一种基于动态关联规则挖掘的工业过程异常工况预测方法与流程
本发明属于可靠性维护工程
技术领域:
,涉及一种基于动态关联规则挖掘的工业过程异常工况预测方法。
背景技术:
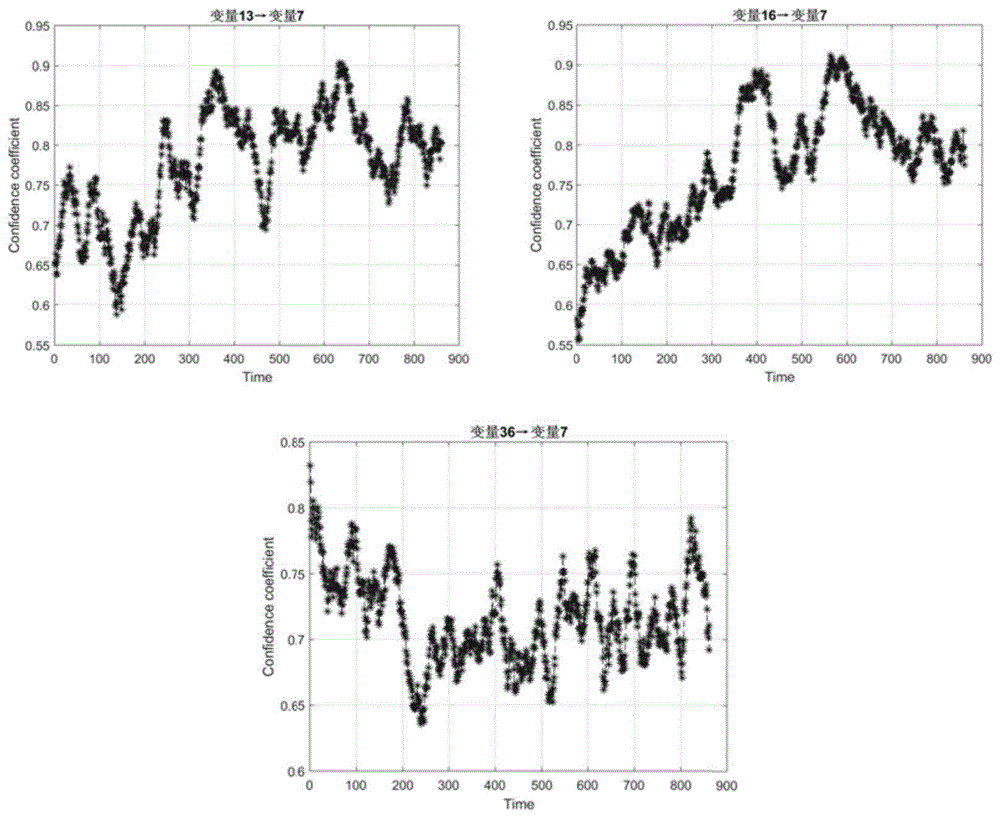
:随着复杂系统的不断出现以及工业过程实时监测的需求不断增加,现代工业设备在运行过程中往往配备多个传感器对其运行状态进行监测。同时,设备运行过程中可能会出现多种故障模式,某一故障可能对应若干征兆,在此情况下,单传感器信息已无法完全体现设备运行状态,基于多传感器信息的故障预测应运而生。基于多传感器信息的故障预测旨在利用全面的传感器信息分析设备的运行状态,从而进行更可靠的设备诊断和预测。随着传感技术的持续发展,使用多个传感器进行设备的状态监测、故障诊断和预测已经成为发展趋势。设备运行过程中其运行参数之间存在一定关联性,在故障预测领域,目前仍鲜有将关联规则挖掘与故障预测相结合的工作。传统的关联规则挖掘算法认为,对于某一对象系统所发现的关联规则是不变的即在分析该系统其他数据集时也是有效的。如此挖掘出来的关联规则并没有考虑到时间因素,由此得到的是一种静态的关联规则。而实际上,随着数据的更新,可能伴随着系统运行状态的变化,随之而来的是数据特性的变化,从而关联规则也可能发生变化。在工业设备运行过程中,运行状态并不是固定不变的。随着数据的更新或当设备运行状态发生变化,其运行参数的特性也会随之变化,从而运行参数的关联性也可能发生了变化。在此情况下,若一直使用从最初的数据集中挖掘得到的关联规则来指导后续决策显然是不合理的。技术实现要素:针对现有技术的现状,本发明的目的是解决现有数据驱动的预测技术中鲜有考虑传感器数据动态关联的情况,提出一种基于运行参数动态关联规则的设备异常工况预测方法,利用动态关联规则更新小波神经网络并进行异常工况预测(故障预测)。现将本发明的构思阐述如下:本发明针对工业设备运行过程中运行参数之间的关联性可能随设备运行状态的变化而发生变化的问题,引入了动态关联规则挖掘。本发明利用滑动窗口的方式,对每一个窗口内的数据进行关联规则挖掘,从而随着窗口的滑动得到动态变化的关联规则。为得到参数关联性的完整变化情况,本发明所提方法在参数层面的关联规则挖掘时并没有设置最小支持度和置信度阈值,而是保存所有两两参数的关联规则,并以支持度和置信度描述其强度。随后,将动态关联规则挖掘结果引入小波神经网络的训练和更新中,通过由动态关联规则挖掘获得的关联参数进行异常工况预测。根据以上发明构思,本发明提出了一种基于动态关联规则挖掘的工业过程异常工况预测方法,具体步骤如下:步骤1:基于滑动窗口对工业过程中传感器所采集的测量值时间序列进行数据预处理,对时间序列进行分段线性化表示、聚类、符号化,生成适用于关联规则挖掘的事务集;步骤2:采用两阶段的频繁项集产生策略生成频繁项集,并挖掘两两参数的关联规则;步骤3:利用初始数据集进行关联规则挖掘,基于初始关联规则挖掘结果,训练初始小波神经网络模型;步骤4:基于数据更新进行数据窗口的滑动,对于新数据窗口进行关联规则更新和小波神经网络模型更新;步骤5:基于更新的小波网络模型进行异常工况预测,并在预测到异常工况发生前不断更新关联规则和小波神经网络模型。基于上述方案,各步骤可具体采用如下实现方式:作为优选,所述的步骤1具体通过如下子步骤实现:步骤1.1:记传感器测量序列为n为传感器数量,k为序列长度,k=1,2,…,k;记滑动窗口长度为l,每次滑动距离设为l,将滑动窗口记为wk,窗口中包含的数据为步骤1.2:对于每一数据窗口进行时间序列分段线性化表示、聚类、符号化处理,具体过程如下:对每一个数据窗口wk执行1.2.1~1.2.5过程:1.2.1.设置初始拟合起点为终点为h=2;拟合误差阈值为ωe;初始化分段点计数值count=1;1.2.2.依次对每个拟合起点执行步骤1.1)-步骤1.4):1.1)首先计算end=start+h;1.2)对于数据利用最小二乘法进行拟合,计算拟合误差err;1.3)若拟合误差err不大于拟合误差阈值ωe,则h=h+1,重新跳转至步骤1);1.4)若拟合误差err大于拟合误差阈值ωe,则保存分段点至pi;保存拟合线段采用三元组的方式表示该拟合线段并保存至ki表示该线段的斜率,表示该线段在时间轴上的跨度,ri表示该线段数据的增长率;重置拟合起点start=start+h,重置h=2;更新count=count+1;1.2.3.循环执行1.2.2直到end大于k+l-1结束,得到拟合后的线段化时间序列和分段点组成的分段点序列pi;1.2.4.以wk-1窗口的聚类中心为初始聚类中心,采用k-means聚类算法对三元组序列进行聚类,并为不同类的线段分配不同符号得到符号化序列其中聚类过程中采用基于欧氏距离的指标描述两条线段si和sj之间的相似度:其中,dij即表示线段si和sj的相似度,dij越小,则表示两条线段有更相似的变化形态,ωk和ωr表示权重;1.2.5.对于两个运行参数vi和vj,分别得到符号化后的序列和合并两个运行参数的分段点序列pi和pj,并按合并后的分段点对其符号化序列和进行分割重构,得到重构后的符号化序列和由其构成事务集,nij-1为pi和pj合并后的分段点个数。作为优选,所述的步骤2具体通过如下子步骤实现:步骤2.1:由步骤1获得的事务集的每一事务记为另将和中所包含的线段类别符号分别记为和mi和mj分别为和中所包含的线段类别数;设频繁项集产生过程的最小支持度阈值为minsup1;步骤2.2:对于初始数据窗口w1进行关联规则挖掘,其具体过程如下:2.2.1)对所有传感器的传感器测量序列数据集进行扫描以计算每个项的支持度,记σ(·)表示某项或项集的支持度计数,初始为0;假设的类别符号为tk,e表示i或j,t表示c或d;对每一个计算σ(tk)=σ(tk)+1;对每一个tk,判断是否成立,若成立则认为tk为频繁1-项集,保留tk并记录相应的支持度计数σ(tk);2.2.2)使用已得到的频繁1-项集tk构成2-项集,并发现频繁2-项集,分别记cp和dq分别为经过步骤2.2.1)从原线段类别符号和中保留的项;对于每一个{cp,dq}执行操作:对每一个存在于中的{cp,dq},计算σ({cp,dq})=σ({cp,dq})+1;如果不小于minsup1,则认为{cp,dq}为频繁2-项集,保留{cp,dq}并记录相应的支持度计数;2.2.3)使用步骤2.2.2中获得的频繁2-项集{cp,dq}计算每两个运行参数vi和vj在整个数据集中的支持度,计算过程如下:对每两个运行参数vi和vj构成的项集{vi,vj},计算σ({vi,vj})=sum(σ({cp,dq})),两个参数的关联规则支持度并计算σ(vi)=sum(σ(cp));σ(vj)=sum(σ(dq));2.2.4)对于每组{vi,vj},产生如下关联规则:vj→vi和vi→vj;对于每一个关联规则,计算其置信度为步骤2.3:对于每一个新的数据窗口,采用以下过程进行频繁项集产生并生成关联规则:对每一个k>1的数据窗口wk执行步骤2.3.1)~2.3.3):2.3.1)对每一滑出窗口的事务记为{ca1,da2},判断{ca1,da2}是否为频繁项集,若是则更新σ({ca1,da2})=σ({ca1,da2})-1;2.3.2)对每一滑入窗口的事务记为{cb1,db2},判断{cb1,db2}是否为频繁项集,若是,则更新σ({cb1,db2})=σ({cb1,db2})+1,若否,则在数据窗口wk内计算该{cb1,db2}的支持度计数为σ({cc1,dc2});2.3.3)对每一个{ca1,da2},若则更新{ca1,da2}相应项集的支持度计数,若不满足则剔除相应项集;对每一个{cb1,db2},若则更新{cb1,db2}相应项集的支持度计数,若不满足则剔除相应项集;对每一个{cc1,dc2},若则更新{cc1,dc2}相应项集的支持度计数,若不满足则剔除相应项集;2.3.4)利用步骤2.2.3)和2.2.4)更新每一关联规则的支持度和置信度。作为优选,所述的步骤3具体通过如下子步骤实现:记预设的预测步长为lp,由训练数据集挖掘到的关联规则中提取的一组关联参数为{v1,v2,…,vu},u为提取出的一组关联参数个数;对于每一参数vi,其测量值序列为构造以下矩阵itrain为初始的神经网络训练输入:其中,itrain中每一列为一个训练输入样本;构造训练输出otrain为,利用上述公式构造的训练样本,对小波神经网络进行训练;在网络初始化时,利用关联规则vi→vu对应的初始置信度ωi设置网络输入层和隐含层之间的初始权值,i=1,2,…u-1。作为优选,所述的步骤4具体通过如下子步骤实现:步骤4.1:关联规则更新做法为:记在设备运行过程中传感器已采集到的c个新数据为c>l;利用新采集到的数据中最近的l个数据通过步骤2.3更新关联规则,从而更新关联规则vi→vu所对应的置信度记为步骤4.2:模型更新做法为:结合训练数据以及新采集到的数据构造新的模型训练样本,即数据集为构造矩阵itest为神经网络更新的输入,构造otest为输出,利用上述公式构造新的训练样本,对小波神经网络进行训练;在网络初始化时,利用新的置信度设置网络输入层和隐含层之间的初始权值。作为优选,所述的步骤5具体通过如下子步骤实现:记预设的异常工况(失效)发生阈值为ωp,对于最新采集到的数据,利用步骤4中更新的模型进行lp步预测,若得到的目标参数预测值相对于初始正常的漂移量超过所设阈值,则认为异常工况发生。作为优选,在预测过程结束前,每更新预定数量的数据,就回到步骤4进行关联规则和模型的更新。本发明利用滑动窗口的方式挖掘工业设备运行参数动态关联规则,并将其引入工业过程异常工况预测中。本发明考虑关联规则的时间特性,利用滑动窗口限制数据长度,提出一种用于两两运行参数动态关联规则挖掘的关联规则挖掘算法,随后将关联规则挖掘结果引入小波神经网络预测中,以动态关联规则不断更新网络,以获得更为准确的预测结果。对于工程上的故障预测和健康管理有重大应用价值。附图说明图1为实施例中idv(13)关联规则(v13,v16,v36→v7)置信度变化曲线;图2为实施例中idv(13)关联规则(v35,v36→v11)置信度变化曲线;图3为实施例中idv(13)变量7预测结果;图4为实施例中idv(13)变量7预测误差;图5为实施例中idv(13)变量11预测结果;图6为实施例中idv(13)变量11预测误差。具体实施方式现结合附图对本发明的具体实施方式作进一步的说明。下面本实施例通过田纳西-伊斯曼(te)过程仿真数据来具体阐述具体操作步骤以及验证方法的效果。该数据集的采样间隔为3分钟,数据集记录了该采样间隔下各传感器采集到的变量测量值。在每一种运行条件下(正常运行状态以及21种预设故障下的故障运行状态),仿真过程的测量数据都将生成两类数据集,即训练集和测试集。其中,对于训练集的采集过程,是在仿真过程运行25个小时的情况下获得的所有52个变量的测量值,其中,除正常运行状态采集到的训练集外,其余21个训练集数据的采集是在仿真过程运行1小时候引入故障,并只记录随后24个小时的测量数据。也即是说,正常运行状态的训练集有500个观测样本,其余21个故障状态下采集的训练集均为480个观测样本。另外,对于22个测试集,其数据是仿真过程运行48个小时所采集到的所有变量测量值,也就是说,每一个测试集中包含960个样本数据。需要注意的是,在对21种过程故障进行仿真时,相应的故障是在仿真运行8小时后引入的。因此,对于21个故障运行状态下的测试集,其前160个观测样本为正常数据,后800个观察样本为故障数据。在te过程仿真模型中,只有idv(13)是一个缓变故障,因此,在本例中,我们使用idv(13)的相关数据进行实验。工业过程异常工况预测方法具体执行过程如下:步骤1:基于滑动窗口对工业过程中传感器所采集的测量值时间序列进行数据预处理,对时间序列进行分段线性化表示、聚类、符号化,生成适用于关联规则挖掘的事务集。本步骤具体通过如下子步骤实现:步骤1.1:记传感器测量序列为n为传感器数量,k为序列长度,k=1,2,…,k;记滑动窗口长度为l,每次滑动距离设为l,将滑动窗口记为wk,窗口中包含的数据为需要注意的是,在本发明中,i、j作为上标是表示传感器的编号,作为下标是仅表示序数,与传感器编号无关。步骤1.2:对于每一数据窗口进行时间序列分段线性化表示、聚类、符号化处理,具体过程如下:对每一个数据窗口wk执行1.2.1~1.2.5过程:1.2.1.设置初始拟合起点为终点为h=2;拟合误差阈值为ωe;初始化分段点计数值count=1;1.2.2.依次对每个拟合起点执行步骤1.1)-步骤1.4):1.1)首先计算end=start+h;1.2)对于数据利用最小二乘法进行拟合,计算拟合误差err;1.3)若拟合误差err不大于拟合误差阈值ωe,则h=h+1,重新跳转至步骤1);1.4)若拟合误差err大于拟合误差阈值ωe,则保存分段点至pi;保存拟合线段采用三元组的方式表示该拟合线段并保存至ki表示该线段的斜率,表示该线段在时间轴上的跨度,ri表示该线段数据的增长率;重置拟合起点start=start+h,重置h=2(重置拟合起点和h);更新count=count+1;1.2.3.循环执行1.2.2直到end大于k+l-1结束,得到最小二乘法拟合后的线段化时间序列(其中具有多条拟合线段)和分段点组成的分段点序列pi;1.2.4.以wk-1窗口的聚类中心为初始聚类中心,采用k-means聚类算法对三元组序列进行聚类,并为不同类的线段分配不同符号得到符号化序列其中聚类过程中采用基于欧氏距离的指标描述两条线段si和sj之间的相似度:其中,dij即表示线段si和sj的相似度,dij越小,则表示两条线段有更相似的变化形态,ωk和ωr表示权重;1.2.5.对于两个运行参数vi和vj,分别得到符号化后的序列和合并两个运行参数的分段点序列pi和pj,并按合并后的分段点对其符号化序列和进行分割重构,得到重构后的符号化序列和由其构成事务集,nij-1为pi和pj合并后的分段点个数。步骤2:采用两阶段的频繁项集产生策略生成频繁项集,并挖掘两两参数的关联规则。本步骤具体通过如下子步骤实现:步骤2.1:由步骤1获得的事务集的每一事务记为另将和中所包含的线段类别符号分别记为和mi和mj分别为和中所包含的线段类别数;设频繁项集产生过程的最小支持度阈值为minsup1;在本例中,设置最小支持度阈值为0.2;步骤2.2:对于初始数据窗口w1进行关联规则挖掘,其具体过程如下:2.2.1)对所有传感器的传感器测量序列数据集进行扫描以计算每个项的支持度,记σ(·)表示某项或项集的支持度计数,初始为0;假设的类别符号为tk,e表示i或j,t表示c或d(即ck或dk);对每一个更新计算σ(tk)=σ(tk)+1;对每一个tk,判断是否成立,若成立则认为tk为频繁1-项集,保留tk并记录相应的支持度计数σ(tk);2.2.2)使用已得到的频繁1-项集tk构成2-项集,并发现频繁2-项集,分别记cp和dq分别为经过步骤2.2.1)从原线段类别符号和中保留的项;对于每一个{cp,dq}执行操作:对每一个存在于中的{cp,dq},计算σ({cp,dq})=σ({cp,dq})+1;如果不小于minsup1,则认为{cp,dq}为频繁2-项集,保留{cp,dq}并记录相应的支持度计数;2.2.3)使用步骤2.2.2中获得的频繁2-项集{cp,dq}计算每两个运行参数vi和vj在整个数据集中的支持度,计算过程如下:对每两个运行参数vi和vj构成的项集{vi,vj},计算σ({vi,vj})=sum(σ({cp,dq})),两个参数的关联规则支持度并计算σ(vi)=sum(σ(cp));σ(vj)=sum(σ(dq));2.2.4)对于每组{vi,vj},产生如下关联规则:vj→vi和vi→vj;对于每一个关联规则,计算其置信度为在本例中,对于idv(13),通过训练集挖掘初始的关联规则。设置支持度阈值为0.2,置信度阈值0.7,得到几组不同的关联规则,其结果可见表1,其中包含两组关联参数,即(变量13,变量16,变量36→变量7)和(变量35,变量36→变量11)。步骤2.3:对于每一个新的数据窗口,采用以下过程进行频繁项集产生并生成关联规则。在本例中,设置动态关联规则挖掘的滑动窗口长度为100,且每次滑动1个数据点。对每一个k>1的数据窗口wk执行步骤2.3.1)~2.3.3):2.3.1)对每一滑出窗口的事务记为{ca1,da2},判断{ca1,da2}是否为频繁项集,若是则更新σ({ca1,da2})=σ({ca1,da2})-1;2.3.2)对每一滑入窗口的事务记为{cb1,db2},判断{cb1,db2}是否为频繁项集,若是,则更新σ({cb1,db2})=σ({cb1,db2})+1,若否,则在数据窗口wk内计算该{cb1,db2}的支持度计数为σ({cc1,dc2});2.3.3)对每一个{ca1,da2},若则更新{ca1,da2}相应项集的支持度计数,若不满足则剔除相应项集;对每一个{cb1,db2},若则更新{cb1,db2}相应项集的支持度计数,若不满足则剔除相应项集;对每一个{cc1,dc2},若则更新{cc1,dc2}相应项集的支持度计数,若不满足则剔除相应项集;2.3.4)利用步骤2.2.3)和2.2.4)更新每一关联规则的支持度和置信度。利用idv(13)的测试集,从第100个点开始,每更新1个采样数据,本例就用包括这个点的前100个点来挖掘关联规则,得到的置信度变化情况如图1和图2所示。由图可知,关联规则(置信度)随着数据的更新在不断变化,但对于idv(13)的这两组参数,其数值均保持在一个较高的水平。步骤3:利用初始数据集进行关联规则挖掘,基于初始关联规则挖掘结果,训练初始小波神经网络模型。本步骤具体通过如下子步骤实现:记预设的预测步长为lp,在本例中为10。由训练数据集挖掘到的关联规则中提取的一组关联参数为{v1,v2,…,vu},u为提取出的一组关联参数个数;对于每一参数vi,其测量值序列为构造以下矩阵itrain为初始的神经网络训练输入:其中,itrain中每一列为一个训练输入样本;构造训练输出otrain为,利用上述公式构造的训练样本,对小波神经网络进行训练;在网络初始化时,利用关联规则vi→vu对应的初始置信度ωi设置网络输入层和隐含层之间的初始权值,i=1,2,…u-1。步骤4:基于数据更新进行数据窗口的滑动,对于新数据窗口进行关联规则更新和小波神经网络模型更新。本步骤具体通过如下子步骤实现:步骤4.1:关联规则更新做法为:记在设备运行过程中传感器已采集到的c个新数据为c>l;利用新采集到的数据中最近的l个数据通过步骤2.3更新关联规则,从而更新关联规则vi→vu所对应的置信度记为需要注意的是,其中c需大于预设的滑动窗口长度l。也就是说,仅当设备开始运行且采集到的数据长度大于l时,才开始进行关联规则的更新。步骤4.2:模型更新做法为:结合训练数据以及新采集到的数据构造新的模型训练样本,即数据集为构造矩阵itest为神经网络更新的输入,构造otest为输出,利用上述公式构造新的训练样本,对小波神经网络进行训练;在网络初始化时,利用新的置信度设置网络输入层和隐含层之间的初始权值。在本例中,利用测试集的前300个数据,每更新10个数据,便对关联规则和模型进行更新。步骤5:基于更新的小波网络模型进行异常工况预测,并在预测到异常工况发生前不断更新关联规则和小波神经网络模型。本步骤具体通过如下子步骤实现:记预设的异常工况(失效)发生阈值为ωp,本例中异常工况(失效)发生的阈值为ωp=0.015。对于最新采集到的数据,利用步骤4中更新的模型进行lp步预测,若得到的目标参数预测值相对于初始正常的漂移量超过所设阈值,则认为异常工况发生。在预测过程结束前,每更新u个数据则回到步骤4进行关联规则和模型的更新,u的数值可以调整,本例中u为10。表1关联规则规则前项规则后项置信度变量13变量70.7527变量16变量70.7446变量36变量70.7017变量35变量110.7513变量36变量110.7390表2总预测误差率引入动态关联规则引入关联规则未引入关联规则变量70.76021.02471.7423变量110.80750.83091.1884本例为验证本章所用方法的有效性,将引入动态关联规则的预测结果与未引入关联规则以及引入静态关联规则的情况进行对比,预测结果和预测误差的对比见图3-图6。在图3和图5中,竖实线为在预设的失效阈值下的实际失效时刻,竖点划线为引入动态关联规则的失效时刻预测值,竖虚线为引入静态关联规则的失效时刻预测值,竖点线为未引入关联规则的失效时刻预测值。另外,为了更好地量化预测误差,本例计算两个参数预测在不同条件下的总误差率,如表2所示。从预测结果(图3和图5)来看,与另外两种情况相比,引入动态关联规则可以获得更准确的异常工况预测结果,尤其是与未引入关联规则的情况相比,从预测曲线中便可看出引入动态关联规则具有明显优势。需要注意的是,在图5中,引入静态关联规则以及未引入关联规则的情况下的预测值与真实值出现了较大的偏差,这其实是由于该参数的失效实际值正好处于某一极值点,故若在此处存在细微的预测误差便会导致异常工况预测结果出现较大偏差。实际上,可以设置多个不同的越限阈值对参数进行监测,以避免这样的情况带来的风险。另外,从预测误差的角度(图4和图6)来看,与引入静态关联规则的情况相比,引入动态关联规则可以在一定程度上减小预测误差,从表2可以看出,对于变量7,引入动态关联规则的提升效果较为明显,而对于变量11,由于关联规则变化并不大,所以其效果并不显著;与未引入关联规则的情况相比,从图4和图6中可以看出引入动态关联规则可以明显降低预测误差,由表2也可以更直观得看出引入动态关联规则相较于未引入关联规则具有明显优势。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1