一种城市地上生物量光学微波协同反演方法及系统与流程
本发明涉及一种反演方法,具体来说,涉及一种城市地上生物量光学微波协同反演方法及系统。
背景技术:
植被地上生物量对于生态系统固碳能力和碳储量有重要的指示作用,在国际地圈-生物圈研究计划(igbp)中,碳循环被确定为全球变化和陆地生态系统(gcte)等计划的重要研究内容。因此,植被地上生物量的准确提取对于全球变化及陆地生态系统监测具有重要意义。
遥感技术由于其宏观动态实时多源的特点,已在植被地上生物量以及其他植被参数研究中蓬勃开展。常见的方法是通过建立样地实测数据与遥感特征变量之间的关系模型来估测植被参数。但是,样地实测数据的获取面临众多挑战,一方面,用于建模及验证的样地数据的获取精度难以得到评估;另一方面,收集的样地数据难以覆盖整个研究区,无法充分反映研究区内植被结构及生长状态的变化;并且,由于时间、人力成本以及无法到达的区域等的限制,获取足够数量的样本来进行模型构建几乎是不可能的。近几年,越来越多的国内外研究表明,基于机载激光雷达(lidar)数据获取的植被参数,如冠层高度、冠层覆盖度以及地上生物量具有可与样地实测数据相媲美的精度。然而,相比卫星遥感数据,机载lidar数据在多时相应用以及大区域制图方面具有较大局限性。因此,结合机载lidar数据与卫星遥感数据进行区域尺度的植被参数估测具有高度的应用潜力,将机载lidar数据提取的植被参数作为训练和验证样本集,卫星遥感数据提供预测变量,是大区域植被参数反演的一个重要发展趋势。
在众多卫星遥感数据源中,多光谱卫星遥感数据,尤其是多光谱植被指数,仍然是植被地上生物量估测使用最为广泛的数据源之一。然而,被动光学遥感在获取生物量参数信息时,不但要受到云、雨、雪等天气现象的影响,而且当植被比较茂密时,光学遥感获得的植被反射波谱信息出现饱和。合成孔径雷达(sar)卫星遥感数据具有无昼夜性、受天气影响小等优势,并且具有一定的穿透性,对植被结构信息较为敏感。许多研究表明,sar后向散射系数与植被结构参数(如胸径、体积、树高、生物量等)存在显著的相关性。但是,利用sar后向散射系数进行生物量估测仍然面临严峻的挑战,一方面,当植被覆盖度比较低时,微波遥感受地表土壤含水量、粗糙度等影响显著;另一方面,在浓密植被区域,sar后向散射对植被信息的响应也会出现饱和。因此,针对目前生物量精准定量反演的迫切需求以及当前单源遥感数据存在的局限性,本领域亟待提供更有效的技术方案。
技术实现要素:
对此,本发明提出了一种城市地上生物量光学微波协同反演方法及系统,有效结合光学与微波遥感提取生物量。。
本发明的技术方案提供一种城市地上生物量光学微波协同反演方法,包括以下步骤:
步骤a,利用地面观测试验获取的样地单株参数数据集,获得样地生物量agb观测值;
步骤b,分别对覆盖研究区的lidar数据、光学遥感数据和微波遥感数据进行预处理,相应得到冠层高度值chm、地表反射率数据与后向散射系数;
步骤c,基于chm数据,提取各种lidar变量,并基于光学地表反射率数据,提取多种光学特征植被指数,同时基于微波后向散射系数数据,提取多种微波特征变量;
步骤d,以样地实测agb为因变量,提取的lidar变量为自变量,建立生物量的多元逐步线性回归模型,得到lidar数据覆盖区域的生物量估测值;
步骤e,将lidar数据覆盖区域的生物量值作为训练及验证样本集,利用分层随机采样的方法,选取样本用于后续的建模及验证;
步骤f,采用变量筛选方法筛选出最佳光学与微波特征变量;
步骤g,将最佳光学变量、最佳微波变量及二者的结合分别应用于多种预测模型中,分别构建agb反演的光学模型、微波模型及光学微波协同的模型,根据步骤e选取的样本实现建模及验证后,选择最优的模型实现生物量反演。
而且,所述步骤c中,选取的lidar变量包括最小值、最大值、平均值、高度分位数、标准差、变异系数、倾斜度、峰值以及冠层覆盖度。
而且,所述步骤c中,选取的光学特征植被指数包括归一化植被指数ndvi、比值植被指数sr、增强型植被指数evi、土壤调节植被指数savi、修正土壤调节植被指数msavi,优化型土壤调节植被指数osavi、水分胁迫指数msi、归一化水指数ndwi和叶绿素指数clgreen,其计算公式如下:
式中,r、g、b、nir和swir1分别为红光、绿光、蓝光、近红外及短波红外波段的反射率。
而且,所述步骤c中,选取的微波特征变量包括vv,hh,vh,hv,vv/hh,hh/hv,vv/hv以及rvi,其中rvi的计算公式如下:
其中,vv、hh、vh是极化方式,vv/hh、hh/hv、vv/hv是相应的比值。
而且,所述步骤f中,采用的变量选择方法为逐步筛选法。
而且,所述步骤f中,筛选出的最佳光学特征变量为sr,ndvi,osavi,msi和ndwi,最佳微波特征变量为vv,hv,hh/hv和rvi。
而且,所述步骤g中,选用的预测模型包括多元逐步线性回归slr、k最近邻knn,支持向量机svm,bp神经网络bpnn,随机森林rf以及深度学习dl,其中深度学习模型选用的是栈式稀疏自编码网络模型ssae。
本发明提供一种城市地上生物量光学微波协同反演系统,包括以下模块:
第一模块,用于利用地面观测试验获取的样地单株参数数据集,获得样地生物量agb观测值;
第二模块,用于分别对覆盖研究区的lidar数据、光学遥感数据和微波遥感数据进行预处理,分别得到冠层高度值chm、地表反射率数据与后向散射系数;
第三模块,用于基于chm数据,提取各种lidar变量,并基于光学地表反射率数据,提取多种光学特征植被指数,同时基于微波后向散射系数数据,提取多种微波特征变量;
第四模块,用于以样地实测agb为因变量,提取的lidar变量为自变量,建立生物量的多元逐步线性回归模型,得到lidar数据覆盖区域的生物量估测值;
第五模块,用于将lidar数据覆盖区域的生物量值作为训练及验证样本集,利用分层随机采样的方法,选取样本用于后续的建模及验证;
第六模块,用于采用变量筛选方法筛选出最佳光学与微波特征变量;
第七模块,用于将最佳光学变量、最佳微波变量及二者的结合分别应用于多种预测模型中,分别构建agb反演的光学模型、微波模型及光学微波协同的模型,根据第五模块选取的样本实现建模及验证后,选择最优的模型实现生物量反演。
综上所述,本发明具有如下特点:
(1)将基于lidar数据提取的生物量值作为训练及验证样本集,避免了使用费时费力的人工采样方法,对于充足且具代表性的野外调查数据难以获取的大面积区域具有尤为重要的意义。
(2)采用分层随机采样方法选择生物量样本,该数据集实现了对研究区生物量值在统计和地理位置上的全覆盖,充分反映了研究区植被群落的生长状况变化。
(3)构建了光学与微波数据协同反演模型,充分发挥两者估测生物量的优势,有效提高了地上生物量的定量反演精度。
附图说明
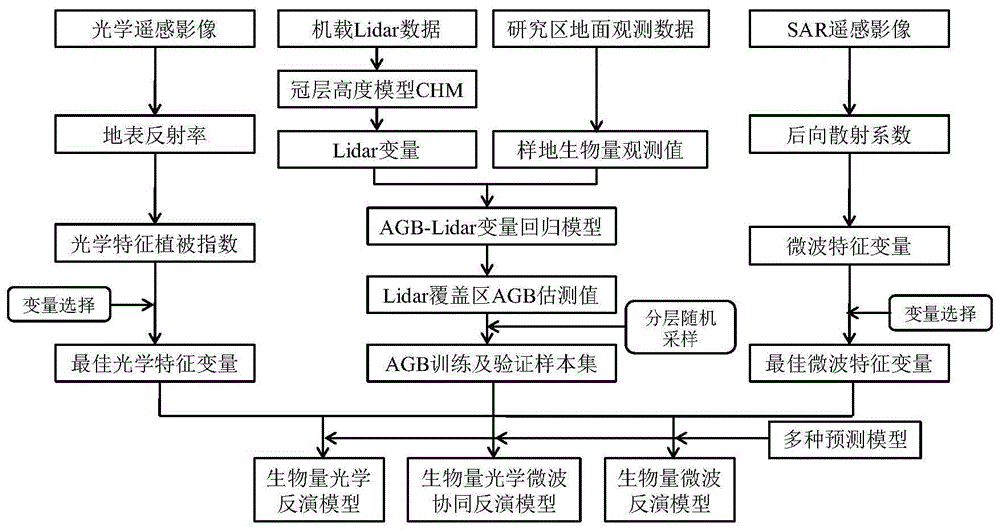
图1为本发明实施例的流程图。
具体实施方式
下面结合附图和实施例对本发明技术方案做进一步说明。
不同于以往的反演方法,本发明首先以样地实测agb为因变量,提取的lidar变量为自变量,建立生物量的多元逐步线性回归模型,得到lidar数据覆盖区域的地上生物量值;然后将lidar数据覆盖区域的生物量值作为生物量训练及验证样本集,利用分层随机采样的方法,选取一定数量的样本进行后续的建模及验证;最后采用变量筛选方法筛选出最佳光学与微波特征变量,并将最佳光学变量、最佳微波变量及二者的结合分别应用于多种预测模型中,分别构建agb反演的光学模型、微波模型及二者协同的模型。
本发明的实施例是基于landsat8operationallandimager(oli)和radarsat-2,对广州市从化研究区森林地上生物量进行估算,参照图1,本发明实施例的具体步骤如下:
步骤a:研究区样地地上生物量计算,包括利用地面观测试验获取的样地单株参数数据集,基于地上生物量计算公式,获得样地生物量(agb)观测值;
实施例中,通过地面观测获取了各样地内单木的树高和胸径参数的测量结果数据集。根据研究区主要树种的异速生长模型(j.fang,g.liu,ands.xu,“biomassandnetproductionofforestvegetationinchina,”actaecologicasinica,vol.16,pp.497–508,1996.),首先计算出样地内单木生物量,进而计算出样地总生物量,样地总生物量与样地面积之比即为样地生物量观测值,单位为mg/ha。
步骤b:分别对覆盖研究区的lidar数据、光学遥感数据和微波遥感数据进行预处理,分别得到冠层高度值(chm)、地表反射率数据与后向散射系数;
实施例中进行lidar数据、landsat8oli以及radarsat-2数据预处理:
具体实施时可以利用terrascan软件,首先,将高度大于其周围点高度中位数的点以及孤立点进行去除;其次,将剩余的lidar点云数据分为地面点和非地面点,再分别对地面点和所有首次回波插值生成数字高程模型(digitalelevationmodel,dem)和数字表面模型(digitalsurfacemodel,dsm),且分辨率均为1m;然后,将dsm减去dem,得到1m分辨率的冠层高度模型(crownheightmodel,chm),即归一化的高度值,根据实地调查情况,保留值在2m-35m范围内的chm像元,将其作为植被像元,以此排除研究区内的林下低矮植被和高于树木的地物;最后,以正射校正后的landsat8影像为基准,对chm影像进行几何校正。
具体实施时可以利用envi5.1软件,首先,将数字信号值(digitalnumber,dn)转换为表观辐亮度值,实现对影像的辐射定标;其次,采用flaash(fastline-of-sightatmosphericanalysisofspectralhypercube)模型对定标后的影像进行大气校正,得到地表反射率影像;然后,利用全球公开的30m公开的dem对大气校正后的影像进行正射校正;最后,基于预处理后的lidarchm影像对正射校正后的landsat8-oli影像进行裁剪,得到覆盖从化研究区的光学影像。
具体实施时可以利用nest(nexteuropeanspaceagency(esa)sartoolbox)软件,首先对radarsat-2影像进行辐射定标得到后向散射系数;然后对sar数据进行滤波来减小斑点噪声;利用预处理后的landsat8oli影像对sar数据进行几何校正,并将其重采样到与landsat8oli一致的空间分辨率(30m);最后将预处理后的landsat8oli和radarsat-2进行裁剪,只保留与研究区域一致的landsat8oli和radarsat-2影像。
步骤c:lidar变量、光学变量与微波变量提取:基于chm数据,提取多种lidar变量,并基于光学地表反射率数据,提取多种光学特征植被指数,同时基于微波后向散射系数数据,提取多种微波特征变量
基于chm,计算的lidar变量包括最小值、最大值、平均值、高度分位数、标准差、变异系数、倾斜度、峰值以及冠层覆盖度。这些是lidar统计变量中常用的变量,本发明不予赘述。例如提取限定范围内的chm值最小值。取值范围是与卫星影像相同的分辨率,即30m*30m内获取的这些lidar变量。
基于预处理后的landsat8oli地表反射率数据,计算归一化植被指数ndvi、比值植被指数sr、增强型植被指数evi、土壤调节植被指数savi、修正土壤调节植被指数msavi,优化型土壤调节植被指数osavi、水分胁迫指数msi、归一化水指数ndwi和叶绿素指数clgreen,其数学表达式见公式(1)-(9)。
式中,r、g、b、nir和swir1分别为红光、绿光、蓝光、近红外及短波红外波段的反射率。
基于预处理后的radarsat-2数据,计算的微波特征变量包括vv,hh,vh,hv,vv/hh,hh/hv,vv/hv以及rvi,这里的vv、hh、vh是radarsat-2数据的三种极化方式,vv/hh、hh/hv、vv/hv是相应的比值,其中rvi的计算公式如下:
步骤d:agb基准图获取,包括以样地实测agb为因变量,提取的lidar变量为自变量,建立生物量的多元逐步线性回归模型,得到lidar数据覆盖区域的生物量估测值;
实施例中,以样地实测agb为因变量,提取的lidar变量为自变量,采用多元逐步线性回归方法建立agb与lidar变量之间的关系模型,得到agb-lidar变量回归模型,进而得到lidar数据覆盖区域的生物量值,作为后续反演模型建立的生物量基准图。
步骤e:分层随机采样,包括将lidar数据覆盖区域的生物量值作为训练及验证样本集,利用分层随机采样的方法,选取一定数量的样本进行后续的建模及验证;
将lidar数据覆盖区域的生物量值作为训练及验证样本集,采用分层随机采样的方法,选取一定数量的样本进行后续的建模及验证。在实施分层随机采样时,选取平均值和标准差两个lidar高度变量作为先验知识来进行分层,这是因为这两个变量能够直接显示森林结构及其生长状态。首先,进行lidar条带覆盖区域的数据准备,包括生物量基准图中的agb值及其对应的预测变量值(包括所有光学变量、sar变量以及高度平均值和标准差);其次,将以上数据集按照平均值进行升序排列,再平均分为10个大小相同的数据层;然后,将每个数据层按照标准差进行升序排列,再平均分为4等份,从而一共生成40个相同大小的数据层;最后,从每个数据层中随机选择20个样本,总共可获得800个样本数据,并按照3:1的比例随机分为训练和验证样本集。
步骤f:最佳光学与微波变量选择,包括采用变量筛选方法筛选出最佳光学与微波特征变量;
实施例优选利用逐步筛选法分别对光学与微波特征变量进行筛选,具体步骤为:(1)设n为预测变量的个数,每个变量均有一次排除在预测变量集之外,形成n组变量,每组包含n-1个变量,将n组变量分别输入预测模型中进行模型训练;(2)对(1)中所有模型进行精度验证,验证指标为rmse和r2,具有最佳预测效果(即r2最大)的模型能够间接证明,该模型未采用的预测变量具有最差的解释能力;(3)将步骤(2)判别出的解释力最差的变量剔除出候选变量集;
(4)重复以上步骤,直到r2收敛为止。需要注意的是,模型的精度评价采用的是所有预测模型(即slr、knn、bpnn、svm、rf和ssae)验证精度的平均值。最终筛选出的最佳光学特征变量为sr,ndvi,osavi,msi和ndwi,最佳微波特征变量为vv,hv,hh/hv和rvi。
步骤g:光学、微波及二者协同的生物量反演模型构建,包括将最佳光学变量、最佳微波变量及二者的结合分别应用于多种预测模型中,分别构建agb反演的光学模型、微波模型及二者协同的模型,即生物量光学反演模型、生物量微波反演模型及生物量光学微波协同反演模型。根据步骤e选取的样本实现建模及验证后,选择最优的模型实现生物量反演。
优选地,选用的预测模型包括多元逐步线性回归(slr)、k最近邻(knn),支持向量机(svm),bp神经网络(bpnn),随机森林(rf)以及深度学习(dl),其中深度学习模型选用的是栈式稀疏自编码网络模型(stackedsparseautoencodernetwork,ssae)。
相比传统的统计回归方法,k最近邻(knn)、支持向量机(svm)、误差反向传播神经网络(bpnn)、随机森林(rf)方法以及近几年关注度颇高的深度学习方法(dl)能够有效描述植被参数与预测变量之间复杂的非线性关系,在生物量以及其他植被参数的估测研究中展现出了更大的应用潜力,比参数化方法更易于工程化实施。
实施例中,将最佳光学变量(sr、ndvi、osavi、msi、ndwi)、最佳微波变量(vv、hv、hh/hv、rvi)及二者的协同分别应用于6种预测模型(slr、knn、svm、bpnn、rf、ssae)中,协同策略是将所有的最佳光学变量和所有的最佳微波变量一起分别输入这6种预测模型,构建agb的光学反演模型、微波反演模型及二者协同反演模型,其中光学反演模型的输入变量为最佳光学变量;微波反演模型的输入变量为最佳微波变量;协同反演模型的输入变量为所有的最佳光学变量和所有的最佳微波变量。
实验基于本发明提出的光学微波协同反演模型,利用landsat8oli和radarsat-2卫星数据,估算广州市从化研究区地上生物量的结果图。
以广州市从化研究区森林为实验对象,将光学反演模型和微波反演模型估测结果与协同反演结果进行对比验证,客观评价指标选取判定系数(r2)、均方根误差(rmse)和相对均方根误差(rmser)。
表1生物量反演模型精度评价结果
验证结果如表1所示,发现在所有预测方法中,深度学习(ssae)方法具有最高的估测精度,并且光学微波数据协同在所有预测方法中均好于单一数据源的预测结果,因此,光学微波数据协同并结合深度学习模型取得了最好的估测效果,判定系数为0.812,均方根误差为21.753,相对均方根误差为14.457%。表明光学与微波数据协同能够发挥两者在agb反演中各自的优势,提高反演精度。
具体实施时,以上技术方案可采用计算机软件技术实现自动运行流程,也可以采用模块化方式提供相应系统。本发明实施例还提供一种城市地上生物量光学微波协同反演系统,包括以下模块:
第一模块,用于利用地面观测试验获取的样地单株参数数据集,获得样地生物量agb观测值;
第二模块,用于分别对覆盖研究区的lidar数据、光学遥感数据和微波遥感数据进行预处理,分别得到冠层高度值chm、地表反射率数据与后向散射系数;
第三模块,用于基于chm数据,提取各种lidar变量,并基于光学地表反射率数据,提取多种光学特征植被指数,同时基于微波后向散射系数数据,提取多种微波特征变量;
第四模块,用于以样地实测agb为因变量,提取的lidar变量为自变量,建立生物量的多元逐步线性回归模型,得到lidar数据覆盖区域的生物量估测值;
第五模块,用于将lidar数据覆盖区域的生物量值作为训练及验证样本集,利用分层随机采样的方法,选取样本用于后续的建模及验证;
第六模块,用于采用变量筛选方法筛选出最佳光学与微波特征变量;
第七模块,用于将最佳光学变量、最佳微波变量及二者的结合分别应用于多种预测模型中,分别构建agb反演的光学模型、微波模型及光学微波协同的模型,根据第五模块选取的样本实现建模及验证后,选择最优的模型实现生物量反演。
具体各模块实现可参见相应步骤,本发明不予赘述。
本文中所描述的具体实施例仅仅是对本发明精神做举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或超越所附权利要求书所定义的范围。
- 还没有人留言评论。精彩留言会获得点赞!