基于MMC的STATCOM控制器自适应动态规划方法与流程
本申请涉及电力系统技术领域,尤其涉及一种基于mmc的statcom控制器自适应动态规划方法。
背景技术:
静止同步补偿器(staticsynchronouscompensator,statcom)作为一种无功功率补偿装置可有效改善系统电压水平和提高功率因数,是柔性交流输电系统的重要设备;随着电力系统的规模不断扩大,对补偿装置的容量和电压等级要求越来越高,statcom往高压大功率方向发展已成为一种趋势。
目前,绝大部分的statcom控制器是基于数学模型设计的pid/pi控制器。该方法对控制对象精确数学模型有较强的依赖性,因此,基于数学模型设计的pid/pi控制器普遍存在响应速度与稳定性相矛盾的问题,控制器的适应性和鲁棒性较差。特别电网出现三相不平衡或者故障时在statcom暂态控制时,需要statcom准确快速的响应电网要求的时候,statcom的表现往往很难令人满意,有时候甚至会因为调节速度慢,干扰电网的正常运行。从而使得statcom的利用率大打折扣。
模块化多电平换流器(modularmultilevelconverter,mmc)具有高度模块化的特点,通过增加功率单元数量,即可实现主电路扩容,且输出电平数目较多,对交流电网的谐波影响小。基于mmc结构的statcom在电能质量治理领域中,高度模块化的特性使其能够比较容易的实现高压大功率,是一种很有应用前景的治理装置。然而,基于mmc的statcom系统是一多重耦合的非线性系统,很难给出其准确的数学模型,因而系统精确模型难以建立,因此基于mmc的statcom控制器不能够自适应实际电网工况的变化,鲁棒性较差。
技术实现要素:
本申请提供了一种基于mmc的statcom控制器自适应动态规划方法,以根据电网工况变化在线实时调整参数,提高控制器的鲁棒性。
为了解决上述技术问题,本申请实施例公开了如下技术方案:
本申请提供的基于mmc的statcom控制器自适应动态规划方法,基于mmc结构的statcom包括目标网络、执行网络及评价网络,所述方法包括:
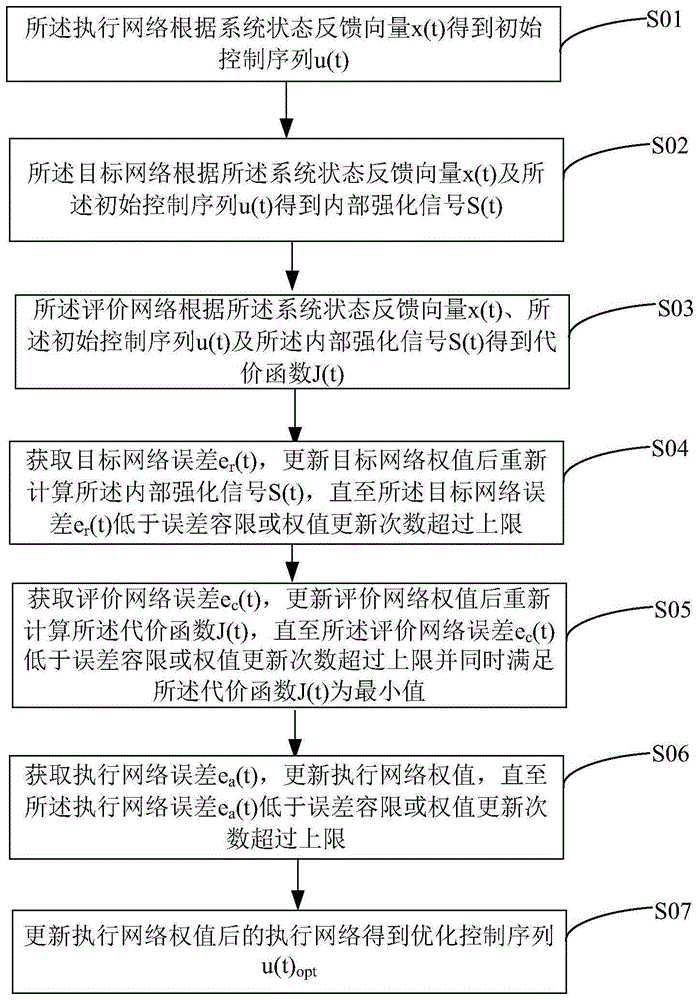
所述执行网络根据系统状态反馈向量x(t)得到初始控制序列u(t);
所述目标网络根据所述系统状态反馈向量x(t)及所述初始控制序列u(t)得到内部强化信号s(t);
所述评价网络根据所述系统状态反馈向量x(t)、所述初始控制序列u(t)及所述内部强化信号s(t)得到代价函数j(t);
获取目标网络误差er(t),更新目标网络权值后重新计算所述内部强化信号s(t),直至所述目标网络误差er(t)低于误差容限或权值更新次数超过上限;
获取评价网络误差ec(t),更新评价网络权值后重新计算所述代价函数j(t),直至所述评价网络误差ec(t)低于误差容限或权值更新次数超过上限并同时满足所述代价函数j(t)为最小值;
获取执行网络误差ea(t),更新执行网络权值,直至所述执行网络误差ea(t)低于误差容限或权值更新次数超过上限;
更新执行网络权值后的执行网络得到优化控制序列u(t)opt。
优选地,所述执行网络根据系统状态反馈向量x(t)得到初始控制序列u(t)包括:
将所述系统状态反馈向量x(t)代入执行网络得到输出量初始控制序列u(t)。
优选地,所述目标网络根据所述系统状态反馈向量x(t)及所述初始控制序列u(t)得到内部强化信号s(t)包括:
根据s(t)=r(t)+αs(t+1)得到内部强化信号s(t),其中r(t)为t时刻的reward值,s(t+1)为t+1时刻的内部强化信号,α为折合因子。
优选地,所述评价网络根据所述系统状态反馈向量x(t)、所述初始控制序列u(t)及所述内部强化信号s(t)得到代价函数j(t)包括:
根据j(t)=s(t)+γj(t+1)得到代价函数j(t),其中s(t)为t时刻的内部强化信号,j(t+1)为t+1时刻的代价函数,γ为折合因子。
优选地,所述获取目标网络误差er(t)包括:
根据
优选地,所述获取评价网络误差ec(t)包括:
根据
优选地,所述获取执行网络误差ea(t)包括:
根据
与现有技术相比,本申请的有益效果为:
本申请提供的基于mmc的statcom控制器自适应动态规划方法中,执行网络根据系统状态反馈向量自动得到初始控制序列,其中系统状态反馈向量可以取系统中三相交流电流、每相的子模块电容电压及三相环流等;目标网络自动生成内部强化信号以替代外部强化信号,评价网络得到代价函数;分别获取目标网络误差、执行网络误差及评价网络误差,根据相应的误差更新目标网络、执行网络及评价网络权值,直至网络误差低于误差容限或权值更新次数超过上限并同时满足代价函数为最小值,当代价函数为最小值时此时的控制输入序列最优,即系统状态轨迹最优,此时返回至执行网络将更新后的输入量输入得到优化控制序列,在根据误差调整和更新网络权值的过程中,优化控制序列对比初始控制序列得到了更新和优化,从而优化了控制效果;本申请提供的基于mmc的statcom控制器在不依赖精确模型的前提下,基于数据驱动的自适应动态规划算法设计控制器;该控制器可根据工况变化在线调整参数,实现多给定无功功率、电压实时跟踪,子模块电容均压及环流抑制的多目标优化,保障statcom快速准确的响应系统要求,提高statcom的利用率。该方法相比传统的pid/pi控制器具有更好的鲁棒性,能够自适应实际电网工况的变化。因而,本申请提供的基于mmc的statcom控制器同时具有更快的响应速度、更小的超调、更快的达到稳态、更大的阻尼。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本申请。
附图说明
为了更清楚地说明本申请的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例中的基于mmc的statcom控制器自适应动态规划方法的流程示意图;
图2为本发明实施例中的基于mmc的statcom控制器执行网络的结构示意图;
图3为本发明实施例中的基于mmc的statcom控制器目标网络的结构示意图;
图4为本发明实施例中的基于mmc的statcom控制器评价网络的结构示意图;
图5为本发明实施例中的基于mmc的statcom控制器自适应动态规划方法的应用过程示意图;
图6为本发明实施例中的基于mmc的statcom控制器的控制系统结构示意图。
具体实施方式
为了使本技术领域的人员更好地理解本申请中的技术方案,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本申请保护的范围。
现有的statcom控制器是基于数学模型设计的pid/pi控制器,该控制器是一种线性控制器,可根据给定值与实际输出值构成控制偏差,将偏差的比例和积分通过线性组合构成控制量,对控制对象进行控制。该方法对控制对象精确数学模型有较强的依赖性,因此,基于数学模型设计的pid/pi控制器普遍存在响应速度与稳定性相矛盾的问题,控制器的适应性和鲁棒性较差。
本申请提供的基于mmc的statcom控制器自适应动态规划方法,基于mmc结构的statcom包括目标网络、执行网络及评价网络,具体方法参考图1,图1为本发明实施例中的基于mmc的statcom控制器自适应动态规划方法的流程示意图;可同时结合图5,图5为本发明实施例中的基于mmc的statcom控制器自适应动态规划方法的应用过程示意图;如图1所示,所述方法包括:
s01:所述执行网络根据系统状态反馈向量x(t)得到初始控制序列u(t);执行网络的运行过程参考图2,图2为本发明实施例中的基于mmc的statcom控制器执行网络的结构示意图;如图2所示,将所述系统状态反馈向量x(t)代入执行网络得到输出量初始控制序列u(t)。系统状态反馈向量x(t)可以为系统三相交流电流,每相的子模块电容电压及三相环流等,初始控制序列u(t)可为各子模块开关状态。
s02:所述目标网络根据所述系统状态反馈向量x(t)及所述初始控制序列u(t)得到内部强化信号s(t);以内部强化信号来代替外部强化信号,目标网络的运行过程参考图3,图3为本发明实施例中的基于mmc的statcom控制器目标网络的结构示意图,如图3所示,根据s(t)=r(t)+αs(t+1)得到内部强化信号s(t),其中r(t)为t时刻的reward值,s(t+1)为t+1时刻的内部强化信号,α为折合因子。
在强化学习里reward表示在当前状态使用当前控制的好坏程度,因此需要环境对所研究的问题有一定的先验知识,这样才能给出合适的reward,因此需要内部强化信号替代外部强化信号,目标网络形成一个自适应的内部强化信号,更好地调节输入-输出之间的映射关系,极大改善statcom暂态控制时的动态性能和控制效果。
s03:所述评价网络根据所述系统状态反馈向量x(t)、所述初始控制序列u(t)及所述内部强化信号s(t)得到代价函数j(t);评价网络的运行过程参考图4,图4为本发明实施例中的基于mmc的statcom控制器评价网络的结构示意图,如图4所示,根据j(t)=s(t)+γj(t+1)得到代价函数j(t),其中s(t)为t时刻的内部强化信号,j(t+1)为t+1时刻的代价函数,γ为折合因子。
α与γ为折合因子。以γ为例,γ表征未来的回报对于当前回报的重要程度。当γ取0时表示只考虑即时回报,不考虑长期回报;当γ取1时表示即时回报与长期回报同等看待。
代价函数j(t)为优化目标,通常由当前状态到稳态所经历的每个时刻的reward之和构成。最小的j(t)对应着最优的控制输入序列,也就对应着最优的系统状态轨迹。
代价函数j(t)是根据所研究问题的目的而设计的,要求代价函数j(t)达到最小值是为了使状态变量x(t)与控制输入u(t)尽可能快的收敛到0,波动尽可能小。
s04:获取目标网络误差er(t),更新目标网络权值后重新计算所述内部强化信号s(t),直至所述目标网络误差er(t)低于误差容限或权值更新次数超过上限;
根据
本申请中定义了目标网络误差er(t),之所以定义er(t)目的是保证目标网络误差为正数,保证后续的计算。
当目标网络误差er(t)为零时,目标网络的输出能很好地逼近未来所有外部强化信号的总和,从而优化控制器输出序列。
s05:获取评价网络误差ec(t),更新评价网络权值后重新计算所述代价函数j(t),直至所述评价网络误差ec(t)低于误差容限或权值更新次数超过上限并同时满足所述代价函数j(t)为最小值;根据
最终的控制目标为最小化代价函数j(t),通过修改网络权值调节输出控制量u(t),从而形成最优控制。
s06:获取执行网络误差ea(t),更新执行网络权值,直至所述执行网络误差ea(t)低于误差容限或权值更新次数超过上限;根据
在实际运行中根据实际仿真情况对误差容限和权值更新次数进行选择,一般误差容限取10^-6,权值更新次数一般不超过2000次。
各网络利用误差反向传播(errorbackpropagation,bp)算法修改网络权值,从而形成一个最优控制序列u(t),使得代价函数j(t)达到最小值,即:
s07:更新执行网络权值后的执行网络得到优化控制序列u(t)opt。
在根据误差调整和更新网络权值的过程中,优化控制序列对比初始控制序列得到了更新和优化,从而优化了控制效果。该控制器实现了可根据工况变化在线调整参数,实现多给定无功功率、电压实时跟踪,子模块电容均压及环流抑制的多目标优化,保障statcom快速准确的响应系统要求
学习好的控制器放到实际工程中,主要完成statcom装置级的控制,该部分控制是stacom的核心控制部分。无论statcom工作在定电压还是定无功的控制模式下,所设计的stacom自适应控制器在收到经电压电流双环解耦控制生成的输出目标电压指令后,通过控制网络产生statcom子模块调制信号。子模块阀控系统则根据调制信号驱动statcom各个子模块。同时,实时反馈系统运行状态至双环解耦控制环节,根据电网实际运行情况不断调整stacom输出目标指令,构成一个完整的闭环控制。整个过程的控制框图如图6所示,图6为本发明实施例中的基于mmc的statcom控制器的控制系统结构示意图。该控制器可对statcom实际运行数据进行学习,并不断调整优化控制器参数,使其达到最理想的控制效果。
综上,本申请提供的基于mmc的statcom控制器自适应动态规划方法中,执行网络根据系统状态反馈向量自动得到初始控制序列,其中系统状态反馈向量可以取系统中三相交流电流、每相的子模块电容电压及三相环流等;目标网络自动生成内部强化信号以替代外部强化信号,评价网络得到代价函数;分别获取目标网络误差、执行网络误差及评价网络误差,根据相应的误差更新目标网络、执行网络及评价网络权值,直至网络误差低于误差容限或权值更新次数超过上限并同时满足代价函数为最小值,当代价函数为最小值时此时的控制输入序列最优,即系统状态轨迹最优,此时返回至执行网络将更新后的输入量输入得到优化控制序列,在根据误差调整和更新网络权值的过程中,优化控制序列对比初始控制序列得到了更新和优化,从而优化了控制效果;本申请提供的基于mmc的statcom控制器在不依赖精确模型的前提下,基于数据驱动的自适应动态规划算法设计控制器;该控制器可根据工况变化在线调整参数,实现多给定无功功率、电压实时跟踪,子模块电容均压及环流抑制的多目标优化,保障statcom快速准确的响应系统要求,提高statcom的利用率。该方法相比传统的pid/pi控制器具有更好的鲁棒性,能够自适应实际电网工况的变化。因而,本申请提供的基于mmc的statcom控制器同时具有更快的响应速度、更小的超调、更快的达到稳态、更大的阻尼。
由于以上实施方式均是在其他方式之上引用结合进行说明,不同实施例之间均具有相同的部分,本说明书中各个实施例之间相同、相似的部分互相参见即可。在此不再详细阐述。
本领域技术人员在考虑说明书及实践这里发明的公开后,将容易想到本申请的其他实施方案。本申请旨在涵盖本发明的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本申请的一般性原理并包括本申请未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本申请的真正范围和精神由权利要求的内容指出。
以上所述的本申请实施方式并不构成对本申请保护范围的限定。
- 还没有人留言评论。精彩留言会获得点赞!