基于声学的电动牙刷口腔清洁质量检测系统及检测方法与流程
本申请涉及移动计算、人工智能技术领域,尤其涉及一种基于声学的电动牙刷口腔清洁质量检测系统及检测方法。
背景技术:
刷牙是保护牙齿健康的一种重要且基本的方法,刷牙质量对牙齿健康有显著的影响。但随着社会的不断发展,现代城市居民的生活节奏不断加快,特别是在生活紧张、充满竞争的大都市,无论是正在上学的中小学生大学生、还是年轻的上班族,由于日常工作学习任务繁忙,不同程度的忽视了自身健康状态,而日常的牙齿护理就属于其中之一。事实上,在考虑频繁出现口腔健康问题和随之而来的牙齿护理费用高昂的情况下,相较与洗牙、冲牙而言,每天刷牙仍然是保持口腔健康的最有效方法。
但是,目前多数人仍在使用不标准的刷牙方式,其刷牙质量难以得到保证。虽然在口腔医学界有多种标准刷牙方法提出,但是人们在使用此类方法时缺乏有效的监督和反馈,在清洁口腔时,各口腔区域清洁的时间、力度、覆盖程度等没有较为定量的评估方式,尤其是前牙龈内表面、臼齿内侧等,长此以往,累积的口腔细菌会在这些区域产生牙菌斑、牙结石、龋齿及更严重的口腔疾病。近年来,为了解决普通手动牙刷难以彻底清洁,电动牙刷得以普及,其可以对一般牙面进行更彻底的清洁,但是同样在对刷牙过程没有较好的评估和检测的情况下,使用者容易忽视牙齿内表面。目前一些装有imu等传感器的高端电动牙刷具有清洁牙面识别的功能,但其制造成本较高,通常其价格要比普通的电动牙刷高4~5倍。
技术实现要素:
为了解决上述技术问题,本申请实施例提供一种基于声学的电动牙刷口腔清洁质量检测系统及检测方法,基于声学原理,构建了使用低成本的喉麦及蓝牙耳机的可穿戴式设备,对市面上一般的电动牙刷,通过分析其音频特性,应用本方法提出的刷牙行为识别模型,即可以实时检测应用者的刷牙质量,并建立其长期的口腔健康档案。
本申请实施例第一方面提供了一种基于声学的电动牙刷口腔清洁质量检测系统,可包括:
电动牙刷声信号采集模块、多通道信号同步模块、simo系统辨识模块、特征提取及降维模块、刷牙行为分类模块和实时检测模块;
电动牙刷声信号采集模块,用于采集观测信号;观测信号由刷头与牙齿摩擦产生的声信号经面部组织传递后在颈部和耳部产生;
多通道信号同步模块,用于对喉麦和蓝牙耳机采集到的有时延信号进行同步和对齐;
simo系统辨识模块,用于获取同步之后的观测信号后计算各牙面对应口腔系统的频域响应函数,提取出牙面的稳定特征;
特征提取及降维模块,用于对频域响应函数和mfcc融合之后的特征进行降维处理,形成融合降维特征;
刷牙行为分类模块,用于对比使用多种机器学习模型,对特征集对应的刷牙行为进行分类识别,优选准确率和计算性能较好的模型集成到实时检测应用中;
实时检测模块,基于融合降维特征对刷牙行为进行识别。
进一步地,电动牙刷声信号采集模块包括:
双通道喉麦模块,包含有两个麦克风,作为信号采集的硬件,其中一个麦克风贴近皮肤,用于采集到牙刷头与牙齿表面摩擦产生的声信号经过食道传递后的观测信号,另一个麦克风朝向外部,用于采集到牙刷电机在清洁不同牙面时其电机旋转的信号差异;
含麦克风的蓝牙耳机,用于采集非对称的刷牙场信号,增加对称分布于口腔左右两侧牙面的识别准确率;
处理模块,对采集到信号进行滑动窗口处理。
进一步地,多通道信号同步模块包括:
相关度计算模块,用于计算同一个窗口内喉麦采集信号和蓝牙耳机采集信号的互相关函数;
采样点获取模块,对互相关函数分步进行分析,找到其距离零点最近的极值对应采样点;
对齐模块,用于将有时延的信号向前偏移采样点获取模块中计算得到的采样点数,对齐信号。
进一步地,simo系统辨识模块包括:
空转事件输入信号模块,用于在空转事件中采集到的电动牙刷空转声信号,提取出其前k个主要频率成分,估计输入信号;
两路输出模块,用于针对一个采样窗口内的喉麦信号和蓝牙耳机信号,计算输入的自功率谱;
频域响应函数模块,用于计算空转事件输入信号模块和两路输出模块之间的互功率谱并通过hv估计,得到两个输出信号分别对应的频域响应函数分布。
进一步地,特征提取及降维模块包括:
特征融合模块,基于频域响应函数模块的函数分布利用直方图估计获取频域响应向量后,与原始音频的mfcc特征进行融合;
特征降维模块,采用anova方法对全体特征集进行方差分析并进行特征降维,以满足在移动设备上实时监测的计算要求。
进一步地,实时检测模块包括:
采样分类模块,对于每一个采样窗口信号,抽取并融合特征,并通过最优分类器对牙面进行分类;
刷牙状态显示模块,按照基准刷牙方法对各牙面的清洗时间和覆盖率进行累计,并在应用中针对清洁不到位的牙面,给使用者图形和声音提示;据各牙面清洁质量对本次刷牙进行评分反馈,并存储到云服务器,记录使用者的长期牙齿健康数据。
本申请实施例第二方面提供了一种基于声学的电动牙刷口腔清洁质量检测检测方法,包括:
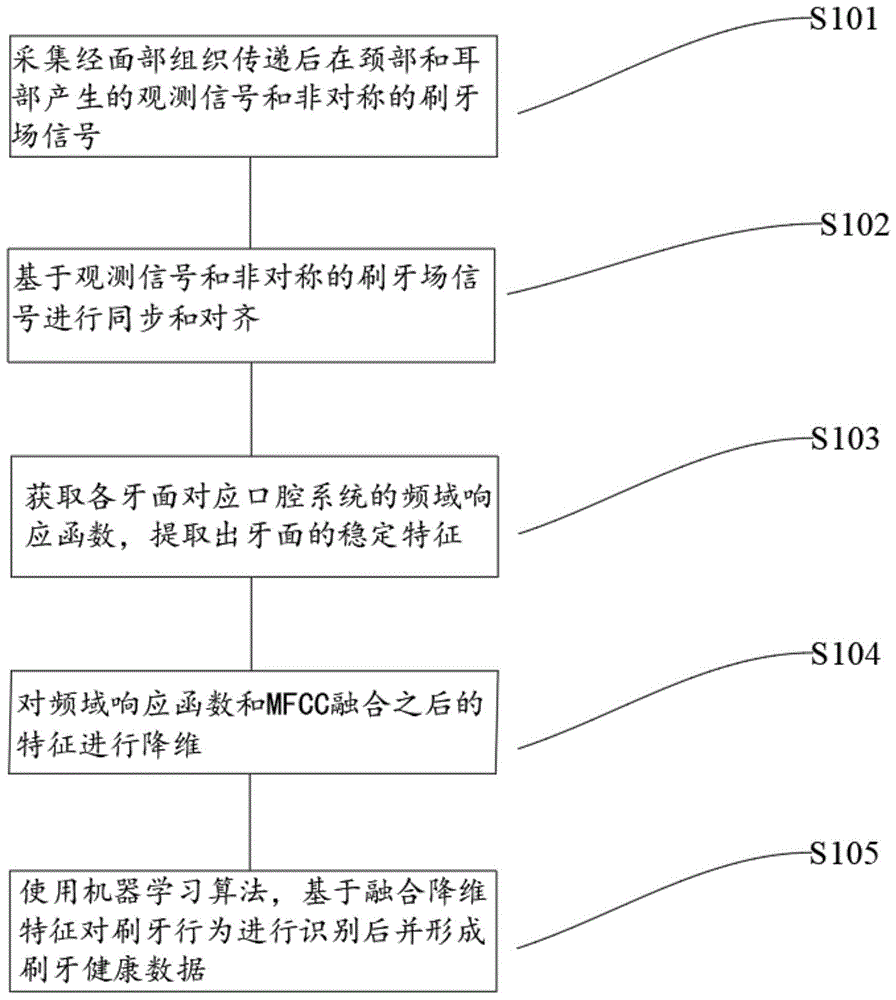
采集经面部组织传递后在颈部和耳部产生的观测信号和非对称的刷牙场信号;
基于观测信号和非对称的刷牙场信号进行同步和对齐;
获取各牙面对应口腔系统的频域响应函数,提取出牙面的稳定特征;
对频域响应函数和mfcc融合之后的特征进行降维;
使用机器学习算法,基于融合降维特征对刷牙行为进行识别后并形成刷牙健康数据。
进一步地,采集经面部组织传递后在颈部和耳部产生的观测信号和非对称的刷牙场信号包括:
采用喉麦采集刷头与牙齿摩擦产生的声信号经面部组织传递后在颈部和耳部产生的观测信号;
采用有麦克风的蓝牙耳机采集非对称的刷牙场信号,增加对称分布于口腔左右两侧牙面的识别准确率;
其中,喉麦采用双通道喉麦,其中一个麦克风贴近皮肤,用于采集到牙刷头与牙齿表面摩擦产生的声信号经过食道传递后的观测信号,另一个麦克风朝向外部,采集到牙刷电机在清洁不同牙面时其电机旋转的信号差异。
进一步地,基于观测信号和非对称的刷牙场信号进行同步和对齐包括:
获取同一个窗口内喉麦采集信号和蓝牙耳机采集信号的互相关函数;
基于互相关函数分步进行分析,找到其距离零点最近的极值对应采样点;
针对有时延的信号向前偏移上步中计算得到的采样点数,对齐信号。
进一步地,获取各牙面对应口腔系统的频域响应函数,提取出牙面的稳定特征包括:
针对空转事件中采集到的电动牙刷空转声信号,提取出其前k个主要频率成分,估计输入信号;
对于一个采样窗口内的喉麦信号和蓝牙耳机信号,计算输入的自功率谱;
获取输入信号和两路输出之间的互功率谱;
通过hv估计,获取两个输出信号分别对应的频域响应函数分布。
在本申请实施例中,本方案提出了基于声学的刷牙行为识别监控方法,使用低成本的喉麦和蓝牙耳机构建可穿戴式设备,可以非对称的获取并分析电动牙刷产生的声信号,提高了识别左右对称口腔区域的准确度;本方案基于simo系统建模的方法,将不同口腔区域视为不同的线性时不变系统,从各系统的频域响应函数中提取特征,相比于统计特征具有更高的稳定性,在电动牙刷电量或档位存在扰动变化时仍能有效区分出各牙面对应系统;并且通过方差分析的方法大幅度的对原始数据进行了降维处理,有效的降低了计算量,延长了移动智能手机的续航时间;本方案通过综合对比和实验测试不同的机器学习模型以及不同窗口长度和步长设置,考虑了最佳准确率和较低计算量的情况,选择最优的机器学习模型,以及对应的窗口和步长等参数进行集成,提升了实时刷牙行为识别应用的检测精度。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明检测方法的流程示意图;
图2为本发明刷牙行为识别流程图;
图3为本发明的牙面划分示意图;
图4为本发明多通道声信号采集设备佩戴示意图;
图5为在不同的传感器组合下对识别准确率的贡献示意图;
图6为在不同窗口长度和步长下对识别准确率的影响示意图;
图7(a)为本发明的喉麦信号示意图;
图7(b)为本发明的蓝牙耳机信号示意图;
图7(c)为本发明的喉麦信号和蓝牙耳机信号同步的示意图;
图8(a)-(b)为本发明不同牙面对应系统的频域响应函数分布示意图;
图9为本发明的分类器模型性能对比示意图;
图10(a)-(c)为本发明识别不同牙面的混淆矩阵示意图。
具体实施方式
为使得本申请的申请目的、特征、优点能够更加的明显和易懂,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,下面所描述的实施例仅仅是本申请一部分实施例,而非全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本申请保护的范围。
下面结合附图和具体实施例,进一步阐明本发明。
在本申请的描述中,需要理解的是,术语“上”、“下”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本申请和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本申请的限制。
本发明的目的是对电动牙刷使用者的的刷牙行为进行识别,从而达到检测和保证使用者的刷牙质量,以及长期刷牙质量监控的目的,由电动牙刷声信号采集模块、多通道信号同步模块、simo系统辨识模块、特征提取及降维模块、刷牙行为分类模块及实时检测模块这几部分构成,系统流程图如图2所示。
在本申请中,电动牙刷声信号采集模块,用于采集观测信号,这里的观测信号由刷头与牙齿摩擦产生的声信号经面部组织传递后在颈部和耳部产生。
电动牙刷声信号采集模块包括:
双通道喉麦模块,包含有两个麦克风,作为信号采集的硬件,其中一个麦克风贴近皮肤,用于采集到牙刷头与牙齿表面摩擦产生的声信号经过食道传递后的观测信号,另一个麦克风朝向外部,用于采集到牙刷电机在清洁不同牙面时其电机旋转的信号差异。
含麦克风的蓝牙耳机,用于采集非对称的刷牙场信号,增加对称分布于口腔左右两侧牙面的识别准确率。
处理模块,对采集到信号进行滑动窗口处理,作平滑处理。
在本申请中,多通道信号同步模块主要是用于同步并对齐喉麦和蓝牙耳机产采集到的信号,消除通道之间信号时延对特征提取和牙面识别的影响。具体包括:
相关度计算模块,用于计算同一个窗口内喉麦采集信号和蓝牙耳机采集信号的互相关函数。
采样点获取模块,对互相关函数分步进行分析,找到其距离零点最近的极值对应采样点。
对齐模块,用于将有时延的信号向前偏移采样点获取模块中计算得到的采样点数,对齐信号。
在本申请中,simo系统辨识模块,其将电动牙刷电机信号传递到喉麦和蓝牙耳机所经过的各口腔部位视为线性时不变系统,并提取其稳定特征。具体包括:
空转事件输入信号模块,用于在空转事件中采集到的电动牙刷空转声信号,提取出其前k个主要频率成分,估计输入信号;
两路输出模块,用于针对一个采样窗口内的喉麦信号和蓝牙耳机信号,计算输入的自功率谱;
频域响应函数模块,用于计算空转事件输入信号模块和两路输出模块之间的互功率谱并通过hv估计,得到两个输出信号分别对应的频域响应函数分布。
在本申请中,特征提取及降维模块,用于对频域响应函数和mfcc融合之后的特征进行降维处理,形成融合降维特征。具体包括:
特征融合模块,基于频域响应函数模块的函数分布利用直方图估计获取频域响应向量后,与原始音频的mfcc特征进行融合;
特征降维模块,采用anova方法对全体特征集进行方差分析并进行特征降维,以满足在移动设备上实时监测的计算要求。
在本申请中,刷牙行为分类模块,用于对比使用多种机器学习模型,对特征集对应的刷牙行为进行分类识别,优选准确率和计算性能较好的模型集成到实时检测应用中;
在本申请中,实时检测模块,基于融合降维特征对刷牙行为进行识别。具体包括:
采样分类模块,对于每一个采样窗口信号,抽取并融合特征,并通过最优分类器对牙面进行分类;
刷牙状态显示模块,按照基准刷牙方法对各牙面的清洗时间和覆盖率进行累计,并在应用中针对清洁不到位的牙面,给使用者图形和声音提示;据各牙面清洁质量对本次刷牙进行评分反馈,并存储到云服务器,记录使用者的长期牙齿健康数据。
本申请具体采集信号时,使用改装后的非对称双通道喉麦,结合蓝牙耳机的麦克风,构建成可穿戴的声信号采集系统,采集电动牙刷在清洁时源信号经不同传递路径传播后的多通道信号。根据基准刷牙方法,将口腔划分为16个不同的区域,如图3所示,同时增加漱口事件以及电动牙刷空转事件,共18个待识别事件。对于不同牙面采集到的音频信号,将对应的牙面视为不同的线性时不变系统,使用系统建模的方式计算各系统的频域响应函数,提取其稳定特征,使用机器学习算法挖掘出各系统之间的差异,从而能够识别使用者的刷牙行为。
本申请实施例还提供一种基于声学的电动牙刷口腔清洁质量检测方法,该方法用于内嵌于前述任一项检测系统。
本发明提供的基于声学的电动牙刷口腔清洁质量检测方法,具体包括以下几个步骤:
s101:多通道音频数据采集与标注。
在采集标注数据以及实时检测时,喉麦通过3.5mm音频接口与手机连接并佩戴在颈部;蓝牙耳机通过蓝牙与手机建立无线连接,并佩戴在使用者的一侧耳部,如示意图4所示。
为了构建通用性的刷牙行为识别模型,对多名志愿者的刷牙声信号进行了采集,并使用与实时监测应用配套的标注工具对各牙面对应的声信号进行了标注,形成原始训练数据集。
s102:音频信号同步:在实时检测的过程中,喉麦和蓝牙耳机采集到的声信号是有两条不同的链路最终传递到手机的,其各自的传播时延不同;并且喉麦和蓝牙耳机分别的信号采集线程存在启动不同步的问题,这两点造成了蓝牙耳机和喉麦之间信号时间差,如果直接对存在时间差的两路信号进行分析,则会造成较为严重的特征提取偏差和识别误差。因此本方法使用基于互相关函数的方式对实时采集到的信号进行同步处理。通过计算多通道信号之间的互相关函数极值点的偏移量来确定信号延时。具体包括:
s102a:计算同一个窗口内喉麦采集信号和蓝牙耳机采集信号的互相关函数。
s102b:对互相关函数分步进行分析,找到其距离零点最近的极值对应采样点。
s102c:将有时延的信号向前偏移步骤s102b中计算得到的采样点数,对齐信号。
s103:对口腔区域进行系统建模以及特征融合。为了识别出使用者正在清洁的牙面,本发明使用基于simo系统建模的方法,将口腔的16个区域对应的面部组织视为各自不同的线性时不变系统。将电动牙刷的电机旋转产生的声信号作为系统的输入信号,将喉麦和蓝牙耳机处的观测信号作为系统的输出信号,通过挖掘输入-输出之间的变换关系,求出系统的频域响应函数(frf)以表示个口腔区域的稳定特征。具体步骤包括:
s103a:在空转事件中采集到的电动牙刷空转声信号,提取出其前k个主要频率成分,估计输入信号;
s103b:对于一个采样窗口内的喉麦信号和蓝牙耳机信号,计算输入的自功率谱;
s103c:计算输入信号和两路输出之间的互功率谱;
s103d:通过hv估计,得到两个输出信号分别对应的频域响应函数分布。
s104:将两个通道的frf分布以及原始音频的mfcc特征融合后,为了保证在移动设备上的计算实时性,使用方差分析方法对特征进行降维,最终使用降维后的特征描述符集合进行牙面分类和刷牙行为识别。具体包括:
s104a:对s103d中得到的频域响应函数进行直方图估计,得到频域响应向量;
s104b:将喉麦和蓝牙耳机分别对应的频域响应向量与原始音频的mfcc特征进行融合;
s104c:使用anova方法对全体特征集进行方差分析并进行特征降维,以满足在移动设备上实时监测的计算要求。
s105:刷牙行为识别模型构建及实时监测。
对于步骤s104c中获取到的各口腔位置的特征描述符,对比并优选多种机器学习分类器模型,选取其中准确率和计算复杂性最合适的模型集成到实时检测应用中。在实时检测用户刷牙行为的过程中,对于每一个采样窗口信号,通过步骤s102~104的方法抽取并融合特征,并通过最优分类器对牙面进行分类。得到每个时刻刷洗的牙面后,按照基准刷牙方法对各牙面的清洗时间和覆盖率进行累计,并在应用中针对清洁不到位的牙面,给使用者图形和声音提示。在每次刷牙过程结束后,依据各牙面清洁质量对本次刷牙进行评分反馈,并存储到云服务器,记录使用者的长期牙齿健康数据。具体包括:
s105a:对比使用多种机器学习模型,对特征集对应的刷牙行为进行分类识别,优选准确率和计算性能较好的模型集成到实时检测应用中;
s105b:实时检测时,对于每一个采样窗口信号,通过步骤2~6的过程抽取并融合特征,并通过最优分类器对牙面进行分类;
s105c:按照基准刷牙方法对各牙面的清洗时间和覆盖率进行累计,并在应用中针对清洁不到位的牙面,给使用者图形和声音提示;
s105d:据各牙面清洁质量对本次刷牙进行评分反馈,并存储到云服务器,记录使用者的长期牙齿健康数据。
上述提出的基于声学的电动牙刷口腔清洁质量检测方法,通过对电动牙刷使用者的刷牙行为进行识别,从而达到检测和保证使用者的刷牙质量,以及长期刷牙质量监控的目的。
下面结合具体的实施例,对本申请进行说明。
首先,对传统的双通道喉麦进行了改装,使其中一个麦克风贴近皮肤,这样可以采集到牙刷头与牙齿表面摩擦产生的声信号经过食道传递后的观测信号,另一个麦克风朝向外部,主要采集到牙刷电机在清洁不同牙面时其电机旋转的信号差异。将两个麦克风的数据通过硬件融合成单通道音频数据后,结合蓝牙耳机的麦克风,构建成可穿戴的声信号采集系统,各通道获取的声信号对识别准确率的贡献如图5所示。根据基准刷牙方法,将口腔划分为16个不同的区域其中上(以u表示)下(以d表示)两个门牙区各包含外侧区(以o表示)和内侧区(以i表示),四个后牙区各包含内侧、外侧和咀嚼面,左右牙面以l和r加以区分,共计16个区域。同时,增加漱口事件,以提高识别方法在区分刷牙和非刷牙事件之间进行区分的鲁棒性;以及电动牙刷空转事件,通过提取其主频率来计算和矫正系统的输入信号。对于不同牙面采集到的音频信号,将对应的牙面视为不同的线性时不变系统,使用系统建模的方式计算各系统的频域响应函数,提取其稳定特征,使用机器学习算法挖掘出各系统之间的差异,从而能够识别使用者的刷牙行为。
检测方法具体包括以下几个步骤:
步骤1:多通道音频数据采集与标注。
在采集标注数据以及实时检测时,喉麦通过3.5mm音频接口与手机连接并佩戴在颈部;蓝牙耳机通过蓝牙与手机建立无线连接,并佩戴在使用者的一侧耳部。采集的信号使用44100hz的采样率,及16bit的位宽,分为喉麦和蓝牙耳机两个通道。对于进一步的声信号处理,本方法设置了128、512、1024、2048、4096、8192、10240采样点的滑动窗口大小,以及30%、50%、70%、100%的步长,在实时监测中选择最优的大小和步长进行实现,其不同组合的性能如图6所示。为了构建通用性的刷牙行为识别模型,对多名志愿者的刷牙声信号进行了采集,并使用与实时监测应用配套的标注工具对各牙面对应的声信号进行了标注,形成原始训练数据集。
步骤2:音频信号同步。
在实时检测的过程中,喉麦的信号是由麦克风-音频线-3.5mm接口的链路传递到手机;蓝牙耳机采集的信号是由麦克风-dsp编码-蓝牙无线传输的链路传递到手机,两条链路的传播时延不同;并且喉麦和蓝牙耳机分别的信号采集线程存在启动不同步的问题。以上两点造成了蓝牙耳机和喉麦之间信号时间差,如果直接对存在时间差的两路信号进行分析,则会造成较为严重的特征提取偏差和识别误差。因此本方法使用基于互相关函数的方式对实时采集到的信号进行同步处理。对于一个窗口内的蓝牙和喉麦信号,计算其互相关函数的分布,选取互相关系数分布中,与0点最近的极值点对应的采样点,作为蓝牙信号和喉麦信号的偏移采样点数,并将有时延的信号向前平移对应的采样点数,构成同步后的双通道信号。同步方法示意图如图7所示,对于图中的两路信号,其互相关函数在3710采样点达到极值,说明喉麦采集信号落后于蓝牙耳机采集信号3710个采样点。
步骤3:对口腔区域进行系统建模。
为了识别出使用者正在清洁的牙面,本发明使用基于simo系统建模的方法,将口腔的16个区域对应的面部组织视为各自不同的线性时不变系统。由于电动牙刷有稳定旋转的特性,其电机旋转产生的信号可视为系统的输入;该信号在经过某一个特定的传递路径,到达蓝牙和喉麦观测点后,将观测信号作为系统的输出信号,则该路径对应的系统会使信号发生特定的变化,并且对于不同的牙面,其传递路径是不同的。例如刷左侧后牙内表面时,到达两个观测点的信号传递路径分别为牙齿-下颚内部-食道-喉麦左侧麦克风,牙齿-口腔-下颚外部-空气-喉麦右侧麦克风,以及牙齿-右侧口腔-右侧面部-蓝牙耳机麦克风,而刷右侧后牙外表面时,输入信号会经过不同的路径进行传递。由于使用者的面部结构是相对稳定的,通过系统建模得到的特征与统计特征相比有更高的稳定性。当电动牙刷由于电量低导致转速下降,或者由于切换档位导致转动模式发生变化,系统的输入信号会发生变化,这时输出信号的统计特征模式会发生很大的变化,无法用来区分不同的牙面;而输入-输出信号对应的面部结构系统却没有发生变化,此时系统模型的特征对于各个牙面仍然有很好的区分度。
本发明使用以下的方式获取口腔系统模型参数:首先使用在空转事件中采集到的电动牙刷空转声信号,提取出其前k个主要频率成分,估计出输入信号i;然后对于一个采样窗口内的喉麦信号t和蓝牙耳机信号b,计算输入的自功率谱gt和gb;计算输入和两路输出之间的互功率谱git,gib;最后通过hv估计,得到两个输出信号分别对应的频域响应函数(frf)分布,作为口腔系统参数的描述符。不同的口腔位置对应的frf分布之间存在较好的区分度,如图8所示。
步骤4:系统特征抽取及融合。
全部特征集合由三部分构成:输入-喉麦系统的frf分布,输入-蓝牙耳机系统的frf分布,以及原始输出信号的12-ordermfcc特征。在特征集合中添加mfcc特征以增加特征丰富性。在对喉麦和蓝牙耳机分别对应的frf分布进行直方图估计后,融合三部分特征以构成一个采样窗口的完整特征描述符。使用anova方法上述全部特征集合进行方差分析,从而进行特征降维,以满足实时检测的计算需求,最终保留m维特征,其中m值根据在标定数据集上建模和测试的结果进行优选。
步骤5:刷牙行为识别模型构建及实时监测。
对于步骤4中获取到的各口腔位置的特征描述符,对比使用xgboost、svm、randomforest、bagging、naivebayes以及深度神经网络等分类器对上述特征的分类结果,其准确率、召回率以及f1值性能度量如图9所示(图中黑色垂直线表示的是对应直方图的误差棒),最终选择准确率较高,且计算复杂性比深度神经网络低的xgboost模型集成到实时检测应用中。在实时检测用户刷牙行为的过程中,对于每一个采样窗口信号,通过步骤2~4的方法抽取并融合特征,并通过最优分类器对牙面进行分类,对不同牙面错分的混淆矩阵(反应的是检测器对实际值的评估质量和错分类别)如图10所示,可以看出使用本方法后,对各牙面得到了较好的划分效果。得到每个时刻刷洗的牙面后,按照基准刷牙方法对各牙面的清洗时间和覆盖率进行累计,并在应用中针对清洁不到位的牙面,给使用者图形和声音提示。在每次刷牙过程结束后,依据各牙面清洁质量对本次刷牙进行评分反馈,并存储到云服务器,记录使用者的长期牙齿健康数据。
以上详细描述了本发明的优选实施方式,但是本发明并不限于上述实施方式中的具体细节,在本发明的技术构思范围内,可以对本发明的技术方案进行多种等同变换(如数量、形状、位置等),这些等同变换均属于本发明的保护。
- 还没有人留言评论。精彩留言会获得点赞!