乘加器的制作方法与工艺
本发明涉及一种乘加器,尤其涉及一种可以根据操作数的位宽配置资源的乘加器。
背景技术:
随着FPGA芯片容量的提高和工艺的发展,很多FPGA都预先设计并内嵌了硬件乘加器(MACIP)。如果用户需要实现多位二进制的乘法,加法或者累加操作,为了避免占用大量的可配置逻辑和路由资源(PLB),往往都通过调用此硬件乘加器模块(MACIP)来实现。例如,若需要并行实现4个8*8bit的乘累加操作,用户可在代码中例化4个MACIP实现。这种方法很好,用户不用担心MACIP的实现功能是否准确,同时也节约了较多的可配置资源。但现有的FPGAMACIP在设计时,由于事先无法得知用户的具体应用中操作数的位宽,往往都采用了较长的且固定位宽的设置(例如xilinxSpartan-3A中采用了18bit),这种MACIP的设计方案在输入的操作位数宽数较少的情况下,同样也占用了较多的IP资源,资源利用效率低。由于FPGA内嵌了硬件乘加器,所以FPGA在数字信号处理系统方面的成本和功耗性能已经接近专用的DSP处理器。在实现中,不同系列芯片中,FPGA内嵌的硬件乘加器特点略有不同,但为了覆盖大部分的应用情况,从整体而言,往往将缺省的操作位数宽设置的比较长,即乘法器的规模比较大。如18*18bit,都能完全准确的输出36bit结果,累加运算也可以扩展到40bit以上。图1为现有的乘加器的示意图,如图所示:乘法功能:18*18bit乘法操作,具有完全准确的36bit输出结果。预置数功能:当sload有效时,可将load[39:0]直接置位到输出寄存器中,并输出;加法功能:可实现最大40bit的加法操作,其中一个操作数来自于乘法器的输出,另一个来自于输入Z[39:0];累加功能:可将乘法器的输出随时钟节拍进行内部累加,并在适当的节拍时输出。这种模式可方便的应用于FIRFilter实现中;另外,一些MACIP也包含Pre-Adder功能。现有技术的缺陷如下:资源利用效率低,对于一个乘法累加器,即乘加器资源,如果只使用了其少数的低位资源,则剩余的高位资源就不能再被使用了,资源利用效率低。运算速度慢。如果仅需要实现一个小位宽的操作,上述结构中,还是需要计算18bit与18bit的乘法,内部的累加还是必须进行40bit的累加,直到输出结果。这极大的影响了小位宽输出情况下的性能。乘加器是DSP的基础器件,其性能的优化是至关重要的。
技术实现要素:
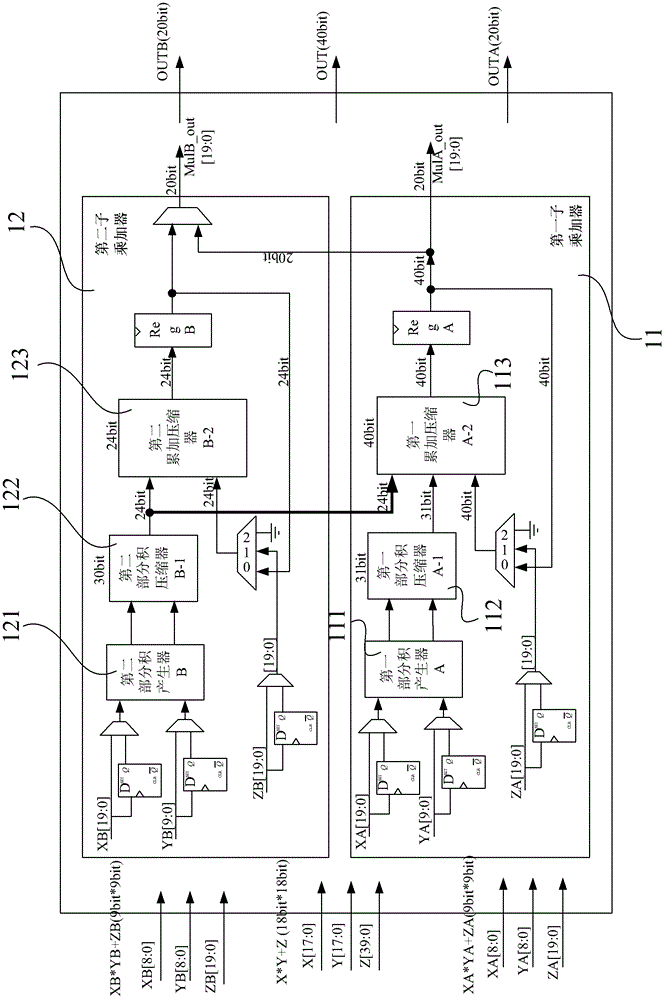
本发明的目的是针对现有技术的缺陷,提供了一种乘加器,可以在节约资源的情况下,快速的完成处理操作。为实现上述目的,本发明提供了一种乘加器,所述乘加器包括两个子乘加器,每个所述子乘加器具体包括:部分积产生器,用于对小于第一位数阈值的乘数和小于第一位数阈值的被乘数相乘,获得部分积数据;部分积压缩器,用于对所述部分积数据进行压缩处理,获得部分积压缩数据;累加压缩器,用于对所述部分积压缩数据,以及加法数据做累加处理,获得求和数据。本发明的乘加器可以实现1个18*18bit(或以下)或2个并行9*9bit(或以下)的乘加处理,资源利用率高;在操作数较大位宽时提高了运算速度;在操作数较小位宽时,提高了资源的利用率。附图说明图1为现有的乘加器的示意图;图2为本发明乘加器的示意图。具体实施方式下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。本发明的乘加器(MACIP),在占用资源相同的情况下,通过灵巧的配置输入操作数的位置,可实现一个第一位数阈值(第一位数),如18*18bit(含以下)且带40bit累加的操作,也可实现2个并行的第二位数阈值(第二位数),如9*9bit(含以下)且带20bit累加的操作,支持有符号数或无符号数。在MACIP中,为了节约面积和提高运算速度,采用了ModifiedRadix-4boothMultipliers算法,同时在部分积(PartialProduct)累加时,充分利用了算法中的压缩技巧,将压缩任务分配给两个压缩器并行实现,提高了运算速度。另外,在相同的IP资源上,实现了1个18*18bit或两个9*9bit的MACIP,提高了资源利用率。本发明包括两个子乘加器,子乘加器具体包括:部分积产生器、部分积压缩器和累加压缩器。部分积产生器用于对小于第一位数阈值的乘数和小于第一位数阈值的被乘数相乘,获得部分积数据;部分积压缩器用于对所述部分积数据进行压缩处理,获得部分积压缩数据;累加压缩器用于对所述部分积压缩数据,以及加法数据做累加处理,获得求和数据。图2为本发明乘加器的示意图,如图所示,本实施例的乘加器具体包括两个子乘加器,即第一子乘加器11和第二子乘加器12。第一子乘加器11具有第一部分积产生器111(PartialProductorgenerator)、第一部分积压缩器112(PPSumCompressor)和第一累加压缩器113(AccumulatorCompressor);第二子乘加器12具有第二部分积产生器121、第二部分积压缩器122和第二累加压缩器123。本发明的乘加器可以实现两个第一位数,例如9*9bit的运算,OUTA[19:0]=XA[8:0]*YA[8:0]+ZA[19:0]和OUTB[19:0]=XB[8:0]*YB[8:0]+ZB[19:0],并有overflow指示;也可以实现一个第二位数,如18*18bit的运算,如OUT[39:0]=X[17:0]*Y[17:0]+Z[39:0]。为了兼容有符号数或无符号数的运算,对于乘加器中的每一个子乘加器处理的任意一个操作数,进行符号位扩展。具体符号位扩展方式是:对于有符号数,在其最高位前面扩展符号位;对于无符号数,在其最高位前面补零即可;以下叙述中,涉及到符号位扩展,原则都是相同的。第一子乘加器MultA11和第二子乘加器MultB12可以共同支持1个18*18bit,或者第一子乘加器MultA11和第二子乘加器MultB12可以单独并行9*9bit,并且两个子乘加器是20bit*10bit的有符号数乘法器,采用了ModifiedRadix-4booth算法实现。下面详细说明第一子乘加器MultA和第二子乘加器MultB如何具体处理过程。1、第一子乘加器MultA和第二子乘加器MultB分别单独处理第一位数阈值,如9*9bit;当乘加器处理的位数均小于第一位数阈值,例如9*9bit,则加法器可以利用第一子加法器和第二子加法器实现2个并行9*9bit的模式,即实现第一子乘加器输出OUTA[19:0]=XA[8:0]*YA[8:0]+ZA[19:0]和第二子乘加器输出OUTB[19:0]=XB[8:0]*YB[8:0]+ZB[19:0]。在第一子加法器的第一部分积产生器中,用于乘数{sign,YA[8:0]}和被乘数{sign,sign,XA[8:0],0,0,0,0,0,0,0,0,0}相乘,获得部分积数据并输出;第一部分积压缩器对部分积数据进行压缩处理,获得部分积压缩数据;第一累加压缩器对部分积压缩数据,以及加法数据ZA[19:0]做累加处理,获得求和数据。输入操作数配置如下:对于MultA:被乘数为{sign,sign,XA[8:0],0,0,0,0,0,0,0,0,0};乘数为{sign,YA[8:0]};加法输入为ZA[19:0];输出求和数据OUTA[19:0]为MultA_out[19:0]在第二子加法器的第二部分积产生器中,用于乘数{sign,YB[8:0]}和被乘数{sign,sign,XB[8:0],0,0,0,0,0,0,0,0,0}相乘,获得部分积数据并输出;第二部分积压缩器对部分积数据进行压缩处理,获得部分积压缩数据;第二累加压缩器对部分积压缩数据,以及加法数据ZB[19:0]做累加处理,获得求和数据。输入操作数配置如下:对于MultB:被乘数为{sign,sign,XB[8:0],0,0,0,0,0,0,0,0,0};乘数为{sign,YB[8:0]};加法输入为ZB[19:0];输出求和数据OUTB[19:0]为MultB_out[19:0]在2个子乘加器并行9*9bit(及以下)的模式下,第一子乘加器MultA或第二子乘加器MultB独立运算,将各自所有的部分积(PartialProduct,共5个)压缩并求和,产生OUTA或OUTB,结果可分别通过MultA_out[19:0]或MultB_out[19:0]输出。2、第一子乘加器MultA和第二子乘加器MultB同时处理第二位数阈值,如18*18bit;当乘加器处理的位数大于第一位数阈值,例如9*9bit,但是小于第二位数阈值,例如18*18bit,则加法器可以利用第一子加法器和第二子加法器共同实现18*18bit的模式,即实现乘加器输出数据0UT[39:0]=X[17:0]*Y[17:0]+Z[39:0]时:第一子乘加器的第一部分积产生器用于乘数高位Y[9:0]和被乘数{sign,sign,X[17:0]}相乘,获得第一部分积数据;第二子乘加器的第二部分积产生器用于乘数{sign,sign,Y[17:9]}低位和被乘数{sign,sign,X[17:0]}相乘,获得第二部分积数据。然后由第一累加压缩器或第二累加压缩器对第一部分积数据、第二部分积数据以及加法数据Z[39:0]做累加处理,获得求和数据。输入操作数配置如下:对于MultA:被乘数为{sign,sign,X[17:0]};乘数为Y[9:0];加法输入为Z[39:0];对于MultB:被乘数为{sign,sign,X[17:0]};乘数为{sign,sign,Y[17:9]};加法输入为24’d0;输出求和数据0UT[39:0]为{MultB_out[19:0],MultA_out[19:0]}当乘加器在处理1个18*18bit(及以下)的模式下,由于将乘数分割成了高9bit和低9bit两部分,故首先第一子乘加器MultA和第二子乘加器MultB各自完成一半的部分积压缩,即5个部分积在各自的乘法器内完成了压缩,然后第二子乘加器MultB将压缩好的中间结果(第二压缩部分积数据)传递到第一子乘加器MultA的第一累加压缩器AccumulatorCompressorA-2,与第一子乘加器MultA的中间结果(第一压缩部分积数据)和加法数据一起,完成全部压缩并求和,最终结果通过组合{MultB_out[19:0],multA_out[19:0]}输出。根据应用情况,通过安排输入操作数的具体位置,可以实现1个18*18bit和2个9*9bit的乘加运算共享部分逻辑。从实现结构可以看出,在18*18bit模式下,部分和的压缩任务分成了两块,由MultB和MultA并行完成,最后由MultA将两个结果相加,输出最终结果。这样的实现也提高了较长位宽时的计算速度,且MultB的部分和压缩逻辑实现了不同模式下的资源共享。用户可通过MACIPUserWizard,根据具体操作数的位宽情况,灵活配置内置的MACIP输入。例如,可将一个18*18bit的MACIP,配置成两个独立的9*9bit的子乘加器使用。如现有技术的4个8*8bit的MACIP,此时只需要调用两个18*18bit的MACIP即可实现。这在芯片资源有限且操作位数宽较少的情况下,提高了乘加器的利用效率约一倍。同时在操作位数宽较多的情况下,运算速度也有提高。本发明的乘加器实现了1个18*18bit或2个并行9*9bit的MACIP,部分资源共享,资源利用率提高;根据操作数的宽度,选择并设置硬件乘加器的操作数,使用合理的结构,在较大位宽时提高了运算速度,在较小位宽时提高了资源的利用率。专业人员应该还可以进一步意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。结合本文中所公开的实施例描述的方法或算法的步骤可以用硬件、处理器执行的软件模块,或者二者的结合来实施。软件模块可以置于随机存储器(RAM)、内存、只读存储器(ROM)、电可编程ROM、电可擦除可编程ROM、寄存器、硬盘、可移动磁盘、CD-ROM、或技术领域内所公知的任意其它形式的存储介质中。以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1