基于模型预测控制引导的强化学习自动驾驶车队控制方法
本发明涉及智能交通,特别涉及基于模型预测控制引导的强化学习自动驾驶车队控制方法。
背景技术:
1、随着智能交通系统的诞生和发展,智能网联车辆的自动驾驶技术将成为解决交通拥堵、交通安全、交通污染等问题的新契机,智能网联的优势在于可以形成自动驾驶车辆队列行驶,使自动驾驶车辆间保持较小的间距,对降低燃油消耗、减少尾气排放、提高道路安全水平等方面有积极意义。
2、近年来对自动驾驶车辆队列控制的研究大多采用如模型预测控制等最优控制理论,并通过一些启发式算法求解,但较大的队列规模会导致求解空间维数过高,对算力需求较高,降低了实际应用的可行性。一些单智能体强化学习方法也被应用到了车辆队列控制问题,但动作和状态的数量会随着队列规模增加呈指数增长,会导致在训练过程中发生灾难性故障。另外,现有自动驾驶车队控制方案缺少对混合流中随机性的建模,导致生成的控制策略无法在复杂车流环境中有效应用。
技术实现思路
1、发明目的:针对以上问题,本发明目的是提供一种基于模型预测控制引导的强化学习自动驾驶车队控制方法。
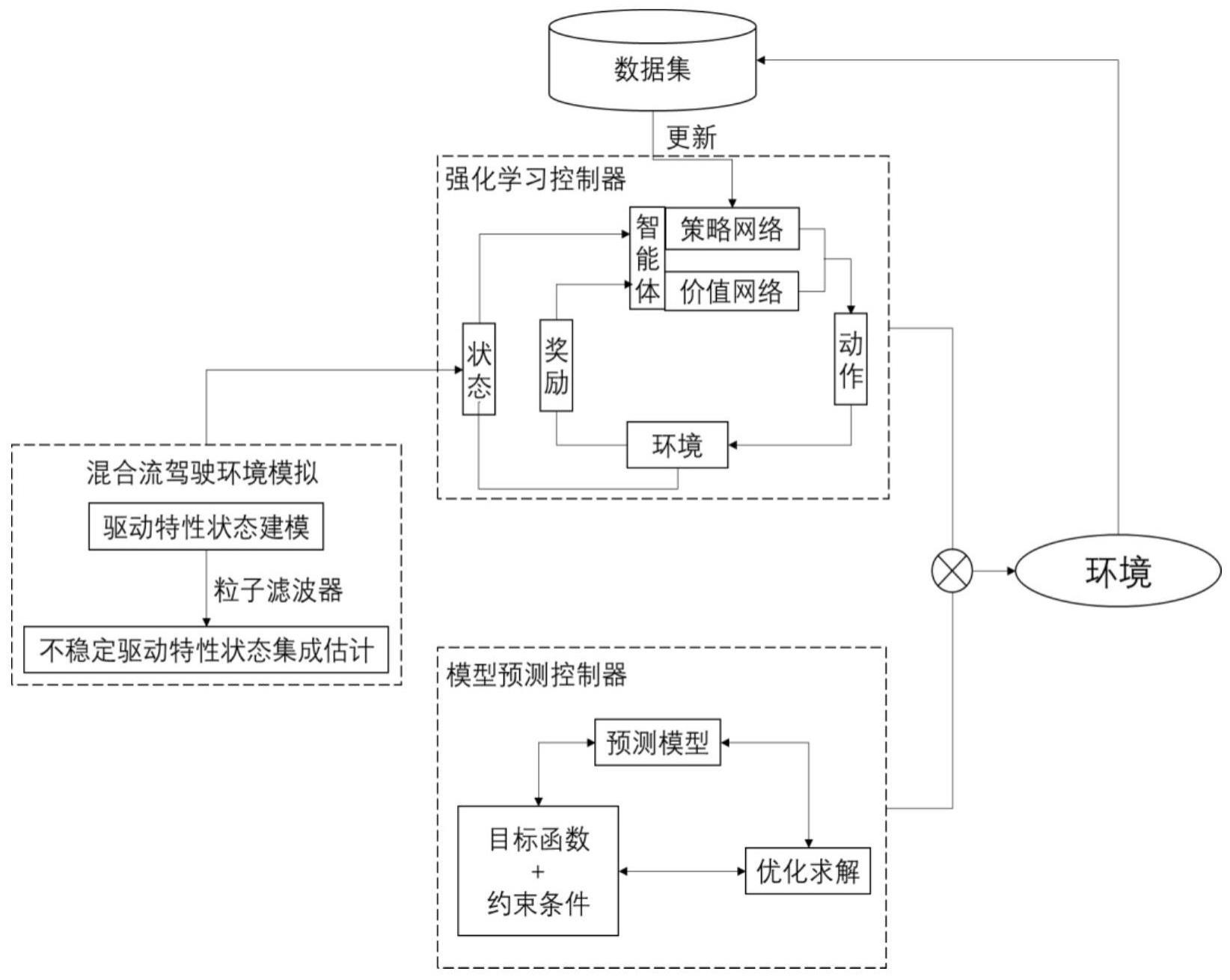
2、技术方案:本发明的一种基于模型预测控制引导的强化学习自动驾驶车队控制方法,包括:
3、针对智能网联环境下非线性混合流的自动驾驶车队构建预测控制模型,根据预测控制模型得到第一加速度;
4、针对自动驾驶车队周围的非自动驾驶车辆构建状态过渡模型,基于状态过渡模型构建非自动驾驶车辆的状态集成参数ψ,采用粒子滤波算法对状态集成参数ψ进行优化得到状态估计ψ′;
5、基于多智能体通信拓扑结构及状态估计ψ′,对自动驾驶车队构建基于深度确定性策略梯度的强化学习控制模型,根据强化学习控制模型输出第二加速度;
6、将第一加速度和第二加速度结合为融合控制律,根据融合控制律对强化学习控制模型进行训练,将训练后的强化学习控制模型作为自动驾驶车辆的控制策略,通过训练后强化学习控制模型输出的动作对自动驾驶车队进行控制。
7、进一步,针对智能网联环境下非线性混合流的自动驾驶车队构建预测控制模型,根据预测控制模型得到第一加速度包括:
8、将自动驾驶车队中第i个自动驾驶车辆cav i在t时刻的状态定义为xi(t)=[δvi,hdv(t),δdi(t),δvi(t),ai(t)]t,自动驾驶车队在t时刻的状态定义为s=[x0(t),x1(t)…xn(t)]t,其中n表示自动驾驶车辆的队列长度,δvi,hdv(t)表示t时刻自动驾驶车辆cav i和队列前非自动驾驶车辆hdv的速度差值,δdi(t)表示t时刻相邻自动驾驶车辆的实际间距和期望间距的差值,δvi(t)表示t时刻自动驾驶车辆cav i和cav i-1的速度差值,ai(t)表示t时刻自动驾驶车辆cav i的加速度;
9、根据状态定义构建自动驾驶车辆cav i的状态转移方程,表示为:
10、
11、上式中,u(t)表示t时刻的自动驾驶车辆cav i的动作,即ai(t);δt表示相邻时间间隔;
12、基于控制效率、驾驶舒适性及燃油消耗效率,建立目标成本函数g,表达式为:
13、
14、上式中,qi表示正定对角系数矩阵,ri表示驾驶舒适性及油耗系数,ui(t)表示t时刻自动驾驶车辆cav i的动作,h表示优化滚动开始时间,m表示优化滚动时间步数;
15、基于自动驾驶车辆的速度、加速度极限以及安全因素,建立约束条件,表达式为:
16、0<vi(t)<vmax
17、amin<a<amax
18、si(t)-si-1(t)>li+lmin
19、上式中,vmax表示车辆最大速度,amin和amax分别表示车辆最小加速度及最大加速度,li表示自动驾驶车辆cav i车辆长度,lmin表示车辆间的最小间距,si(t)表示车辆i在t时刻的位置;
20、基于状态转移方程和约束条件,最小化目标成本函数g,将最小化后的目标成本函数作为预测控制模型,通过最小化目标成本函数得到第一加速度a1。
21、进一步,针对自动驾驶车队周围的非自动驾驶车辆构建状态过渡模型,基于状态过渡模型构建非自动驾驶车辆的状态集成参数ψ包括:
22、基于非自动驾驶车辆不稳定驱动特性,状态过渡模型包括跟驰模型和换道模型,跟驰模型的表达式为:
23、
24、上式中,aj(t)表示t时刻非自动驾驶车辆j的加速度,vflow表示自由流速度,vj(t)表示t时刻非自动驾驶车辆j的速度,dj(t)表示t时刻非自动驾驶车辆j和前车的间距,δvj(t)表示t时刻非自动驾驶车辆j和前车的速度差,a0表示非自动驾驶车辆j的最大加速度,δ表示加速度指数,g0表示最小车头间距,t表示安全车头时距,b表示非自动驾驶车辆j的舒适减速度;
25、换道模型表达式为:
26、
27、若换道效益δa大于换道效益阈值δath,则非自动驾驶车辆换道成功,否则继续在原车道进行跟驰动作;上式中,表示非自动驾驶车辆j换道成功后的加速度,aj表示非自动驾驶车辆j当前的加速度;表示非自动驾驶车辆j换道后在新车道上后车的加速度,atf表示该后车当前加速度;是非自动驾驶车辆j在换道后在原车道上后车的加速度,af表示该后车当前加速度;p是车辆礼让系数;
28、根据跟驰模型和换道模型定义非自动驾驶车辆的状态集成参数ψ,表示成ψ={a0,δ,g0,t,b,p}。
29、进一步,对自动驾驶车队构建基于深度确定性策略梯度的强化学习控制模型之前包括:
30、根据自动驾驶车辆队列周围的非自动驾驶车辆不稳定驱动特性,将自动驾驶车辆cav i在t时刻的状态定义为xi(t),奖励函数定义为ri(t),动作定义为ui(t),状态定义表达式为:
31、xi(t)={slocal,sglobal,ψ‘}
32、上式中,slocal表示每个智能体i从队列中前车cav i-1接收的局部状态信息,sglobal表示每个智能体i从队列头车车cav 1接收的全局状态信息,表达式分别为:
33、slocal={δdi(t),δvi(t),i}
34、sglobal={δvi,hdv(t),ai(t)}
35、其中,
36、δdi(t)=si(t)-si-1(t)-di(t)*
37、δvi(t)=vi-1(t)-vi(t)
38、δvi,hdv(t)=vhdv(t)-vi(t)
39、
40、其中,δdi(t)表示t时刻自动驾驶车辆cav i和cav i-1实际间距和目标控制间距的差值,si(t)表示t时刻cav i的位置,di(t)*表示t时刻cav i的目标控制间距,δvi(t)表示t时刻cav i和cav i-1的速度差,vi(t)表示t时刻cav i的车辆速度,δvi,hdv(t)表示t时刻cav车队前hdv车的速度和cav i的速度差,vhdv(t)表示t时刻cav车队前hdv车的速度,表示期望时距,是超参数,li表示t时刻cav i的车辆长度;
41、奖励函数ri(t)表达式为:
42、ri(t)=ri(t)+ri+1(t)·γ+ri+2(t)·γ2+…+rn(t)·γn-i
43、上式中,γ表示奖励传播的折扣系数;ri(t)表示根据当前t时刻加速度状态计算出来的智能体i的奖励值,表达式为:
44、
45、上式中,ηpenality表示当cav i与前车的距离δs超过距离阈值lthreshold或者加速度ai(t)超过安全加速度asaf时,增加的一个惩罚系数;
46、动作定义ui(t)表达式为:ui(t)=ai(t)。
47、进一步,对自动驾驶车队构建基于深度确定性策略梯度的强化学习控制模型,根据强化学习控制模型输出第二加速度包括:对自动驾驶车队中的每个智能体构建策略网络πθ(s,a)和价值网络q(s,a|θq),将状态转移轨迹输入至策略网络πθ(s,a)和价值网络q(s,a|θq)中,使用策略网络输出的动作作为第二加速度控制自动驾驶车辆运动。
48、进一步,将第一加速度和第二加速度结合为融合控制律,根据融合控制律对强化学习控制模型进行训练包括:
49、将预测控制模型输出的第一加速度和策略网络输出的第二加速度相结合,得到融合控制律,表达式为:
50、u(t)=g(t)*a1(t)+(1-g(t))*a2(t)
51、上式中,a1(t)表示第一加速度,a2(t)表示第二加速度;g(t)是t时刻的动作权重函数,计算表达式为:
52、
53、根据融合控制律u(t)对强化学习控制模型进行交互和更新,在交互过程中,预测控制模型和强化学习模型的策略网络将根据融合控制律进行控制,得到状态转移轨迹<st,at,rt,st+1>,st表示t时刻的状态,at表示t时刻的动作,rt表示t时刻的奖励值,st+1表示t+1时刻的状态,将状态转移轨迹组成数据元组储存在回放缓冲区;在更新过程中,对回放缓冲区中的样本进行采样,用来更新价值网络和策略网络。
54、进一步,在更新过程中,使价值网络的期望回报最大化,以求解当前策略网络中的最优参数θπ,表示为:
55、
56、使损失函数l最小化,以求解当前价值网络的最优参数θq,表示为:
57、
58、利用最优参数θπ和θq对价值网络和策略网络进行更新,表示为:
59、θq′←τθq+(1-τ)θq′
60、θπ′←τθπ+(1-τ)θπ′
61、将更新后的θq′输入至策略网络中,输出的加速度作为自动驾驶车辆的控制策略,对自动驾驶车队进行控制。
62、有益效果:本发明与现有技术相比,其显著优点是:
63、1、本发明将模型预测控制用于强化学习训练,针对智能网联混合流自动驾驶车队队列控制,降低模型预测控制中的在线控制算力需求,减少强化学习训练过程中的无意义数据,增强混合流场景下的控制鲁棒性,为混合流车辆等不确定性场景下的队列控制提供了新思路;
64、2、本发明通过对非自动驾驶车辆的不稳定驱动状态模型进行构建和粒子滤波器估计,模拟了混合流下驾驶环境的不确定性,更接近真实驾驶环境;
65、3、本发明提供一种多智能体通信的参数共享结构,包括基于前车及头车的多向通信拓扑状态共享方式及基于奖励传播机制的奖励交互方式,提高了信息利用效率,解决了局部状态带来的不稳定问题,降低了训练过程的复杂度,加速收敛速度,可以解决多智能体中存在的非真实奖励和“惰性智能体”问题;
66、4、本发明通过对奖励函数进行改进,在保证车辆队列安全性的同时,可降低燃油消耗,对高速公路和城市道路上的交通振荡场景有应用价值,实现智能网联混合流环境下自动驾驶车辆队列的有效控制。
- 还没有人留言评论。精彩留言会获得点赞!