一种拉曼光谱数据的处理方法及系统与流程
本发明涉及光谱数据处理领域,尤其是一种拉曼光谱数据处理方法及系统。
背景技术:
拉曼光谱分析技术是利用激光刺激被测样品,被测样品受激辐射拉曼信号,由于不同物质的内部分子结构不同,使得样品受激能够产生特定的拉曼散射光谱,从而可以通过分析拉曼信号研究分子结构和成分构成。随着激光技术和光电探测技术的进步,拉曼技术在成分检测领域的应用越来越广泛。近年来,国内对食品药品安全监督的力度越来越大,相比较传统气相液相分析设备,采用拉曼光谱检测设备进行成分检测具有检测周期短、成本低和携带方便的优势。但是,由于拉曼信号非常弱,尤其是小型轻量化设备的激光能量弱,其对散射光的收集能力也有限,导致探测器件得到的拉曼信号容易受到本底光谱、噪声和杂散光的干扰,如果直接对探测器采集的数据进行处理和分析,则会影响对测试样品进行成分判断的准确性。
技术实现要素:
为解决上述技术问题,本发明的目的在于:提供一种能有效地检测出测试样品中是否含有标准样品成分的拉曼光谱数据的处理方法及系统。
本发明采用的第一种技术方案是:一种拉曼光谱数据的处理方法,包括以下步骤:
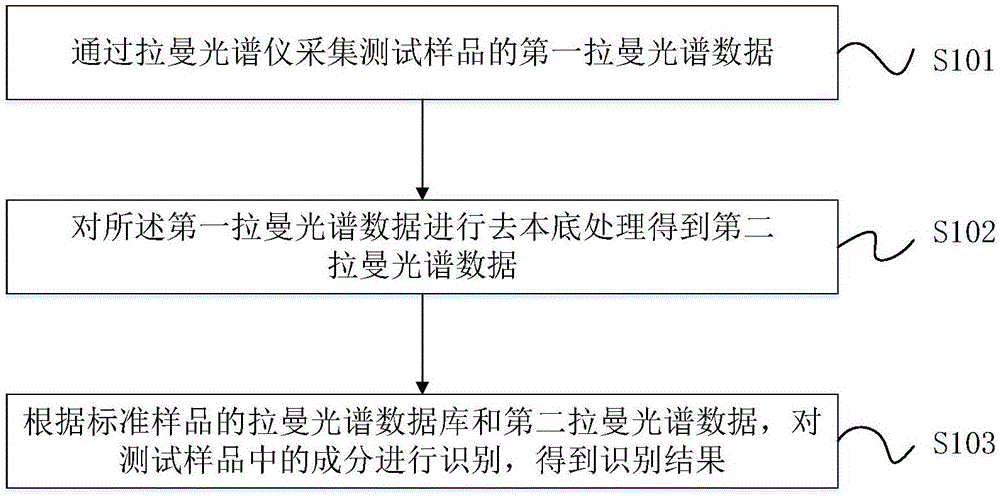
通过拉曼光谱仪采集测试样品的第一拉曼光谱数据;
对所述第一拉曼光谱数据进行去本底处理得到第二拉曼光谱数据;
根据标准样品的拉曼光谱数据库和第二拉曼光谱数据,对测试样品中的成分进行识别,得到识别结果。
进一步地,所述对所述第一拉曼光谱数据进行去本底处理得到第二拉曼光谱数据,具体为:
通过高通滤波器矩阵和惩罚函数对第一拉曼光谱数据进行去本底处理,得到第二拉曼光谱数据,所述第二拉曼光谱数据的计算公式为:
其中,
进一步地,所述有限域高通滤波器矩阵,通过以下步骤获取:
获取第一微分算子和截断算子;
根据第一微分算子和截断算子,得到第一增广矩阵和第二增广矩阵;
获取延展模式变换矩阵;
根据第一增广矩阵和延展模式变换矩阵,得到截断矩阵;
根据第二增广矩阵和延展模式变换矩阵,得到微分矩阵;
根据截断矩阵和微分矩阵得到有限域高通滤波器矩阵。
进一步地,在对所述第一拉曼光谱数据进行去本底处理之前,还包括以下步骤:
根据拉曼光谱仪的波长分辨率计算波数最小分辨率,得到波数分度值,所述波数分度值的计算公式为:
其中,kδ为波数分度值,λmax为第一拉曼光谱数据中可测波长的最大值,λδ为拉曼光谱仪的波长分辨率。
进一步地,所述标准样品的拉曼光谱数据库,通过以下方式获取:
获取标准样品的第三拉曼光谱数据;
对第三拉曼光谱数据进行去本底处理,得到第四拉曼光谱数据;
根据波数分度值对第四拉曼光谱数据进行插值处理,得到第一拉曼位移谱数据;
将第一拉曼位移谱数据中的最大值作为归一化参数,对第一拉曼位移谱数据进行归一化处理,得到第二拉曼位移谱数据;
根据第一拉曼位移谱数据和第一阈值的大小关系,得到掩模数组;
根据掩模数组对第二拉曼位移谱数据进行去除背景干扰处理,得到第三拉曼位移谱数据,所述第三拉曼位移谱数据的计算公式为:
yk=yk0οαk
其中,yk为第三拉曼位移谱数据,αk为掩模数组,yk0为使用波数分度值对拉曼光谱数据库中序号为k的拉曼光谱数据进行插值处理后,得到维度为n的第一拉曼位移谱数据;
对第三拉曼位移谱数据进行标记并存储,得到标准样品的拉曼光谱数据库。
进一步地,所述对测试样品中的成分进行识别,具体包括:
根据波数分度值对第二拉曼光谱数据进行插值处理,得到第四拉曼位移谱数据;
根据标准样品的拉曼光谱数据库和第四拉曼位移谱数据对测试样品中的成分进行识别。
进一步地,所述根据标准样品的拉曼光谱数据库和第四拉曼位移谱数据对测试样品中的成分进行识别,具体包括:
根据掩模数组对第四拉曼位移谱数据进行去除背景干扰处理,得到第五拉曼位移谱数据;
计算测试样品中的第五拉曼位移谱数据的能量占比,所述能量占比的计算公式为:
其中,ηk为能量占比,n为第四拉曼位移谱数据的数据维度,zk为第四拉曼位移谱数据在标准样品k掩模张成的向量子空间上的投影,z为第四拉曼位移谱数据;
判断能量占比和第二阈值的大小关系,得到第一判断结果。
进一步地,所述根据标准样品的拉曼光谱数据库和第四拉曼位移谱数据对测试样品中的成分进行识别,还包括以下步骤:
计算第三拉曼位移谱数据和第五拉曼位移谱数据的相关系数,所述相关系数的计算公式为:
其中,ρk为相关系数,yk为第三拉曼位移谱数据,zk为第五拉曼位移谱数据;
判断相关系数和第三阈值的大小关系,得到第二判断结果。
进一步地,所述根据标准样品的拉曼光谱数据库和第四拉曼位移谱数据对测试样品中的成分进行识别,还包括以下步骤:
若第一判断结果为能量占比大于第二阈值且第二判断结果为相关系数大于第三阈值,则判定测试样品中含有标准样品的成分;反之,则判定测试样品中不含有标准样品的成分。
本发明采用的第二种技术方案是:
一种拉曼光谱数据的处理系统,包括:
至少一个存储器,用于存储程序;
至少一个处理器,用于加载所述程序以实现所述的一种拉曼光谱数据的处理方法。
本发明的有益效果是:通过对测试样品的第一拉曼光谱数据进行去本底处理,去除第一拉曼光谱数据中的本底光谱,得到第二拉曼光谱数据,再根据标准样品的拉曼光谱数据库和第二拉曼光谱数据,对测试样品中的成分进行识别,得到识别结果,本发明通过去本底处理,避免识别过程中本底光谱对测试结果的影响,保证识别结果的准确性。
附图说明
图1为本发明的一种拉曼光谱数据的处理方法的流程图;
图2为本发明的一种拉曼光谱数据的处理系统的系统框图。
具体实施方式
下面结合附图和具体实施例对本发明做进一步的详细说明。对于以下实施例中的步骤编号,其仅为了便于阐述说明而设置,对步骤之间的顺序不做任何限定,实施例中的各步骤的执行顺序均可根据本领域技术人员的理解来进行适应性调整。
参照图1,一种拉曼光谱数据的处理方法,包括以下步骤:
s101、通过拉曼光谱仪采集测试样品的第一拉曼光谱数据;
具体地,第一拉曼光谱数据是通过拉曼光谱仪采集测试样品的初始光谱数据,其数据维度为n,单位为波长。
s102、对所述第一拉曼光谱数据进行去本底处理得到第二拉曼光谱数据;
具体地,第二拉曼光谱数据是对测试样品的初始光谱数据进行去本底处理后,得到的测试样品的目标光谱数据。
s103、根据标准样品的拉曼光谱数据库和第二拉曼光谱数据,对测试样品中的成分进行识别,得到识别结果。
具体地,对测试样品的成分进行识别是指识别出测试样品中与标准样品相同的成分。将第二拉曼光谱数据进行插值、掩模处理后得到测试样品的拉曼位移谱数据,将测试样品的拉曼位移谱数据分别与标准样品的拉曼光谱数据库中的拉曼位移谱数据进行比对识别,根据识别结果判定测试样品中是否含有标准样品的成分。
具体地,通过对测试样品的第一拉曼光谱数据进行去本底处理,去除第一拉曼光谱数据中的本底光谱,得到第二拉曼光谱数据,再根据标准样品的拉曼光谱数据库和第二拉曼光谱数据,对测试样品中的成分进行识别,得到识别结果,本发明通过去本底处理,避免识别过程中本底光谱对测试结果的影响,保证识别结果的准确性。
进一步作为优选的实施方式,所述对所述第一拉曼光谱数据进行去本底处理得到第二拉曼光谱数据,具体为:
通过高通滤波器矩阵和惩罚函数对第一拉曼光谱数据进行去本底处理,得到第二拉曼光谱数据,所述第二拉曼光谱数据的计算公式为:
其中,
具体地,所述有限域高通滤波器矩阵的表达式为:
h=ba-1
其中,h为高通滤波器矩阵,b为微分矩阵;a为截断矩阵,h、b和a均为n×n维矩阵。
所述惩罚函数的表达式为:
φ=cx2
其中,φ为惩罚函数,c为系数,x为迭代光谱数据。
所述迭代光谱数据是通过采用beads算法对第一拉曼光谱数据进行处理得到的,处理步骤如下:
步骤一、获取第一拉曼光谱数据y,截断矩阵a,微分矩阵b,第i阶微分di,惩罚函数的一阶导数φ’(x),以及权重系数λi,其中,i=0,1,…m,m为微分总阶数;
步骤二、根据截断矩阵a和微分矩阵b得第一中间数据,所述第一中间数据的计算公式为:
b=btba-1x;
步骤三、设置迭代光谱数据x=y;
步骤四、根据第i阶微分di和惩罚函数的一阶导数φ’(x)得第二中间数据,所述第二中间数据的计算公式为:
步骤五、根据权重系数λi、第i阶微分di和第二中间数据得第三中间数据,所述第三中间数据的计算公式为:
步骤六、根据截断矩阵a、微分矩阵b和第三中间数据d得第四中间数据,所述第四中间数据的计算公式为:
q=btb+atda;
步骤七、根据截断矩阵a、第一中间数据b和第四中间数据q得第一迭代光谱数据g,所述第一迭代光谱数据g的计算公式为:
g=aq-1b;
步骤八、判断第一迭代光谱数据g是否达到预设迭代次数,若未达到预设迭代次数,则令x=g,并返回到步骤四;反之,则令x=g,迭代结束,并输出x。
具体地,通过采用beads算法处理第一拉曼光谱数据,分离第一拉曼光谱数据中的本底光谱和干扰噪声。所述惩罚函数是用于稀疏化初始光谱数据。通过高通滤波器和惩罚函数对第一拉曼光谱数据进行去本底处理后,得到去除本底光谱的第二拉曼光谱数据。
进一步作为优选的实施方式,所述有限域高通滤波器矩阵,通过以下步骤获取:
获取第一微分算子和截断算子;
具体地,所述第一微分算子是2d阶微分算子,可通过以下方式得到:
以p=[-1,2,-1]为二阶微分算子,则2d阶微分算子可由p的d次卷积求得,所以p的d次卷积的计算公式为:
pd=[ad......a0......ad]
其中,a0、ad和d都是常数。
具体地,所述截断算子是通过以下方式得到的:
设置截断频率为fc,则截断算子为qd,所以截断算子qd的计算公式为:
qd=convd([-12-1])+αconvd([121])
其中,d为常数,
根据第一微分算子和截断算子,得到第一增广矩阵和第二增广矩阵;
具体地,所述第一增广矩阵为ae和第二增广矩阵be,增广矩阵ae和be是通过以下方式得到:
根据p的d次卷积pd和截断算子qd构建截断矩阵a和微分矩阵b的n×(n+d)维增广矩阵ae和be,第一增广矩阵ae的表达式为:
第二增广矩阵be的表达式为:
其中,a0、ad、b0、bd和d均为常数,ae为第一增广矩阵,be为第二增广矩阵。
获取延展模式变换矩阵;
具体地,边界延展矩阵的表达式为:
其中,g为边界延展矩阵,e为n×n维单位矩阵,l和r分别为d×n维左边界和右边界。
根据第一增广矩阵和延展模式变换矩阵,得到截断矩阵;
具体地,所述截断矩阵的表达式为:
a=aeg
其中,a为截断矩阵,ae为第一增广矩阵,g为边界延展矩阵。
根据第二增广矩阵和延展模式变换矩阵,得到微分矩阵;
具体地,所述微分矩阵的表达式为:
b=beg
其中,b为微分矩阵,be为第二增广矩阵,g为边界延展矩阵。
根据截断矩阵和微分矩阵得到有限域高通滤波器矩阵。
具体地,所述有限域高通滤波器矩阵的计算公式为:
h=ba-1
其中,h为高通滤波器矩阵,b为微分矩阵,a为截断矩阵,h、b和a均为n×n维矩阵。
具体地,通过在有限域高通滤波器矩阵中引入边界延展矩阵,消除现有技术中由于边界位置的微分值为非零数值导致的基线偏移现象。
进一步作为优选的实施方式,在对所述第一拉曼光谱数据进行去本底处理之前,还包括以下步骤:
根据拉曼光谱仪的波长分辨率计算波数最小分辨率,得到波数分度值,所述波数分度值的计算公式为:
其中,kδ为波数分度值,λmax为第一拉曼光谱数据中可测波长的最大值,λδ为拉曼光谱仪的波长分辨率。
具体地,波数分度值是精确到有限小数位的波数分辨率,该波数分辨率是通过拉曼光谱仪的参数计算得到的。为后续步骤中对拉曼光谱数据进行插值处理提供统一的波数分度值,保证变量的单一性。
进一步作为优选的实施方式,所述标准样品的拉曼光谱数据库,通过以下方式获取:
获取标准样品的第三拉曼光谱数据;
具体地,第三拉曼光谱数据是通过拉曼光谱仪采集标准样品的拉曼光谱数据后,得到标准样品的初始光谱数据。
对第三拉曼光谱数据进行去本底处理,得到第四拉曼光谱数据;
具体地,第四拉曼光谱数据是对标准样品进行去本底处理后得到的标准样品的标准光谱数据,对标准样品的每个标准光谱数据都设置一个序号,方便后续步骤的处理。对标准样品进行去本底处理的步骤和对测试样品进行去本底处理的步骤是相同的,即对第三拉曼光谱数据进行去本底处理的步骤和对第一拉曼光谱数据进行去本底处理的步骤是相同的。
根据波数分度值对第四拉曼光谱数据进行插值处理,得到第一拉曼位移谱数据;
具体地,使用波数分度值对第四拉曼光谱数据中的每个拉曼光谱数据分别进行插值处理后得到全局拉曼位移谱数据,即第一拉曼位移谱数据。例如,选取第四拉曼光谱数据中序号为k的标准样品的拉曼光谱数据,使用波数分度值进行插值处理,得到维度为n、单位为波数的拉曼位移谱数据。
将第一拉曼位移谱数据中的最大值作为归一化参数,对第一拉曼位移谱数据进行归一化处理,得到第二拉曼位移谱数据;
根据第一拉曼位移谱数据和第一阈值的大小关系,得到掩模数组;
具体地,第一阈值是拉曼位移谱数据阈值,其根据实际需要设置。掩模数组的维度和第一拉曼位移谱数据的维度是相同的。所述掩模数组的计算公式为:
其中,αk为掩模数组,ε为第一阈值,yk0为使用波数分度值对拉曼光谱数据库中序号为k的拉曼光谱数据进行插值处理后,得到维度为n的第一拉曼位移谱数据。
根据掩模数组对第二拉曼位移谱数据进行去除背景干扰处理,得到第三拉曼位移谱数据,所述第三拉曼位移谱数据的计算公式为:
yk=yk0οαk,“ο”为hadamard积;
其中,yk为第三拉曼位移谱数据,αk为掩模数组,yk0为使用波数分度值对拉曼光谱数据库中序号为k的拉曼光谱数据进行插值处理后,得到维度为n的第一拉曼位移谱数据;
具体地,所述第三拉曼位移谱数据的计算公式表示第三拉曼位移谱数据yk等于第一拉曼位移谱数据yk0和掩模数组αk进行复合运算得到的运算结果。所述去除背景干扰处理是第二拉曼位移谱数据中的微小值进行置零处理,微小值的范围是根据实际需要设置。
对第三拉曼位移谱数据进行标记并存储,得到标准样品的拉曼光谱数据库。
具体地,通过构建标准样品的拉曼光谱数据库,为测试样品进行成分检测时提供标准的参考数据,保证测试结果的准确性。
进一步作为优选的实施方式,所述对测试样品中的成分进行识别,具体包括:
根据波数分度值对第二拉曼光谱数据进行插值处理,得到第四拉曼位移谱数据;
根据标准样品的拉曼光谱数据库和第四拉曼位移谱数据对测试样品中的成分进行识别。
具体地,第四拉曼位移谱数据是维度为n,单位为波数的测试样品的拉曼位移谱数据,其是使用波数分度值对第二拉曼光谱数据进行插值处理后得到的。使用波数分度值对第二拉曼光谱数据进行插值处理,能够保证检测过程中变量的单一性,免除其他因素对检测结果的影响。
进一步作为优选的实施方式,所述根据标准样品的拉曼光谱数据库和第四拉曼位移谱数据对测试样品中的成分进行识别,具体包括:
根据掩模数组对第四拉曼位移谱数据进行去除背景干扰处理,得到第五拉曼位移谱数据;
具体地,对第四拉曼位移谱数据进行去除背景干扰处理具体是对第四拉曼位移谱数据中的微小值进行置零处理,微小值是根据实际需要设置。所述第五拉曼位移谱数据的计算公式为:
zk=zοαk,“ο”为hadamard积;
其中,zk为第四拉曼位移谱数据z在标准样品k掩模张成的向量子空间上的投影,αk为掩模数组,z为第四拉曼位移谱数据。
第五拉曼位移谱数据的计算公式表示第五拉曼位移谱数据zk等于第四拉曼位移谱数据z和掩模数组αk进行复合运算得到的运算结果。
计算测试样品中的第五拉曼位移谱数据的能量占比,所述能量占比的计算公式为:
其中,ηk为能量占比,n为第四拉曼位移谱数据的数据维度,zk为第四拉曼位移谱数据在标准样品k掩模张成的向量子空间上的投影,z为第四拉曼位移谱数据;
判断能量占比和第二阈值的大小关系,得到第一判断结果。
具体地,第二阈值是能量占比阈值,其根据标准样品进行测试得到的。使用掩模数列,是为了避免寻峰运算的同时,消除相关系数计算过程中非相关峰值对计算结果的影响,降低计算的复杂度。
进一步作为优选的实施方式,所述根据标准样品的拉曼光谱数据库和第四拉曼位移谱数据对测试样品中的成分进行识别,还包括以下步骤:
计算第三拉曼位移谱数据和第五拉曼位移谱数据的相关系数,所述相关系数的计算公式为:
其中,ρk为相关系数,yk为第三拉曼位移谱数据,zk为第五拉曼位移谱数据;
判断相关系数和第三阈值的大小关系,得到第二判断结果。
具体地,第三阈值是相关系数阈值,其根据大量实验数据得到的。通过计算测试样品的位移谱数据和标准样品的位移谱的相关系数,可以进一步判断测试样品中是否含有标准样品,提高判断结果的准确性。
进一步作为优选的实施方式,所述根据标准样品的拉曼光谱数据库和第四拉曼位移谱数据对测试样品中的成分进行识别,还包括以下步骤:
若第一判断结果为能量占比大于第二阈值且第二判断结果为相关系数大于第三阈值,则判定测试样品中含有标准样品的成分;反之,则判定测试样品中不含有标准样品的成分。
具体地,通过第一判断结果和第二判断结果共同判断测试样品中是否含有标准样品的成分,保证判断结果的准确性。
参照图2,本发明实施例还提供了一种与图1方法相对应的拉曼光谱数据的处理系统,包括:
至少一个存储器,用于存储程序;
至少一个处理器,用于加载所述程序以实现所述的一种拉曼光谱数据的处理方法。
上述方法实施例中的内容均适用于本系统实施例中,本系统实施例所具体实现的功能与上述方法实施例相同,并且达到的有益效果与上述方法所达到的有益效果也相同。
综上所述,本发明的一种拉曼光谱数据的处理方法及系统,通过对测试样品的第一拉曼光谱数据进行去本底处理,去除第一拉曼光谱数据中的本底光谱,得到第二拉曼光谱数据,再根据标准样品的拉曼光谱数据库和第二拉曼光谱数据,对测试样品中的成分进行识别,得到识别结果,本发明通过去本底处理,避免识别过程中本底光谱对测试结果的影响,保证识别结果的准确性;进一步地,通过高通滤波器边界延展矩阵,消除现有技术中由于边界位置微分值为非零数值导致的基线偏移现象;进一步地,通过对初始光谱数据进行去本底处理,去除基线本底光谱和干扰噪声的影响;进一步地,通过引入掩模数列,避免寻峰运算时,非相关峰值数值对计算结果的影响,降低计算的复杂度。
以上是对本发明的较佳实施进行了具体说明,但本发明并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可做作出种种的等同变形或替换,这些等同的变形或替换均包含在本申请权利要求所限定的范围内。
- 还没有人留言评论。精彩留言会获得点赞!