一种基于随机森林模型的拉曼光谱物质识别方法与流程
本发明涉及物质识别
技术领域:
,尤其涉及一种基于随机森林模型的拉曼光谱物质识别方法。
背景技术:
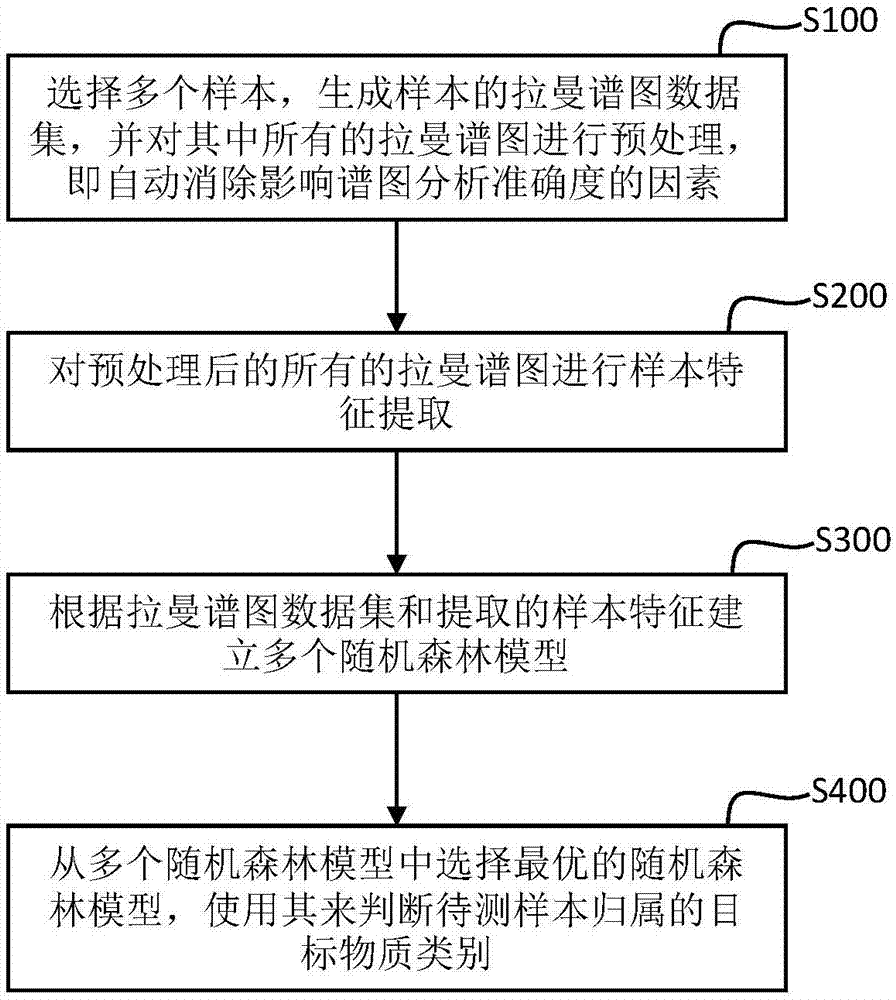
:随着科学、经济和社会发展,复杂体系痕量物质检测已经成为关乎国计民生的重大问题。无论是日常生产生活中的食品安全、环保和医药,还是表面科学、分子电子学和材料科学等基础研究,都对先进快捷的物质检测技术有迫切需求。例如近年曝光的孔雀石绿海鲜、苏丹红鸡蛋、三聚氰胺奶粉、塑化剂保健品、毒生姜、镉大米和霉菌开心果等食品安全事件,凸显了有害物质检测技术的滞后和监管制度的不健全。为了有效监督和保障国家人民安全,研究和开发快速高效的物质检测仪器和分析方法具有重大意义。主流的物质检测方法包括光谱分析法、色谱分析法、质谱分析法和电化学分析法等。特别是拉曼光谱(ramanspectra)技术具有快速、无损和样品无需制备等特点,能获取高灵敏度的分子指纹谱图,实现物质快速检测。由于表面增强拉曼散射(sers)提高了检测灵敏度和普适性,拉曼光谱技术在痕量物质检测应用中进入了实用阶段,不再局限于实验室里费时费力的集中检测。现场采集过程中,拉曼光谱会受到许多因素的影响,例如由激光产生的荧光背景、由射线产生的毛刺峰和仪器的固有噪声等。为了提高后续物质检测的准确性,需要设计谱图预处理算法消除噪音和荧光背景。例如,基于高斯假设的自动自适应算法和基于自适应迭代惩罚最小二乘法(airpls)的算法能较好地消除荧光背景,已集成到商业化仪器中。预处理后,谱图的峰值特征则成为判断目标物质是否存在的关键。常见的拉曼谱图识别技术采用与标准谱图进行模板匹配的方法,通过相似度阈值判定是否含有目标物质。例如,浙江大学的乔西娅在2010年发表的硕士学位论文《拉曼光谱特征提取方法在定性分析中的应用》中针对纺织纤维提出定性分析的方法,建立各种纯组分纤维的拉曼光谱特征峰表,并将未知样品与表进行逐一匹配并计算相似度,进而完成快速识别;zhangzm等人2014年在“chemometricsandintelligentlaboratorysystems”发表的期刊论文《mixtureanalysisusingreversesearchingandnon-negativeleastsquares》中选择光谱特征峰位置上的最大小波系数作为参数,利用简单反向匹配思路计算相似度,实现了简单高效的物质识别算法。这类方法在单个体系的物质检测中有较好表现,但由于相邻拉曼峰相互“淹没”的情形时有发生,对复杂体系的拉曼谱图分析造成了不良影响。随着快检技术的普及和便携拉曼光谱仪器的出现,在现场获取的复杂体系中的拉曼谱图数量迅速增长,传统的光谱分析方法由于过程复杂且需要专业人士进行操作,面临智能化和实时性的双重挑战。随着机器学习的兴起,不断涌现的优秀算法模型为拉曼光谱谱图分析开拓新途径,例如支持向量机(svm)、adaboost、多层神经网络、超图和随机森林等。章颖强等人2012年在“光谱学与光谱分析”发表的期刊论文《基于拉曼光谱和最小二乘支持向量机的橄榄油掺伪检测方法研究》中采用最小二乘svm模型并进行多重迭代优化,可以对分别掺入了葵花籽油、大豆油和玉米油的橄榄油的拉曼光谱检测样本进行快速准确的定性分析识别;公开号为“cn107679569a”的中国发明专利《基于自适应超图算法的拉曼光谱物质自动识别方法》提出了基于自适应超图算法的拉曼光谱物质自动识别方法。基于svm和多层神经网络的拉曼谱图分类算法也被运用于特定物质的检测应用,但在复杂体系下的适用性不强,需要专业人士针对体系或物质对算法参数进行调整。相比之下,基于自适应超图的拉曼光谱分析算法通用性较强,无需对算法参数进行调整;但由于模型训练的样本需求大耗时长,在小规模数据集上准确率不高,实时性偏弱。技术实现要素:针对上述问题,本发明旨在提供一种基于随机森林模型的拉曼光谱物质识别方法,将拉曼谱图的物质识别(定性分析)问题转换为机器学习的分类问题,并实现样本批量实时处理。具体方案如下:一种基于随机森林模型的拉曼光谱物质识别方法,包括以下步骤:s100:选择多个样本,生成样本的拉曼谱图数据集,并对其中所有的拉曼谱图进行预处理,即自动消除影响谱图分析准确度的因素;s200:对预处理后的所有拉曼谱图进行样本特征提取,所述样本特征为适用于随机森林模型的特征向量;s300:根据拉曼谱图数据集所提取的样本特征建立多个随机森林模型,即将拉曼谱图数据集的样本随机均分为k组,每个样本使用其样本特征来表示,依次取第i组数据作为测试集,则余下的k-1组作为训练集,i=1,…,k,由此得到k种训练集和测试集组合,其中每种组合分别训练成一个随机森林模型rfi;s400:从多个随机森林模型中选择最优的随机森林模型,使用其来判断待测样本归属的目标物质类别。进一步的,步骤s100中所述预处理包括以下步骤:s110:搜索原始光谱数据s的局部极大值点;s120:在相邻局部极大值点间使用插值方法,获得荧光背景的估计曲线b;s130:更新光谱数据s=b,对步骤s110和步骤s120进行循环迭代,以获得荧光背景曲线b,将原始光谱数据s减去荧光背景曲线b得到预处理后的拉曼谱图s`。进一步的,步骤s200中所述样本特征的提取包括以下步骤:s210:设定波数区间[l,r];s220:拉曼谱图在波数区间[l,r]采集的光谱信号强度序列,记为向量d={d[k]},其中,k=1,...,n,f为频率;s230:对光谱信号强度序列中的每个光谱信号强度d[k]进行数值归一化处理(k=1,...,n),计算取值范围为(-1,1)的归一化特征向量z;归一化特征向量的元素z[k]的计算方法为:其中,arctan是反正切函数,mean[d]是d向量所有元素的平均值。进一步的,步骤s300中所述随机森林模型rfi的训练方法为:s310:设所述随机森林模型rfi由t棵决策树构成,且树的深度不超过d。从训练集中,有放回地随机选取n个样本,构成样本集dj={z1,z2,...,zn},其中zt为样本的归一化特征向量,t=1,...,n,j=1,...,t;s320:使用dj建立第j棵决策树(j=1,...,t),并针对决策树的根节点,选择最优划分特征及其阈值,具体包括以下步骤:s321:对归一化特征向量随机选择u个划分特征,设第v个划分特征为wv∈[1,n],并对每个划分特征随机地选择一个阈值δv,其中,v=1,...,u;s322:判断zt[wv]是否小于δv,若zt[wv]小于δv,则将zt划分到根节点的左孩子结点子集dlv,j中,否则划分到根节点的右孩子结点子集drv,j中;s323:针对第v种划分方式,计算其基尼指数,计算公式为:其中dlv,j和drv,j的纯度用基尼值来度量,数据集的gini(·)计算公式为:其中,γ为目标物质的类别总数,pμ为第μ类样本所占的比例,μ=1,...,γ;s324:在u种划分方式中,选取基尼指数最小的作为最优划分方式,标记v*是最优划分特征wv*及其相应最佳阈值δv*的序号,dlv*,j和drv*,j分别为该根节点的左右孩子结点的子集,简单记为和s330:当决策树的深度大于等于d,不再对孩子结点进一步划分;当决策树的深度小于d时,如果所包含的样本个数小于阈值ε,或中的样本属于同一类别,则将左孩子结点当做叶子结点,不再进行划分;否则将其视作新的根节点,且令重复步骤s320;同理,针对右孩子结点和重复步骤s330中的操作;s340:将第j棵决策树上的叶子结点记为xj,其分类概率计算公式为:其中,y是xj的样本集所包含的样本个数,yμ是属于第μ类物质的样本个数,μ=1,...,γ,j=1,...,t。进一步的,步骤s400具体包括以下步骤:s410:在第i种组合的测试集中,每个样本采用步骤s300的随机森林模型的训练方法完成样本分类,并通过下面方法判断该样本归属的目标物质类别:s411:若样本被分到叶子结点xj,那么该样本属于第μ类物质的概率hj(μ)的计算公式为:s412:综合t棵决策树的分析结果,样本属于第μ类物质的概率h(μ)的计算公式为:其中μ=1,...,γ;s413:判断测试样本属于第c类物质,其置信概率为h(c),公式为:s420:通过公式计算随机森林模型rfi的分类结果的准确率gi;其中,ei为该组合中测试集的样本总数,ei为测试集中被正确分类的样本数;s430:通过公式找出k种随机森林模型中准确率最高的随机森林模型rfξ,完成最优的随机森林模型的构建;s440:使用最优的随机森林模型rfξ判断待测样本属于的目标物质类别,具体操作流程与步骤s410相同。本发明采用如上技术方案,并具有有益效果:(1)、由于随机森林模型具有稳健性、随机性和高效性的特点,本发明创新性地将随机森林算法应用于拉曼光谱定性分析,解决多目标物质分类的问题。(2)、本发明可以对大量的待测谱图进行特征提取和快速分类,从而准确有效地识别所含的目标物质并提供置信概率。(3)、本发明可根据数据集的大小对随机森林的决策树数目进行调整,满足复杂体系下物质自动识别的实际需求,提高拉曼技术在复杂体系的适用性和易用性,可以视作“拉曼光谱大数据挖掘”的一个重要解决方案。(4)、本发明提出的随机森林算法在保证高准确率的情况下,其建立分类器的速度及对光谱进行分类的速度高于常用的svm分类算法以及自适应超图算法,且只需要调整很少的参数即可控制计算资源规模。附图说明图1所示为本发明实施例的流程示意图。图2所示为该实施例中各目标物质的识别准确率和假阳性率示意图。图3所示为该实施例中识别错误的拉曼谱图与标准谱图的对比图。具体实施方式为进一步说明各实施例,本发明提供有附图。这些附图为本发明揭露内容的一部分,其主要用以说明实施例,并可配合说明书的相关描述来解释实施例的运作原理。配合参考这些内容,本领域普通技术人员应能理解其他可能的实施方式以及本发明的优点。现结合附图和具体实施方式对本发明进一步说明。参考图1所示,本发明提供了一种基于随机森林模型的拉曼光谱物质识别方法,包括以下步骤:s100:选择多个样本,生成样本的拉曼谱图数据集,并对其中所有的拉曼谱图进行预处理,即自动消除影响谱图分析准确度的因素;所述样本为拉曼光谱仪器在现场测试体系(如果汁、甜食和牛奶等)采集到的拉曼光谱样本数据。现场采集的拉曼光谱样本通常是一组二维数据,横坐标是波数,纵坐标是该波数对应的光谱信号强度。假设拉曼光谱仪器采集的光谱数据波数相同,则可使用一维向量s来记录信号强度。该实施例中,采用基于高斯假设的自动自适应算法来对原始光谱样本进行谱图预处理,在无人工干预情况下准确地消除复杂体系中影响拉曼谱图分析准确度的因素。所述影响拉曼谱图分析准确度的因素包括荧光背景、噪声和毛刺峰等。该实施例中所述方法在复杂体系下利用高斯假设和自适应迭代的思想来扣除荧光背景,但不会使拉曼信号受到损失或者产生局部形变。所述预处理包括以下步骤:s110:搜索原始光谱数据s的局部极大值点。s120:在相邻局部极大值点间使用插值方法,获得荧光背景的估计曲线b。s130:更新光谱数据s=b,对步骤s110和步骤s120进行循环迭代。迭代终止条件满足,即可获得荧光背景曲线b,然后用原始光谱数据s减去b得到预处理后的拉曼谱图s`。在无人工干预的情况下,谱图自动预处理方法可以准确可靠地消除复杂体系下的拉曼光谱荧光背景,处理异常数据。s200:提取预处理后的每个拉曼谱图的样本特征,所述样本特征为适用于随机森林模型的特征向量,该实施例中为归一化特征向量z。为了使随机森林模型可以用于拉曼谱图的分类和物质识别,需要对预处理后的拉曼谱图s`进行特征提取,即将每个拉曼谱图的信号特征表示成一个取值范围相同的等长特征向量。所述样本特征的提取包括以下步骤:s210:设定波数区间[l,r];s220:拉曼谱图在波数区间[l,r]采集的光谱信号强度序列,记为向量d={d[k]},其中,k=1,...,n,f为频率;s230:对光谱信号强度序列中的每个光谱信号强度d[k]进行数值归一化处理(k=1,...,n),计算取值范围为(-1,1)的归一化特征向量z;归一化特征向量的元素z[k]的计算方法为:其中,arctan是反正切函数,mean[d]是d向量所有元素的平均值,即n个光谱信号强度的平均值。s300:根据样本的拉曼谱图数据集和其样本特征建立随机森林模型,即将拉曼谱图数据集的样本随机均分为k组,每个样本使用其样本特征来表示,依次取第i组数据作为测试集,则余下的k-1组作为训练集,i=1,…,k,由此可得到k种训练集和测试集组合,每种组合分别训练一个随机森林模型rfi,便于下一步选出最优的随机森林模型并完成待测拉曼谱图的识别。所述随机森林模型rfi的训练方法如下,可参见算法1。算法1:随机森林模型算法针对第i种训练集和测试集组合,训练随机森林模型rfi。s310:设定所述随机森林模型rfi由t棵决策树构成,且树的深度不超过d,在建立第j棵决策树时,其中,j=1,...,t,从训练集中有放回地随机选取n个样本,构成样本集dj={z1,z2,...,zn},其中zt为样本的归一化特征向量,t=1,...,n,j=1,...,t;s320:使用dj建立第j棵决策树(j=1,...,t),可参见算法2。首先对决策树的根节点,选择最优划分特征及其阈值。算法2:决策树学习算法步骤s320包括以下步骤:s321:对归一化特征向量随机选择u个划分特征,设第v个划分特征为wv∈[1,n],并对每个划分特征随机地选择一个阈值δv,其中,v=1,...,u;s322:判断zt[wv]是否小于δv,若zt[wv]小于δv,则将zt划分到根节点的左孩子结点子集dlv,j中,否则划分到根节点的右孩子结点子集drv,j中;s323:针对第v种划分方式,计算其基尼指数,计算公式为:其中dlv,j和drv,j的纯度用基尼值来度量,数据集的gini(·)计算公式为:其中,γ为目标物质的类别总数,pμ为第μ类样本所占比例,μ=1,...,γ;所述目标物质为样本中待检测的物质,如样本采集于果汁测试体系,目标物质为柠檬黄和日落黄等若干色素。本发明的目的即为检测待测样本中所包含的是哪种目标物质。所述目标物质的类别总数由物质检测应用针对的目标物质数量决定。s324:在u种划分方式中,选取基尼指数最小的作为最优划分方式,标记v*是最优划分特征wv*及其相应最佳阈值δv*的序号,dlv*,j和drv*,j分别为该根节点的左右孩子结点的子集,简单记为和s330:采用迭代思路考虑根节点的左右孩子结点的划分。当决策树的深度大于等于d,不再对孩子结点进一步划分。当决策树的深度小于d时,如果所包含的样本个数小于阈值ε,或中的样本属于同一类别,则将左孩子结点当做叶子结点,不再进行划分;否则将其视作新的根节点,且令重复步骤s320;同理,针对右孩子结点和重复步骤s330中的操作。s340:将第j棵决策树上的叶子结点记为xj,其分类概率计算方法公式为:其中,y是xj的样本集所包含的样本个数,yμ是属于第μ类物质的样本个数,μ=1,...,γ,j=1,...,t。s400:从多个随机森林模型中选择最优的随机森林模型,使用其来判断待测样本属于的目标物质类别,从而实现物质检测的定性分析。s410:在第i种组合的测试集中,每个样本的归一化特征向量zt通过随机森林模型rfi的t棵决策树,完成样本分类。具体做法与决策树的生成过程类似:对第j棵决策树,首先将zt置于根节点上。如果zt[wv*]小于δv*,则将它分到根节点的左孩子结点中;否则分到右孩子结点中。将zt被分到的孩子结点作为根节点,重复以上操作,直至到达叶子结点。若zt被分到叶子结点xj,那么该样本属于第μ类物质的概率hj(μ)的计算公式为:综合t棵决策树的分析结果,zt属于第μ类物质的概率h(μ)的计算公式为:其中μ=1,...,γ。最后通过公式判定zt属于第c类物质,置信概率为h(c)。s420:通过公式计算随机森林模型rfi的分类结果的准确率gi;其中,ei为该组合中测试集的样本总数,ei为测试集中被正确分类的样本数。s430:通过公式找出k种随机森林模型中准确率最高的随机森林模型rfξ,完成最优的随机森林模型的构建;该步骤需要为构建的k种随机森林模型依次计算其准确率。s440:使用最优的随机森林模型rfξ判断待测样本属于的目标物质类别,具体操作流程与步骤s410相同。于是,每个待测光谱样本最终被归于第c类物质,其置信概率为h(c)。表1所示为算法和实施例中的主要参数和变量的列表。表1实验验证:该实施例中进行的实验采用的光谱数据均来自于真实环境下的拉曼谱图样本,由高意pt2000仪器(光谱范围200~2500cm-1,光谱分辨率8~10cm-1)采集所得。所有谱图采用该实施例中所述的预处理算法和特征提取方法进行自动处理后,采用随机森林方法进行物质分类识别。假设实验数据集针对γ个目标物质,含有m个拉曼谱图,其中含有mt个待测谱图,m-mt个物质已知谱图。可使用如下指标来衡量该实施例方法的物质识别性能。(1)、混淆矩阵r,在机器学习领域也被称为可能性表格或是错误矩阵,用一种特定的矩阵来呈现多分类算法性能的可视化效果。每一个元素r(σ,λ)统计含有第σ种物质的待测谱图被分类到第λ种物质的个数,σ=1,...,γ,λ=1,...,γ。显然σ=λ时,即对角线上的元素r(σ,σ)是物质识别正确的拉曼谱图数目。r的所有元素之和为mt,即(2)、第σ种物质的识别准确率和假阳性率显然,越高,φσ越低,则对该物质的识别性能越好。(3)、总体识别准确率显然是越高越好。如表2中所列出的pt2000酸性色素数据集包括6种目标物质(亮蓝、柠檬黄、日落黄、苋菜红、胭脂红和诱惑红)和不含任何目标物质的空白类别,即γ=7,m=1064。甜食体系中采集的389个拉曼谱图作为已知样本(标记目标物质),其余的mt=675个待测拉曼谱图来自其他体系,作为未知样本进行物质分类识别。图2和表3详细记录了各目标物质识别的准确率/假阳性率和混淆矩阵。单个物质的辨识准确率98.20%~100%,总体识别准确率为99.7%。本发明方法整体的辨识准确率优于传统方法。特别是,被误判的2个谱图皆是bb低浓度样品,见图3,由于信噪比差而淹没了特征峰,故而被误判为空白样本。表2表3样本数目bbtafy3a27a18arblbb109000002ta08100000fy300780000a2700081000a18000016200ar00000810bl00000081上述的实验验证表明,该实施例可以识别未知体系下的拉曼谱图,而无须为每种物质每个体系准备大量标准谱,特别适用于现场快检实际应用中的复杂环境体系。本发明实施例采用基于随机森林模型的自动算法快速准确地实现大量拉曼谱图的物质分类。随机森林由若干决策树(decisiontree)集合而成,可以处理多分类问题,具有速度快、对噪声鲁棒性强以及泛化(generalization)能力强等特点。由于在训练样本的选择和树的生长过程中引入随机性,降低了树结构分类器的方差,因此非常适合对拉曼光谱谱图进行分类识别,适用于不同规模的数据集。在执行谱图预处理过程后,以目标物质的拉曼标准谱图和已知谱图作为训练样本,设计特征提取算法进行特征学习,从而获得随机森林模型。待测样本输入随机森林模型后,判断其是否属于含有目标物质的谱图类别,实现定性分析。由于决策树具有相互独立性,容易做成并行化方法,以此在保证高准确率的基础上,大大提高了运行速度。尽管结合优选实施方案具体展示和介绍了本发明,但所属领域的技术人员应该明白,在不脱离所附权利要求书所限定的本发明的精神和范围内,在形式上和细节上可以对本发明做出各种变化,均为本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1