一种基于SAC强化学习算法的高速飞行器集群编队控制方法及系统
本发明涉及飞行器协同编队控制,具体涉及一种基于sac强化学习算法的高速飞行器集群编队控制方法及系统。
背景技术:
1、在高速飞行器的集群飞行任务中,如何实现高速环境下的编队控制是一个关键问题。传统的飞行器编队控制方法依赖于事先设计的控制策略,以领队-跟随控制法、虚拟结构控制法、行为控制法、一致性编队控制法这四类为典型代表,均根据飞行器集群的某一些状态量计算误差,并控制误差值减小至零,实现预期的编队效果。其中,编队控制的响应速度、精度取决于控制策略参数,同时根据不同的飞行环境需要修正参数以实现更好的控制效果。
2、然而,对于高速飞行器集群这类高动态飞行环境、强时变气动参数的飞行器集群而言,上述传统的编队控制方式不能适应如此复杂环境下的编队控制。这主要是因为高速飞行器集群在飞行过程中状态、环境均变化剧烈,无法针对每个状态设计对应的最优控制参数。
技术实现思路
1、为此,不考虑传统事先设计的控制策略,本发明提出了一种基于软演员评论家(soft actor-critic,sac)强化学习算法的高速飞行器集群编队控制方法及系统,用以解决现有基于固定参数控制策略的编队控制在高动态环境下失效的问题。
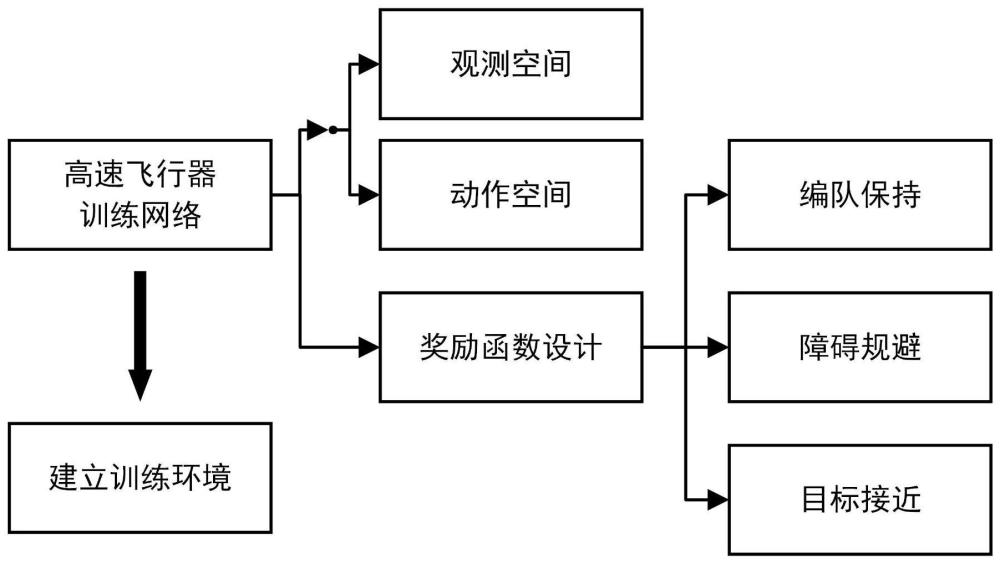
2、根据本发明的一方面,提出一种基于sac强化学习算法的高速飞行器集群编队控制方法,该方法包括以下步骤:
3、采集观测数据,确定高速飞行器集群的观测空间和动作空间;
4、基于观测数据训练基于sac强化学习算法的高速飞行器智能体网络;
5、利用训练好的高速飞行器智能体网络进行飞行器集群编队控制。
6、进一步地,所述观测数据包括集群状态、障碍状态、目标状态、自身状态;所述集群状态包括某一飞行器相对周围其他飞行器的相对位置和相对速度;所述障碍状态包括飞行器与障碍物中心的相对位置;所述目标状态包括目标相对于飞行器的相对位置和相对速度;所述自身状态包括飞行器自身的加速度、速度及位置;所述动作空间中动作量为过载指令。
7、进一步地,所述训练基于sac强化学习算法的高速飞行器智能体网络的过程包括:
8、初始化策略网络参数θ,策略值函数网络函数φ1和φ2,经验池d;设置值函数的目标网络参数φtarg1、φtarg2分别与参数φ1、φ2相同;按照下述过程迭代重复执行训练:
9、观测环境状态s,根据控制策略输出控制指令a~πθ(·|s);在环境中执行动作a;
10、观测下一个状态s',反馈的奖励r以及回合结束标志位d;将经验组(s,a,r,s',d)储存到经验池d;s代表状态,a代表动作,r代表奖励,s'代表下一个状态,d代表回合结束标志位;若回合结束则初始化环境状态;若达到更新周期则执行下述步骤:
11、从经验池d中随机采样一组经验,表示为b={(s,a,r,s',d)};通过下式计算值函数的真值估计:
12、
13、式中,γ∈[0,1]表示折扣率;表示目标网络参数下的动作价值函数;α表示权衡系数;表示该状态s下不同动作的策略分布,用以计算熵;
14、通过最小化以下损失函数更新值函数网络参数φi:
15、
16、式中,表示动作价值函数;
17、通过最小化以下损失函数更新集群控制策略网络参数θ:
18、
19、式中,通过πθ(·|s')采样得到;表示动作价值函数;表示该状态s下不同动作的策略分布;
20、更新目标网络:φtarg,i←ρφtarg,i+(1-ρ)φi i=1,2;
21、式中,ρ表示目标网络更新中的一个系数,该系数越大,目标网络变化越小,算法收敛速度越慢;φtarg,i表示目标网络参数。
22、进一步地,基于sac强化学习算法的高速飞行器智能体网络中设计如下奖励函数:编队保持奖励、障碍规避奖励、目标接近奖励。
23、进一步地,编队保持奖励表示为:
24、
25、式中,rfkeepv表示相对速度保持奖励;rfkeepp表示相对位置保持奖励;kfkeepv表示相对速度保持奖励系数;kfkeepp表示相对位置保持奖励系数;dv表示飞行器与周围通信范围内飞行器的速度偏差;vfkeepv表示无量纲化系数,将速度偏差无量纲化;drij表示飞行器i与周围j单元的距离偏差;rfkeepp表示无量纲化系数,将距离偏差无量纲化。
26、进一步地,当飞行器与障碍区外表面距离大于安全距离时,障碍规避奖励表示为:
27、
28、式中,kobsavoids表示半球形障碍区域规避奖励系数;dobssafe表示障碍区安全距离;δrmtoobs表示飞行器与障碍区的相对位置向量减去障碍区的半径向量;
29、当飞行器与障碍区外表面距离小于安全距离时,障碍规避奖励表示为robsavoids和robsavoidg两部分的和:
30、
31、
32、式中,kobsdangers表示一常值负系数,也代表一常值奖励;h表示飞行器高度,kobsdangerg表示地面障碍负值奖励系数;hsafe表示安全飞行高度。
33、进一步地,目标接近奖励包括目标接近奖励rtotgtp和目标到达奖励rtotgtdone:
34、
35、rtotgtdone=ktotgtdone,dmtotgt<ddone
36、式中,ktotgtp表示目标接近奖励系数;dmtotgt表示弹目相对位置向量的模长;drange表示初始位置时飞行器与目标的距离;ddone表示判停距离条件,当有飞行器与目标的距离小于该距离时,表示飞行器到达目标,任务结束;ktotgtdone表示一次性奖励,当飞行器到达目标时,提供该项奖励,该奖励远大于其他奖励。
37、根据本发明的另一方面,提出一种基于sac强化学习算法的高速飞行器集群编队控制系统,该系统包括:
38、数据获取模块,其配置成采集观测数据,确定高速飞行器集群的观测空间和动作空间;所述观测数据包括集群状态、障碍状态、目标状态、自身状态;所述集群状态包括某一飞行器相对周围其他飞行器的相对位置和相对速度;所述障碍状态包括飞行器与障碍物中心的相对位置;所述目标状态包括目标相对于飞行器的相对位置和相对速度;所述自身状态包括飞行器自身的加速度、速度及位置;所述动作空间中动作量为过载指令;
39、模型训练模块,其配置成基于观测数据训练基于sac强化学习算法的高速飞行器智能体网络;
40、编队控制模块,其配置成利用训练好的高速飞行器智能体网络进行飞行器集群编队控制。
41、进一步地,所述模型训练模块中所述训练基于sac强化学习算法的高速飞行器智能体网络的过程包括:
42、初始化策略网络参数θ,策略值函数网络函数φ1和φ2,经验池d;设置值函数的目标网络参数φtarg1、φtarg2分别与参数φ1、φ2相同;按照下述过程迭代重复执行训练:
43、观测环境状态s,根据控制策略输出控制指令a~πθ(·|s);在环境中执行动作a;
44、观测下一个状态s',反馈的奖励r以及回合结束标志位d;将经验组(s,a,r,s',d)储存到经验池d;s代表状态,a代表动作,r代表奖励,s'代表下一个状态,d代表回合结束标志位;若回合结束则初始化环境状态;若达到更新周期则执行下述步骤:
45、从经验池d中随机采样一组经验,表示为b={(s,a,r,s',d)};通过下式计算值函数的真值估计:
46、
47、式中,γ∈[0,1]表示折扣率;表示目标网络参数下的动作价值函数;α表示权衡系数;表示该状态s下不同动作的策略分布,用以计算熵;
48、通过最小化以下损失函数更新值函数网络参数φi:
49、
50、式中,表示动作价值函数;
51、通过最小化以下损失函数更新集群控制策略网络参数θ:
52、
53、式中,通过πθ(·|s')采样得到;表示动作价值函数;表示该状态s下不同动作的策略分布;
54、更新目标网络:φtarg,i←ρφtarg,i+(1-ρ)φi i=1,2;
55、式中,ρ表示目标网络更新中的一个系数,该系数越大,目标网络变化越小,算法收敛速度越慢;φtarg,i表示目标网络参数。
56、进一步地,所述模型训练模块中所述基于sac强化学习算法的高速飞行器智能体网络中设计如下奖励函数:编队保持奖励、障碍规避奖励、目标接近奖励。
57、本发明的有益技术效果是:
58、本发明通过飞行器集群与环境的交互以学习得到控制策略,能够根据状态、环境的变化自动调整控制参数,并做出机动,代替原本固定的编队控制策略,极大提高了高速飞行器集群的编队控制能力。利用sac强化学习算法训练高速飞行器,实现有障碍环境下的飞行器集群编队控制,采用强化学习算法实现的智能编队控制有如下优势:1)飞行器在虚拟环境中进行了大量试错仿真,探索了尽可能多的飞行状态,能在不同的环境下做出不同的决策,提高应对环境的能力;2)在奖励函数的设计中可以充分考虑不同的任务,并通过参数的修正来权衡不同任务的重要程度,丰富了飞行器的任务执行种类与执行任务的能力。
59、本发明能够在高速飞行器面临高动态环境的情况下,保障高速飞行器集群的智能编队,开展大规模高速飞行器集群飞行。
- 还没有人留言评论。精彩留言会获得点赞!