一种基于增量PCA的工业监测数据分类方法与流程
本发明属于工业监测数据分类的技术领域,具体涉及一种基于增量pca的工业监测数据分类方法。
背景技术:
由于工业经济在我国的迅速发展,随之产生的数据呈指数级增长。不可避免地,在大量的工业数据中会存在冗余数据,这将给数据分析及后续计算带来很大的困难。如果,可以对高维数据进行降维即数据压缩,在对高维数据压缩的同时对其提取有效信息,这将给数据分析带来很大的便利。但是在现有降维方法中,主要针对的对象是离线数据,而对于不断更新的在线数据,离线降维方法是无法对更新的监测数据进行有效压缩。
技术实现要素:
为解决上述问题,提出了一种基于增量pca(principalcomponentanalysis)的工业监测数据分类方法。该方法可实时对有标签的工业监测数据进行有效分类,相对于未降维的高维数据减小了计算量,是一种有效的数据分类方法,且对于线性数据和非线性数据都适用。
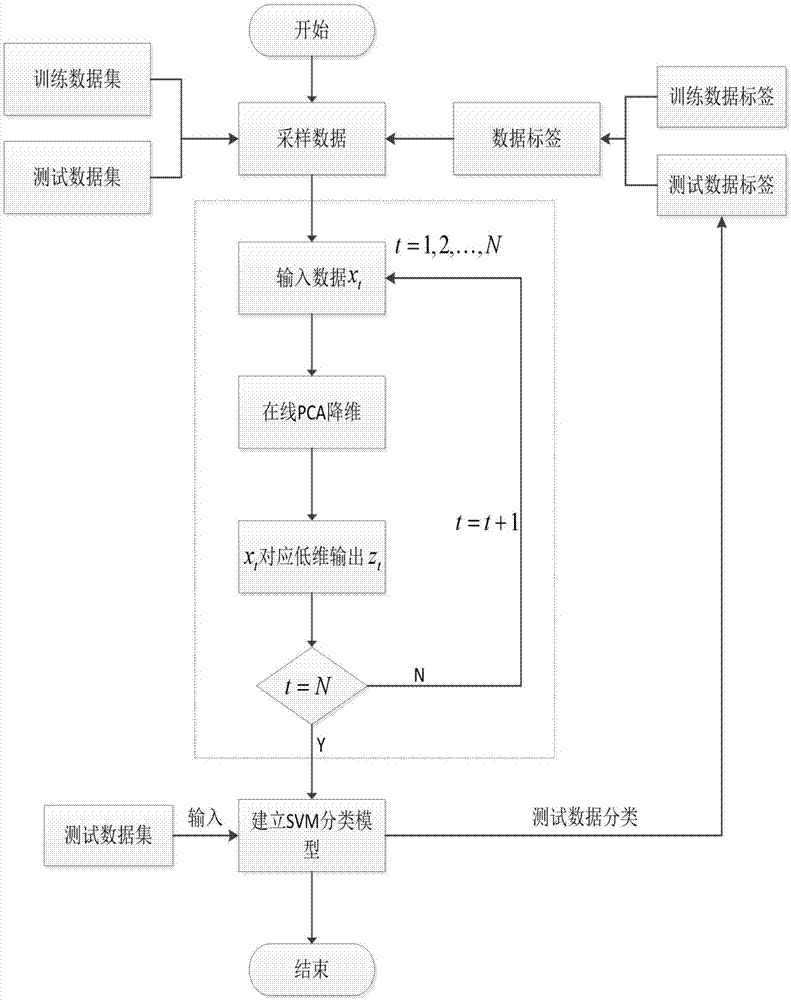
本发明采用以下技术方案:一种基于增量pca的工业监测数据分类方法,包括如下步骤:
步骤1、对工业监测数据进行采集,按采样顺序排列,并记录其数据标签,将其分为训练集和测试集;
步骤2、基于增量pca方法建立模型,分别对步骤1中的训练集和测试集进行在线降维;
步骤3、步骤2中的训练集作为数据对象建立支持向量机svm分类模型,并通过对测试集数据进行分类验证该模型。
作为本发明进一步的方案,所述步骤1具体包括如下步骤:
步骤1.1、对工业系统中的传感器进行数据采样,假设采样数据为有标签数据,采集到的工业监测高维数据用x={x1,x2,…,xn}∈rd×n表示,其中d表示高维数据的维数,每间隔1s进行一次采样,n表示采样数据的数目,第t个采样数据用xt表示,t∈{1,2,...,n},xt=[xt1xt2…xtd]t;
步骤1.2、对采样数据进行分配,采样数据的标签信息用y={y1,y2,…,yn}∈r1×n表示,与高维数据x一一对应,选取高维数据x和数据标签y的前百分之八十作为训练数据集和训练标签,剩下百分之二十作为测试数据集和测试标签。
作为本发明进一步的方案,所述步骤2包括如下步骤:
步骤2.1、输入高维数据x和所需参数:离线降维目标维数k<d,在线降维目标维数
步骤2.2、对矩阵u、矩阵z以及各参数进行初始化:矩阵u和z为
步骤2.3、进入for循环:当接收到第t个采样数据xt时,对参数w、残差rt和矩阵c进行更新,更新公式如下所示,而对于每个采样数据xt,其低维(
rt=xt-u*ut*xt;
c=(i-u*ut)*z*zt*(i-u*ut);
步骤2.4、对初始矩阵和参数进行设置,判断是否更新矩阵c和向量rt,具体包括以下步骤:
步骤2.4.1、对初始矩阵和参数进行设置后,判断是否满足条件式
步骤2.4.2、先对矩阵c进行特征值分解,其最大特征值和其相对应的特征向量分别用λ、u表示,并将特征值λ赋给(wu)u;
步骤2.4.3、判断u中是否有非零列,如果有,用特征向量u代替u的第一个非0列,更新矩阵c和向量rt,更新公式如下:
c=(i-u*ut)*z*zt*(i-u*ut);
rt=xt-u*ut*xt;
步骤2.5、由于rt的更新,矩阵z会随之更新,具体更新过程如下;
步骤2.5.1、先对矩阵z进行转置,矩阵z的第
步骤2.5.2、再对矩阵z进行svd分解,即[u1,σ1,v1]←svd(z),σ1为奇异矩阵,其中的奇异值从大到小排列;
步骤2.5.3、按照公式c1=σ1v1和
步骤2.5.4、按照公式
步骤2.5.5、输出更新后的矩阵z:
步骤2.6、低维输出:对于矩阵u中每一个非零列u,其元素按公式(wu)u=(wu)u+<xt,u>2更新,(wu)u为向量wu在u方向上的投影,并进行低维输出st=ut*xt,并结束for循坏;
作为本发明进一步的方案,所述步骤3包括如下步骤:
步骤2中将高维数据进行降维,降维之后用s={s1,s2,…,sn}表示,其中st为
步骤3.1、将训练数据作为输入,训练标签作为输出,训练分类模型,根据方程|wx+b|=1建立两边支持向量,该算法在训练过程中需要满足支持向量间距离尽可能大,这样可以对采样数据实现有效分类;
步骤3.2、根据方程wx+b=0在两支持向量中间寻找最优超平面,最优超平面可以保证将不同类别的采样数据通过最优超平面分类;
步骤3.3、如果采样数据线性不可分,则通过选取核函数将采样数据映射到更高维的特征空间中,这样在高维空间中映射的采样数据就可以满足线性可分;
步骤3.4、模型训练完成后通过计算得到最优的w和b,即最优超平面,将测试数据集代入,并输出其测试标签。
本发明的有益效果是:一种基于增量pca的工业监测数据分类方法,分别通过建立降维模型和传统的svm分类模型,可对有标签的高维数据进行分类;该方法在保证计算量的同时,通过寻找最优超平面,对线性数据和非线性数据都可以进行二分类;对于工业监测系统而言,本发明可以通过对采样数据进行分类,可将其用于工业系统的故障检测,从而及时反映机器性能,能够采取相应措施,这样就可以避免一系安全事故。
附图说明
图1是本发明总体流程图;
图2是本发明方法中步骤2的在线降维方法的流程图。
图3是本发明方法中步骤3中的支持向量机流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的阐述。
如图1~图3所示,一种基于增量pca的工业监测数据分类方法,具体按照以下步骤实施:
步骤1、对工业监测数据进行采集,按采样顺序排列,并记录其数据标签,将其分为训练集和测试集;
步骤1.1、对工业系统中的传感器进行数据采样,假设采样数据为有标签数据。采集到的工业监测高维数据用x={x1,x2,…,xn}∈rd×n表示,其中d表示高维数据的维数,每间隔1s进行一次采样,n表示采样数据的数目。第t个采样数据用xt表示,t∈{1,2,...,n},xt=[xt1xt2…xtd]t;
步骤1.2、对采样数据进行分配,采样数据的标签信息用y={y1,y2,...,yn}∈r1×n表示,与高维数据x一一对应。选取高维数据x和数据标签y的前百分之八十作为训练数据集和训练标签,剩下百分之二十作为测试数据集和测试标签。
步骤2、基于增量pca方法建立模型,分别对步骤1中的训练集和测试集进行在线降维;
步骤2.1、输入:高维数据x和所需参数:离线降维目标维数k<d,在线降维目标维数
步骤2.2、对矩阵u、矩阵z以及各参数进行初始化:矩阵u和z为
步骤2.3、进入for循环:当接收到第t个采样数据xt时,对参数w、残差rt和矩阵c进行更新,更新公式如下所示,而对于每个采样数据xt,其低维(
rt=xt-u*ut*xt;
c=(i-u*ut)*z*zt*(i-u*ut);
步骤2.4、对初始矩阵和参数进行设置,判断是否更新矩阵c和向量rt,具体按照以下步骤实施:
步骤2.4.1、对初始矩阵和参数进行设置后,判断是否满足条件式
步骤2.4.2、先对矩阵c进行特征值分解,其最大特征值和其相对应的特征向量分别用λ、u表示,并将特征值λ赋给(wu)u;
步骤2.4.3、判断u中是否有非零列,如果有,用特征向量u代替u的第一个非0列,更新矩阵c和向量rt,更新公式如下:
c=(i-u*ut)*z*zt*(i-u*ut);
rt=xt-u*ut*xt;
步骤2.5、由于rt的更新,矩阵z会随之更新,具体更新过程如下;
步骤2.5.1、先对矩阵z进行转置,矩阵z的第
步骤2.5.2、再对矩阵z进行svd分解,即[u1,σ1,v1]←svd(z),σ1为奇异矩阵,其中的奇异值从大到小排列;
步骤2.5.3、按照公式c1=σ1v1和
步骤2.5.4、按照公式
步骤2.5.5、输出更新后的矩阵z:
步骤2.6、低维输出:对于矩阵u中每一个非零列u,其元素按公式(wu)u=(wu)u+<xt,u>2更新,(wu)u为向量wu在u方向上的投影,并进行低维输出st=ut*xt,并结束for循坏;
步骤3、基步骤2中的训练集作为数据对象建立支持向量机svm分类模型,并通过对测试集数据进行分类验证该模型:
步骤2中将高维数据进行降维,降维之后用s={s1,s2,…,sn}表示,其中st为
步骤3.1、将训练数据作为输入,训练标签作为输出,训练分类模型,根据方程|wx+b|=1建立两边支持向量,该算法在训练过程中需要满足支持向量间距离尽可能大,这样可以对采样数据实现有效分类;
步骤3.2、根据方程wx+b=0在两支持向量中间寻找最优超平面,最优超平面可以保证将不同类别的采样数据通过最优超平面分类;
步骤3.3、如果采样数据线性不可分,则通过选取核函数将采样数据映射到更高维的特征空间中,这样在高维空间中映射的采样数据就可以满足线性可分;
步骤3.4、模型训练完成后通过计算得到最优的w和b,即最优超平面,将测试数据集代入,并输出其测试标签。
步骤3中采用的是传统的svm分类方法,该方法是机器学习中常见的分类方法。该方法对线性可分的数据十分有效,如果不满足该条件,则需要通过核函数将输入数据映射到高维特征空间中,建立最优模型,这样有利于寻找最优超平面,使采样数据在该特征空间中可通过最优超平面最大程度地进行分类。
本发明一种基于增量pca的工业监测数据分类方法,通过对降维数据进行分类,进而可以判断降维方法的有效性,也即降维过程中保留数据特征信息的多少。如果方法有效,分类效果就会良好;反之,分类效果会较差。而分类是机器学习中重要的研究领域,对于工业系统中的故障检测以及文本分类等都具有非凡的意义。
以上所述为本发明较佳实施例,对于本领域的普通技术人员而言,根据本发明的教导,在不脱离本发明的原理与精神的情况下,对实施方式所进行的改变、修改、替换和变型仍落入本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!