一种基于离散时间强化学习的卫星智能鲁棒近似最优轨道控制方法
本发明涉及卫星轨道智能控制领域,具体是一种基于离散时间强化学习的卫星智能鲁棒近似最优轨道控制方法。
背景技术:
1、卫星轨道智能控制一直是卫星在轨服务中的关键课题,并广泛应用于空间重大任务,例如:空间碎片的主动清除、星际探测等。对于空间卫星来说,推进器燃料是保证卫星正常工作的重要的资源。在设计卫星轨道控制策略时,需要将燃料消耗纳入控制性能指标中。然而,由于卫星轨道的强非线性特征,增加了以燃料为性能指标的轨道控制器设计难度。此外,在卫星运行过程中,容易受到各种摄动力等不确定性的影响,会严重降低卫星轨道的控制精度,进一步增加了卫星非线性最优控制器的设计难度。
2、针对卫星轨道的最优控制问题,目前已经提出了多种控制方法。常用的卫星轨道控制策略普遍需要对卫星轨道系统进行局部线性化,然后再进行控制器设计。然而,这种局部线性化会降低卫星轨道的控制精度。此外,现有的非线性最优控制方法没有考虑不确定性的影响,导致所设计的控制策略不够精确。因此,针对卫星轨道最优控制任务,如何避免局部线性化,设计一种非线性鲁棒最优控制方法是一个难题。
技术实现思路
1、本发明的技术解决问题是:针对卫星非线性轨道最优控制问题,克服现有技术的不足,并充分利用神经网络的非线性逼近特性,提出了一种基于离散时间强化学习的卫星智能鲁棒近似最优轨道控制方法。
2、为了实现上述目的,本发明采用如下技术方案:
3、一种基于离散时间强化学习的卫星智能鲁棒近似最优轨道控制方法,包括以下步骤:
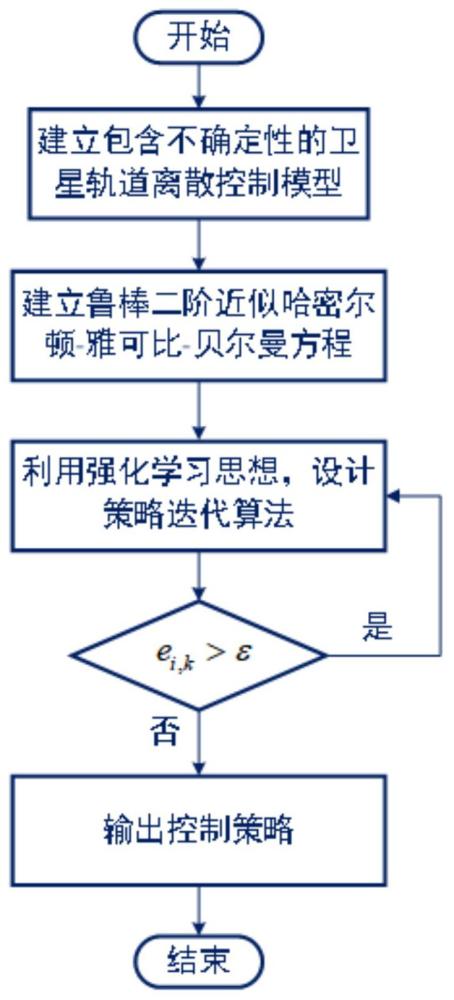
4、步骤1:根据二体动力学,建立包含不确定性的卫星轨道离散控制模型;
5、步骤2:利用泰勒公式的二阶展开式,建立卫星最优控制的鲁棒二阶近似哈密尔顿-雅可比-贝尔曼方程;
6、步骤3:基于鲁棒二阶近似哈密尔顿-雅可比-贝尔曼方程,设计卫星轨道控制策略迭代算法;
7、进一步地,步骤1具体为:
8、建立卫星轨道控制模型:
9、
10、其中,为关于卫星位置和速度的向量;为卫星轨道控制系统的非线性项;为控制输入的系数矩阵;为卫星的控制输入。和具体形式如下:
11、
12、其中,为万有引力常数;为参考轨道的真近点角;为参考轨道半径。和分别满足如下动态方程:
13、
14、进一步,利用欧拉离散化方法,建立卫星轨道离散控制模型:
15、
16、其中,,;为采样周期,为卫星状态在第时刻的值,为卫星输入在第时刻的值。
17、进一步地,建立包含不确定性的卫星轨道离散控制模型
18、
19、其中,为卫星轨道控制系统的非匹配不确定项,且满足如下不等式:
20、
21、其中,为已知确定的关于状态的函数。
22、为了量化控制性能,卫星控制成本函数设置为:
23、
24、其中,矩阵为可调节的已知正定常数矩阵。控制器的设计目的是最小化控制成本函数。
25、进一步地,步骤2具体为:利用泰勒公式的二阶展开式,建立鲁棒二阶近似哈密尔顿-雅可比-贝尔曼方程:
26、且
27、其中,和分别为值函数的梯度向量和海森矩阵,其表达式分别为:
28、
29、其中,为向量中的第个元素。
30、进一步地,步骤3具体为:基于上述鲁棒二阶近似哈密尔顿-雅可比-贝尔曼方程,利用强化学习思想,设计如下策略迭代算法:
31、步骤3.1:首先选择一个初始允许控制策略,并初始化计算误差阈值。
32、步骤3.2:对于迭代次数,迭代值函数按照如下方程计算:
33、
34、其中,为可调节的正常数。
35、步骤3.3:在得出的值函数的基础之上,计算下一迭代步数的控制策略
36、
37、其中,
38、
39、步骤3.4:计算相邻两次的控制策略范数误差。如果,则转至步骤3.2,否则,计算结束,输出最优控制策略。
40、本发明的有益效果是:针对包含不确定性的卫星轨道离散控制问题,本发明设计了一种全新的鲁棒二阶近似哈密尔顿-雅可比-贝尔曼方程及具有收敛特性的策略迭代算法。本发明既克服了卫星轨道的非线性特性,又解决了卫星轨道不确定性的不良影响,保证了卫星轨道的控制精度。
技术特征:
1.一种基于离散时间强化学习的卫星智能鲁棒近似最优轨道控制方法,其特征在于包括以下步骤:
2.根据权利要求1所述的一种基于离散时间强化学习的卫星智能鲁棒近似最优轨道控制方法,其特征在于,建立卫星轨道控制模型:
3.根据权利要求2所述的一种基于离散时间强化学习的卫星智能鲁棒近似最优轨道控制方法,其特征在于,利用欧拉离散化方法,建立卫星轨道离散控制模型:
4.根据权利要求2所述的一种基于离散时间强化学习的卫星智能鲁棒近似最优轨道控制方法,其特征在于,建立包含不确定性的卫星轨道离散控制模型
5.根据权利要求4所述的一种基于离散时间强化学习的卫星智能鲁棒近似最优轨道控制方法,其特征在于:卫星控制成本函数设置为:
6.根据权利要求5所述的一种基于离散时间强化学习的卫星智能鲁棒近似最优轨道控制方法,其特征在于,上述步骤3中,基于上述鲁棒二阶近似哈密尔顿-雅可比-贝尔曼方程,利用强化学习思想,设计如下策略迭代算法:
技术总结
本发明涉及一种基于离散时间强化学习的卫星智能鲁棒近似最优轨道控制方法,针对包含不确定性的卫星轨道离散控制问题,设计了一种全新的鲁棒二阶近似哈密尔顿‑雅可比‑贝尔曼方程,基于此方程,设计了一种具有收敛特性的策略迭代算法。该方法既可以有效解决系统中的不确定性,还可以保证卫星轨道控制的稳定性,与此同时,这种策略迭代方法便于在实际工程中应用。
技术研发人员:张鹏,陈谋,邵书义
受保护的技术使用者:南京航空航天大学
技术研发日:
技术公布日:2024/3/27
- 还没有人留言评论。精彩留言会获得点赞!