元素概率化预测模型的训练方法和元素概率化预测方法
1.本发明涉及人工智能技术领域,更具体地涉及一种元素概率化预测模型的训练方法和元素概率化预测方法。
背景技术:
2.了解行星表面的物质成分,对于研究其行星地质、岩石学甚至天体生物学背景具有重要意义。目前,对于火星等太阳系行星表面的原位探测均依赖遥控探测器,不受控的地外环境、未知的目标性质、有限的载荷质量以及天地通讯延迟等因素,都使得对行星表面物质成分探测的效率与精度都受到了较大限制。
3.为了适应行星原位的表面物质成分探测场景,激光诱导击穿光谱(libs,laser-induce breakdown spectroscopy)仪器已被广泛应用。这类行星libs仪器观测无需额外样品准备,测试快速便捷,能快速获取指定目标点的元素信息。libs光谱属于一种原子发射光谱(aes,atomic emission spectroscopy)技术,其一般通过低能量、短脉冲的高功率激光汇聚于目标表面的微小区域,瞬间气化其中物质并从中激发炽热的等离子体。等离子体产生的辐射被libs配套的光谱仪接收,其中包含了与目标物质成分相关联的多种原子、离子的发射谱线,从而可以为提供目标的元素成分信息。
4.然而,由于实际火星表面物质的复杂性,这些火星libs光谱常受基体效应的影响,即单一元素的谱线特征不仅与自身含量相关,也和其它元素的含量、目标的物理性质等复杂因素相关,为行星libs光谱元素定量带来了困难。因此,以往的应用偏向于使用综合全谱信息的多变量分析手段。例如,偏最小二乘-子模型和独立成分分析组合的主量氧化物含量模型等。但现有方法多数仅关注对于元素含量值本身的估计,而无法给出概率化估计,即对于元素含量的概率分布、不确定度不能给出直接的判断。这使得预测结果缺乏概率化的信息,在应用于地球化学投图时将难以绘制误差棒,在与其它物质成分比较时无法进行更具有说服力的假设检验。
技术实现要素:
5.鉴于上述问题,本发明提供了一种元素概率化预测模型的训练方法和元素概率化预测方法。
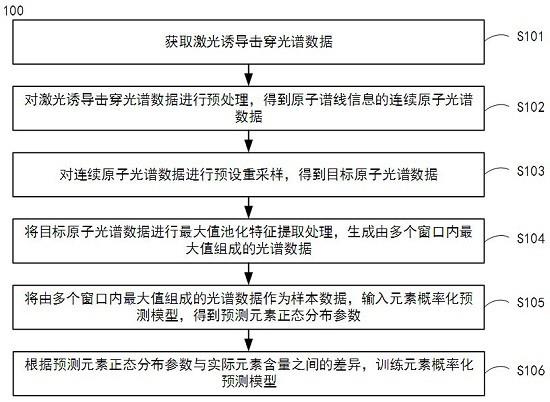
6.根据本发明的第一个方面,提供了一种元素概率化预测模型的训练方法,包括:获取激光诱导击穿光谱数据;对所述激光诱导击穿光谱数据进行预处理,得到原子谱线信息的连续原子光谱数据;对所述连续原子光谱数据进行预设重采样,得到目标原子光谱数据;将所述目标原子光谱数据进行最大值池化特征提取处理,生成由多个窗口内最大值组成的光谱数据;将所述由多个窗口内最大值组成的光谱数据作为样本数据,输入元素概率化预测模型,得到预测元素正态分布参数;以及根据所述预测元素正态分布参数与实际元素含量之间的差异,训练所述元素概率化预测模型。
7.根据本发明的实施例,所述对所述激光诱导击穿光谱数据进行预处理,得到原子
谱线信息的连续原子光谱数据,包括以下操作中的至少一个:扣除光谱仪暗背景处理;转换光谱仪响应值为辐射亮度值处理;转换光谱仪像素位数为波长值处理;去除高斯白噪声处理;去除连续光谱背景信号处理;以及拼接多个光谱通道处理。
8.根据本发明的实施例,所述元素概率化预测模型的训练方法还包括,在所述预处理包括所述去除高斯白噪声处理的情况下:采用带有自适应阈值的带孔小波变换去除高斯白噪声;和/或,在所述预处理包括所述去除连续光谱背景信号处理的情况下:采用非对称最小二乘法去除连续光谱背景信号。
9.根据本发明的实施例,所述元素概率化预测模型的训练方法还包括,在将所述目标原子光谱数据进行最大值池化特征提取处理,生成由多个窗口内最大值组成的光谱数据之前:将最大值池化窗口大小设置为可调变量。
10.根据本发明的实施例,所述根据所述预测元素正态分布参数与实际元素含量之间的差异,训练所述元素概率化预测模型,包括:根据差异,调整待调整的参数,直到所述差异收敛,所述待调整的参数包括回归树的约束策略、学习率、回归树的个数中的一种或多种;其中,所述回归树的约束策略包括限制回归树的最大深度,和/或,限制回归树的树叶节点个数。
11.根据本发明的第二个方面,提供了一种元素概率化预测方法,包括:元素概率化预测方法,包括:将目标光谱数据输入元素概率化预测模型,得到与所述目标光谱数据对应的元素正态分布参数;以及根据所述元素正态分布参数,确定元素含量的点估计值和不确定度;其中,所述元素概率化预测模型是根据本发明提供的方法训练的。
12.本发明的第三方面提供了一种元素概率化预测模型的训练装置,包括:获取模块,用于获取激光诱导击穿光谱数据;预处理模块,用于对所述激光诱导击穿光谱数据进行预处理,得到原子谱线信息的连续原子光谱数据;重采样模块,用于对所述连续原子光谱数据进行预设重采样,得到目标原子光谱数据;提取模块,用于将所述目标原子光谱数据进行最大值池化特征提取处理,生成由多个窗口内最大值组成的光谱数据;第一预测模块,用于将所述由多个窗口内最大值组成的光谱数据作为样本数据,输入元素概率化预测模型,得到预测元素正态分布参数;以及训练模块,用于根据所述预测元素正态分布参数与实际元素含量之间的差异,训练所述元素概率化预测模型。
13.本发明的第四方面提供了一种元素概率化预测装置,包括:第二预测模块,用于将目标光谱数据输入元素概率化预测模型,得到与所述目标光谱数据对应的元素正态分布参数;以及确定模块,用于根据所述元素正态分布参数,确定元素含量的点估计值和不确定度;其中,所述元素概率化预测模型是根据本发明提供的装置训练的。
14.本发明的第五方面提供了一种电子设备,包括:一个或多个处理器;存储器,用于存储一个或多个程序,其中,当所述一个或多个程序被所述一个或多个处理器执行时,使得一个或多个处理器执行上述公开的方法。
15.本发明的第六方面还提供了一种计算机可读存储介质,其上存储有可执行指令,该指令被处理器执行时使处理器执行上述公开的方法。
附图说明
16.通过以下参照附图对本发明实施例的描述,本发明的上述内容以及其他目的、特
征和优点将更为清楚,在附图中:图1示意性示出了根据本发明实施例的元素概率化预测模型的训练方法的流程图;图2示意性示出了根据本发明实施例的元素概率化预测方法的流程图;图3示意性示出了根据本发明实施例的适用于火星表面成分探测仪的主量元素概率化定量反演方法的流程示意图;图4示意性示出了根据本发明实施例的元素概率化预测模型的训练装置的结构框图;图5示意性示出了根据本发明实施例的元素概率化预测装置的结构框图;以及图6示意性示出了根据本发明实施例的适于实现元素概率化预测模型的训练方法和/或元素概率化预测方法的电子设备的方框图。
具体实施方式
17.以下,将参照附图来描述本发明的实施例。但是应该理解,这些描述只是示例性的,而并非要限制本发明的范围。在下面的详细描述中,为便于解释,阐述了许多具体的细节以提供对本发明实施例的全面理解。然而,明显地,一个或多个实施例在没有这些具体细节的情况下也可以被实施。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本发明的概念。
18.在此使用的术语仅仅是为了描述具体实施例,而并非意在限制本发明。在此使用的术语“包括”、“包含”等表明了所述特征、步骤、操作和/或部件的存在,但是并不排除存在或添加一个或多个其他特征、步骤、操作或部件。
19.在此使用的所有术语(包括技术和科学术语)具有本领域技术人员通常所理解的含义,除非另外定义。应注意,这里使用的术语应解释为具有与本说明书的上下文相一致的含义,而不应以理想化或过于刻板的方式来解释。
20.在使用类似于“a、b和c等中至少一个”这样的表述的情况下,一般来说应该按照本领域技术人员通常理解该表述的含义来予以解释(例如,“具有a、b和c中至少一个的系统”应包括但不限于单独具有a、单独具有b、单独具有c、具有a和b、具有a和c、具有b和c、和/或具有a、b、c的系统等)。
21.本发明的实施例提供了一种元素概率化预测模型的训练方法,获取激光诱导击穿光谱数据;对激光诱导击穿光谱数据进行预处理,得到原子谱线信息的连续原子光谱数据;对连续原子光谱数据进行预设重采样,得到目标原子光谱数据;将目标原子光谱数据进行最大值池化特征提取处理,生成由多个窗口内最大值组成的光谱数据;将由多个窗口内最大值组成的光谱数据作为样本数据,输入元素概率化预测模型,得到预测元素正态分布参数;以及根据预测元素正态分布参数与实际元素含量之间的差异,训练元素概率化预测模型。
22.通过图1对公开实施例的元素概率化预测模型的训练方法进行详细描述。
23.图1示意性示出了根据本发明实施例的元素概率化预测模型的训练方法100的流程图。
24.如图1所示,该实施例包括操作s101~操作s106。
25.在操作s101,获取激光诱导击穿光谱数据。
26.例如,利用火星表面成分探测仪libs的正样或其它具有近似仪器状态的鉴定件、复制件等,收集地面样品库在对应火星模拟环境下、不同探测距离的libs光谱(即激光诱导击穿光谱数据),作为地面光谱库,并划分出训练集和验证集。
27.进一步地,地面样品库可以根据火星探测地区的地质背景,选择成分经其它精确分析化学手段(例如x射线荧光、质谱仪、原子发射光谱等)准确表征的地球岩石、标准物质、模拟物质。行星模拟环境需与实际探测火星大气拥有相同的成分与接近的气压(700 pa,95.7% co2、2.7% n2、1.6% ar),以保证libs等离子体演化的方式相似。优选的,在地面光谱库中,训练集、验证集的比例可以大于6:1。
28.在操作s102,对激光诱导击穿光谱数据进行预处理,得到原子谱线信息的连续原子光谱数据。
29.可以理解的,通过对激光诱导击穿光谱数据进行预处理,可以得到仅包含原子谱线信息的连续原子光谱数据。
30.在操作s103,对连续原子光谱数据进行预设重采样,得到目标原子光谱数据。
31.可以理解的,通过对连续原子光谱数据进行预设重采样,可以得到规范化的原子光谱,即目标原子光谱数据。
32.例如,重采样可以使得所有光谱数据的采样波长位置一致,且重采样后光谱分辨率可以与光谱仪最高分辨率一致。
33.在操作s104,将目标原子光谱数据进行最大值池化特征提取处理,生成由多个窗口内最大值组成的光谱数据。
34.可以理解的,对目标原子光谱数据进行最大值池化(max-pooling)特征提取。如在每个光谱数据上从起始开等宽、相邻不重叠的窗口(其中,若最后一个窗口若超出光谱范围,则超出部分的强度可以记为0),提取窗口中数据的最大值,生成由每个窗口内最大值组成的新光谱数据,即由多个窗口内最大值组成的光谱数据。优选的,可以对这一新光谱数据(即由多个窗口内最大值组成的光谱数据)除以其平均值进行归一化。
35.在操作s105,将由多个窗口内最大值组成的光谱数据作为样本数据,输入元素概率化预测模型,得到预测元素正态分布参数。
36.可以理解的,将由多个窗口内最大值组成的光谱数据作为输入数据,输入元素概率化预测模型,可以得到预测元素正态分布参数。通过该预测元素正态分布参数,可以从中读出目标元素含量的点估计值和不确定度。
37.在操作s106,根据预测元素正态分布参数与实际元素含量之间的差异,训练元素概率化预测模型。
38.可以理解的,实际元素含量即元素概率化预测模型的标签。在训练的过程中可以使用地面实验数据,这些数据对应的样品有经其它化学分析方法表征的标准成分,该标准成分作为训练时的数据标签,即实际元素含量。
39.可以理解的,在本实施例中比较了预测正态分布参数与实际元素含量的关系,不需要输入实际元素含量的分布情况(即默认了实际元素含量的不确定度可以忽略不计)。这一差异可以通过负对数相似度(即nll,negative log-likelihood)的方式定量的。
40.可以针对主量元素(如ca,mg,al,si,fe,na,k,ti)的含量,利用本实施例提供的元
素概率化预测模型的训练方法,分别训练与各个主量元素对应的元素概率化预测模型。
41.其中,每个元素对应的元素概率化预测模型可以采用回归树作为基学习器,假设这些元素的含量满足正态分布,使用负对数相似度(nll,negative log-likelihood)作为损失函数。元素概率化预测模型均有一个或多个可调超参数(即待调整参数):如回归树的约束策略、学习率、回归树的个数。待调整参数还可以包括最大值池化窗口大小。
42.本实施例的目的在于为了克服当前火星libs探测中有关概率化预测的不足,针对当前火星探测所搭载的libs仪器——火星表面成分探测仪,提供一种元素概率化预测模型。再利用该元素概率化预测模型,进行元素概率化预测,即提供基于自然梯度提升(ngboost)概率化估计,辅以适当的数据预处理,对火星环境下libs数据情况具有适应性的主量元素概率化定量解决方案。元素概率化预测方法能够在给出指定元素含量的同时,也给出了该含量的预测的不确定度情况,以方便科研人员在后续研究和应用中得到可靠和有效的使用数据。
43.本实施例提供的元素概率化预测模型的训练方法,可以提供一种元素概率化预测模型,适用于火星表面成分探测仪的主量元素概率化反演。通过该元素概率化预测模型进行预测可以得到概率化估计,即得到预测元素正态分布参数。
44.对激光诱导击穿光谱数据进行预处理,得到原子谱线信息的连续原子光谱数据,包括以下操作中的至少一个:扣除光谱仪暗背景处理;转换光谱仪响应值为辐射亮度值处理;转换光谱仪像素位数为波长值处理;去除高斯白噪声处理;去除连续光谱背景信号处理;以及拼接多个光谱通道处理。
45.可以理解的,对激光诱导击穿光谱数据进行预处理,该预处理可以包括:扣除光谱仪暗背景、转换光谱仪响应值为辐射亮度值、转换光谱仪像素位数为波长值、去除数据中的高斯白噪声、去除数据中的连续谱背景信号以及拼接各光谱通道中的一种或多种。
46.本实施例提供的元素概率化预测模型的训练方法,有利于得到仅包含原子谱线信息的连续原子光谱数据。
47.元素概率化预测模型的训练方法还包括,在预处理包括去除高斯白噪声处理的情况下:采用带有自适应阈值的带孔小波变换去除高斯白噪声;和/或,在预处理包括去除连续光谱背景信号处理的情况下:采用非对称最小二乘法去除连续光谱背景信号。
48.可以理解的,去除数据中的高斯白噪声要求对数据信息损失最少,以白噪声去除前后数据间的交叉熵判定,采用带有自适应阈值的带孔小波变换(wavelet transform
ꢀàꢀ
trous)滤波具有良好效果。
49.可以理解的,去除数据中的连续谱背景信号时,要求连续击打同一目标的libs光谱在去除连续谱背景信号后,数据间信息损失减少,同样使用交叉熵判定,采用非对称最小二乘法具有良好效果。
50.本实施例提供的元素概率化预测模型的训练方法,采用带有自适应阈值的带孔小波变换(wavelet transform
ꢀàꢀ
trous)滤波具有良好的去除高斯白噪声效果。
51.本实施例提供的元素概率化预测模型的训练方法,采用非对称最小二乘法具有良好的去除连续光谱背景信号效果。
52.元素概率化预测模型的训练方法还包括,在将目标原子光谱数据进行最大值池化特征提取处理,生成由多个窗口内最大值组成的光谱数据之前:将最大值池化窗口大小设
置为可调变量。
53.可以理解的,将最大值池化窗口大小设置为可调变量,可以将可调范围最小值设置为大于光谱仪最劣的半高全宽分辨率。
54.最大值池化窗口大小可以与元素概率化预测模型的待调整参数一同优化调整。从而在行星探测未知、不易受控的环境下,libs光谱仪常因温度变化而产生波长漂移,这一最大值池化特征提取可以提高对于这类不稳定性的适应性。
55.本实施例提供的元素概率化预测模型的训练方法,可以提高该元素概率化预测模型的适应性。
56.根据预测元素正态分布参数与实际元素含量之间的差异,训练元素概率化预测模型,包括:根据差异,调整待调整的参数,直到差异收敛,待调整的参数包括回归树的约束策略、学习率、回归树的个数中的一种或多种;其中,回归树的约束策略包括限制回归树的最大深度,和/或,限制回归树的树叶节点个数。
57.可以理解的,元素概率化预测模型均有一个或多个可调超参数(即待调整参数):如回归树的约束策略、学习率、回归树的个数。
58.可以理解的,回归树约束策略可以包括限制回归树最大深度或限制回归树叶节点个数。该待调整的参数可以通过模型(元素概率化预测模型)在验证集上的点估计误差(也即元素含量正态分布平均值与真实值的均方根误差)进行优化训练。
59.本实施例提供的元素概率化预测模型的训练方法,。
60.通过图2对公开实施例的元素概率化预测方法进行详细描述。
61.图2示意性示出了根据本发明实施例的元素概率化预测方法的流程图。
62.如图2所示,该实施例包括操作s201~操作s202。
63.在操作s201,将目标光谱数据输入元素概率化预测模型,得到与目标光谱数据对应的元素正态分布参数。
64.在操作s202,根据元素正态分布参数,确定元素含量的点估计值和不确定度。
65.例如,元素概率化预测模型是根据本发明提供的方法训练的。
66.例如,元素概率化预测模型是根据本发明提供的方法100训练的。
67.可以理解,如对火星表面获取实际libs探测数据,即在轨探测数据。该在轨探测数据经过如预处理、预设重采样处理以及最大值池化特征提取处理等得到目标光谱数据。
68.将目标光谱数据输入元素概率化预测模型,可以得到与目标光谱数据对应的元素正态分布参数(平均值和标准差);然后通过元素正态分布参数,可以确定元素含量的点估计值(平均值)以及不确定度(标准差),从而可以用于概率化地描述火星表面目标的元素成分。
69.本实施例提供的元素概率化预测方法,可以对目标光谱数据的元素正态分布参数进行预测,通过元素正态分布参数,可以确定元素含量的点估计值(平均值)以及不确定度(标准差),从而可以用于概率化地描述火星表面目标的元素成分。
70.为了更好的理解本发明,下面结合实施例进一步阐述本发明的内容,但本发明不仅仅局限于下面实施例。
71.图3示意性示出了根据本发明实施例的适用于火星表面成分探测仪的主量元素概率化定量反演方法的流程示意图。参见图3,举例来说。
72.举例来说,该适用于火星表面成分探测仪的主量元素概率化定量反演方法,可以包括以下步骤:步骤31,在地面光谱库中获取激光诱导击穿光谱数据,如利用火星表面成分探测仪的libs设备,收集在对应火星模拟环境下的libs光谱,作为地面光谱库,并划分出训练集和验证集。
73.步骤32,libs数据预处理,即对激光诱导击穿光谱数据进行预处理,如去除非原子发射的光谱信号。
74.步骤33,libs数据规范化,如对连续原子光谱进行重采样,得到规范化的原子光谱,即目标原子光谱数据。
75.步骤34,最大值池化特征提取,即对目标原子光谱数据进行最大值池化(max-pooling)特征提取;步骤35,训练元素概率化预测模型,如针对主量元素(ca, mg, al, si, fe, na, k, ti)的含量,利用已经过步骤32-34处理的训练集、验证集数据及其对应地面样品库的元素真实含量,分别训练各个主量元素的元素概率化预测模型;步骤36,实际火星目标主量元素概率化预测,如对火星表面获取的实际libs探测数据,经如步骤32-34处理,利用步骤35训练出的多个元素概率化预测模型进行目标元素(即主量元素)的概率化预测,得到目标元素概率化预测结果,如表1所示。
76.表1 目标元素概率化预测结果可以看出,从对成分已知在轨定标样品的预测中,本实施例的适用性在实际火星环境下可以得到验证。本实施例给出的元素含量正态分布预测包含了较为精准的点估计值(对应正态分布的平均值),而点估计值的误差也在1~2倍预测不确定度(对应正态分布的标准差)范围之内。
77.图4示意性示出了根据本发明实施例的元素概率化预测模型的训练装置的结构框图。
78.如图4所示,该实施例的元素概率化预测模型的训练装置400包括获取模块410、预处理模块420、重采样模块430、提取模块440、第一预测模块450和训练模块460。
79.获取模块410,用于获取激光诱导击穿光谱数据;预处理模块420,用于对所述激光
诱导击穿光谱数据进行预处理,得到原子谱线信息的连续原子光谱数据;重采样模块430,用于对所述连续原子光谱数据进行预设重采样,得到目标原子光谱数据;提取模块440,用于将所述目标原子光谱数据进行最大值池化特征提取处理,生成由多个窗口内最大值组成的光谱数据;第一预测模块450,用于将所述由多个窗口内最大值组成的光谱数据作为样本数据,输入元素概率化预测模型,得到预测元素正态分布参数;以及训练模块460,用于根据所述预测元素正态分布参数与实际元素含量之间的差异,训练所述元素概率化预测模型。
80.在一些实施例中,所述预处理模块,用于执行以下操作中的至少一个:扣除光谱仪暗背景处理;转换光谱仪响应值为辐射亮度值处理;转换光谱仪像素位数为波长值处理;去除高斯白噪声处理;去除连续光谱背景信号处理;以及拼接多个光谱通道处理。
81.在一些实施例中,所述装置还用于,在所述预处理包括所述去除高斯白噪声处理的情况下:采用带有自适应阈值的带孔小波变换去除高斯白噪声;和/或,在所述预处理包括所述去除连续光谱背景信号处理的情况下:采用非对称最小二乘法去除连续光谱背景信号。
82.在一些实施例中,所述装置还包括,设置模块,用于在将所述目标原子光谱数据进行最大值池化特征提取处理,生成由多个窗口内最大值组成的光谱数据之前:将最大值池化窗口大小设置为可调变量。
83.在一些实施例中,所述训练模块,用于根据差异,调整待调整的参数,直到所述差异收敛,所述待调整的参数包括回归树的约束策略、学习率、回归树的个数中的一种或多种;其中,所述回归树的约束策略包括限制回归树的最大深度,和/或,限制回归树的树叶节点个数。
84.根据本发明的实施例,获取模块410、预处理模块420、重采样模块430、提取模块440、第一预测模块450和训练模块460中的任意多个模块可以合并在一个模块中实现,或者其中的任意一个模块可以被拆分成多个模块。或者,这些模块中的一个或多个模块的至少部分功能可以与其他模块的至少部分功能相结合,并在一个模块中实现。根据本发明的实施例,获取模块410、预处理模块420、重采样模块430、提取模块440、第一预测模块450和训练模块460中的至少一个可以至少被部分地实现为硬件电路,例如现场可编程门阵列(fpga)、可编程逻辑阵列(pla)、片上系统、基板上的系统、封装上的系统、专用集成电路(asic),或可以通过对电路进行集成或封装的任何其他的合理方式等硬件或固件来实现,或以软件、硬件以及固件三种实现方式中任意一种或以其中任意几种的适当组合来实现。或者,获取模块410、预处理模块420、重采样模块430、提取模块440、第一预测模块450和训练模块460中的至少一个可以至少被部分地实现为计算机程序模块,当该计算机程序模块被运行时,可以执行相应的功能。
85.图5示意性示出了根据本发明实施例的元素概率化预测装置的结构框图。
86.如图5所示,该实施例的元素概率化预测装置500包括第二预测模块510和确定模块520。
87.第二预测模块510,用于将目标光谱数据输入元素概率化预测模型,得到与所述目标光谱数据对应的元素正态分布参数;以及确定模块520,用于根据所述元素正态分布参数,确定元素含量的点估计值和不确定度。
88.例如,所述元素概率化预测模型是根据本发明提供的装置训练的。
89.根据本发明的实施例,第二预测模块510和确定模块520中的任意多个模块可以合并在一个模块中实现,或者其中的任意一个模块可以被拆分成多个模块。或者,这些模块中的一个或多个模块的至少部分功能可以与其他模块的至少部分功能相结合,并在一个模块中实现。根据本发明的实施例,第二预测模块510和确定模块520中的至少一个可以至少被部分地实现为硬件电路,例如现场可编程门阵列(fpga)、可编程逻辑阵列(pla)、片上系统、基板上的系统、封装上的系统、专用集成电路(asic),或可以通过对电路进行集成或封装的任何其他的合理方式等硬件或固件来实现,或以软件、硬件以及固件三种实现方式中任意一种或以其中任意几种的适当组合来实现。或者,第二预测模块510和确定模块520中的至少一个可以至少被部分地实现为计算机程序模块,当该计算机程序模块被运行时,可以执行相应的功能。
90.图6示意性示出了根据本发明实施例的适于实现元素概率化预测模型的训练方法和/或元素概率化预测方法的电子设备的方框图。
91.如图6所示,根据本发明实施例的电子设备600包括处理器601,其可以根据存储在只读存储器(rom)602中的程序或者从存储部分608加载到随机访问存储器(ram)603中的程序而执行各种适当的动作和处理。处理器601例如可以包括通用微处理器(例如cpu)、指令集处理器和/或相关芯片组和/或专用微处理器(例如,专用集成电路(asic))等等。处理器601还可以包括用于缓存用途的板载存储器。处理器601可以包括用于执行根据本发明实施例的方法流程的不同动作的单一处理单元或者是多个处理单元。
92.在ram 603中,存储有电子设备600操作所需的各种程序和数据。处理器 601、rom602以及ram 603通过总线604彼此相连。处理器601通过执行rom 602和/或ram 603中的程序来执行根据本发明实施例的方法流程的各种操作。需要注意,所述程序也可以存储在除rom 602和ram 603以外的一个或多个存储器中。处理器601也可以通过执行存储在所述一个或多个存储器中的程序来执行根据本发明实施例的方法流程的各种操作。
93.根据本发明的实施例,电子设备600还可以包括输入/输出(i/o)接口605,输入/输出(i/o)接口605也连接至总线604。电子设备600还可以包括连接至i/o接口605的以下部件中的一项或多项:包括键盘、鼠标等的输入部分606;包括诸如阴极射线管(crt)、液晶显示器(lcd)等以及扬声器等的输出部分607;包括硬盘等的存储部分608;以及包括诸如lan卡、调制解调器等的网络接口卡的通信部分609。通信部分609经由诸如因特网的网络执行通信处理。驱动器610也根据需要连接至i/o接口605。可拆卸介质611,诸如磁盘、光盘、磁光盘、半导体存储器等等,根据需要安装在驱动器610上,以便于从其上读出的计算机程序根据需要被安装入存储部分608。
94.本发明还提供了一种计算机可读存储介质,该计算机可读存储介质可以是上述实施例中描述的设备/装置/系统中所包含的;也可以是单独存在,而未装配入该设备/装置/系统中。上述计算机可读存储介质承载有一个或者多个程序,当上述一个或者多个程序被执行时,实现根据本发明实施例的方法。
95.根据本发明的实施例,计算机可读存储介质可以是非易失性的计算机可读存储介质,例如可以包括但不限于:便携式计算机磁盘、硬盘、随机访问存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、便携式紧凑磁盘只读存储器(cd-rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。在本发明中,计算机可读存储介质可
以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。例如,根据本发明的实施例,计算机可读存储介质可以包括上文描述的rom 602和/或ram 603和/或rom 602和ram 603以外的一个或多个存储器。
96.本发明的实施例还包括一种计算机程序产品,其包括计算机程序,该计算机程序包含用于执行流程图所示的方法的程序代码。当计算机程序产品在计算机系统中运行时,该程序代码用于使计算机系统实现本发明实施例所提供的元素概率化预测模型的训练方法和/或元素概率化预测方法。
97.在该计算机程序被处理器601执行时执行本发明实施例的系统/装置中限定的上述功能。根据本发明的实施例,上文描述的系统、装置、模块、单元等可以通过计算机程序模块来实现。
98.在一种实施例中,该计算机程序可以依托于光存储器件、磁存储器件等有形存储介质。在另一种实施例中,该计算机程序也可以在网络介质上以信号的形式进行传输、分发,并通过通信部分609被下载和安装,和/或从可拆卸介质611被安装。该计算机程序包含的程序代码可以用任何适当的网络介质传输,包括但不限于:无线、有线等等,或者上述的任意合适的组合。
99.在这样的实施例中,该计算机程序可以通过通信部分609从网络上被下载和安装,和/或从可拆卸介质611被安装。在该计算机程序被处理器601执行时,执行本发明实施例的系统中限定的上述功能。根据本发明的实施例,上文描述的系统、设备、装置、模块、单元等可以通过计算机程序模块来实现。
100.根据本发明的实施例,可以以一种或多种程序设计语言的任意组合来编写用于执行本发明实施例提供的计算机程序的程序代码,具体地,可以利用高级过程和/或面向对象的编程语言、和/或汇编/机器语言来实施这些计算程序。程序设计语言包括但不限于诸如java,c++,python,“c”语言或类似的程序设计语言。程序代码可以完全地在用户计算设备上执行、部分地在用户设备上执行、部分在远程计算设备上执行、或者完全在远程计算设备或服务器上执行。在涉及远程计算设备的情形中,远程计算设备可以通过任意种类的网络,包括局域网(lan)或广域网(wan),连接到用户计算设备,或者,可以连接到外部计算设备(例如利用因特网服务提供商来通过因特网连接)。
101.附图中的流程图和框图,图示了按照本发明各种实施例的系统、方法和计算机程序产品的可能实现的体系架构、功能和操作。在这点上,流程图或框图中的每个方框可以代表一个模块、程序段、或代码的一部分,上述模块、程序段、或代码的一部分包含一个或多个用于实现规定的逻辑功能的可执行指令。也应当注意,在有些作为替换的实现中,方框中所标注的功能也可以以不同于附图中所标注的顺序发生。例如,两个接连地表示的方框实际上可以基本并行地执行,它们有时也可以按相反的顺序执行,这依所涉及的功能而定。也要注意的是,框图或流程图中的每个方框、以及框图或流程图中的方框的组合,可以用执行规定的功能或操作的专用的基于硬件的系统来实现,或者可以用专用硬件与计算机指令的组合来实现。
102.本领域技术人员可以理解,本发明的各个实施例和/或权利要求中记载的特征可以进行多种组合和/或结合,即使这样的组合或结合没有明确记载于本发明中。特别地,在不脱离本发明精神和教导的情况下,本发明的各个实施例和/或权利要求中记载的特征可
以进行多种组合和/或结合。所有这些组合和/或结合均落入本发明的范围。
103.以上对本发明的实施例进行了描述。但是,这些实施例仅仅是为了说明的目的,而并非为了限制本发明的范围。尽管在以上分别描述了各实施例,但是这并不意味着各个实施例中的措施不能有利地结合使用。本发明的范围由所附权利要求及其等同物限定。不脱离本发明的范围,本领域技术人员可以做出多种替代和修改,这些替代和修改都应落在本发明的范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1