机器学习装置、伺服控制装置、伺服控制系统以及机器学习方法与流程
[0001]
本发明涉及针对控制多个电动机的多个伺服控制部进行机器学习的机器学习装置、包含该机器学习装置的伺服控制装置、伺服控制系统以及机器学习方法,其中,所述多个电动机对多个轴中的一个轴因其他至少一个轴的运动而受干扰的机器进行驱动。
背景技术:
[0002]
例如专利文献1以及专利文献2中记载了具有对多个电动机进行控制的多个伺服控制部的装置,所述多个电动机对具有多个轴的机器进行驱动。
[0003]
专利文献1中记载了包含以下部分的控制装置:第1电动机控制部,其对驱动机床、机器人、或者工业机器有关的第1轴的第1电动机进行控制;第2电动机控制部,其对驱动与第1轴不同方向的第2轴的第2电动机进行控制。并且,专利文献1中记载有一种评价用程序,其用于评价控制装置有关的动作特性,使第1和第2电动机控制部动作,所述评价用程序使第1和第2电动机控制部动作,使得通过由第1和第2电动机驱动的第1和第2轴而移动的控制对象的移动轨迹的形状至少具有以下形状:第1和第2电动机的旋转方向都存在不反转的角(拐角)的形状;描绘第1和第2电动机中的一个在一个方向上旋转,且第1和第2电动机中的另一个的旋转方向反转的弧的形状。
[0004]
专利文献2中记载有一种位置驱动控制系统,具有:一个位置指令控制装置;位置驱动控制装置,其具有按各伺服电动机设置的多个位置驱动控制部,从位置指令控制装置被给予位置指令,所述位置驱动控制系统具有存储各轴的控制状态数据的共享存储器,位置驱动控制部具有:轴间修正速度和转矩控制部,其在多轴的同步和调谐控制时,从共享存储器中取得其他轴的控制状态数据来计算其他轴的负载变动对应的轴间修正指令值,通过由该轴间修正速度和转矩控制部计算出的轴间修正指令值来修正本轴的指令值。
[0005]
现有技术文献
[0006]
专利文献1:日本特开2019-003404号公报
[0007]
专利文献2:日本特开2001-100819号公报
[0008]
在通过多个伺服控制部来对驱动多个轴的多个电动机进行控制时,在一个伺服控制部驱动一个轴时,该一个轴的驱动有时会对其他伺服控制部驱动的其他轴的驱动产生干扰。
[0009]
为了提升受干扰侧的伺服控制部中的指令随动性,希望对该干扰进行校正。
技术实现要素:
[0010]
(1)本公开的第一方式提供一种机器学习装置,对控制多个电动机的多个伺服控制部进行机器学习,所述电动机对具有多个轴,该多个轴中的一个轴因其他至少一个轴的运动而受干扰的机器进行驱动,
[0011]
所述多个伺服控制部中的、受干扰的轴相关的第1伺服控制部具有:校正部,其根
据函数来求出对所述第1伺服控制部的位置偏差、速度指令、转矩指令中的至少一个进行校正的校正值,所述函数包含给予干扰的轴相关的第2伺服控制部的位置指令相关的变量和位置反馈信息相关的变量中的至少一个变量,
[0012]
所述机器学习装置具有:
[0013]
状态信息取得部,其取得状态信息,该状态信息包含所述第1伺服控制部的第1伺服控制信息、所述第2伺服控制部的第2伺服控制信息、所述函数的系数;
[0014]
行为信息输出部,其将包含调整信息的行为信息输出给所述校正部,该调整信息是所述状态信息所包含的所述系数的调整信息;
[0015]
回报输出部,其输出使用了评价函数的、强化学习中的回报值,该评价函数是所述第1伺服控制信息的函数;以及
[0016]
价值函数更新部,其根据由所述回报输出部输出的回报值、所述状态信息、所述行为信息来更新价值函数。
[0017]
(2)本公开的第二方式提供一种伺服控制装置,包含:
[0018]
上述(1)所记载的机器学习装置;以及
[0019]
多个伺服控制部,其对多个电动机进行控制,所述多个电动机对具有多个轴的机器进行驱动,该多个轴中的一个轴因其他至少一个轴的运动而受干扰,
[0020]
所述多个伺服控制部中的、受干扰的轴相关的第1伺服控制部具有:校正部,其根据函数来求出对所述第1伺服控制部的位置偏差、速度指令、转矩指令中的至少一个进行校正的校正值,所述函数包含给予干扰的轴相关的第2伺服控制部的位置指令相关的变量和位置反馈信息相关的变量中的至少一个变量,
[0021]
所述机器学习装置将包含所述系数的调整信息的行为信息输出给所述校正部。
[0022]
(3)本公开的第三方式提供一种伺服控制系统,包含:
[0023]
上述(1)所记载的机器学习装置;以及
[0024]
伺服控制装置,其包含对多个电动机进行控制的多个伺服控制部,所述多个电动机对具有多个轴的机器进行驱动,该多个轴中的一个轴因其他至少一个轴的运动而受干扰,
[0025]
所述多个伺服控制部中的、受干扰的轴相关的第1伺服控制部具有:校正部,其根据函数来求出对所述第1伺服控制部的位置偏差、速度指令、转矩指令中的至少一个进行校正的校正值,所述函数包含给予干扰的轴相关的第2伺服控制部的位置指令相关的变量和位置反馈信息相关的变量中的至少一个变量,
[0026]
所述机器学习装置将包含所述系数的调整信息的行为信息输出给所述校正部。
[0027]
(4)本公开的第四方式提供一种机器学习装置的机器学习方法,所述机器学习装置对控制多个电动机的多个伺服控制部进行机器学习,所述多个电动机对具有多个轴的机器进行驱动,该多个轴中的一个轴因其他至少一个轴的运动而受干扰,
[0028]
所述多个伺服控制部中的、受干扰的轴相关的第1伺服控制部具有:校正部,其根据函数来求出对所述第1伺服控制部的位置偏差、速度指令、转矩指令中的至少一个进行校正的校正值,所述函数包含给予干扰的轴相关的第2伺服控制部的位置指令相关的变量和位置反馈信息相关的变量中的至少一个变量,
[0029]
所述机器学习方法中,
[0030]
取得状态信息,该状态信息包含所述第1伺服控制部的第1伺服控制信息、所述第2伺服控制部的第2伺服控制信息、所述函数的系数,
[0031]
将包含调整信息的行为信息输出给所述校正部,该调整信息是所述状态信息所包含的所述系数的调整信息,
[0032]
输出使用了评价函数的、强化学习中的回报值,该评价函数是所述第1伺服控制信息的函数,
[0033]
根据所述回报值、所述状态信息、所述行为信息来更新价值函数。
[0034]
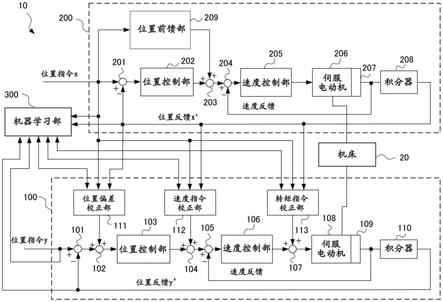
发明效果
[0035]
根据本公开的各方式,可以在受干扰的轴相关的伺服控制部中,避免繁杂的调整,并且可以校正轴间干扰,提升指令随动性。
附图说明
[0036]
图1是表示本公开的第1实施方式的伺服控制装置的框图。
[0037]
图2是移动作为机床的4轴加工机的主轴的主轴移动机构的部分结构图。
[0038]
图3是表示作为机床的5轴加工机的搭载工件的工作台机构的部分结构图。
[0039]
图4是表示本公开的第1实施方式的机器学习部的框图。
[0040]
图5是表示对图2所示的4轴加工机进行驱动时的机器学习涉及的系数调整前的位置反馈信息的变动的特性图。
[0041]
图6是表示对图2所示的4轴加工机进行驱动时的机器学习涉及的系数调整后的位置反馈信息的变动的特性图。
[0042]
图7是表示对图3所示的5轴加工机进行驱动时的机器学习涉及的系数调整前的旋转轴与x轴的位置反馈信息的变动的特性图。
[0043]
图8是表示对图3所示的5轴加工机进行驱动时的机器学习涉及的系数调整后的旋转轴与x轴的位置反馈信息的变动的特性图。
[0044]
图9是对本公开的第1实施方式的机器学习部的动作进行说明的流程图。
[0045]
图10是对本公开的第1实施方式的机器学习部的优化行为信息输出部的动作进行说明的流程图。
[0046]
图11是表示包含伺服控制装置和机器学习装置的伺服控制系统的一结构例的框图。
[0047]
符号说明
[0048]
10、10-1~10-n 伺服控制装置
[0049]
20、20-1~20-n 机床
[0050]
100、200 伺服控制部
[0051]
101、201 减法器
[0052]
102 加法器
[0053]
103、202 位置控制部
[0054]
104、203 加法器
[0055]
105、204 减法器
[0056]
106、205 速度控制部
[0057]
107 加法器
[0058]
108、206 伺服电动机
[0059]
109、207 旋转编码器
[0060]
110、208 积分器
[0061]
111 位置偏差校正部
[0062]
112 速度指令校正部
[0063]
113 转矩指令校正部
[0064]
209 位置前馈部
[0065]
300 机器学习部
[0066]
300-1~300-n 机器学习装置
[0067]
400 网络
具体实施方式
[0068]
以下,使用附图对本公开的实施方式进行详细说明。
[0069]
(第1实施方式)
[0070]
图1是表示本公开的第1实施方式的伺服控制装置的框图。
[0071]
如图1所示,伺服控制装置10具有伺服控制部100、200和机器学习部300。机器学习部300是机器学习装置。机器学习部300可以设置在伺服控制部100或者伺服控制部200内。机床20通过伺服控制部100、200而被驱动。
[0072]
作为伺服控制部100和200的控制对象,这里列举机床20来进行说明,但是成为控制对象的机器不限于机床,例如也可以是机器人、工业机器等。伺服控制部100和200也可以设置为机床、机器人、工业机器等机器的一部分。
[0073]
伺服控制部100和200控制机床20的2个轴。机床例如是3轴加工机、4轴加工机或者5轴加工机,2个轴例如是y轴与z轴等2个直线轴,或者x轴与b轴等直线轴和旋转轴。机床20的具体结构在后面进行描述。
[0074]
伺服控制部100具有:减法器101、加法器102、位置控制部103、加法器104、减法器105、速度控制部106、加法器107、伺服电动机108、旋转编码器109、积分器110、位置偏差校正部111、速度指令校正部112以及转矩指令校正部113。
[0075]
伺服控制部200具有:减法器201、位置控制部202、加法器203、减法器204、速度控制部205、伺服电动机206、旋转编码器207、积分器208以及位置前馈部209。
[0076]
伺服控制部100对应于受干扰的轴相关的第1伺服控制部,伺服控制部200对应于给予干扰的轴相关的第2伺服控制部。
[0077]
伺服控制部100与伺服控制部200的差异是伺服控制部100具有位置偏差校正部111、速度指令校正部112以及转矩指令校正部113。之所以设置位置偏差校正部111、速度指令校正部112以及转矩指令校正部113,是因为在伺服控制部200对机床20的一个轴进行驱动时,该一个轴的驱动对伺服控制部100驱动的其他轴的驱动产生干扰,通过伺服控制部100来对该一个轴的驱动的影响进行校正。
[0078]
图1中位置前馈部209设置于伺服控制部200,但是也可以不设置。此外,位置前馈部209可以设置于伺服控制部100中,也可以设置于伺服控制部100与伺服控制部200双方
中。
[0079]
以下,对伺服控制装置10的各部以及机床20进行进一步说明。首先,对给予干扰的轴相关的伺服控制部200进行说明。另外,受干扰的轴相关的伺服控制部100将在后面进行描述。
[0080]
<伺服控制部200>
[0081]
生成位置指令x,以便通过上位控制装置或者外部输入装置等,按照规定的加工程序来改变脉冲频率,以使伺服电动机206的速度变化。位置指令x是控制指令。位置指令x被输出给减法器201、位置前馈部209、位置偏差校正部111、速度指令校正部112、转矩指令校正部113、以及机器学习部300。
[0082]
减法器201求出位置指令x与位置反馈(位置fb)的检测位置(成为位置反馈信息x’)之差,将该差作为位置偏差输出给位置控制部202。
[0083]
位置控制部202将位置增益kp乘以位置偏差而得的值作为速度指令输出给加法器203。
[0084]
加法器203将速度指令与位置前馈部209的输出值(位置前馈项)相加,作为前馈控制的速度指令输出给减法器204。
[0085]
减法器204求出加法器203的输出与速度反馈的速度检测值之差,将该差作为速度偏差输出给速度控制部205。
[0086]
速度控制部205将积分增益k1v乘以速度偏差而进行了积分而得的值与比例增益k2v乘以速度偏差而得的值相加,作为转矩指令输出给伺服电动机206。
[0087]
积分器208对从旋转编码器207输出的速度检测值进行积分而输出位置检测值。
[0088]
旋转编码器207将速度检测值作为速度反馈信息输出给减法器204。积分器208从速度检测值求出位置检测值,将该位置检测值作为位置反馈(位置fb)信息x’输出给减法器201。位置反馈(位置fb)信息x’也被输出给机器学习部300、位置偏差校正部111、速度指令校正部112以及转矩指令校正部113。
[0089]
旋转编码器207和积分器208是检测器,伺服电动机206可以是进行旋转运动的电动机,也可以是进行直线运动的线性电动机。
[0090]
位置前馈部209将对位置指令值进行微分并乘以常数而得的值与位置前馈系数相乘,将相乘得到的值作为位置前馈项,输出给加法器203。
[0091]
如上所述,构成伺服控制部200。
[0092]
<伺服控制部100>
[0093]
生成位置指令y,以便通过上位控制装置或外部输入装置等,按照规定的加工程序改变脉冲频率,以使伺服电动机108的速度变化。位置指令y为控制指令。位置指令y被输出给减法器101和机器学习部300。
[0094]
减法器101求出位置指令y与位置反馈的检测位置(成为位置反馈信息y’)之差,将该差作为位置偏差输出给加法器102。
[0095]
加法器102求出位置偏差与从位置偏差校正部111输出的位置偏差校正值之差,将该差作为校正后的位置偏差输出给位置控制部103。
[0096]
位置控制部103将位置增益kp乘以校正后的位置偏差而得的值作为速度指令输出给加法器104。
[0097]
加法器104求出速度指令与从速度指令校正部112输出的速度指令校正值之差,将该差作为校正后的速度指令输出给减法器105。
[0098]
减法器105求出加法器104的输出与速度反馈的速度检测值之差,将该差作为速度偏差输出给速度控制部106。
[0099]
速度控制部106将积分增益k1v乘以速度偏差并进行了积分而得的值与比例增益k2v乘以速度偏差而得的值相加,作为转矩指令输出给加法器107。
[0100]
加法器107求出转矩指令与从转矩指令校正部113输出的转矩指令校正值之差,将该差作为校正后的转矩指令输出给伺服电动机108。
[0101]
积分器110对从旋转编码器109输出的速度检测值进行积分输出位置检测值。
[0102]
旋转编码器109将速度检测值作为速度反馈信息输出给减法器105。积分器110从速度检测值求出位置检测值,将该位置检测值作为位置反馈信息y’输出给减法器101和机器学习部300。
[0103]
旋转编码器109和积分器110是检测器,伺服电动机108可以是进行旋转运动的电动机,也可以是进行直线运动的线性电动机。
[0104]
位置偏差校正部111接受从伺服控制部200的积分器208输出的位置反馈信息x’、输入给伺服控制部200的位置指令x、以及从机器学习部300输出的由以下的数学公式1(以下的数学式1)所表示的函数的系数a1~a6的变更量,使用数学公式1,求出位置偏差校正值err
comp
并输出给加法器102。
[0105]
【数学式1】
[0106][0107]
速度指令校正部112接受从伺服控制部200的积分器208输出的位置反馈信息x’、输入给伺服控制部200的位置指令x、以及从机器学习部300输出的由以下的数学公式2(以下的数学式2)所表示的函数的系数b1~b6的变更量,使用数学公式2,求出速度指令校正值vcmd
comp
并输出给加法器104。
[0108]
【数学式2】
[0109][0110]
转矩指令校正部113接受从伺服控制部200的积分器208输出的位置反馈信息x’、输入给伺服控制部200的位置指令x、以及从机器学习部300输出的由以下的数学公式3(以下的数学式3)所表示的函数的系数c1~c6的变更量,使用数学公式3,求出转矩指令校正值tcmd
comp
并输出给加法器107。
[0111]
【数学式3】
[0112][0113]
位置偏差校正部111、速度指令校正部112以及转矩指令校正部113对应于校正部,使用伺服控制部200的位置指令x、位置反馈信息x’来制作伺服控制部100的位置偏差的校正值err
comp
、速度指令的校正值vcmd
comp
以及转矩指令的校正值tcmd
comp
。伺服控制部100的
位置偏差、速度指令以及转矩指令中,无视方向,将校正值err
comp
、速度指令的校正值vcmd
comp
以及转矩指令的校正值tcmd
comp
的标量值(scalar value)相加。这样,可以从伺服控制部100的位置偏差、速度指令以及转矩指令中消除由伺服控制部200驱动的轴涉及的干扰量。位置偏差校正部111、速度指令校正部112以及转矩指令校正部113不需要全部设置,可以根据需要来设置位置偏差校正部111、速度指令校正部112以及转矩指令校正部113中的一个或者两个。
[0114]
另外,数学公式1~3分别是作为变量而包含位置指令x、位置指令x的1阶微分、位置指令x的2阶微分、位置反馈信息x’、位置反馈信息x’的1阶微分、位置反馈信息x’的2阶微分的式子。但是,数学公式1~3也可以不全部包含这些变量,可以适当选择一个或者多个。例如,可以从位置指令x的2阶微分与位置反馈信息x’的2阶微分,即,位置指令x的加速度与位置反馈信息x’的加速度求出位置偏差的校正值err
comp
、速度指令的校正值vcmd
comp
以及转矩指令的校正值tcmd
comp
。
[0115]
位置指令x、位置指令x的1阶微分、位置指令x的2阶微分分别是位置指令相关的变量,位置反馈信息x’、位置反馈信息x’的1阶微分、位置反馈信息x’的2阶微分分别是位置反馈信息相关的变量。
[0116]
如上所述,构成伺服控制部100。
[0117]
<机床20>
[0118]
机床20例如是3轴加工机、4轴加工机、5轴加工机。
[0119]
图2是移动4轴加工机的主轴的主轴移动机构的部分结构图。图3是表示5轴加工机的搭载工件的工作台机构的部分结构图。
[0120]
机床20是图2所示的4轴加工机20a时,例如伺服控制部200控制y轴的直线移动,伺服控制部100控制z轴的直线移动。该情况下,伺服控制部200为给予干扰的轴相关的伺服控制部,伺服控制部100为受干扰的轴相关的伺服控制部。
[0121]
如图2所示,x轴移动台22在x轴方向上可移动地装载于静止台21上,y轴移动柱23在y轴方向上可移动地装载于x轴移动台22上。此外,主轴安装台24安装在y轴移动柱23的侧面,主轴25相对于b轴能够转动,且在z轴方向上可移动地安装在主轴安装台24上。例如,y轴移动柱23在y轴方向加减速时,主轴25在z轴方向的驱动从y轴受到干扰。
[0122]
机床20是图3所示的5轴加工机20b时,例如伺服控制部200控制旋转轴的旋转,伺服控制部100控制作为直线轴的x轴的直线移动。如图3所示,有离心负载的旋转分度工作台28的旋转轴配置于直线轴上时,彼此给予影响而产生干扰。为了排除该干扰,在伺服控制部100与伺服控制部200的至少一方中设置校正部。这里,在伺服控制部100作为校正部而设置位置偏差校正部111、速度指令校正部112、转矩指令校正部113。与图2所示的4轴加工机20a一样,伺服控制部200为给予干扰的轴的伺服控制部,伺服控制部100为受干扰的轴的伺服控制部。输入到伺服控制部200的位置指令是规定旋转轴的旋转角度的指令。
[0123]
如图3所示,x轴移动台27在x轴方向上可移动地装载于静止台26上,旋转分度工作台28可转动地装载于x轴移动台27上。因搭载于旋转分度工作台28的工件或者工件夹具的影响,有时在从旋转轴的中心偏离的位置处形成离心负载29。形成离心负载29时,x轴移动台27与旋转分度工作台28之间彼此产生干扰。
[0124]
另外,关于伺服控制部100和伺服控制部200的结构,在对图2所示的4轴加工机20a
进行驱动时、对图3所示的5轴加工机20b进行驱动时,结构是相同的。其中,关于伺服控制部100的位置偏差校正部111的数学公式1的系数a1~a6、速度指令校正部112的数学公式2的系数b1~b6、转矩指令校正部113的数学公式3的系数c1~c6的值,在y轴对z轴给予干扰的图2所示的4轴加工机20a和旋转轴与x轴彼此干扰的图3所示的5轴加工机20b中彼此不同。
[0125]
<机器学习部300>
[0126]
机器学习部300执行预先设定的加工程序(以下,也称为“学习时的加工程序”),使用从伺服控制部100输出的位置指令y以及位置反馈(位置fb)信息y,对位置偏差校正部111的系数a1~a6、速度指令校正部112的系数b1~b6以及转矩指令校正部113的系数c1~c6进行机器学习(以下,称为学习)。机器学习部300是机器学习装置。机器学习部300进行的学习可以在出库前进行,也可以在出库后进行再学习。
[0127]
以下,作为机床20而使用4轴加工机20a,伺服控制部200通过学习时的加工程序来控制伺服电动机206,伺服电动机206对4轴加工机20a的y轴进行驱动。此外,伺服控制部100通过学习时的加工程序来控制伺服电动机108,伺服电动机108对4轴加工机20a的z轴进行驱动。
[0128]
对4轴加工机20a进行驱动的学习时的加工程序,通过对给予干扰的轴的伺服控制部200进行控制可以使y轴往复移动,通过对受干扰的轴的伺服控制部100进行控制可以使z轴往复移动也可以不往复移动。以下的说明中,对不使z轴移动的情况进行说明。
[0129]
通过学习时的加工程序,上位控制装置或者外部输入装置对伺服控制部200输出使y轴往返移动的位置指令,对伺服控制部100输出使z轴静止的位置指令。但是,即使输入使z轴静止的位置指令,伺服控制部100因y轴的移动产生的干扰,使得伺服控制部100的位置偏差、速度指令以及转矩指令受到影响。因此,机器学习部300通过对位置偏差校正部111的系数a1~a6、速度指令校正部112的系数b1~b6以及转矩指令校正部113的系数c1~c6进行学习,将位置偏差、速度指令以及转矩指令的校正值设定为最佳值。
[0130]
以下,对机器学习部300进行更详细的说明。
[0131]
在以下的说明中对机器学习部300进行强化学习的情况进行说明,但是机器学习部300进行的学习并不特别限定于强化学习,例如,本发明还能够应用于进行监督学习的情况。
[0132]
在进行机器学习部300所包含的各功能块的说明之前,首先对强化学习的基本结构进行说明。智能体(相当于本实施方式中的机器学习部300)观测环境状态,选择某个行为,根据该行为环境发生变化。随着环境的变化,提供某种回报,智能体学习更好的行为选择(决策)。
[0133]
监督学习表示完全的正确答案,而强化学习中的回报大多是基于环境的部分变化的片段值。因此,智能体学习选择行为使得到将来的回报合计为最大。
[0134]
这样,在强化学习中通过学习行为,在行为给予环境的相互作用基础上学习适当的行为,即学习用于使将来获得的回报为最大的要学习的方法。这表示在本实施方式中,可以获得例如选择在受干扰的轴相关的伺服控制部中,用于对轴间干扰进行校正的行为信息这样的、影响未来的行为。
[0135]
这里,作为强化学习可以使用任意的学习方法,在以下的说明中,以在某种环境状态s下,使用q学习(q-learning)的情况为例进行说明,所述q学习是学习选择行为a的价值q
(s、a)的方法。
[0136]
q学习以在某种状态s时从能够取得的行为a中将价值q(s、a)最高的行为a选择为最佳行为为目的。
[0137]
但是,在最初开始q学习的时间点,对于状态s与行为a的组合来说,完全不知道价值q(s、a)的正确值。因此,智能体在某种状态s下选择各种行为a,针对当时的行为a,根据给予的回报,选择更好的行为,由此,继续学习正确的价值q(s、a)。
[0138]
此外,想要使将来获得的回报的合计最大化,因此,目标是最终成为q(s、a)=e[σ(γ
t
)r
t
]。这里,e[]表示期待值,t表示时刻、γ表示后述的称为折扣率的参数,r
t
表示时刻t的回报,σ是时刻t的合计。该数学式中的期待值是按最佳行为状态发生变化时的期望值。但是在q学习的过程中,由于不知道最佳行为,因此通过进行各种行为,一边搜索一边进行强化学习。这样的价值q(s、a)的更新式例如可以通过如下的数学公式4(以下表示为数学式4)来表示。
[0139]
【数学式4】
[0140][0141]
在上述的数学式4中,s
t
表示时刻t的环境状态,a
t
表示时刻t的行为。通过行为a
t
,状态变化为s
t+1
。r
t+1
表示通过该状态的变化而得到的回报。此外,带有max的项是:在状态s
t+1
下,将γ乘以选择出当时知道的q值最高的行为a时的q值而得的。这里,γ是0<γ≤1的参数,称为折扣率。此外,α是学习系数,设α的范围为0<α≤1。
[0142]
上述的数学公式4表示如下方法:根据尝试a
t
的结果而反馈回来的回报r
t+1
,更新状态s
t
下的行为a
t
的价值q(s
t
、a
t
)。
[0143]
该更新式表示了:若行为a
t
导致的下一状态s
t+1
下的最佳行为的价值max
a q(s
t+1
、a)比状态s
t
下的行为a
t
的价值q(s
t
、a
t
)大,则增大q(s
t
、a
t
),反之如果小,则减小q(s
t
、a
t
)。也就是说,使某种状态下的某种行为的价值接近该行为导致的下一状态下的最佳行为价值。其中,尽管其差因折扣率γ和回报r
t+1
的存在形式而变化,但基本上是某种状态下的最佳行为价值传播至其前一个状态下的行为价值的结构。
[0144]
这里,q学习存在如下方法:制作针对所有状态行为对(s、a)的q(s、a)的表格,来进行学习。但是,有时为了求出所有状态行为对的q(s、a)的值状态数量会过多,使得q学习收敛需要很多时间。
[0145]
因此,可以利用公知的称为dqn(deep q-network)的技术。具体来说,可以使用适当的神经网络来构成价值函数q,调整神经网络的参数,由此通过适当的神经网络来近似价值函数q来计算价值q(s、a)的值。通过利用dqn,能够缩短q学习收敛所需的时间。另外,关于dqn,例如在以下的非专利文献中有详细的记载。
[0146]
<非专利文献>
[0147]“human-level control through deep reinforcement learning”,volodymyr mnih1著[online],[平成29年1月17日检索],因特网〈url:http://files.davidqiu.com/research/nature14236.pdf〉
[0148]
机器学习部300进行以上说明的q学习。具体来说,机器学习部300通过执行学习时的加工程序而从伺服控制部200取得位置指令x的集合与位置反馈信息x’的集合。此外,机
器学习部300通过执行学习时的加工程序而取得伺服控制部100的位置指令y的集合与位置反馈信息y’的集合。位置指令y与位置反馈信息y’是第1伺服控制信息,位置指令x与位置反馈信息x’是第2伺服控制信息。位置指令y指令z轴的静止。位置指令x的集合与位置反馈信息x’的集合、以及位置指令y的集合与位置反馈信息y’的集合是状态s。并且,机器学习部300学习如下价值q:将该状态s有关的、伺服控制部100的位置偏差校正部111的数学公式1的系数a1~a6、速度指令校正部112的数学公式2的系数b1~b6、转矩指令校正部113的数学公式3的系数c1~c6的值的调整,选择为行为a。
[0149]
伺服控制部200执行学习时的加工程序,进行驱动y轴的伺服电动机206的伺服控制。此外,伺服控制部100执行学习时的加工程序,进行伺服电动机108的伺服控制,以便使用通过具有系数a1~a6的数学公式1、具有系数b1~b6的数学公式2、具有系数c1~c6的数学公式3求出的位置偏差校正值、速度指令校正值、转矩指令校正值来校正位置偏差、速度指令、转矩指令,并且根据位置指令使z轴静止。
[0150]
机器学习部300观测状态s的信息,而决定行为a,所述状态s包含通过执行学习时的加工程序而取得的、位置指令x的集合与位置反馈信息x’的集合、以及位置指令y的集合与位置反馈信息y’的集合。机器学习部300每当进行行为a时给予回报。机器学习部300例如试错性地搜索最佳行为a以使到将来的回报合计为最大。通过这样,机器学习部300能够针对状态s选择最佳的行为a(即,系数a1~a6、系数b1~b6、系数c1~c6),所述状态s包含通过执行学习时的加工程序而取得的位置指令x的集合与位置反馈信息x’的集合、以及根据系数a1~a6、系数b1~b6、系数c1~c6来执行学习时的加工程序而取得的位置指令y的集合与位置反馈信息y’的集合。
[0151]
即,根据由机器学习部300学习到的价值函数q,选择应用于某种状态s有关的系数a1~a6、系数b1~b6、系数c1~c6的行为a中的、q值为最大的行为a,由此,能够选择对执行学习时的加工程序而产生的轴间干扰进行校正的行为a(即,系数a1~a6、系数b1~b6、系数c1~c6)。
[0152]
图4是表示本公开的第1实施方式的机器学习部300的框图。
[0153]
为了进行上述的强化学习,如图4所示,机器学习部300具有:状态信息取得部301、学习部302、行为信息输出部303、价值函数存储部304以及优化行为信息输出部305。学习部302具有:回报输出部3021、价值函数更新部3022以及行为信息生成部3023。
[0154]
状态信息取得部301取得状态s,所述状态s包含通过执行学习时的加工程序而取得的、伺服控制部200的位置指令x的集合与位置反馈信息x’(成为第2伺服控制信息)的集合、以及根据位置偏差校正部111的数学公式1的系数a1~a6、速度指令校正部112的数学公式2的系数b1~b6、转矩指令校正部113的数学公式3的系数c1~c6,执行学习时的加工程序而取得的、伺服控制部100的位置指令y的集合与位置反馈信息y’的集合。该状态信息s相当于q学习中的环境状态s。另外,图4中,系数a1~a6、系数b1~b6、系数c1~c6为了简化而表示为系数a、b、c。
[0155]
状态信息取得部301将取得的状态信息s输出给学习部302。
[0156]
另外,最初开始q学习的时间点的位置偏差校正部111的数学公式1的系数a1~a6、速度指令校正部112的数学公式2的系数b1~b6、转矩指令校正部113的数学公式3的系数c1~c6预先由用户生成。本实施方式中,通过强化学习将用户制作出的系数a1~a6、系数b1~
b6、系数c1~c6的初始设定值调整为最佳。
[0157]
另外,在操作员预先调整了机床的情况下,可以将调整完的值作为初始值来对系数a1~a6、系数b1~b6、系数c1~c6进行机器学习。
[0158]
学习部302是在某种环境状态s下对选择某种行为a时的价值q(s、a)进行学习的部分。
[0159]
回报输出部3021是在某种状态s下计算选择了行为a时的回报的部分。通过状态s’来表示因行为a(系数a1~a6、系数b1~b6、系数c1~c6的修正)而从状态s发生了变化的状态。
[0160]
回报输出部3021求出状态s以及状态s’下的、位置指令y与位置反馈信息y’之差(y-y’)。回报输出部3021中,通过位置指令y与位置反馈信息y’之差而求出的位置偏差为第2位置偏差。将差(y-y’)的集合称为位置偏差集合,通过pd(s)来表示状态s下的位置偏差集合,通过pd(s’)来表示状态s’下的位置偏差集合。
[0161]
作为评价函数f,通过位置偏差e来表示受干扰的轴的伺服控制部100的位置偏差(y-y’)时,例如可以应用:
[0162]
计算位置偏差的绝对值的积分值的函数
[0163]
∫|e|dt
[0164]
对位置偏差的绝对值进行时间加权计算积分值的函数
[0165]
∫t|e|dt
[0166]
计算位置偏差的绝对值的2n(n是自然数)次幂的积分值的函数
[0167]
∫e
2n
dt(n是自然数)
[0168]
计算位置偏差的绝对值的最大值的函数
[0169]
max{|e|}。
[0170]
将通过位置偏差集合pd(s)求出的评价函数f的值设为评价函数值f(pd(s)),将通过位置偏差集合pd(s’)求出的评价函数f的值设为评价函数值f(pd(s’))。
[0171]
输入到伺服控制部100的位置指令y不是使z轴静止的指令,而是使z轴往返移动的指令,评价函数可以使用上述评价函数f。
[0172]
此时,根据通过行为信息a进行了修正的状态信息s’有关的修正后的位置偏差校正部111、速度指令校正部112以及转矩指令校正部113,伺服控制部100动作时的评价函数值f(pd(s’)),比根据通过行为信息a进行修正前的状态信息s有关的修正前的位置偏差校正部111、速度指令校正部112以及转矩指令校正部113,伺服控制部100动作时的评价函数值f(pd(s))大时,回报输出部3021使回报值为负值。
[0173]
另一方面,在评价函数值f(pd(s’))比评价函数值f(pd(s))小时,回报输出部3021使回报值为正值。
[0174]
另外,在评价函数f(pd(s’))与评价函数值f(pd(s))相等时,回报输出部3021使回报值为零。
[0175]
此外,作为执行行为a后的状态s’的评价函数值f(pd(s’))比之前的状态s下的评价函数值f(pd(s))大时的负值,可以根据比例将负值的绝对值设定得大。也就是说,根据f(pd(s’))的值变大的程度使得负值的绝对值变大。反之,作为执行行为a后的状态s’的评价函数值f(pd(s’))比之前的状态s下的评价函数值f(pd(s))小时的正值,根据比例将正值设定得大。也就是说,根据f(pd(s’))的值变小的程度使得正值变大。
[0176]
价值函数更新部3022根据状态s、行为a、将行为a应用于状态s时的状态s’、如上所述计算出的回报的值来进行q学习,由此,对价值函数存储部304存储的价值函数q进行更新。
[0177]
价值函数q的更新既可以通过在线学习来进行,也可以通过批量学习来进行,还可以通过小批量学习来进行。
[0178]
在线学习是如下学习方法:通过将某种行为a应用于当前状态s,每当状态s向新状态s’转移时,立即进行价值函数q的更新。此外,批量学习是如下学习方法:通过重复将某种行为a应用于当前状态s,状态s向新状态s’转移,由此收集学习用的数据,使用收集到的所有学习用数据,来进行价值函数q的更新。并且,小批量学习是在线学习与批量学习中间的学习方法,是每当积攒了某种程度学习用数据时进行价值函数q的更新的学习方法。
[0179]
行为信息生成部3023针对当前状态s选择q学习的过程中的行为a。行为信息生成部3023在q学习的过程中,为了进行对位置偏差校正部111的数学公式1的系数a1~a6、速度指令校正部112的数学公式2的系数b1~b6、转矩指令校正部113的数学公式3的系数c1~c6进行修正的动作(相当于q学习中的行为a),而生成行为信息a,将生成的行为信息a输出给行为信息输出部303。更具体来说,行为信息生成部3023例如针对状态s所包含的位置偏差校正部111的数学公式1的系数a1~a6、速度指令校正部112的数学公式2的系数b1~b6、转矩指令校正部113的数学公式3的系数c1~c6,使包含于行为a的、位置偏差校正部111的数学公式1的系数a1~a6、速度指令校正部112的数学公式2的系数b1~b6、转矩指令校正部113的数学公式3的系数c1~c6加上或减去增量。
[0180]
并且,可以采取如下策略:行为信息生成部3023在应用系数a1~a6、系数b1~b6、系数c1~c6的增加或减少而向状态s’转移,给予正回报(正值的回报)时,作为下一行为a’针对系数a1~a6、系数b1~b6、系数c1~c6与前次的动作同样地加上或减去增量等,选择评价函数f的值更小那样的行为a’。
[0181]
此外,反之还可以采取如下策略:当给予了负回报(负值的回报)时,行为信息生成部3023作为下一行为a’,例如针对系数a1~a6、系数b1~b6、系数c1~c6与前次的动作相反地减去或者加上增量等,选择评价函数比前次的值小的行为a’。
[0182]
此外,行为信息生成部3023也可以采取如下策略:通过在当前推定的行为a的价值中,选择价值q(s、a)最高的行为a’的贪婪算法、通过某个较小的概率ε随机选择行为a’,除此之外选择价值q(s、a)最高的行为a’的ε贪婪算法这样的众所周知的方法来选择行为a’。
[0183]
行为信息输出部303是针对位置偏差校正部111、速度指令校正部112、转矩指令校正部113发送从学习部302输出的行为信息a的部分。如上所述,位置偏差校正部111、速度指令校正部112、转矩指令校正部113根据该行为信息对当前状态s即当前设定的系数a1~a6、系数b1~b6、系数c1~c6进行微调整,而向下一状态s’(即,修正后的位置偏差校正部111的数学公式1的系数a1~a6、速度指令校正部112的数学公式2的系数b1~b6、转矩指令校正部113的数学公式3的系数c1~c6)转移。
[0184]
价值函数存储部304是存储价值函数q的存储装置。价值函数q例如按状态s和行为a而存储为表(以下,称为行为价值表)。存储于价值函数存储部304的价值函数q通过价值函数更新部3022而被更新。此外,存储于价值函数存储部304的价值函数q可以在其他机器学习部300之间被共享。如果在多个机器学习部300之间共享价值函数q,则可以通过各机器学
习部300分散地进行强化学习,因此,能够提升强化学习的效率。
[0185]
最佳化行为信息输出部305根据价值函数更新部3022进行q学习而更新了的价值函数q,生成用于使位置偏差校正部111、速度指令校正部112、转矩指令校正部113进行价值q(s、a)为最大的动作的行为信息a(以下,称为“最佳化行为信息”)。
[0186]
更具体来说,最佳化行为信息输出部305取得价值函数存储部304存储的价值函数q。该价值函数q如上所有是通过价值函数更新部3022进行q学习而被更新的函数。并且,最佳化行为信息输出部305根据价值函数q生成行为信息,对位置偏差校正部111、速度指令校正部112、转矩指令校正部113输出所生成的行为信息。在该最佳化行为信息中,与行为信息输出部303在q学习的过程中输出的行为信息一样,包含修正位置偏差校正部111的数学公式1的系数a1~a6、速度指令校正部112的数学公式2的系数b1~b6、转矩指令校正部113的数学公式3的系数c1~c6的信息。
[0187]
位置偏差校正部111、速度指令校正部112、转矩指令校正部113中根据该行为信息来修正系数a1~a6、系数b1~b6、系数c1~c6。
[0188]
机器学习部300可以按以上的动作来进行动作,以便进行位置偏差校正部111的数学公式1的系数a1~a6、速度指令校正部112的数学公式2的系数b1~b6、转矩指令校正部113的数学公式3的系数c1~c6的优化,对轴间干扰进行校正,提升指令随动性。
[0189]
图5是表示对图2所示的4轴加工机20a进行驱动时的机器学习涉及的系数(参数)调整前的位置反馈(位置fb)信息的变动的特性图。图6是表示对图2所示的4轴加工机20a进行驱动时的机器学习涉及的系数(参数)调整后的位置反馈(位置fb)信息的变动的特性图。
[0190]
图5和图6表示以使y轴往返移动、使z轴静止的方式对伺服控制部200和100进行驱动时的伺服控制部100的位置反馈信息的变动。如图6的特性图所示,通过机器学习涉及的系数(参数)调整可知图5的特性图的位置变动得以改善,指令随动性得以提升。
[0191]
图7是表示对图3所示的5轴加工机20b进行驱动时的机器学习涉及的系数(参数)调整前的旋转轴与x轴的位置反馈(位置fb)信息的变动的特性图。图8是表示对图3所示的5轴加工机20b进行驱动时的机器学习涉及的系数(参数)调整后的旋转轴与x轴的位置反馈(位置fb)信息的变动的特性图。图7和图8中,右纵轴表示作为直线轴的x轴的位置反馈(位置fb)信息的值,左纵轴表示旋转轴的位置反馈(位置fb)信息的值。
[0192]
图7和图8表示以使旋转轴旋转、使x轴静止的方式对伺服控制部200和100进行驱动时的伺服控制部100的位置反馈信息的变动。如图8的特性图所示,通过机器学习涉及的系数(参数)调整可知图7的特性图的x轴的位置变动得以改善,指令随动性得以提升。
[0193]
如上所述,通过利用本实施方式有关的机器学习部300,可以使位置偏差校正部111、速度指令校正部112、转矩指令校正部113的系数调整简化。
[0194]
以上,对伺服控制装置10所包含的功能块进行了说明。
[0195]
为了实现这些功能块,伺服控制装置10具有cpu(central processing unit,中央处理单元)等运算处理装置。此外,伺服控制装置10还具有存储应用软件或os(operating system,操作系统)等各种控制用程序的hdd(hard disk drive,硬盘驱动器)等辅助存储装置、存储运算处理装置执行程序之后暂时需要的数据的ram(random access memory,随机存取存储器)这样的主存储装置。
[0196]
并且,伺服控制装置10中运算处理装置从辅助存储装置中读入应用软件或os,一
边在主存储装置上展开读入的应用软件或os,一边进行基于这些应用软件或os的运算处理。此外,根据该运算结果来控制各装置具有的各种硬件。由此,实现本实施方式的功能块。也就是说,本实施方式可以通过硬件与软件协作来实现。
[0197]
关于机器学习部300,由于伴随机器学习的运算量增多,因此例如利用在个人计算机搭载gpu(graphics processing units,图形处理器),称为gpgpu(general-purpose computing on graphics processing units,通用图形处理器)的技术,在将gpu用于伴随机器学习的运算处理时可以进行高速处理。并且,为了进行更高速的处理,可以使用多台搭载了这样的gpu的计算机来构筑计算机集群,通过该计算机集群所包含的多个计算机来进行并行处理。
[0198]
接下来,参照图9的流程对本实施方式中的q学习时的机器学习部300的动作进行说明。
[0199]
步骤s11中,状态信息取得部301从伺服控制部100和200取得最初的状态信息s0。将取得的状态信息输出给价值函数更新部3022或行为信息生成部3023。如上所述,该状态信息s是相当于q学习中的状态的信息。
[0200]
最初开始q学习的时间点的状态s0下的、位置指令x的集合以及位置指令y的集合从上位控制装置或外部输入装置、或者伺服控制部200和伺服控制部100获得。状态s0下的、位置反馈信息x’的集合以及位置反馈信息y’的集合,通过按学习时的加工程序使伺服控制部100和伺服控制部200进行动作来获得。输入到伺服控制部200的位置指令x的集合是使y轴往返移动的指令,输入到伺服控制部100的位置指令y的集合是使z轴静止的指令。位置指令x输入到位置前馈部209、减法器201、位置偏差校正部111、速度指令校正部112、转矩指令校正部113以及机器学习部300。位置指令y输入到减法器101以及机器学习部300。位置偏差校正部111的数学公式1的系数a1~a6、速度指令校正部112的数学公式2的系数b1~b6、转矩指令校正部113的数学公式3的系数c1~c6的初始值由用户预先生成,系数a1~a6、系数b1~b6以及系数c1~c6的初始值被输送给机器学习部300。例如,初始值是将系数a1~a6全部设为0,将系数b1~b6全部设为0以及将系数c1~c6全部设为0。另外,机器学习部300中,也可以提取所述状态s0下的、位置指令x的集合与位置反馈信息x’的集合、位置指令y的集合与位置反馈信息y’的集合。
[0201]
步骤s12中,行为信息生成部3023生成新的行为信息a,将生成的新的行为信息a经由行为信息输出部303输出给位置偏差校正部111、速度指令校正部112以及转矩指令校正部113。行为信息生成部3023根据上述的策略,输出新的行为信息a。另外,接收到行为信息a的伺服控制部100通过根据接收到的行为信息对当前的状态s有关的位置偏差校正部111、速度指令校正部112以及转矩指令校正部113的系数a1~a6、系数b1~b6、系数c1~c6进行了修正的状态s’,对包含伺服电动机108的机床进行驱动。如上所述,该行为信息相当于q学习中的行为a。当前的状态s在最初开始q学习时是状态s0。
[0202]
步骤s13中,状态信息取得部301取得新的状态s’下的、位置指令x的集合与位置反馈信息x’的集合、位置指令y的集合与位置反馈信息y’的集合、系数a1~a6、系数b1~b6、以及系数c1~c6。这样,状态信息取得部301取得状态s’下的系数a1~a6、系数b1~b6以及系数c1~c6时的、位置指令x的集合与位置反馈信息x’的集合、位置指令y的集合与位置反馈信息y’的集合。将取得的状态信息输出给回报输出部3021。
[0203]
步骤s14中,回报输出部3021判断状态s’下的评价函数值f(pd(s’))与状态s下的评价函数值f(pd(s))的大小关系,在f(pd(s’))>f(pd(s))时,步骤s15中使回报为负值。f(pd(s’))<f(pd(s))时,步骤s16中使回报为正值。f(pd(s’))=f(pd(s))时,步骤s17中使回报为零。另外,可以对回报的负值、正值进行加权。另外,状态s在开始q学习的时间点是状态s0。
[0204]
步骤s15、步骤s16和步骤s17中的某一个结束时,在步骤s18中,根据在该某一个步骤计算出的回报值,价值函数更新部3022对存储在价值函数存储部304中的价值函数q进行更新。然后,再次返回到步骤s12,通过重复上述的处理,使得价值函数q收敛为适当的值。另外,可以以重复规定次数的上述处理、或重复规定时间的上述处理为条件来结束处理。
[0205]
另外,步骤s18示例了在线更新,也可以替换在线更新而置换成批量更新或小批量更新。
[0206]
以上,通过参照图9所说明的动作,在本实施方式中,通过利用机器学习部300获得以下效果:可以取得位置偏差校正部111的数学公式1的系数a1~a6、速度指令校正部112的数学公式2的系数b1~b6、转矩指令校正部113的数学公式3的系数c1~c6的调整用的、适当的价值函数,可以使系数a1~a6、系数b1~b6、以及系数c1~c6的优化简易化。
[0207]
接下来,参照图10的流程,对优化行为信息输出部305涉及的优化行为信息的生成时的动作进行说明。
[0208]
首先,步骤s21中,优化行为信息输出部305取得存储在价值函数存储部304中的价值函数q。如上所述价值函数q是通过价值函数更新部3022进行q学习而被更新的函数。
[0209]
步骤s22中,优化行为信息输出部305根据该价值函数q,生成优化行为信息,将生成的优化行为信息输出给伺服控制部100。
[0210]
此外,通过参照图10所说明的动作,本实施方式中,可以根据由机器学习部300进行学习而求出的价值函数q,生成优化行为信息,根据该优化行为信息,使当前设定的位置偏差校正部111的数学公式1的系数a1~a6、速度指令校正部112的数学公式2的系数b1~b6、转矩指令校正部113的数学公式3的系数c1~c6的调整简化,可以提升工件加工面的品质。
[0211]
上述的伺服控制装置以及机器学习部所包含的各结构部可以通过硬件、软件或者它们的组合来实现。此外,由上述伺服控制装置所包含的各结构部的各自协作来进行的伺服控制方法,也可以通过硬件、软件或者它们的组合来实现。这里,所谓通过软件来实现表示计算机通过读入程序来执行从而实现。
[0212]
可以使用各种类型的非临时性的计算机可读记录介质(non-transitory computer readable medium)来存储程序并将该程序提供给计算机。非临时性的计算机可读记录介质包含各种类型的有实体的记录介质(tangible storage medium)。非临时性的计算机可读记录介质的示例包含:磁记录介质(例如,硬盘驱动器)、光-磁记录介质(例如,光磁盘)、cd-rom(read only memory)、cd-r、cd-r/w、半导体存储器(例如,掩模rom、prom(programmable rom)、eprom(erasable prom)、闪存rom、ram(random access memory))。
[0213]
上述实施方式是本发明的优选实施方式,但是并非将本发明的范围仅限定于上述实施方式,可以在不脱离本发明精神的范围内以实施了各种变更的方式来进行实施。
[0214]
例如,上述实施方式中,机器学习部300为了求出评价函数f的值,而求出受干扰的轴的伺服控制部100的位置指令y与位置反馈信息y’之差,但是也可以使用伺服控制部100
的减法器101的输出即位置偏差(y-y’)来求出评价函数f的值。伺服控制部100的减法器101的输出即位置偏差(y-y’)是第1位置偏差。
[0215]
此外,上述实施方式中,以机器学习部300同时对位置偏差校正部111的数学公式1的系数a1~a6、速度指令校正部112的数学公式2的系数b1~b6、转矩指令校正部113的数学公式3的系数c1~c6进行学习的示例进行了说明,但是机器学习部300也可以对系数a1~a6、系数b1~b6以及系数c1~c6中的一个系数先进行学习并优化后,对其他系数依次进行学习来进行优化。
[0216]
此外,上述实施方式中,机器学习部300的回报输出部3021作为评价函数而使用了位置偏差,但是也可以使用速度偏差或者加速度偏差。
[0217]
速度偏差可以从位置偏差的时间微分求出,加速度偏差可以从速度偏差的时间微分求出。速度偏差可以使用加法器104的输出即速度指令与速度反馈信息之差,或者减法器105的输出。
[0218]
(第2实施方式)
[0219]
第1实施方式中,对机器学习部设置为伺服控制装置的一部分的示例进行了说明,但是本实施方式中,对机器学习部设置于伺服控制装置的外部而构成伺服控制系统的示例进行说明。以下,由于机器学习部与伺服控制装置独立地设置,因此称为机器学习装置。
[0220]
图11是表示包含伺服控制装置与机器学习装置的伺服控制系统的一个结构例的框图。图11所示的伺服控制系统30具有:n(n是2以上的自然数)个伺服控制装置10-1~10-n、n个机器学习装置300-1~300-n、以及连接伺服控制装置10-1~10-n与n个机器学习装置300-1~300-n的网络400。n(n是2以上的自然数)个伺服控制装置10-1~10-n与n个机床20-1~20-n连接。
[0221]
伺服控制装置10-1~10-n的每一个除了不具有机器学习部这一点以外,具有与图1的伺服控制装置10相同的结构。机器学习装置300-1~300-n具有与图5所示的机器学习部300相同的结构。
[0222]
这里,伺服控制装置10-1与机器学习装置300-1为1对1的组,能够通信地连接。伺服控制装置10-2~10-n和机器学习装置300-2~300-n也与伺服控制装置10-1和机器学习装置300-1一样地连接。图11中,伺服控制装置10-1~10-n与机器学习装置300-1~300-n的n个组经由网络400连接,而关于伺服控制装置10-1~10-n与机器学习装置300-1~300-n的n个组,各组的伺服控制装置与机器学习装置可以经由连接接口直接连接。这些伺服控制装置10-1~10-n与机器学习装置300-1~300-n这n个组,例如可以在同一个工厂中设置多组,也可以分别设置于不同的工厂中。
[0223]
另外,网络400例如是在工厂内构建的lan(local area network:局域网)、互联网、公共电话网、或者它们的组合。对于网络400中具体的通信方式是有线连接还是无线连接等不做特别限定。
[0224]
<系统结构的自由度>
[0225]
在上述的实施方式中,伺服控制装置10-1~10-n与机器学习装置300-1~300-n分别为一对一的组以能够通信的方式进行连接,但例如一台机器学习装置也可以经由网络400与多台电动机控制装置以及多台加速度传感器能够通信地连接,实施各电动机控制装置和各机床的机器学习。
[0226]
此时,可以是将一台机器学习装置的各功能适当分散到多个服务器的分散处理系统。此外,也可以在云上利用虚拟服务器功能等来实现一台机器学习装置的各功能。
[0227]
此外,当存在n台相同型号名称、相同规格、或者相同系列的与伺服控制装置10-1~10-n分别对应的n个机器学习装置300-1~300-n时,可以共享各机器学习装置300-1~300-n中的学习结果。这样,能够构建更理想的模型。
[0228]
本公开涉及的机器学习装置、控制系统以及机器学习方法可以取得包含上述实施方式、具有如下结构的各种实施方式。
[0229]
(1)本公开的一方式提供一种机器学习装置(例如,机器学习部300、机器学习装置300-1~300-n),对控制多个电动机的多个伺服控制部(例如,伺服控制部100、200)进行机器学习,所述多个电动机对具有多个轴的机器进行驱动,该多个轴中的一个轴因其他至少一个轴的运动而受干扰,
[0230]
所述多个伺服控制部中的、受干扰的轴相关的第1伺服控制部(例如,伺服控制部100)具有:校正部(例如,位置偏差校正部111、速度指令校正部112、转矩指令校正部113),其根据函数来求出对所述第1伺服控制部的位置偏差、速度指令、转矩指令中的至少一个进行校正的校正值,所述函数包含给予干扰的轴相关的第2伺服控制部(例如,伺服控制部200)的位置指令相关的变量和位置反馈信息相关的变量中的至少一个变量,
[0231]
所述机器学习装置具有:
[0232]
状态信息取得部(例如,状态信息取得部301),其取得状态信息,该状态信息包含所述第1伺服控制部的第1伺服控制信息、所述第2伺服控制部的第2伺服控制信息、所述函数的系数;
[0233]
行为信息输出部(例如,行为信息输出部303),其将包含调整信息的行为信息输出给所述校正部,该调整信息是所述状态信息所包含的所述系数的调整信息;
[0234]
回报输出部(例如,回报输出部3021),其输出使用了评价函数的、强化学习中的回报值,该评价函数是所述第1伺服控制信息的函数;以及
[0235]
价值函数更新部(例如,价值函数更新部3022),其根据由所述回报输出部输出的回报值、所述状态信息、所述行为信息来更新价值函数。
[0236]
根据该机器学习装置,可以实现对轴间干扰进行校正的伺服控制部的校正部系数的优化,可以避免伺服控制部中繁杂的调整,并且可以提升伺服控制部的指令随动性。
[0237]
(2)在上述(1)所记载的机器学习装置中,所述第1伺服控制信息包含所述第1伺服控制部的位置指令和位置反馈信息、或者所述第1伺服控制部的第1位置偏差,
[0238]
所述评价函数根据以下值来输出所述回报值,所述值包括:从所述第1伺服控制部的位置指令和位置反馈信息求出的第2位置偏差或者所述第1位置偏差、该第1中求出或者第2位置偏差的绝对值或者该绝对值的平方。
[0239]
(3)在上述(1)或者(2)所记载的机器学习装置中,所述第2伺服控制部的位置指令相关的变量是所述第2伺服控制部的所述位置指令、所述位置指令的1阶微分以及所述位置指令的2阶微分中的至少一个,
[0240]
所述第2伺服控制部的位置反馈信息相关的变量是所述第2伺服控制部的所述位置反馈信息、所述位置反馈信息的1阶微分以及所述位置反馈信息的2阶微分中的至少一个。
[0241]
(4)在上述(1)~(3)中任一项所记载的机器学习装置中,对所述第1伺服控制部以及所述第2伺服控制部进行控制的学习时的加工程序,在机器学习时,使给予所述干扰的轴运动,使受所述干扰的轴静止。
[0242]
(5)在上述(1)~(4)中任一项所记载的机器学习装置中,所述机器学习装置具有:优化行为信息输出部,其根据由所述价值函数更新部更新了的价值函数,输出所述校正部的所述系数的调整信息。
[0243]
(6)本公开的另一方式提供一种伺服控制装置(例如,伺服控制装置10),其包含:
[0244]
上述(1)~(5)中任一项所记载的机器学习装置(例如,机器学习部300);以及
[0245]
多个伺服控制部(例如,伺服控制部100、200),其对多个电动机进行控制,所述多个电动机对具有多个轴的机器进行驱动,该多个轴中的一个轴因其他至少一个轴的运动而受干扰,
[0246]
所述多个伺服控制部中的、受干扰的轴相关的第1伺服控制部(例如,伺服控制部100)具有:校正部(例如,位置偏差校正部111、速度指令校正部112、转矩指令校正部113),其根据函数来求出对所述第1伺服控制部的位置偏差、速度指令、转矩指令中的至少一个进行校正的校正值,所述函数包含给予干扰的轴相关的第2伺服控制部(例如,伺服控制部200)的位置指令相关的变量和位置反馈信息相关的变量中的至少一个变量,
[0247]
所述机器学习装置将包含所述系数的调整信息的行为信息输出给所述校正部。
[0248]
根据该伺服控制装置,可以避免伺服控制部中繁杂的调整,并且可以校正轴间干扰,提升指令随动性。
[0249]
(7)本公开的另一方式提供一种伺服控制系统(例如,伺服控制系统30),其包含:
[0250]
上述(1)~(5)中任一项所记载的机器学习装置;以及
[0251]
伺服控制装置(例如,伺服控制装置10-1~10-n),其包含对多个电动机进行控制的多个伺服控制部(例如,伺服控制部100、200),所述多个电动机对具有多个轴的机器进行驱动,该多个轴中的一个轴因其他至少一个轴的运动而受干扰,
[0252]
所述多个伺服控制部中的、受干扰的轴相关的第1伺服控制部(例如,伺服控制部100)具有:校正部(例如,位置偏差校正部111、速度指令校正部112、转矩指令校正部113),其根据函数来求出对所述第1伺服控制部的位置偏差、速度指令、转矩指令中的至少一个进行校正的校正值,所述函数包含给予干扰的轴相关的第2伺服控制部(例如,伺服控制部200)的位置指令相关的变量和位置反馈信息相关的变量中的至少一个变量,
[0253]
所述机器学习装置将包含所述系数的调整信息的行为信息输出给所述校正部。
[0254]
根据该伺服控制系统,可以避免伺服控制部中繁杂的调整,可以校正轴间干扰,提升指令随动性。
[0255]
(8)本公开的另一方式提供一种机器学习装置(例如,机器学习部300、机器学习装置300-1~300-n)的机器学习方法,所述机器学习装置对控制多个电动机的多个伺服控制部(例如,伺服控制部100、200)进行机器学习,所述多个电动机对具有多个轴的机器进行驱动,该多个轴中的一个轴因其他至少一个轴的运动而受干扰,
[0256]
所述多个伺服控制部中的、受干扰的轴相关的第1伺服控制部(例如,伺服控制部100)具有:校正部(例如,位置偏差校正部111、速度指令校正部112、转矩指令校正部113),其根据函数来求出对所述第1伺服控制部的位置偏差、速度指令、转矩指令中的至少一个进
行校正的校正值,所述函数包含给予干扰的轴相关的第2伺服控制部(例如,伺服控制部200)的位置指令相关的变量和位置反馈信息相关的变量中的至少一个变量,
[0257]
所述机器学习方法中,
[0258]
取得状态信息,该状态信息包含所述第1伺服控制部的第1伺服控制信息、所述第2伺服控制部的第2伺服控制信息、所述函数的系数,
[0259]
将包含调整信息的行为信息输出给所述校正部,该调整信息是所述状态信息所包含的所述系数的调整信息,
[0260]
输出使用了评价函数的、强化学习中的回报值,该评价函数是所述第1伺服控制信息的函数,
[0261]
根据所述回报值、所述状态信息、所述行为信息来更新价值函数。
[0262]
根据该机器学习方法,可以实现对轴间干扰进行校正的伺服控制部的校正部系数的优化,可以避免伺服控制部中繁杂的调整,并且可以提升伺服控制部的指令随动性。
[0263]
(9)在上述(8)所记载的机器学习方法中,根据更新了的所述价值函数,输出作为优化行为信息的、所述校正部的所述系数的调整信息。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1