一种分散处理单元的流数据二维处理方法与流程
本发明涉及自动控制技术领域,具体涉及一种分散处理单元流数据的二维处理方法。
背景技术:
在自动控制领域广泛使用的分散处理单元在处理数据采集、标度变换、报警限值检查、操作记录与顺序事件记录、逻辑控制等方面能力较强,但是普遍缺少流数据的计算能力,即对宽载的、具有流特征的数据缺少处理和分析能力,而只能对单载的即时时间端面的数据进行处理,所实施的计算大部分限于逻辑计算,即分散处理单元逻辑组态的模块之间只能批量地传递单个的模拟量或者开关量或者以模拟量形式表达的多个开关量等,不能读写、传递、计算流数据。
随着平行仿真和平行控制等智慧能源的平台方法在自控领域的深入应用,在成熟并且应用丰富的分散处理单元上面拓展流数据的处理和计算能力,一方面使得平行仿真与控制可以充分利用分散处理单元的优势,另一方面使得智慧能源平台的应用与自动控制相结合,成为融合的、在线的智能应用,例如基于燃煤电站材料老化条件下发电效率和发电设备寿命竞争的控制优化策略,则是流计算和逻辑计算的综合应用,具备流计算能力的分散控制单元既能实施发电效率和发电设备寿命竞争的流计算分析,也能实施竞争性的控制优化。
以现有的分散处理单元架构来看,实现流计算存在以下问题:
第一,分散处理单元的数据io通道缺少流数据的读取与存储能力,对数据进行实时存贮时采用的是时间断面的模式,将流数据分解为每个时间断点上的数值,以时间断点为坐标统一存贮所有数据,不能读取或者存贮流数据;专利《过程控制历史数据文件结构的建立方法和数据读写方法》(申请号cn200910197024.x,公开号cn102043795a)公开的一种过程控制历史数据文件结构的建立方法即存在此不足。
第二,分散处理单元的数据传输通道缺少宽载能力,在逻辑组态的模块之间通过连线所表达的只有模拟量和开关量两种基本类型,以及利用模拟量来表达多个开关量的一种特殊的拓展类型,不能表达流数据;专利《实时数据在线压缩与解压缩方法》(申请号cn200310108294.1,公开号cn1612252a)公开的一种过程控制系统中实时数据在线压缩与解压缩方法及相应的文件结构即存在该不足;
在逻辑计算能力的基础上拓展流计算能力,分散处理单元需要从标识、存储、取值与传输等方面进行功能扩充,使得分散处理单元兼容流数据的处理能力。本发明所阐述的方法可以使得分散处理单元在逻辑计算框架上具备流数据处理的能力,使得仅具备逻辑计算能力的分散处理单元具有基于流数据的建模能力,从而用于智慧平台平行仿真与平行控制的场合;本发明所阐述的方法也可以使得分散处理单元为流计算单独使用而不含逻辑计算的功能,从原理上讲和兼容流计算和逻辑计算能力的分散处理单元是一样的。
技术实现要素:
本发明要解决的技术问题是,提供一种分散处理单元流数据的二维处理方法,从流数据的长度和宽度等两个维度出发,对流数据进行标识、存贮、读取和传输。本发明基于分散处理单元进行,使得工业控制领域普遍应用的分散处理单元在常用的逻辑计算能力之外获得流数据的二维处理能力,为分散处理单元的在线建模和修正,以及基于模型的预测控制或者有约束的优化控制等提供技术支撑,使得平行控制可以基于分散处理单元部署并且展开。
为解决上述技术问题,本发明提供的技术方案为:
一种分散处理单元的流数据二维处理方法,所述方法从流数据的长度和宽度等两个维度出发,对流数据进行标识、存贮、读取和传输,所述方法基于分散处理单元进行,使得工业控制领域普遍应用的分散处理单元在常用的逻辑计算能力之外获得流数据的二维处理能力,为分散处理单元的在线建模和修正,以及基于模型的预测控制或者有约束的优化控制等提供技术支撑,使得平行控制可以基于分散处理单元部署并且展开;
所述方法包括以下具体步骤:
1)为需要纳入流数据的测点给出专用标识:所述标识为分散处理单元通用点表的一个特征字段,在所有的分散处理单元及其网络中通用,所述字段不超过3个字符,具有标识的唯一性,拥有该特征字段的测点自动归类为一个数据流,所述分散处理单元的通用点表能够实时修改实时生效;
2)为流数据设置特征值算法以及特征值判断依据:所述特征值为流数据宽度方向的数值特征的统计值,所述特征值算法为统计值的计算方法,特征值的计算为实时逻辑计算,当流数据需要进入存储环节时特征值成为流数据的一个组成部分,所述特征值判断依据是利用流数据特征值进行流数据价值判断的依据,当流数据特征值满足所述判据时,流数据被认为具有存储的价值,并且可被实时或者后续调取,构建流计算;
3)为流数据创建存储空间并且写入:首先根据所定义的流数据分别建立头文件,头文件中包含了对应流数据的全部索引,头文件丢失或者篡改会导致流数据的索引丢失;头文件可以更新;根据头文件的索引,满足特征值判据的流数据被写入存储空间,写入过程是实时的、批量性的;写入的数据具有时标,所述存储空间为内存空间或者磁盘空间,当存储空间为内存空间时,受限于预设的内存空间大小,流数据保持一定的长度,旧的数据被自动剔除;当存储空间为磁盘空间时,流数据理论上为受限于磁盘空间的无限长;
4)取值并且传输流数据:针对磁盘文件方式,流数据的取值为磁盘文件读入过程,流数据的读入为从磁盘空间读入流数据并且置入内存空间;针对内存空间方式,流数据的取值为内存参数的指针赋值,取值的批次和大小受限于预设的内存空间大小,流数据按照一定的长度读入。
作为改进,所述方法适用于专门进行历史记录的历史站和工程师站或者有需要的操作员站。
作为改进,所述方法基于分散处理单元进行,对分散处理单元已经具备的逻辑计算能力不做修改,所述流数据的二维处理方法对逻辑计算能力没有影响,基于流数据开展的流计算与逻辑计算相互结合。
作为改进,建立所述流数据的处理能力之后,即可开展流计算的部署和应用。
采用以上结构后,本发明具有如下优点:
通过本发明对流数据进行长度和宽度二维处理,使得分散处理单元的流计算具备了流数据支持,进而使得分散处理单元能够具有基于流计算的建模和在线校验能力,进而为基于模型的预测控制或者有约束的优化控制等提供技术支撑,使得平行控制可以基于分散处理单元部署并且展开。
附图说明
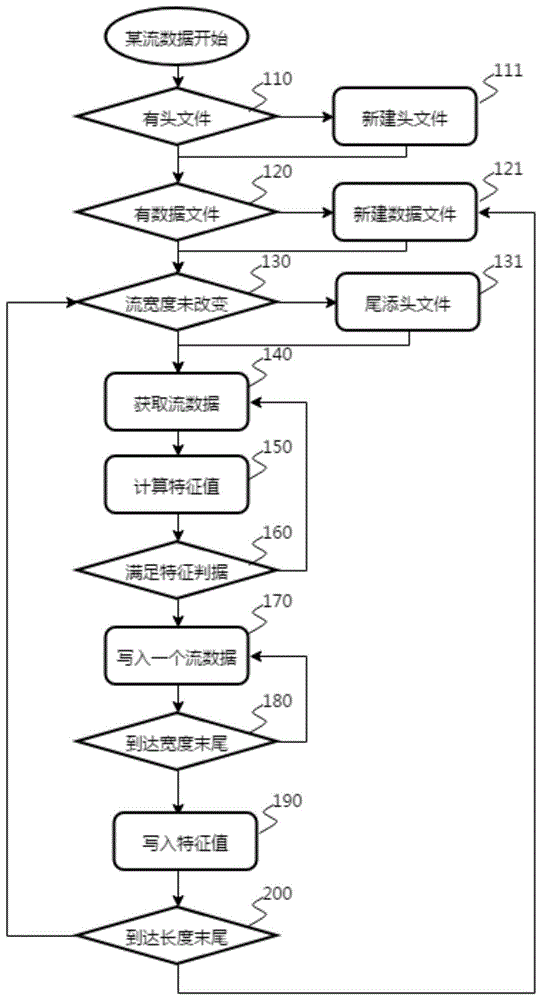
图1是本发明实施例提供的流数据存储过程的流程示意图;
图2是本发明实施例提供的流数据存储文件的格式示意图。
具体实施方式
下面结合附图对本发明做进一步的详细说明。
结合附图1-2,一种分散处理单元的流数据二维处理方法,所述方法从流数据的长度和宽度等两个维度出发,对流数据进行标识、存贮、读取和传输,所述方法基于分散处理单元进行,使得工业控制领域普遍应用的分散处理单元在常用的逻辑计算能力之外获得流数据的二维处理能力,为分散处理单元的在线建模和修正,以及基于模型的预测控制或者有约束的优化控制等提供技术支撑,使得平行控制可以基于分散处理单元部署并且展开;
所述方法包括以下具体步骤:
1)为需要纳入流数据的测点给出专用标识:所述标识为分散处理单元通用点表的一个特征字段,在所有的分散处理单元及其网络中通用,所述字段不超过3个字符,具有标识的唯一性,拥有该特征字段的测点自动归类为一个数据流,所述分散处理单元的通用点表能够实时修改实时生效;
2)为流数据设置特征值算法以及特征值判断依据:所述特征值为流数据宽度方向的数值特征的统计值,所述特征值算法为统计值的计算方法,特征值的计算为实时逻辑计算,当流数据需要进入存储环节时特征值成为流数据的一个组成部分,所述特征值判断依据是利用流数据特征值进行流数据价值判断的依据,当流数据特征值满足所述判据时,流数据被认为具有存储的价值,并且可被实时或者后续调取,构建流计算;
3)为流数据创建存储空间并且写入:首先根据所定义的流数据分别建立头文件,头文件中包含了对应流数据的全部索引,头文件丢失或者篡改会导致流数据的索引丢失;头文件可以更新;根据头文件的索引,满足特征值判据的流数据被写入存储空间,写入过程是实时的、批量性的;写入的数据具有时标,所述存储空间为内存空间或者磁盘空间,当存储空间为内存空间时,受限于预设的内存空间大小,流数据保持一定的长度,旧的数据被自动剔除;当存储空间为磁盘空间时,流数据理论上为受限于磁盘空间的无限长;
4)取值并且传输流数据:针对磁盘文件方式,流数据的取值为磁盘文件读入过程,流数据的读入为从磁盘空间读入流数据并且置入内存空间;针对内存空间方式,流数据的取值为内存参数的指针赋值,取值的批次和大小受限于预设的内存空间大小,流数据按照一定的长度读入。
所述方法适用于专门进行历史记录的历史站和工程师站或者有需要的操作员站。
所述方法基于分散处理单元进行,对分散处理单元已经具备的逻辑计算能力不做修改,所述流数据的二维处理方法对逻辑计算能力没有影响,基于流数据开展的流计算与逻辑计算相互结合。
建立所述流数据的处理能力之后,即可开展流计算的部署和应用。
本发明在具体实施时,从流数据的长度和宽度等两个维度出发,对流数据进行标识、存贮、读取和传输。本发明基于分散处理单元进行,使得工业控制领域普遍应用的分散处理单元在常用的逻辑计算能力之外获得流数据的二维处理能力,为分散处理单元的在线建模和修正,以及基于模型的预测控制或者有约束的优化控制等提供技术支撑,使得平行控制可以基于分散处理单元部署并且展开。
所述流数据的长度是指流数据在时间维度上的度量,流数据具有时间标戳,时间标戳是分割流数据长度的唯一标记,在本发明的定义中,时间标戳为唯一而非连续的。所述唯一是指时间标戳的墙上时刻是唯一的;所述非连续是指流数据的时间标戳并非按照严格的墙上时间间隔,而是根据流计算等实际应用的特征进行了筛选。
所述流数据的宽度是指流数据在空间维度上的度量,流数据具有空间标戳,空间标戳是分割流数据宽度的唯一标记,在本发明的定义中,空间标戳是唯一且连续的。所述连续是指流数据的空间标戳根据实际应用对象的定义而依序排列,并且其空间上的相邻数据也被严格标戳,并且具有唯一性。
所述流数据两个维度的处理是指依照长度和宽度等两个维度对流数据进行标识、存储、取值与传输。所述标识是指在分散处理单元中对流数据进行特征字段标注,所述存储是指将流数据从分散处理单元的输出通道存放到本地或者网络的内存或者磁盘文件中,所述取值是指将流数据从内存或者磁盘文件中读入到分散处理单元的输入通道中,所述传输是指在分散处理单元的全局数据库中进行流数据的页间传递、网间传递、并行传递等。所述页间是指分散处理单元的组态页面之间,所述网间是指分散处理单元的全局数据网络之间,所谓并行是指并列运行的分散处理单元之间,分散处理单元的并行不是指同时运行的多个独立的分散处理单元,也不是指同步运行的多个冗余分散处理单元,而是指进行了并行计算部署的多个分散处理单元。
通过以下技术方案来实施:
第一步,为需要纳入流数据的测点给出专用标识。所述标识为分散处理单元通用点表的一个特征字段,在所有的分散处理单元及其网络中通用,所述字段通常不超过3个字符,具有标识的唯一性,即拥有该特征字段的测点自动归类为一个数据流。所述分散处理单元的通用点表一般能够实时修改实时生效,否则需要离线修改完成后重启分散处理单元及其网络。
第二步,为流数据设置特征值算法以及特征值判断依据。所述特征值为流数据宽度方向的数值特征的统计值,亦即流数据空间上的数值特征的统计值,所述特征值算法为统计值的计算方法,特征值的计算为实时逻辑计算,当流数据需要进入存储环节时特征值成为流数据的一个组成部分。所述特征值判断依据是指利用流数据特征值进行流数据价值判断的依据,当流数据特征值满足所述判据时,流数据被认为具有存储的价值,并且可被实时或者后续调取,构建流计算。
第三步,为流数据创建存储空间并且写入。首先根据所定义的流数据分别建立头文件,头文件中包含了对应流数据的全部索引,头文件丢失或者篡改会导致流数据的索引丢失;头文件可以更新;根据头文件的索引,满足特征值判据的流数据被写入存储空间,写入过程是实时的、批量性的;写入的数据具有时标。所述存储空间为内存空间或者磁盘空间,当存储空间为内存空间时,受限于预设的内存空间大小,流数据保持一定的长度,旧的数据被自动剔除;当存储空间为磁盘空间时,流数据理论上为受限于磁盘空间的无限长。
第四步,取值并且传输流数据。针对磁盘文件方式,流数据的取值为磁盘文件读入过程,流数据的读入为从磁盘空间读入流数据并且置入内存空间。针对内存空间方式,流数据的取值为内存参数的指针赋值。取值的批次和大小受限于预设的内存空间大小,流数据按照一定的长度读入。
本发明适用于专门进行历史记录的历史站,也可以用于工程师站或者有需要的操作员站。所述历史站、工程师站、操作员站已有公认的定义,此不赘述。
本发明基于分散处理单元进行,分散处理单元定义如通用点表、kks编码、tag名(测点名)、特征字段、全局数据库等已有公认的定义,以及分散处理单元的数据广播、扫描计算等过程已有公认的描述,均为本发明的先验知识,此不赘述。
本发明基于分散处理单元进行,对分散处理单元已经具备的逻辑计算能力不做修改,所述流数据的二维处理方法对逻辑计算能力没有影响,基于流数据开展的流计算与逻辑计算相互结合。
本发明不区分单个独立的分散处理单元或者多个并行的分散处理单元,也不区分本地应用或者网络应用,不过如果本发明应用于并行环境或者网络应用,需要在网络广播包中为流数据类型定义流数据缓冲,方法与公认的网络广播包的定义并无特殊的不同,此不赘述。
本发明的实施例包括流数据标识、存取(存储与取值)、传输等内容,图1是为本发明实施例提供的流数据存储过程的流程示意图,包含了存储的内容,标识、取值与传输的内容通过文字说明;图2是为本发明实施例提供的流数据存储文件的格式示意图,是图1的补充说明。
以下说明流数据的标识方法:
流数据的标识包括流数据长度维度上的标识和流数据宽度维度上的标识,流数据的标识主要是指流数据宽度维度上的标识,更明确的,是指分散处理单元全局数据库中归属于特定流数据的测点的特定标识。所述特定流数据是指被纳入分析的一组测点,例如燃煤电站材料老化条件下跟某个发电设备某个区段寿命相关的一组测点,所述特定标识是指给这一组测点的每个测点定义特征字段。所述特征字段是指全局数据库中每个测点都具备的特定字段,在所有的分散处理单元及其网络中通用,所述特定字段通常不超过3个字符,具有标识的唯一性,即拥有该特征字段的测点自动归类为一个数据流。所述分散处理单元的通用点表一般能够实时修改实时生效,否则需要离线修改完成后重启分散处理单元及其网络。
特征字段通常以xyz的样式表达,以前例说明,其中x为某发电设备代号,以设备英文的首字母表达,y为某区段代号,以英文字母依序表达,从a到z共计代表26个区段,z为流数据复用标志,可以为0~9、a~z中任意一个,当z为0时,该测点不复用,否则可复用。例如sd0特征字段代表过热器第d段所有的管壁温度并且不被复用,若该流数据中的某个管壁温度的特征字段被标识为sd1,它同样归属于过热器第d段所有的管壁温度这个流数据,但是也可以被其他流数据复用,归属于一个新的流数据,这个新的流数据的典型特征是所有测点特征字段的末尾均为数字1。
分散处理单元以两种形式归纳流数据,一种方式依据xyw,以xy为标识而无论w,这是主要的归纳方式;另一种方式依据wwz,以z为标识而无论ww,这是辅助的归纳方式。所述标识方法使得测点具有复用性,这种复用性使得本发明在归纳流数据时具有更大的灵活性,例如前例中主要以过热器受热面为对象进行流数据归纳,在某些特殊区域如折焰角处等还需要以折焰角的整个覆盖面为对象进行流数据归纳。
以下结合图1说明流数据存储过程的流程:
步骤110,头文件检查。所述检查是针对每一个流数据进行的,不同的流数据具有不同的头文件,每一个头文件和该流数据所有的数据文件在单独的内存空间或者磁盘目录里面。所述检查是在分散处理单元启动初期进行的,也可以在分散处理单元运行的时候重新进行,头文件检查不仅包括文件存在性检查,也包括文件语法合法性检查,当文件语法不合法或者不存在时转向步骤111完成头文件的修正或者新建;无论流数据的存储是在内存区域还是磁盘文件,头文件均为一块专属空间,并且可以写入磁盘文件。
步骤120,数据文件存在性检查。当数据文件不存在时转向步骤121完成数据文件的新建,如前所述流数据的存储空间可为内存空间或者磁盘空间,当存储空间为内存空间时,受限于预设的内存空间大小,流数据保持一定的长度,旧的数据被自动剔除;当存储空间为磁盘空间时,流数据理论上为受限于磁盘空间的无限长度。
步骤130,流数据的宽度检查。所述流数据的宽度是指流数据在空间维度上的度量,所述流数据宽度检查是指对流数据在空间维度上的度量是否变化进行检查。流数据具有空间标戳,空间标戳是分割流数据宽度的唯一标记,在本发明的定义中,空间标戳是唯一且连续的,所述连续是指流数据的空间标戳根据实际应用对象的定义而依序排列,并且其空间上的相邻数据也被严格标戳。当流数据宽度发生改变时,转向步骤131进行头文件的尾添工作,所述尾添是指流数据中增加的测点信息被添置在头文件流索引的最后。流数据一般不发生测点的减少,如果发生,则头文件保持不变。
步骤140,流数据的获取。所述获取是指从分散处理单元实时数据网络中,通过广播包的侦听,以流数据所包含的测点为单位获取实时数据,此为现有技术,不再赘述。特别地,由于测点复用的存在,流数据的获取存在同一个测点多次被获取的情形,优选地,可以通过一次获取多次分配来提高这个获取效率。
步骤150,流数据的特征值计算。所述特征值为流数据数值特征的统计值,是以流数据宽度为维度的,亦即流数据空间上的数值特征的统计值,所述特征值计算为统计值的计算方法,为实时逻辑计算,当流数据需要进入存储环节时特征值成为流数据的一个组成部分,当流数据不需要进入存储环节时所计算的特征值自动被抛弃。
步骤160,流数据的特征值判据判断。所述特征值判据是指利用流数据特征值进行流数据价值判断的依据,当流数据特征值满足所述判据时,流数据被认为具有存储的价值,并且可被实时或者后续调取,构建流计算。所述特征值判据判断是指这个判断过程,如果不满足,则转入步骤140继续获取流数据,没有进入存储空间的流数据自动被抛弃。优选地,分散处理单元相关的历史记录软件记录了这些流数据以及前述相关的特征值,当后续流计算需要补充这些数。
本发明建立流数据的处理能力之后,即可开展流计算的部署和应用,该内容不在本发明的范围内。
以上对本发明及其实施方式进行了描述,这种描述没有限制性,附图中所示的也只是本发明的实施方式之一,实际的结构并不局限于此。总而言之如果本领域的普通技术人员受其启示,在不脱离本发明创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!