一种动态事件驱动的多机器人固定时间饱和控制方法
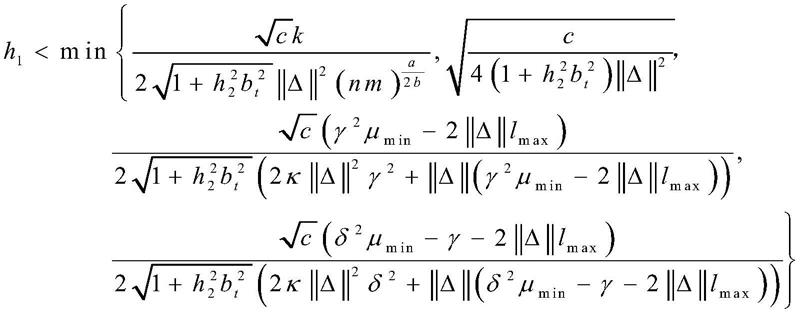
1.本发明属于自动化技术领域,涉及一种动态事件驱动的多机器人固定时间饱和控制方法。
背景技术:
2.多机器人协同控制应用于许多领域,如无人机编队、环境监测、遇险营救等复杂任务。其中:编队任务是多机器人协同控制中最基本任务之一。在传统的多机器人编队控制方法中,固定时间控制方法是一种有效的编队控制方法,该方法能够不依赖于机器人的初始状态而在给定时间范围内,完成多机器人的编队任务。并且,通过使用静态事件驱动机制,节省系统的通信资源。然而,使用静态事件驱动机制的固定时间编队控制方法,在多机器人编队形成后,存在zeno现象。这就意味着,在多机器人系统按照编队方式稳定运行时,静态事件驱动机制失效,多机器人系统仍然需要连续通信维持系统编队队形,因此,通信资源没有得到有效节省。在另一方面,由于机器人的驱动能力有限,控制输入饱和是多机器人系统普遍存在的一种控制约束,如果处理不当会导致系统性能下降甚至失稳。而传统的编队控制方法没有有效的考虑这一点。因此,在这一背景下,本发明弥补了现有技术的不足。
技术实现要素:
3.本发明的目标是针对现有技术的不足,提供一种有效的多机器人编队控制方法,使得多机器人系统在受输入饱和的影响下完成编队任务,同时节省系统通信资源,并且在完成编队任务后,事件驱动机制仍然正常工作。首先为了节省系统通信资源,设计了一种动态事件驱动机制,该机制引入了一个动态变量,由于该变量具有非负性,这在解决zeno行为上发挥重要的作用。接着,将提出的动态事件驱动机制与固定时间控制算法相融合,得到动态事件驱动的固定时间控制方法。最后,引入控制输入饱和,给出动态事件驱动机制的固定时间饱和控制算法。
4.一种动态事件驱动的多机器人固定时间饱和控制方法,该方法具体如下:能独立运行在机器人群体中每个机器人的控制系统中,对于第i个机器人,i=1,2,...,n,n是机器人的数量,该方法的具体步骤如下:
5.第一步:计算多机器人系统的常用参数数据,具体步骤如下:
6.a)建立多机器人系统的邻接矩阵a=[a
ij
];如果第i个机器人能够和第j个机器人通信,则a
ij
>0,否则,a
ij
=0,i=1,2,...,n,j=1,2,...,n;
[0007]
b)建立机器人群体的拉普拉斯矩阵
[0008]
其中:
[0009][0010]
c)设定一个虚拟领导者,即虚拟机器人,具有位置x0(t)和速度v0(t);虚拟领导者
的所有计算在任意一个实体机器人上完成;如果虚拟领导者能够和第i个机器人通信,则a
i0
>0;否则,a
i0
=0,i=1,2,...,n;
[0011]
d)建立矩阵其中:diag{a
10
,...,a
n0
}是对角矩阵;建立矩阵其中:是克罗内克积;i
m
是m
×
m的单位矩阵;m是机器人状态向量的维数;
[0012]
第二步:建立多机器人动力学模型,具体步骤如下:
[0013]
a)第i个机器人的动力学模型表示为:
[0014][0015]
其中:x
i
(t)、v
i
(t)、u
i
(t)和l
i
(x
i
(t),v
i
(t),t)分别表示第i个机器人的位置、速度、控制输入和非线性项;
[0016]
b)虚拟领导者的动力学模型表示为:
[0017][0018]
其中:x0(t)、v0(t)和l0(x0(t),v0(t),t)分别表示虚拟领导者的位置、速度和非线性项;并且公式(2)和(3)中的非线性项满足:
[0019]
||l
i
(x
i
(t),v
i
(t),t)
‑
l0(x0(t),v0(t),t)||≤l1||x
i
(t)
‑
x0(t)||+l2||v
i
(t)
‑
v0(t)||
ꢀꢀꢀ
(4)
[0020]
其中:l1和l2是正常数;
[0021]
第三步:设计动态事件驱动机制;
[0022]
定义第i个机器人的事件触发时刻为inf是取下限;ω
i
(t)是事件驱动的规则;和分别为第i个机器人当前的触发时刻和下一次的触发时刻;动态事件驱动规则为:
[0023][0024]
其中:γ>0;δ>0;h1>0;h2>0;表示机器人i在t时刻的位置状态误差;是机器人i在触发时刻的位置;x
i
(t)是机器人i在t时刻的位置;表示机器人i在t时刻的速度状态误差;是机器人i在触发时刻的速度;v
i
(t)是机器人i在t时刻的速度;表示虚拟领导者在时间t时刻的位置状态误差;是虚拟领导者在触发时刻的位置;x0(t)是虚拟领导者在t时刻的位置;表示虚拟领导者在t时刻的速度状态误差;是虚拟领导者在触发时刻的速度;v0(t)是虚拟领导者在t时刻的速度;多机器人系统的位置状态总误差和速度状态总误差分别为和和和分别为机器人j和机器人i的事件触发时刻,s=1,2,
…
,s为事件触发的序列;是
第j个机器人在事件触发时刻的位置信息;是第j个机器人在事件触发时刻的速度信息;θ
i
(t)是引入的内部动态变量,其定义如下:
[0025][0026]
其中:参数β>0;初始值θ
i
(0)>0;
[0027]
第四步:计算第i个机器人的控制输入;
[0028]
当事件驱动规则ω
i
(t)<0,即时间t满足时,s=1,2,
…
,是初始时刻,第i个机器人的控制输入u
i
(t)将不会更新,从而达到了节省系统通信资源的目的;当事件驱动规则ω
i
(t)≥0时,将当前时刻t标记为事件触发时刻并且将控制输入u
i
(t)中的时刻替换为那么一个新的时间区间将被设定,即控制输入u
i
(t)重新计算;u
i
(t)如(7)式所示;
[0029][0030]
其中:a是正偶数,b是正奇数,且a<b;d
j
是第j个机器人的编队距离向量;d
i
是第i个机器人的编队距离向量;sat(
·
):是一个向量饱和函数;表示一个m维的实数向量集合;让q
z
是向量q的第z个元素,z=1,...,m,sat(q)表示向量q中的每一个元素q
z
满足下式:
[0031][0032]
其中:u
max
>0表示控制输入的最大值;此外,其它参数满足:μ
min
是δ+δ
t
的最小特征值;
[0033][0034]
其中:k>0,b
t
是两个事件触发间隔的最大值;κ和c是两个正常数;l1和l2满足公式(4);σ
min
(δ
t
δ)是矩阵δ
t
δ的最小特征值;多机器人系统能够在时间t内达到一致,t满足
[0035][0036]
其中:λ
max
为矩阵的最大特征值;
[0037]
第五步:如果终止条件满足,则机器人停止运行;如果终止条件没有满足,则返回第三步继续执行。
[0038]
作为优选,所述的终止条件为给定的最大搜索时间已经达到。
[0039]
本发明提出的一种动态事件驱动的多机器人固定时间饱和控制方法,该方法通过动态事件驱动机制与固定时间控制方法相融合,在完成编队任务的同时还能有效节省通信资源,该机制通过引入一个内部动态变量,利用内部动态变量的非负性,来避免多机器人系统形成编队后产生的zeno行为,同时将输入饱和因素考虑在内,令所提出的控制方法更具有通用性。
具体实施方式
[0040]
以多机器人编队为例,设定范围为100m
×
100m,以此范围建立坐标系,可以进一步表示成[
‑
50,50]
×
[
‑
50,50]。采用4个机器人进行编队。对于第i个机器人,i=1,...,n,n=4是机器人的数量,该方法的具体步骤如下:
[0041]
第一步:计算多机器人系统的常用参数数据。初始化机器人的位置信息x1(0)=[
‑
5,
‑
5]
t
,x2(0)=[
‑
15,
‑
10]
t
,x3(0)=[
‑
20,
‑
25]
t
,x4(0)=[
‑
15,
‑
15]
t
,机器人的初始速度设
为0。
[0042]
a)建立多机器人系统的邻接矩阵a=[a
ij
]:
[0043][0044]
b)建立多机器人系统的拉普拉斯矩阵
[0045][0046]
c)定义一个虚拟领导者,初始化位置x0(0)=[
‑
5,
‑
5]
t
,速度为0,并且虚拟领导者仅和第1个机器人通信,即a
10
=0.5,a
j0
=0,j=2,3,4。
[0047]
d)建立矩阵其中:diag{a
10
,...,a
40
}是对角矩阵。建立矩阵其中:是克罗内克积;i2是2
×
2的单位矩阵。
[0048]
第二步:建立多机器人动力学模型,具体步骤如下:
[0049]
a)第i个机器人的动力学模型可以表示为:
[0050][0051]
其中:x
i
(t)、v
i
(t)、u
i
(t)分别表示第i个机器人的位置、速度、控制输入。
[0052]
b)虚拟领导者的动力学模型表示为:
[0053][0054]
其中:x0(t)和v0(t)分别表示虚拟领导者的位置和速度。
[0055]
第三步:设计动态事件驱动机制,具体为:
[0056][0057]
其中:h1=0.02,h2=0.1,β=0.05,γ=10,δ=12.6,θ
i=1,
…
,4
(0)=70;inf是取下限,ω
i
(t)是事件驱动的规则,和分别为第i个机器人当前的触发时刻和下一次的触发时刻;表示机器人i在t时刻的位置状态误差;是机器人i在触发时刻的位置;x
i
(t)是机器人i在t时刻的位置;表示机器人i在t时刻的速度状态误差;是机器人i在触发时刻的速度;v
i
(t)是机器人i在t时刻的速度;
表示虚拟领导者在时间t时刻的位置状态误差;是虚拟领导者在触发时刻的位置;x0(t)是虚拟领导者在t时刻的位置;表示虚拟领导者在t时刻的速度状态误差;是虚拟领导者在触发时刻的速度;v0(t)是虚拟领导者在t时刻的速度;多机器人系统的位置状态总误差和速度状态总误差分别为和和和(s=1,2,
…
,s为事件触发的序列)分别为机器人j和机器人i的事件触发时刻;是第j个机器人在事件触发时刻的位置信息;是第j个机器人在事件触发时刻的速度信息。
[0058]
第四步:计算第i个机器人的控制输入。当事件驱动规则ω
i
(t)<0即时间t满足时,,s=1,2,
…
,是初始时刻。第i个机器人的控制输入u
i
(t)将不会更新,从而达到了节省系统通信资源的目的;当事件驱动规则ω
i
(t)≥0时,将当前时刻t标记为事件触发时刻并且将控制输入u
i
(t)中的时刻替换为那么一个新的时间区间将被设定,即控制输入u
i
(t)重新计算。u
i
(t)如(4)式所示。
[0059][0060]
其中:a=2,b=5;d1=[0,0]
t
,d2=[0.4,0]
t
,d3=[0,0.4]
t
,d4=[0.4,0.4]
t
,d0=[0,0]
t
(t表示转置);sat(
·
):是一个向量饱和函数;表示一个m维的实数向量集合。让q
z
是向量q的第z个元素,z=1,...,m,sat(q)表示向量q中的每一个元素q
z
满足下式:
[0061][0062]
第五步:如果给定终止时间满足,则机器人停止运行;如果终止时间没有满足,则返回第三步继续执行。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1