基于动态运动基元学习模型的移动机器人路径规划方法与流程
本发明涉及移动机器人路径规划领域,具体是一种基于动态运动基元学习模型的移动机器人路径规划方法。
背景技术:
路径规划是移动机器人的关键技术之一,它在一定程度上标志着移动机器人智能水平的高低,能快速找出一条便捷、无碰撞的路径不仅保证了移动机器人自身的安全,更体现了机器人的高效性和可靠性。
目前,常用到的机器人路径规划方法有人工势场法、模糊逻辑模型、遗传等模型。人工势场法是路径规划模型中较成熟且较高效的规划方法,以其简单的数学计算被广泛使用。但是传统的人工势场法存在局部极小点和目标不可达等问题。目前,有多种解决局部极小点的办法,如启发式搜索,随机逃走法等,但这些改进的人工势场法只是对机器人施加附加的控制力,没有从根本上解决问题。遗传模型是一种基于遗传和自然选择的多搜索模型,具有鲁棒、灵活、在种群中搜索不易落入局部最小点等优点。但遗传模型在进行机器人路径规划时存在种群规模大、搜索空间大、容易陷入局部极小点、收敛速度慢等问题。
以上传统的机器人路径规划模型主要存在以下两个方面的问题:
(1)任务是特定的,仅仅针对某一任务有很好性能,而不具有泛化推广能力;
(2)学习往往是离线的,这就导致了对新的场景要重新训练学习,实时性很差。
技术实现要素:
本发明要解决的技术问题是:针对上述的移动机器人路径规划方法中所存在的实时性差,以及移动机器人完成任务单一的问题,提出一种基于动态运动基元学习模型的路径规划方法。能够实时搜索路径,与其自主避障功能结合起来能有效地提高路径规划的效率,此外,机器人在完成新的任务时,可以不用重新训练样本而保持原来样本轨迹的特性到达新的目标位置。
为解决上述技术问题,本发明提供如下技术方案:
一种基于动态运动基元学习模型的移动机器人路径规划方法,其特征在于主要包括如下步骤:
步骤1:对机器人运动的二维环境进行建模,模拟机器人运动的二维环境界面,机器人用小实心圆来代替,障碍物为各种平面图形;
步骤2:利用手柄对机器人的操控,使机器人能从起点避免与障碍物碰撞而到达目标点;
步骤3:在步骤2进行的过程中,采集机器人运动轨迹数据作为动态运动基元学习模型的样本点,所述机器人运动轨迹数据包括位移、速度和加速度;
步骤4:根据步骤3得到的机器人运动轨迹时的位移、速度和加速度数据,将这些数据作为训练样本,通过动态运动基元算法对样本进行训练得到机器人运动轨迹所对应的最佳权重值;
步骤5:针对特定任务设置初始参数,所述初始参数包括机器人运动的起点和终点,根据步骤4得到的最佳权重值,规划出通过动态运动基元模型学习后的路径,该路径具有原样本轨迹的特性,即起点和终点一致,并且其运行轨迹与样本轨迹大致相同;
步骤6:在步骤5的基础上,加入圆形障碍物,并且在原有的动力学方程中加入耦合项,从而构建带有避障功能的动力学系统,实现动态运动基元学习模型的自主避障功能;
步骤7:在步骤5的基础上,改变机器人运动的目标位置,在不重新训练样本的前提下,仅仅改变目标位置的参数,机器人仍能自主到达新的目标点位置,即机器人可以完成不针对某一指定任务,而对于其他的任务也具有泛化推广的能力。
上述技术方案中,步骤1中对机器人运动的二维环境进行建模,建模的要求为:移动机器人的活动范围在一个有限的二维空间;以移动机器人的尺寸为基准,将障碍物的尺寸向外扩展,将机器人看作一个质点;障碍物由各种平面图形组成,数目有限,并且在机器人移动过程中这些障碍物不会发生变化和移动。
上述技术方案中,步骤2具体过程如下:
步骤2-1:读取机器人手柄的数据,当手柄向上下或左右推动时,该界面实时的显示机器人在建模环境中运动的位移、速度和加速度;
步骤2-2:遥控手柄,人为的规划出一条机器人能从起始点到达终点的最优路径,考虑到机器人一般只能前后和左右运动,因此规划出来的路径也是前后或者左右运动的路径,规划出来的轨迹也叫做样本轨迹;
步骤2-3:在规划路径时,要避开障碍物,并且用数据保存的方法将样本轨迹的位移、速度和加速度的值记录下来,并作为样本数据。
上述技术方案中,步骤4包括如下具体步骤:
步骤4-1:建立动态运动基元的数学模型:动态运动基元一般用来形成离散的运动,对于单一的自由度位移y,引入带有恒定系数线性微分方程并称之为动力学系统,此系统作为对运动学习的基础:
式中:
x和v分别是系统的位移和速度;x0和g分别是初始位置和目标位置;τ是时间伸缩因子;K是弹簧的弹性系数;D是系统处于临界状态下的阻尼系数;f是非线性函数,用于生成任意复杂的运动;
步骤4-2:设置初始参数,机器人运动的起始点x0和目标点g,时间常数τ,弹簧的弹性系数K,系统处于临界状态下的阻尼系数D;非线性函数f用于形成任意复杂的运动,定义f为:
式中:
ψi(s)是径向基核函数,i表示第i个径向基核函数ψi(s),其取值范围是1到N,其中N表示径向基核函数的个数;径向基核函数定义为:
ψi(s)=exp(-hi(s-ci)2) (4)
式中:
ci是径向基核函数的中心,hi>0且决定核函数的宽;其中hN=hN-1,i=1,...N,α为任意正常数;
公式(3)中的函数f并不取决于时间参数,而是取决于相位变量s,s的表达形式为:
式中:
s是关于时间t的函数,α为任意正常数,τ是时间伸缩因子;由方程(5)可知s是由1到0单调递减的,因此方程(5)称为正则系统;
步骤4-3:将步骤3中得到的样本数据代入公式(1)和公式(2)中,因为正则系统是可积分的,即s可以根据参数τ计算出来,所以训练样本中的非线性扰动f′(s)可以表示成:
根据最小误差准则函数J来求解最佳权重值wi,其中最小误差准则函数的表达式为:
J=∑s(f′(s)-f(s))2 (7)
当J取最小时的wi就是最佳的权重值。
上述技术方案中,步骤5包括如下具体步骤:
步骤5-1:当机器人执行指定的任务时,设置机器人的起点位置与终点位置;
步骤5-2:样本数据是二维的,也即包括x轴方向上的数据和y轴方向上的数据,将x轴方向上的数据按照步骤4进行训练,得到x轴方向上的最佳权重值,代入步骤5-1中的起点和终点值,计算出x方向上通过动态运动基元模型学习后的位移、速度和加速度;
步骤5-3:将y轴方向上的数据按照步骤4进行训练,得到y轴方向上的最佳权重值,代入步骤5-1中的起点和终点值,计算出y方向上通过动态运动基元模型学习后的位移、速度和加速度;
步骤5-4:读入步骤5-2和步骤5-3中得到的数据,分别得到x轴和y轴两个方向的运动数据,在二维平面上输出运动的轨迹仿真图,即完成基于动态运动基元学习模型对移动机器人的路径规划。
上述技术方案中,步骤6中所加入的障碍物是以(0.4,0.4)为圆心坐标,半径为0.1m的圆。
本发明的方法开始以简单的线性动态系统(一组微分方程)开始研究,通过转换系统将简单的线性动态系统转换成非线性系统,并且通过吸引子来形成任意复杂的运动,这样就能较简单的对非线性系统进行研究。其中,用微分方程来表示的优点在于误差可以自动的被校正,而且微分方程都是以固定的格式形成的,按照这个固定的格式仅仅只需要简单的改变一个目标参数,就能适应新的环境,即可以对新目标进行泛化;基于动态运动基元学习的方法是在线学习的,对于新的情形不用重新学习,能实时的跟踪目标位置。因而,在避障方面上,通过构建带避障功能的动力学系统实现自主避障,并且动态运动基元模型的在线学习特征和其自主避障功能相结合提高了路径规划的效率。
与现有技术相比,本发明的有益效果是:
(1)本发明提出一种基于动态运动基元学习模型的移动机器人路径规划方法,该学习模型具有泛化推广能力,机器人在完成新的任务时,可以不用重新训练样本而保持原来样本轨迹的特性到达新的目标位置。
(2)本发明提出的路径规划模型在搜索路径时是实时的,与其自主避障功能结合起来能有效地提高路径规划的效率。
附图说明
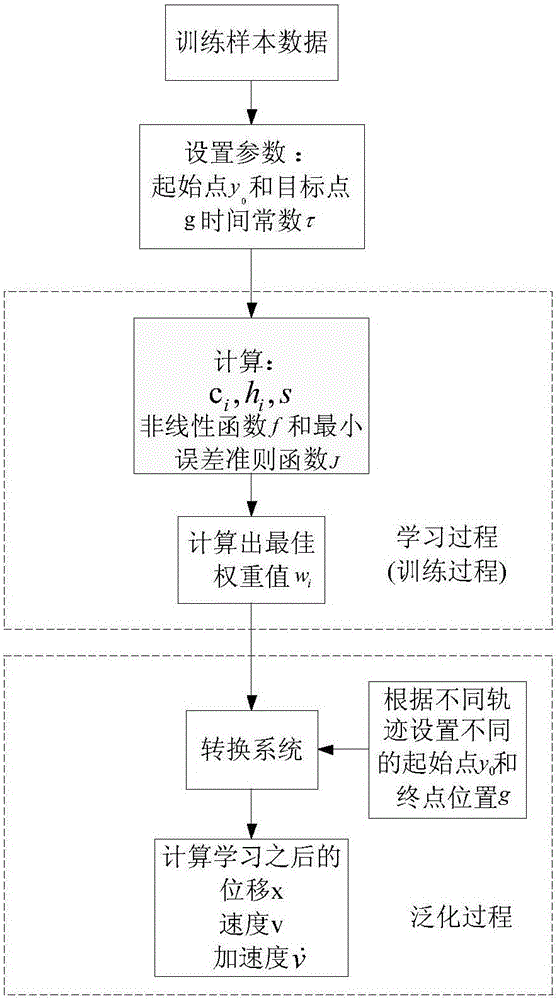
图1是本发明基于动态运动基元学习模型的移动机器人路径规划过程示意图;
图2是本发明中模拟机器人运动的二维环境;其中直线型轨迹代表样本轨迹;各种形状的图形(如矩形、圆形、椭圆形)表示二维环境中的障碍物;
图3是本发明中动态运动基元学习模型的自主避障仿真图;
图4是本发明中动态运动基元学习模型所具有泛化推广能力的仿真图;
图5是训练的样本轨迹与通过动态运动基元模型学习后的轨迹对比图。
具体实施方式
为了进一步说明本发明的技术方案,下面结合附图1-5对本发明进行详细的说明。
步骤1:模拟机器人运动的二维环境界面,其界面上机器人用小实心圆来代替,障碍物为各种平面图形;设置机器人运动的二维环境界面为正方形(长和宽都为1m),机器人用一个直径为5mm的小实心圆来代替。
步骤2:利用OPENCV(Open Source Computer Vision Library)实现手柄对机器人的操控,使机器人能从起点避免与障碍物碰撞到达目标点;
步骤2-1:基于MFC(Microsoft Foundation Classes)界面编写一个上位机软件,该软件可以读取机器人手柄的数据,当手柄向上下或左右推动时,该界面可以实时的显示机器人在建模环境中运动的位移、速度和加速度;
步骤2-2:遥控手柄,人为的规划出一条机器人能从起始点到达终点的最优路径,考虑到机器人一般只能前后和左右运动,因此规划出来的路径也是前后或者左右运动的路径,规划出来的轨迹也叫做样本轨迹;
步骤2-3:在规划路径时,要避开障碍物,并且用数据保存的方法将样本轨迹的位移、速度和加速度的值记录下来,并作为样本数据;
步骤2中使用的是基于MFC编写的上位机软件,通过对手柄的操控就能实现对机器人的控制。其中设置手柄推杆的位移为机器人运动时的速度大小,其中控制机器人运动速度的范围为-5mm/s~5mm/s。
步骤3:在步骤2进行的过程中,采集机器人运动轨迹数据作为动态运动基元学习模型的样本点,其中机器人运动轨迹数据包括其位移、速度和加速度值的大小;
步骤4:根据步骤3得到的机器人运动轨迹时的位移、速度和加速度,将这些数据作为DMP学习模型的训练样本,通过对样本的训练得到机器人运动轨迹所对应的最佳权重值;
步骤4-1:建立动态运动基元的数学模型。动态运动基元一般用来形成离散的运动,对于单一的自由度位移y,引入带有恒定系数线性微分方程并称之为动力学系统,此系统作为对运动学习的基础:
式中:
x和v分别是系统的位移和速度;x0和g分别是初始位置和目标位置;τ是时间伸缩因子;K是弹簧的弹性系数;D是系统处于临界状态下的阻尼系数;f是非线性函数,用于生成任意复杂的运动;
步骤4-2:设置初始参数,机器人运动的起始点x0和目标点g,时间常数τ,弹簧的弹性系数K,系统处于临界状态下的阻尼系数D;非线性函数f用于形成任意复杂的运动,定义为:
式中:
ψi(s)是径向基核函数,i表示第i个径向基核函数ψi(s),其取值范围是1到N,其中N表示径向基核函数的个数;径向基核函数定义为:
ψi(s)=exp(-hi(s-ci)2) (4)
式中:
ci是径向基核函数的中心,hi>0且决定核函数的宽;其中hN=hN-1,i=1,...N,α为任意正常数;
公式(3)中的函数f并不取决于时间参数,而是取决于相位变量s,s的表达形式为:
式中:
s是关于时间t的函数,α为任意正常数,τ是时间伸缩因子;由方程(5)可知s是由1到0单调递减的,因此方程(5)称为正则系统;
步骤4-3:将步骤3中得到的样本数据代入上述公式中,因为正则系统是可积分的,即s可以根据参数τ计算出来,所以训练样本中的非线性扰动f′(s)可以表示成:
根据最小误差准则函数J来求解最佳权重值wi,其中最小误差准则函数的表达式为:
J=∑s(f′(s)-f(s))2 (7)
当J取最小时的wi就是最佳的权重值;
步骤5:针对特定任务设置初始参数(机器人运动的起点和终点),根据步骤4得到的最佳权重值,规划出通过动态运动基元模型学习后的路径,该路径具有原样本轨迹的特性;
步骤5-1:当机器人执行指定的任务时,设置机器人的起点位置与终点位置;
步骤5-2:样本数据是二维的(x轴方向上的数据和y轴方向上的数据),将x轴方向上的数据按照步骤4进行训练,得到x轴方向上的最佳权重值,代入步骤5-1中的起点和终点值,就可以计算出x方向上通过动态运动基元模型学习后的位移、速度和加速度;
步骤5-3:将y轴方向上的数据按照步骤4进行训练,得到y轴方向上的最佳权重值,代入步骤5-1中的起点和终点值,就可以计算出y方向上通过动态运动基元模型学习后的位移、速度和加速度;
步骤5-4:将步骤5-2和步骤5-3中得到的数据通过MATLAB读入,得到x轴和y轴两个方向的运动数据,在二维平面上输出运动的轨迹仿真图,即完成基于动态运动基元学习模型对移动机器人的路径规划。
步骤6:在步骤5的基础上,加入圆形障碍物,并且在原有的动力学方程中加入耦合项,从而构建带有避障功能的动力学系统,实现了动态运动基元学习模型的自主避障功能;
步骤6-1:在步骤5-4的基础上,加入圆形障碍物,其中障碍物是以(0.4,0.4)为圆心坐标,半径为0.1m的圆;
步骤6-2:在步骤4-1给出的动力学系统方程的基础上加入耦合项P(x,v)来构建带有避障功能的动力学系统,其中耦合项P(x,v)的表达式为:
式中:
是以为轴,为旋转角的旋转矩阵,矢量是障碍物的位置,γ与β是常量,θ是轨迹上的点与障碍物的距离矢量与轨迹上那一点的相对速度之间的夹角;
步骤6-3:给定耦合项P(x,v)公式中的常数项初值,其中γ=8,旋转矩阵R表示成:
步骤6-4:通过构建带有避障功能的动力学系统,加入步骤6-1中所述的障碍物,机器人仍能避开障碍物到达目标点,其中带有避障功能的动力学系统的数学表达式为:
由图3可以看出,动态运动基元模型具有自主避障的功能;
步骤7:在步骤5的基础上,改变机器人运动的目标位置,在不重新训练样本的前提下,仅仅改变目标位置的参数,机器人仍能自主的到达新的目标点位置,即机器人可以完成不针对某一指定任务,而对于其他的任务也具有泛化推广的能力。
步骤7-1:在步骤5-4的基础上,改变机器人目标点的位置为(0.5,0.5),代入步骤4,得到在不重新训练样本的前提下,动态运动基元模型学习后的轨迹;
步骤7-2:在步骤5-4的基础上,改变机器人目标点的位置为(0.8,0.8),代入步骤4,得到在不重新训练样本的前提下,动态运动基元模型学习后的轨迹;
步骤7-3:由图4可知,在步骤7-1和步骤7-2中,机器人可以到达新的目标位置,并且保持原样本轨迹的特性,因此证明了动态运动基元学习模型所具有的泛化推广能力;
综上,本发明基于动态运动基元学习模型实现对机器人的路径规划,该学习模型的在线学习特征和其自主避障功能相结合提高了路径规划的效率,并且该模型具有泛化推广能力。本发明的提出,提高了移动机器人的智能性,为移动机器人在路径规划、避障与导航等相关领域提供了参考。
- 还没有人留言评论。精彩留言会获得点赞!