一种车辆队列纵横向控制方法
本公开实施例涉及智能网联车辆控制,尤其涉及一种车辆队列纵横向控制方法。
背景技术:
1、随着感知、通信等技术的不断发展,智能网联技术日趋成熟,智能网联车辆逐渐得到推广普及并对交通管理和出行效率等产生重要影响。在网联环境下,自动驾驶车辆调整运动状态进行编队,达到一致的行驶速度和期望的间距,形成车辆队列。车辆队列可以提高道路通行能力、提升道路行车的安全性、降低车辆的能源消耗、减少环境污染。
2、现有车辆队列控制技术仍有一定的不足。首先,队列控制方法主要集中于车辆队列的纵向控制,未考虑队列纵向行驶引起的横向偏差。综合考虑车辆队列的纵横向行驶,可以提升行驶的安全性,减少交通事故。其次,间距策略是车辆队列协同控制系统的重要组成部分之一,其决定了车辆行驶过程中的期望跟车间距。间距策略影响车辆队列的行车安全和道路利用率。目前主要采用固定间距(constant spacing,cs)策略和固定时距(constanttime headway,cth)间距策略。cs策略确定的期望车间距为常值,其优势在于结构简单,但既要兼顾各种复杂的交通环境,又要保证驾驶安全性,因此对间距值的选择极其困难苛刻。cth策略假定车头时距恒定,期望车间距与本车速度呈线性关系,在复杂的交通环境下,cth策略的表现不尽理想。
技术实现思路
1、为了避免现有技术的不足之处,本发明提供一种车辆队列纵横向控制方法。
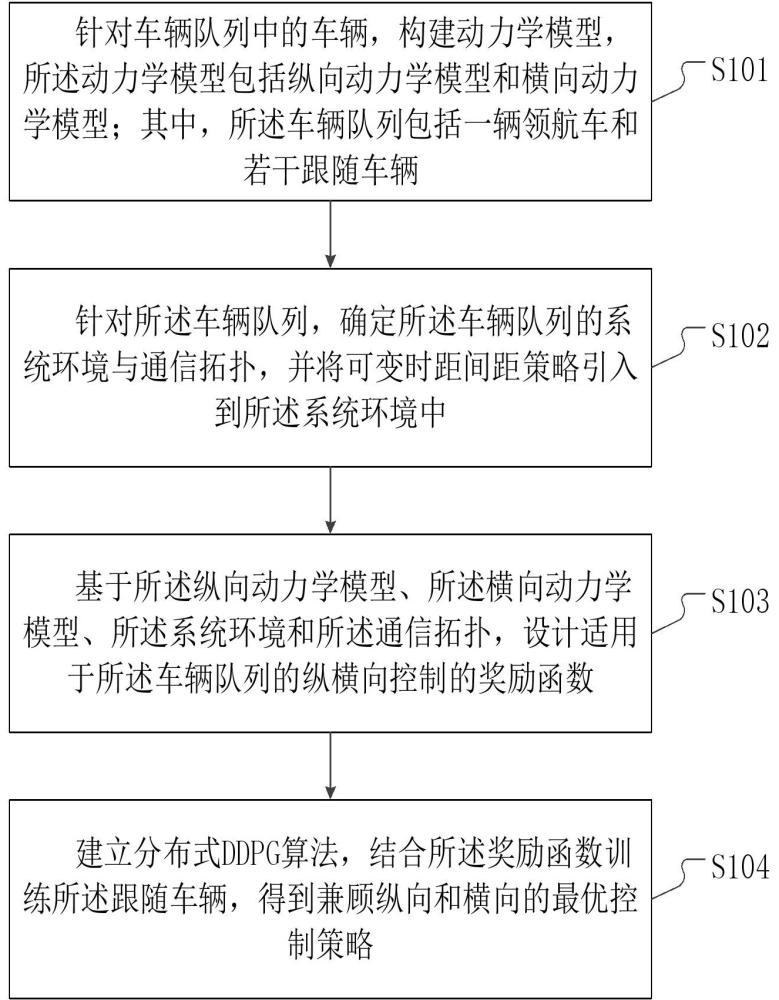
2、根据本公开实施例,提供一种车辆队列纵横向控制方法,该方法包括:
3、针对车辆队列中的车辆,构建动力学模型,所述动力学模型包括纵向动力学模型和横向动力学模型;其中,所述车辆队列包括一辆领航车和若干跟随车辆;
4、针对所述车辆队列,确定所述车辆队列的系统环境与通信拓扑,并将可变时距间距策略引入到所述系统环境中;
5、基于所述纵向动力学模型、所述横向动力学模型、所述系统环境和所述通信拓扑,设计适用于所述车辆队列的纵横向控制的奖励函数;
6、建立分布式ddpg算法,结合所述奖励函数训练所述跟随车辆,以得到兼顾纵向和横向的最优控制策略。
7、所述跟随车辆的纵向动力学模型的表达式为:
8、
9、
10、
11、式中,pi(t)为车辆队列中第i辆跟随车辆的位置,vi(t)为车辆队列中第i辆跟随车辆的速度,udes_i(t)为车辆队列中第i辆跟随车辆的期望加速度,τ为延迟,uactual_i(t)为实际输出执行加速度。
12、所述车辆队列中领航车的纵向动力学模型为:
13、
14、
15、式中,p0(t)为领航车的位置,v0(t)为领航车的速度,u0(t)为领航车的加速度。
16、所述横向动力学模型的表达式为:
17、
18、
19、式中,y表示车辆的侧向位移,为车辆横摆角,和分别为车辆前后轮的侧偏刚度,m为整车质量,vx表示车身坐标系下速度在x轴方向的分量,a与b分别为车辆质心到前后轮的距离,iz为车辆绕z轴转动的转动惯量,δ表示前轮转角,u表示控制输入。
20、所述可变时距间距策略的表达式为:
21、
22、式中,ddes_i表示第i辆车的期望间距,k0为当车辆静止时与前车的间距,k1为关于速度的一次项系数,k2关于速度的二次项系数。
23、所述分布式ddpg算法中的动作空间为:
24、a=(a1,a2,...,at)
25、式中,ai=(udes_i,steeringi)表示第i辆跟随车辆的动作空间,steeringi表示车辆i的前轮转角,t表示车辆队列中跟随车辆的数量。
26、所述分布式ddpg算法中的状态空间为:
27、s=(s1,s2,...,st)
28、式中,si为第i个车辆的状态观测量,包括本车速度、速度误差、速度误差的积分、角度偏差、角度偏差的导数及积分、横向位移误差、横向位移误差的导数及积分。
29、所述分布式ddpg算法中整个所述车辆队列控制系统的奖励函数为:
30、r=(r1,r2,...,rt)
31、式中,ri=ki(r1+r2+r3+r4+r5+r6+r7+r8)为第i个车辆的纵横向控制学习训练的奖励函数,其中,纵向碰撞奖励函数
32、
33、速度层面的奖励函数
34、
35、式中,verr_i为第i辆跟随车辆的速度误差;
36、间距层面的奖励函数
37、
38、式中,derr_i为第i辆跟随车辆的间距误差;
39、加速度层面奖励函数
40、
41、舒适性层面奖励函数
42、r5=-0.05jerki2
43、式中,jerki表示第i辆跟随车辆的跃度;
44、横向停止训练奖励函数
45、
46、前轮转角层面奖励函数
47、
48、横向偏差层面奖励函数
49、
50、式中,ed_i表示第i辆跟随车辆的横向位移误差。
51、所述分布式ddpg算法如下:
52、
53、其中,st表示当前状态,θμ为在策略μ下的actor网络参数,μ(st|θμ)表示在θμ条件下智能体在st时的动作输出;yi表示目标回报值,ri为当前状态下的奖励,γ表示折扣因子,si+1表示当前状态的下一个状态,θμ′为目标策略网络参数,θq′为目标价值网络参数,n为批处理大小,μ′(si+1|θμ′)表示目标动作输出,q′(si+1,μ′(si+1|θμ′)|θq′)表示目标动作价值;表示动作值函数对动作的梯度,表示策略μ对策略网络参数θμ的梯度,ξ表示软更新参数。
54、本公开的实施例提供的技术方案可以包括以下有益效果:
55、本公开的实施例中,通过上述车辆队列纵横向控制方法,首先,给出了车辆的纵向和横向动力学模型,通过控制加速度和前轮转角来控制车辆的纵向速度、横向位移及横摆角。其次,根据车辆队列的通信拓扑,确定智能体的观测量;引入可变时距间距策略,使得车辆在队列化行驶过程中兼顾安全性与道路利用率。再次,通过设计的奖励函数激励智能体逐步学习到最优策略,优化算法效率。最后,在保证安全的前提下,设计的分布式ddpg算法可以训练智能体做出兼顾纵向和横向控制的决策。所设计的分布式ddpg算法无需进行复杂的车辆动力学建模,根据所设计的状态观测可以探索到最优策略函数,凸显了无模型算法的优势。
技术特征:
1.一种车辆队列纵横向控制方法,其特征在于,该方法包括:
2.根据权利要求1所述车辆队列纵横向控制方法,其特征在于,所述跟随车辆的纵向动力学模型的表达式为:
3.根据权利要求2所述车辆队列纵横向控制方法,其特征在于,所述车辆队列中领航车的纵向动力学模型为:
4.根据权利要求3所述车辆队列纵横向控制方法,其特征在于,所述横向动力学模型的表达式为:
5.根据权利要求4所述车辆队列纵横向控制方法,其特征在于,所述可变时距间距策略的表达式为:
6.根据权利要求5所述车辆队列纵横向控制方法,其特征在于,所述分布式ddpg算法中的动作空间为:
7.根据权利要求6所述车辆队列纵横向控制方法,其特征在于,所述分布式ddpg算法中的状态空间为:
8.根据权利要求7所述车辆队列纵横向控制方法,其特征在于,所述分布式ddpg算法中整个所述车辆队列控制系统的奖励函数为:
9.根据权利要求8所述车辆队列纵横向控制方法,其特征在于,所述分布式ddpg算法如下:
技术总结
本公开实施例是关于一种车辆队列纵横向控制方法。该方法包括:构建车辆的纵横向动力学模型;确定车辆队列的系统环境与通信拓扑,引入可变时距间距策略;设计适用于车辆纵横向控制的奖励函数;建立分布式DDPG算法对跟随车辆进行训练得到最优控制策略。本公开实施例给出了车辆的纵横向动力学模型,通过控制加速度和前轮转角来控制车辆的纵向速度、横向位移及横摆角。根据车辆的通信拓扑,确定智能体的观测量。引入可变时距间距策略,使得车辆在队列化行驶过程中兼顾安全性与道路利用率。通过设计的奖励函数激励跟随车辆逐步学习到最优策略,优化算法效率。在保证安全的前提下,设计的分布式DDPG算法训练跟随车辆做出兼顾纵向和横向控制的决策。
技术研发人员:陈建忠,王文杰,许智赫,吕泽凯,吴晓宝
受保护的技术使用者:西北工业大学
技术研发日:
技术公布日:2024/2/29
- 还没有人留言评论。精彩留言会获得点赞!