一种基于四阶矩奇异值分解的间歇过程故障监测方法与流程
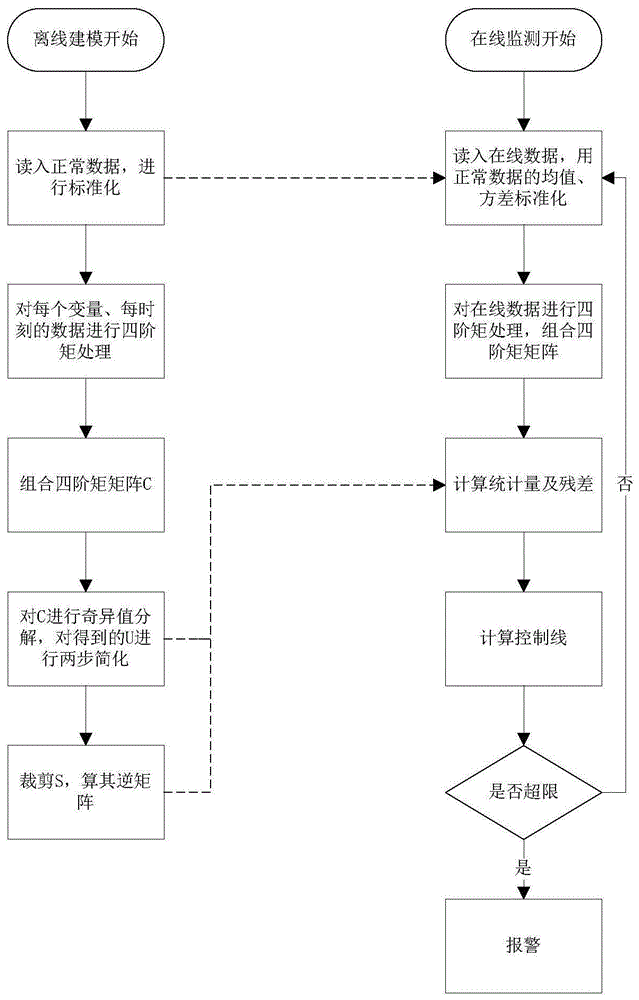
本发明处于工业过程故障监测领域,特别是涉及一种四阶矩奇异值分解技术。本发明的基于四阶矩奇异值分解故障监测的方法是在te(tenesseeeastman)过程的具体应用。
背景技术:
现代的工业过程中有大量的间歇过程,常见的间歇过程有微生物制药、污水处理、啤酒制备、酸奶制备等。间歇过程生产批量规模比较灵活,工艺改变较容易,同时对于产品切换有一定的兼容性,可以进行少量的不同品种的生产,可以较快地适应原料或运行条件的变化。
工业过程数据大多具有强烈的非线性.由于系统的非线性,采集到的数据通常具有非高斯分布,而非高斯信息对于系统的监测非常重要。通常,非高斯信息需要高阶分析(数据阶数大于2)。
目前,高阶分析方法主要有:核主成分分析(kpca)、多元核独立成分分析(mkica)、多元核熵成分分析(mkeca)。上述算法使用的高阶分析方法是核技巧。核能够将数据映射到高维,但同时数据间的结构信息会遭到破坏,对故障诊断会有一定的影响。
技术实现要素:
为了克服上述现有技术的不足,本发明提供了一种基于四阶矩奇异值分解的间歇过程故障监测方法。每种变量与前时刻的自身生成四阶矩,而不是通过核与全部数据进行运算。从而保存下数据本身的结构。四阶矩中包含着显著的非高斯信息,对监控准确率的提升有很大帮助。本文所提方法在进行基于统计的监测前就对数据进行了四阶矩处理。在对数据构建统计量的阶段,由于数据本身就具有高阶特性统计量自然就带有了高阶特性,并不需要额外创建新的统计方式。
本发明采用了如下的技术方案及实现步骤:
a.离线建模阶段:
1)读入正常数据,计算每种(共d种)变量的均值meand与标准差stdd,对正常数据标准化,公式如下:
其中,xd表示第d个变量全部时刻的数据,meand表示xd的平均值,stdd表示xd的标准差;
2)对共计d种的xd的每个时刻的数据进行四阶矩处理,公式如下;
cd(k)=xd(k)xd(k-τ1)xd(k-τ2)xd(k-τ3)
cd(k)表示第d个变量第k时刻的四阶矩,k表示采样时刻。xd(k)表示第d个变量在第k时刻的值。τ1、τ2、τ3表示步长,本文选择1、2、3,在此条件下需k≥4。
3)将cd(k)组合为四阶矩矩阵c,公式如下:
其中,n表示结束时刻;
4)对c进行奇异值分解(svd),svd(c)=usvt,对u进行两步简化。
i.u的第一步简化,步骤如下:
计算能令下方公式满足的最小m值。
其中,si,i是s对角线上的元素,i是s行、列数中的最小值,。δ是阈值,可以调整,本文选择90。
保留u的前m列,其余删除,得到第一步简化后的u。
ii.u的第二步简化,步骤如下:
判断简化后的u中每个元素数值大小,公式如下:
其中,
当ui,m满足上方公式判断条件,将其置0,得到第二步简化后的u。
5)裁剪s矩阵,使其为m行m列。求裁剪后s的逆矩阵sinv。将前文中两步简化后的u和sinv保存,用于后文在线监测
b.在线监测阶段:
6)读入在线数据,对在线数据进行标准化,公式如下:
其中,xd.on为在线数据的第d个变量值,meand,stdd为正常数据的均值与标准差;
7)对xd,on进行四阶矩处理,公式如下:
cd,on(k)=xd,on(k)xd,on(k-τ1)xd,on(k-τ2)xd,on(k-τ3)
并组合为con
8)计算统计量f2及其残差fs:
f2=(conu)sinv(conu)t
fs=(con-conu)(con-conu)t
其中的u、sinv为离线阶段步骤5中保存的矩阵。
9)计算f2、fs的控制线,公式如下:
其中,f(0.95,m,n′-m)表示置信度95%,分子自由度m(为步骤4中的值),分母自由度n′-m的f检验。n′=n-τ3。
l=diag(son)
其中,son为在线数据经过奇异值分解后得到的s矩阵。l为其对角线上的元素值。li为l中第i个元素。c为期望为0,标准差为1的95%分位数。
10)将每一时刻的f2、fs与相应的控制线对比。未超过则正常,
回步骤6;超过控制线则发生故障,报警。
有益效果
与现有技术相比,本发明构造高阶统计量的方法保留了数据原始结构的信息,并在监控过程中充分挖掘了高阶数据的的信息。充分考虑了数据的非线性,以及由非线性所带来的非高斯性。通过将数据构造为四阶矩的方式分析数据,用分析后的数据计算统计量及其残差,完成监控获得令人满意的监控效果。
附图说明
图1为本发明的方法流程图;
图2(a)为te过程故障1f2监测图;
图2(b)为te过程故障1fs监测图;
图3(a)为te过程故障2f2监测图;
图3(b)为te过程故障2fs监测图;
图4(a)为te过程故障5f2监测图;
图4(b)为te过程故障5fs监测图;
图5(a)为te过程故障1mkicai2统计量监测图;
图5(b)为te过程故障1mkica残差监测图;
具体实施方式
本文所提出的算法可以监控工业间歇过程生产中发生的故障。通过对变量四阶矩处理,进行奇异值分解,构造统计量及相应的控制线完成监测。最终能够得到令人满意的监控结果,保证生产的安全进行。
为验证本文中所提的算法的准确性,使用te过程数据进行了测试。te(tenesseeeastman)仿真平台是依据实际化工反应过程建立的仿真平台,其产生的数据具有时变、强耦合和非线性特征,广泛用于测试复杂工业过程的控制和故障诊断模型。
te过程有21种故障,具体描述见表1
表1te过程故障列表
本文所提方法的具体实施步骤如下:
a.离线建模阶段:
步骤1:读入正常数据,计算每种(共d种)变量的均值meand与标准差stdd,对正常数据标准化,公式如下:
d从1开始,到d(变量总个数)结束。xd=[xd(1),xd(2),...,xd(n)]。n为总采样时刻
步骤2:用公式cd(k)=xd(k)xd(k-τ1)xd(k-τ2)xd(k-τ3)对xd的每时刻数据进行四阶矩处理。k为时刻,起始值为τ3+1;
步骤3:将cd(k)组合为四阶矩矩阵c,拼法如下:
其中,n为总采样时刻n减τ3后的值。
步骤4:对c进行svd分解,得到u矩阵、s矩阵,进行两步简化。
第一步:找能令公式
第二步:依据公式
步骤5:裁剪s矩阵,使其为m行m列,其余删除。求裁剪后s的逆矩阵sinv;
b.在线监控阶段:
步骤6:依据公式
步骤7:依据公式cd,on(k)=xd,on(k)xd,on(k-τ1)xd,on(k-τ2)xd,on(k-τ3)对在线数据进行四阶矩处理。并组合为
k为当前时刻,起始值为τ3+1,因此需要在工业过程进行到第τ3个时刻后开始监控;
步骤8:计算统计量f2及其残差fs:
全部时刻的统计量计算公式为:
f2=(conu)sinv(conu)t
fs=(con-conu)(con-conu)t
单独第k时刻的统计量计算公式如下:
f2(k)=(con(k)u)sinv(con(k)u)t
fs(k)=(con(k)-con(k)u)(con(k)-con(k)u)t
其中,con(k)为con的第k列。f2(k)、fs(k)分别为的k时刻的统计量及残差。
步骤9:计算统计量及残差的控制线,公式如下:
步骤10:将每一时刻的f2、fs与相应的控制线对比。未超过则正常,回步骤6;超过控制线则发生故障,报警。
上述步骤即为本发明方法在te过程上的具体应用步骤。
通过图2、图3、图4可以验证本方法的有效性。
在200时刻前,生产处于正常阶段。可以看出,本文中方法所提的统计量及残差值全部低于控制线,没有产生误报的情况。而通过图5可以看出,由于工业过程起始阶段的波动较大,导致mkica在前期有较多的误报。
te过程的数据于200时刻引入了故障。从图2、3、4中可以看出,由于本文构造的统计量有着四阶特性,因此对故障的响应非常敏感,经过较短时间就越过控制线,产生了报警。成功保障了生产安全。而mkica使用的高阶分析方式为核技巧,对数据的高阶信息的挖掘没有四阶矩方法有效。因此,从图中可以发现mkica统计量的升高较为缓慢,没有四阶矩统计量的高速响应能力。在实际工业过程中,及时响应是非常重要的一项能力。
通过对实验图的分析可以得出,本文所提出的基于四阶矩奇异值分解的间歇过程故障诊断方法,在正常阶段有较低的误报率,在故障阶段有较低的漏报率及较快的响应能力。证明了所提方法的有效性。
- 还没有人留言评论。精彩留言会获得点赞!