声源角度信息和声源距离信息,所述声源角度信息与声源距离信息以二维矩阵标签的方式进行存储,每一声源对应一个二维矩阵标签;所述声源距离信息为当前声源位置与识别该声源的麦克风之间的距离。优选的,麦克风阵列采集到的多组声源信息中的声源信号强度符合正态分布,即每次采集声源的角度和距离分别服从(-a,+a)以及(-r,+r)的正态分布,以保证进行神经网络电路的训练数据的更具针对性。
而后控制神经网络电路进行神经网络训练,直至训练完成。
如图1所示,神经网络电路包括可重构网络矩阵单元101、参数缓存单元102、取数单元103、参数配置单元104、初始值存储单元105、反向回写单元106和误差计算单元107;
所述初始值存储单元105用于存储各个参数初始值。在本实施方式中,所述装置包括wifi通信单元108,所述wifi通信单元108与互联网连接。所述神经网络电路包括初始值配置查询单元,初始值配置查询单元用于查询初始值存储单元的各个参数初始值,初始值配置查询单元还用于在未从初始值存储单元105中查询到声源定位对应的神经网络结构配置参数初始值时,通过wifi通信单元108从互联网中搜索声源定位所需的神经网络结构配置参数初始值,并在搜索到需要的神经网络结构配置参数初始值后,将其存储于初始值存储单元105中。
所述参数配置单元104用于根据各个参数初始值控制取数单元103从参数缓存单元102中获取相应数量的各个参数元素,对可重构网络矩阵单元101进行配置。在本实施方式中,神经网络网络的配置参数包括神经网络层数、各层神经网络的神经元数量、各层神经网络的卷积核值、卷积配置值以及权值。
所述可重构网络矩阵单元101用于根据配置的各个参数元素的初始值进行神经网络计算,所述误差计算单元107用于判断本次计算结果与标准信息的匹配度的误差是否小于预设误差,若是则判定为训练完成,可重构神经网络矩阵单元101用于将各个参数元素的参数值更新为当前的各个参数值,并将更新后的各个参数值写入参数缓存单元102中;否则可重构神经网络矩阵单元101用于根据本次训练结果的匹配度相较于上一次训练结果的匹配度的差异,调整各个参数元素的配置参数值,并通过反向回写单元106将调整后的参数值写入参数缓存单元102中,以及控制取数单元103根据调整后的参数值从获取相应数量的各个参数元素,并再次进行神经网络计算,直至训练完成。误差计算单元的电路结构如图2所示。
所述标准信息是指输入至可重构网络矩阵单元进行参考比对的信息,以声源定位为例,可重构网络矩阵单元需要根据输入的声源信号强度定位出当前声源所在的坐标位置,那么标准信息就是指当前声源与采集该声源信号强度的麦克风之间的实际距离。
如图5所示,所述可重构神经网络矩阵101包括互联矩阵单元1015、累加器单元1014、升级单元1011、激活函数单元1012、累加器配置单元;所述累加器单元、升级单元、激活函数单元分别与互联矩阵单元连接,所述累加器单元与累加器配置单元连接;所述累加器单元包括多个不同精度的累加器单元。
参数配置单元除了配置可重构神经网络矩阵进行训练的各个参数之外,同时也会配置各个参数元素之间的参数连接信息,以使得可重构神经网络矩阵可以根据各个配置参数和参数连接信息重构出相应功能(如声源定位)的神经网络结构。参数连接信息与其对应的配置参数初始值事先存储于初始值存储单元中,当初始值存储单元未查询到任务请求对应的神经网络结构配置参数初始值时,通过wifi通信单元108从互联网中搜索任务请求所需的神经网络结构配置参数初始值时可以一并下载该参数初始值对应的参数连接关系,并存储于初始值存储单元中。
所述累加器配置单元用于配置累加器精度,所述可重构神经网络矩阵在进行神经网络训练时,根据配置的累加器精度采用相对应精度的累加器单元进行计算;所述互联矩阵单元用于根据参数连接信息对累加器单元、升级单元、激活函数单元进行互联,从而形成对应的神经网络结构。升级单元的电路结构如图3所示、累加器单元的电路结构如图4所示。
而后将麦克风采集到的声源信号强度传输至训练好的神经网络电路,并接收神经网络电路输出的声源位置信息。由于音源与麦克风之间二维矩阵关系是通过神经网络电路经过反复多次训练得出的,因而将麦克风采集到的声源信号强度传输至训练好的神经网络电路,可以提高声源定位的精确度。
如图6所示,为本发明一实施方式涉及的基于神经网络的声源定位方法的流程图。所述方法应用于基于神经网络的声源定位装置,所述装置包括麦克风阵列、处理器、神经网络电路;所述麦克风阵列包括阵列排布的多个麦克风;处理器与各个麦克风连接,所述方法包括以下步骤:
首先进入步骤s601控制麦克风阵列采集多组声源信息,并将其传输给神经网络电路;所述声源信息包括声源信号强度和声源位置信息。在本实施方式中,麦克风阵列采集到的多组声源信息中的声源信号强度符合正态分布。所述声源位置信息包括声源角度信息和声源距离信息,所述声源角度信息与声源距离信息以二维矩阵标签的方式进行存储,每一声源对应一个二维矩阵标签;所述声源距离信息为当前声源位置与识别该声源的麦克风之间的距离。
而后进入步骤s602控制神经网络电路进行神经网络训练,直至训练完成;
而后进入步骤s603将麦克风采集到的声源信号强度传输至训练好的神经网络电路,并接收神经网络电路输出的声源位置信息。
如图7所示,神经网络电路包括可重构网络矩阵单元、参数缓存单元、取数单元、参数配置单元、初始值存储单元、反向回写单元和误差计算单元;所述方法包括以下步骤:
首先进入步骤s701初始值存储单元存储各个参数初始值;
而后进入步骤s702参数配置单元根据各个参数初始值控制取数单元从参数缓存单元中获取相应数量的各个参数元素,对可重构网络矩阵单元进行配置;在本实施方式中,神经网络网络的配置参数包括神经网络层数、各层神经网络的神经元数量、各层神经网络的卷积核值、卷积配置值以及权值。
而后进入步骤s703可重构网络矩阵单元根据配置的各个参数元素的初始值进行神经网络计算,误差计算单元判断本次计算结果与标准信息的匹配度的误差是否小于预设误差,若是则进入步骤705训练完成,可重构神经网络矩阵单元将各个参数元素的参数值更新为当前的各个参数值,并将更新后的各个参数值写入参数缓存单元中;否则进入步骤s704可重构神经网络矩阵单元根据本次训练结果的匹配度相较于上一次训练结果的匹配度的差异,调整各个参数元素的配置参数值,并通过反向回写单元将调整后的参数值写入参数缓存单元中,以及控制取数单元根据调整后的参数值从获取相应数量的各个参数元素。步骤s704后继续执行步骤s702、s703直至训练完成。
本发明提供了一种基于神经网络的声源定位方法和装置,所述方法包括以下步骤:控制麦克风阵列采集多组声源信息,并将其传输给神经网络电路;所述声源信息包括声源信号强度和声源位置信息;控制神经网络电路进行神经网络训练,直至训练完成;将麦克风采集到的声源信号强度传输至训练好的神经网络电路,并接收神经网络电路输出的声源位置信息。本发明利用深度学习和麦克风阵列,对音源样本与声源位置信息进行训练,构建两者之间关系,相较于传统的采用波束成形算法构建音源与麦克风之间二维矩阵关系的方式,有效降低样本采集的复杂度,提高了二维矩阵关系的准确性,进而提高了声源定位的精确度。
需要说明的是,尽管在本文中已经对上述各实施例进行了描述,但并非因此限制本发明的专利保护范围。因此,基于本发明的创新理念,对本文所述实施例进行的变更和修改,或利用本发明说明书及附图内容所作的等效结构或等效流程变换,直接或间接地将以上技术方案运用在其他相关的技术领域,均包括在本发明的专利保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!