一种动态扰动环境下多旋翼飞行器自学习抗干扰控制方法
本发明涉及飞行器控制,尤其是涉及一种动态扰动环境下多旋翼飞行器自学习抗干扰控制方法。
背景技术:
1、多旋翼飞行器因其多种独特的优势而具有很高的应用潜力和商业价值,这些优势包括飞行方式灵活、体积小、结构简单、能够垂直起降和悬停等。随着多旋翼飞行器在民用和军事等多个领域广泛的应用,其任务要求越来越复杂,如何有效的抵抗未知的环境扰动并保持稳定,是多旋翼飞行器研究领域中的关键问题。在系统受到扰动或由此存在模型不确定性时,传统的处理方法,如用简单的二次空气阻力模型替代等,不能保持良好的性能。因此,探索一种能够有效处理飞行过程中的不确定性从而抵抗未知扰动的控制策略是至关重要的。
2、然而,传统的仅依赖于控制手段的方法抗干扰能力有限,而且多旋翼飞行器在当前状态下不能利用先前飞行过程中的先验信息来调整自身状态。基于学习的方法可以通过获取数据信息预先对系统进行训练,从而使多旋翼飞行器在遭遇飞行中的环境扰动时,能够快速适应并保持稳定。但是现有的基于学习的方法往往只关注于单一的环境条件,在应对持续变化的环境扰动时,如何从已经学习过的任务中迁移知识到新的任务是目前多旋翼飞行器控制领域的一个积极研究方向。
技术实现思路
1、本发明的目的是提供一种动态扰动环境下多旋翼飞行器自学习抗干扰控制方法,将前馈pid控制方法与元学习及自适应控制相结合,能够利用先前飞行过程中积累的信息,在扰动条件持续变化时能够更快的进行自适应,提高飞行系统对新任务的泛化能力。
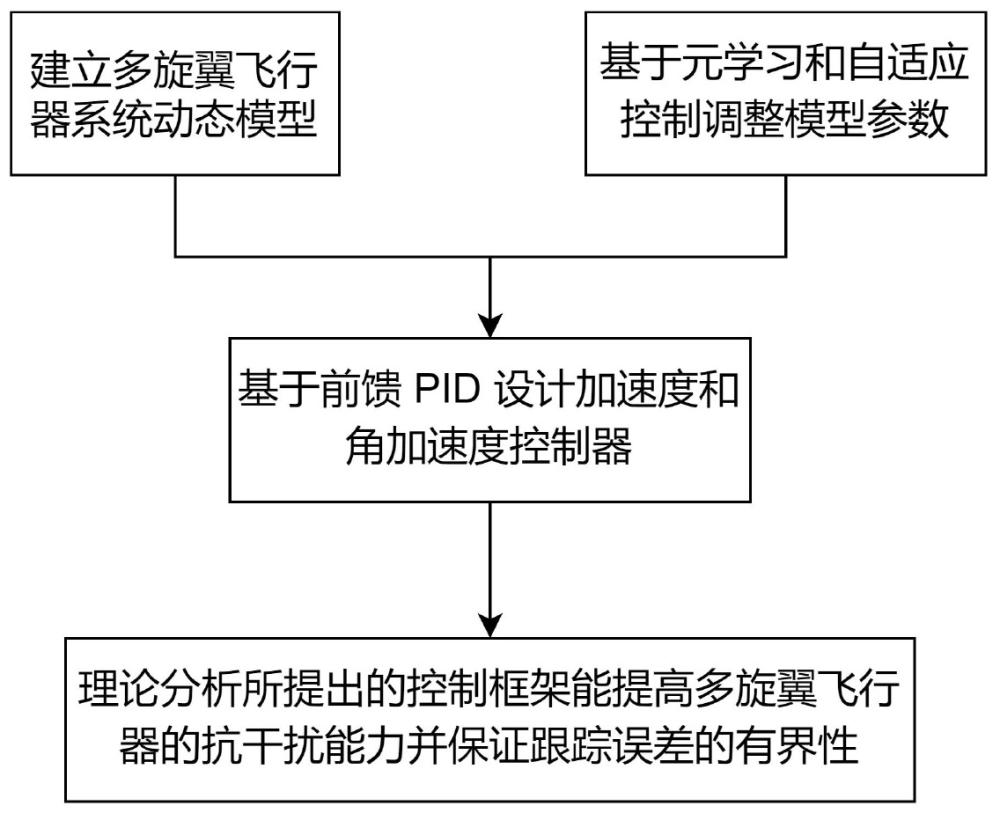
2、为实现上述目的,本发明提供了一种动态扰动环境下多旋翼飞行器自学习抗干扰控制方法,包括以下步骤:
3、s1、建立多旋翼飞行器系统动态模型;
4、s2、基于元学习和自适应控制更新多旋翼飞行器系统动态模型参数;
5、s3、根据更新后的多旋翼飞行器系统动态模型,基于前馈pid控制律设计加速度和角加速度控制器。
6、优选的,所述s1具体为:
7、多旋翼飞行器每个旋翼产生的拉力为:
8、;
9、其中,为旋翼编号,为对应旋翼产生的拉力,为对应的电机转速,为旋翼的拉力系数;
10、旋翼产生的总拉力为:
11、;
12、从机体坐标系到惯性坐标系的旋转矩阵表示为:
13、;
14、其中,定义表示姿态向量,为滚转角,为俯仰角,为偏航角;
15、多旋翼飞行器的质量为,重力加速度为,在惯性坐标系下的位置,多旋翼飞行器的线运动方程描述为
16、;
17、其中,为未知的系统扰动力;
18、整理得:
19、;
20、旋翼拉力产生的滚转和俯仰力矩分别为和,表示为:
21、;
22、力臂和大小相等,是编号为的旋翼产生的拉力,空气对每个旋翼产生的旋翼反扭矩为:
23、;
24、其中为旋翼扭矩系数,偏航运动由反扭矩控制,偏航力矩为:
25、;
26、多旋翼飞行器的转动惯量矩阵为,由旋转动力学得
27、;
28、其中,分别为滚转、俯仰和偏航角速度,为机体角速度,为旋翼产生的力矩,为系统扰动力矩;是对角矩阵;角运动方程为
29、;
30、从机体角速度到姿态角速度的转换矩阵记为,形式为:
31、;
32、机体角速度到姿态角速度的转换关系为
33、。
34、优选的,所述s2具体为:
35、在训练数据集时,用控制输入和系统状态计算出预期的模型参数,得到电机模型参数的残差值。假设有条训练数据,则数据集表示为:
36、;
37、为学习结束后对参数残差值的估计量,采用外环离线元学习与内环在线自适应控制相结合的分层嵌套方法对其进行调整;
38、定义如下函数
39、;
40、其中,外环为不同环境中共有的特征表示,采用三层深度神经网络进行训练,输入是多旋翼飞行器的状态,为网络的权重;在与单一环境进行交互时,保持神经网络固定,基于预测误差调整线性系数。
41、优选的,分层网络架构的实现为:
42、解决如下最优问题:
43、;
44、损失函数为
45、;
46、首先,基于损失函数对系数进行简单适应,接着,采用梯度下降法对神经网络进行优化:
47、;
48、其中,为学习率,为一次学习迭代中的总时间步;引入adam优化器对学习率进行动态调整,引入谱归一化方法限制深度神经网络模型三个全连接层的权重;采用批量梯度下降的方法,通过对批次任务中每个元素进行迭代,计算批量数据的损失,然后在这个批量上执行一次优化步骤;
49、针对特定环境,采用在线梯度下降的方法基于预测误差对系数进行调整,公式为:
50、,
51、其中,为第次训练时的学习率;
52、得到对参数的残差估计后,控制器根据电机模型参数执行操作。
53、优选的,所述s3中,加速度控制指令表达式如下:
54、;
55、其中,表示拉普拉斯变换域中的复频率,,,均为正定对角增益矩阵,,,分别为参考位置、速度和加速度的前馈量;
56、拉力指令为
57、;
58、通过如下表达式分别解算出滚转角和俯仰角指令:
59、;
60、;
61、结合偏航角参考量得姿态角指令;
62、角加速度控制指令表达式为:
63、;
64、其中,,,均为正定对角增益矩阵,,分别为参考角速度和角加速度的前馈量,其计算方法为根据微分平坦特性用多旋翼飞行器的位置和偏航角的高阶导数表示,用于在系统响应之前就调整控制输入;
65、得到加速度和角加速度控制指令后结合
66、;
67、;
68、得到每个电机的转速指令。
69、优选的,通过理论分析,证实结合元学习和自适应控制的前馈pid控制框架能提高多旋翼飞行器的抗干扰能力,并且能够保证跟踪误差的有界性;随着控制精度的提升和学习效果的增强,误差得到相应地减少;
70、对多旋翼飞行器自学习抗干扰控制方法稳定性分析如下:
71、给定期望位置,定义跟踪误差如下:
72、;
73、定义学习误差如下:
74、;
75、只要神经网络具有足够多的神经元,具有任意小的有界性约束;
76、假定测量误差有界,随着环境扰动条件的变化,考虑的情况,得到稳定性定理:
77、;
78、其中,为有界常数,大小取决于,,,,,,,系统模型参数,随着控制律的优化和模型学习效果的提升,有界误差的值会随之减小。
79、本发明所述的一种动态扰动环境下多旋翼飞行器自学习抗干扰控制方法的优点和积极效果是:
80、1、本发明方法通过引入元学习,可以使多旋翼飞行器系统利用来自不同环境条件的先验信息,从而加速系统适应新环境的能力;通过自适应控制调整模型参数,使系统能够更有效地应对特定的环境扰动条件。
81、2、本发明方法在学习后的模型上采用前馈pid进行控制,对于环境干扰和模型不确定性具有良好的鲁棒性。
82、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
- 还没有人留言评论。精彩留言会获得点赞!