一种基于TD3强化学习算法的液压挖掘机用轨迹规划方法
本发明涉及智能液压挖掘机,具体为一种基于td3强化学习算法的液压挖掘机用轨迹规划方法。
背景技术:
1、智能液压挖掘机的轨迹规划方法指的是通过算法和技术,使挖掘机能够自动规划并执行其运动轨迹,以实现特定任务。这种方法通常涉及传感器、计算机视觉和控制系统,帮助挖掘机在工作区域内进行移动、挖掘或执行其他操作。能够更智能、更高效地执行任务,减少人为干预的需要,并在复杂环境中提供更可靠的运动控制。
2、目前传统的智能液压挖掘机工作依赖于插值策略的最优轨迹规划方法,该方法在进行复杂环境下的挖掘作业时,需要对复杂任务进行规划并精确建模,导致实际使用过程中系统响应速率不够高效,任务的执行精度也存在差异,为此本发明提出一种基于td3强化学习算法的液压挖掘机用轨迹规划方法。
技术实现思路
1、针对现有技术的不足,本发明提供了一种基于td3强化学习算法的液压挖掘机用轨迹规划方法,解决了现有技术中对复杂任务进行规划并精确建模,导致实际使用过程中系统响应速率不够高效,任务的执行精度也存在差异的问题。
2、为实现以上目的,本发明通过以下技术方案予以实现:一种基于td3强化学习算法的液压挖掘机用轨迹规划方法,包括以下步骤:
3、步骤一、在不考虑回转作业的情况下,挖掘机工作装置在作业过程中以动臂、斗杆和铲斗三个关节之间耦合运动来实现铲斗齿尖末端的运动轨迹,将动臂、斗杆和铲斗每个关节作为单独的决策智能体,最终规划的作业轨迹是三个关节的决策序列;
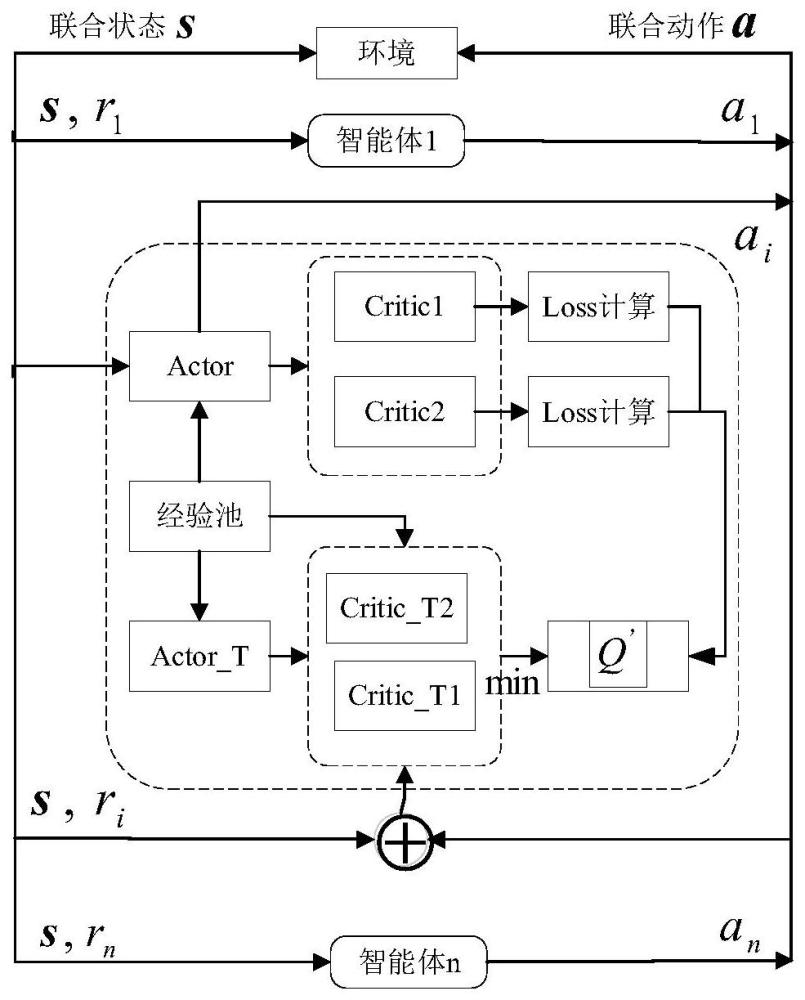
4、步骤二:采用集中训练-分布执行训练方式,将环境状态和三个智能体的联合动作作为训练过程中评价器决策网络的输入,使得输出的评价值函数包含了三个关节智能体协同的指导信息;
5、步骤三:基于步骤二的训练结果,进行分布式执行,主要通过各智能体执行动作无需互相沟通,经过长时间的训练,可实现动臂、斗杆和铲斗三个关节协同作业,完成多智能体系统模型的建立,之后对建立的多智能体系统模型的基本要素进行定义;
6、步骤四:利用td3算法对挖掘机点到点作业任务进行优化,对步骤三建立的多智能体系统模型进行训练,对动臂、斗杆和铲斗各关节建立actor-critic框架。
7、优选的,所述步骤三中进行要素定义包括状态空间设计,以动臂、斗杆和铲斗关节的角度为状态参数,将初始关节角度作为策略网络的输入参数,根据动作策略网络输出对应的关节角度值的变化幅度计算获得下一个状态的角度值,其具体计算公式如下:
8、θi=θi0+δθi(i=2,3,4)
9、式中,θi0代表动臂、斗杆和铲斗关节在起始点的关节角度值,δθi代表各关节角度值变化幅度,i=2,3,4依次表示动臂、斗杆和铲斗关节。
10、优选的,所述步骤三中进行要素定义包括动作空间设计,定义策略网络的输出为关节角度变化幅度,且采取的动作满足ai~n(0,1)正态分布,为了降低决策动作的难度,需要对输出信息进行离散化处理。
11、优选的,所述步骤三中进行要素定义包括奖励函数设计,为了实现工作装置在其允许的工作范围内高效率、平稳的自主作业,设计智能体的奖励函数为:
12、
13、r=r11+r12+r13+r21+r22+r23+r31+r32+r33+rt
14、式中,θ2,θ3,θ4依次为动臂、斗杆和铲斗关节角度值;r11,r12表示动臂关节运动是否超出允许运动范围获得的奖励,r13表示动臂关节的速度是否超出约束范围,θ2min,θ2max表示动臂关节允许运动范围,v2表示动臂关节的速度约束值,r21,r22和r23,r31,r32和r33依次为斗杆和铲斗关节运动是否超出允许运动范围获得的奖励,dt为铲斗齿尖末端当前位置和目标终点的距离,t为作业的总时间。
15、优选的,所述奖励函数中θ2<θ2min,θ2>θ2max和为布尔表达式,即当动臂关节角度和角速度值在允许运动范围内时,布尔表达式结果为0,反之,当动臂关节角度和角速度值超过允许范围时,布尔表达式的结果为1。
16、优选的,所述步骤三中进行要素定义包括神经网络设计,基于td3算法中的actor和critic网络,它们的结构基本相同,采用双隐层结构的全连接网络,隐藏层包含512个神经元,relu函数为激活函数,其中包括:
17、actor网络接收归一化的状态观测信息,经过全连接层后,设置softmax函数作为神经网络最后一层,将输出结果转化为概率分布向量,形成离散化的输出信息;
18、critic网络输出1维状态值函数。
19、8.优选的,所述步骤三中进行要素定义包括超参数设置,对于神经网络训练过程中采用adam网络优化器,基于td3算法的时间最优轨迹规划过程包括以下步骤:
20、s1、初始化评估网络critic1、critic2和策略网络actor,并随机给定网络参数θ1,θ2,φ;
21、s2、初始化目标网络critic_t1,critic_t2和actor_t,且使θ'1←θ1,θ'2←θ2,φ'←φ;
22、s3、初始化经验池β;
23、s4、for 1 to t;
24、s5、产生带有噪声的动作a~πφ(s)+ε,ε~n(0,σ),根据奖励函数计算执行动作获得的奖励值以及新的状态s',将四元组(s,a,r,s')放入经验池β;
25、s6、从经验池取数量为n的四元组(s,a,r,s')用于训练目标网络。
26、优选的,所述s6中包括:
27、actor_t:
28、critic_t1和critic_t2:
29、更新critic1和critic2网络参数:
30、if t积累一定步长do;
31、更新确定性策略的参数φ:
32、利用梯度下降法更新:
33、θ'i←τθi+(1-τ)θ'i
34、更新目标网络参数:φ'←τφ+(1-τ)φ'。
35、优选的,所述步骤四中actor网络用于策略迭代更新,actor_t网络用于经验池采样更新,其网络参数定期从actor网络更新。
36、优选的,所述步骤四中critic1和critic2网络为评估当前actor的行为更新q值;critic_t1和critic_t2网络负责计算全局奖励值,其网络参数定期从critic1和critic2处更新,最终通过以高效率为目标,求取满足奖励值大的作业路径。
37、本发明提供了一种基于td3强化学习算法的液压挖掘机用轨迹规划方法。
38、具备以下有益效果:
39、1、本发明不依赖于特定的插值策略模型,利用强化学习算法-td3算法可实现挖掘机的自主在线作业轨迹规划,不需要根据规划路径的目标点选择对应的插值策略模型,也就是避免了对复杂规划任务的精确建模。
40、2、本发明通过利用td3强化学习算法对挖掘机工作装置的训练,可实现快速连续决策,不需要对控制律进行求解,通过利用td3强化学习算法对挖掘机的动臂、斗杆和铲斗三个关节进行训练,最终可实现挖掘机工作装置的及时决策并执行规划结果,避免了传统控制方法中对控制律的求取。
41、3、本发明相比于传统的采用智能优化算法对插值策略进行优化求解最优轨迹的方法,利用td3强化学习算法优化求取挖掘机的时间最优轨迹,可有效地降低计算量,从而有助于提高规划效率。
- 还没有人留言评论。精彩留言会获得点赞!