基于机器学习辅助的卡尔曼滤波金属粉尘浓度检测方法
本发明涉及一种改进后的金属粉尘浓度检测技术,具体为基于机器学习卡尔曼滤波算法的静电感应检测金属粉尘浓度技术,属于粉尘浓度检测和粉尘防爆。
背景技术:
1、金属粉尘,作为一种工业原料,在工厂生产中十分重要,被广泛运用于材料、建筑、化工、航空航天等各个领域。然而在制造,生产,储存和运输的过程中,往往伴随着金属粉尘飘散到空气中的情况,对作业场所的生命财产安全造成巨大威胁。在金属制品加工过程中,诸如抛光、打磨、焊接和切割等工艺操作很容易产生电弧、高温以及火花。一旦这些点火因素遇到了散布在空气中的可燃悬浮粉尘云,就有可能引发灾难性的爆炸,对场地设备,周边环境,以及工作人员的生命健康造成毁灭性的打击。因此,对金属制品生产作业场所的粉尘浓度进行实时监测显得尤为必要,以避免因金属粉尘爆炸而造成的损失。
2、目前,工业领域主要采用粉尘浓度传感器来实时检测生产性金属粉尘浓度,这种设备主要采用两种技术,分别是光散射技术和静电感应法检测技术。光散射技术通过颗粒散射强度分析,来实现粉尘浓度的实时检测。然而,光散射技术的检测单元容易受到环境中的粉尘污染,导致气路阻塞,需要频繁进行维护,难以实现长时间准确检测。因此,光学粉尘浓度传感器通常用于低浓度的粉尘检测。第二种方法采用基于静电感应法的新型粉尘浓度检测技术。该技术具有无源信号为主、测量范围宽、适应性强、经久耐用等优点。与传统技术相比,该方法的检测单元不会受到粘结粉尘的影响,因此不需要频繁进行维护。
3、目前,静电检测电极的主要应用场景是固定的金属管道。通常采用管道作为屏蔽体,可有效保证静电检测电极不受外界静电干扰,提高检测效果的准确性和可靠性。然而,实验环境的开敞性使得粉尘浓度的变化范围较大,并且容易受到多种电磁干扰。这些因素会对基于静电感应的粉尘浓度检测技术产生影响,导致感应信号不稳定,从而影响检测结果的稳定性和准确性。特别是在环境中的粉尘流量不稳定、粉尘浓度变化大以及周围的电磁干扰因素丰富的情况下,由于统计感应信号的标准偏差反映粉尘浓度大小,随着粉尘浓度的增加,感应信号的波动性逐步增加。随着粉尘颗粒流场的扰动或是外界的干扰等不明因素,容易造成感应信号的意外变化,对静电感应法粉尘浓度的检测结果造成较大误差。
4、传统卡尔曼滤波算法可以通过预测误差和测量误差的权重,将预测结果优化到真实值附近,但仍有一定缺陷。当测量误差比较大时,卡尔曼滤波算法的预测结果比较接近于上一次的预测结果;反之,当预测误差比较大时,预测结果比较接近测量结果。在应用过程中,卡尔曼滤波的缺点在于:其仅能对线性过程的过程模型和测量模型进行精确估计,在非线性的场景中并不能达到最优的估计效果。
技术实现思路
1、针对现有技术中金属粉尘测量技术存在高浓度不适用、易受电磁干扰、速度慢与噪声等问题,本发明的目的之一是提供基于机器学习卡尔曼滤波算法的静电感应检测金属粉尘浓度技术,以减小开敞空间内金属粉尘浓度测量中出现的波动偏差,提高测量精度。
2、因此为了简化计算和节省计算量,基于由机器学习辅助的卡尔曼滤波金属粉尘浓度检测算法进行感应信号的波动参数提取,通过大量实验获取的数据对模型进行训练,使得模型能够通过已经采集到的数据对总体标准偏差平均值进行预测。当测量信号在真实值附近波动时,模型会快速收敛到真实值附近,由此得到最优估计值。
3、本发明采用的技术方案为:一种由机器学习辅助的卡尔曼滤波金属粉尘浓度检测方法,根据已有粉尘感应出的电压信号标准偏差进行训练,实现对不同浓度粉尘感应出电压信号标准偏差均值的预测;具体包括以下步骤:
4、s1. 数据集构建
5、对不同浓度的金属粉尘进行多次测量,使用横河示波器获取不同浓度的金属粉尘感应出的电压信号,保存并记录;进行电压信号预处理,求取时间窗口内所有电压信号的标准偏差,获取剩余采样窗口的标准偏差连续变化值,用于构建标记数据集;
6、
7、其中,表示该窗口内电压信号标准偏差,表示窗口顺序,是时间窗口内的采样数,是第窗口内第采样点的电压信号,是第窗口内的平均电压信号;
8、进行数据集划分,随机挑选不同浓度组数的金属粉尘电压信号,对于每一个单独的测量过程,通过将窗口序号与该窗口内的电压信号标准偏差变化数据归一化组合,合并形成二维向量作为训练样本,并计算出该测量过程的标准偏差总体均值作为样本标签;
9、s2.构建神经网络
10、构建由输入层、两个隐藏层和输出层所组成的网络模型,设置初始权重和偏置值参数,隐藏层由gru单元构成,表示为:
11、
12、其中:每个隐藏层的输出为,权重为,偏置为;初始权重和偏置参数使用随机初始化,即;隐藏层节点使用sigmoid激活函数,并初始化隐藏状态,其公式如下:
13、
14、其中,,是自然对数的底, 表示sigmoid函数的导数;
15、s3.训练模型
16、将构建好的数据集传入网络模型中,采用随机梯度下降法进行训练,通过梯度的反向传播更新模型参数,其公式为:
17、
18、其中,是学习率,是损失函数对的偏导数;
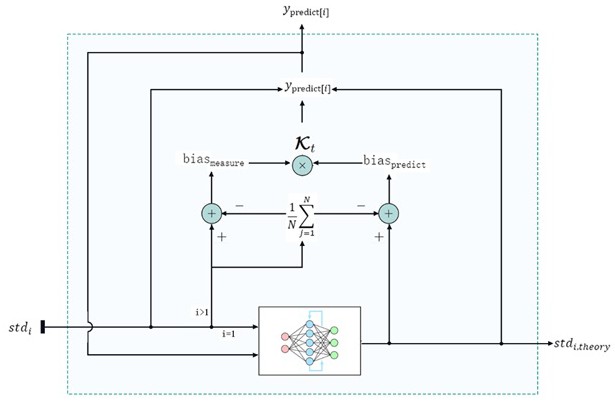
19、训练目标值表示为,将输出值与目标值交叉熵损失函数设为最优化目标,其公式为:
20、
21、其中:是实际标签的独热编码形式,是模型的预测输出,表示每个类别的预测概率,是类别的总数;
22、训练数据集导入模型通过迭代,优化网络模型参数,使得损失函数趋向于最小值,使其能够有效预测下一时刻实际浓度对应标准偏差值:
23、
24、其中:为下一时刻标准偏差理论预测值,为网络模型预测,为模型权重,为模型输入,为模型偏置。
25、当损失函数不再随训练轮次增加而减小模型训练结束;
26、s4.卡尔曼耦合
27、构建基于机器学习的卡尔曼滤波算法,设定初始值:
28、<msub><mi>y</mi><mi>predict[0]</mi></msub><mi>=</mi><msub><mi>x</mi><mi>measure[0,1]</mi></msub>
29、其中:<msub><mi>y</mi><mrow><mi>predict</mi><mi>[0]</mi></mrow></msub>表示初始化的预测结果数组的第一个元素,<msub><mi>x</mi><mrow><mi>measure</mi><mi>[0,1]</mi></mrow></msub>表示第一个窗口的标准偏差值;
30、用上一时刻的预测值和真实值继续预测:
31、<mi>temp</mi><mi>=</mi><mi>predict</mi><mi>(</mi><msub><mi>t</mi><mi>prev</mi></msub><mi>,</mi><msub><mi>y</mi><mrow><mi>predict</mi><mi>[i-1]</mi></mrow></msub><mi>)</mi>
32、其中:表示神经网络模型的输出预测值,表示上一时刻对应的时间值,<msub><mi>y</mi><mrow><mi>predict</mi><mi>[</mi><mi>i</mi><mi>-1]</mi></mrow></msub>表示上一时刻的预测值,表示网络模型预测所进行的处理;
33、用当前预测值减去当前采样数据的标准偏差总体均值,结合测量值与标准偏差总体均值差,经过指数化处理偏置值,使卡尔曼增益系数始终处于零到一之间:
34、
35、<msub><mi>bias</mi><mi>measure</mi></msub><mi>=exp(</mi><msub><mi>x</mi><mrow><mi>measure</mi><mi>[</mi><mi>i</mi><mi>,1]</mi></mrow></msub><mi>-</mi><msub><mover><mi>x</mi><mo stretchy="true">¯</mo></mover><mrow><mi>measure</mi><mi>,1:</mi><mi>i</mi></mrow></msub><mi>)</mi>
36、其中,表示神经网络模型的输出预测值,表示截至时刻的所有窗口标准偏差累积均值,<msub><mi>x</mi><mrow><mi>measure</mi><mi>[</mi><mi>i</mi><mi>,1]</mi></mrow></msub>表示时刻的标准偏差值,表示神经网络输出的偏置值,表示实际测量值的偏置值,其作用是结合神经网络的输出和卡尔曼滤波算法对标准偏差均值进行预测:
37、<msub><mi>y</mi><mrow><mi>predict[</mi><mi>i</mi><mi>]</mi></mrow></msub><mi>=</mi><mfrac><mrow><msub><mi>x</mi><mrow><mi>measure[</mi><mi>i</mi><mi>,1]</mi></mrow></msub><mi>⋅</mi><msub><mi>bias</mi><mi>predict</mi></msub></mrow><mrow><msub><mi>bias</mi><mi>predict</mi></msub><mi>+</mi><msub><mi>bias</mi><mi>measure</mi></msub></mrow></mfrac><mi>+</mi><mfrac><mrow><mi>temp⋅</mi><msub><mi>bias</mi><mi>measure</mi></msub></mrow><mrow><msub><mi>bias</mi><mi>predict</mi></msub><mi>+</mi><msub><mi>bias</mi><mi>measure</mi></msub></mrow></mfrac>
38、其中:<msub><mi>y</mi><mrow><mi>predict</mi><mi>[</mi><mi>i</mi><mi>]</mi></mrow></msub>表示时刻的预测值;
39、通过卡尔曼增益系数的修正,计算出当前状态的真实值,继续作为下一时刻预测值的输入,从而获取真实状态的预测曲线,以构建机器学习辅助的卡尔曼滤波算法;
40、更新当前时刻为下一时刻值,获取采样数据,重复上述过程,直到采样结束。
41、本发明相对于现有技术的有益效果:本发明选择基于卡尔曼滤波辅助的机器学习算法来处理,对感应信号数据的标准差进行二次处理,消除感应信号的标准偏差波动性。将其应用于静电感应传感器中,能够让检测信号的标准差波动在短时间内消除,使得处理后的标准偏差曲线能够快速收敛至目标值,提高了感应信号标准偏差值的稳定性。
42、该方法利用预测误差和测量误差的权重,将系统的预测结果逐步优化,不仅能够实现较高浓度的金属粉尘浓度检测,也表现出灵敏度高、抗干扰能力强等优点,能够快速、准确地检测金属粉尘浓度。
43、上述概述仅仅是为了说明书的目的,并不意图以任何方式进行限制。除上述描述的示意性的方面、实施方式和特征之外,通过参考附图和以下的详细描述,本发明进一步的方面、实施方式和特征将会是容易明白的。
- 还没有人留言评论。精彩留言会获得点赞!