一种基于滚动博弈的自动驾驶车辆换道决策方法及系统与流程
本发明涉及自动驾驶车辆行为决策博弈领域,特别涉及一种基于滚动博弈的自动驾驶车辆换道决策方法及系统。
背景技术:
自动驾驶汽车所处的交通环境和执行任务多变且具有非确定性,这给复杂工况下的自动驾驶决策带来了巨大挑战。首先,自动驾驶车辆运动学和动力学模型中参数的不确定带来了模型误差;其次,在开放道路上,不仅有其他机动车辆,还有一些其他例如行人等智能体,这些智能体的行为随机性和相互长期博弈给自主决策带来极大地挑战,导致不能实现自主决策。常见的换道决策方法根据是否考虑智能体相互交互作用可分为两种:交互式和非交互式。
非交互式的换道策略又可以分为基于规则的和基于统计的。基于规则的方法优点是简单且可解释强。基于规则的方法一般是人为的定义了各种工况的状态条件及各个工况之间的转移函数,通过实时测量的数据,判断当前所处于的工况,然后通过定义的效益函数,给出基于当前工况下最优策略。但是基于规则的行为决策体系中没有考虑智能体和环境中存在的不确定性,在较为复杂工况下,可能存在误判等影响驾驶行为的错误决定;基于统计的决策方法可以通过概率来考虑不确定性,但是往往带来的可解释很差,人类不能很好的理解最后的决策行为内部过程,这样对自动驾驶中安全性是个致命的打击。
交互式的换道策略往往是通过将多个参与者建立为博弈模型,通过设定的收益函数,来选取最佳的换道策略。一般可通过车联网来获取信息和实现相互交互,这样可以得到周围车辆的准确状态,然后通过考虑驾驶员风格的收益函数来选择当前时刻的最优策略。但是对于非车联网而言,车辆状态和环境是不确定的。同时对车辆的长期收益缺乏考虑,可能会产生一些过于考虑近期收益的不符合人类驾驶行为的换道策略。
因此,为了给自动驾驶提供更加符合人类认知的行为决策,需要提供一种基于考虑其他车辆驾驶意图的长期博弈和考虑不确定性的,能处理复杂环境下的决策方法或模型。
技术实现要素:
为了解决复杂环境下自动驾驶车辆的换道决策问题,相较于基于当前时刻的博弈决策行为,本发明的目的在于提供一种基于滚动博弈的自动驾驶车辆换道决策方法及系统,该方法在考虑其他车辆驾驶意图基础上做出基于长期博弈的换道策略,可提高自动驾驶车辆决策与人类的符合度;通过引入滚动优化策略,可有效率的处理的车辆和环境中的不确定性。
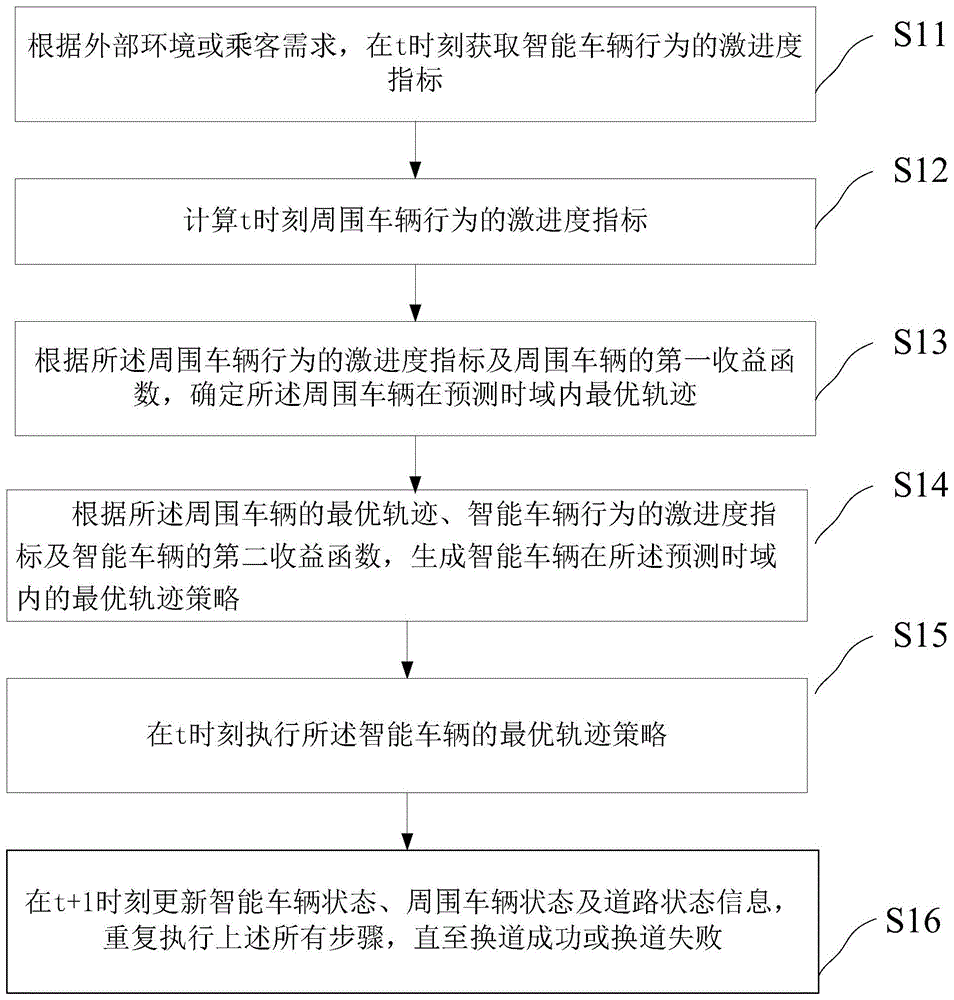
本发明实施例提供一种基于滚动博弈的自动驾驶车辆换道决策方法,包括:根据外部环境或乘客需求,在t时刻获取智能车辆行为的激进度指标;所述激进度指标表示驾驶模式;
计算t时刻周围车辆行为的激进度指标;
根据所述周围车辆行为的激进度指标及周围车辆的第一收益函数,确定所述周围车辆在预测时域内最优轨迹;所述预测时域为t+n;
根据所述周围车辆的最优轨迹、智能车辆行为的激进度指标及智能车辆的第二收益函数,生成智能车辆在所述预测时域内的最优轨迹策略;
在t时刻执行所述智能车辆的最优轨迹策略;
在t+1时刻更新智能车辆状态、周围车辆状态及道路状态信息,重复执行上述所有步骤,直至换道成功或换道失败。
在一个实施例中,所述激进度指标的集合a={f,m,ε};
其中,f表示以比较激进的方式通过当前的预测时域,m表示以平缓的方式通过当前的预测时域,而ε表示以保守的方式通过当前的预测时域;默认驾驶激进度为m。
在一个实施例中,计算t时刻周围车辆行为的激进度指标,包括:
获取周围车辆的与智能车辆的相对位置、相对速度、相对加速度及获取周围车辆的航向角和道路信息;
通过预设模型,计算输出所述周围车辆的激进度指标。
在一个实施例中,所述预设模型为贝叶斯网络模型,包括:行为层,隐藏层和表现层;
将评估驾驶员操作的可行性因素设置在行为层中;所述因素有:{el,er,lv,ld,rv,rd,mv,md,sv};其中,el表示左边车道是否存在,er表示右边车道是否存在,lv表示与左边车道前后车的速度差,ld表示与左边车道前后车的距离差,rv表示与右边车道的速度差,rd表示与右边车道的距离差,mv表示与当前车道前后车的速度差,md表示与当前车道前后车的距离差,sv表示智能车辆的速度;
周围车辆的激进度设置在隐藏层中;
将{bo,yo}设置在表现层;所述bo表示车辆与相邻车道线的距离,yo表示车辆行驶方向与道路之间的角度。
在一个实施例中,根据所述周围车辆行为的激进度指标及周围车辆的第一收益函数,确定所述周围车辆在预测时域内最优轨迹,包括:
设周围车辆状态为
将所述周围车辆状态、周围车辆激进度指标和智能车辆状态,代入第一收益函数,优化求解得到周围车辆在预测时域内的最优轨迹
所述第一收益函数如下:
其中:
k表示0到n的正整数;n表示正整数;αo表示周围车辆激进度,
在一个实施例中,所述约束条件包括:
(1)横向位移y:
(2)纵向速度vx:vxmin<<vx<<vxmax,vxmin为保持车道时能达到的最
小纵向速度;vxmax为保持车道时能达到的最大纵向速度;
(3)纵向加速度ax:axmin<<ax<<axmax,axmin为最小纵向加速度,axmax为最大纵向加速度;
(4)横向加速度ay:aymin<<ay<<aymax,aymin为最小横向加速度,aymax为最大横向加速度。
在一个实施例中,根据所述周围车辆的最优轨迹、智能车辆行为的激进度指标及智能车辆的第二收益函数,生成智能车辆在所述预测时域内的最优轨迹策略,包括:
将所述周围车辆的最优轨迹
所述第二收益函数如下:
其中:
k表示0到n的正整数;n表示正整数;αs表示智能车辆激进度,
在一个实施例中,所述智能车辆的最优轨迹策略包括:多个时序动作;
在t时刻执行所述智能车辆的最优轨迹策略,包括:
在t时刻执行所述最优轨迹策略的第一个时序动作
第二方面,本发明实施例还提供一种基于滚动博弈的自动驾驶车辆换道决策系统,包括:
获取模块,用于根据外部环境或乘客需求,在t时刻获取智能车辆行为的激进度指标;所述激进度指标表示驾驶模式;
计算模块,用于计算t时刻周围车辆行为的激进度指标;
确定模块,用于根据所述周围车辆行为的激进度指标及周围车辆的第一收益函数,确定所述周围车辆在预测时域内最优轨迹;所述预测时域为t+n;
生成模块,用于根据所述周围车辆的最优轨迹、智能车辆行为的激进度指标及智能车辆的第二收益函数,生成智能车辆在所述预测时域内的最优轨迹策略;
执行模块,用于在t时刻执行所述智能车辆的最优轨迹策略;
更新模块,用于在t+1时刻更新智能车辆状态、周围车辆状态及道路状态信息。
本发明实施例提供的一种基于滚动博弈的自动驾驶车辆换道决策方法,通过滚动优化每一个时域内的最优决策,在每一个时域内考虑了长期的收益函数,通过驾驶激进度设定了不同的收益函数,在每一个时域内同时考虑周围车辆和智能车辆,通过双层规划来求解最优智能车辆的决策策略。在下一个时刻,更新智能车辆状态、周围车辆状态及道路状态信息,随后重复整个博弈过程,直至达到终止状态。可提高自动驾驶车辆决策与人类的符合度;通过引入滚动优化策略,可有效率的处理的车辆和环境中的不确定性。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1为本发明实施例提供的基于滚动博弈的自动驾驶车辆换道决策方法的流程图。
图2为本发明实例一中对应的一种换道情况。
图3为本发明实例二中对应的一种换道情况。
图4为本发明实施例提供的基于滚动博弈的自动驾驶车辆换道决策系统的框图。
图5为本发明实施例提供的基于滚动博弈的自动驾驶车辆换道决策系统又一框图。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
参照图1所示,为本发明实施例提供的基于滚动博弈的自动驾驶车辆换道决策方法,包括:
s11、根据外部环境或乘客需求,在t时刻获取智能车辆行为的激进度指标;所述激进度指标表示驾驶模式;
s12、计算t时刻周围车辆行为的激进度指标;
s13、根据所述周围车辆行为的激进度指标及周围车辆的第一收益函数,确定所述周围车辆在预测时域内最优轨迹;所述预测时域为t+n;
s14、根据所述周围车辆的最优轨迹、智能车辆行为的激进度指标及智能车辆的第二收益函数,生成智能车辆在所述预测时域内的最优轨迹策略;
s15、在t时刻执行所述智能车辆的最优轨迹策略;
s16、在t+1时刻更新智能车辆状态、周围车辆状态及道路状态信息,重复执行上述所有步骤,直至换道成功或换道失败。
其中,步骤s11中,根据环境信息或驾驶员及乘客需求,获取智能车激进度指标,激进度指标的指标集为a={f,m,ε},f代表以激进的方式通过当前的预测时域,m代表以平缓的方式通过当前的预测时域,ε代表以保守的方式通过当前的预测时域,如果没有外部强制输入,默认驾驶激进度为m;其中外部环境比如为市区、郊区、或上下坡路况等;当市区路况时,比如对应m;当郊区路况时对应f;当上下坡时对应ε。
而乘客需求是由驾驶员或乘客的性格决定的,比如,性格激进的驾驶员或乘客更希望智能车辆开的更快一点,就会选择激进度指标f,而年纪较大的驾驶员或乘客则更希望智能车辆开的稳一点,安全一点,则会选择激进度指标m或ε,因此其可用于用户个性化选择智能车的驾驶风格,具有较高的自定性。
步骤s12中,计算t时刻周围车辆行为的激进度指标;即从当前时刻获取周围车辆(可以是多个)的相对位置、相对速度、相对加速度、航向角、道路信息等,并根据预算得到周围车辆行为的激进度。
步骤s13中,根据周围车辆行为的激进度指标及周围车辆的第一收益函数,确定周围车辆在预测时域内最优轨迹;在估计周围车辆行为激进度之后,将其对应的周围车辆状态和智能车辆状态的坐标代入第一收益函数,在此基础上,使周围车辆满足约束条件,通过优化求解之后就可以得到周围车辆在预测时域内的最优轨迹。
设周围车辆状态为
将周围车辆状态、周围车辆激进度指标和智能车辆状态,代入第一收益函数,优化求解得到周围车辆在预测时域内的最优轨迹
其中:第一收益函数如下:
k表示0到n的正整数;n表示正整数;αo表示周围车辆激进度,
上述约束条件表示:
(1)横向位移y:
(2)纵向速度vx:vxmin<<vx<<vxmax,vxmin为保持车道时能达到的最小纵向速度;vxmax为保持车道时能达到的最大纵向速度;根据实际车辆定义,一般在[-2.7,23]m/s;
(3)纵向加速度ax:axmin<<ax<<axmax,axmin为最小纵向加速度,axmax为最大纵向加速度;根据实际车辆定义,一般在[-2.7,2.7]m/s;
(4)横向加速度ay:aymin<<av<<aymax,aymin为最小横向加速度,aymax为最大横向加速度;根据实际车辆定义,一般在[-1,1]m/s。
步骤s14中,在得到周围车辆在预测时域内的最优轨迹之后,将其和智能车辆坐标带入第二收益函数,并使智能车辆满足约束条件,通过优化求解之后就可以得到智能车辆在预测时域内的最优轨迹策略。
将该周围车辆的最优轨迹
其中:第二收益函数如下:
其中:
k表示0到n的正整数;n表示正整数;αs表示智能车辆激进度,
步骤s15中,在t时刻执行所述智能车辆的最优轨迹策略;就是将上一步骤中得到的智能车辆在预测时域内的最优轨迹策略作用在智能车上。
步骤s16中,在t+1时刻更新智能车辆状态、周围车辆状态及道路状态信息,重复执行上述所有步骤,直至换道成功或换道失败;比如:如果由于周围车辆或其他因素造成没法换道,换道失败则会以原来车道为目标值返回原来车道。其中,智能车辆状态包括:速度、加速度、航向角、位置坐标等;周围车辆状态包括:相对位置,相对速度,相对加速度,航向角等;道路信息包括:直道弯道等道路类型、几个车道、车道前进方向、路宽及道路的其他交通状况等信息。
本发明实施例中步骤s11和步骤s12在执行上没有先后顺序,也可以同时执行,本发明实施例对此不做限定。
本发明实施例中,首先在当前t时刻根据外部环境或乘客需求得到智能车辆行为的激进度;其次,根据t时刻周围车辆的偏航角,相对速度,相对加速度,道路信息(直道弯道等道路类型,几个车道,车道前进方向,车道多宽等)计算得到周围车辆的驾驶激进度;通过结合周围车辆的驾驶激进度,确定周围车辆在该工况下的t+n预测时域内的最优轨迹;在得到周围车辆的最优轨迹后,通过智能车辆的激进度,得到智能车辆t+n预测时域内的最优轨迹;把最优轨迹作用智能车辆上,在t+1时刻后,更新智能车辆状态,周围车辆状态及道路状态等,重复上述步骤;直至达到终止状态;可提高自动驾驶车辆决策与人类的符合度;通过引入滚动优化策略,可有效率的处理的车辆和环境中的不确定性。
下面通过两个具体的实施例对本发明的技术方案进行详细说明:
实施例一
步骤1:根据外部环境信息或者驾驶员(乘客)需求,给智能汽车当前时刻下驾驶激进度一个指标。比如,总的指标集为a={f,m,ε},其中f代表以比较激进的方式通过当前的预测时域,m代表以平缓的方式通过当前的预测时域,而ε代表以保守的方式通过当前的预测时域,如外部没强制性输入,则默认驾驶激进度为m。
步骤2:输出的周围车辆及其他信息,推测周围车辆的行为激进度。其中,推测算法为贝叶斯网络。利用动态贝叶斯网络的方法进行激进度预测,内在的概率框架能有效处理预测过程中的不确定性。预测所用的特征不仅反应了车辆物理状态,道路信息,车辆间的交互作用,同时也考虑所选择特征的连续变化和历史状态。
其中贝叶斯网络由三层组成,分别是行为层,隐藏层和表现层。通过评估驾驶员特定操作的可行性,这些评价的因素设置在行为层中。如果所有条件满足,驾驶员会采取合适策略来应对不断变化的环境。同时,这种影响会以一些可测量的物理状态形式表现。周围车辆的激进度设置在隐藏层中,是需要推测的隐藏变量。最后,这些物理运动状态也会进一步影响后续的操作行为。
在行为层中,考虑的因素有:{el,er,lv,ld,rv,rd,mv,md,sv}。el为左边车道是否存在,er为右边车道是否存在,lv为与左边车道前后车的速度差,ld是与左边车道前后车的距离差,rv是与右边车道的速度差,rd是与右边车道的距离差,mv是与当前车道前后车的速度差,md是与当前车道前后车的距离差,sv是智能车里的速度。
在隐藏层中,状态量是周围车辆的激进度,是需要推测的隐藏变量。
在表现层中,考虑有的因素有{bo,yo}。bo是车辆与相邻车道线的距离,yo是车辆行驶方向与道路之间的角度。
根据网络结构的定义,可得到联合概率分布,通过贝叶斯公式,得到条件概率分布。
在每个时间点进行激进度估计时候,通过两个连续时间片所有特征推测激进度的可能性分布,选择最大可能性为候选结果。
步骤3:在估计周围车辆行为激进度后,预测在此激进度下周围车辆在预测时域内的轨迹。假定工况如图2所示,其中car_o为周围车辆,动态贝叶斯网络输出的激进度为m,在t时刻的状态为
智能车辆首先根据周围车辆的状态
用于预测周围车辆的车道保持行为模型为:
其中
而优化的第一收益函数为:
其中:
其中αo是周围车辆的激进度,即为m。n为预测时域长度。vxmax是周围车辆在
有了预测模型和第一收益函数,还必须满足一定的约束条件:
1、纵向速度vx:vxmin<<vx<<vxmax,在当前激进度m下速度限制;
2、纵向加速度ax:axmin<<ax<<axmax,在当前激进度m下纵向加速度限制;
通过带约束的优化求解,可得到在当前时刻下,周围车辆在前激进度m下,在预测时域内的最优轨迹
步骤4:对于智能车辆,在得到周围车辆在预测时域内的最优轨迹
对于智能车辆的换道模型为:
其中
其中:
其中js为智能车辆的收益函数,αs为智能车辆的激进度,即外部输入量f,n为预测时域长度。vxmax是周围车辆在
需要特别说明是kroad,即道路使用权系数,kroad∈(0,1),比如可以选取0.7或0.8等。由于智能车辆在执行换道操作,而周围车辆在执行车道保持操作,周围车辆享有本车道道路使用的优先权。通过对kroad进行设置,在收益函数方面,达到换道车辆对安全责任更加敏感。
对于智能车辆,有了预测模型和收益函数,还必须满足一定的约束条件:
1、横向位移y:
2、纵向速度vx:vxmin<<vx<<vxmax,在当前激进度f下的速度限制;
3、纵向加速度ax:axmin<<ax<<axmax,在当前激进度f下的纵向加速度限制;
4、横向加速度ay:aymin<<ay<<aymax,在当前激进度f下横向加速度限制;
通过优化求解得到智能车在预测时域内的最优轨迹:即:通过设定第二收益函数,构成非线性优化的求解问题,可通过常用的高斯牛顿法或lm(levenber-marquard)算法求得。
由于智能车辆的激进度大于周围车辆的激进度,智能车辆会更加着重换道效率收益函数,而对于周围车辆,在相同的危险程度上,更加对于看中安全收益函数。这样通过不同激进度和道路使用权系数,可得到智能车辆在预测时域内的最优轨迹策略即
步骤5:通过将得到的最优轨迹策略的第一个时序动作
随后在t+1时刻,更新周围车辆、智能车辆状态及道路信息,其中,智能车辆状态包括:速度、加速度、航向角、位置坐标等;周围车辆状态包括:相对位置,相对速度,相对加速度,航向角等;道路信息包括:直道弯道等道路类型、几个车道、车道前进方向、路宽及道路的其他交通状况等信息。
继续做在预测时域内的博弈规划,得到更新后的最优决策策略,作用更新后时序的第一个元素,随后在t+2时刻继续重复以上步骤,直到达到终止状态,即换道完成或换道失败。
在本实施例中,由于智能车辆car_s激进度大于周围车辆,最终状态为智能车辆成功加速抢入周围车辆的车道,而周围车辆car_o减速以保证安全。
实施例二
一种示意工况如图3所示:
其中car_s为智能车辆,car_o为周围车辆,car_s和car_o的激进度相同。智能车辆在做换道操作,而周围车辆在做车道保持操作。
在t时刻,智能车辆car_s预测完成换道操作所需要的纵向位移为ds,周围车辆car_o预测当前时刻到智能车辆换道完成时刻纵向坐标的位移为do。
首先智能车辆通过动态贝叶斯网络在线估计出周围车辆的激进度与自己相同,智能车辆用于预测周围车辆做车道保持的模型为:
其中
而优化的第一收益函数为:
其中:
其中αo是周围车辆的激进度,即为m。n为预测时域长度。vxmax是周围车辆在
有了预测模型和第一收益函数,还必须满足一定的约束条件:
1、纵向速度vx:vxmin<<vx<<vxmax,在当前激进度下速度限制;
2、纵向加速度ax:axmin<<ax<<axmax,在当前激进度下纵向加速度限制;
通过带约束的优化求解,可得到在当前时刻下,周围车辆在前激进度下,在预测时域内的最优轨迹
对于智能车辆,在得到周围车辆在预测时域内的最优轨迹
对于智能车辆的换道模型为:
其中
其中:
其中js为智能车辆的收益函数,αs为智能车辆的激进度,n为预测时域长度。vxmax是智能车辆
通过将得到的最优轨迹策略的第一个时序动作
随后在t+1时刻,更新周围车辆、环境和智能车辆的相关状态,包括相对位置、相对速度、相对加速度、道路信息等。重复上述所有步骤,继续做在预测时域内的博弈规划,得到更新后的最优决策策略,作用更新后时序的第一个元素,随后在t+2时刻继续重复以上步骤,直到达到终止状态,即换道完成或换道失败。
在本实施例中,由于智能车辆car_s和周围车辆car_o的激进度相同或相近,在t时刻到t_m时刻,智能车辆一直尝试做换道操作,而周围车辆car_o一直尝试做车道保持动作同时抵抗智能车辆的插入。
需要特别强调的是,在t时刻到t_m时刻,虽然智能车辆一直在和周围车辆做博弈,智能车辆由于对周围车辆的车道使用权低于周围车辆。在t_m时刻,对于相同的危险物理观测量,在道路系数kroad的作用下,智能车辆选择保持一定的直线运动,让路于周围车辆car_o,随后又继续执行换道操作,直到换道完成。
基于同一发明构思,本发明实施例还提供了一种基于滚动博弈的自动驾驶车辆换道决策系统,由于该系统所解决问题的原理与前述方法相似,因此该系统的实施可以参见前述方法的实施,重复之处不再赘述。
第二方面,本发明还提供一种基于滚动博弈的自动驾驶车辆换道决策系统,参照图4所示,包括:
获取模块41,用于根据外部环境或乘客需求,在t时刻获取智能车辆行为的激进度指标;所述激进度指标表示驾驶模式;
计算模块42,用于计算t时刻周围车辆行为的激进度指标;
确定模块43,用于根据所述周围车辆行为的激进度指标及周围车辆的第一收益函数,确定所述周围车辆在预测时域内最优轨迹;所述预测时域为t+n;
生成模块44,用于根据所述周围车辆的最优轨迹、智能车辆行为的激进度指标及智能车辆的第二收益函数,生成智能车辆在所述预测时域内的最优轨迹策略;
执行模块45,用于在t时刻执行所述智能车辆的最优轨迹策略;
更新模块46,用于在t+1时刻更新智能车辆状态、周围车辆状态及道路状态信息。
参照图5所示,为本发明实施例提供的基于滚动博弈的自动驾驶车辆换道决策系统又一框图,整个系统包括以下几个组成部分:
外部需求输入模块,可用于用户个性化选择智能车的驾驶风格,具有较高的自定性。
滚动博弈输入模块,用于滚动优化决策,其中在每一个滚动优化过程中,预测和优化整个预测时域内的周围车辆轨迹和智能车轨迹,通过双层规划建立博弈模型。同时,每次只作用于第一个时序内的优化决策,随后重复整个博弈过程,直到达到终止状态,即换道成功或换道失败。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!