生产力增强的实时机会发现的制作方法
背景技术:
1、本公开总体上涉及机器学习领域,并且更具体地涉及用于使用历史数据编码的生产过程的生产率增强的实时机会发现。
2、许多生产方法可能是相当复杂的。例如,在油砂生产中,开采的矿石可以经过几个阶段的提取、升级、和精炼。类似的方法可见于食品和炼钢生产过程中。来自上游过程的流出流可以变成进入下游过程的流入流。每个阶段可以涉及多个组件和过程,并且该系统是动态系统。对于油砂工艺,在典型的构型中,当从采矿可获得足够的原料并且所有部件正确地运行时,操作在全能力下进行。升级处理操作可以在没有真空工艺的情况下执行。当来自加工的油砂的沥青的质量较低(例如,具有高浓度的氯化物)时,可以产生低生产模式以避免焦化单元的降解。当原材料流水线正在经历维护时,可以发生部分能力的操作。当来自加工的油砂的沥青的质量较低(例如,具有高浓度的氯化物)时,可以产生低生产模式以避免焦化单元的降解。当原材料流水线正在经历维护时,可以发生部分能力的操作。
3、传统上,在市场上出售给炼油厂之前,大部分生产的沥青被升级成合成原油。然而,一些沥青足够好以直接送到具有加工重/酸原油的能力的高转化精炼厂。直接销售给精炼厂的这种稀释沥青实例包括来自现场设施和其他地方的产物。石油产物可以通过三个基本步骤从油砂生产:i)从油砂提取沥青,其中除去固体和水,ii)将重质沥青升级至较轻的中间原油产物,和iii)将粗油精炼成最终产物,如汽油、润滑剂和稀释剂。所有这些方法涉及物理或化学转化的多个顺序步骤以从一种材料转化为另一种材料。需要工艺的最佳平衡以达到这种生产系统内的多个目标。需要工厂操作员寻求机会来提高生产率,例如,更少的原料、更便宜的添加剂、更高的最终产品。进一步需要集中于具有高商业价值的特定区域以在制造工艺的局部步骤中提供增量值。还有另一种需要是发现成本、原材料、以及节能模型的机会,并且帮助获得增加的额外利润,该额外利润限于整个工厂操作的局部步骤,其中这些机会在制造过程中的相对短的时间窗口内。
技术实现思路
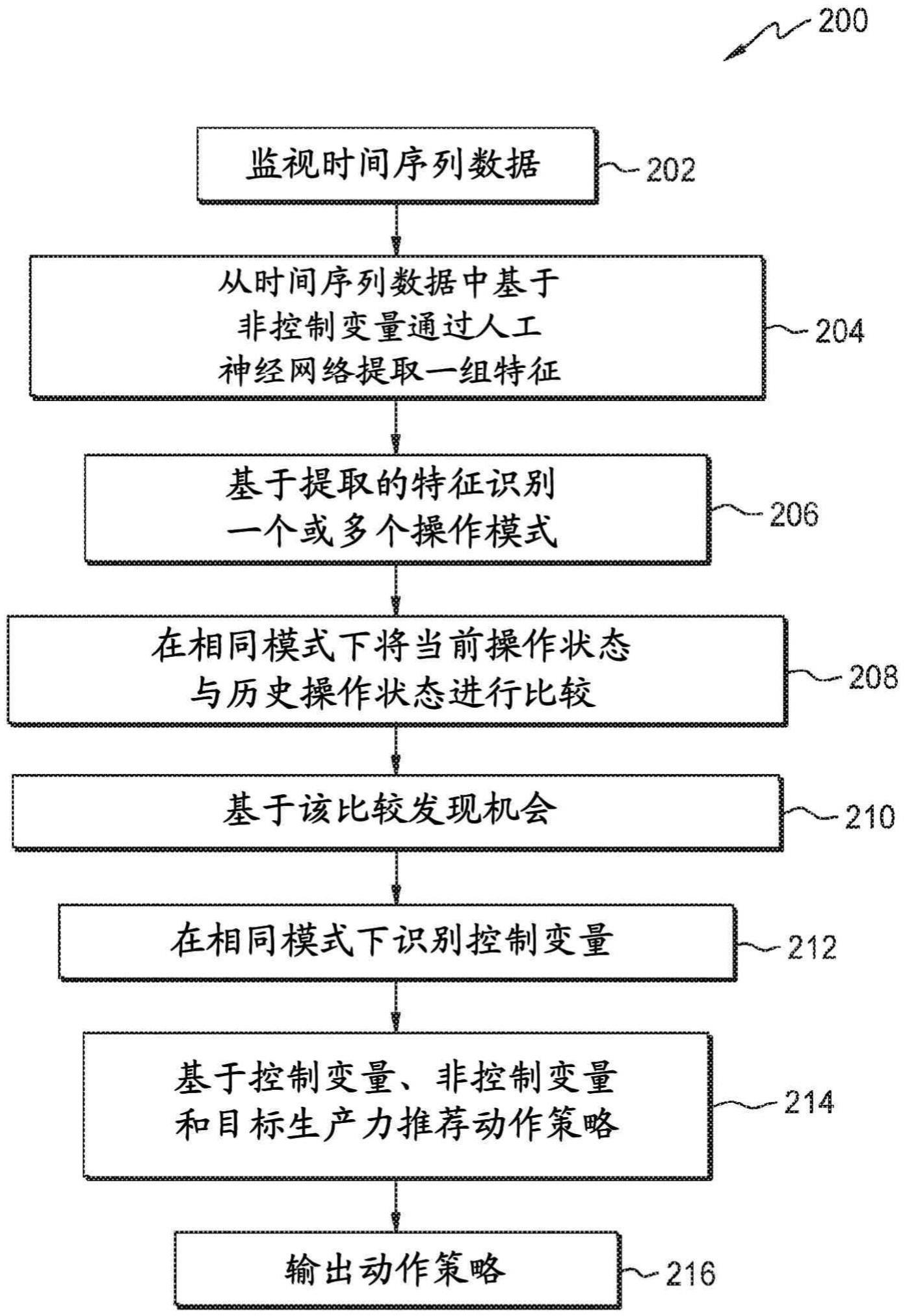
1、现有技术的某些缺点被克服,并且通过提供用于生产工艺的生产率增强的实时机会发现的方法来提供附加的优点。有利地,处理器基于时间序列数据的非控制变量,通过使用神经网络的自动编码,从时间序列数据中提取一组特征。处理器基于所提取的特征(包括尺寸缩小)识别一个或多个操作模式,其中,表示从时间序列数据中学习。处理器基于所提取的特征来识别当前操作状态的邻域。处理器基于同一操作模式下的时间序列数据,将当前操作状态与历史操作状态进行比较。处理器使用邻域基于当前操作状态与历史操作状态的比较来发现操作机会。处理器识别相同模式中的控制变量,这些变量与当前操作状态相关。处理器基于一个或多个控制变量、一个或多个非控制变量和目标生产力推荐动作策略。
2、在一个或多个实施例中,提供了一种计算机实现的方法,用于监测从一个或多个传感器生成的时间序列数据。例如,时间序列数据可以是来自油砂操作和生产过程的数据。石油产物可以通过几个阶段从油砂生产,例如萃取、升级和精炼。有利地,提供了工艺的最佳平衡以达到这种生产系统内的多个目标。
3、在一个或多个实施例中,提供了一种计算机实现的方法,以基于时间序列数据的一个或多个非控制变量,通过使用神经网络(例如,lstm自动编码器)的自动编码,从时间序列数据中提取一组特征。有利地,lstm自动编码器不仅使用该组特征来学习,而且通过lstm自动编码器学习该组特征。特征集是与时间序列数据相关的信息。特征集合可以是从时间序列数据中观察到的现象的个体可测量属性或特性。机会发现模块可以基于定义用户对时间序列数据的控制的缺乏的非控制变量来选择用于创建预测模型的相关特征的子集。有利地,所述机会发现模块可以减少描述所述时间序列数据所需的资源的数量。机会发现模块可通过lstm自动编码器以足够的精度构建描述时间序列数据的非控制变量的组合。有利地,lstm自动编码器可调用基于时间序列数据的自动编码过程以将传感器标签空间的维度减小到有限的嵌入空间。
4、在一个或多个实施例中,提供了一种计算机实现的方法,用于基于所提取的特征来标识一个或多个操作模式,所述特征包括伴随从所述时间序列数据的表示学习的维度缩减。有利地,维数减少是时间序列数据从高维空间到低维空间的变换,使得低维表示保持原始数据的一些有意义的属性,理想地接近固有维数。有利地,可为当前操作状态识别邻域。邻域可以是相同操作模式内的动态模式,并且可以通过历史操作状态和当前操作状态之间的欧几里得距离找到。有利地,提供自动处理,而不是依赖于需要大量现有知识和存储原理的基于规则的模式检测。机会发现模块可通过使用无监督机器学习的分析来实现机会实现。例如,机会发现模块可通过将当前状态与模式或邻域内部的历史类似操作进行比较来标识操作机会。
5、在一个或多个实施例中,提供了一种计算机实现的方法,用于利用机会发现模块在一个或多个操作模式中的相同操作模式下基于时间序列数据来将当前操作状态与历史操作状态进行比较。有利地,机会发现模块可标识当前操作状态所处的特定模式。机会发现模块可以使用t分布式随机邻居嵌入(t-sne)压缩来投影集群以生成图。机会发现模块可以用遵守具有t-sne压缩的点之间的相似性的方式将高维点嵌入在低维中。在实例中,机会发现模块可以通过将当前操作状态与位于相同模式下的其他操作进行比较来实现高沥青提取。机会发现模块可分析性能差的事件并可发现操作性机会来改进。
6、在一个或多个实施例中,提供了一种计算机实现的方法,用于基于当前操作状态与历史操作状态的比较来发现操作机会。有利地,可以通过当前状态与模式或邻域内的历史类似操作的比较来识别操作机会。在示例中,操作机会可以是从历史操作状态推导出的一组操作改变,以将当前操作状态增加到所定义的短期未来时段(例如,两小时窗口)中的较高产量。在另一实例中,操作机会可以是从历史操作状态推断的一组操作变化,以将当前操作状态减少至所定义的短期未来时期的添加剂或原材料的低使用率。可以找到其他合适的机会。
7、在一个或多个实施例中,提供了一种计算机实现的方法,以识别处于同一模式中的控制变量,这些变量与当前操作状态相关。有利地,控制变量可用于从时间序列数据的情节计算奖励(或机会)。例如,控制变量可以是生产速率和原材料变量,用户可以基于所发现的最佳相邻事件来优化所述生产速率和原材料变量。可以从相似的历史非控制变量的已建立的邻域中识别控制变量,以基于时间序列数据创建与当前状态相关的可能的动作策略。
8、在一个或多个实施例中,提供了一种计算机实现的方法,以基于控制变量、非控制变量和目标生产力来推荐动作策略。有利地,基于当前状态与历史操作状态的比较,相似性测量可被定义以从时间序列数据中识别具有类似操作状态的历史情节。情节可从展示较高生产率或吞吐量的历史情节创建。得分可以基于替代动作策略生成并且可以用于基于针对每个替代动作策略的得分推荐动作策略。
9、在一个或多个实施例中,提供了一种计算机实现的方法以输出用于用户的动作策略。有利地,使用加时间戳图表的邻域情节可以呈现在用户界面中。可以呈现动作策略的估计增益。
10、在另一方面中,提供一种计算机程序产品,其包括一个或一个以上计算机可读存储媒体,以及共同存储在所述一个或一个以上计算机可读存储媒体上的程序指令。有利地,程序指令基于时间序列数据的非控制变量,通过使用神经网络的自动编码,从时间序列数据中提取一组特征。程序指令基于所提取的特征来识别一个或多个操作模式,所述特征包括使用从所述时间序列数据中学习的表示的维度减小。程序指令基于所提取的特征来识别当前操作状态的邻域。程序指令基于同一操作模式下的时间序列数据,将当前操作状态与历史操作状态进行比较。程序指令基于所述当前操作状态与使用所述邻域的所述历史操作状态的比较来发现操作机会。程序指令识别相同模式中的控制变量,这些变量与当前操作状态相关。程序指令基于所述一个或多个控制变量、所述一个或多个非控制变量和目标生产力推荐动作策略。
11、在进一步方面,提供了一种计算机系统,该计算机系统包括一个或多个计算机处理器、一个或多个计算机可读存储介质、以及存储在该一个或多个计算机可读存储介质上用于由该一个或多个计算机处理器中的至少一个执行的程序指令。有利地,程序指令基于时间序列数据的非控制变量,通过使用神经网络的自动编码,从时间序列数据中提取一组特征。程序指令基于所提取的特征来识别一个或多个操作模式,所述特征包括使用从所述时间序列数据中学习的表示的维度减小。程序指令基于所提取的特征来识别当前操作状态的邻域。程序指令基于同一操作模式下的时间序列数据,将当前操作状态与历史操作状态进行比较。程序指令基于所述当前操作状态与使用所述邻域的所述历史操作状态的比较来发现操作机会。程序指令识别相同模式中的控制变量,这些变量与当前操作状态相关。程序指令基于所述一个或多个控制变量、所述一个或多个非控制变量和目标生产力推荐动作策略。
12、通过本发明的技术实现了附加特征和优点。本发明的其他实施例和方面在本文中详细描述,并且被认为是要求保护的发明的一部分。
- 还没有人留言评论。精彩留言会获得点赞!