一种利用近红外光谱判别茶鲜叶地理信息的方法与流程
本发明涉及一种判别不同地理信息茶鲜叶的方法,更具体的说涉及一种应用近红外光谱技术判别不同海拔高度、不同土壤类型及不同栽培地区茶鲜叶的方法。
背景技术
地理信息包括海拔高度、土壤类型及栽培地区等,而这些地理信息最终也会反馈到茶叶品质上,代表茶叶“身份”来源,地理信息能在一定程度上反应茶鲜叶质量,而茶鲜叶质量是成品茶品质的基础,只有应用高质量的茶鲜叶才会加工出高品质的成品茶。但是,当茶叶被采摘下来后,很难用肉眼进行地理信息的识别,因此,在茶鲜叶的收购市场,因缺乏一种有效的检测地理信息的手段,当要知道这些信息时往往凭借茶农或者商贩(卖方)的口述,由于受利益的驱使,很多茶农或者商贩并不会说出实情,这给茶叶加工厂带来诸多困惑。
就海拔高度来说,俗话说“高山云雾出好茶”,茶鲜叶质量除受自身遗传特性影响外,还与茶树栽培产地生态环境等因素密切相关,而海拔高度就是其中一个非常重要的因素。一般来说,生长在高海拔地区的茶鲜叶质量要优于低海拔地区的茶鲜叶,采摘于高海拔地区的茶鲜叶收购价格也会远高于低海拔地区的茶鲜叶。洪生等研究表明,随着海拔高度的增加,鲜叶氨基酸和咖啡碱含量均增加,茶多酚含量降低,有利于提高鲜叶质量;唐颢等研究了茶树生长海拔高度对茶鲜叶生化品质存在较大的影响;袁杰等认为应用高海拔栽培地区的鲜叶加工的成品茶香气浓度高、香气成分较多和更合理的香气含量比例;朱小苗等研究认为:茶树生长的海拔高度对茶叶中的游离氨基酸含量有显著影响,进而影响茶汤的滋味和营养价值。上述文献都佐证了海拔高度的增加对鲜叶质量存在着正影响作用,但都没有给出一种可以有效判别不同海拔高度茶鲜叶的方法。
就土壤类型来说,茶园土壤类型对茶树的生长发育起着非常重要的作用,就我国茶区土壤类型而言,主要分为红壤土、黄壤土和沙壤土三种类型。红壤土是我国中亚热带湿润地区分布的地带性红壤,属中度脱硅富铝化的铁铝土,通常具深厚红色土层,网纹层发育明显,粘土矿物以高岭石为主,呈酸性,盐基饱和度低;黄壤土是指亚热带常年湿润的生物气候条件下形成的地带性土壤,ph4.5-5.5,黏粒硅铝率2.0-2.3,有机质可达5%以上。表层有机质和氮、磷、钾等养分高于红壤,质地也较轻;沙壤土是指土壤颗粒组成中黏粒、粉粒、砂粒含量适中的土壤。沙壤土土质松散,通气透水,不黏不硬,易于耕作,但保水和保肥较差。由于三种类型土壤的营养成分和理化性质都存在着较大的不同,因此,同一品种的茶树种植在3种不同的土壤类型上,鲜叶的质量也会存在着较大的不同,也是造成单位面积茶叶产量产生较大差异的一个重要原因。由于不同土壤类型上生长的鲜叶的品质存在较大差异,导致加工的成品茶品质也存在较大差异,因此,影响了茶叶的市场销售价格。在收购鲜叶时,收购人员会将鲜叶按照其生长土壤类型的不同而进行分类,开展分类加工,再根据市场需求对成品茶品质进行有目的的拼配,有利于茶叶品质的保障,也有利于茶叶企业利益的最大化。但目前因缺乏有效的判别手段,在进行判别时,收购人员常应用感官方法和工作经验判别不同土壤类型生长的茶鲜叶,但判别结果主观性很强,且易出错。
就栽培地区来说,茶树与栽培环境是统一体。在茶树生长发育过程中,由于当地小气候环境的不同以及栽培土壤肥力、营养元素的差别,相同的茶树品种在不同的栽培地区,茶鲜叶的内含成分种类与含量高低会发生一定的变化。当前,常用感官方法和工作经验来判别不同栽培地区的同一品种的茶鲜叶,但该方法同样存在主观性较强,且易出错。
技术实现要素:
针对上述现有技术存在的问题,本发明提供一种利用近红外光谱技术,将线性的联合区间偏最小二乘法和非线性的人工神经网络方法相结合,用于准确的预测茶鲜叶的海拔高度、土壤类型和栽培地区等地理信息。
为实现上述目的,本发明采用如下技术方案:
一种利用近红外光谱判别茶鲜叶地理信息的方法,所述方法为利用具有不同地理信息茶鲜叶的近红外光谱建立预测模型,然后根据所建立的预测模型对未知茶鲜叶进行地理信息的判定;其特征在于:所述预测模型的建立方法为:通过扫描不同地理信息茶鲜叶样品的近红外光谱并将近红外光谱信息进行去噪处理后,应用线性的联合区间偏最小二乘法筛选反映不同地理信息茶鲜叶的特征光谱区间,再对筛选的特征光谱区间进行主成分分析,得到主成分数和主成分得分值,再以主成分得分值为输入值建立茶鲜叶地理信息的人工神经网络预测模型;所述地理信息为海拔高度、土壤类型、栽培地区的任意一种。
所述的一种利用近红外光谱判别茶鲜叶地理信息的方法,其特征在于:所述地理信息预测模型的建立方法包括如下主要步骤:
1)茶鲜叶样品采集:分别采集不同地理信息的茶鲜叶样品;
2)茶鲜叶样品光谱扫描:应用傅里叶变换型近红外光谱仪分别扫描茶鲜叶样品的近红外光谱,得到光谱信息;
3)光谱信息去噪处理:用opus7.0软件对茶鲜叶样品的近红外光谱数据进行去噪处理,所述去噪处理为平滑;经平滑处理的光谱数据转化为成对的数据点,作为建模的光谱数据,每条光谱有1557对数据点,光谱数据点间隔为3.86cm-1;然后对不同地理信息的茶鲜叶样品分别赋予不同的化学值;将建模的光谱数据和与其对应的化学值存储于excel表中;
4)茶鲜叶样品特征光谱区间筛选:将步骤3)excel表中光谱数据的吸光度值和赋予的化学值导入到matlab2012a软件中,选用combin函数计算建模总数,应用线性的联合区间偏最小二乘法程序包,将样品光谱等划分为10-25个子区间,联合其中的2,3和4个子区间分别建立近红外光谱预测模型,当rmsecv最小时,此时建模的光谱区间即为筛选的最佳特征光谱区间;
5)特征光谱区间主成分分析:应用matlab2012a软件中的主成分分析程序包对筛选的特征光谱区间进行主成分分析,得到每个主成分的单独贡献率值、累计贡献率值和主成分得分;
6)建立人工神经网络预测模型:以步骤5)中筛选的特征光谱区间主成分得分为输入值,以步骤3)中赋予的化学值为输出值,应用neuroshell2软件建立wardnets方法的人工神经网络预测模型;
根据所建立的预测模型对未知茶鲜叶进行地理信息的判定方法包括如下主要步骤:
a):应用傅里叶变换型近红外光谱仪扫描未知茶鲜叶样品的近红外光谱;
b):将步骤6)中已建好的人工神经网络预测模型调入neuroshell2软件,应用该软件中的模型预测功能,得到输出值,根据输出值数据判定未知茶鲜叶样品的地理信息。
所述的一种利用近红外光谱判别茶鲜叶地理信息的方法,其特征在于:所述的步骤1)中茶鲜叶样品包括:单芽,第一叶、第二叶、第三叶、一芽一叶、一芽二叶和一芽三叶。
所述的一种利用近红外光谱判别茶鲜叶地理信息的方法,其特征在于:所述步骤2)中的傅里叶变换型近红外光谱仪为美国赛默飞·世尔antarisⅱ型傅里叶变换近红外光谱仪,光谱扫描软件:tqanalyst9.4.45软件,光谱扫描范围4000-10000cm-1,分辨率8cm-1,检测器为ingaas,每个样品采集3次光谱,每次扫描64次,然后对3次采集的光谱进行平均,以平均光谱作为该鲜叶样品的最终光谱。
所述的一种利用近红外光谱判别茶鲜叶地理信息的方法,其特征在于:所述地理信息为海拔高度时,所述步骤4)中筛选的最佳特征光谱区间包括4个子区间,分别为[36920],4个子区间对应的波数区间分别为:4547.32-4817.31cm-1;5368.85-5638.84cm-1;6190.38-6460.36cm-1;9194.93-9461.06cm-1。
所述的一种利用近红外光谱判别茶鲜叶地理信息的方法,其特征在于:所述地理信息为土壤类型时,所述步骤4)中筛选的最佳特征光谱区间包括4个子区间,分别为[3111920],4个子区间对应的波数区间分别为:4547.32-4817.31cm-1;6738.06-7008.05cm-1;8924.94-9191.07cm-1;9194.93-9461.06cm-1。
所述的一种利用近红外光谱判别茶鲜叶地理信息的方法,其特征在于:所述地理信息为栽培地区时,所述步骤4)中筛选的最佳特征光谱区间包括4个子区间,分别为[3111922],4个子区间对应的波数区间分别为:4547.32-4817.31cm-1;6738.06-7008.05cm-1;8924.94-9191.07cm-1;9734.9-10000cm-1。
所述的一种利用近红外光谱判别茶鲜叶地理信息的方法,其特征在于:所述步骤5)中的主成分累计贡献率≥85%才可以有效代表样品光谱信息,用前3个主成分得分为输入值建立人工神经网络预测模型。
所述的一种利用近红外光谱判别茶鲜叶地理信息的方法,其特征在于:所述步骤6)中的人工神经网络预测模型为应用3个隐含层的wardnets方法。
与现有技术相比,本发明的有益效果:
本发明提供一种利用近红外光谱判别茶鲜叶地理信息的方法,通过将线性的联合区间偏最小二乘法和非线性的人工神经网络相结合,用于准确的预测茶鲜叶的海拔高度、土壤类型和栽培地区。通过先剔除鲜叶样品噪声信息,然后应用线性联合区间偏最小二乘法筛选反映不同海拔高度、不同土壤类型和不同栽培地区等地理信息的茶鲜叶的特征光谱区间,有利于降低模型的运算量,增加模型的稳健性;再对筛选的特征光谱区间进行主成分分析,并以主成分得分为输入值建立判别茶鲜叶地理信息的人工神经网络预测模型,不仅达到大大降低模型运算量、简化模型的目的,同时还起到提高模型的预测准确度和增强模型实用性的目的,研究结果也为成品茶质量保障提供了一种科学的依据。
附图说明
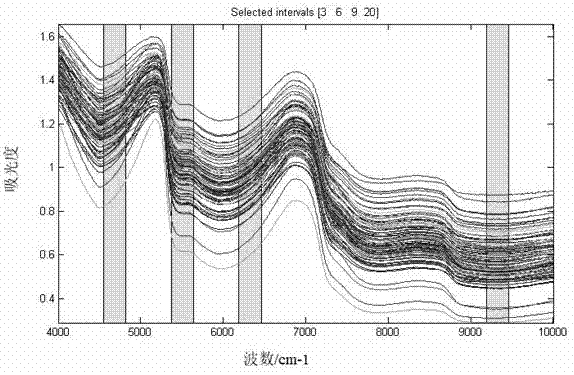
图1是本发明实施例1中应用联合区间偏最小二乘法筛选的特征光谱区间。
图2是本发明中wardnets方法第1种信息传递方式内部结构(2个隐含层)。
图3是本发明中wardnets方法第2种信息传递方式内部结构(3个隐含层)。
图4是本发明中wardnets方法第3种信息传递方式内部结构(2个隐含层)。
图5是本发明实施例2中应用联合区间偏最小二乘法筛选的特征光谱区间。
图6是本发明实施例3中应用联合区间偏最小二乘法筛选的特征光谱区间。
具体实施方式
以下结合附图和具体实施例对本发明作进一步的详细说明。
实施例1:一种利用近红外光谱判别茶鲜叶海拔高度的方法
一种近红外光谱结合线性和非线性化学计量学方法判别不同海拔高度茶鲜叶的方法,扫描获得不同海拔高度鲜叶样品近红外光谱并对样品光谱进行预处理后,应用联合区间偏最小二乘法筛选反映不同海拔高度茶鲜叶样品的特征光谱区间和对特征光谱进行主成分分析后,再以主成分得分为输入值建立三种信息传递方式的不同海拔高度鲜叶人工神经网络预测模型,用于判别不同海拔高度的鲜叶,具体包括以下步骤:
(1)茶鲜叶样品采集与分类
鲜叶样品共400份,200m<鲜叶海拔≤500m,500m<鲜叶海拔≤850m,850m<鲜叶海拔≤1100m和1100m<鲜叶海拔≤1400m的4类不同海拔高度的鲜叶样品,每类样品各100份。鲜叶样品采摘标准分别为:芽,第一叶、第二叶、第三叶、一芽一叶、一芽二叶和一芽三叶(每个海拔高度均采集了包括芽,第一叶、第二叶、第三叶、一芽一叶、一芽二叶和一芽三叶等不同成熟度茶鲜叶样品,每种成熟度茶鲜叶样品数量大致相等)。根据海拔高度的不同,鲜叶样品按照3:1的比例随机划分为校正集和验证集2个集合,其中校正集样品300份,验证集样品100份;校正集样品用于建立不同海拔高度鲜叶的近红外光谱校正模型,验证集样品用于对校正集预测模型稳健性进行检验。对4类不同海拔的茶鲜叶样品赋予不同的化学值,其中200m<鲜叶海拔≤500m赋值1.000,500m<鲜叶海拔≤850m赋值2.000,850m<鲜叶海拔≤1100m赋值3.000,1100m<鲜叶海拔≤1400m赋值4.000。
(2)光谱扫描
采用美国赛默飞·世尔antarisⅱ型傅里叶变换近红外光谱仪(ft-nir),选用积分球漫反射光学平台;光谱扫描范围4000-10000cm-1;分辨率8cm-1,检测器为ingaas。每个样品采集3次光谱,每次扫描64次,对3次采集的光谱进行平均,以平均光谱作为该鲜叶样品的最终光谱。在扫描鲜叶样品光谱前,将该近红外光谱仪预热30min-1h,保持室内温度和湿度基本一致后,再将样品装入与仪器配套的旋转杯中进行光谱扫描,每次样品的装样厚度保持一致,保证近红外光无法穿透样品。
(3)光谱信息去噪处理
应用opus7.0化学计量学软件对扫描得到的不同海拔高度的鲜叶样品近红外光谱进行平滑、一阶导数,二阶导数、多元散射校正和矢量归一化预处理,提高建模时光谱的信噪比,有利于建立稳健的预测模型;在此基础上,将样品光谱转化为成对的数据点存储于excel表中,每条光谱有1557对数据点,光谱数据点间隔为3.86cm-1,经比较模型结果,最佳光谱预处理方法为平滑。
(4)鲜叶特征光谱区间筛选
应用线性的联合区间偏最小二乘法(synergyintervalpartialleast-squares,sipls)建立4类海拔高度鲜叶的近红外光谱预测模型,当交互验证均方根方差(rootmeansquareerrorofcalibration,rmsecv)最小时,此时建模的光谱区间即为筛选的反映不同海拔高度鲜叶的最佳光谱区间,得到校正集模型的相关系数值(correlationcoefficientofcrossvalidation,rc)。其中,rmsecv越小,rc越大,表示模型预测效果越好。
rmsecv计算公式为:
式中,n表示样本数,yi和yi’分别为样品集中第i个样品的实测值和预测值,
r计算公式为:
n表示样本数,yi和yi’分别为样品集中第i个样品的实测值和预测值,
表1联合区间偏最小二乘法筛选的特征光谱区间
从表1可以看出,将鲜叶样品光谱区间等划分为22个光谱子区间、应用8个因子数,选择[36920]4个子区间时,建立的近红外光谱预测模型rmsecv最小,为0.6886,模型的相关系数rc为0.7912。[36920]4个子区间对应的波数区间分别为:4547.32-4817.31cm-1;5368.85-5638.84cm-1;6190.38-6460.36cm-1;9194.93-9461.06cm-1(参见图1),占全部光谱数据点的比例为18.18%。
(5)特征光谱区间主成分分析
应用matlab2012a软件对上述筛选的4个特征光谱子区间[36920]进行主成分分析,求得每个主成分的单独贡献率、累计贡献率和前三个主成分得分。前7个主成分的贡献率分别如下:
表2前7个主成分贡献率
从表2可以看出,pc1贡献率最大,为95.858%,从pc1-pc7主成分贡献率急剧降低,pc6和pc7的贡献率仅为0.001%,可见,基本没有了有用信息。其中,pc1,pc2和pc3三个主成分的累计贡献率为99.973%,完全可以代表上述光谱信息用于后续数据分析。可见,筛选特征光谱区间对样品信息进行主成分提取起到了非常重要的作用。
表3建模样品前3个主成分得分
(6)人工神经网络预测模型的建立
在建立人工神经网络模型时,为有效提高模型的稳健性,减少噪声信息的输入对模型的不利影响,要求建模时输入变量尽可能的少,但还要有效的代表原始光谱数据信息,因此,本模型以上述主成分分析筛选的前3个主成分得分为输入值,以不同海拔高度鲜叶赋值为输出值(200m<鲜叶海拔≤500m输出值为1.000,500m<鲜叶海拔≤850m输出值为2.000,850m<鲜叶海拔≤1100m输出值为3.000和1100m<鲜叶海拔≤1400m输出值为4.000),经多次优化,建立不同海拔高度鲜叶的人工神经网络预测模型。在建立模型时,由于模型内部隐含层和输出层间信息传递方式的不同,会对模型预测效果产生较大的影响。在建立人工神经网络模型时,选择并分别比较了wardnets方法的3种不同内部信息传递方法对模型预测结果的影响(包含不同的隐含层和活跃因子),具体参见图2,图3和图4。通过将前3个主成分得分分别输入到3种人工神经网络模型中,比较该三种模型相关系数rc和交互验证均方根方差rmsecv值,得到最佳预测模型。最佳校正集模型为具有3个隐含层的wardnets方法2人工神经网络模型,rc为0.995,rmsecv为0.157。
(7)模型稳健性检验
为有效避免出现过拟合现象,建立一个稳健的预测模型,因此,应用全部验证集样品对不同海拔高度茶鲜叶的人工神经网络预测模型效果进行检验,所得结果用相关系数(correlationcoefficientofprediction,rp)、验证均方差(rootmeansquareerrorofprediction,rmsep)和判别率表示,其中相关系数rp越大、rmsep越小则表示模型预测效果越好,可以准确的预测鲜叶样品;
rmsep计算公式为:
式中,n表示样本数,yi和yi’分别为样品集中第i个样品实测值和预测值,式中i≤n。
应用验证集100份样品对三种校正集模型进行检验,具体结果见表4:
表43种wardnets方法人工神经网络模型验证集结果
从表4可以看出,不同海拔高度鲜叶wardnets方法第1种信息传递方式的人工神经网络模型校正集rc为0.875,rmsecv为0.475,当用全部100个验证集样品对模型稳健性进行检验时,得到验证集模型rp为0.837,rmsep为0.536;不同海拔高度鲜叶wardnets方法第2种信息传递方式的人工神经网络模型校正集rc为0.995,rmsecv为0.157,当用全部100个验证集样品对模型稳健性进行检验时,得到验证集模型rp为0.988,rmsep为0.178;不同海拔高度鲜叶wardnets方法第3种信息传递方式的人工神经网络模型校正集rc为0.917,rmsecv为0.351,当用全部100个验证集样品对模型稳健性进行检验时,得到验证集模型rp为0.893,rmsep为0.422。可见,在应用wardnets方法但内部不同信息传递方式建立的人工神经网络模式中,以wardnets方法2(3个隐含层)建立的人工神经网络模型结果最佳,模型预测效果最好;其次为wardnets方法3(2个隐含层)建立的人工神经网络模型,最差为应用wardnets方法1(2个隐含层)建立的人工神经网络模型。可见,同样的方法,但内部信息传递方式的不同,会对建立模型的预测结果产生较大的影响,因此,建立模型时,要合理选择信息传递方式。
应用wardnets方法2(3个隐含层)建立的最佳人工神经网络模型对100个验证集鲜叶样品进行预测,预测结果见表5。从表5可以看出,鲜叶样品真值和预测值的差值(偏差)全部在±0.2范围内,表明模型对所有样品预测正确,判别率为100%。可见,应用联合区间偏最小二乘法结合非线性的人工神经网络方法实现了不同海拔高度鲜叶样品的快速、准确判别。
表5100个验证集鲜叶样品预测结果
(8)未知茶鲜叶样品海拔高度的判别
未知茶鲜叶样品海拔高度的判别其步骤同上述的模型稳健性检验,包括如下主要步骤:
a):应用傅里叶变换型近红外光谱仪扫描未知茶鲜叶样品的近红外光谱;
b):将上述(6)中已建好的人工神经网络预测模型调入neuroshell2软件,应用该软件中的模型预测功能,得到输出值,根据输出值数据判定未知茶鲜叶样品的海拔高度来源。如输出值在1.000附近时判别结果为:200m<鲜叶海拔≤500m;输出值在2.000附近时判别结果为:500m<鲜叶海拔≤850m;输出值在3.000附近时判别结果为:850m<鲜叶海拔≤1100m;输出值在4.000附近时判别结果为:1100m<鲜叶海拔≤1400m赋值4.000。
本发明提供一种利用近红外光谱技术,将线性的联合区间偏最小二乘法和非线性的人工神经网络方法相结合,用于准确的预测不同海拔高度的茶鲜叶。先剔除鲜叶样品噪声信息,得到最佳光谱预处理方法为平滑;然后应用线性联合区间偏最小二乘法筛选特征光谱区间,将鲜叶样品光谱区间等划分为22个光谱子区间、应用8个因子数,选择[36920]4个子区间时,建立的近红外光谱预测模型rmsecv最小,为0.6886,模型的相关系数rc为0.7912。[36920]4个子区间对应的波数区间分别为:4547.32-4817.31cm-1;5368.85-5638.84cm-1;6190.38-6460.36cm-1;9194.93-9461.06cm-1,有利于降低模型的运算量,增加模型的稳健性;再对筛选的特征光谱区间进行主成分分析,pc1,pc2和pc3三个主成分的累计贡献率为99.973%,以前3个主成分得分为输入值建立wardnets方法的三种内部信息传递方式的人工神经网络预测模型,以wardnets方法2(3个隐含层)建立的人工神经网络模型结果最佳(rp=0.988,rmsep=0.178),预测效果最好;其次为wardnets方法3(2个隐含层)建立的人工神经网络模型,最差为应用wardnets方法1(2个隐含层)建立的人工神经网络模型。本发明专利不仅可以达到大大降低模型运算量、简化模型的目的,同时还起到提高模型的预测准确度和增强模型实用性的目的。
实施例2:一种利用近红外光谱判别茶鲜叶土壤类型的方法
一种近红外光谱结合线性和非线性化学计量学方法判别不同土壤类型茶鲜叶的方法,用于准确的判别不同土壤类型的茶鲜叶。扫描获得鲜叶样品近红外光谱,先剔除噪声信息,然后应用线性联合区间偏最小二乘法筛选特征光谱区间,有利于降低模型的运算量,增加模型的稳健性;再对筛选的特征光谱区间进行主成分分析,并以主成分得分为输入值建立人工神经网络预测模型判别不同土壤类型的鲜叶。具体包括以下步骤:
(1)茶鲜叶样品采集与分类
鲜叶样品共400份,红壤土、黄壤土和沙壤土的3类不同土壤类型的鲜叶样品,样品数量各为133份,133份和134份,3类共400份样品。鲜叶样品采摘标准分别为:芽,第一叶、第二叶、第三叶、一芽一叶、一芽二叶和一芽三叶(每个土壤类型均采集了包括芽,第一叶、第二叶、第三叶、一芽一叶、一芽二叶和一芽三叶等不同成熟度茶鲜叶样品,每种成熟度茶鲜叶样品数量大致相等)。根据土壤类型的不同,鲜叶样品按照3:1的比例随机划分为校正集和验证集2个集合,其中校正集样品300份,验证集样品100份;校正集样品用于建立不同土壤类型鲜叶的近红外光谱校正模型,验证集样品用于对校正集预测模型稳健性进行检验。3类不同土壤类型鲜叶样品分别赋予不同的化学值,本实施例中将红壤土的化学值设定为1.000,黄壤土的化学值设定为2.000,沙壤土的化学值设定为3.000。
(2)光谱扫描
采用美国赛默飞·世尔antarisⅱ型傅里叶变换近红外光谱仪(ft-nir),选用积分球漫反射光学平台;光谱扫描范围4000-10000cm-1;分辨率8cm-1,检测器为ingaas。每个样品采集3次光谱,每次扫描64次,对3次采集的光谱进行平均,以平均光谱作为该鲜叶样品的最终光谱。在扫描鲜叶样品光谱前,将该近红外光谱仪预热30min-1h,保持室内温度和湿度基本一致后,再将样品装入与仪器配套的旋转杯中进行光谱扫描,每次样品的装样厚度保持一致,保证近红外光无法穿透样品。
(3)光谱信息去噪处理
应用opus7.0化学计量学软件对扫描得到的不同土壤类型的鲜叶样品近红外光谱进行平滑、一阶导数,二阶导数、多元散射校正和矢量归一化预处理,提高建模时光谱的信噪比,有利于建立稳健的预测模型;在此基础上,将样品光谱转化为成对的数据点存储于excel表中,每条光谱有1557对数据点,光谱数据点间隔为3.86cm-1,经比较模型结果,最佳光谱预处理方法为平滑。
(4)鲜叶特征光谱区间筛选
应用线性的联合区间偏最小二乘法(synergyintervalpartialleast-squares,sipls)建立3类土壤类型鲜叶的近红外光谱预测模型,当交互验证均方根方差(rootmeansquareerrorofcalibration,rmsecv)最小时,此时建模的光谱区间即为筛选的最佳光谱区间,得到校正集模型的相关系数值(correlationcoefficientofcrossvalidation,rc)。其中,rmsecv越小,rc越大,表示模型预测效果越好。
rmsecv计算公式为:
式中,n表示样本数,yi和yi’分别为样品集中第i个样品的实测值和预测值,
r计算公式为:
n表示样本数,yi和yi’分别为样品集中第i个样品的实测值和预测值,
表6联合区间偏最小二乘法筛选的特征光谱区间
从表6可以看出,将鲜叶样品光谱区间等划分为22个光谱子区间、应用8个因子数,选择[3111920]4个子区间时,建立的近红外光谱预测模型rmsecv最小,为0.5688,模型的相关系数rc为0.7864。[3111920]4个子区间对应的波数区间分别为:4547.32-4817.31cm-1;6738.06-7008.05cm-1;8924.94-9191.07cm-1;9194.93-9461.06cm-1(参见图5),占全部光谱数据点的比例为18.18%。
(5)特征光谱区间主成分分析
应用matlab2012a软件对上述筛选的4个特征光谱子区间[3111920]进行主成分分析,求得每个主成分的单独贡献率、累计贡献率和前三个主成分得分。前7个主成分的贡献率分别如下:
表7前7个主成分贡献率
从表7可以看出,pc1贡献率最大,为93.720%,从pc1-pc7主成分贡献率急剧降低,pc6和pc7的贡献率仅为0.001%,可见,基本没有了有用信息。其中,pc1,pc2和pc3三个主成分的累计贡献率为99.964%,完全可以代表上述光谱信息用于后续数据分析。可见,筛选特征区间对样品信息进行主成分提取起到了非常重要的作用。
表8建模样品前3个主成分得分
(6)人工神经网络预测模型的建立
在建立人工神经网络模型时,为有效提高模型的稳健性,减少噪声信息的输入对模型的不利影响,要求建模时输入变量尽可能的少,但还要有效的代表原始光谱数据信息,因此,本模型以上述主成分分析筛选的前3个主成分得分为输入值,以不同土壤类型鲜叶赋值为输出值(红壤土鲜叶输出值为1.000,黄壤土鲜叶输出值为2.000,沙壤土鲜叶输出值为3.000),经多次优化,建立不同土壤类型鲜叶的人工神经网络预测模型。在建立模型时,由于模型内部隐含层和输出层间信息传递方式的不同,会对模型预测效果产生较大的影响。在建立人工神经网络模型时,选择并分别比较了wardnets方法的3种不同内部信息传递方法对模型预测结果的影响(包含不同的隐含层和活跃因子),具体参见图2,图3和图4。通过将前3个主成分得分(表8)分别输入到3种人工神经网络模型中,比较该三种模型相关系数rc和交互验证均方根方差rmsecv值,得到最佳预测模型。最佳校正集模型为具有3个隐含层的wardnets方法2人工神经网络模型,rc为0.998,rmsecv为0.142。
(7)模型稳健性检验
为有效避免出现过拟合现象,建立一个稳健的预测模型,因此,应用全部验证集样品对不同土壤类型茶鲜叶的人工神经网络预测模型效果进行检验,所得结果用相关系数(correlationcoefficientofprediction,rp)、验证均方差(rootmeansquareerrorofprediction,rmsep)和判别率表示,其中相关系数rp越大、rmsep越小则表示模型预测效果越好,可以准确的预测不同土壤类型的鲜叶样品;
rmsep计算公式为:
式中,n表示样本数,yi和yi’分别为样品集中第i个样品的实测值和预测值,式中i≤n。
应用验证集100份样品对三种校正集模型进行检验,具体结果见表9。
表93种wardnets方法人工神经网络模型验证集结果
从表9可以看出,不同土壤类型鲜叶wardnets方法第1种信息传递方式的人工神经网络模型校正集rc为0.914,rmsecv为0.411,当用全部100个验证集样品对模型稳健性进行检验时,得到验证集模型rp为0.878,rmsep为0.475;不同土壤类型鲜叶wardnets方法第2种信息传递方式的人工神经网络模型校正集rc为0.998,rmsecv为0.142,当用全部100个验证集样品对模型稳健性进行检验时,得到验证集模型rp为0.990,rmsep为0.149;不同土壤类型鲜叶wardnets方法第3种信息传递方式的人工神经网络模型校正集rc为0.932,rmsecv为0.314,当用全部100个验证集样品对模型稳健性进行检验时,得到验证集模型rp为0.913,rmsep为0.420。可见,在应用wardnets方法但内部不同信息传递方式建立的人工神经网络模式中,以wardnets方法2(3个隐含层)建立的人工神经网络模型结果最佳,模型预测效果最好;其次为wardnets方法3(2个隐含层)建立的人工神经网络模型,最差为应用wardnets方法1(2个隐含层)建立的人工神经网络模型。可见,同样的方法,但内部信息传递方式的不同,会对建立模型的预测结果产生较大的影响,因此,建立模型时,要合理选择信息传递方式。
应用wardnets方法2(3个隐含层)建立的最佳人工神经网络模型对100个验证集鲜叶样品进行预测,预测结果见表10。从表10可以看出,鲜叶样品真值和预测值的差值(偏差)全部在±0.2范围内,表明模型对所有样品预测正确,判别率为100%。可见,应用联合区间偏最小二乘法结合非线性的人工神经网络方法实现了不同土壤类型鲜叶样品的快速、准确判别。
表10100个验证集鲜叶样品预测结果
(8)未知茶鲜叶样品土壤类型的判别
未知茶鲜叶样品土壤类型的判别其步骤同上述的模型稳健性检验,包括如下主要步骤:
a):应用傅里叶变换型近红外光谱仪扫描未知茶鲜叶样品的近红外光谱;
b):将上述(6)中已建好的人工神经网络预测模型调入neuroshell2软件,应用该软件中的模型预测功能,得到输出值,根据输出值数据判定未知茶鲜叶样品的产地土壤类型。如输出值在1.000附近时判别其为红壤土;输出值在2.000附近时判别其为黄壤土;输出值在3.000附近时判别其为沙壤土。
本发明提供一种利用近红外光谱技术,将线性的联合区间偏最小二乘法和非线性的人工神经网络方法相结合,用于准确的预测不同土壤类型的茶鲜叶。先剔除鲜叶样品噪声信息,得到最佳光谱预处理方法为平滑;然后应用线性联合区间偏最小二乘法筛选特征光谱区间,将鲜叶样品光谱区间等划分为22个光谱子区间、应用8个因子数,选择[3111920]4个子区间时,建立的近红外光谱预测模型rmsecv最小,为0.5688,模型的相关系数rc为0.7684。[3111920]4个子区间对应的波数区间分别为:4547.32-4817.31cm-1;6738.06-7008.05cm-1;8924.94-9191.07cm-1;9194.93-9461.06cm-1,有利于降低模型的运算量,增加模型的稳健性;再对筛选的特征光谱区间进行主成分分析,pc1,pc2和pc3三个主成分的累计贡献率为99.964%,以前3个主成分得分为输入值建立wardnets方法的三种内部信息传递方式的人工神经网络预测模型,以wardnets方法2(3个隐含层)建立的人工神经网络模型结果最佳(rp=0.990,rmsep=0.149),预测效果最好;其次为wardnets方法3(2个隐含层)建立的人工神经网络模型,最差为应用wardnets方法1(2个隐含层)建立的人工神经网络模型。本发明专利不仅可以达到大大降低模型运算量、简化模型的目的,同时还起到提高模型的预测准确度和增强模型实用性的目的。
实施例3:一种利用近红外光谱判别茶鲜叶栽培地区的方法
本实施例提供了一种近红外光谱结合线性和非线性化学计量学方法判别不同栽培地区同一品种茶鲜叶的方法,扫描获得不同栽培地区同一品种鲜叶样品近红外光谱并对样品光谱进行预处理后,应用联合区间偏最小二乘法筛选反映不同栽培地区同一品种茶鲜叶样品的特征光谱区间并对特征光谱进行主成分分析,再以主成分得分为输入值建立三种信息传递方式的不同栽培地区同一品种鲜叶人工神经网络预测模型,用于判别不同栽培地区同一品种的鲜叶,具体包括以下步骤:
(1)鲜叶样品采集与分类
鲜叶样品共400份,采摘时间为2017.3.4-2017.4.27,咸宁市、利川市和宣恩县的3个栽培地区中茶108鲜叶样品,样品数量各为133份,133份和134份,3类共400份样品。鲜叶样品采摘标准分别为:芽,第一叶、第二叶、第三叶、一芽一叶、一芽二叶和一芽三叶(每个栽培地区均采集了包括芽,第一叶、第二叶、第三叶、一芽一叶、一芽二叶和一芽三叶等不同成熟度茶鲜叶样品,每种成熟度茶鲜叶样品数量大致相等)。根据栽培地区不同,鲜叶样品按照3:1的比例随机划分为校正集和验证集2个集合,其中校正集样品300份,验证集样品100份;校正集样品用于建立3个地区中茶108茶鲜叶的近红外光谱校正模型,验证集样品用于对校正集预测模型稳健性进行检验。对3个不同栽培地区分别赋予不同的化学值,将咸宁市、利川市和宣恩县的茶鲜叶样品化学值分别设定为1.000,2.000和3.000。
(2)光谱扫描
采用美国赛默飞·世尔antarisⅱ型傅里叶变换近红外光谱仪(ft-nir),选用积分球漫反射光学平台;光谱扫描范围4000-10000cm-1;分辨率8cm-1,检测器为ingaas。每个样品采集3次光谱,每次扫描64次,对3次采集的光谱进行平均,以平均光谱作为该鲜叶样品的最终光谱。在扫描鲜叶样品光谱前,将该近红外光谱仪预热30min-1h,保持室内温度和湿度基本一致后,再将样品装入与仪器配套的旋转杯中进行光谱扫描,每次样品的装样厚度保持一致,保证近红外光无法穿透样品。
(3)光谱信息去噪处理
应用opus7.0化学计量学软件对扫描得到的3个地区中茶108鲜叶样品近红外光谱进行平滑、一阶导数,二阶导数、多元散射校正和矢量归一化预处理,提高建模时光谱的信噪比,有利于建立稳健的预测模型;在此基础上,将样品光谱转化为成对的数据点存储于excel表中,每条光谱有1557对数据点,光谱数据点间隔为3.86cm-1,经比较模型结果,最佳光谱预处理方法为平滑。
(4)鲜叶特征光谱区间筛选
应用线性的联合区间偏最小二乘法(synergyintervalpartialleast-squares,sipls)建立3个地区中茶108鲜叶的近红外光谱预测模型,当交互验证均方根方差(rootmeansquareerrorofcalibration,rmsecv)最小时,此时建模的光谱区间即为筛选的最佳光谱区间,得到校正集模型的相关系数值(correlationcoefficientofcrossvalidation,rc)。其中,rmsecv越小,rc越大,表示模型预测效果越好。
rmsecv计算公式为:
式中,n表示样本数,yi和yi’分别为样品集中第i个样品的实测值和预测值,
r计算公式为:
n表示样本数,yi和yi’分别为样品集中第i个样品的实测值和预测值,
表11联合区间偏最小二乘法筛选的特征光谱区间
从表11可以看出,将鲜叶样品光谱区间等划分为22个光谱子区间、应用7个因子数,选择[3111922]4个子区间时,建立的近红外光谱预测模型rmsecv最小,为0.5853,模型的相关系数rc为0.6918。[3111922]4个子区间对应的波数区间分别为:4547.32-4817.31cm-1;6738.06-7008.05cm-1;8924.94-9191.07cm-1;9734.9-10000cm-1(参见图6),占全部光谱数据点的比例为18.18%。
(5)特征光谱区间主成分分析
应用matlab2012a软件对上述筛选的4个特征光谱子区间[3111922]进行主成分分析,求得每个主成分的单独贡献率、累计贡献率和前三个主成分得分。前7个主成分的贡献率分别如下:
表12前7个主成分贡献率
从表12可以看出,pc1贡献率最大,为92.120%,从pc1-pc7主成分贡献率急剧降低,pc6和pc7的贡献率仅为0.001%,可见,基本没有了有用信息。其中,pc1,pc2和pc3三个主成分的累计贡献率为99.164%,完全可以代表上述光谱信息用于后续数据分析。可见,筛选特征光谱区间对样品信息进行主成分提取起到了非常重要的作用。
表13建模样品前3个主成分得分
(6)人工神经网络预测模型的建立
在建立人工神经网络模型时,为有效提高模型的稳健性,减少噪声信息的输入对模型的不利影响,要求建模时输入变量尽可能的少,但还要有效的代表原始光谱数据信息,因此,本模型以上述主成分分析筛选的前3个主成分得分为输入值,以不同栽培地区中茶108鲜叶为输出值(咸宁市中茶108鲜叶输出值为1.000,利川市中茶108鲜叶输出值为2.000,宣恩县中茶108鲜叶输出值为3.000),经多次优化,应用neuroshell2软件建立3个地区中茶108鲜叶的人工神经网络预测模型。在建立模型时,由于模型内部隐含层和输出层间信息传递方式的不同,会对模型预测效果产生较大的影响。在建立人工神经网络模型时,选择并分别比较了wardnets方法的3种不同内部信息传递方法对模型预测结果的影响(包含不同的隐含层和活跃因子),具体参见图2,图3和图4。通过将前3个主成分分别输入到3种人工神经网络模型中,比较该三种模型相关系数rc和交互验证均方根方差rmsecv值,得到最佳预测模型。最佳校正集模型为具有3个隐含层的wardnets方法2人工神经网络模型,rc为0.996,rmsecv为0.144。
(7)模型稳健性检验
为避免出现过拟合现象,建立一个稳健的预测模型,因此,应用全部验证集样品对不同栽培地区同一品种茶鲜叶的人工神经网络预测模型效果进行检验,所得结果用相关系数(correlationcoefficientofprediction,rp)、验证均方差(rootmeansquareerrorofprediction,rmsep)和判别率表示,其中相关系数rp越大、rmsep越小则表示模型稳健性越好,可以准确的预测不同栽培地区同一品种的鲜叶样品。
rmsep计算公式为:
式中,n表示样本数,yi和yi’分别为样品集中第i个样品的实测值和预测值,式中i≤n。
应用验证集100份样品对三种校正集模型进行检验,具体结果见表14。
表143种wardnets方法人工神经网络模型验证集结果
从表14可以看出,3个栽培地区中茶108鲜叶wardnets方法第1种信息传递方式的人工神经网络模型校正集rc为0.894,rmsecv为0.473,当用全部100个验证集样品对模型稳健性进行检验时,得到验证集模型rp为0.840,rmsep为0.523;3个栽培地区中茶108鲜叶wardnets方法第2种信息传递方式的人工神经网络模型校正集rc为0.996,rmsecv为0.144,当用全部100个验证集样品对模型稳健性进行检验时,得到验证集模型rp为0.993,rmsep为0.148;3个栽培地区中茶108鲜叶wardnets方法第3种信息传递方式的人工神经网络模型校正集rc为0.910,rmsecv为0.352,当用全部100个验证集样品对模型稳健性进行检验时,得到验证集模型rp为0.905,rmsep为0.372。可见,在应用wardnets方法但内部不同信息传递方式建立的人工神经网络模式中,以wardnets方法2(3个隐含层)建立的人工神经网络模型结果最佳,模型预测效果最好;其次为wardnets方法3(2个隐含层)建立的人工神经网络模型,最差为应用wardnets方法1(2个隐含层)建立的人工神经网络模型。可见,同样的方法,但内部信息传递方式的不同,会对建立模型的预测结果产生较大的影响,因此,建立模型时,要合理选择信息传递方式。
应用wardnets方法2(3个隐含层)建立的最佳人工神经网络模型对100个验证集鲜叶样品进行预测,预测结果见表15。从表15可以看出,鲜叶样品真值和预测值的差值(偏差)全部在±0.2范围内,表明模型对所有样品预测正确,判别率为100%。可见,应用联合区间偏最小二乘法结合非线性的人工神经网络方法实现了对3个栽培地区中茶108鲜叶样品的快速、准确判别。
表15100个验证集鲜叶样品预测结果
(8)未知茶鲜叶样品栽培地区的判别
同一品种未知茶鲜叶样品栽培地区的判别其步骤同上述的模型稳健性检验,包括如下主要步骤:
a):应用傅里叶变换型近红外光谱仪扫描未知茶鲜叶样品的近红外光谱;
b):将上述(6)中已建好的人工神经网络预测模型调入neuroshell2软件,应用该软件中的模型预测功能,得到输出值,根据输出值数据判定未知茶鲜叶样品的栽培地区。如输出值在1.000附近时判别为咸宁市;输出值在2.000附近时判别其栽培地为利川市;输出值在3.000附近时判别其栽培地为宣恩县。此外,本发明提供的方法还可以应用于其他茶叶栽培地的判别,此时只需增加采集相应栽培地区的茶叶样品进行建模(建模步骤同上,不再赘述),然后再运用建立的模型进行其栽培地区的判别。
本发明提供一种利用近红外光谱技术,将线性的联合区间偏最小二乘法和非线性的人工神经网络方法相结合,用于准确的预测不同栽培地区同一品种的茶鲜叶。先剔除鲜叶样品噪声信息,得到最佳光谱预处理方法为平滑;然后应用线性联合区间偏最小二乘法筛选特征光谱区间,将鲜叶样品光谱区间等划分为22个光谱子区间、应用7个因子数,选择[3111922]4个子区间时,建立的近红外光谱预测模型rmsecv最小,为0.5853,模型的相关系数rc为0.6918。[3111922]4个子区间对应的波数区间分别为:4547.32-4817.31cm-1;6738.06-7008.05cm-1;8924.94-9191.07cm-1;9734.9-10000cm-1,有利于降低模型的运算量,增加模型的稳健性;再对筛选的特征光谱区间进行主成分分析,pc1,pc2和pc3三个主成分的累计贡献率为99.164%,以前3个主成分为输入值建立wardnets方法的三种内部信息传递方式的人工神经网络预测模型,以wardnets方法2(3个隐含层)建立的人工神经网络模型结果最佳(rp=0.993,rmsep=0.148),预测效果最好;其次为wardnets方法3(2个隐含层)建立的人工神经网络模型,最差为应用wardnets方法1(2个隐含层)建立的人工神经网络模型。本发明专利不仅可以达到大大降低模型运算量、简化模型的目的,同时还起到提高模型的预测准确度和增强模型实用性的目的。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,上述结构都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!