一种血液生化指标计算性别和年龄的方法与流程
本发明涉及血液检测技术领域,具体为一种血液生化指标计算性别和年龄的方法。
背景技术:
衰老是个体不可避免的生命阶段,是生物发育成熟后的一个持续、动态并缓慢发生的阶段,在这一阶段中,个体机能减退、生理结构组分逐渐退行性病变,同时伴发一系列退行性疾病,如老年骨质增生、阿尔兹海默症(老年痴呆症)、帕金森综合征等。衰老伴随的器官功能减退、细胞和分子水平的改变渐进性影响健康,因此衰老与疾病和死亡密切相关。近年来,关于个体衰老的研究也成为生命科学中一个热门的研究领域。衰老的个体差异较大,同一个体各个系统和器官的衰老水平和速度也不同,因此历法年龄并非反应寿命的最可靠指标,生物学年龄则更为精确。
类似mark-age的大型纵向项目已经开始研究多种生物标记物在衰老过程中的改变与实际年龄的关系,甲基化相关的标记物、转录组代谢组相关代谢物、端粒长度、免疫细胞数量和应答效果等都可作为衡量个体年龄的标准之一。爱丁堡大学的研究团队根据血液中的dna甲基化水平预测个体年龄,然后将这一年龄与个体真实年龄进行比较,结果发现,甲基化预测年龄比实际年龄大五岁以上老人,死亡风险要高21‰;端粒普遍存在于染色体末端,一方面保护染色体不被降解,另一方面也防止染色体相互融合,一但端粒耗尽,染色体将无法正常分裂,细胞的更新也将结束,因此端粒的长度强烈指向细胞分裂潜力的大小,端粒越短表明细胞再生能力越小,越长则表示细胞再生活力越强,剩余分裂次数充裕。
然而现有的技术所研究的指标大多缺乏对全部器官或者系统的整体描述,只针对某一系统或个体的某一层面做衰老方面的解释;同时这些指标的测量难度大、成本高;最重要的是这些研究获取的指标大多从具有病理性特征的个体上选取,并不具有针对所有个体的普遍性,血液检测是医学和健康产业中最常见、最简单的检测,血液指标在自然状态下个体差异多样,并且对不同的生理状况反应敏感(炎症或醉酒情况等),因此血液检测在临床上的使用十分普遍。研究表明,个体步入老年后,血液中红细胞数量较青壮年时减少约10%到20%,红细胞比容和血红细胞蛋白量均有降低;白细胞也会随着年龄的增长而降低,其中以淋巴细胞降低的最明显,因此老年人的免疫能力普遍降低,发生感染、炎症和肿瘤的几率增高;白蛋白数量逐渐减少,血脂总量显著升高,甘油三酯含量增加,胆固醇含量增加等,以上血液指标均已被证明是个体衰老的标记物。
现有计算个体年龄的方法只针对个体的某个器官或组织,缺乏对个体衰老的整体描述和解释,无法全面的反应个体衰老情况,血液指标涉及多种组学代谢物,以血液指标作为计算个体年龄的方法可以更加全面的描述个体衰老情况;
甲基化相关的标记物、转录组代谢组相关代谢物、端粒长度、免疫细胞数量和应答效果来衡量衰老与个体年龄的方法需要检测的指标获取难度大、成本高,血液检测在临床的使用上更加普遍,指标更易获取。
技术实现要素:
针对上述背景技术的不足,本发明提供了一种血液生化指标计算性别和年龄的方法,具备获取样本难度小、成本低、数据精准度高的优点,解决了背景技术提出的问题。
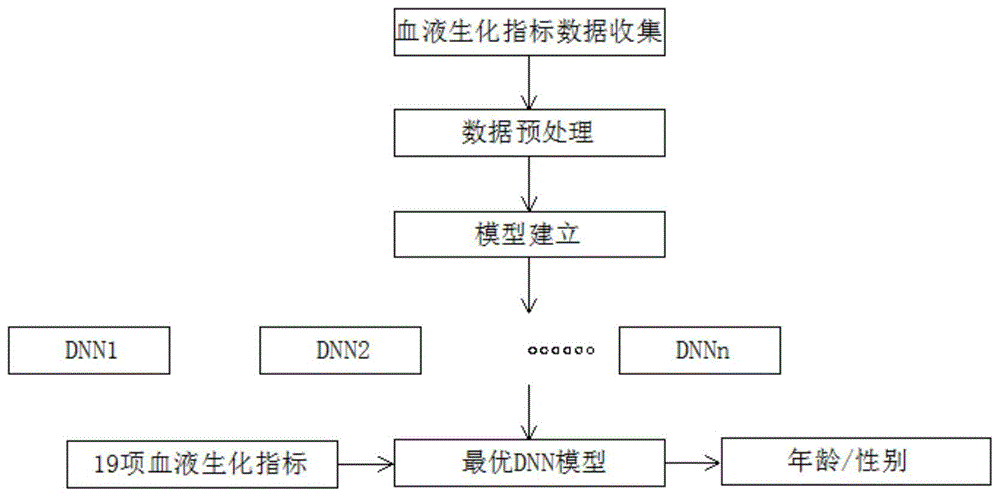
本发明提供如下技术方案:一种血液生化指标计算性别和年龄的方法,包括血液生化指标数据收集、数据预处理、模型建立,所述样本收集后对其进行数据预处理,然后经过dnn模型计算后得出结果,所述血液生化指标按以下方法计算性别和年龄:
第一步,收集原始数据,共计收入92062个样本,所述每个样本中包含个体年龄、性别和19项血液生化指标,所述所选指标常见于医院和体检机构的血常规和血液生化指标检测报告单;
第二步数据预处理,移除有遗漏数据的样本和明显错误离群值(outliar)的样本后,总计获得26754例完整样本用于两个模型的训练和测试,随后对19项血液生化指标进行标准化处理,将所有指标的数值都映射在0,1范围内;
第三步模型建立与评估,在使用模型进行计算时,将待测样本的19项血液生化指标直接传入模型中,经过dnn模型计算后,传出即为计算好的年龄和性别。
优选的,所述19项血液生化指标包括白蛋白、葡萄糖、尿素、胆固醇、总蛋白、血清钠、肌酸酐、血红蛋白、总胆红素、甘油三酯、高密度脂蛋白胆固醇、低密度脂蛋白胆固醇、血清钙、血清钾、血细胞比容、平均红细胞血红蛋白浓度、平均红细胞体积、血小板计数和红细胞计数。
优选的,所述年龄计算使用dnn回归算法,性别计算使用dnn分类算法。
优选的,所述dnn模型主要由输入层、隐藏层和输出层构成、每层中有若干神经元,输入层神经元与输入变量个数对应,输出层神经元与输出结果变量个数对应。
本发明具备以下有益效果:
该血液生化指标计算性别和年龄的方法,通过以血液指标为衡量对象,增加测量的全面性,同时血液指标包含了多组学的代谢物,可以更加全面的反应个体衰老状况,并解释衰老水平,并通过dnn模型对血液生化指标进行计算,使得整个流程更加便捷化,使得血液生化指标传入dnn模型后,即可得到测试结果,且计算模型中的各项参数和模型结构经过多次验证,保证计算结果的准确性,同时所选取的血液生化指标是临床使用和体检机构中最常见的指标,获取难度小成本低,解释程度高,使得样本被计算后得出的结果更加全面化。
附图说明
图1为本发明流程示意图;
图2为深度神经网络dnn算法结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1-2,一种血液生化指标计算性别和年龄的方法,包括血液生化指标数据收集、数据预处理、模型建立,所述样本收集后对其进行数据预处理,该计算方法分为性别计算和年龄计算两部分,每一部分都包括计算模型的训练和模型的使用两个步骤,模型的训练我们都使用dnn算法,该算法经验证,在这项技术的结果准确率、解释性上都显著高于其他机器学习算法(k近邻算法、随机森林、线性回归、支持向量机等),dnn算法中引入隐藏层和神经元、增强了模型的表达能力,同时dnn在自动缩放神经元权重方面的特性,也最大程度的丰富了模型发展方向,然后经过dnn模型计算后得出结果,所述血液生化指标按以下方法计算性别和年龄:
第一步,收集原始数据,共计收入92062个样本,所述每个样本中包含个体年龄、性别和19项血液生化指标,所述所选指标常见于医院和体检机构的血常规和血液生化指标检测报告单;
第二步数据预处理,移除有遗漏数据的样本和明显错误离群值(outliar)的样本后,总计获得26754例完整样本用于两个模型的训练和测试,随后对19项血液生化指标进行标准化处理,将所有指标的数值都映射在0,1范围内,避免模型在不同维度上的迭代速度不同,从而造成模型收敛缓慢的问题,提升模型的收敛速度;
第三步模型建立与评估,在使用模型进行计算时,将待测样本的19项血液生化指标直接传入模型中,经过dnn模型计算后,传出即为计算好的年龄和性别。
其中,所述19项血液生化指标包括白蛋白、葡萄糖、尿素、胆固醇、总蛋白、血清钠、肌酸酐、血红蛋白、总胆红素、甘油三酯、高密度脂蛋白胆固醇、低密度脂蛋白胆固醇、血清钙、血清钾、血细胞比容、平均红细胞血红蛋白浓度、平均红细胞体积、血小板计数和红细胞计数。
其中,所述年龄计算使用dnn回归算法,性别计算使用dnn分类算法,便于区分血液样本中的年龄和性别,使得测试的结果更加精确化。
其中,所述dnn模型主要由输入层、隐藏层和输出层构成、每层中有若干神经元,输入层神经元与输入变量个数对应,输出层神经元与输出结果变量个数对应,使得样本在测量中,通过输入层的神经元分析,得出测量。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!