一种基于双聚类自适应模糊神经网络的重量控制方法
1.本发明属于称重仓重量控制领域,具体的说是一种基于双聚类自适应模糊神经网络的重量控制方法。
背景技术:
2.近年来,模糊控制与工业过程相结合的智能控制方案得到更多应用,然而模糊控制过程中的模糊化以及模糊规则依赖于专家经验,这也使得模糊控制的应用存在局限性。人工神经网络可以模拟人脑功能,通过大量数据拟合出类似专家经验的模糊规则,人工神经网络与模糊控制的结合,诞生了模糊神经网络,模糊神经网络可以作为控制器应用到称重仓重量控制中,然而,模糊神经网络隐含层节点的确定仍然依赖于专家经验,同时对于过多的隐含层节点,会导致网络学习时间过长、过少的隐含层节点又无法正确充分反映操作员经验;同时目前多数水泥厂称重仓重量控制仍采用人工经验控制,不同操作员对于称重仓重量期望目标值不同,且无实时称重仓重量目标值记录。
技术实现要素:
3.本发明是为了解决上述现有技术存在的不足之处,提出一种基于双聚类自适应模糊神经网络的重量控制方法,以期能自适应获取称重仓重量目标值,并学习操作人员经验以获得双聚类自适应模糊神经网络控制器,从而能实现对称重仓重量的实时控制。
4.本发明为达到上述发明目的,采用如下技术方案:
5.本发明一种基于双聚类自适应模糊神经网络的重量控制方法的特点是应用于由称重仓、称重传感器、皮带秤和控制器所构成的装置中,并按如下步骤进行:
6.步骤1、利用所述称重传感器实时采集所述称重仓中均匀混合物料的重量数据,从而得到时间段t1~td的重量数据{y1,
…
,yi,
…
,yd};其中,yi为ti时刻的物料重量,i=1,
…
,d;
7.利用所述皮带秤实时采集称重仓的进料量,从而得到时间段t1~td的进料量信息{u1,
…
,ui,
…
,ud},其中,ui为ti时刻称重仓的进料量;
8.步骤2、给定聚类数k的取值范围为{k1,
…
,kv…
,kn},其中,kv表示第v个取值;
9.基于聚类数k的取值范围{k1,
…
,kv…
,kn},利用k-means聚类对时间段t1~td的重量数据{y1,
…
,yi,
…
,yd}分别进行聚类,得到不同取值所对应的簇,其中,令第v个取值kv所对应的簇记为其对应的聚类中心为c
vj
表示第v个取值kv对应的第j个簇,c
vj
表示第v个取值kv对应第j个簇的聚类中心,hv表示第v个取值kv所对应的簇的数量;
10.步骤3、在聚类数k取值为kv时,计算ti时刻的物料重量yi与所属的第j个簇c
vj
中其他物料重量的平均值并计算ti时刻的物料重量yi与其他一个簇中所有物料重量的平均值,从而得到ti时刻的物料重量yi到所有簇物料重量的平均值,并选取最小平均值记为
从而利用式(1)得到ti时刻的物料重量yi的轮廓值s
vi
,进而得到时间段t1~td的重量数据的轮廓值{s
v1
,
…
,s
vi
,
…
,s
vd
},并求取第v个取值kv对应的平均轮廓值sv;
[0011][0012]
步骤4、按照步骤3的过程得到聚类数k在不同取值下所对应的平均轮廓值{s1,
…
,sv,
…
,sn};
[0013]
步骤5、在聚类数k取值为kv时,利用式(2)得到簇内误差平方和ssev:
[0014][0015]
步骤6、按照步骤5的过程得到聚类数k在不同取值下所对应的簇内误差平方和{sse1,
…
,ssev,
…
,ssen};
[0016]
步骤7、利用双评价标准取得最佳聚类数;
[0017]
步骤7.1、对平均轮廓值{s1,
…
,sv,
…
,sn}进行降序排序,得到排序后的平均轮廓值{s
′1,
…
,s
′v,
…
,s
′n};
[0018]
步骤7.2、对簇内误差平方和{sse1,
…
,ssev,
…
,ssen}进行曲线拟合,并将下降幅度变缓时出现的拐点定义为聚类数k
max_sse
;
[0019]
步骤7.3、初始化v=1;
[0020]
步骤7.4、将s
′v所对应的聚类数记为k
max_s
;
[0021]
步骤7.5、判断k
max_s
=k
max_sse
是否成立,若成立,则将k
max_sse
即为最佳聚类数目k
best
,并执行步骤8;否则,将v+1赋值给v后,判断v>n是否成立,若成立,则执行步骤7.6;否则,返回步骤7.4顺序执行;
[0022]
步骤7.6、改变拐点k
max_sse
后返回步骤7.3顺序执行,直至求出时间段t1~td的重量数据{y1,
…
,yi,
…
,yd}在给定聚类数范围{k1,
…
,kv…
,kn}内的最佳聚类数目k
best
;
[0023]
步骤8、根据最佳聚类数k
best
求出所对应各个簇的聚类中心c
best
,对聚类中心c
best
进行筛选处理,得到筛选后的k
′
best
个聚类中心并作为各个簇的目标重量值;
[0024]
步骤9、计算各个簇的目标重量值与各自簇内的物料重量的重量偏差、偏差变化率并分别进行归一化处理,得到归一化后的重量偏差{e1,
…
,ei,
…
,ed}、归一化后的偏差变化率{ec1,
…
,eci,
…
,ecd};其中,ei表示归一化后ti时刻的重量偏差,eci表示归一化后的ti时刻的重量偏差变化率;
[0025]
计算进料偏差并进行数据归一化处理,得到归一化后的进料偏差{eu1,
…
,eui,
…
,eud},其中,eui表示归一化后的ti时刻的进料量偏差;
[0026]
步骤10、利用减法聚类求出重量偏差的聚类中心{c
e1
,
…
,c
ea
,
…
,c
ef
}、偏差变化率的聚类中心{c
ec1
,
…
,c
eca
,
…
,c
ecf
}以及进料偏差的聚类中心{c
eu1
,
…
,c
eua
,
…
,c
euf
},重量偏差的密度半径{σ
e1
,
…
,σ
ea
,
…
,σ
ef
}、偏差变化率的密度半径{σ
ec1
,
…
,σ
eca
,
…
,cσ
ecf
}、进料偏差的密度半径{σ
eu1
,
…
,σ
eua
,
…
,σ
euf
},其中,c
ea
表示重量偏差的第a个聚类中心,σ
ea
表示重量偏差的第a个密度半径,c
eca
表示重量偏差变化率的第a个聚类中心,σ
eca
表示重量偏差变化率的第a个密度半径,c
eua
表示进料量偏差的第a个聚类中心,σ
eua
表示进料量偏差的第a个密度半径;
[0027]
利用式(3)-式(5)得到与模糊语言对应的隶属度:
[0028][0029][0030][0031]
式(3)-式(5)中,μ
ea
表示重量偏差的第a个聚类中心对应的隶属度,μ
eca
表示重量偏差变化率的第a个聚类中心对应的隶属度,μ
eua
表示进料量偏差的第a个聚类中心对应的隶属度;
[0032]
建立模糊规则:如果ei的隶属度为μ
ea
且eci的隶属度为μ
eca
,则eui的隶属度为μ
eua
;
[0033]
步骤11、利用模糊神经网络在模糊规则上对归一化后的重量偏差{e1,
…
,ei,
…
,ed}、归一化后的偏差变化率{ec1,
…
,eci,
…
,ecd}和归一化后的进料偏差{eu1,
…
,eui,
…
,eud}进行学习,得到双聚类自适应模糊神经网络控制器;
[0034]
步骤12、设定称重仓的目标值y
goal
;
[0035]
步骤13、利用称重传感器采集t时刻所述称重仓的重量y
t
,并与设定的目标值y
goal
比较后得到实时偏差e
t
以及偏差变化率ec
t
,并经过双聚类自适应模糊神经网络控制器的处理后得到进料量偏差eu
t
;
[0036]
步骤14、对进料量偏差eu
t
进行反归一化,再与t-1时刻的进料量u
t-1
相加后得到t时刻的进料量u
t
并传输给皮带秤,返回步骤13。
[0037]
与现有技术相比,本发明的有益效果在于:
[0038]
1、本发明可以在没有具体目标值的情况下,通过现有称重仓重量数据,自主寻找到最佳的目标值,利用k-means聚类,通过双评价方式,求出其最佳聚类中心,同时,基于现场实际,通过数据处理,将最佳聚类中心转换成所用数据对应的称重仓重量目标值,解决了无实时称重仓重量目标值记录的问题;
[0039]
2、本发明可以在没有具体专家经验的情况下,利用减法聚类获取模糊神经网络的先验规则,之后模糊神经网络在先验规则的基础上继续学习,得到双聚类自适应模糊神经网络控制器。通过上述过程,无需专家经验,即可得到合适的模糊神经网络节点数,同时也加快了模糊神经网络的学习速度,此外得到的控制器对于称重仓重量控制具有很好的效果。
附图说明
[0040]
图1为本发明不同聚类数对应的平均轮廓值图;
[0041]
图2为本发明不同聚类数对应的簇内误差平方和图;
[0042]
图3为本发明称重仓重量目标值与实际值图;
[0043]
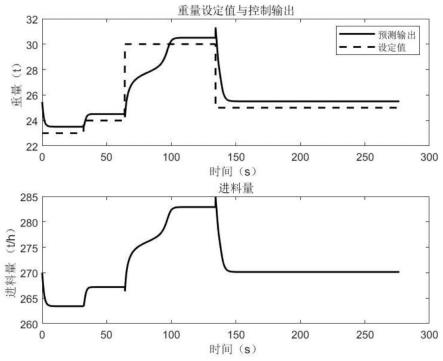
图4为本发明双聚类自适应模糊神经网络控制器的控制效果图;
[0044]
图5为普通模糊神经网络控制器的控制效果图。
具体实施方式
[0045]
本实施例中,一种基于双聚类自适应模糊神经网络的重量控制方法,是应用于由
称重仓(水泥稳流仓)、称重传感器、皮带秤和控制器所构成的装置中,并按如下步骤进行:
[0046]
步骤1、利用称重传感器实时采集称重仓中均匀混合物料的重量数据,从而得到时间段t1~td的重量数据{y1,
…
,yi,
…
,yd};其中,yi为ti时刻的物料重量,i=1,
…
,d;
[0047]
利用皮带秤实时采集称重仓的进料量,从而得到时间段t1~td的进料量信息{u1,
…
,ui,
…
,ud},其中,ui为ti时刻称重仓的进料量;
[0048]
本实施例中,取得水泥厂26多个小时称重仓重量、进料量数据,间隔2s取值,共有数据46700条数据。
[0049]
步骤2、给定聚类数k的取值范围为{k1,
…
,kv…
,kn},其中,kv表示第v个取值;
[0050]
基于聚类数k的取值范围{k1,
…
,kv…
,kn},利用k-means聚类对时间段t1~td的重量数据{y1,
…
,yi,
…
,yd}分别进行聚类,得到不同取值所对应的簇,其中,令第v个取值kv所对应的簇记为其对应的聚类中心为c
vj
表示第v个取值kv对应的第j个簇,c
vj
表示第v个取值kv对应第j个簇的聚类中心,hv表示第v个取值kv所对应的簇的数量;
[0051]
步骤3、在聚类数k取值为kv时,计算ti时刻的物料重量yi与所属的第j个簇c
vj
中其他物料重量的平均值并计算ti时刻的物料重量yi与其他一个簇中所有物料重量的平均值,从而得到ti时刻的物料重量yi到所有簇物料重量的平均值,并选取最小平均值记为从而利用式(1)得到ti时刻的物料重量yi的轮廓值s
vi
,进而得到时间段t1~td的重量数据的轮廓值{s
v1
,
…
,s
vi
,
…
,s
vd
},并求取第v个取值kv对应的平均轮廓值sv;
[0052][0053]
步骤4、按照步骤3的过程得到聚类数k在不同取值下所对应的平均轮廓值{s1,
…
,sv,
…
,sn};
[0054]
步骤5、在聚类数k取值为kv时,利用式(2)得到簇内误差平方和ssev:
[0055][0056]
步骤6、按照步骤5的过程得到聚类数k在不同取值下所对应的簇内误差平方和{sse1,
…
,ssev,
…
,ssen};
[0057]
步骤7、利用双评价标准取得最佳聚类数;
[0058]
步骤7.1、对平均轮廓值{s1,
…
,sv,
…
,sn}进行降序排序,得到排序后的平均轮廓值{s
′1,
…
,s
′v,
…
,s
′n};
[0059]
步骤7.2、对簇内误差平方和{sse1,
…
,ssev,
…
,ssen}进行曲线拟合,并将下降幅度变缓时出现的拐点定义为聚类数k
max_sse
;
[0060]
步骤7.3、初始化v=1;
[0061]
步骤7.4、将s
′v所对应的聚类数定义为聚类数k
max_s
;
[0062]
步骤7.5、判断k
max_s
=k
max_sse
是否成立,若成立,则将k
max_sse
即为最佳聚类数目k
best
,并执行步骤8;否则,将v+1赋值给v后,判断v>n是否成立,若成立,则执行步骤7.6;否则,返回步骤7.4顺序执行;
[0063]
步骤7.6、改变拐点k
max_sse
后返回步骤7.3顺序执行,直至求出时间段t1~td的重量
数据{y1,
…
,yi,
…
,yd}在给定聚类数范围{k1,
…
,kv…
,kn}内的最佳聚类数目k
best
;
[0064]
步骤8、根据最佳聚类数k
best
求出所对应各个簇的聚类中心c
best
,对聚类中心c
best
进行筛选处理,得到筛选后的k
′
best
个聚类中心并作为各个簇的目标重量值;
[0065]
本实施例中,给定聚类数k范围(1,10),进行k-means聚类,得到不同聚类数对应的平均轮廓值图,如图1所示,不同聚类数对应的簇内误差平方和图,如图2所示。通过图1可以选出聚类数k
max_s
=2,通过图2可选出k
max_sse
=2,此时k
max_s
=k
max_sse
,因此可以求出最佳聚类数k
best
=2。基于最佳聚类数利用k-means聚类算法求出的最佳聚类中心并不能作为最后的称重仓重量目标值,按照现场实际情况,通过数据处理,按范围将在短时间内多次改变的聚类中心值改为占比最大的值,经过上述数据处理,得到最后的称重仓重量的目标值,如图3所示,称重仓重量目标值为26.2384t、31.2382t
[0066]
步骤9、计算各个簇的目标重量值与各自簇内的物料重量的重量偏差、偏差变化率并分别进行归一化处理,得到归一化后的重量偏差{e1,
…
,ei,
…
,ed}、归一化后的偏差变化率{ec1,
…
,eci,
…
,ecd};其中,ei表示归一化后ti时刻的重量偏差,eci表示归一化后的ti时刻的重量偏差变化率;
[0067]
计算进料偏差并进行数据归一化处理,得到归一化后的进料偏差{eu1,
…
,eui,
…
,eud},其中,eui表示归一化后的ti时刻的进料量偏差;
[0068]
步骤10、利用减法聚类求出重量偏差、偏差变化率以及进料偏差的聚类中心{c
e1
,
…
,c
ea
,
…
,c
ef
}、{c
ec1
,
…
,c
eca
,
…
,c
ecf
}、{c
eu1
,
…
,c
eua
,
…
,c
euf
},密度半径{σ
e1
,
…
,σ
ea
,
…
,σ
ef
}、{σ
ec1
,
…
,σ
eca
,
…
,cσ
ecf
}、{σ
eu1
,
…
,σ
eua
,
…
,σ
euf
},其中,c
ea
表示重量偏差的第a个聚类中心,σ
ea
表示重量偏差的第a个密度半径,c
eca
表示重量偏差变化率的第a个聚类中心,σ
eca
表示重量偏差变化率的第a个密度半径,c
eua
表示进料量偏差的第a个聚类中心,σ
eua
表示进料量偏差的第a个密度半径;
[0069]
利用式(3)~式(5)得到跟模糊语言对应的隶属度:
[0070][0071][0072][0073]
式(3)~式(5)中,μ
ea
表示重量偏差的第a个聚类中心对应的隶属度,μ
eca
表示重量偏差变化率的第a个聚类中心对应的隶属度,μ
eua
表示进料量偏差的第a个聚类中心对应的隶属度;
[0074]
建立模糊规则:如果ei的隶属度为μ
ea
且eci的隶属度为μ
eca
,则eui的隶属度为μ
eua
;
[0075]
经过减法聚类求得重量偏差、偏差变化率以及进料偏差各有3个聚类中心,共3个对应关系,因此初始模糊规则中,各有3个模糊语言,共3条规则。
[0076]
步骤11、利用模糊神经网络在模糊规则上对归一化后的重量偏差{e1,
…
,ei,
…
,ed}、归一化后的偏差变化率{ec1,
…
,eci,
…
,ecd}和归一化后的进料偏差{eu1,
…
,eui,
…
,eud}进行学习,得到双聚类自适应模糊神经网络控制器;
[0077]
步骤12、设定称重仓的目标值y
goal
;
[0078]
步骤13、利用称重传感器采集t时刻称重仓的重量y
t
,并与设定的目标值y
goal
比较后得到实时偏差e
t
以及偏差变化率ec
t
,并经过双聚类自适应模糊神经网络控制器的处理后得到进料量偏差eu
t
;
[0079]
步骤14、对进料量偏差eu
t
进行反归一化后,与t-1时刻的进料量u
t-1
相加后得到t时刻的进料量u
t
并传输给皮带秤后,返回步骤13。
[0080]
为验证基于双聚类自适应模糊神经网络的重量控制方法的有效性及优越性,采用matlab仿真进行实验。由于需要得到控制量即进料量,而所用双聚类自适应模糊神经网络控制器输出为进料量增量,因此设定了进料量稳定值为270t/h。为模拟工程现场,在运行程序进行仿真的过程中,分别在运行10000步、20000步、30000步时改变称重仓重量设定值,分别设定为23、24、30、25,利用双聚类自适应模糊神经网络控制器以及普通模糊神经网络控制器分别进行控制,得到的曲线图如图4以及图5所示:
[0081]
通过图5可以看到,在控制过程中,当设定值在23、24时,普通模糊神经网络控制器可以很好控制进料量,使模型输出跟随设定值;当设定值改变为30时,控制器无法继续控制进料量,当设定值增加到30t,进料量反而减少,说明普通模糊神经网络学习得到的控制器规则部分有误,导致预测输出与设定值相差过大;控制器并不能很好的适应设定值的改变。
[0082]
双聚类自适应模糊神经网络控制器相较于普通的模糊神经网络控制器,它在控制过程中没有过大的跳变,不会对实际工程现场造成危害,同时当设定值改变时,双聚类自适应模糊神经网络控制器能迅速做出反应,调节进料量,使得实际仓重值跟随设定值,其次,经过双聚类自适应模糊神经网络控制器控制后,仓重设定值与实际值误差只有0.5059,误差远远低于普通的模糊神经网络控制器,总体来说,双聚类自适应模糊神经网络控制器的控制效果好于普通的模糊神经网络控制器。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1