一种深度强化学习中基于涡量光滑的奖励机制
本发明涉及一种流动控制与优化技术,特别涉及一种基于深度强化学习中基于涡量光滑的奖励机制。
背景技术:
1、翼型的流动分离是流体动力学工程应用领域中典型的减阻减振和流动控制问题。其中射流控制技术作为一种主动流动控制方法,可以适用于多种情况。但是如何合理、高效利用合成射流仍是一项挑战。
2、目前已有专利在深度强化学习中采用基于阻力与升力的奖励机制进行主动流动控制。cn114626277a-一种基于强化学习的主动流动控制方法。该专利使用奖励函数rt=-(cd)t+0.2|(cd)t|,仍不能满足更好的增升减阻效果。
3、考虑到涡量统计值与分布对流场和气动性能有着重要影响,涡量统计值过大会导致阻力增大,过小会导致升力减小,涡量统计值的不稳定性可能导致流动分离和失速现象。因此控制涡量统计值,可以改善翼型的气动稳定性,并减少不良的流动现象。
技术实现思路
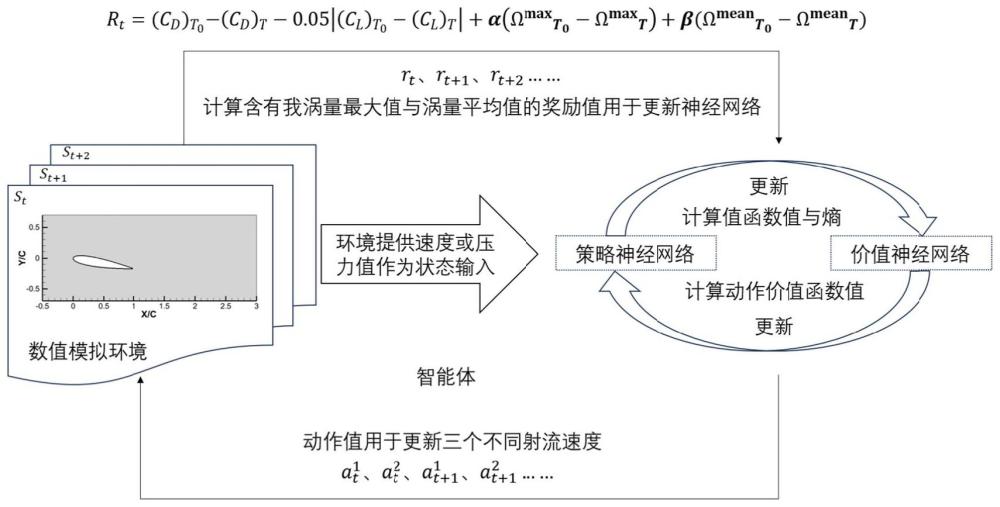
1、针对翼型流动分离的闭环主动控制的稳定性不足的问题,提出了一种深度强化学习中基于涡量光滑的奖励机制。考虑到翼型绕流流场尾涡强度与涡核大小的增加会对翼型绕流气动力环境产生消极影响,将探针点获取的涡量统计量大小配以权重作为奖励函数负积累的指标;综合考虑了翼型表面阻力系数、升力系数和以探针获取的涡量统计值;通过人工深度神经网络与流场数值模拟环境不断交互,动态更新神经网络参数,获取最优策略,控制翼型射流装置,改变流场流动状态,实现翼型增升减阻的目的。
2、本发明的技术方案为:
3、一种深度强化学习中基于涡量光滑的奖励机制,通过将翼型表面阻力系数、升力系数和探针点获取的涡量统计值结合构成奖励函数;根据该奖励函数对神经网络进行训练,获取合适的控制策略π,从而实现神经网络的主动流动控制,以期获得抑制流动分离最佳优化效果,具体包括如下步骤:
4、1)搭建翼型绕流数值模拟与人工深度神经网络的深度强化学习框架;对翼型绕流进行数值模拟,通过提前设置于流场内不同数量、位置的探针,获取不同控制周期内最后一个瞬时时刻的速度与压力值并计算该周期内翼型表面的平均升阻力系数与涡量统计值作为智能体更新所需数据;
5、人工深度神经网络作为框架内的智能体,包含策略神经网络π与价值神经网络;策略神经网络π根据流场提供的状态值输出动作分布参数;价值神经网络根据流场信息以及熵值评估当前状态的价值;
6、2)翼型绕流数值模拟环境提供智能体所需要的状态,首先获取无控制条件下不同攻角的流动情况,当流动发展至稳定状态的时刻,将该时刻作为不同攻角环境的初始状态,该时刻下,数值模拟流场中设置的探针所获得的速度或压力值作为初始状态值s0;
7、3)智能体根据当前时刻t环境输送的状态值st,输出动作值at,该动作值用来改变t时刻的翼型上表面所设有的主动流动控制装置所需参数,该控制装置根据该参数控制环境,进入到t+1时刻;
8、4)建立一种基于涡量光滑奖励函数,将翼型表面阻力系数、升力系数、涡量统计值考虑进奖励函数中,如下公式(1):
9、
10、其中rt表示t时刻的瞬时奖励值,α、β为涡量统计值大小变化的权重,根据不同流动条件而决定;表示初始时刻下的值;(·)t表示不同轨迹下的值;cd、cl分别表示翼型表面的阻力系数与升力系数;ωmax、ωmean分别为涡量最大值与涡量平均值;
11、计算不同时刻获得的价值函数,记录n个轨迹后,获得当前瞬时时刻的累计回报ut,组成经验池;
12、5)从经验池采用数据对价值神经网络进行更新。
13、进一步的,步骤1)中,策略神经网络与价值神经网络分别含有一套与四套神经网络,每套神经网络结构都含有两层全连接层,每层256个神经元,激活函数设置为adam函数。
14、进一步的,步骤1)中,数值模拟环境可以基于开源软件openfoam、su2平台进行,翼型表面设置有三个射流装置,它们之间在一个控制周期内添加零质量射流约束:q1+q2=-q3,其中qi,i=1,2,3为第i个射流位置的射流速度值。
15、进一步的,步骤1)的数值模拟中,翼型上表面设置有射流口,流场整体作为强化学习框架内的环境。
16、进一步的,步骤4)中,翼型绕流流场尾涡强度与涡核大小的增加作为评价翼型流动分离影响因素之一,以涡量统计值的形式同阻力系数和升力系数共同考虑进奖励函数;流场中设置了一定数量的探针,涡量数据ωmax、ωmean由探针计算得到。
17、进一步的,步骤4)中,流场包括层流及湍流、内流及外流、低雷诺数与高雷诺数、亚音速与超音速、二维或三维范畴内的翼型、柱体、钝体及其他不同形状和结构的固体绕流流场。
18、进一步的,步骤4)中,由探针得到的涡量统计值涵盖由涡量数据计算得到的平均值、四分位数、标准差、标准分、众数及其他可以代表涡量统计值的数据;也可以选择不同时刻下涡量统计值之间的差值作为奖励函数中的一部分;α、β为涡量统计值大小变化的权重;权重系数随攻角、流场条件以及涡量统计值变化并设置不同的值。
19、进一步的,步骤3)中的主动流动控制装置内部运行翼型流动分离主动控制方法,翼型流动分离主动控制方法可采用单射流、合成射流、吹吸装置,等离子体射流多种控制方式。
20、本发明的有益效果在于:
21、本发明用于进一步增强深度强化学习优化翼型流动分离问题。该方法采用柔性演员评论家(soft actor-critic),该算法融合熵值,用于指导强化学习中智能体即神经网络的更新方式,并与将翼型表面产生的升力、阻力、涡量统计值融合的奖励函数配合进行训练,训练得到的全连接层人工神经网络可以得到最优化的控制策略,从而有效地、全方位地改善流动环境。
22、针对采用零质量射流约束主动控制翼型流动分离问题,建立基于涡量光滑的奖励函数并引入到基于深度强化学习主动闭环控制中。相较于传统奖励机制,可以通过更新神经网络参数,更快获取最优策略。同时,通过涡量光滑抑制的翼型分离现象可实现有效减小和消去,稳定尾流振荡,因此,翼型增升减阻效果更优。
技术特征:
1.一种深度强化学习中基于涡量光滑的奖励机制,其特征在于,通过将翼型表面阻力系数、升力系数和探针点获取的涡量统计值结合构成奖励函数;根据该奖励函数对神经网络进行训练,获取合适的控制策略π,从而实现神经网络的主动流动控制,以期获得抑制流动分离最佳优化效果,具体包括如下步骤:
2.根据权利要求1所述的深度强化学习中基于涡量光滑的奖励机制,其特征在于,步骤1)中,策略神经网络与价值神经网络分别含有一套与四套神经网络,每套神经网络结构都含有两层全连接层,每层256个神经元,激活函数设置为adam函数。
3.根据权利要求1所述的深度强化学习中基于涡量光滑的奖励机制,其特征在于,步骤1)中,数值模拟环境可以基于开源软件openfoam、su2平台进行,翼型表面设置有三个射流装置,它们之间在一个控制周期内添加零质量射流约束:q1+q2=-q3,其中qi,i=1,2,3为第i个射流位置的射流速度值。
4.根据权利要求1所述的深度强化学习中基于涡量光滑的奖励机制,其特征在于,步骤1)的数值模拟中,翼型上表面设置有射流口,流场整体作为强化学习框架内的环境。
5.根据权利要求1所述的深度强化学习中基于涡量光滑的奖励机制,其特征在于,步骤4)中,翼型绕流流场尾涡强度与涡核大小的增加作为评价翼型流动分离影响因素之一,以涡量统计值的形式同阻力系数和升力系数共同考虑进奖励函数;流场中设置了一定数量的探针,涡量数据ωmax、ωmean由探针计算得到。
6.根据权利要求5所述的深度强化学习中基于涡量光滑的奖励机制,其特征在于,步骤4)中,流场包括层流及湍流、内流及外流、低雷诺数与高雷诺数、亚音速与超音速、二维或三维范畴内的翼型、柱体、钝体及其他不同形状和结构的固体绕流流场。
7.根据权利要求5所述的深度强化学习中基于涡量光滑的奖励机制,其特征在于,步骤4)中,由探针得到的涡量统计值涵盖由涡量数据计算得到的平均值、四分位数、标准差、标准分、众数及其他可以代表涡量统计值的数据;也可以选择不同时刻下涡量统计值之间的差值作为奖励函数中的一部分;α、β为涡量统计值大小变化的权重;权重系数随攻角、流场条件以及涡量统计值变化并设置不同的值。
8.根据权利要求1所述的深度强化学习中基于涡量光滑的奖励机制,其特征在于,步骤3)中的主动流动控制装置内部运行翼型流动分离主动控制方法,翼型流动分离主动控制方法可采用单射流、合成射流、吹吸装置,等离子体射流多种控制方式。
技术总结
本发明涉及一种深度强化学习中基于涡量光滑的奖励机制,通过将翼型表面阻力系数、升力系数和探针点获取的涡量统计值结合构成奖励函数;根据该奖励函数对神经网络进行训练,获取合适的控制策略π,从而实现神经网络的主动流动控制,以期获得抑制流动分离最佳优化效果。解决了翼型流动分离的闭环主动控制的稳定性不足的问题,综合考虑了翼型表面阻力系数、升力系数和以探针获取的涡量统计值;通过人工深度神经网络与流场数值模拟环境不断交互,动态更新神经网络参数,获取最优策略,控制翼型射流装置,改变流场流动状态,实现翼型增升减阻的目的。通过涡量光滑抑制的翼型分离现象可实现有效减小和消去,稳定尾流振荡,翼型增升减阻效果更优。
技术研发人员:尤孙钰,董祥瑞,靳智昊
受保护的技术使用者:上海理工大学
技术研发日:
技术公布日:2024/3/24
- 还没有人留言评论。精彩留言会获得点赞!