一种基于机会约束模型预测控制的无人车避障方法与流程
本发明涉及无人驾驶车辆避障领域,尤其是涉及一种基于机会约束模型预测控制的无人车避障方法。
背景技术:
由于无人驾驶车辆在减少交通事故及人员伤亡、缓解降低交通拥堵、减少用户在驾驶上消耗的精力等方面的优势,获得了学术界和产业界的广泛关注。无人驾驶车辆的实施涉及各个领域,包括信息与传感技术、轨迹跟踪技术与避障技术。实现无人车在各种情况下的避障具有十分重要的意义。避障能力是无人车的基础,只有具有良好的避障能力的无人车才有可能真正具有实用性。
无人车避障是通过路径规划算法实现的。路径规划是指寻找一条恰从给定起点到目标点的路径,使得无人车能够安全无碰撞地绕过环境中的障碍物达到目标点。传统的路径规划方法主要包括栅格法与快速扩展随机树法。栅格法,包括知名的a*与d*算法,采用大小相同的栅格对环境地图中的的二维运动空间进行划分,然后将路径规划问题转化为图搜索问题。栅格法的主要缺点在于,实时性能不强,对动态环境中适应性较差,不能够处理车辆动力学约束。快速扩展随机树算法由s.m.lavalle于1999年提出,该方法通过创建随机扩展树来连接起始位姿和目标位姿。快速扩展随机树算法缺点主要包括:需要对全局空间进行随机搜索,由于随机搜索具有不确定性,运算量大,规划时间长,导致算法的实时性较差;路径由多个随机采样点连接而成,导致最终的路径不够光滑;不能处理车辆动力学约束。
模型预测控制算法是一种通过滚动求解优化问题获取控制序列的方法,已经在多个领域得到广泛应用。能够处理车辆动力学约束是模型预测控制算法的突出优势。
在无人驾驶车辆实际应用中,传感系统的测量误差可能突然增大(比如在无人驾驶车辆经过隧道时,定位系统测量误差会突然增大)。避障算法必须考虑这种不确定性。
机会约束模型预测控制能够有效的处理这种不确定性。由于存在不确定性,在机会约束模型预测控制中,部分约束以一定的置信水平满足,该部分约束称之为机会约束。近年来,许多学者提出了一些基于机会约束模型预测控制的避障方法。
文献(l.blackmore,m.onoandb.c.williams,”chance-constrainedoptimalpathplanningwithobstacles”,ieeetransactionsonrobotics,v27,n6,p1080-1094,dec.2011.)针对线性高斯系统,将路径规划的优化问题估计为析取规划,并通过分支界定法求解。但是,该算法的主要不足在于:没有考虑车辆实际占据区域,仅仅将车辆视作质点;只考虑了车辆状态的不确定性,没有考虑障碍物状态的不确定性。
为了能够同时考虑车辆状态与障碍物信息不确定性,文献(n.e.toitandj.w.burdick,”probabilisticcollisioncheckingwithchanceconstraints”,ieeetransactionsonrobotics,v27,n4,p809-815,aug.2011.)提出了一种基于机会约束的碰撞检查方法,在假设车辆半径非常小的前提下,通过积分运算,分别针对车辆状态与障碍物状态的不确定性独立与否的两种情况,该方法将关于不确定变量的约束近似转化为关于均值与方差的替代约束,并通过大量采样的方法验证了估计的精度。由于替代约束关于决策变量是非凸的,使得最终模型预测控制优化问题不易求取。
技术实现要素:
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种基于机会约束模型预测控制的无人车避障方法。
本发明的目的可以通过以下技术方案来实现:
一种基于机会约束模型预测控制的无人车避障方法,包括以下步骤:
1)建立无人驾驶车辆的动力学模型,描述无人驾驶车辆动力学特征;
2)构建模型预测控制最优化问题的代价函数和约束条件;
3)求解模型预测控制最优化问题,获取无人车避障的最优路径。
所述的步骤1)中,无人驾驶车辆的动力学模型为:
u=δf
其中,x为状态向量,u为输入向量,
所述的步骤2)中,将关于目标位置的代价函数作为模型预测控制的代价函数,并将无碰撞机会约束替代无碰撞条件约束作为约束条件。
所述的步骤2)中,关于目标位置的代价函数为:
mine(h(δu,x(t|t),u(t-1|t)))
其中,e(·)表示期望,h(δu,x(t|t),u(t-1|t))为关于目标位置的代价函数,xgoal为目标位置,q和r均为权重矩阵,nc为控制时域的长度,δu为,x(t|t)为当前时刻的系统状态,u(t-1|t)为上一时刻系统输入,x(t+i|t)为在t时刻第i个预测时域的车辆状态,δu(t+i|t)为在t时刻第i个预测时域的控制增量。
所述的步骤2)中,模型预测控制最优化问题的代价函数为:
其中,j(δu,x(t|t),u(t-1|t))为优化指标,np为预测时域的长度,nc为控制时域的长度,μi为在第i个预测时域车辆状态信息所服从高斯分布的期望,
约束条件为:
x(t+i+1|t)=ax(t+i|t)+bu(t+i|t)+d(t+i|t),i=0,1,...np-1
x(t|t)~n(μt0,∑t0)
xj~n(μj,∑j)
u(t+i|t)=u(t+i-1|t)+δu(t+i|t),i=0,1,...nc-1
δu(t)=[δu(t|t),δu(t+1|t),…δu(t+nc-1|t)]t
ρi,j,k∈{0,1},i∈zp,j∈zo,k∈zv
其中,t为时间,x(t+i|t)为在t时刻第i个预测时域的车辆状态,
与现有技术相比,本发明具有以下优点:
一、在以往的研究中,避障算法中仅仅将车辆视作一个质点,车辆实际占据区域被完全忽略了,显然,车辆质心是无碰撞的并不能保证整个车辆是无碰撞的,本发明将车辆实际占据区域视作一系列约束的析取而不是质点,更好地保证了车辆的安全性。
二、本发明能够同时考虑车辆状态信息与障碍物信息的不确定性,因此具有更好的环境适应性。
附图说明
图1为本发明系统流程图。
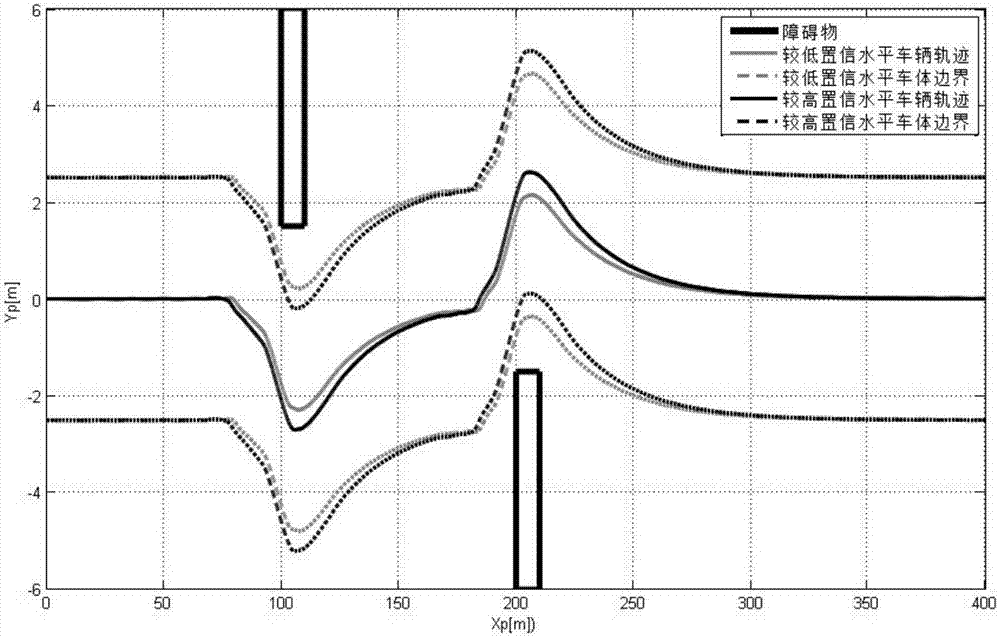
图2为不同置信水平下车辆轨迹曲线对比图。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。
实施例
如图1所示,一种基于机会约束模型预测控制的无人车避障方法包括以下步骤:
s1:建立车辆动力学模型,该模型用于描述无人驾驶车辆动力学特征:
车辆动力学模型描述如下:
其中,状态向量和输入向量分别为:
s2:无碰撞条件设计:
将原车身占据区域约束视作由一系列约束组成的凸多边形。
原无碰撞条件rcprvs描述如下:
fk,i(δu,x(t|t),u(t-1|t))xj-bk,i(δu,x(t|t),u(t-1|t))≥0
δu(t)=[δu(t|t),δu(t+1|t),…δu(t+nc-1|t)]t(3)
其中,t表示时间。
由于公式(2)具体形式比较复杂,关于决策变量的凸性是未知的,因此本发明提出原无碰撞条件的估计racprvs,描述如下:
其中lh与lt分别表示车头与车尾到质心的纵向距离,w表示车辆宽度。fk与bk的值如表1所示。xj定义如下:
其中xo,j与yo,j分别表示障碍物在全局坐标系下的横向位置与纵向位置。
表1fk与bk的参数
s3:无碰撞机会约束估计
对应于公式(2)的机会约束记作cccprvs,该约束具体写成以下形式:
p(rcprvs)≥c(6)
其中,c为置信水平。
对应于公式(4)的机会约束记作ccacprvs,该约束具体写成以下形式:
p(racprvs)≥c(7)
其中,c为置信水平。
将障碍物位置信息的不确定性描述为高斯分布xj~n(μj,∑j)。将初始车辆状态信息的不确定性描述为高斯分布x(t|t)~n(μt0,∑t0)且独立于xj。车辆状态信息在预测时域里服从高斯分布x(t+i|t)~n(μi,∑i)。通过递推计算μi与∑i:
s31:单个机会约束转化:
定义一个新的随机变量xnew=fkx(t+i|t)-bkxj。可知xnew服从高斯分布n(fkμi-bkμj,fk∑ifkt+bk∑jbkt)。利用xnew的概率分布,即可得到:
s32:ccacprvs的计算:
利用公式(10),避障机会约束ccacprvs计算如下:
其中,c=1-npno(1-α),no是障碍物的个数。
公式(11)是从单个置信水平为α的机会约束推出总体置信水平为c的机会约束。α与c都是接近但小于概率1的数值。公式(11)的直观意义是,如果单个机会约束不满足的概率不超过1-α,那么整个无碰撞条件racprvs满足的概率不低于c=1-npno(1-α),即把racprvs的机会约束转化为单个机会约束。
s33:cccprvs的计算
事件a与事件b分别定义如下:
为了方便表述,将公式(2)中fk,i(δu,x(t|t),u(t-1|t))简写为fk,i,将公式(2)中bk,i(δu,x(t|t),u(t-1|t))简写为bk,i。
根据公式(5),事件a与事件b的关系可以描述如下:
根据公式(12)、公式(13)与公式(14),将rcprvs与racprvs的关系表述如下:
利用公式(15),进一步得到:
利用公式(16)与公式(11),机会约束cccprvs计算如下:
其中,c=1-npno(1-α)。
s34:析取约束转化:
公式(17)中的析取约束可以通过“大m”方法转化为以下形式:
ρi,j,k∈{0,1},i∈zp,j∈zo,k∈zv(20)
其中,m表示足够大的正数。ρi,j,k为0-1变量,只取值为整数0或者整数1。
s4:代价函数设计:
代价函数设计如下:
mine(h(δu,x(t|t),u(t-1|t)))(21)
其中,e(·)表示期望,h(δu,x(t|t),u(t-1|t))表示关于目标位置的代价函数:
其中,xgoal表示目标位置,q和r均为权重矩阵。公式(22)中第一项反映算法趋近于目标位置的能力,也反映了避障算法的经济性和能耗。第二项反映了避障算法要求控制增量的变化较为平滑,也反映了避障轨迹的平顺性。
利用公式(22),将公式(21)重写:
将公式(23)重写如下:
其中,tr(·)表示矩阵的迹。
将与控制增量无关的常数项舍弃,公式(24)重写如下:
至此,期望的计算完成。
s5:模型预测控制最优化问题设计与求解:
综上,模型预测控制最优化问题设计如下:
s.t.
x(t|t)~n(μt0,∑t0)(28)
xj~n(μj,∑j)(29)
u(t+i|t)=u(t+i-1|t)+δu(t+i|t),i=0,1,...nc-1(30)
δu(t)=[δu(t|t),δu(t+1|t),…δu(t+nc-1|t)]t(33)
ρi,j,k∈{0,1},i∈zp,j∈zo,k∈zv(36)
其中,t表示时间,x(t+i|t)表示在t时刻第i个预测时域的车辆状态,
根据具体实施方式进行仿真实验,仿真结果如图2所示;
基于机会约束模型预测控制算法,∑t0=0.2*i5,∑j=0.2*i2,在较高置信水平c=1-10-10与较低置信水平c=0.9两种工况下的车辆避障轨迹的均值图2所示。相对于c=0.9的工况,c=1-10-10工况下的车辆总避障轨迹更长,即具有更高的能耗和经济代价。因此,图2说明,更高的置信水平是以能耗为代价的,即在车辆状态与障碍物位置信息存在不确定性的情况下,如果要获取更高的置信水平的避障轨迹,那么就要付出更高的经济代价。
- 还没有人留言评论。精彩留言会获得点赞!