基于MCMC优化Q学习的自主航行器控制参数在线调节方法与流程
本发明属于自主航行器控制参数在线调整领域,具体的说是一种对自主航行器控制参数调节的方法。
背景技术:
航行器自主航行是指航行器在水面中通过人为指定到达的目的地,然后自主规划好行进的路径,最终通过不断的自我调节到达目的地。在水质巡检和水面巡逻等方面有着重要的应用价值。
目前,传统的自主航行器采用的是固定pid参数方法,该方法采用固定的航行器控制参数,参数是由大量的航行器自主航行工程项目经验所获取。当固定的控制参数不适合当前环境时会给航行器自主航行带来超调和响应延时的问题,尤其是在环境多变的情况下,固定的控制参数可能对个别环境状态有较好的响应,但是却不能满足所有的环境情况,当环境改变时需要人为的更改航行器控制参数不便于航行器的使用。
还有一些采用模糊算法、退火算法来进行航行器控制参数调节的方法,这些方法在一定程度上引入了控制参数自动调节机制,但是由于这些方法本身不是智能控制算法,所以对环境多变的情况仍然无法解决自主航行器控制参数快速调节到最优值的问题。
技术实现要素:
本发明为解决上述现有技术中存在的不足之处,提供了一种基于mcmc优化q学习的自主航行器控制参数在线调节方法,以期能解决自主航行器在航行过程中的超调和时延问题,从而使得自主航行器快速适应环境的变化并快速平稳的到达目的地。
为了达到上述目的,本发明所采用的技术方案为:
本发明一种基于mcmc优化q学习的自主航行器控制参数在线调节方法的特点包括以下步骤:
步骤1、根据自主航行器的控制精度α,利用式(1)分别得到自主航行器pid三个控制参数kp、ki和kd的调节参数δkp、δki和δkd:
式(1)中,xp、xi、xd分别表示所述自主航行器三个pid控制参数kp、ki和kd的阈值范围;
步骤2、利用所述调节参数δkp、δki和δkd组合得出所述自主航行器的参数变化动作集合,记为a={a1,a2,···,an,···,an},其中,an表示所述参数变化动作集合中第n个控制参数调节动作,且
步骤3、设定时间t=1,随机选择一个控制参数调节动作
初始化q学习算法中的相关参数:t时刻学习因子lt和折扣因子γ,lt>0,γ∈[0,1];
根据所述自主航行器的控制经验来初始化所述pid三个控制参数kp、ki和kd;
将所述q学习算法中t-1时刻的值函数估计值
步骤4、根据所述自主航行器的参数变化动作集合a中控制参数调节动作的个数n,利用式(2)对q学习算法中的决策过程的转移矩阵
式(2)中,
步骤5、利用mcmc优化q学习算法获取t时刻的决策过程;
步骤5.1、利用式(3)计算t时刻第n个控制参数调节动作
式(3)中,wj(t-1)表示bp神经网络中t-1时刻第j个隐含层的权值,j=1,2,...,nh;nh表示bp神经网络隐含层的个数;yj(t-1)表示bp神经网络中t-1时刻第j个隐含层的输出,并有:
式(4)中,oj(t-1)表示bp神经网络中t时刻第j个隐含层的输入,并有:
式(5)中,wij(t-1)表示bp神经网络中t-1时刻第i个输入层到第j个隐含层的权值,xi(t-1)表示bp神经网络中t-1时刻第i个输入层的输入,i=1,2,...,ni,ni表示bp神经网络输入层的个数;
步骤5.2、利用mcmc算法采样得出t时刻所述自主航行器的控制参数调节动作
步骤5.2.1、根据t时刻第n个控制参数调节动作
式(6)中,
步骤5.2.2、设定采样次数c=0,1,2···c;
步骤5.2.3、对t时刻的转移概率矩阵
式(7)中,
步骤5.2.4、从均匀分布uniform[0,1]中进行采样得到随机接受率u,将随机接受率u和所述接受率
步骤5.2.5、利用式(8)更新t时刻第c+1次采样所得到的动作
式(8)中,
步骤5.2.6、令c+1赋值给c,并判断c>c是否成立,若成立,则执行步骤5.2.7,否则,返回步骤5.2.3顺序执行;
步骤5.2.7、对t时刻的转移概率矩阵
步骤6、利用式(9)得到t时刻自主航行器的控制参数调节动作
式(9)中,α和β分别表示误差回报参数和误差变化率回报参数,0<α<1,0<β<1,且α+β=1;
步骤7、利用式(10)更新t-1时刻值函数估计值
式(10)中,
步骤8、令t+1赋值给t,判断t>tmax是否成立,若成立,则执行步骤9;否则根据spsa步长调节算法随着时间t的变化,利用式(12)对学习因子lt进行调节,其中,tmax表示所设定最大迭代次数:
式(12)中,l为t=1时刻的学习因子值,μ和λ为spsa步长调节算法中的非负常数;
步骤9、判断连续两个时刻的最终值函数值
步骤10、判断t是否超出规定时间,若超出,则跳转至步骤3,重新选择初始控制参数调节动作
步骤11、令t=1;
步骤12、所述自主航行器采集t时刻的环境状态et和δet,判断|et|>|emin|或|δet|>|δemin|是否成立,若成立,则执行步骤13;否则返回步骤11;其中,emin和δemin分别表示自主航行器允许的环境状态误差和误差变化率最小值;
步骤13、令t+1赋值给t,并判断t>t是否成立,若成立,则执行步骤3;否则返回步骤12执行;其中,t表示自主航行器适应环境变化快慢的时间常数。
与已有技术相比,本发明的有益效果为:
1、本发明采用了q学习算法对航行器自主航行控制参数进行在线调节,并在q学习算法中引入了mcmc采样算法和spsa步长调节算法,使航行器在自主航行的过程中自适应环境的变化并提前预判下一时刻的航行状况,解决了航行器超调和时延的问题,使航行过程更加平稳,特别是在天气变化的情况下参数调节迅速,在航行器自主航行领域具有广阔的应用前景。
2、本发明引入q学习算法,将航行器控制效果与环境状态相关联,通过环境反馈的回报值来判定此次参数调节动作的好坏,并使得参数调节向好的方向逐渐逼近,解决了航行器在航行过程中出现超调和响应延时的问题,将控制参数随着环境的变化而快速变化到最优值,从而能快速适应环境的变化。
3、本发明在传统的q学习算法中引入了mcmc采样算法用于优化,将当前时刻采取的参数调节动作策略不采用单一的取最大行为值函数值的动作,而是通过行为动作之间的转移概率去估计整体的概率分布模型,解决了q学习算法选择动作时陷入局部最优的问题,从而能得出自主航行器航行过程中的最优调节动作策略。
4、本发明在mcmc采样算法中将初始采样时刻动作概率分布设置为等概分布,使得mcmc采样算法在算法运行前期具有动作行为采样的一般性,后期随着每次采样得到的动作对动作概率分布进行更新,将每次采样得到的动作所对应的动作概率分布比例增大,从而提高了每时刻动作采样的正确性。
5、本发明对传统的q学习算法中学习因子l的变化采用了spsa步长调节算法,通过spsa步长调节算法中各个参数的设定,限定了学习因子l变化的快慢程度和变化的区间范围,从而使q学习算法过程中学习因子l的改变具有一定规律性,使自主航行器参数调节更加精确。
附图说明
图1为本发明基于mcmc优化q学习的自主航行器控制参数在线调节方法原理框图;
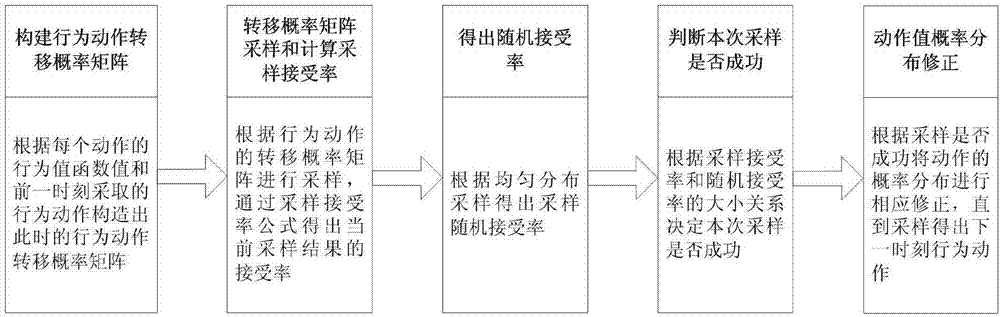
图2为本发明q学习算法中mcmc优化步骤图;
图3为本发明基于mcmc优化q学习的自主航行器控制参数在线调节方法流程图;
图4为bp神经网络求解动作行为值函数原理图;
图5为本发明方法与传统固定pid参数方法在不同实验下自主航行器航行过程消耗时间的实验结果比较图;
图6为本发明方法与传统固定pid参数方法在自主航行器航行过程中环境不变的情况下实时误差et的实验结果比较图;
图7为本发明方法与传统固定pid参数方法在自主航行器航行过程中环境发生变化的情况下实时误差et的实验结果比较图;
图8为本发明方法与传统固定pid参数方法在自主航行器航行过程中环境已经发生变化后的情况下的实时误差et实验结果比较图。
具体实施方式
本实施例中,基于mcmc优化q学习的自主航行器控制参数在线调节方法的原理如图1所示,自主航行器实时接收当前环境的误差et和误差变化率δet,通过mcmc优化q学习算法实时决策出下一时刻的参数调节动作an,最终当q学习算法中的最终值函数值不在发生变化时得出当前环境下的控制参数最优值。q学习算法中mcmc优化步骤如图2所示。该方法是应用于自主航行器控制参数在线调整领域,通过改变自主航行器的控制参数来适应当前环境。
如图3所示,自主航行器控制参数在线调节方法按如下步骤进行:
步骤1、pid控制参数包括比例参数kp、积分参数ki和微分参数kd,其中比例参数kp的作用是加快系统的响应速度,提高系统的调节精度,积分参数ki的作用是消除系统的稳态误差,微分参数kd的作用是改善系统的动态特性;
根据自主航行器的控制精度α,利用式(1)分别得到自主航行器pid三个控制参数kp、ki和kd的调节参数δkp、δki和δkd:
式(1)中,xp、xi、xd分别表示所述自主航行器三个pid控制参数kp、ki和kd的阈值范围;
例如α=0.1,xp∈[10,20],xi∈[1,6],xp∈[1,2],根据式(1)得出调节参数δkp的变化动作为正向增大1,不变和反向减小1;同理可得出δki和δkd的变化动作;
传统的自主航行器采用的是固定pid参数方法,该方法由于环境的不确定性给自主航行器在航行过程中带来了超调和响应延时的问题,同时对于不同的环境需要人为修改pid参数来适应。所以针对这些问题和困扰,本文引入了q学习算法来实时在线调整pid控制参数。
q学习算法是chriswatkins在1989年提出的一种智能学习算法,将td算法和动态规划相结合,watkins的工作推进了强化学习的快速发展。q学习算法是一种与真实系统模型无关、值迭代型的强化学习算法,该算法是动态规划的有关理论及动物学习心理学的有利相互结合,用于解决具有延迟回报的惯序优化决策问题。
步骤2、由于q学习中需要通过决策对自主航行器控制参数改变,如果将pid调节参数分为三个动作来看,则会增大q学习算法中的计算复杂度,所以利用所述调节参数δkp、δki和δkd组合得出所述自主航行器的参数变化动作集合,记为a={a1,a2,···,an,···,an},其中,an表示所述参数变化动作集合中第n个控制参数调节动作,且
步骤3、设定时间t=1,随机选择一个控制参数调节动作
初始化q学习算法中的相关参数:t时刻学习因子lt和折扣因子γ,lt>0,γ∈[0,1];
所述q学习算法中的学习因子lt随着时间t的变化而变化,q学习算法的前期需要从样本数据中获取较大的学习值,所以初始学习因子lt为一个较大的正数,随着时间t的增加自主航行器不在需要很大的学习值从而将学习因子lt逐渐变小;折扣因子γ用于控制自主航行器对短期和长期结果的考虑程度,例如考虑两个极端情况,当γ=0时自主航行器只考虑当前时刻环境的回报值,当γ=1时只考虑未来时刻环境的回报值,所以根据自主航行器实际需求对折扣因子进行设定,一般取γ=0.5对当前时刻和未来时刻进行综合考虑;
根据所述自主航行器的控制经验来初始化所述pid三个控制参数kp、ki和kd;例如本实验系统初始设定三个控制参数为kp=2.5、ki=0.5、kd=0.2;
将所述q学习算法中t-1时刻的值函数估计值
t=1时刻设定值函数估计值
步骤4、q学习算法中,不但需要自主航行器选择值函数值最大的动作,以得到最大的即时回报;还需要自主航行器尽可能选择不同的动作,考虑到所有动作的情况从而得到最优策略。如果自主航行器一直选择具有最高值函数值的动作,会存在如下缺点:若在初期获取经验的阶段,自主航行器尚未学到最优的策略,则在以后的学习阶段将不可能再得到最优的策略。
所以在q学习算法中引入了mcmc采样算法用于决策每时刻选取的动作。mcmc采样算法通过对动作转移矩阵采样得到符合动作概率分布的采样值,对于概率分布未知的情况能够准确的采样得出每时刻选取的动作。
根据所述自主航行器的参数变化动作集合a中控制参数调节动作的个数n,利用式(2)对q学习算法中的决策过程的转移矩阵
式(2)中,
步骤5、利用mcmc优化q学习算法获取t时刻的决策过程;
步骤5.1、bp神经网络具有逼近任意非线性函数的能力,对于解决在大规模和连续状态空间中的泛化问题具有重要作用,bp神经网络求解动作行为值函数原理如图4所示,利用式(3)计算t时刻第n个控制参数调节动作
式(3)中,wj(t-1)表示bp神经网络中t-1时刻第j个隐含层的权值,j=1,2,...,nh;nh表示bp神经网络隐含层的个数;yj(t-1)表示bp神经网络中t-1时刻第j个隐含层的输出,并有:
式(4)中,oj(t-1)表示bp神经网络中t时刻第j个隐含层的输入,并有:
式(5)中,wij(t-1)表示bp神经网络中t-1时刻第i个输入层到第j个隐含层的权值,xi(t-1)表示bp神经网络中t-1时刻第i个输入层的输入,i=1,2,...,ni,ni表示bp神经网络输入层的个数;
例如ni=3表示bp神经网络3个输入层节点,分别为误差et-1,误差变化率δet-1和动作
步骤5.2、利用mcmc算法采样得出t时刻所述自主航行器的控制参数调节动作
步骤5.2.1、根据t时刻第n个控制参数调节动作
式(6)中,
步骤5.2.2、设定采样次数c=0,1,2···c;
步骤5.2.3、对t时刻的转移概率矩阵
式(7)中,
通过公式(7)可以看出,t时刻
由于mcmc采样算法是通过采样动作的转移概率矩阵
步骤5.2.4、从均匀分布uniform[0,1]中进行采样得到随机接受率u,将随机接受率u和所述接受率
例如当随机接受率u=0.5时,如果根据式(7)得到的采样接受率
步骤5.2.5、利用式(8)更新t时刻第c+1次采样所得到的动作
式(8)中,
步骤5.2.6、令c+1赋值给c,并判断c>c是否成立,若成立,则执行步骤5.2.7,否则,返回步骤5.2.3顺序执行;
步骤5.2.7、对t时刻的转移概率矩阵
根据mcmc算法当采样次数c达到100次时动作
步骤6、利用式(9)得到t时刻自主航行器的控制参数调节动作
式(9)中,α和β分别表示误差回报参数和误差变化率回报参数,0<α<1,0<β<1,且α+β=1;
行为动作回报值
步骤7、利用式(10)更新t-1时刻值函数估计值
式(10)中,
步骤8、令t+1赋值给t,判断t>tmax是否成立,若成立,则执行步骤9;否则根据spsa步长调节算法随着时间t的变化,利用式(12)对学习因子lt进行调节,其中,tmax表示所设定最大迭代次数:
式(12)中,l为t=1时刻的学习因子值,μ和λ为spsa步长调节算法中的非负常数;
引入spsa步长调节算法使q学习中的学习因子lt变化具有一定的规律性,并且通过spsa步长调节算法中非负参数μ和λ的设定,限定了学习因子lt变化的快慢程度和变化的区间范围使航行器参数调节更加精确,一般设定tmax=30,μ=0.3,λ=1.2;
步骤9、判断连续两个时刻的最终值函数值
ε为一个极小的正数用于判定pid控制参数是否调节完毕,和航行器的控制精度有关;当ε越小,则航行器自主航行的精度就会越高,得到的航行器pid控制参数就会越接近最优值,一般设定ε=0.2;
步骤10、判断t是否超出规定时间,若超出,则跳转至步骤3,重新选择初始控制参数调节动作
步骤11、令t=1;
步骤12、所述自主航行器采集t时刻的环境状态et和δet,判断|et|>|emin|或|δet|>|δemin|是否成立,若成立,则执行步骤13;否则返回步骤11;其中,emin和δemin分别表示自主航行器允许的环境状态误差和误差变化率最小值;例如一般设定emin=0.1,δemin=0.05;
步骤13、令t+1赋值给t,并判断t>t是否成立,若成立,则执行步骤3;否则返回步骤12执行;其中,t表示自主航行器适应环境变化快慢的时间常数。
实验结果:
同时将本专利方法和传统固定pid参数方法分别用于自主航行器,进行了多组对比实验,实验中保证两组自主航行器同时从相同起点出发到达相同的终点。图5为自主航行器航行过程消耗时间的对比结果;图6、图7和图8为自主航行器航行过程实时误差et的对比结果。
在对比消耗时间的实验上,采取了三组对比实验,每组实验进行50次并对结果取平均值。第一组为当前环境稳定的情况下对比两组自主航行器的到达时间,第二组为环境在航行过程中突然变化的情况下对比两组自主航行器的到达时间,第三组为环境变化以后的情况下对比两组自主航行器的到达时间;如图5可见,在初始环境稳定的状态下由于采用固定pid参数方法的自主航行器采用的pid控制参数接近最优参数所以和采用本专利方法的自主航行器消耗时间大致相同;当环境在航行过程中突然变化的情况下,虽然两组自主航行器到达的时间都变长,但可以明显看出采用本专利方法的自主航行器消耗时间比采用传统方法的自主航行器小得多,采用本专利方法的自主航行器增长的时间主要发生在调节控制参数的过程中;在环境变化以后的情况下,由于采用本专利方法的自主航行器已经将当前环境下的控制参数调节到最优值,所以消耗的时间又回到了和环境变化前相同的水平,而采用传统方法的自主航行器由于新环境下的控制参数已经不再接近最优控制参数,所以消耗的时间继续变长,当环境变化剧烈时,采用传统方法的自主航行器将会出现无法到达指定目的地的情况。
在对比实时误差et的实验上,同样采取上述三组对比实验,每组实验进行50次并对结果取平均值。图6为初始环境不变的对比结果,可发现两组自主航行器实时误差et的变化情况大致相同;图7为环境在自主航行器航行过程第7秒时突然变化的情况下的对比结果,可发现在环境突然变化时两组自主航行器实时误差et都极具增大,但采用本专利方法的自主航行器在经过一段时间航行参数调整后实时误差et又快速减小到接近于0,而采用传统方法的自主航行器实时误差et无法减小为0一直在一个误差范围内上下波动;图8为环境变化以后的情况下的对比结果,可发现采用本专利方法的自主航行器的实时误差et变化规律和环境变化前的规律基本一致,而采用传统方法的自主航行器实时误差et无法减小为0一直在一个误差范围内上下波动。
综合上诉三组实验下的两种对比结果发现,本专利方法相对传统固定pid控制参数方法在环境多变的情况下具有更好的自主航行效果,同时解决了由于控制参数不是当前环境下的最优值而导致的自主航行器超调和响应延时的问题。
- 还没有人留言评论。精彩留言会获得点赞!